
Ce blog n'a d'autre prétention que de me permettre de mettre à la disposition de tous des petits textes que j'écris. On y parle surtout d'informatique mais d'autres sujets apparaissent parfois.
À quoi ressemblera la résolution de noms dans l'Internet de demain ?
Première rédaction de cet article le 25 décembre 2011
Dans tout réseau, il y a besoin d'un mécanisme de
résolution des noms, traduisant les noms en
identificateurs de plus bas niveau, plus proches du fonctionnement
technique du réseau. C'est ainsi que, de 1983 à
2011, la résolution de noms sur l'Internet a
surtout été assurée par le DNS, permettant
ainsi de séparer des noms stables, comme
www.example.org, des identificateurs moins stables,
comme 2001:db8:af::1:567. Mais est-ce que cela
sera toujours le cas demain ?
Car le DNS est aujourd'hui menacé. Pas par les vagues
projets de construire un système « meilleur », tâche plus compliquée qu'elle n'en a l'air. Mais par
l'intérêt que portent des forces néfastes au DNS, et par les réactions
que cela va entraîner. Aujourd'hui, avec le DNS, nous avons sur
l'Internet un système d'une très grande fiabilité (les attaques
DoS contre la racine ont
toujours échoué, par exemple), largement
déployé, qui permet des identificateurs stables (mon blog est resté en
www.bortzmeyer.org même lorsque je suis passé de
Slicehost à 6sync), et
qui assure une signification unique pour les noms. Pas besoin de
nuancer, de se renseigner, de demander quel réseau utilise son
interlocuteur, on est sûr que tout le monde pourra utiliser
www.bortzmeyer.org et avoir un résultat
équivalent.
En raison de ces propriétés, le DNS est donc aujourd'hui à la base de toutes les transactions sur l'Internet, qui commencent toujours par une requête DNS (et parfois bien plus).
Ce rôle a évidemment attiré l'attention des méchants, notamment des censeurs. C'est ainsi que la loi LOPPSI en France permet d'imposer aux FAI de bloquer l'accès à certains sites, sur simple décision administrative (pour éviter que les citoyens puissent prendre connaissance de la liste des sites bloqués, et vérifier qu'ils sont bloqués pour de bonnes raisons). Un des mécanismes évidents pour mettre en œuvre ce blocage est le DNS (transformation du résolveur du FAI en DNS menteur, avec blocage du port 53). Déjà, de nombreux commerciaux font le tour des acteurs de l'Internet pour promouvoir des solutions de filtrage DNS, qui est également possible dans des logiciels comme BIND (avec la RPZ). La France dispose d'une grande avance technologique dans ce domaine, avec des entreprises comme Amesys, fournisseur de censure pour l'ex-dictature lybienne.
Les autres pays ne sont pas en reste et c'est ainsi que les États-Unis ont leur projet SOPA, équivalent de la LOPPSI, qui permet également d'obliger les FAI à bloquer l'accès à tel ou tel site. Comme, là encore, une implémentation évidente d'un tel système est via le DNS, SOPA a suscité des réactions vigoureuses de la part des acteurs du DNS, ce qui explique en partie le recul des promoteurs du projet. Toutefois, la présence ou l'absence de cette loi ne sera pas forcément le facteur principal : un certain nombre d'opérateurs censurent déjà via le DNS (c'est donc une censure privée, contrairement à SOPA qui proposait une censure étatique).
Naturellement, cette censure ne restera pas sans réponse. Des tas de gens chercheront des contournements, des moyens de passer outre à la censure, comme cela s'est déjà produit pour Wikileaks. Comme le dit An dans les commentaires d'un blog : « Dans le temps, on s'échangeait des adresses de ftp warez. Dans un futur proche, on s'échangera peut-être des fichiers hosts contenant des listes:
warez1 @IP1 warez2 @IP2 etc...
et on lancera bien gentiment notre navigateur sur http://warez1, http://warez2 etc..
les sites webs auront été hackés et se verront ajouter un hostname warez1 qui servira
des films de vacances d'été comme au bon vieux temps du ftp warez. Ça ne tiendra pas
longtemps, ça sera difficilement traçable, et ça bougera bien trop rapidement pour
être coincé. ». D'autres tentatives ont déjà été faites, de diffuser
des listes d'adresses IP, suscitant de
vives discussions. En d'autres termes, il s'agit de revenir aux
anciennes listes genre
hosts.txt distribuées, et
jamais parfaitement à jour (comme le note Pierre Beyssac, ce sera du « hosts.txt, cloud-style »).
Autre solution, on verra apparaître des résolveurs DNS promettant de ne pas censurer comme ceux de Telecomix. Des outils apparaîtront pour permettre de changer de résolveur DNS plus facilement (comme le montre l'article de Korben).
Ces réactions entraineront à leur tour des contre-réactions, vers davantage de contrôle, comme l'industrie du divertissement le prévoit déjà.
Lors d'une discussion sur la liste FRnog, Ronan Keryell s'exclamait : « Je pense qu'il faut à la base arrêter de tuer Internet.
C'était mieux avant (quand nous utilisions tous les 2 Internet dans les
années 80... :-) ).
Doit-on vraiment revenir au bon vieux hosts.txt
(RFC 952 pour ceux qui ont oublié ou plus
probablement ici n'ont jamais connu) face à tous ces délires de filtrage
et de résolution de faux problèmes imaginaires pour le bonheur de
l'utilisateur comme dans toute dictature qui se respecte ?
Stop ! On s'arrête ! ».
Mais nous en sommes déjà là, à revenir à des systèmes mal fichus, dont le résultat varie selon l'utilisateur, et dont la fiabilité n'est pas garantie. Les gens qui font les lois comme LOPPSI ou SOPA se moquent bien de tuer l'Internet. Ce n'est pas par ignorance de la technique qu'ils décident des mesures qui vont gravement blesser l'Internet. Ils veulent le contrôle avant tout, même au prix de problèmes permanents pour les utilisateurs.
Petit à petit, ces utilisateurs vont se servir de systèmes de résolution « inhabituels ». Ce seront des résolveurs DNS avec des règles spéciales (comme le plugin Firefox de Pirate Bay) puis des infrastructures utilisant le protocole DNS mais avec des données différentes (comme les racines alternatives sauf que cette fois, cela sera réellement adopté massivement, car il existe une forte motivation, qui manquait aux racines alternatives d'il y a dix ans, qui n'avaient rien à proposer aux utilisateurs).
On verra par exemple des « pseudo-registres » qui partiront des données des « vrais » registres puis les « corrigeront », ajouteront des termes ou d'autres, à partir d'une base à eux (contenant les domaines censurés).
Puis cela sera des systèmes de résolution nouveaux, comme Namecoin,
avec des passerelles vers le DNS (projet .bit).
Pour l'utilisateur, cela entrainera désordre et confusion. Des noms
marcheront à
certains endroits et pas d'autres. On verra des tas de discussions sur
des forums avec des conseils plus ou moins avisés du genre « pour voir
tous les .fr, utilise
telle ou telle adresse de résolveur DNS, et
pas ceux de X ou de Y qui sont
censurés ».
À la fin de l'année 2011, ce scénario catastrophe semble difficilement évitable, sauf réaction vigoureuse contre les ayant-trop-de-droits et autres censeurs.
L'article seul
RFC 6474: vCard Format Extensions : place of birth, place and date of death
Date de publication du RFC : Décembre 2011
Auteur(s) du RFC : K. Li, B. Leiba (Huawei Technologies)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF vcarddav
Première rédaction de cet article le 24 décembre 2011
Le format de carte de visite numérique
vCard, normalisé dans le RFC 6350, est un des grands succès de l'Internet. On trouve ces
cartes partout. Le format de base définit un jeu de données limité
mais permet des extensions. Ce RFC est donc la
première extension à vCard version 4 (ex-aequo avec celle du RFC 6473), et normalise des
champs pour indiquer un lieu de naissance, un lieu de mort et une date
de mort (la date de naissance, BDAY, est dans le
format de base).
La section 2 décrit ces trois propriétés, toutes facultatives :
BIRTHPLACEindique le lieu de naissance. Il peut être indiqué en texte libre ou bien sous forme d'une URI, comme par exemple les URI de plangeo:du RFC 5870. Ainsi, Jésus-Christ pourrait avoirBIRTHPLACE: Dans une grange, Bethléem (Palestine)ou bienBIRTHPLACE;VALUE=uri:geo:31.7031,35.196.DEATHPLACEindique le lieu de mort, par exempleDEATHPLACE: Colline du Golgotha, Jérusalem(le RFC fournit un exemple où la longitude et latitude indiqués sont celles du point où a coulé le Titanic).DEATHDATEindique la date de la mort. Il avait longtemps été envisagé de la garder dans le format de base, commeBDAYmais elle avait finalement été retirée, suite à la réunion IETF de Pékin en 2010. Comme son homologueBDAY, le format préféré deDEATHDATEest celui d'ISO 8601 (cf. RFC 6350, section 4.3), par exempleDEATHDATE:00300501(date mise un peu au hasard, vu le manque de sources fiables...). Mais on peut aussi utiliser du texte libre pour le cas où on doit utiliser des formules vagues comme « au début du treizième siècle ».
Un exemple complet d'une vCard avec ces trois propriétés est :
BEGIN:VCARD VERSION:4.0 FN:Jeanne d'Arc N:d'Arc;Jeanne;;; UID:urn:uuid:4f660936-28d5-46bf-86c6-9720411ac02a GENDER:F KIND:individual TITLE:Bergère TITLE:Pucelle TITLE:Sauveuse de la France PHOTO:http://commons.wikimedia.org/wiki/File:Lenepveu,_Jeanne_d%27Arc_au_si%C3%A8ge_d%27Orl%C3%A9ans.jpg LANG:fr URL:http://fr.wikipedia.org/wiki/Jeanne_d%27arc BDAY:14120106 BIRTHPLACE:Domrémy (Lorraine) DEATHDATE:14310530 DEATHPLACE:Rouen (Normandie) END:VCARD
Ces trois nouvelles propriétés sont désormais enregistrées dans le registre IANA.
L'article seul
RFC 6434: IPv6 Node Requirements
Date de publication du RFC : Décembre 2011
Auteur(s) du RFC : E. Jankiewicz (SRI International), J. Loughney (Nokia), T. Narten (IBM Corporation)
Pour information
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 22 décembre 2011
Il existe des tas de RFC qui concernent IPv6 et le programmeur qui met en œuvre ce protocole dans une machine risque fort d'en rater certains, ou bien d'implémenter certains qu'il aurait pu éviter. Ce RFC était donc un méta-RFC, chargé de dresser la liste de ce qui est indispensable dans une machine IPv6. Il a été remplacé depuis par le RFC 8504. Les deux points les plus chauds concernaient la configuration (par DHCP ou par RA - Router Advertisment ?) et la gestion d'IPsec, désormais officiellement facultative.
Ce document remplace son prédécesseur, le RFC 4294 (et est lui-même remplacé par le RFC 8504. Il vise le même but, servir de carte au développeur qui veut doter un système de capacités IPv6 et qui se demande s'il doit vraiment tout faire (réponse : non). Ce RFC explique clairement quels sont les points d'IPv6 qu'on ne peut pas négliger, sous peine de ne pas pouvoir interagir avec les autres machines IPv6. Le reste est laissé à l'appréciation du développeur. La section 2 résume ce but.
Les deux gros changements par rapport au RFC 4294 sont :
- DHCP monte en grade, bien que restant derrière les RA pour la configuration des machines IPv6,
- IPsec n'est plus obligatoire.
Ce RFC s'applique à tous les nœuds IPv6, aussi bien les routeurs (ceux qui transmettent des paquets IPv6 reçus qui ne leur étaient pas destinés) que les machines terminales (toutes les autres).
Bien, maintenant, les obligations d'une machine IPv6, dans l'ordre. D'abord, la couche 2 (section 4 du RFC). Comme IPv4, IPv6 peut tourner sur des tas de couches de liaison différentes et d'autres apparaîtront certainement dans le futur. En attendant, on en a déjà beaucoup, Ethernet (RFC 2464), 802.16 (RFC 5121), PPP (RFC 5072) et bien d'autres, sans compter les tunnels.
Ensuite, la couche 3 (section 5 du RFC) qui est évidemment le gros morceau puisque c'est la couche d'IP. Le cœur d'IPv6 est normalisé dans le RFC 2460 et ce dernier RFC doit donc être intégralement implémenté, à l'exception de l'en-tête de routage de type 0, qui a été abandonné par le RFC 5095.
Comme IPv6, contrairement à IPv4, ne permet pas aux routeurs intermédiaires de fragmenter les paquets, la découverte de la MTU du chemin est particulièrement cruciale. La mise en œuvre du RFC 1981 est donc recommandée. Seules les machines ayant des ressources très limitées (genre où tout doit tenir dans la ROM de démarrage) sont dispensées. Mais le RFC se doit de rappeler que la détection de la MTU du chemin est malheuresement peu fiable dans l'Internet actuel, en raison du grand nombre de pare-feux configurés avec les pieds et qui bloquent tout l'ICMP. Il peut être donc nécessaire de se rabattre sur les techniques du RFC 4821).
Le RFC 2460 décrit le format des paquets et leur traitement. Les adresses y sont simplement mentionnées comme des champs de 128 bits de long. Leur architecture est normalisée dans le RFC 4291, qui est obligatoire.
Également indispensable à toute machine IPv6, l'autoconfiguration sans état du RFC 4862, ainsi que ses protocoles auxiliaires comme la détection d'une adresse déjà utilisée.
ICMP (RFC 4443) est évidemment obligatoire, c'est le protocole de signalisation d'IP (une des erreurs les plus courantes des administrateurs réseaux incompétents est de bloquer ICMP sur les pare-feux).
Dernier protocole obligatoire, la sélection de l'adresse source selon les règles du RFC 3484 (depuis remplacé par le RFC 6724), pour le cas où la machine aurait le choix entre plusieurs adresses (ce qui est plus fréquent en IPv6 qu'en IPv4).
Le reste n'est en général pas absolument obligatoire mais recommandé (le terme a un sens précis dans les RFC, définie dans le RFC 2119 : ce qui est marqué d'un SHOULD doit être mis œuvre, sauf si on a une bonne raison explicite et qu'on sait exactement ce qu'on fait). Par exemple, la découverte des voisins (NDP, RFC 4861) est recommandée. Toutes les machines IPv6 en ont besoin, sauf si elles utilisent les liens ne permettant pas la diffusion.
Moins générale, la sélection d'une route par défaut s'il en existe plusieurs, telle que la normalise le RFC 4191. Elle est particulièrement importante pour les environnements SOHO (RFC 7084).
On a vu que l'autoconfiguration sans état (sans qu'un serveur doive se souvenir de qui a quelle adresse) était obligatoire. DHCP (RFC 8415), lui, n'est que recommandé.
Une extension utile (mais pas obligatoire) d'IP est celle des adresses IP temporaires du RFC 8981, permettant de résoudre certains problèmes de protection de la vie privée. Évidemment, elle n'a pas de sens pour toutes les machines (par exemple, un serveur dans son rack n'en a typiquement pas besoin). Elle est par contre recommandée pour les autres.
Encore moins d'usage général, la sécurisation des annonces de route (et des résolutions d'adresses des voisins) avec le protocole SEND (RFC 3971). Le déploiement effectif de SEND est très faible et le RFC ne peut donc pas recommander cette technique pour laquelle on n'a pas d'expérience, et qui reste simplement optionnelle.
L'une des grandes questions que se pose l'administrateur réseaux avec IPv6 a toujours été « autoconfiguration RA - Router Advertisment - ou bien DHCP ? » C'est l'un des gros points de ce RFC et la section 6 le discute en détail. Au début d'IPv6, DHCP n'existait pas encore pour IPv6 et les RA ne permettaient pas encore de transmettre des informations pourtant indispensables comme les adresses des résolveurs DNS (le RFC 6106 a résolu cela). Aujourd'hui, les deux protocoles ont à peu près des capacités équivalentes. RA a l'avantage d'être sans état, DHCP a l'avantage de permettre des options de configuration différentes par machine. Alors, quel protocole choisir ? Le problème de l'IETF est que si on en normalise deux, en laissant les administrateurs du réseau choisir, on court le risque de se trouver dans des situations où le réseau a choisi DHCP alors que la machine attend du RA ou bien le contraire. Bref, on n'aurait pas d'interopérabilité, ce qui est le but premier des normes Internet. Lorsque l'environnement est très fermé (un seul fournisseur, machines toutes choisies par l'administrateur réseaux), ce n'est pas un gros problème. Mais dans un environnement ouvert, par exemple un campus universitaire ou un hotspot Wifi, que faire ? Comme l'indiquent les sections 5.9.2 et 5.9.5, seul RA est obligatoire, DHCP ne l'est pas. RA est donc toujours la méthode recommandée si on doit n'en choisir qu'une, c'est la seule qui garantit l'interopérabilité. (Voir aussi la section 7.2 sur DHCP.)
Continuons à grimper vers les couches hautes. La section 7 est
consacrée aux questions DNS. Une machine IPv6
devrait pouvoir suivre le RFC 3596 et donc avoir
la possibilité de gérer des enregistrements DNS de type AAAA (les
adresses IPv6) et la résolution d'adresses en noms grâce à des
enregistrements PTR dans
ip6.arpa. Les anciens enregistrements A6 (RFC 3363) ont été
abandonnés mais on constate que ces
enregistrements sont toujours très demandés lors des requêtes à des
serveurs DNS faisant autorité, comme ceux de
.fr (dans les 0,5 % des requêtes, soit davantage que SRV ou DS).
À noter qu'une machine IPv6, aujourd'hui, a de fortes chances de se retrouver dans un environnement où il y aura une majorité du trafic en IPv4 (c'est certainement le cas si cet environnement est l'Internet). La section 8 rappelle donc qu'une machine IPv6 peut avoir intérêt à avoir également IPv4 et à déployer des techniques de transition comme la double-pile du RFC 4213.
Encore juste une étape et nous en sommes à la couche 7, à laquelle la section 9 est consacrée. Si elle parle de certains détails de présentation des adresses (RFC 5952), elle est surtout consacrée à la question des API. En 2011, on peut dire que la grande majorité des machines a IPv6, côté couche 3 (ce qui ne veut pas dire que c'est activé, ni que le réseau le route). Mais les applications sont souvent en retard et beaucoup ne peuvent tout simplement pas communiquer avec une autre machine en IPv6. L'IETF ne normalise pas traditionnellement les API donc il n'y a pas d'API recommandée ou officielle dans ce RFC, juste de l'insistance sur le fait qu'il faut fournir une API IPv6 aux applications, si on veut qu'elles utilisent cette version d'IP, et qu'il en existe déjà, dans les RFC 3493 (fonctions de base) et RFC 3542 (fonctions avancées).
La sécurité d'IPv6 a fait bouger beaucoup d'électrons, longtemps avant que le protocole ne soit suffisamment déployé pour qu'on puisse avoir des retours d'expérience. Certains ont survendu IPv6 en prétendant que, contrairement à IPv4, il avait la sécurité intégrée dès le début et était donc plus sûr. Cette légende vient du fait qu'en théorie, IPsec était obligatoire pour toute mise en œuvre d'IPv6. Ce point n'a jamais été respecté par les implémentations (et puis, de toute façon, avoir IPsec est une chose, l'activer, avec sa complexe configuration, en est une autre). Désormais, depuis la sortie de notre RFC 6434, ce point n'est même plus vrai en théorie, IPsec (RFC 4301) est officiellement simplement recommandé.
Le RFC note donc bien que la sécurité est un processus complexe, qui ne dépend certainement pas que d'une technique magique (« IPsec est intégré donc il n'y a pas de problème de sécurité ») et qu'aucun clair gagnant n'émerge de la liste des solutions de sécurité (IPsec, TLS, SSH, etc). D'autant plus qu'IPv6 vise à être déployé dans des contextes comme « l'Internet des Trucs » où beaucoup de machines n'auront pas forcément les ressources nécessaires pour faire de l'IPsec.
Toutes les règles et recommandations précédentes étaient pour tous les nœuds IPv6. La section 12 expose les règles spécifiques aux routeurs. Ils doivent être capables d'envoyer les Router Advertisment et de répondre aux Router Solicitation du RFC 4861 et on suggère aux routeurs SOHO d'envisager sérieusement d'inclure un serveur DHCP (RFC 7084) et aux routeurs de réseaux locaux de permettre le relayage des requêtes DHCP.
Enfin, la section 13 se penche sur la gestion des réseaux IPv6 en notant que deux MIB sont obligatoires, celle du RFC 4292 sur la table de routage, et celle du RFC 4293 sur IP en général.
Les changements par rapport au RFC 4294 sont résumés dans l'annexe 16. Les deux plus importants, comme déjà noté, sont IPsec et DHCP, un qui descend, l'autre qui monte. Mais on y trouve aussi l'arrivée de SEND (mais en option), celle des options DNS du RFC 6106, et beaucoup de détails et de clarifications. Depuis, le RFC 8504 a aussi apporté ses changements.
L'article seul
Administration de machines Unix dans plusieurs fuseaux horaires
Première rédaction de cet article le 16 décembre 2011
Dernière mise à jour le 17 décembre 2011
Si vous administrez des machines Unix situées dans plusieurs fuseaux horaires, vous vous êtes peut-être déjà posé la question : quel fuseau indiquer à la machine ? Celui de sa localisation physique ? Celui de votre localisation physique ? Un autre ?
Voici la situation : Jean Michu, administrateur
système est à Paris et il gère des
machines à Newark,
Saint-Louis et d'autres endroits. Sur
Unix, on peut configurer chaque machine pour
indiquer son fuseau horaire (je ne crois pas qu'il existe de moyen
standard, par contre, sur Debian, c'est
dpkg-reconfigure tzdata et sur Red Hat, c'est vi /etc/sysconfig/clock). Mais lequel indiquer ?
Il y a au moins trois solutions :
- La localisation physique de la machine. Cela peut être plus pratique lorsqu'on veut communiquer avec des humains qui sont sur place, par exemple pour coordonner une intervention. Mais, autrement, cette localisation est une des choses les moins importantes dans l'Internet d'aujourd'hui. Avec le nuage, on peut même ne pas savoir dans quel fuseau horaire se trouve la machine qu'on administre. En outre, cela rend plus difficile de comparer des estampilles temporelles sur les différentes machines (par exemple pour déterminer si elles ont eu le même problème au même moment).
- La localisation physique de l'administrateur système. Cela a certainement plus de sens que celle de la machine : contrairement aux ordinateurs, les humains sont fortement dépendants de l'heure (la machine se moque de travailler à deux heures du matin ou à quatre heures de l'après-midi). Mais l'administrateur peut se déplacer. S'il se trouve temporairement en Chine, il va devoir jongler entre le fuseau horaire de sa localisation habituelle et celui de sa localisation actuelle. Et, surtout, s'il y a plusieurs administrateurs système, qui peuvent être dans des fuseaux horaires différents, cette méthode ne marche plus du tout.
- UTC? Ce fuseau horaire a l'avantage d'être normalisé, et d'avoir un sens pour tout le monde quel que soit sa localisation sur la planète. Lorsqu'il faut communiquer avec d'autres personnes (par exemple parce qu'il y a eu un problème de sécurité et qu'il faut indiquer le contenu d'un journal), UTC est la seule référence internationale.
C'est donc la dernière solution que j'ai choisie. Je configure toutes mes machines de manière à ce que leur heure par défaut soit UTC, ce qui produit des journaux utilisant cette heure.
Mais n'est-ce pas pénible que la commande date donne
cette heure UTC qui ne correspond pas au vécu de l'humain ? Et que
ls -l ne donne pas l'heure légale ?
Heureusement, Unix a réglé le problème depuis longtemps. Il suffit à
chaque administrateur système de définir la variable d'environnement TZ et il aura l'heure
dans son fuseau horaire :
% date Fri Dec 16 20:03:03 UTC 2011 % export TZ=Europe/Paris % % date Fri Dec 16 21:03:08 CET 2011
Même chose pour ls. Si les États-uniens font parfois preuve de provincialisme (par exemple en utilisant ASCII sans penser que sept bits ne suffisaient pas pour toutes les écritures du monde), le fait que leur pays compte plusieurs fuseaux horaires a certainement contribué à mettre en place une gestion correcte de ce concept sur Unix.
Évidemmment, aucune solution n'est parfaite. Par exemple, si on veut configurer cron pour lancer une tâche à une heure légale particulière, il faudra faire un peu de calcul avant de le programmer. Ceci dit, vous pouvez demander à date de le faire pour vous (merci à Gabriel Kerneis pour le rappel). Si vous voulez savoir quelle est l'heure légale à Doualalorsque UTC est à midi :
% TZ=Africa/Douala date --date="2011-12-16 12:00:00Z" Fri Dec 16 13:00:00 WAT 2011
(Le format utilisé est celui du RFC 3339, Z signifiant UTC.)
Si on veut faire l'inverse, trouver quelle sera l'heure UTC correspondant à une certaine heure légale (ici, on se demande quelle sera l'heure UTC lorsqu'il est cinq heures du matin en Californie) :
% TZ=UTC date --date="$(TZ=America/Los_Angeles date --date='2011-12-16 05:00:00')" Fri Dec 16 13:00:00 UTC 2011
Une dernière chose sur les fuseaux horaires. Certaines personnes disent que l'argument de communication (« We observed an abnormal traffic from your AS around 0200 UTC ») n'est pas si important que ça car on peut toujours indiquer le fuseau horaire explicitement, même lorsqu'il n'est pas UTC (« We observed an abnormal traffic from your AS around 0300 CET »). Le problème est que ces abréviations ne sont pas forcément connues mondialement (demandez à un États-unien ce qu'est CET et à un Français à quoi correspond MST) et qu'elles sont ambigues : par exemple EST peut être un fuseau horaire aux États-Unis ou bien en Australie. On peut demander à date d'afficher l'heure avec un fuseau horaire explicite, indiqué numériquement, sans ses abréviations (ici, pour le fuseau horaire de la Californie) :
# Par défaut, affiche une abréviation ambigue % date Sat Dec 17 14:16:40 PST 2011 # Avec un décalage numérique, tout est plus clair % date --rfc-3339=seconds 2011-12-17 14:16:46-08:00
mais les utilisateurs n'y pensent pas toujours.
L'article seul
Quel est le genre des RFC ?
Première rédaction de cet article le 14 décembre 2011
Vous l'avez remarqué, ce blog parle entre autres des RFC, qui représentent un bon bout des articles. Les RFC y sont actuellement mentionnés au masculin (« un RFC », « le RFC 6455 »). Est-ce une règle ? Est-ce la meilleure ?
Je le dis tout de suite, il n'y a pas de réponse simple à cette question. Le terme RFC veut dire en anglais Request For Comments qu'on peut traduire par « demande de commentaires » ou « appel à commentaires » (la traduction que je préfère). Dans le premier cas, on devrait utiliser le féminin, dans le second le masculin. En anglais, la langue dans laquelle sont écrits (écrites ?) les RFC, le terme est neutre. Il ne faut donc pas chercher un argument d'autorité pour trancher.
Et l'usage, que nous dit-il ? Si on cherche sur Google en faisant s'affronter "le RFC" contre "la RFC" ou bien "un RFC" contre "une RFC", on obtient des scores très proches (en décembre 2011, "un RFC" -> 38 200 résultats, "une RFC" -> 29 400 résultats). Il n'y a pas d'interprétation dominante. On trouve même des textes où l'auteur dit à un endroit « une RFC » et à un autre « le RFC 2616 ». À défaut de l'opinion majoritaire, quelle est celle des experts ? Le site du projet de traduction des RFC utilise le féminin. Wikipédia fait de même.
Les arguments basés sur la traduction de Request For Comments ne sont pas parfaits. Écartons d'abord la traduction erronée « requête de commentaires » qui n'est pas du français correct (une requête n'est pas une request). Mais toutes les traductions, même justes, souffrent du même défaut : le sigle n'a plus beaucoup de signification, même en anglais. À l'origine, il avait été choisi par modestie (puisque les costards-cravate refusaient aux documents Internet le titre de normes, on les appelait « appel à commentaires ») et il reflétait une certaine réalité. Aujourd'hui, les RFC sont figés (une fois publié, un RFC n'est jamais modifié, même d'une virgule) et l'étymologie du sigle est devenue très trompeuse (il y a même des projets à l'IETF de supprimer le développé Request For Comments et de ne garder que le sigle).
Une autre traduction possible, qui respecte le sigle, serait « Référence Formalisée par la Communauté », qui décrit bien mieux la réalité des RFC (merci à Emmanuel Saint-James).
Bref, pour l'instant, je traduis par « appel à commentaire » (même si cela ne reflète pas leur réalité de documents stables) et je parle des RFC au masculin. Ça changera peut-être plus tard, mais il me faudra reprendre tout mon blog...
L'article seul
Est-ce la même chose d'accéder à une donnée individuelle, et d'avoir un accès en masse ?
Première rédaction de cet article le 14 décembre 2011
Dans les discussions sur la protection de la vie privée, une confusion est souvent faite entre « donnée accessible publiquement » et « la totalité des données est récupérable » (ce qu'on nomme en anglais le bulk access).
Par exemple, cette confusion est souvent faite dans le cas de
l'accès aux données stockées dans le
DNS. N'importe qui peut interroger les serveurs
DNS de .fr pour savoir si
le nom
anemelectroreculpedalicoupeventombrosoparacloucycle.fr
existe ou pas (on peut aussi le faire via le protocole whois). En revanche, le fichier comportant tous les noms
existants dans .fr n'est pas
disponible. (Certaines zones permettent cet accès.) N'y a-t-il pas
une incohérence ? Si les données sont publiques, quel mal y aurait-il
à donner un accès à l'ensemble de ces données, un « bulk
access » (accès en masse) ?
Techniquement, la différence peut en effet sembler mince : si on
peut faire une requête DNS (ou whois) pour un nom, il est trivial de
faire une boucle pour essayer plein de
noms. Cela se nomme une attaque par dictionnaire et les serveurs de .fr
en voient régulièrement. Mais ce n'est pas très discret.
Et surtout, penser que l'accès individuel (éventuellement répété
dans une boucle) équivaut à l'accès en masse, c'est oublier
l'explosion combinatoire, qui limite
sérieusement les possibilités d'une attaque par
dictionnaire. Imaginons qu'on soit intéressé par les variantes de
mabanqueserieuse.example. Imaginons également qu'on se
limite aux variations d'un seul
caractère. mabanqueserieuse a 17 caractères. En
exploration systématique par des requêtes DNS, il faudrait 36 essais
(les lettres d'ASCII, plus les chiffres et le
tiret, moins le caractère existant) par caractère soit 612 essais. Et
cela ne teste que les substitutions, pas les ajouts ou suppressions
(dont on verra plus loin qu'ils existent). Bref, de tels tests
seraient assez bavards et feraient râler l'administrateur des serveurs
DNS (et c'est encore plus net avec whois). Dans la plupart des cas, énumérer toutes les variantes « intéressantes » (pour faire ensuite des requêtes DNS) n'est pas faisable.
Si on a l'accès en masse, tout est plus simple, car de superbes
algorithmes existent pour rechercher de manière plus efficace. Voyons
un exemple avec le programme agrep
(tre-agrep en fait), -E 1 signifiant qu'on cherche
les noms qui ne diffèrent que d'un seul caractère :
% grep mabanqueserieuse example.txt mabanqueserieuse.example % tre-agrep -E 1 mabanqueserieuse example.txt mabanqueserieuse.example mabanqueserieusr.example mabanqueserieusse.example mbanqueserieuse.example manbanqueserieuse.example ...
et on trouve ainsi de nombreuses autres variantes (testé avec une
banque réelle, où presque toutes les variantes avaient été
enregistrées par un bureau d'enregistrement
situé aux Bahamas). Le fait d'avoir accès à la
totalité de la base permet également des recherches sur une partie du
nom et de trouver ainsi les
doppelgangers comme wwwmabanqueserieuse.fr.
Dans ce cas précis, vous me direz peut-être que détecter les cybersquatteurs opérant depuis un paradis fiscal ne serait pas une mauvaise chose. Mais mon but était de montrer que l'accès aux données en masse permettait des recherches bien plus poussées, et que cela peut se faire au détriment d'innocents (par exemple des particuliers harcelés par les détenteurs de titre de propriété intellectuelle, comme dans l'affaire Milka).
C'est pour cela que le mécanisme NSEC3 du RFC 5155 était important. Sans lui, il était possible d'énumérer tous les noms d'une zone DNS signée avec DNSSEC. Certaines personnes avaient relativisé ce risque en disant « les données DNS sont publiques, de toute façon », ce qui est une sérieuse erreur, comme indiqué plus haut.
Si vous préférez aborder le problème sous l'angle juridique, il faut lire les articles L. 342-1 à 3 du Code de la Propriété Intellectuelle (merci à Thomas Duboucher pour les indications).
Les curieux noteront que les algorithmes de recherche approximative de texte sont proches de ceux utilisés en génomique comme Smith et Waterman ou Needleman et Wunsch. En effet, la recherche d'une séquence de bases dans un génome ne peut pas se faire littéralement, comme avec grep. En raison des mutations et des erreurs dans le séquençage, la correspondance n'est jamais parfaite, et il faut donc accepter, comme dans l'exemple avec tre-agrep, un certain nombre de différences.
L'article seul
Les malheurs du réseau 128.0.0.0/16
Première rédaction de cet article le 13 décembre 2011
Une série de chiffres en vaut une autre, pensez-vous ? Eh bien
non. Quoique numériques, toutes les adresses IP ne se valent pas. Le préfixe
128.0.0.0/16, quoique parfaitement légal, est
ainsi invisible depuis une bonne partie de
l'Internet.
Tentez l'expérience depuis votre machine en visant l'amer mis en place par le RIPE-NCC :
% ping -c 3 128.0.0.1 PING 128.0.0.1 (128.0.0.1) 56(84) bytes of data. 64 bytes from 128.0.0.1: icmp_req=1 ttl=55 time=83.6 ms 64 bytes from 128.0.0.1: icmp_req=2 ttl=55 time=83.8 ms 64 bytes from 128.0.0.1: icmp_req=3 ttl=55 time=83.5 ms --- 128.0.0.1 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2005ms rtt min/avg/max/mdev = 83.519/83.692/83.890/0.367 ms
Si cela marche (comme ci-dessus), vous faites partie des favorisés. Sinon :
% ping -c 3 128.0.0.1 PING 128.0.0.1 (128.0.0.1) 56(84) bytes of data. --- 128.0.0.1 ping statistics --- 3 packets transmitted, 0 received, 100% packet loss, time 2010ms
Mais pourquoi ? Qu'est-ce que ce chiffre a de particulier ?
C'est parce qu'une bogue des routeurs Juniper
traite ce réseau différemment et, par défaut, le considère comme
« martien » (anormal sur l'Internet) et refuse les annonces
BGP pour lui (ce
préfixe était réservé, mais le RFC 3330 l'a libéré en 2002). Le numéro
(interne) de bogue chez Juniper est le PSN-2011-10-393. Le problème est bien expliqué
dans un
article des RIPE labs et son effet mesuré
par les sondes Atlas. Aujourd'hui, un tiers de l'Internet ne
peut pas joindre ce réseau 128.0.0.0/16. Autre
façon de mesurer le même problème, regarder la propagation des
annonces BGP, par exemple au
RIS qui, en décembre 2011, voit une propagation de seulement 80 %.
Une mise à jour existe désormais chez Juniper. On peut aussi
changer la configuration par défaut (qui est incorrecte). Si votre routeur
Juniper affiche 128.0.0.0/16 en réponse à
show route martians, c'est que vous avez la
mauvaise configuration. Changez-la :
set routing-options martians 128.0.0.0/16 orlonger allow set routing-options martians 191.255.0.0/16 orlonger allow set routing-options martians 223.255.255.0/24 exact allow
(Trois préfixes sont concernés, même si c'est surtout le premier qui a fait parler de lui.)
Si vous n'arivez pas à pinguer l'adresse de l'amer ci-dessus, tapez sur votre FAI jusqu'à ce qu'il mette à jour ses routeurs (et ainsi de suite récursivement car cela dépend également de l'opérateur qui connecte le FAI).
Avant la mise à jour, sur la console du routeur :
admin@m7i-2-sqy> show route 128.0.0.1
admin@m7i-2-sqy> show route 128.0.0.1 hidden
SERVICE.inet.0: 395145 destinations, 730370 routes (394162 active, 0
holddown, 1051 hidden)
+ = Active Route, - = Last Active, * = Both
128.0.0.0/21 [BGP/170] 1w5d 21:07:00, localpref 100
AS path: 2200 20965 1103 12654 I
> to 193.51.182.46 via ge-1/3/0.0
Après la mise à jour :
admin@m7i-2-sqy> show route 128.0.0.1
SERVICE.inet.0: 369404 destinations, 369404 routes (368357 active, 0
holddown, 1047 hidden)
+ = Active Route, - = Last Active, * = Both
128.0.0.0/21 +[BGP/170] 00:01:55, localpref 100
AS path: 2200 20965 1103 12654 I
> to 193.51.182.46 via ge-1/3/0.0
Merci à Sylvain Busson pour sa prompte mise à jour des routeurs.
L'article seul
RFC 6458: Sockets API Extensions for Stream Control Transmission Protocol (SCTP)
Date de publication du RFC : Décembre 2011
Auteur(s) du RFC : R. Stewart (Adara Networks), M. Tuexen (Muenster University of Applied Sciences), K. Poon (Oracle Corporation), P. Lei (Cisco Systems), V. Yasevich (HP)
Pour information
Réalisé dans le cadre du groupe de travail IETF tsvwg
Première rédaction de cet article le 12 décembre 2011
Il n'y a pas de protocole qui réussit sans une API, c'est-à-dire une spécification d'une interface qui permet au programmeur d'utiliser le protocole en question. Le protocole de transport SCTP, normalisé dans le RFC 4960, n'avait pas jusqu'à présent d'API standard et les programmes ne fonctionnaient donc qu'avec une seule bibliothèque. Désormais, avec ce RFC, SCTP a des chances de voir le développement de programmes portables.
SCTP est le principal concurrent de TCP dans la catégorie « protocole de couche 4 fiable » (i.e. qui garantit l'acheminement des données, contrairement à UDP). Mais il est beaucoup moins utilisé que TCP, plus ancien, et qui a une API standard depuis longtemps, interface décrite dans la norme POSIX. Il y a aussi d'autres raisons au moindre déploiement de SCTP. Mais l'absence d'API jouait certainement un rôle : pas moyen de programmer avec SCTP sans devoir se limiter, non seulement à un système donné, mais en prime à une mise en œuvre particulière de SCTP. Les instructions d'installation devenaient donc pénibles à lire. C'est ce problème que résout notre RFC.
L'API décrite dans ce RFC est longue (le RFC fait 113 pages) donc je résume plutôt sauvagement. Elle permet d'écrire des programmes qui font la même chose qu'avec TCP, comme des programmes qui tirent profit des fonctions spécifiques de SCTP. Car la sémantique de SCTP n'est pas exactement la même que celle de TCP, le remplacement de l'un par l'autre n'est pas entièrement invisible aux applications. Les points importants de cette nouvelle API :
- Elle est basée sur la traditionnelle interface socket,
- Elle permet le style de programmation un-vers-N (section 3). TCP ne permet que un-vers-un, UDP permet d'utiliser une prise (socket) pour du un-vers-N, et SCTP aussi. En termes SCTP, une prise permet de contrôler plusieurs associations. Par contre, pas de diffusion, que ne permet pas SCTP.
- Elle permet également le style un-vers-un (section 4), familier aux programmeurs qui utilisent TCP. Avec ce style (une seule association par prise), les applications existantes qui se servent de TCP peuvent être portées en SCTP avec très peu d'efforts.
Ces deux styles ne sont pas compatibles dans le même programme, le programmeur devra choisir.
Notez que les efforts de conception d'une API SCTP sont anciens. Résultat, il traîne dans la nature des tutoriels, des Howto, des exemples de programme utilisant des mécanismes qui ne sont plus les mécanismes recommandés. Plusieurs éléments des API expérimentales qui ont précédé celle-ci sont repris dans ce RFC, en les notant comme dépassés et ne devant plus être utilisés pour de nouveaux programmes.
Un programme serveur typique qui utilise le style un-vers-N ressemble à :
socket(..., SOCK_SEQPACKET, IPPROTO_SCTP): /* Le type SOCK_SEQPACKET indique le style 1-vers-n. Section 3.1.1 */ bind(...); listen(...); /* Pas besoin de accept(). Les nouvelles associations sont gérées automatiquement (si le serveur le veut, il est prévenu lors des recvmsg(), évenement SCTP_ASSOC_CHANGE). Section 3.1.3 */ recvmsg(...); sendmsg(...); close(...); /* close() ferme tout. Pour ne fermer qu'une seule association, on utilise sendmsg() avec SCTP_EOF. */
pendant que le client fera plutôt :
socket(..., SOCK_SEQPACKET, IPPROTO_SCTP): sendmsg(...); recvmsg(...); close(...):
Toutes les associations du serveur seront représentées par une seule
prise et distinguées par leur identificateur d'association, de type
sctp_assoc_t. La section 3.3 fournit les détails
pour ce cas. Par exemple, si le programme n'utilise qu'un seul tampon
par prise réseau, une association qui traîne peut bloquer toutes les
autres. Le RFC recommande d'utiliser des prises non-bloquantes.
Quant au style un-vers-un, c'est celui de TCP et il est familier à tous les programmeurs réseau. Il est présenté en section 4. L'idée est qu'une application d'aujourd'hui, qui utilise TCP, sera ainsi portée en très peu de temps.
La séquence de commandes pour le serveur est typiquement :
socket(..., SOCK_STREAM, IPPROTO_SCTP); /* Le protocole IPPROTO_SCTP est la seule différence avec TCP. */ bind(...); listen(...); accept(...); /* Ensuite, recv() et send() avec la nouvelle prise retournée par accept(). */ close(...);
Et chez le client :
socket(..., SOCK_STREAM, IPPROTO_SCTP); connect(...); /* Ensuite, recv()/recvmsg() et send()/sendmsg() */ close(...);
Voici pour le code. La section 5 présente ensuite les nouvelles
structures de données, celles qui sont spécifiques à SCTP, lorsqu'on
utilise recvmsg() et
sendmsg() pour des opérations de
contrôle (et pas seulement d'envoi et de récupération de données). Ces
fonctions prennent un paramètre message de type
msghdr (RFC 3542). On peut
s'en servir pour définir des paramètres de la connexion (options
SCTP_INIT et SCTP_SNDINFO),
ou obtenir des informations supplémentaires lors de la réception de
données (option SCTP_RCVINFO, par exemple le
champ rcv_assoc_id indiquera par quelle
association est venue le message).
Pendant la durée de vie d'une connexion SCTP, des tas d'évenements
qui n'ont pas d'équivalent dans le monde TCP peuvent se produire :
changement d'adresse IP d'un pair
(SCTP_PEER_ADDR_CHANGE, section 6.1.2), établissement de nouvelles
associations (ou arrêt des anciennes,
cf. SCTP_ASSOC_CHANGE, section 6.1.1), etc. La section 6 décrit
comment être informé de ces évenements. Quant aux options des prises spécifiques
à SCTP, elles sont dans la section 8. Elles s'utilisent avec
setsockopt() et
getsockopt(). Par exemple,
SCTP_ASSOCINFO permet d'obtenir (ou de modifier)
les paramètres liés aux associations,
SCTP_PRIMARY_ADDR d'obtenir l'adresse IP du pair
pour une association donnée, etc.
Le RFC contient en annexe A deux exemples d'utilisation de cette API, un pour un serveur en un-vers-N et un pour un client en un-vers-un. Pour les raisons expliquées plus haut (retard à normaliser l'API et bibliothèque non standards développées en attedant), ces exemples ne compilent pas sur une Debian ou une Ubuntu récente :
% gcc sctp-sample-client.c sctp-sample-client.c: In function 'main': sctp-sample-client.c:40:25: error: storage size of 'info' isn't known sctp-sample-client.c:97:54: error: 'SCTP_SENDV_SNDINFO' undeclared (first use in this function) sctp-sample-client.c:97:54: note: each undeclared identifier is reported only once for each function it appears in
Je n'ai pas encore trouvé de système où ces exemples compilent. Il existe en effet plusieurs mises en œuvre de SCTP mais pas de cette API. Plus exactement, les implémentations de cette API sont ultra-récentes et ne sont pas encore arrivés chez l'utilisateur. On a :
- Sur Linux Linux Kernel Stream Control Transmission Protocol (dont l'API est fondée sur une très vieille version de l'Internet-Draft qui a fini par donner naissance à ce RFC),
- Sur FreeBSD, SCTP existe depuis longtemps mais l'API a le même problème.
- Et pareil pour sctplib (une mise en œuvre de SCTP en espace utilisateur) et son API.
Le RFC note que des implémentations de l'API standard existent sur Linux, FreeBSD et Solaris mais leur déploiement effectif est inconnu. Elles ont apparemment déjà servi à ajouter SCTP à Firefox et Chrome.
Le livre de référence sur la programmation réseau, celui de Stevens, ne parle pas de SCTP dans les deux premières éditions. C'est à partir de la troisième édition (réalisée par d'autres, après la mort de l'auteur) que SCTP apparaît.
En attendant, la bogue echoping #1676608 risque d'attendre longtemps (d'autant plus que je n'ai plus le temps de m'occuper d'echoping).
L'article seul
RFC 6455: The WebSocket protocol
Date de publication du RFC : Décembre 2011
Auteur(s) du RFC : I. Fette (Google), A. Melnikov (Isode)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF hybi
Première rédaction de cet article le 12 décembre 2011
Ce nouveau protocole, WebSocket, vise à résoudre un problème embêtant pour les développeurs d'applications réseau. L'architecture de l'Internet était conçue pour que le seul point commun réellement obligatoire soit le protocole de couche 3, IP. Ce protocole est simple et fournit peu de services. Les développeurs qui voulaient des choses en plus les mettaient dans leurs applications ou, la plupart du temps, comptaient sur les protocoles de transport comme TCP. Si aucun des protocoles de transport existant ne satisfaisaient leurs besoins, ils avaient parfaitement le droit d'en inventer un autre et de le déployer sans rien demander à personne (principe dit « de bout en bout »). Ce modèle ne marche plus guère aujourd'hui. Il est devenu très difficile de faire passer un autre protocole de transport que TCP à travers les innombrables obstacles du réseau (NAT et pare-feux, notamment), et même un protocole applicatif nouveau, tournant sur un port TCP à lui, risque d'avoir le plus grand mal à passer. D'où l'idée de base de WebSocket : faire un protocole de transport au dessus de HTTP, qui va être le seul à passer à peu près partout. WebSocket est donc l'aboutissement d'un processus, qui a mené à ce que le protocole d'unification ne soit plus IP mais HTTP. Bienvenue dans l'Internet d'aujourd'hui « Tout sur le port 80 ».
WebSocket n'est toutefois pas un protocole généraliste, il est conçu pour fonctionner essentiellement dans le cadre du navigateur Web qui charge du code inconnu (typiquement en JavaScript) et qui va ensuite l'exécuter. Ce code pourra utiliser le réseau, dans une certaine limite (vers la même origine, cf. RFC 6454) mais les possibilités de communication offertes précédemment étaient limitées. WebSocket donne à ce code JavaScript (ou écrit dans d'autres langages) les possibilités d'une vraie communication réseau bidirectionnelle.
Avant, les applications s'exécutant sur le navigateur n'avaient pas
de moyen simple de faire de telles communications, équivalentes à ce
qu'on fait en TCP. Des applications comme la messagerie instantanée, le partage d'un document en cours d'édition
ou bien comme des jeux en commun souhaitaient un
modèle d'interaction plus riche que le traditionnel
GET du client vers le serveur. Bien sûr, elles
auraient pu être extérieures au navigateur, ce qui était certainement
plus propre du point de vue architectural. Mais elles se heurtent
alors au problème de filtrage décrit plus haut. Et, dans le
navigateur, elles dépendaient de
XMLHttpRequest ou bien de <iframe> et de
polling. Par exemple, un
code tournant sur le navigateur qui voulait simplement se mettre en
attente de donnés émises de manière asynchrone par le serveur n'avait
pas d'autres solutions que d'interroger ce dernier de temps en temps. Ce problème est
décrit en détail dans le RFC 6202. Il avait
plusieurs conséquences fâcheuses comme un surcoût en octets (tout
envoi de données nécessitait les en-têtes HTTP complets) ou comme un
modèle de programmation peu naturel.
WebSocket vise à résoudre ce problème en transformant HTTP en un protocole de transport. Il réutilise toute l'infrastructure HTTP (par exemple les relais ou bien l'authentification). Passant sur les mêmes ports 80 et 443, on espère qu'il réussira à passer partout. Comme le note un observateur, « WebSocket est un protocole totalement alambiqué pour contourner la stupidité du monde ».
Le résultat n'est donc pas parfait (rappelez-vous que HTTP n'avait pas été conçu pour cela) et le RFC note qu'on verra peut-être un jour les services de WebSocket fonctionner directement sur TCP (personnellement, j'ai des doutes, puisqu'on pourrait aussi bien dans ce cas utiliser des protocoles de transport qui fournissent les mêmes services, comme SCTP - RFC 4960).
Une petite note avant d'attaquer le RFC : si vous avez l'habitude de lire des RFC, vous noterez que celui-ci a des notations originales (section 2.1) comme d'utiliser les tirets bas pour souligner les définitions, les barres verticales pour encadrer les noms d'en-têtes ou de variables et les barres obliques pour les valeurs des variables.
La section 1.2 résume le fonctionnement du protocole (le lecteur
pressé du RFC peut d'ailleurs se contenter de la section 1, non
normative mais qui contient l'essentiel sur WebSocket). Le principe
de base est d'utiliser du HTTP normal (RFC 7230) mais le client ajoute un en-tête
Upgrade: à une requête GET, pour indiquer sa volonté de faire du
WebSocket :
GET /chat HTTP/1.1 Host: server.example.com Upgrade: websocket Connection: Upgrade Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ== Origin: http://example.com Sec-WebSocket-Protocol: chat, superchat Sec-WebSocket-Version: 13
Le serveur répond alors par un code 101 et en indiquant upgrade dans
l'en-tête Connection: et en ajoutant des en-têtes
spécifiques à WebSocket :
HTTP/1.1 101 Switching Protocols Upgrade: websocket Connection: Upgrade Sec-WebSocket-Accept: s3pPLMBiTxaQ9kYGzzhZRbK+xOo= Sec-WebSocket-Protocol: chat
Bien sûr, d'autres en-têtes HTTP sont possibles comme les petits gâteaux du RFC 6265. Une fois que le client a fait sa demande, et que le serveur l'a acceptée, il existe une connexion bidirectionnelle entre ces deux acteurs et on peut faire passer les données.
Contrairement à TCP (mais comme dans SCTP), la communication n'est pas un flot d'octets sans structure ; c'est une suite de messages, chacun composé d'une ou plusieurs trames. Les trames sont typées et toutes les trames d'un même message ont le même type. Par exemple, il existe un type texte, où les trames contiennent des caractères Unicode encodés en UTF-8. Il existe évidemment un type binaire. Et il existe des trames de contrôle, conçues pour l'usage du protocole lui-même.
La section 1.3 se focalise sur la poignée de main entre
client et serveur qui lance le protocole (les détails complets étant en section 4). On l'a vu, le client doit
ajouter l'en-tête Upgrade: websocket pour
demander au serveur de basculer en WebSocket (RFC 7230, section 6.7 ; la valeur
websocket pour cet en-tête est enregistrée à l'IANA, cf. section 11.2, et aussi le RFC 2817, section 7.2). Le client indique également des
en-têtes spécifiques à WebSocket comme
Sec-WebSocket-Protocol: qui permet d'indiquer un
protocole applicatif au dessus de WebSocket (chat
dans l'exemple plus haut). Ces protocoles applicatifs (section 1.9)
sont normalement enregistrés à l'IANA pour
assurer l'unicité de leurs noms. L'en-tête Origin: du
RFC 6454 sert à indiquer quelle était l'origine de la page Web
qui a chargé le script client. Quand à
Sec-WebSocket-Key:, son rôle est de permettre de
vérifier que la connexion était bien prévue pour être du WebSocket et
pas des jeux faits par un programme malveillant qui enverrait des
données ressemblant à du WebSocket sur le port 80, sans être passé par
la poignée de main normale. Le serveur doit combiner la valeur de
l'en-tête Sec-WebSocket-Key: avec un
GUID (RFC 9562) fixe,
258EAFA5-E914-47DA-95CA-C5AB0DC85B11. Il passe le résultat par
SHA-1 puis par Base64
et retourne ce résultat au client (dans un en-tête Sec-WebSocket-Accept:), qui peut alors être sûr que c'est
bien ce serveur qui a reçu sa poignée de main. (Voir la section 1.6
sur ce point. Les en-têtes commençant par Sec ne
peuvent pas être ajoutés via du code
XMLHttpRequest normal et, donc, un client
JavaScript ordinaire ne peut pas se comporter en client
WebSocket.)
À noter que les en-têtes spécifiques de WebSocket ont été ajoutés au registre des en-têtes.
La réponse du serveur utilise le code HTTP 101 (qui avait été prévu
de longue date par le RFC 7231, section 6.2.2), qui signifie que le serveur accepte
le changement de protocole. Tout autre code indique que le serveur
n'accepte pas WebSocket et que le client doit donc continuer en HTTP
normal. Ainsi, un serveur HTTP normal refusera l'en-tête Upgrade: :
% telnet www.bortzmeyer.org http Trying 2605:4500:2:245b::bad:dcaf... Connected to www.bortzmeyer.org. Escape character is '^]'. GET / HTTP/1.1 Host: www.bortzmeyer.org Upgrade: websocket HTTP/1.1 400 Bad Request Date: Tue, 29 Nov 2011 21:15:34 GMT Server: Apache/2.2.16 (Debian) Vary: Accept-Encoding Content-Length: 310 Connection: close Content-Type: text/html; charset=iso-8859-1
La section 1.4, elle, décrit la fermeture de la connexion (détails en section 7). Elle se fait par l'envoi d'une trame de contrôle ad hoc. Notez que la simple fermeture de la connexion TCP sous-jacente ne suffit pas forcément : en présence d'intermédiaires, par exemple les relais, elle peut être insuffisante.
Un peu de philosophie après ces détails ? La section 1.5 décrit les concepts à la base de WebSocket. Par exemple, l'un des buts était de garder au strict minimum le nombre de bits de tramage. La structure des données que permet WebSocket est donc réduite (séparation des trames, et typage de celles-ci) et toute structuration plus sophistiquée (par exemple pour indiquer des métadonnées) doit être faite par l'application, au dessus de WebSocket.
Dans cette optique « ne pas trop en ajouter », cette section note que WebSocket ajoute à TCP uniquement :
- Le modèle de sécurité du Web, fondé sur la notion d'origine du RFC 6454,
- Un mécanisme de nommage permettant de mettre plusieurs
applications sur le même port (c'est le chemin donné en argument de la
commande
GET), - Un système de tramage, que n'a pas TCP, qui ne connait que les flots d'octets sans structure,
- Un mécanisme de fermeture explicite de la connexion (on l'a dit, TCP seul ne suffit pas, dans la jungle qu'est le Web d'aujourd'hui, truffé de middleboxes).
Et c'est tout. Le reste doit être fait par les applications. Compte-tenu des contraintes spécifiques du Web, WebSocket offre donc pratiquement le même service aux applications que TCP. Sans ces contraintes Web (de sécurité, de fonctionnement à travers les middleboxes), du TCP brut suffirait.
Voila, vous connaissez maintenant l'essentiel de WebSocket. Le
reste du RFC précise les détails. La section 3 décrit les
URI WebSocket. Ils utilisent le plan
ws: (non chiffré, port 80
par défaut) ou le wss: (chiffré avec
TLS, port 443 par défaut). La section 11 décrit
l'enregistrement de ces plans dans le registre
IANA. Par exemple
ws://example.com/chat est un URI WebSocket (pour la connexion donnée en exemple au début de cet article), comme ws://www.3kbo.com:9090/servers/1/status ou wss://foobar.example/newsfeed.
Comment fonctionne le tramage, le découpage du flot de données en
trames bien délimitées ? La section 5 le normalise avec précision. Une
trame a un type, une longueur et des données. On trouve également
quelques bits comme FIN qui indique la dernière
trame d'un message, ou comme RSV1,
RSV2 et RSV3, réservés pour
de futures extensions du protocole. Une grammaire complète
est donnée en section 5.2, en utilisant ABNF
(RFC 5234. Les fanas d'ABNF noteront que cette
grammaire ne décrit pas des caractères mais des bits, ce qui
représente une utilisation originale de la norme.
Le type est nommé opcode et occupe quatre bits. Les valeurs de 0x0 à 0x7 indiquent une trame de données, les autres sont des trames de contrôle. 0x1 indique une trame de texte, 0x2 du binaire, 0x8 est une trame de contrôle signalant la fin de la connexion, 0x9 une demande d'écho (ping), 0xA une réponse (pong), etc. La sémantique des trames de contrôle figure en section 5.5. On y apprend par exemple que des échos non sollicités (pong non précédé d'un ping) sont légaux et peuvent servir à indiquer qu'une machine est toujours en vie.
On le sait, l'insécurité est une des plaies du Web, on trouve tout le temps de nouvelles manières de pirater les utilisateurs. Les problèmes viennent souvent de nouveaux services ou de nouvelles fonctions qui semblent super-cool sur le moment mais dont on découvre après qu'elles offrent plein de pièges. Il n'est donc pas étonnant que la section 10, sur la sécurité, soit longue.
D'abord, le serveur WebSocket doit se rappeler qu'il peut avoir
deux sortes de clients (section 10.1) : du code « embarqué » par
exemple du JavaScript exécuté par un navigateur
et dont l'environnement d'exécution contraint sérieusement les
possibilités. Par exemple, l'en-tête Origin: est
mis par ce dernier, pas par le code Javascript, qui ne peut donc pas
mentir sur sa provenance. Mais un serveur WebSocket peut aussi être
appelé par un client plus capable, par exemple un programe
autonome. Celui-ci peut alors raconter ce qu'il veut. Le serveur ne
doit donc pas faire confiance (par exemple, il ne doit pas supposer
que les données sont valides : il serait très imprudent de faire
une confiance aveugle au champ Payload length,
qu'un client malveillant a pu mettre à une valeur plus élevée que la
taille de la trame, pour tenter un débordement de
tampon).
WebSocket ayant été conçu pour fonctionner au dessus de
l'infrastructure Web existante, y compris les relais, la section 10.3
décrit les risques que courent ceux-ci. Un exemple est l'envoi, par un
client malveillant, de données qui seront du WebSocket pour le serveur
mais qui sembleront un GET normal pour le
relais. Outre le tramage, la principale protection de WebSocket contre
ce genre d'attaques est le masquage des données avec une clé contrôlée
par l'environnement d'exécution (l'interpréteur JavaScript, par
exemple), pas par l'application (section 5.3 pour en savoir plus sur
le masquage). Ainsi, un code JavaScript méchant ne pourra pas
fabriquer des chaînes de bits de son choix, que WebSocket
transmettrait aveuglément.
Un peu d'histoire et de politique, maintenant. WebSocket a une histoire compliquée. L'idée de pousser les informations du serveur vers le client (connue sous le nom de Comet) est ancienne. Le protocole WebSocket (dont l'un des buts est justement cela) a été créé par Ian Hickson (qui a aussi écrit les premiers projets de RFC mais n'apparait plus comme auteur). Le groupe de travail WHATWG a ensuite beaucoup participé. La plupart des mises en œuvre de WebSocket citent ce groupe ou bien les anciens Internet-Drafts, écrits avant la création du groupe de travail IETF HyBi en janvier 2010.
Le principe même de WebSocket a souvent été contesté. Pourquoi passer tant d'efforts à contourner les problèmes de l'Internet aujourd'hui (notamment les middleboxes abusives) plutôt qu'à les résoudre ? Un intéressant texte de justification a été écrit à ce sujet. Notez qu'il inclut des exemples de code. Le groupe HyBi a connu de vives discussions, avec menaces de scission (« À WHATWG, c'était mieux, on va quitter l'IETF si ça n'avance pas »). Un des points d'affrontement était par exemple les problèmes de sécurité (résolus par la solution du masquage). Cela s'est ensuite arrangé, début 2011.
Si vous voulez vous lancer dans la programmation d'applications WebSocket tournant dans le navigateur, regardez l'API. Aujourd'hui, on trouve des implémentations de WebSocket pour les différents serveurs (GlassFish, Jetty, Apache). Dans les environnements de développement, on trouve du WebSocket chez Django et bien d'autres. Chez les clients, Firefox l'a en théorie depuis la version 6, Chrome et Internet Explorer l'ont annoncé pour une version prochaine. Bon, en pratique, c'est compliqué, et la démo ne donne pas toujours les résultats attendus (elle me refuse mon Firefox 7 mais accepte un Chrome).
Attention si vous lisez les sources, pas mal d'implémentations ont été faites en suivant des vieilles versions de la spécification de WebSocket, antérieures à sa normalisation à l'IETF. Cela se sent par exemple dans les noms des variables utilisés. (Un terme comme « opcode » pour le type est dans le RFC mais pas toujours dans les programmes.)
En dehors du monde des navigateurs, si vous voulez programmer du WebSocket, vous avez, entre autres :
- En Python, la bibliothèque pywebsocket, également ws4py, websocket-client et python-websocket. Ne me demandez pas un avis, je n'ai pas eu l'occasion et le temps de les comparer sérieusement. Je crains que, comme souvent en Python, il y ait pléthore d'implémentations plus au moins au point, et aucune « de référence ».
- En Go, il y a un paquetage dans la bibliothèque standard. Un exemple pour un chat est décrit.
- En C++, il y a la bibliothèque websocketpp.
- Enfin, il existe un article de Wikipédia de comparaison des mises en œuvres.
Si vous voulez jouer plutôt avec un programme client comme curl, vous avez un bon article qui explique comment faire du WebSocket avec curl.
Si vous cherchez des fichiers pcap de Websocket, on en trouve sur pcapr mais attention, la plupart concernent des mises en œuvres de versions antérieures du protocole. Mais Wireshark n'a pas l'air encore capable de décoder le framing Websocket. (Une mise en œuvre existe.)
Les autres registres IANA pour WebSocket
sont en https://www.iana.org/assignments/websocket/websocket.xml. Il existe un site de référence
sur WebSocket.
Un exemple de service publiquement accessible et utilisant WebSocket est le service RIS Live.
Enfin, si vous voulez d'autres articles sur WebSocket, j'ai beaucoup apprécié celui de Brian Raymor.
L'article seul
RFC 6454: The Web Origin Concept
Date de publication du RFC : Décembre 2011
Auteur(s) du RFC : A. Barth (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF websec
Première rédaction de cet article le 12 décembre 2011
Chaque jour, plusieurs failles de sécurité sont annoncées frappant
un site Web, ou, plus rarement, un
navigateur. Ces failles proviennent souvent de
l'exécution de code, par exemple Java ou
JavaScript, téléchargé depuis un serveur qui
n'était pas digne de confiance, et exécuté avec davantage de privilèges
qu'il n'aurait fallu. Une des armes principales utilisées par la
sécurité du Web, pour essayer d'endiguer la marée de ces attaques, est
le concept d'origine. L'idée est que toute
ressource téléchargée (notamment le code) a une origine, et que cette
ressource peut ensuite accéder uniquement à ce qui a la même origine
qu'elle. Ainsi, un code JavaScript téléchargé depuis
www.example.com aura le droit d'accéder à l'arbre
DOM de www.example.com, ou
à ses cookies, mais pas à
ceux de manager.example.net. Ce concept d'origine
semble
simple mais il y a plein de subtileries qui le rendent en fait très
complexe et, surtout, il n'avait jamais été défini précisément. Ce que
tente de faire ce RFC.
Pour comprendre l'importance de l'origine,
revoyons un navigateur Web en action. Imaginons
qu'il n'impose aucune limite au code (Java,
JavaScript, Silverlight,
etc) qu'il exécute. Un méchant pourrait alors mettre du
code malveillant JavaScript sur son serveur, faire de la
publicité (par exemple via le spam) pour
http://www.evil.example/scarlet-johansson-pictures/,
et attendre les visites. Le navigateur récupérerait
l'HTML, puis le JavaScript inclus, et celui-ci
pourrait faire des choses comme lancer une DoS
par connexions HTTP répétées vers
http://www.victim.example/. C'est pour éviter ce
genre d'attaques que tous les navigateurs ont la notion d'origine. Le
code récupéré sur le site du méchant va avoir l'origine
www.evil.example, et le navigateur l'empêchera de
faire des requêtes HTTP vers un autre serveur que
www.evil.example. En gros, le principe
traditionnel de sécurité est « Le contenu récupéré depuis l'origine X
peut interagir librement avec les ressources ayant cette même
origine. Le reste est interdit. » (section 1 du RFC, pour un résumé).
Mais ce principe très simple à énoncer et à comprendre dissimule pas mal de pièges. Ce RFC va donc essayer de les mettre en évidence. À noter qu'il ne fait que fournir un cadre, ce n'est pas un protocole, et il n'y a donc pas besoin de modifier les navigateurs pour obéir à ce texte. Les détails concrets du principe d'origine vont en effet dépendre du protocole utilisé et chacun (HTML, WebSockets du RFC 6455, etc) va donc devoir décliner ce principe selon ses caractéristiques propres. Par exemple, pour le futur HTML5, voici la définition.
Donc, on attaque avec la section 3, qui expose ce qu'est ce
« principe de même origine » (Same Origin
Policy). D'abord, la
confiance (section 3.1) est exprimée sous forme
d'un URI. Lorsque le serveur
www.niceguy.example sert une page
HTML
https://www.niceguy.example/foo/bar.html qui contient :
<script src="https://example.com/library.js"/>
Il annonce sa confiance envers l'URI
https://example.com/library.js. Le code
JavaScript téléchargé via cet URI sera exécuté avec les privilèges de
https://www.niceguy.example/foo/bar.html, qui a choisi de lui faire confiance.
Cette idée de « confiance par URI » peut poser des problèmes dans
certains cas. Par exemple, si on utilise le
STARTTLS du RFC 2817, le
fait d'utiliser TLS ou pas n'apparait pas dans
l'URI et la page HTML ne peut donc pas exiger TLS. Les URI de plan
https: n'ont pas ce défaut, l'exigence de TLS y
est explicite.
Mais il y a une question plus sérieuse : dans
https://www.niceguy.example/foo/bar.html, quelle
est l'origine, celle dont vont dépendre les
autorisations ultérieures (section 3.2) ? Est-ce tout l'URI ? Ou bien
seulement le FQDN
www.niceguy.example ? Réponse : aucune des
deux.
Utiliser tout l'URL comme origine manquerait de souplesse. Un code
venu de http://www.niceguy.example/foo ne
pourrait pas interagir avec du contenu récupéré en
http://www.niceguy.example/bar. Mais n'utiliser
que le nom de domaine n'est pas génial non plus. Car cela permettrait
à du code JavaScript récupéré par
http://www.niceguy.example:8080/ de modifier un
arbre DOM de
https://www.niceguy.example/ (notez que la
seconde est sécurisée avec HTTPS ; ne se servir
que du nom de domaine comme origine permettrait à du contenu non sûr
de manipuler du contenu sûr).
Et faut-il utiliser tout le FQDN ? Cela
empêche http://portal.niceguy.example/ de jouer
avec http://manager.niceguy.example/ alors que
les deux sites sont sous la même autorité, celle de
niceguy.example. Mais le problème est que la
détermination de cette autorité est difficile. Contrairement à ce que
croient les débutants, elle n'est pas forcément dans les deux derniers
composants du nom de domaine. Par exemple,
jones.co.uk et smith.co.uk
ne sont pas sous la même autorité. Et, même lorsque c'est le cas, une
Université ne souhaite pas forcément que
http://students.example.edu/ (consacré aux pages
personnelles des étudiants) aient des droits sur
http://admin.example.edu/. Bien sûr, aucun
système n'est parfait. Avec le FQDN,
http://example.edu/students/~mark aura des droits
sur http://example.edu/grades/admin. Mais ce
modèle fondé sur le FQDN est maintenant trop ancien pour le changer
(rappelez-vous qu'il a évolué informellement, notre RFC 6454 ne fait que le documenter a posteriori).
Donc, pour résumer le point important de la section 3.2 : une
origine est un tuple {FQDN, plan, port}. Par exemple,
http://example.com/,
http://example.com:80 et
http://example.com/toto.html ont tous les trois la même origine,
le tuple {example.com, http,
80}. En revanche, http://example.com:81/ a une
autre origine (port différent), de même que
ftp://example.com (plan différent), ou
http://www.example.com/ (nom différent).
Ce principe de même origine ne répond pas à tous les risques de
sécurité. Il faut également intégrer la notion d'autorité (tel que ce
terme est utilisé en sécurité, notez que le RFC 3986 utilise ce mot dans un autre sens). L'autorité est
que le navigateur donne des droits différents selon le type de document. Une
image n'a aucun droit, c'est du contenu passif (du moins pour les formats traditionnels : avec des formats comme SVG, l'analyse de sécurité est bien plus complexe). En revanche, un
document HTML a le droit de déclencher le
chargement d'autres ressources (styles CSS mais
surtout code actif, par exemple JavaScript). Normalement, l'autorité
dépend du type MIME indiqué
(image/png pour une image,
text/html pour l'HTML). Si ce type est déterminé
par un utilisateur, de nouvelles vulnérabilités peuvent
survenir (et certains navigateurs sont assez imprudents pour deviner
le type MIME en examinant le contenu, une mauvaise pratique, connue
sous le nom de content sniffing). Pire, si l'utilisateur peut insérer du contenu qu'il choisit
dans des documents ayant une forte autorité (pages HTML), de nouveaux
risques peuvent survenir. Par exemple, une attaque
XSS débute par l'insertion de contenu dans une
page HTML, contenu qui sera ensuite interprété par le navigateur, et
exécuté avec l'origine de la page Web (cf. section 8.3). Or, ce cas est très fréquent
(pensez à un moteur de recherche qui affiche la requête originale sans
précaution, alorss qu'elle était choisie par un utilisateur
extérieur). La protection contre les XSS est complexe mais le conseil
de base est : modifiez tout contenu venu de l'extérieur avant de
l'inclure dans un document ayant de l'autorité (comme une page HTML),
de façon à ce qu'il ne puisse pas être interprété par le
navigateur. Le plus simple pour cela est d'utiliser exclusivement un
système de gabarit pour fabriquer les pages. Il
se chargera alors des précautions comme de transformer
les < en <.
Une fois déterminée l'origine, il reste à décider des privilèges donnés aux objets de la même origine (section 3.4). Pour les objets récupérés, on l'a vu, la politique est typiquement de ne donner accès qu'aux objets de même origine que le code. Mais pour les accès à d'autres objets, tout est bien plus complexe et la sécurité rentre ici en conflit avec l'utilisabilité. Par exemple, une application stricte du principe de même origine aux accès aux ressources interdirait à une page Web de mener à une autre page, d'origine différente, alors que c'est évidemment une fonction essentielle du Web. Moins caricatural, le cas d'images ou autres contenus embarqués dans une page Web. Bien que cela pose des problèmes de sécurité (pensez aux Web bugs), aucun navigateur n'impose que les images aient la même origine que la page qui les charge... De même, aucun navigateur n'interdit complètement d'envoyer des données à une autre origine, même si c'est la base de nombreuses CSRF.
Voilà, l'essentiel des principes du RFC tient dans cette section
3. Le reste, ce sont les détails pratiques. La section 4 formalise la
notion d'origine en en donnant une définition rigoureuse. Elle couvre
des cas rigolos comme les URI de plan file:
(autrefois, les navigateurs considéraient tous les fichiers locaux
comme ayant la même origine, aujourd'hui, les plus paranoïaques font
de chaque fichier une origine différente), ou bien explicite le cas
des ports par défaut de certains plans (vous avez remarqué
l'équivalence entre les URI http://example.com/,
http://example.com:80, plus haut ?). La section 5
décrit d'autres pièges comme le cas des plans où n'apparaissent pas de
noms de machine comme par exemple les data: du RFC 2397 (un cas amusant car
deux URI data: complètement identiques, bit par
bit, sont quand même d'origine différente). Et la section 6 explique
la sérialisation d'un URI, à des fins de comparaison simples avec
d'autres URI, pour déterminer s'ils ont la même origine. Par exemple,
http://www.example.com:80/ et
http://www.example.com/toto se sérialisent tous
les deux en http://www.example.com. Pour les URI
de type {scheme, host,
port} (les plus fréquents), une simple
comparaison de chaînes de caractères nous dira ensuite s'ils ont la
même origine (ici, oui).
Si on revient au premier exemple JavaScript que j'ai donné, celui
où https://www.niceguy.example/foo/bar.html
charge https://example.com/library.js, on voit
que l'origine n'est pas l'URI du script mais celle de la page qui le
charge. Or, on peut imaginer que le serveur
example.com voudrait bien connaître cette
origine, par exemple pour appliquer des règles différentes. ou tout
simplement pour informer le script du contexte dans lequel il va s'exécuter. C'est le rôle de l'en-tête
HTTP Origin:, normalisé
dans la section 7, et qui peut être ajouté aux requêtes. Ainsi, dans
l'exemple ci-dessus, la requête HTTP ressemblerait à :
[Connexion à exemple.com...] GET /library.js HTTP/1.1 Host: example.com Origin: https://www.niceguy.example ...
On voit que l'origine indiquée est la forme sérialisée comme indiqué
plus haut. Ce n'est donc pas l'équivalent de
Referer: qui indique un URI complet.
Cet en-tête est désormais dans le registre des en-têtes (cf. section 9).
Comme tout ce RFC décrit un mécanisme de sécurité, il est prudent de bien lire la section 8, Security Considerations, qui prend de la hauteur et rappelle les limites de ce mécanisme. Historiquement, d'autres modèles que le « principe de même origine » ont été utilisés (à noter que le RFC ne fournit pas de référence), comme le taint tracking ou l'exfiltration prevention mais pas avec le même succès.
D'abord, la notion d'origine est une notion unique qui s'applique à des problèmes très différents et peut donc ne pas être optimisée pour tous les cas.
Ensuite, elle dépend du DNS (section 8.1)
puisque la plupart des plans d'URI utilisent la notion
d'host et que la politique de même origine considère que deux serveurs sont les mêmes s'ils ont le
même nom. Si l'attaquant contrôle le DNS, plus aucune sécurité n'est
possible (on croit parler au vrai www.example.com et on
parle en fait à une autre machine).
À noter que le RFC prend bien soin de ne pas parler de la principale vulnérabilité de ce concept d'host : l'absence de notion générale d'identité d'une machine dans l'Internet (cette notion n'existe que pour certains protocoles spécifiques comme SSH). En l'absence d'une telle notion, des attaques sont possibles sans que l'attaquant ait eu à compromettre le DNS, comme par exemple le changement d'adresse IP.
Autre piège, le fait que le principe de même origine, ne soit pas
apparu tout de suite et que certaines techniques de sécurité du Web
utilisent une autre unité d'isolation que l'origine (section
8.2). Le Web n'a pas en effet de sécurité cohérente. C'est le cas des
cookies (RFC 6265), qui se servent d'un autre concept, le « domaine
enregistré ». Le navigateur essaie de trouver, lorsqu'il récupère un
cookie, à quel « domaine enregistré » il appartient
(l'idée étant que sales.example.com et
it.example.com appartiennent au même domaine
enregistré, alors qu'ils n'ont pas la même origine). Il enverra
ensuite le cookie lors des connexions au même
domaine enregistré. Pour déterminer ce domaine, notez que les
cookies ne font pas de différence entre HTTP et
HTTPS (sauf utilisation de l'attribut Secure) et
qu'un cookie acquis de manière sûre peut donc être
envoyé par un canal non sûr.
Notre RFC note que cette pratique d'utiliser le « domaine enregistré » est mauvaise et la déconseille. En effet :
- Rien n'indique dans le nom lui-même où est le domaine
enregistré. Sans connaître les règles d'enregistrement de
JPRS, vous ne pouvez pas dire que
a.co.jpetb.co.jpsont deux domaines enregistrés différents. Il existe des listes publiques de politiques d'enregistrement commehttp://publicsuffix.org/mais aucune n'est officielle et aucune n'est à jour. - Cette pratique dépend fortement du plan d'URI utilisé, certains n'ayant pas de domaine (donc pas de domaine enregistré).
Autre faiblesse du principe de même origine, l'autorité diffuse (section 8.3). L'autorité va dépendre de l'URI, pas du contenu. Or, un URI de confiance peut inclure du contenu qui ne l'est pas (pour le cas, fréquent, où une page Web inclut du contenu généré par l'utiisateur) et c'est alors un risque de XSS.
Résultat, le principe de même origine ne suffit pas à lui seul à protéger l'utilisateur (plusieurs attaques ont déjà été documentées.) Il faut donc ajouter d'autres pratiques de sécurité.
Notez que la question des mises en œuvre de ce RFC ne se pose pas, il a été réalisé après le déploiement du concept de même origine et tous les navigateurs Web utilisent aujourd'hui ce système. Toutefois, certains ne le font peut-être pas encore absolument comme décrit ici, par exemple en accordant au plan ou au port moins de poids qu'au host (il semble que cela ait été le cas de certaines versions d'Internet Explorer).
Une autre bonne lecture sur ce concept d'origine est l'article de Google pour les développeurs.
L'article seul
Mais quelle galère que la distribution de programmes Python packagés !
Première rédaction de cet article le 10 décembre 2011
Je sais, je ferais mieux d'être constructif, au lieu de râler, et de dire du mal des autres programmeurs. Mais c'est trop énervant, il faut que je me défoule : lorsqu'on écrit un programme en Python, et qu'il dépend de plusieurs paquetages (dont certains peuvent être installés et d'autres pas), c'est très galère. Il n'existe aucun mécanisme standard pour indiquer dans la distribution quels paquetages sont nécessaires.
Démonstration avec la bibliothèque seenthis-python, qui permet d'accéder au service de court-bloguage et de partage de liens SeenThis. seenthis-python dépend de deux paquetages, SimpleTAL, un système de gabarits, pour générer du XML propre, et FeedParser, pour analyser les messages en Atom que renvoie SeenThis. Dans la distribution de seenthis-python, comment indiquer (à part par du texte libre dans le README) qu'on dépend de ces paquetages ?
Commençons par le grand classique, car c'est le seul distribué avec
Python, dans la bibliothèque standard, et sur lequel tout le monde
peut compter : distutils. Le principe
est qu'on écrit un fichier setup.py qui va
indiquer un certain nombre de choses sur le programme :
from distutils.core import setup
setup(name='SeenThis',
version='0.0',
description='Use the SeenThis API',
license='BSD',
author='Stephane Bortzmeyer',
author_email='stephane+seenthis@bortzmeyer.org',
url='https://github.com/bortzmeyer/seenthis-python',
)
Ce fichier peut ensuite être exécuté avec des options qui vont dire
par exemple d'installer le paquetage (python setup.py
install) ou de l'enregistrer dans le Python Package Index (PyPI) (python setup.py register).
distutils a des tas de limites. Par exemple, il ne permet pas de
faire des eggs, des paquetages binaires pour
Python. Mais, surtout, il ne permet pas d'exprimer des dépendances :
aucun moyen dans le script ci-dessus de dire qu'on a besoin de
SimpleTAL et de FeedParser. Le script setup.py
s'exécutera et installera la bibliothèque, même si les pré-requis
manquent. En lisant la
documentation, on a l'impression qu'on peut ajouter :
requires=['SimpleTAL', 'FeedParser']
mais c'est purement décoratif. La documentation ne le dit pas mais cette variable est complètement ignorée par distutils.
Au passage, le langage d'expression des dépendances (qui ne sert à
rien, on l'a vu) permet également d'indiquer un numéro de version, par
exemple le fait que, pour FeedParser, en raison de la
bogue #91 (« sgmllib.SGMLParseError: unexpected
'\xe2' char in declaration »), il faut au moins la version 5.
Lorsque le débutant en Python se plaint de cet état de chose, les vieux experts blanchis sous le harnais lui rétorquent que tout le monde le sait, et que personne n'utilise le système standard (alors, pense le débutant naïf, pourquoi est-ce que ce truc reste dans la bibliothèque standard ?). Et c'est là que les choses se compliquent, car il existe plusieurs remplaçants possibles.
D'abord, le premier, setuptools (le
lien pointe vers PyPi puisque, à partir de là, on n'est plus dans la
bibliothèque standard, ce qui oblige l'utilisateur qui va installer
la bibliothèque à installer un autre programme d'abord, alors que le
but était de lui simplifier la vie). Il existe une bonne documentation pour débutant. En gros, on remplace la
première ligne de code du setup.py par :
from setuptools import setup
et on a alors des fonctions et variables supplémentaires comme
install_requires qui permet d'indiquer des
dépendances. Tout content, le programmeur Python naïf édite le README
pour indiquer à ses futurs utilisateurs qu'il va falloir installer
setuptools d'abord avant de faire le python setup.py
build. Mais il va vite être déçu : même si SimpleTAL est
installé, le setup.py va tenter de le télécharger
(et échouer, car il n'est pas dans PyPi). En effet, setuptools ne
teste pas si un module Python donné est disponible (import
simpletal), il regarde s'il y a un egg du même
nom. Ce qui n'est pas le cas. Les dépendances de setuptools sont donc
vers les eggs, pas vers les modules, ce qui ôte une
bonne partie de leur intérêt.
D'autant plus que, on l'a vu, des paquetages fréquemment répandus, comme SimpleTAL, ne sont pas forcément disponibles dans PyPi... (SimpleTAL est arrivé plus tard.)
Bon, troisième tentative : distribute, qui prétend remédier aux problèmes de setuptools. Il reprend en partie son nom (ce qui contribue beaucoup à la confusion des programmeurs, par exemple le paquetage Debian de distribute se nomme setuptools) :
from distribute_setup import use_setuptools use_setuptools() from setuptools import setup [puis setup.py comme avant]
Comme setuptools, il permet de déclarer des dépendances, mais il les gère tout aussi mal :
# python setup.py install
...
Searching for simpletal
Reading http://pypi.python.org/simple/simpletal/
Reading http://www.owlfish.com/software/simpleTAL/index.html
No local packages or download links found for simpletal
error: Could not find suitable distribution for Requirement.parse('simpletal')
% python
Python 2.6.6 (r266:84292, Dec 27 2010, 00:02:40)
[GCC 4.4.5] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import simpletal
>>>
(La dernière commande montre que SimpleTAL est pourtant bien installé.)
Bref, on a trois systèmes concurrents et dont aucun ne permet d'assurer une tâche aussi simple que « vérifie que simpletal est bien disponible ». Pire, rien dans la documentation n'indique leurs limites. Ainsi tous les programmeurs Python semblent savoir que distutils est très limité mais cela n'apparaît pas dans la documentation de la bibliothèque standard. Et ce n'est pas fini. Comme l'écrit Victor Stinner «Le packaging Python est une série à la Dallas avec ses drames et ses rebondissements. Le dernier événement marquant est que la réécriture de distutils, "distutils2", a été intégrée dans Python 3.3 sous le nom "packaging". Sa version pour Python 2.5 - 3.2 sera maintenue en dehors de Python sous le nom "distutils2". » Il y a aussi des compétiteurs comme Bento ou plus exotiques comme zc.buildout.
Le problème du packaging Python est discuté avec bien plus de détails techniques (et moins de râleries pas constructives) dans l'excellent article Python packaging de Tarek Ziadé dans le livre Architecture of Open Source Software, (co-dirigé par Greg Wilson et Amy Brown).
Un petit truc : si on veut regarder la variété des fichiers
setup.py possibles, on peut demander
à Google (ici, en se limitant à ceux qui contiennent requires).
Pour terminer, une bonne série de lectures, due à Nicolas Chauvat :
- The Configuration Management Problem,
- Looking for a Windows Package Manager,
- Virtualenv - Play safely with a Python,
- A comprehensive guide through Python packaging (a.k.a. setup scripts), un bon document d'introduction pour ceux qui veulent souffrir le moins possible,
- PyPi is not a software distribution,
- Sprint Distutils2 et la suite,
- Un PEP qui spécifie un format de fichier qui décrit les dépendances d'un module python PEP345, et qui, si un outil s'en servait, simplifierait formidablement la vie de ceux qui font des paquets pour les distributions.
L'article seul
Ma tablette Packard Bell Liberty Pad
Première rédaction de cet article le 9 décembre 2011
Dernière mise à jour le 12 décembre 2011
Je viens d'acheter une tablette Packard Bell « Liberty Pad ». Je n'ai pas encore eu beaucoup d'occasions de m'en servir mais je documente quelques points ici, pour ceux qui envisagent d'acheter un modèle équivalent.
Le modèle que j'ai entre les mains est la Liberty Pad G100W, avec 1 Go de RAM et 12 Go de stockage. Elle a un grand écran, mais, avec plus de 700 grammes, elle est un peu lourde, on ne peut pas lire au lit en la tenant au dessus de soi.
Je m'en suis peu servi pour l'instant. Ce n'est pas qu'elle a des défauts insupportables, c'est plutôt qu'elle n'a pas encore trouvé sa place parmi mes gadgets électroniques, entre le smartphone et l'ordinateur portable.
Elle vient avec Android 3.2. Je n'ai pas mené de tests systématiques de toutes les variantes d'Android, d'autant plus que, comme c'est du logiciel libre, chaque constructeur peut en livrer une version différente avec son matériel. Mes observations sont donc pour l'Android 3.2 livré avec la Liberty Pad, j'accepte bien volontiers les remarques comme quoi c'est différent avec d'autres variantes de ce système.
Je dois dire que, compte-tenu de mon expérience avec les versions 2 d'Android, j'ai été plutôt déçu. Pas d'avantages évidents et des inconvénients :
- Lorsqu'on écrit en français, le mode de saisie des caractères composés sous Android est assez propice à l'erreur (choix du mauvais caractère composé). Avec Android 2, le correcteur orthographique corrigeait cela mais il semble avoir disparu en Android 3. Désormais, plus de droit à l'erreur et, à l'usage, ça s'est traduit par quelques tweets erronés.
- La tablette a une webcam mais je n'ai trouvé aucun logiciel livré avec qui puisse l'utiliser (même pas le client Google Talk). Rien trouvé non plus sur le Market.
- L'installation d'applications depuis le Market marche mais je n'arrive pas à installer un APK qui fonctionnait bien en Android 2. Je le télécharge et j'ai juste un « Impossible d'ouvrir le fichier », sans détail.
- Le navigateur Web livré par défaut ne réajuste pas le texte à la taille de l'écran lorsqu'on agrandit la taille du texte en pinçant celui-ci avec les doigts. On perd donc tout ce qui est trop à droite. Android 2 avait le même problème mais disposait de deux boutons virtuels marqués + et - qui permettaient de changer la taille en ajustant le texte à la largeur de l'écran. Ces deux boutons ont disparu et je ne trouve pas ce qui les remplace. Activer ou désactiver l'option « Ajustement auto des pages » ne change rien. (On peut installer Firefox mais il a exactement le même défaut.)
- Et le plus grave, la connexion à un ordinateur par USB ne marche pas. L'ordinateur détecte un périphérique USB mais ne le voit pas comme un disque. Là encore, c'est un recul par rapport à mon smartphone sous Android 2.
Pour ceux qui aiment déboguer, voici ce que voit un PC Ubuntu quand la tablette est branchée :
[170151.693114] usb 3-2: USB disconnect, device number 9 [170157.054847] usb 3-2: new high speed USB device number 10 using xhci_hcd [170157.079225] xhci_hcd 0000:0b:00.0: WARN: short transfer on control ep [170157.081218] xhci_hcd 0000:0b:00.0: WARN: short transfer on control ep ...
(xhci indiquant de l'USB 3, ehci était l'USB 2.)
L'absence de liaison filaire par USB est évidemment très gênante. J'ai voulu activer Bluetooth et la tablette a alors redémarré... J'ai cherché alors à copier les fichiers vers la tablette en utilisant une synchronisation par un service extérieur, comme le S3 d'Amazon. Pour l'instant, c'est sans succès (pas trouvé de client S3 qui marche sur Android), j'écrirai un article un jour sur ce problème.
Même lorsqu'elles fonctionnent, toutes les applications Android ne se comportent pas comme il faut. Par exemple, le client Twitter Mustard n'arrive pas à utiliser correctement tout l'écran, bien plus large que celui des smartphones auquel il est habitué. Lorsqu'on le met en plein écran, les caractères sont pixelisés...
Certains de ces problèmes ont des solutions. Par exemple, pour le clavier, Florian Maury me suggère l'excellent Hacker's keyboard qui dote la tablette d'un clavier bien plus proche de celui d'un PC et qui facilite la saisie de plusieurs caractères (mais pas le #, qui n'est pas indiqué lorsque je tape en français, il faut un appui prolongé sur la touche 3 pour le voir). Sur un smartphone, une telle application serait pénible (ce clavier prend bien plus de place sur l'écran) mais sur une tablette, ça a un sens.
Pour le navigateur qui ne s'ajuste pas à la taille du texte, la solution la plus simple est de double-tapoter l'écran, le navigateur fait alors ce qu'il faut. (Merci à Gilles Maurer.)
Pour le problème USB, comme me l'a fort bien expliqué Erwann
Abalea, c'est parce qu'Android a changé entre les versions 2 et
3. Avant, la machine Android se présentait comme
Mass Storage Device, reconnue par tous
les systèmes. Depuis Android 3, elle se présente comme
MTP. Il faut donc installer la cuisine MTP (protocole fermé...) sur
Unix. Sur Ubuntu, le programme mtp-detect du paquetage
mtp-tools sur Ubuntu détecte bien la tablette :
Device 0 (VID=18d1 and PID=335e) is UNKNOWN. ... Device info: Manufacturer: Packard Bell Model: Liberty Tab G100
Et on peut la monter avec mtpfs (paquetage du
même nom). On crée /media/tablette puis, à chaque
branchement :
# mtpfs -o allow_other /media/tablette % df -h Filesystem Size Used Avail Use% Mounted on ... mtpfs 13G 346M 13G 3% /media/tablette % ls -l /media/tablette total 0 drwxrwxrwx 2 stephane stephane 0 Jan 1 1970 Alarms drwxrwxrwx 2 stephane stephane 0 Jan 1 1970 AndroAWS drwxrwxrwx 2 stephane stephane 0 Jan 1 1970 Android drwxrwxrwx 2 stephane stephane 0 Jan 1 1970 DCIM drwxrwxrwx 2 stephane stephane 0 Jan 1 1970 Download drwxrwxrwx 2 stephane stephane 0 Jan 1 1970 Foldersync drwxrwxrwx 2 stephane stephane 0 Jan 1 1970 LumiBooks drwxrwxrwx 2 stephane stephane 0 Jan 1 1970 Movies drwxrwxrwx 2 stephane stephane 0 Jan 1 1970 Music drwxrwxrwx 2 stephane stephane 0 Jan 1 1970 Notifications drwxrwxrwx 2 stephane stephane 0 Jan 1 1970 Pictures drwxrwxrwx 2 stephane stephane 0 Jan 1 1970 Playlists drwxrwxrwx 2 stephane stephane 0 Jan 1 1970 Podcasts drwxrwxrwx 2 stephane stephane 0 Jan 1 1970 Ringtones drwxrwxrwx 2 stephane stephane 0 Jan 1 1970 documents drwxrwxrwx 2 stephane stephane 0 Jan 1 1970 lost+found
(Si on veut le faire depuis un compte ordinaire, il faut qu'il soit
propriétaire du point de montage, ici
/media/tablette et que l'option
user_allow_other soit présente dans
/etc/fuse.conf.) Là, on peut copier ses fichiers. Puis on démonte le volume :
# umount mtpfs
Je n'ai pas encore réussi à écrire la règle udev qui fera tout cela automatiquement. Mais au moins je peux copier des fichiers.
Bref, pour l'instant, je m'en sers surtout pour regarder YouTube (image et son sont parfaits). Lorsque j'aurai résolu les problèmes de synchronisation avec le monde extérieur, je m'en servirai pour de la lecture de documents, surtout si je trouve un logiciel qui me permet d'annoter les documents lus (un gros avantage du papier). Pour l'instant, je synchronise (sommairement) avec BotSync et un serveur SSH à moi quelque part dans le nuage.
L'article seul
Une sonde de mesure Internet Atlas à l'Université de Yaoundé au Cameroun
Première rédaction de cet article le 7 décembre 2011
Je viens d'enregistrer la sonde Atlas n° 2012. Elle est située à Yaoundé, au Cameroun. C'est quoi, une sonde Atlas ?
L'Internet est aujourd'hui un énorme réseau,
qui s'étend sur toute la planète et sert à des milliards de gens, pour
tous les aspects de leur vie. Curieusement, on connait peu ce réseau
pourtant si indispensable. Il y a par exemple peu de mesures
quantitatives qui sont effectuées (chaque opérateur fait évidemment
des mesures intensives de son propre réseau ; mais il y a peu de
mesures trans-Internet). L'un des projets existants pour
améliorer la connaissance que nous avons de l'Internet est Atlas. Ce projet, initié et piloté
par le RIPE-NCC, héritier du vieux projet TTM, consiste à faire fabriquer des milliers de
petites sondes matérielles, minuscules boîtiers contenant le logiciel
de mesure, et munis d'une prise
USB (pour le courant) et
Ethernet (pour le réseau).
 (Ces boîtiers sont dérivés du Lantronix Xport pro.) Les sondes sont
branchées, acquièrent une adresse par DHCP puis
« appellent la maison » en l'occurrence le RIPE-NCC. Leur contrôleur
peut alors leur faire effectuer un certain nombre de tests et
rassembler les résultats sur Atlas. On peut alors voir
l'Internet depuis un grand nombre de points.
(Ces boîtiers sont dérivés du Lantronix Xport pro.) Les sondes sont
branchées, acquièrent une adresse par DHCP puis
« appellent la maison » en l'occurrence le RIPE-NCC. Leur contrôleur
peut alors leur faire effectuer un certain nombre de tests et
rassembler les résultats sur Atlas. On peut alors voir
l'Internet depuis un grand nombre de points.
La principale chose que je regrette, dans ce génial projet, est que le code source des sondes Atlas ne soit pas disponible. Le RIPE-NCC semble très fermé à cette idée. (S'il est impératif pour vous d'avoir le source, la seule solution semble être Bismark.)
Cette sonde particulière, la 2012, est la huitième opérationnelle en Afrique (Afrique du Sud exclue). Ce faible nombre donne d'ailleurs une idée de l'ampleur de la fracture numérique. On ne sait pas trop à quoi ressemble l'Internet vu de l'Afrique, à part que ça rame. La sonde m'a été donnée par le RIPE-NCC lors de la réunion RIPE de Vienne le 2 novembre 2011. Rapportée à Paris, confiée le 14 novembre à Michel Tchonang Minze qui rentrait au Cameroun pour la réunion d'AfriNIC (le courrier postal n'est pas toujours fiable, et certainement pas rapide), remise à Janvier N'gnoulaye le 23, qui s'est ensuite occupé de lui trouver une place. La sonde a été branchée et fonctionne depuis le 1er décembre.
Une fois la sonde enregistrée sur le site Web du RIPE-NCC, on peut voir des informations pratiques :
Probe ID: 2012 Firmware Version: 4270 IPv4 IPv6 Internet Address: 41.204.93.114 Undetermined/Unknown Local Address: 192.168.1.15 Undetermined/Unknown Gateway: 192.168.1.1 Undetermined/Unknown DNS Resolver: 192.168.1.1 Undetermined/Unknown AS Number: AS15964 Undetermined/Unknown Your probe is configured dynamically Your probe's public DNS entry is : p2012.probes.atlas.ripe.net Current status: Up since 2011-12-05 16:56:25 UTC Last Week Uptime: 94.75% Last Month Uptime: 94.75% Total Uptime: 94.75% (5d, 19h, 22m)
Notez les uptimes : une des plaies d'Atlas est le nombre de sondes distribuées mais jamais branchées, ou bien distribuées mais qui tombent en panne ou sont débranchées peu après. (D'ailleurs, la sonde de Yaoundé a planté peu après la parution de cet article, puis a été relancée.) Comme on le voit, le site ne dispose pas encore d'IPv6. Pour l'instant, la sonde est connectée via le réseau local de l'Université, qui va ensuite chez Camtel (l'AS 15964). Dans le futur, elle sera connectée par le NREN camerounais, en cours de construction.
Quel genre de mesures fait la sonde ? Elle
pingue par exemple un certain nombre
d'amers. Depuis l'Afrique, les
délais sont énormes (encore la fracture numérique). Par exemple, en
visant k.root-servers.net, le serveur
racine DNS du RIPE-NCC, on trouve en trois tests dans la
journée 1248 ms /
1342 ms / 1495 ms. Les variations dépendent fortement de l'heure, ce
qui indique que ce n'est pas la latence du câble qui est le problème
mais la surcharge des tuyaux. Voici le graphique (le 4 décembre était
un dimanche) : 
Pour une
vue sur une journée, voir par exemple le temps de réponse d'une autre
serveur racine, L, géré par l'ICANN :
Et les sondes Atlas font
bien d'autres mesures, qui nourissent les excellents articles des
RIPE Labs. Par exemple, en ce
moment (décembre 2011), elles testent la connectivité avec le réseau
128.0.0.0/16, qui est filtré par une bogue des
routeurs Juniper. (Le problème ne se pose pas
au Cameroun où il n'y a que des Cisco.)
L'article seul
Le bonheur des globes oculaires (IPv6 et IPv4)
Première rédaction de cet article le 1 décembre 2011
Le déploiement très lent d'IPv6 dans l'Internet fait réfléchir aux causes : pourquoi est-ce que cela ne va pas plus vite ? Pour le cas des sites Web regardés par un public passif (public poétiquement baptisé « globes oculaires » - eyeballs), une des raisons est que d'être accessible en IPv6 peut rendre l'accès très lent pour les clients qui ont une connexion IPv6 incorrecte. Pourquoi ? Et quels sont les derniers développements qui permettent de traiter ce problème ?
Commençons par définir le problème : soit le célébrissime M. Toutlemonde qui veut regarder un site Web avec du graphique plein partout. M. Toutlemonde a donc des eyeballs, des globes oculaires, qui attendent avec impatience de se délecter d'images qui bougent. Mettons que le site Web visé a une connexion IPv4, une en IPv6 et qu'il publie dans le DNS les deux adresses (A et AAAA). Mettons encore que M. Toutlemonde a une connexion IPv6 mais qu'elle est très mauvaise, voire complètement cassée (c'est fréquent avec des techniques comme Teredo, 6to4, ou des tunnels d'amateurs, et c'est pour cela qu'il faut fuir toutes ces techniques).
Le navigateur Web de M. Toutlemonde va tenter une connexion en IPv6 (c'est ce que demande le RFC 6724), la connexion IPv6 étant inutilisable, ce logiciel va attendre... attendre... attendre une réponse qui ne viendra jamais. Il passera finalement à l'adresse suivante, en IPv4, mais trop tard. M. Toutlemonde, furieux, aura déjà éteint son ordinateur et ouvert un livre en papier de Frédéric Mitterrand à la place. Comment lui éviter ce sort tragique ?
L'algorithme utilisé par les programmeurs « naïfs » n'est pas optimum. Cet algorithme, c'est, en gros, la méthode séquentielle suivante :
adresses = getaddrinfo(nom_du_serveur)
pour chaque adresse dans adresses
connexion(adresse)
si connexion réussie, sortir de la boucle
L'étape connexion(adresse) est bloquante et prend un temps fou si
l'adresse en question est injoignable. C'est à cause de cela que
l'écrasante majorité des gros sites Web ne publient pas d'adresse IPv6
dans le DNS, de peur de mécontenter les globes oculaires de leurs utilisateurs.
La première idée d'optimisation a donc été de faire les tentatives de connexion en parallèle et non plus séquentiellement. Mais cette technique a des inconvénients aussi : elle consomme N fois plus de paquets (pour N adresses disponibles) et elle ouvre plusieurs connexions avec le serveur si celui-ci a plusieurs adresses qui répondent, connexions qu'il faudra fermer ensuite.
D'où la méthode qui est à la mode (illustrée par un célèbre programme de l'ISC ou bien par ce code en Go) : tenter la connexion en IPv6 mais avec un délai de garde très court, et passer aux adresses v4 plus vite, sans attendre le délai de garde normal d'une tentative de connexion TCP. 300 à 500 mili-secondes suffisent : il est rare qu'une connexion réussisse en un temps plus long. Ce système permet-il d'avoir toujours des « happy eyeballs », des globes oculaires heureux ?
Si vous avez logiciel et connexion IPv6, vous pouvez tester vous-même avec votre navigateur favori, en
regardant des sites Web dont la connectivité IPv6 est délibérement en
panne, comme http://intentionally.broken.dualstack.wdm.sg.ripe.net/
(admirez son adresse IPv6...) ou http://broken.redpill-linpro.com/. Si vous y
arrivez très vite, vous être un globe oculaire heureux, derrière un
navigateur Web qui met en œuvre correctement les dernières
techniques. Si vous utilisez un logiciel qui utilise l'ancien
algorithme (ici, wget), vous allez souffrir :
% time wget http://intentionally.broken.dualstack.wdm.sg.ripe.net/ --2011-12-01 22:30:39-- http://intentionally.broken.dualstack.wdm.sg.ripe.net/ Resolving intentionally.broken.dualstack.wdm.sg.ripe.net... 2001:67c:2e8:dead:dead:dead:dead:dead, 193.0.0.169 Connecting to intentionally.broken.dualstack.wdm.sg.ripe.net|2001:67c:2e8:dead:dead:dead:dead:dead|:80... [Vingt secondes s'écoulent ici...] failed: Connection timed out. Connecting to intentionally.broken.dualstack.wdm.sg.ripe.net|193.0.0.169|:80... connected. HTTP request sent, awaiting response... 200 OK
Mais un excellent article d'Emile Aben, « Hampering Eyeballs - Observations on Two "Happy Eyeballs" Implementations », montre que le problème est plus compliqué que cela. Il a testé deux implémentations de l'idée ci-dessus, une sur Google Chrome (ticket #81686) et l'autre sur deux navigateurs tournant sur Mac OS X (l'algorithme de Mac OS X a été décrit par Apple). L'analyse montre que Chrome est parfait et réussit à rendre les globes oculaires heureux dans tous les cas. Mais Mac OS X ne s'y est pas aussi bien pris. Avec le navigateur Firefox, les globes oculaires peuvent être dans certains cas (machine qui a démarré récemment et n'a pas encore accumulé de statistiques de performance) aussi malheureux qu'avant. Avec Safari, le pire est évité mais il n'utilise parfois pas des connexions IPv6 pourtant parfaitement opérationnelles.
Si vous voulez tester vous-même le niveau de bon ou mauvais fonctionnement de serveurs IPv6, je recommande un programme attaché au système de gestion de bogues de Mozilla :
% ./test-happiness-eyeballs broken.redpill-linpro.com www.bortzmeyer.org \
intentionally.broken.dualstack.wdm.sg.ripe.net www.ietf.org
[ 0us] begin gai_and_connect(broken.redpill-linpro.com)
[+ 1626us] getaddinfo(broken.redpill-linpro.com) done
[+ 34us] dest = 2a02:c0:1002:11::dead (AF_INET6)
[+ 13us] about to connect()
[+ 20997111us] connect() fails: Connection timed out
[+ 77us] dest = 87.238.47.15 (AF_INET)
[+ 14us] about to connect()
[+ 59079us] connect() suceeds
[ 0us] begin gai_and_connect(www.bortzmeyer.org)
[+ 621us] getaddinfo(www.bortzmeyer.org) done
[+ 18us] dest = 2001:4b98:dc0:41:216:3eff:fece:1902 (AF_INET6)
[+ 11us] about to connect()
[+ 156535us] connect() suceeds
[+ 52us] dest = 2605:4500:2:245b::bad:dcaf (AF_INET6)
[+ 13us] about to connect()
[+ 117633us] connect() suceeds
[+ 65us] dest = 204.62.14.153 (AF_INET)
[+ 14us] about to connect()
[+ 111054us] connect() suceeds
[ 0us] begin gai_and_connect(intentionally.broken.dualstack.wdm.sg.ripe.net)
[+ 558us] getaddinfo(intentionally.broken.dualstack.wdm.sg.ripe.net) done
[+ 19us] dest = 2001:67c:2e8:dead:dead:dead:dead:dead (AF_INET6)
[+ 10us] about to connect()
[+ 20998608us] connect() fails: Connection timed out
[+ 58us] dest = 193.0.0.169 (AF_INET)
[+ 11us] about to connect()
[+ 38271us] connect() suceeds
[ 0us] begin gai_and_connect(www.ietf.org)
[+ 635us] getaddinfo(www.ietf.org) done
[+ 18us] dest = 2001:1890:123a::1:1e (AF_INET6)
[+ 10us] about to connect()
[+ 190011us] connect() suceeds
[+ 61us] dest = 12.22.58.30 (AF_INET)
[+ 14us] about to connect()
[+ 199703us] connect() suceeds
Vous voyez que les connexions qui réussissent le font en moins de 200 ms, alors que celles qui échouent prennent 20 s.
Depuis la publication de cet article, Christophe Wolfhugel me fait remarquer qu'il n'y a pas que l'établissement de la connexion à prendre en compte pour le bonheur des globes oculaires. En effet, IPv6 a plus souvent des problèmes de MTU qu'IPv4 (les tunnels y sont plus fréquents, et l'ICMP plus souvent bloqué par des administrateurs réseaux maladroits, cf. RFC 2923 et RFC 4459). Dans ce cas, le globe oculaire malheureux risque de voir une connexion qui réussit en IPv6 (les paquets TCP de la poignée de main initiale sont tous de petite taille, bien inférieure à la MTU) mais où on ne pourra pas envoyer de données ensuite (car les paquets de données auront, eux, la taille maximale). Je ne connais pas de site Web délibérement cassé de ce point de vue (pour pouvoir tester) mais, en gros, si votre navigateur affiche qu'il a pu se connecter mais qu'ensuite il attend, cela peut être un problème de MTU (voir mon article à ce sujet, en attendant que tout le monde mette en œuvre le RFC 4821).
Un autre article sur le même sujet, très détaillé techniquement avec analyse du comportement des paquets, est « Dual Stack Esotropia ». La question du bonheur des globes oculaires a depuis fait l'objet du RFC 6555 qui spécifie les algorithmes utiles et du RFC 6556 qui décrit une technique de mesure du niveau de bonheur.
L'article seul
Gentoo, un système pour ceux et celles qui aiment tout ajuster
Première rédaction de cet article le 29 novembre 2011
Il existe des tas de systèmes d'exploitation libres. Certains sont très différents de la moyenne et, comme j'ai géré pendant des années un serveur sous Gentoo, voici quelques notes sur Gentoo et deux ou trois choses que j'ai apprises à son sujet.
Le système Gentoo utilise le noyau Linux, la GNU libc et les outils GNU habituels. (C'est donc ce que certains appellent, par erreur, une distribution Linux.) Mais Gentoo se distingue de systèmes comme Debian ou CentOS par le fait que tout est compilé à partir des sources et que l'administrateur système a bien plus de liberté pour ajuster le système à ses goûts. Gentoo n'est pourtant pas forcément plus difficile en utilisation quotidienne.
Un des problèmes du terme « distribution Linux » est qu'il suppose que tous les systèmes ainsi nommés ont des points en commun. Par exemple, j'ai lu lors d'une discussion un partisan de FreeBSD affirmer que « les distributions Linux sont en binaire », ce qui est certainement vrai de Debian ou CentOS, mais pas de Gentoo, qui est au contraire le royaume de la compilation.
Donc, le principe est que tout logiciel installé sur la machine a été compilé, avec des options choisies par l'administrateur. Contrairement à FreeBSD, il n'y a qu'une seule méthode (la bonne) pour maintenir l'arbre à jour (et c'est la même pour tout le système, le noyau, la libc, MySQL).
Lorsqu'on tape :
% emerge postfix
On ne se contente pas d'installer un paquetage
binaire de Postfix, on télécharge les sources
et on recompile. Les options de compilation (dites USE
flags) sont centralisés dans
/etc/portage/package.use et, par exemple, on peut trouver :
mail-mta/postfix -ldap -mailwrapper
qui indiquent de compiler Postfix sans LDAP. Autre exemple :
net-dns/opendnssec -mysql sqlite
indique qu'OpenDNSSEC doit être compilé avec
SQLite mais sans
MySQL. Les valeurs possibles sont indiquées
dans /usr/portage/profiles/use.desc pour les
variables globales, et dans
/usr/portage/profiles/use.local.desc pour celles
spécifiques à une application donnée.
Ces compilations systématiques sont évidemment mauvaises du point de vue écologique (on fait tourner la machine et consommer davantage d'électricité). Il existe un moyen de fabriquer des paquetages binaires mais c'est juste en interne, il n'y a pas d'archive publique de tels paquetages.
Gentoo permet également une grande souplesse dans le choix des
versions installées. On peut masquer ou démasquer des programmes par
leur numéro de version, sélectionnant ainsi le choix de telle ou telle
version. Par
exemple, si on n'est pas prêt pour MySQL 5.1, on interdit mysql>=5.1).
Quelques commandes Gentoo utiles (avec leur équivalent Debian entre parenthèses pour ceux qui sont plus familiarisés avec ce système) :
[Compile et installe le paquetage XXX ("aptitude install XXX")]
% emerge XXX
[Mets à jour la liste des paquetages connus ("aptitude update")]
% emerge --sync
[Ou emerge-webrsync si on est coincé derrière un pare-feu pénible.]
[Cherche le nom d'un paquetage ("apt-cache search XXX")]
% emerge --search XXX
[Supprime le paquetage XXX]
% emerge --unmerge XXX
La compilation peut rater. Par exemple, en essayant
emerge bind :
!!! The ebuild selected to satisfy "net-dns/bind" has unmet requirements.
- net-dns/bind-9.8.1_p1::gentoo USE="berkdb doc ipv6 (multilib) ssl xml -caps -dlz -geoip -gost -gssapi -idn -ldap -mysql -odbc -pkcs11 -postgres -rpz -sdb-ldap (-selinux) -threads -urandom"
The following REQUIRED_USE flag constraints are unsatisfied:
berkdb? ( dlz )
The above constraints are a subset of the following complete expression:
postgres? ( dlz ) berkdb? ( dlz ) mysql? ( dlz !threads ) odbc? ( dlz ) ldap? ( dlz ) sdb-ldap? ( dlz ) gost? ( ssl )
C'est beau comme message, non ? Pour le supprimer, il a fallu ajouter
dans package.use un net-dns/bind -mysql -ldap -berkdb -dlz.
Autre problème, certains programmes nécessitent une énorme quantité de mémoire lors de la compilation. C'est ainsi que Ruby ou Haskell (le compilateur ghc) ne peuvent tout simplement pas être compilés sur un VPS de petite taille.
emerge est l'outil en ligne de commande du système Portage de gestion des paquetages :
% emerge --version Portage 2.1.7.17 (default/linux/amd64/10.0/server, gcc-4.3.4, glibc-2.10.1-r1, 2.6.24-24-xen x86_64)
Mais Gentoo offre d'autres possibilités, par exemple certains préfèrent utiliser Paludis. D'une manière générale, Gentoo dispose de plein d'outils rigolos.
Par exemple :
[Liste des paquetages ("dpkg -l")]
% equery list
equery est livré dans le paquetage gentoolkit. Il sert à bien d'autres choses comme à trouver le paquetage auquel appartient un fichier.
emerge permet de mettre à jour tout le système d'un coup :
% emerge --update --deep --tree --verbose --ask world
Inutile de dire que cela prend du temps. Pire, on découvre souvent à cette occasion des problèmes subtils de dépendance, de bloquage d'un paquetage par un autre, qui sont longs et difficiles à régler. Je ne peux que conseiller d'appliquer la commande précédente fréquemment : plus on attend, plus elle devient cauchemardesque.
Et tout ne se passe pas toujours bien, ce qui ramène au bon (?) vieux temps où on était obligé de tout compiler. Il y a des fois des messages assez mystérieux, notamment concernant le masquage. Mais quand ça marche, on est tout heureux.
% sudo emerge -uDavt world These are the packages that would be merged, in reverse order: Calculating dependencies .... .. ...... done! [ebuild U ] x11-libs/fltk-2.0_pre6970-r1 [2.0_pre6970] USE="doc jpeg png xft zlib -cairo -debug -opengl -xinerama" 2,470 kB [0] [ebuild U ] dev-php/PEAR-PhpDocumentor-1.4.3-r1 [1.4.1] USE="-minimal" 2,367 kB [ 0] [ebuild NS #] dev-lang/php-5.2.17 [5.3.6] USE="apache2 berkdb bzip2 cgi cli crypt c type curl doc filter ftp gd gdbm hash iconv imap ipv6 json mysql ncurses nls pcre pdo pi c posix postgres readline reflection session simplexml snmp sockets spl sqlite ssl token izer truetype unicode xml xmlrpc xsl zlib (-adabas) -bcmath (-birdstep) -calendar -cdb - cjk -curlwrappers -db2 -dbase (-dbmaker) -debug -discard-path -embed (-empress) (-empres s-bcs) (-esoob) -exif (-fdftk) -firebird -flatfile -force-cgi-redirect (-frontbase) -gd- external -gmp -inifile -interbase -iodbc -kerberos -kolab -ldap -ldap-sasl -libedit -mha sh -msql -mssql -mysqli -oci8 -oci8-instant-client -odbc -pcntl -qdbm -recode -sapdb -sh aredext -sharedmem -soap (-solid) -spell -suhosin (-sybase-ct) -sysvipc -threads -tidy - wddx -xmlreader -xmlwriter -xpm -zip" 8,888 kB [0] [ebuild U ] net-analyzer/rrdtool-1.4.5-r1 [1.3.8] USE="doc perl python -lua% -rrdcg i -ruby -tcl (-nls%*)" 1,318 kB [0] ...
(Rappelez-vous que merge, en jargon Gentoo, signifie « installer ».)
Si vous êtes sur une machine AMD64 et
qu'emerge refuse de compiler avec des messages comme (masked
by: missing keyword), il faut typiquement ajouter
~amd64 après le nom du paquet dans
/etc/portage/package.keywords. La
FAQ explique
pourquoi.
Notez que Gentoo dispose d'un Bugzilla qui est très actif.
Et pour ceux qui ne veulent pas tout mettre à jour (même en version
stable, c'est-à-dire testée pendant suffisamment longtemps par suffisamment de
gens), il y a un outil, glsa-check, qui ne met à jour que les paquetages qui
ont des alertes de sécurité :
% glsa-check --test all This system is affected by the following GLSAs: 200809-05 200903-25 201006-18 201009-03
Très utile lorsque vous reprenez en main la gestion d'une Gentoo après une longue période de non-maintenance.
Il y a aussi des particularités de Gentoo qui peuvent être déroutantes, voire agaçantes. Par exemple, les démons ne sont pas redémarrés automatiquement en cas de mise à jour. C'est embêtant lorsque c'est une mise à jour de sécurité.
D'autre part, lorsqu'on met à jour
une bibliothèque, la mise à jour des paquetages qui en dépendent n'est
pas automatique. Si on a changé MYLIB, il faut penser à
revdep-rebuild --library=MYLIB (sinon, on se
récupère des erreurs du genre « error while loading shared
libraries: libjpeg.so.62: cannot open shared object file: No such file
or directory ». Voici un exemple, après avoir recompilé
OpenSSL, on recompile tout ce qui dépendait de la vieille version :
# revdep-rebuild --library=/usr/lib/libssl.so.0.9.8 * Configuring search environment for revdep-rebuild * Checking reverse dependencies * Packages containing binaries and libraries using /usr/lib/libssl.so * will be emerged. * Collecting system binaries and libraries ... * found /usr/bin/htdig * found /usr/bin/ncat * found /usr/bin/ssh-keygen ... * Assigning files to packages * Assigning packages to ebuilds ... emerge --oneshot www-misc/htdig:0 net-analyzer/nmap:0 net-misc/openssh:0 ...
Même chose lorsqu'on a mis à jour des programmes d'infrastructure comme les interpréteurs Perl ou Python. Heureusement, il existe des programme perl-cleaner et python-updater, qui servent justement à cela, et qu'il ne faut pas oublier de lancer.
Enfin, les dépendances ne sont gérées qu'à l'installation, pas à la désinstallation. Rien, même pas un avertissement, ne prévient qu'on est en train de retirer une bibliothèque vitale.
Et pour les fichiers de configuration ? Une fois un emerge
réalisé, on fait un etc-update :
# etc-update
Scanning Configuration files...
The following is the list of files which need updating, each
configuration file is followed by a list of possible replacement files.
1) /etc/bind/named.conf (1)
2) /etc/init.d/named (1)
Please select a file to edit by entering the corresponding number.
(don't use -3, -5, -7 or -9 if you're unsure what to do)
(-1 to exit) (-3 to auto merge all remaining files)
(-5 to auto-merge AND not use 'mv -i')
(-7 to discard all updates)
(-9 to discard all updates AND not use 'rm -i'): -3
Replacing /etc/bind/named.conf with /etc/bind/._cfg0000_named.conf
mv: overwrite `/etc/bind/named.conf'? y
Replacing /etc/init.d/named with /etc/init.d/._cfg0000_named
mv: overwrite `/etc/init.d/named'? y
Exiting: Nothing left to do; exiting. :)
Il existe une alternative à etc-update, dispatch-conf.
Je l'avais signalé, mais Gentoo permet également des paquetages binaires qu'on peut installer avec :
emerge --usepkg --getbinpkgonly XXX
mais il semble qu'il faille un arbre portage complet. De toute façon, en l'absence d'un dépôt public de tels paquetages binaires, ils ne sont utilisables qu'à l'intérieur d'une organisation (si on a des dizaines de machines et qu'on ne veut pas que chacune recompile).
Comment passe t-on d'une version de Gentoo à une autre ? Le processus est documenté mais, en gros :
# cd /etc # ln -sf /usr/portage/profiles/default/linux/amd64/10.0/server make.profile
et cela fait passer en version 10.0 (au fur et à mesure des compilations).
Autre solution : eselect profile set
default/linux/amd64/10.0/server (eselect
list permet de voir tous les choix possibles).
Bien sûr, Gentoo permet aussi de créer son propre paquetage si son programme favori n'est pas encore disponible. On trouve de bonnes documentations en ligne mais le principe est simple :
- On écrit un fichier
ebuilden s'inspirant de ceux qui existent dans/usr/portage. Voici par exemple celui que j'avais fait pour NSD (depuis, le paquetage a évolué). - On met le fichier dans
/usr/local/portage/$DIR/$PROGRAM. - On crée les fichiers auxiliaires nécessaires avec
ebuild $PROGRAM-$VERSION.ebuild digest. - On peut ensuite le traiter comme un paquetage normal (
emerge -u $PROGRAM).
Pour l'anecdote, voici quels avaient été les temps de fonctionnement de ma machine Gentoo chez Slicehost :
% uprecords
# Uptime | System Boot up
----------------------------+---------------------------------------------------
1 370 days, 18:57:23 | Linux 2.6.32.9-rscloud Mon Mar 22 20:20:22 2010
2 335 days, 22:40:29 | Linux 2.6.16.29-xen Mon Sep 22 16:28:39 2008
3 261 days, 23:45:51 | Linux 2.6.16.29-xen Fri Sep 14 10:46:04 2007
-> 4 245 days, 07:01:34 | Linux 2.6.32.9-rscloud Mon Mar 28 16:19:07 2011
5 154 days, 16:14:35 | Linux 2.6.16.29-xen Thu Apr 12 16:47:20 2007
Si vous voulez en savoir plus sur Gentoo :
- Le saviez-vous ? Le Gentoo est un pingouin (oui, je sais, en fait, c'est un manchot). J'ai découvert cela avec ces jolies photos.
- La documentation officielle.
- Le Wiki de Gentoo.
- Un bon HOWTO en français.
- Un projet original, le système de paquetage Gentoo avec le noyau et une partie de FreeBSD.
Merci à Samuel Tardieu pour son aide et ses remarques sur Gentoo.
L'article seul
RFC 6441: Time to Remove Filters for Previously Unallocated IPv4 /8s
Date de publication du RFC : Novembre 2011
Auteur(s) du RFC : L. Vegoda (ICANN)
Réalisé dans le cadre du groupe de travail IETF grow
Première rédaction de cet article le 29 novembre 2011
Dernière mise à jour le 5 janvier 2012
Pour limiter certains risques de sécurité, des opérateurs réseaux filtraient en entrée de leur réseau les adresses IP non encore allouées (dites bogons). Les adresses IPv4 étant désormais totalement épuisées, cette pratique n'a plus lieu d'être et ce RFC demande donc que ces filtres soient démantelés.
L'idée était d'empêcher l'usage de ces préfixes IP non alloués. Ils représentaient des cibles tentantes, par exemple pour un spammeur qui voulait des adresses jetables et non traçables : on trouve un bloc non alloué, on l'annonce en BGP (puisqu'il n'est pas alloué, il n'y a pas de risque de collision), on envoie son spam et on arrête l'annonce BGP (voir les articles cités à la fin). Pour éviter cela, et d'autres attaques analogues, l'habitude s'est prise de filtrer les bogons, ces préfixes non alloués. Certains opérateurs rejetaient les annonces BGP pour ces bogons, d'autres bloquaient sur le pare-feu les paquets ayant une adresse source dans ces préfixes non alloués. Ces pratiques étaient largement documentées par exemple sur le site de référence sur les bogons.
Cette pratique a toujours posé des problèmes, notamment celui de la « débogonisation ». Lorsqu'un préfixe qui n'était pas alloué le devient, il faut toute une gymnastique pour le retirer des filtres existants, sachant que beaucoup de ces filtres ne sont que rarement mis à jour. On voit ainsi des messages sur les listes de diffusion d'opérateurs réseaux avertissant de l'arrivée prochaine d'un nouveau préfixe et demandant qu'il soit supprimé des filtres. Voici deux exemples de ces annonces en 2004 et en 2005. Pour permettre aux opérateurs de tester que tout va bien après cette suppression, les RIR mettent souvent un beacon, un amer, dans le préfixe, une adresse IP qu'on peut pinguer pour tester, comme le recommande le RFC 5943. Tout ce travail faisait donc que la chasse aux bogons était contestée depuis longtemps.
À noter (section 2) que le terme de bogon a été défini dans le RFC 3871, qui recommande leur blocage. Ce même RFC 3871 décrit en détail le problème que posent les bogons et la raison de leur éradication. Le terme de martien, plus flou (il vient du RFC 1208), est appliqué à toutes sortes de paquets dont l'adresse source est anormale (dans le DNS, il a un autre sens, celui de paquet de réponse à une question qui n'a pas été posée).
La section 3 représente le cœur du RFC : elle formule la nouvelle règle. Celle-ci, tenant compte de l'épuisement des adresses IPv4 est simple : tous les préfixes IPv4 sont désormais alloués ou réservés. Il ne faut donc filtrer que les réservés. Les autres peuvent désormais tous être une source légitime de trafic IP. La chasse aux bogons et les difficultés de la débogonisation faisant partie du folklore de l'Internet depuis très longtemps, c'est donc une page d'histoire qui se tourne. (Les adresses IPv6 sont, elles, loin d'être toutes allouées et ne sont donc pas concernées.)
La section 4 rappelle que l'autorité pour cette liste de préfixes réservés est le RFC 6890. On y trouve par exemple les adresses privées du RFC 1918 ou bien les adresses réservées à la documentation du RFC 5737. Les listes de bogons qu'on trouve sur le réseau, comme celle de TeamCymru sont désormais réduites à ce groupe.
À noter que l'assertion « Tous les préfixes sont désormais alloués » ne vaut que pour les préfixes de longueur 8 (les « /8 ») distribués aux RIR. Certains peuvent filtrer à un niveau plus fin, en distinguant dans ces /8 les adresses que les RIR ont affectés de celles qui ne le sont pas encore. Comme le rappelle la section 3.2, cette pratique est risquée, les affectations par les RIR changeant vite. Le RFC demande donc que, si on a de tels filtres, ils soient changés au moins une fois par jour.
Pour en apprendre plus sur les bogons, on peut
regarder la bonne
analyse faite par BGPmon. On voit finalement peu d'annonces
BGP de bogons (6 seulement
en 2011), la plupart pour le préfixe
198.18.0.0/15 des mesures de performance (RFC 5735). Un bon résumé des
bogons et de la débogonisation avait été fait par
Dave Deitrich en 2005.
Quelques articles sur les trucs utilisés par des méchants (spammeurs, par exemple), en connexion avec les bogons :
- « Understanding the network-level behavior of spammers » par Anirudh Ramachandran (Georgia Tech) et Nick Feamster (Georgia Tech). Très bonne analyse technique des trucs réseaux utilisés par les spammeurs. C'était le première article à mettre en évidence le truc d'annoncer en BGP des préfixes bogons, d'envoyer le spam, puis d'arrêter l'annonce BGP.
- « Practical BGP Security: Architecture, Techniques and Tools » (page 3)
- Le premier témoignage, en 2002.
L'article seul
Comment faire pour afficher l'état de nombreuses boîtes aux lettres ?
Première rédaction de cet article le 28 novembre 2011
Dernière mise à jour le 30 novembre 2011
Je sollicite l'aide de mes lecteurs pour trouver un logiciel qui m'affiche l'état (nombre de messages non lus) de mes multiples boîtes aux lettres. J'utilisais gbuffy mais il n'est plus maintenu et dépend de bibliothèques qui n'existent pas dans les systèmes récents.
Voici le problème exact : je classe automatiquement mon courrier dans des dizaines de boîtes (le classement est fait avec procmail, je passerais peut-être un jour à Sieve, cf. RFC 5228). Je tiens à avoir les boîtes en local, à la fois pour pouvoir travailler sans connexion (ah, les tarifs d'itinérance en 3G...) et pour pouvoir utiliser les outils d'Unix pour, par exemple, chercher dans ces boîtes. Gmail n'est donc pas envisageable.
Avec tant de boîtes, comment savoir lesquelles ont du courrier non
lu ? J'utilisais auparavant gbuffy. Il
convient parfaitement à mon usage et affichait de manière très simple
de nombreuses boîtes :
Mais gbuffy n'est plus maintenu depuis longtemps. Il dépend de la très vieille version de la bibliothèque GTK+ libgtk1, désormais retirée de Debian (bogue #520441) et d'Ubuntu (bogue #478219 ; le PPA de secours ne marche même plus avec les Ubuntu récents).
Il existe des tas de programmes qui suivent les boîtes aux lettres (locales ou IMAP) et signalent des choses à l'utilisateur. Beaucoup ont un nom dérivé de l'antique biff. Mais je ne veux pas de notification, je veux de l'affichage. La plupart des « biff-like » sont mono-boîte (ou à la rigueur, pour quatre ou cinq boîtes). Je cherche un programme qui puisse afficher des dizaines de boîtes.
Alors, par quoi puis-je remplacer gbuffy ?
- Le vieil xbuffy segfaulte lorsque la liste des boîtes est si longue...
- ebiff n'est pas maintenu depuis 2004 et ne compile même pas sur un Ubuntu récent.
- Je n'ai pas encore réussi à compiler gnubiff, qui a beaucoup de dépendances.
- Je n'ai pas encore testé asmail, qui n'a pas bougé depuis 2000...
- netbiff est incroyablement compliqué à configurer, avec son système baroque de fichier de configuration éclaté en une demi-douzaine de fichiers et, de toute façon, semble capable de lancer une action lorqu'une boîte change d'état, mais pas d'afficher l'état des boîtes.
- Conky est un truc très spécial, qui peut tout afficher, donc peut-être aussi les boîtes aux lettres. Mais il faut le configurer pour cela, ce que est extrêmement difficile (aucun tutoriel, et le logiciel segfaulte à mes premiers essais).
- Utiliser un MUA qui affiche l'état des boîtes, comme le fait Thunderbird ? Cela m'embête de choisir un MUA pour cela.
Des idées ? Des suggestions ? Ou bien dois-je changer radicalement ma façon de gérer le courrier (en convertissant des années d'archives) ?
Actuellement, je teste le patch «
sidebar » de mutt,
disponible et documenté en http://www.lunar-linux.org/index.php?option=com_content&task=view&id=44. On
peut l'obtenir sur Debian et
Ubuntu par le paquetage
mutt-patched. Je le configure ainsi dans le
.muttrc, pour qu'il connaisse la liste des boîtes :
mailboxes `display-mailboxes`
où le programme display-mailboxes est disponible. C'est loin d'être
convaincant : mutt, comme Thunderbird, affiche la liste des boîtes
linéairement (contrairement à Gbuffy qui le fait en deux dimensions),
ce qui ne convient pas aux longues listes. Et passer de la
sidebar à la vue normale n'est pas naturel, je trouve.
L'article seul
« Derrière la scène : comment et grâce à qui l'Internet fonctionne t-il ? » à l'Ubuntu Party à Toulouse
Première rédaction de cet article le 27 novembre 2011
Le 26 novembre, à Toulouse, j'ai eu le plaisir de faire un exposé lors de l'Ubuntu Party (organisée par Toulibre) sur le sujet indiqué dans le titre.
L'accroche était « Que se passe-t-il derrière ma box ? Qui dirige l'Internet ? Qu'est-ce qu'un Tier 1 ? Pourquoi Comcast et Level 3 s'accusent-ils réciproquement de « patate chaude » ? À quoi sert un point d'échange ? BGP fait-il mal ? Pourquoi un maladroit au Pakistan peut-il bloquer YouTube sur toute la planète ? Cet exposé sera consacré au fonctionnement technique d'Internet : le rôle des différents acteurs, les techniques utilisées pour synchroniser le routage, et les mécanismes qui font que, vaille que vaille, l'infrastructure marche. ».
Voici les supports de présentation produits à cette occasion : en
PDF adaptés à la vue sur écran, en
PDF adaptés à l'impression, et leur source en format LaTeX/Beamer. On peut
également les télécharger à partir du site
de Toulibre. Enfin, une vidéo est disponible, au format WebM, en http://www.toulibre.org/pub/2011-11-26-capitole-du-libre/video/bortzmeyer-comment-internet-fonctionne.webm (attention, 172 Mo).
L'article seul
Exposé sur les clés dans le DNS à JRES
Première rédaction de cet article le 23 novembre 2011
Dernière mise à jour le 24 novembre 2011
Le 23 novembre, à Toulouse, j'ai eu le plaisir de faire un exposé lors des JRES sur le sujet « Des clés dans le DNS, un successeur à X.509 ? ».
Voici les documents produits à cette occasion :
- L'article, en format PDF ou son original en format LibreOffice.
- Il est également récupérable sur le site de JRES à partir du programme.
- Le flux vidéo de la présentation.
- Les transparents en PDF. Et leur source en format LaTeX/Beamer.
L'article est sous GFDL (JRES n'ajoute pas de contraintes).
Depuis, le mécanisme DANE de remplacement de X.509 a été normalisé dans le RFC 6698, en août 2012.
L'article seul
RFC 6419: Current Practices for Multiple Interface Hosts
Date de publication du RFC : Novembre 2011
Auteur(s) du RFC : M. Wasserman (Painless Security, LLC), P. Seite (France Telecom - Orange)
Pour information
Réalisé dans le cadre du groupe de travail IETF mif
Première rédaction de cet article le 22 novembre 2011
Il fut une époque où la machine terminale connectée à l'Internet n'avait typiquement qu'une seule interface réseau. Seuls les routeurs avaient plusieurs interfaces et donc des décisions difficiles à prendre comme « quelle adresse source choisir pour le paquet que je génère ? » Aujourd'hui, les machines les plus ordinaires ont souvent, à leur tour, plusieurs interfaces réseau. Mon smartphone a une interface WiFi et une 3G. Mon ordinateur portable a une interface filaire, une 3G, une Wifi et une Bluetooth. Qui dit plusieurs interfaces dit décisions à prendre. Quel serveur DNS utiliser ? Celui appris via l'interface filaire ou bien celui appris en Wifi ? Par quelle interface envoyer un paquet qui sort de la machine ? La question est d'autant plus difficile que les différentes interfaces fournissent en général des services très différents, en terme de qualité et de prix. Le groupe de travail MIF de l'IETF travaille à normaliser le comportement des machines sur ce point. Son premier RFC (un autre, le RFC 6418, concerne l'exposé du problème) commence par examiner l'état de l'art : que font aujourd'hui les divers systèmes d'exploitation confrontés à cette question ?
Le RFC ne prétend pas couvrir tous les systèmes. Il se contente de ceux que les membres du groupe de travail connaissaient, ceux sur lesquels ils avaient de la documentation et des informations : Nokia S60, Windows Mobile, Blackberry, Android, Windows, et des systèmes à base de Linux.
Comment ces systèmes gèrent cette multiplicité des interfaces
réseaux, se demande la section 2. Une première approche est de
centraliser la gestion des connexions : ce n'est pas l'application qui
choisit l'interface à utiliser, elle passe par un gestionnaire de
connexions (en lui transmettant parfois quelques souhaits) qui choisit
pour elle. Le gestionnaire peut choisir en fonction de la table de
routages (si l'application veut écrire à
172.23.1.35 et qu'une seule interface a une route
vers cette adresse, le choix est vite fait) mais elle ne suffit pas
toujours (que faire si deux interfaces sont connectées à un réseau
privé 172.23.0.0/16 ?). Le gestionnaire doit aussi tenir
compte d'autres facteurs. Le coût est souvent le plus important (prix
élevés de la 3G, surtout en itinérance, par
rapport au Wifi ou au filaire, par exemple).
Une autre solution est que l'application choisisse elle-même, en fonction des informations qu'elle reçoit du système. Certaines applications ont des idées bien précises sur la connexion qu'elles veulent utiliser. Par exemple, sur Android, la plupart des clients SIP refusent par défaut d'utiliser les connexions 3G, les opérateurs y interdisant en général le trafix voix (en violation de la neutralité du réseau). Les deux méthodes (gestionnaire de connexions centralisé et choix par l'application) ne sont pas complètement exclusives. Comme indiqué, on peut aussi avoir un gestionnaire centralisé, mais qui permet aux applications d'indiquer des préférences (« essaie d'éviter la 3G »).
Certains choix sont par contre typiquement réglés par une troisième approche : le faire entièrement dans le système, sans demander à l'utilisateur ou aux applications (section 2.3). Le système rassemble des informations de sources diverses (DHCP, RA (Router Advertisment), configuration manuelle par l'administrateur système) et fait ensuite des choix qui sont globaux au système, ou bien spécifiques à chaque interface. Il n'y a aucune règle commune entre les différents systèmes d'exploitation sur ce plan, et aucun ne semble fournir une solution parfaite.
Par exemple, la configuration DNS voit certains systèmes permettre un jeu de résolveurs DNS différent par interface, avec des règles indiquant quel jeu est choisi. D'autres ont au contraire un seul jeu de résolveurs.
La sélection de l'adresse source est plus « standard
». L'application fournit l'adresse de destination et, lorsqu'elle n'a
pas choisi une adresse source explicité (option
-b de OpenSSH, par
exemple), le système en sélectionne automatiquement une. Pour
IPv6, il existe même une norme pour cela, le
RFC 6724 (et son prédécesseur, le RFC 3484, qui est encore la référence). Un grand nombre de systèmes d'exploitation ont
adapté cette norme à IPv4 et l'utilisent donc pour toutes les familles
d'adresses. En revanche, tous ne fournissent pas forcément un mécanisme
permettant à l'administrateur système d'influencer cette sélection (le
/etc/gai.conf sur Linux). Autre point où les
systèmes diffèrent, certains choisissent l'interface de sortie avant
l'adresse source, d'autres après.
La section 3 est ensuite l'exposé des pratiques des différents systèmes, à l'heure actuelle (une version future pourra changer leur comportement). Ainsi, le système S60 (qui tourne sur Symbian) introduit le concept d'IAP (Internet Access Point) ; un IAP rassemble toutes les informations sur une interface (physique ou virtuelle, dans le cas des tunnels). La machine a en général plusieurs IAP et l'application choisit une IAP au moment où elle a besoin du réseau. Ce choix est motivé par le fait que toutes les IAP ne fournissent pas forcément le service attendu par l'application. Par exemple, l'envoi d'un MMS nécessite l'usage d'un IAP qui donne accès à la passerelle MMS de l'opérateur, qui n'est en général pas joignable depuis l'Internet public. De même, une application qui accède aux serveurs privés d'une entreprise va choisir l'IAP qui correspond au VPN vers l'entreprise.
Ce concept d'IAP permet d'éviter bien des questions. Ainsi, le serveur DNS est indiqué dans l'IAP et, une fois celle-ci choisie, il n'y a pas à se demander quel serveur utiliser. (Reprenez l'exemple du VPN : cela garantira que l'application corporate utilisera un serveur DNS sûr et pas celui du hotspot où le téléphone est actuellement connecté.) De même, il existe une route par défaut par IAP et ce n'est donc pas un problème si deux interfaces de la même machine ont des plages d'adresses RFC 1918 qui se recouvrent (ou même si les deux interfaces ont la même adresse IP).
Comment l'application choisit-elle l'IAP ? Cela peut être fixé en dur dans le programme (cas de l'application MMS, en général), choisi par l'utilisateur au moment de la connexion, ou bien déterminé automatiquement par le système. La documentation de ce système figure en ligne.
Pour Windows Mobile et Windows Phone 7, tout dépend du Connection Manager. Celui-ci gère les connexions pour le compte des applications, en tenant compte de critères comme le coût ou comme la capacité du lien. Les applications peuvent l'influencer en demandant des caractéristiques particulières (par exemple une capacité minimale). Windows met en œuvre le RFC 3484 et l'administrateur système peut configurer des règles qui remplacent celles par défaut. Ce système est documenté en ligne.
Le Blackberry laisse les applications choisir la connexion qu'elles veulent, même s'il fournit un relais pour celles qui le désirent. Cela dépend toutefois de la configuration du réseau (l'utilisation obligatoire du Enterprise Server peut être choisie, par exemple). Les réglages comme le DNS sont par interface et non pas globaux au système. Plus de détails sont fournis dans la documentation.
Et Google Android ? Utilisant un noyau Linux, il partage certaines caractéristiques avec les autres systèmes Linux. Par défaut, il se comporte selon le modèle « machine terminale ouverte » (weak host model, cf. RFC 1122, section 3.3.4.2), mais peut aussi utiliser le modèle « machine strictement terminale » (strong host model). Dans le premier cas, les différentes interfaces réseaux ne sont pas strictement séparées, un paquet reçu sur une interface est accepté même si l'adresse IP de destination n'est pas celle de cette interface. Dans le second, la machine est stricte et refuse les paquets entrants si l'adresse IP de destination ne correspond pas à l'interface d'entrée du paquet.
La configuration DNS est globale (attention, Android ne la note pas
dans /etc/resolv.conf, dont le contenu est
ignoré). Cela veut dire que, dès qu'une réponse DHCP est reçue sur une
interface, la configuration DNS de cette interface remplace la
précédente.
Depuis Android 2.2, le RFC 3484 est géré. (Notez que, à l'heure actuelle, Android ne peut pas faire d'IPv6 sur l'interface 3G.)
La documentation figure dans le paquetage
android.net. Les
applications peuvent utiliser la classe
ConnectivityManager si elles veulent influencer
la sélection de l'interface. Pour cela, le système met à leur
disposition la liste des interfaces et leurs caractéristiques. (Pour étudier un programme qui l'utilise, vous pouvez par exemple regarder les occurrences de ConnectivityManager dans le source Java de CSIPsimple.)
Le RFC se penche aussi sur un système moins connu, Arena, qui utilise également Linux et fournit un gestionnaire de connexions pour choisir les interfaces, avec indication des préférences par les applications. Il sera décrit dans un futur RFC.
Et sur les systèmes d'exploitation utilisés sur le bureau ? Windows est présenté mais sera décrit plus en détail dans un autre RFC. Les systèmes utilisant Linux (comme Ubuntu ou Fedora) partagent plusieurs caractéristiques :
- Les informations comme l'adresse IP utilisée sont stockées par interface et sont obtenues par DHCP (ou RA).
- Un certain nombre d'informations, notamment la route par défaut, les serveurs DNS ou les serveurs NTP sont globales au système. Bien que les clients DHCP utilisés, comme celui de l'ISC, permettent une configuration différente par interface, des paramètres comme la liste des résolveurs DNS, quelle que soit l'interface d'où ils viennent, effacent et remplacent globalement les paramètres précédemment obtenus.
- La dernière interface configurée est donc forcément l'interface principale.
Les systèmes à base de BSD ont en gros les
mêmes caractéristiques. Dans les deux cas, Linux ou BSD, certaines
options permettent de passer outre les informations obtenues par
DHCP. Par exemple, des option modifiers dans le client DHCP OpenBSD offrent la possibilité
d'indiquer des valeurs à utiliser avant, ou bien à la place de, celles
fournies par le serveur DHCP. Même chose pour des options comme
-R du client DHCP
Phystech (qui indique de ne pas modifier
resolv.conf) ou comme nodns
et nogateway dans les options de Pump, pour ignorer les résolveurs DNS et la route
par défaut de certaines interfaces. D'autres systèmes disposent
d'options similaires.
Enfin, même si le RFC ne le mentionne que très rapidement, il existe des systèmes de plus haut niveau (comme Network Manager, très pratique pour les machines qui se déplacent fréquemment) dont la tâche est d'orchestrer tout cela, de surveiller la disponibilité des interfaces, de lancer le client DHCP lorsque c'est nécessaire, d'accepter ou de passer outre ses choix, etc.
Voilà en gros la situation actuelle. Prochains efforts du groupe MIF : l'améliorer... Le RFC 6418 donne le cahier des charges de cet effort. Le RFC 6731 normalise les nouvelles règles de sélection pour les serveurs DNS.
L'article seul
RFC 6409: Message Submission for Mail
Date de publication du RFC : Novembre 2011
Auteur(s) du RFC : R. Gellens (Qualcomm), J. Klensin
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF yam
Première rédaction de cet article le 16 novembre 2011
Pendant longtemps, le système de courrier électronique de l'Internet ne faisait aucune différence entre le serveur de messagerie et le simple PC de l'utilisateur. Tous utilisaient le même protocole SMTP, spécifié dans le RFC 2821. Depuis le RFC 2476 et plus encore depuis le RFC 4409, précurseurs de notre RFC 6409, ce n'est plus vrai. Le simple PC doit désormais utiliser une autre solution, la soumission de message.
L'ancienne architecture était raisonnable à l'époque où toutes les machines connectées à l'Internet étaient de gros serveurs gérés par des professionnels. Ceux-ci pouvaient faire en sorte que tout soit correctement configuré. Et, donc les autres serveurs, les MTA pouvaient ériger en principe le "Pas touche" et ne jamais modifier ou contester un message reçu (section 1 du RFC ; en pratique, pas mal de MTA modifiaient quand même le contenu des messages, avec des conséquences négatives).
Aujourd'hui, avec le nombre de micro-ordinateurs non gérés qui sont connectés à Internet, cela n'est plus possible. Le RFC 2476 avait donc séparé les clients SMTP en deux catégories : les MTA qui se connectent au port traditionnel, le numéro 25 et les MUA qui, s'ils veulent envoyer en SMTP, doivent utiliser un autre service, nommé MSA, tournant en général sur le port 587 (section 3.1), et soumis à d'autres règles :
- Le serveur est autorisé à modifier le message (par exemple en ajoutant des en-têtes comme Date ou Message-ID s'ils sont absents ou incorrects, sections 5, 6 et 8),
- Une authentification est souvent requise, surtout si le port de soumission est accessible de tout l'Internet (sections 4.3 et 9).
Attention toutefois, la section 8 rappelle que les modifications du message soumis ne sont pas toujours inoffensives et qu'elles peuvent, par exemple, invalider les signatures existantes.
Notre RFC, qui remplace le RFC 4409, qui lui-même remplaçait le RFC 2476, pose en principe que, désormais, les machines des simples utilisateurs devraient désormais utiliser ce service.
La soumission de messages, telle que normalisée dans ce RFC est ses prédécesseurs, a été un grand succès depuis dix ans, notamment depuis trois ans. Le port 25 est de plus en plus souvent bloqué en sortie des FAI (pour limiter l'envoi de spam par les zombies), et la seule solution pour écrire sans passer par le serveur de son FAI est désormais le port 587. La norme technique est sortie il y a désormais treize ans et est particulièrement stable et mûre.
Si vous utilisez Postfix, vous pouvez lire un exemple de configuration de Postfix conforme (partiellement) à ce RFC.
Notre RFC a été développé par le groupe de travail YAM de l'IETF. Ce groupe est chargé de prendre toutes les normes IETF liées au courrier électronique et de les faire avancer sur le chemin des normes, si possible. La soumission de courrier est ainsi devenue « norme tout court » (Full Standard) avec ce RFC 6409. Les changements depuis le RFC 4409 sont décrits dans l'annexe A. Les principaux sont l'importance plus grande de l'internationalisation (section 6.5, qui précise que le MSA peut changer l'encodage), et une mise en garde plus nette contre les risques encourus en cas de modification de messages par le MSA.
L'article seul
RFC 6452: The Unicode code points and IDNA - Unicode 6.0
Date de publication du RFC : Novembre 2011
Auteur(s) du RFC : P. Faltstrom (Cisco), P. Hoffman (VPN Consortium)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF appsawg
Première rédaction de cet article le 13 novembre 2011
Une des exigences de la norme sur les IDN
(RFC 5890) est la stabilité : si un caractère est autorisé dans les
noms de domaine à un
moment donné, il devrait l'être pour toujours, sous peine qu'une
épée de Damoclès pèse sur les titulaires de
noms, la crainte qu'un nom qu'ils utilisent devienne subitement
invalide. Mais le mécanisme par lequel sont déterminés les caractères
autorisés ou interdits rend inévitable de tels problèmes, heureusement
dans des cas rares et marginaux. C'est ce qui vient de se produire
avec la sortie de la norme Unicode version 6 : le caractère ᧚ (U+19DA),
autrefois autorisé, est désormais interdit. S'il y avait eu des noms
de domaine l'utilisant (ce n'était apparemment pas le cas), ils
deviendraient subitement illégaux.
Vu que ce caractère est très rare, toute cette discussion n'est-elle pas une tempête dans un verre d'eau ? Pas complètement, parce que c'est la première fois que le problème se pose depuis la sortie de la version 2 de la norme IDN, et que la façon dont ce cas a été traité va servir de modèle pour des futurs problèmes qui pourraient être plus délicats.
Reprenons dès le début : dans la norme actuelle sur les IDN, dite « IDNAbis » (RFC 5890), les caractères Unicode peuvent être valides ou invalides dans un nom de domaine. Cette validité (qui était déterminée manuellement dans la première version d'IDN) découle d'un algorithme, normalisé dans le RFC 5892, qui prend en compte les propriétés que la norme Unicode attache à un caractère. Par exemple, si le caractère a la propriété « Est une lettre », il est valide. Ce système a l'avantage de remédier au principal inconvénient d'IDN version 1, le fait que le premier IDN était lié à une version particulière d'Unicode. Avec IDNAbis, au contraire, lorsque le consortium Unicode sort une nouvelle version de sa norme, il suffit de faire tourner à nouveau l'algorithme, et on a la liste des caractères valides dans cette nouvelle version.
Le problème que cela pose est que les propriétés d'un caractère
Unicode peuvent changer d'une version à l'autre. Elles ne sont pas
forcément couvertes par les engagements de stabilité du consortium
Unicode. C'est ce qui s'est produit en octobre
2010, lors de la sortie de la version 6 d'Unicode. Trois caractères ont vu leur
validité changer car leur GeneralCategory Unicode a
changé. Pour les deux premiers, rien de très grave. ೱ (U+0CF1)
et ೲ (U+0CF2), classés à tort comme des
symboles, ont été reclassés comme lettres et sont donc devenus
valides, alors qu'ils étaient invalides. Personne n'avait donc pu les
utiliser et le changement ne va donc pas affecter les titulaires de
noms de domaine.
Mais le troisième pose un problème épineux. Pas
quantitativement. Ce caractère ᧚ (U+19DA),
de l'écriture Tai
Lue n'a apparemment jamais été utilisé dans un nom de
domaine, en partie par ce que l'écriture dont il fait partie est peu
répandue (et ses utilisateurs sont peu connectés à l'Internet). Mais,
qualitativement, c'est ennuyeux car U+19DA (un
chiffre) fait le chemin inverse. D'autorisé, il devient
interdit. Potentiellement, il peut donc remettre en cause la stabilité
des noms de domaine. Si on applique aveuglément l'algorithme du RFC 5892, U+19DA va devenir
interdit. Alors, que faire ? Le RFC 5892 (section 2.7)
prévoyait une table des exceptions, où on pouvait mettre les
caractères à qui on désirait épargner le sort commun. Fallait-il y
mettre le chiffre 1 du Tai Lue ?
La décision finalement prise, et documentée par ce RFC (décision
pompeusement baptisée « IETF consensus », bien
que la section 5 rappelle qu'elle a été vigoureusement discutée) a
finalement été de laisser s'accomplir le destin. Aucune exception n'a
été ajoutée pour ces trois caractères, l'algorithme normal s'applique
et U+19DA ne peut donc plus être
utilisé. L'argument principal est que ce caractère n'était quasiment
pas utilisé. Les cas suivants mèneront donc peut-être à des décisions
différentes (la section 2 rappelle bien que, dans le futur, les choses
seront peut-être différentes).
Ce RFC 6452 documente donc cette décision. Bien qu'elle se résume à « ne touchons à rien », il était préférable de la noter, car un changement qui casse la compatibilité ascendante n'est pas à prendre à la légère.
Les deux autres caractères, utilisés en Kannada, ೱ (U+0CF1)
et ೲ (U+0CF2) ne créent pas le même
problème car ils ont changé en sens inverse (interdits autrefois, ils sont
désormais autorisés).
L'article seul
RFC 6430: Email Feedback Report Type Value : not-spam
Date de publication du RFC : Novembre 2011
Auteur(s) du RFC : K. Li (Huawei), B. Leiba (Huawei)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF marf
Première rédaction de cet article le 11 novembre 2011
Il existe un format standard pour la transmission de rapports d'abus entre acteurs de l'Internet qui permet, par exemple, à des opérateurs de serveurs de messagerie de signaler un spam, et de traiter automatiquement ces rapports. Ce format se nomme ARF et est normalisé dans le RFC 5965. Chaque rapport ARF indique un type d'abus et ce nouveau RFC 6430 ajoute le type not spam, qui permet d'attirer l'attention sur un message classé à tort.
Le format ARF est conçu pour de gros
opérateurs, traitant des millions de messages et d'innombrables
rapports d'abus (spam mais aussi
hameçonnage, distribution de logiciel
malveillant, etc). Avec de tels
volumes à traiter, l'automatisation est nécessaire et c'est ce que
permet ARF. Le type abuse, documenté en section
7.3 du RFC 5965, permet de signaler un message
comme n'étant pas désiré. Mais on a parfois besoin de l'inverse, signaler
qu'un message n'est pas du spam, pour que le destinataire du rapport
ajuste ses filtres. C'est ce qu'introduit notre RFC, suite à une
demande de l'OMA (« Mobile Spam Reporting
Requirements », OMA-RD-SpamRep-V1_0 20101123-C).
Bien sûr, le destinataire du rapport est libre de l'action à entreprendre. Il peut par exemple attendre d'avoir plusieurs rapports équivalents, Si l'opérateur accepte des rapports envoyés directement par les utilisateurs (ceux-ci ne vont pas taper du ARF à la main mais ils peuvent avoir un MUA muni d'un bouton Report as non-spam qui le fait pour eux), il doit tenir compte du fait que les utilisateurs peuvent se tromper (cliquer trop vite) ou même tenter d'influencer le système (mais non, cette publicité n'est pas du spam, laissez-la passer...). La section 4 rappelle donc de traiter avec prudence ces rapports.
Les détails de syntaxe figurent en section 3 du RFC. Voici un
exemple de rapport avec le Feedback-Type: à
not-spam. abusedesk@example.com
signale à abuse@example.net que le message de
someone@example.net n'est
pas, en dépit des apparences, du spam (mettons qu'il ait été envoyé en
réponse à une sollicitation d'un médecin) :
From: <abusedesk@example.com>
Date: Thu, 8 Mar 2005 17:40:36 EDT
Subject: FW: Discount on pharmaceuticals
To: <abuse@example.net>
Message-ID: <20030712040037.46341.5F8J@example.com>
MIME-Version: 1.0
Content-Type: multipart/report; report-type=feedback-report;
boundary="part1_13d.2e68ed54_boundary"
--part1_13d.2e68ed54_boundary
Content-Type: text/plain; charset="US-ASCII"
Content-Transfer-Encoding: 7bit
This is an email abuse report for an email message received
from IP 192.0.2.1 on Thu, 8 Mar 2005 14:00:00 EDT.
For more information about this format please see
http://tools.ietf.org/html/rfc5965
Comment: I sell pharmaceuticals, so this is not spam for me.
--part1_13d.2e68ed54_boundary
Content-Type: message/feedback-report
Feedback-Type: not-spam
User-Agent: SomeGenerator/1.0
Version: 1
--part1_13d.2e68ed54_boundary
Content-Type: message/rfc822
Content-Disposition: inline
Received: from mailserver.example.net
(mailserver.example.net [192.0.2.1])
by example.com with ESMTP id M63d4137594e46;
Thu, 08 Mar 2005 14:00:00 -0400
From: <someone@example.net>
To: <Undisclosed Recipients>
Subject: Discount on pharmaceuticals
MIME-Version: 1.0
Content-type: text/plain
Message-ID: 8787KJKJ3K4J3K4J3K4J3.mail@example.net
Date: Thu, 02 Sep 2004 12:31:03 -0500
Hi, Joe. I got a lead on a source for discounts on
pharmaceuticals, and I thought you might be interested.
[...etc...]
--part1_13d.2e68ed54_boundary--
Le type not-spam fait donc désormais partie du
registre des types de rapport ARF.
L'article seul
RFC 6386: VP8 Data Format and Decoding Guide
Date de publication du RFC : Novembre 2011
Auteur(s) du RFC : J. Bankoski, J. Koleszar, L. Quillio, J. Salonen, P. Wilkins, Y. Xu (Google)
Pour information
Première rédaction de cet article le 11 novembre 2011
Le monde des formats vidéo est très hostile pour ceux qui apprécient la liberté et l'ouverture : formats privés, non documentés, contrôlés par une seule compagnie, plombé de brevets tous plus futiles les uns que les autres... Aujourd'hui, il est à peu près impossible de regarder une vidéo, quelle qu'elle soit, avec du logiciel entièrement libre, et sans enfreindre une centaine de brevets. Ce RFC documente un des très rares codecs vidéos ouverts, qui puisse être mis en œuvre dans du logiciel libre sans trop de crainte juridique. Il a été produit par Google, documenté pour l'IETF et se nomme VP8.
Lorsqu'on configure une machine utilisant du logiciel libre aujourd'hui, si on s'en tient strictement à ses principes, et qu'on refuse d'intégrer les sources de logiciel que Debian ou Ubuntu marquent comme non-libres, on n'arrivera pas à voir beaucoup de films... Même si le format du container vidéo est relativement ouvert, les techniques de compression ne le sont pas et on constate vite que son MPlayer ou son vlc n'arrivent pas à lire grand'chose. (C'est particulièrement vrai pour les films achetés légalement, pour lesquels l'usage de formats fermés sert de DRM. Les films partagés gratuitement sur le réseau réservent en général moins de mauvaises surprises.) Le problème de la personne qui produit le film est le manque de formats ouverts dans ce domaine. Le principal est Ogg (avec le codec vidéo Theora) mais les experts lui reprochent des performances en compression et décompression qui ne sont pas extraordinaires. Google prétend avoir une solution, son format VP8 (avec le format de container WebM), supposé bien meilleur (il a été développé à l'origine par On2). Mais utiliser un format spécifique à Google n'est pas mieux qu'utiliser un format spécifique à Adobe. Alors, Google a produit un RFC, soumis à l'IETF (en termes IETF, c'est une « soumission indépendante », pas le résutat d'un groupe de travail IETF) et qui devient donc un format ouvert, libre de la compagnie qui lui a donné naissance. Ce RFC inclut également une mise en œuvre de référence du décodeur, distribuée sous une licence libre (la BSD, cf. section 20.26).
La question des brevets est traditionnellement une de celles qui plombent le plus les projets de codecs ouverts. La section 20.27 décrit en détail la situation pour VP8. Google promet une licence gratuite d'exploitation de ses brevets pour toute implémentation de VP8. Mais il n'est pas clair, pour un non-juriste, si cela couvre la possibilité de versions ultérieures de VP8, qui ne seraient pas approuvées par Google. En attendant, pas mal de requins pourraient attaquer VP8. (Un bon article de synthèse est « Video codecs: The ugly business behind pretty pictures ».)
Ce RFC 6386 est essentiellement composé de code. VP8 est en effet défini par son implémentation de référence (la libvpx), le texte n'étant là que pour expliquer. Le RFC note bien (section 1) que, s'il y a une contradiction entre le code et le texte, c'est le code qui a raison (choix inhabituel à l'IETF). Avec ses 310 pages, c'est un des plus longs RFC existants. Je ne vais donc pas le traiter dans sa totalité, d'autant plus que les codecs vidéos ne sont pas ma spécialité.
Donc, en simplifiant à l'extrême, VP8 décompose chaque image d'un flux vidéo en une série de sous-blocs, chacun des sous-blocs étant composé de pixels. La compression d'un sous-bloc dépend des sous-blocs précédents, pour bénéficier de la redondance temporelle de la vidéo (sauf dans les films avec Bruce Willis, il y a relativement peu de changements d'une image à la suivante, et en général sur une partie de l'image seulement). Il y a aussi une redondance spatiale (des parties de l'image qui sont répétées, par exemple un grand ciel noir pour les scènes de nuit). La technique de compression se nomme transformée en cosinus discrète, mais VP8 utilise également à certains endroits une autre technique, la transformée de Walsh-Hadamard. VP8 ne permet pas de reconstituer exactement les pixels originaux, il compte sur la tolérance de l'œil humain (qui peut accepter certains changements sans tiquer).
Contrairement à son concurrent MPEG, VP8 encode et décode uniquement avec des nombres entiers et ne perd donc pas de précision dans les calculs en virgule flottante. Ces pertes peuvent parfois provoquer des effets surprenants, visibles à l'écran (rappelez-vous que, dans l'arithmétique en virgule flottante, il y a moins d'assertions vérifiables. Par exemple, 1 - x + x n'est pas forcément égal à 1).
La section 2 du RFC expose les grandes lignes du format :
utilisation de l'espace YUV en 4:2:0 8bits, c'est-à-dire
que chaque pixel dans les deux plans chromatiques (U et V) fait huit
bits et correspond à un bloc de quatre pixels dans le plan de lumière Y. Les
pixels sont ensuite transmis en lignes, de haut en bas, chaque ligne
étant transmise de gauche à droite. Les informations permettant le
décodage ne sont pas au niveau du pixel mais à celui de
blocs de pixels. Dans l'implémentation de référence, la description du
format se trouve dans le fichier d'en-tête
vpx_image.h.
Une fois comprimées, il y a deux types de trames dans un flux VP8 (section 3) : les intratrames (ou trames clés, ce que MPEG appelle les trames-I) sont complètes et n'ont pas besoin d'autres trames pour être décodées. La première trame envoyée est évidemment une intratrame. Et le deuxième type sont les intertrame (trames-P chez MPEG), qui codent une différence par rapport à la précédente intratrame, et aux autres intertrames arrivées entre temps. La perte d'une intertrame empêche donc de décoder les suivantes, jusqu'à l'arrivée de la prochaine intratrame, qui permettra au décodeur de repartir d'un état connu.
À noter que, contrairement à MPEG, il n'y a pas de trame-B, trame permettant d'indiquer le futur. En revanche, VP8 a des « trames en or » et des « trames de référence de secours » qui sont des intertrames contenant suffisamment d'informations pour permettre de reconstituer les quelques trames suivantes. Elles permettent à VP8 d'être plus tolérant aux pertes de trame (normalement, lorsqu'un perd une intratrame, il n'y a rien d'autre à faire qu'à attendre la suivante).
Le format des trames compressées est décrit en section 4. Un
en-tête (plus grand dans le cas des intratrames), et les données. Bon,
en fait, c'est un peu plus compliqué que cela car, au sein des données, les macroblocs ont
aussi leur en-tête. Pour décoder (section 5), le programme doit garder
quatre tampons YUV : la trame actuellement en
cours de reconstruction, la trame précédente (rappelez-vous que les
intertrames sont uniquement des différences par rapport à la trame
précédente, qu'il faut donc garder en mémoire), et les plus récentes
trames en or et de référence de secours. Le principe est simple (on
réapplique les différences à la trame de référence, obtenant ainsi la
trame originale), mais il y plein de pièges, dus par exemple à
l'abondance du contexte à maintenir (puisque le décodage dépend du
contexte en cours). Le code se trouve dans
dixie.c dans le RFC (l'implémentation de référence a été réorganisée et ce fichier n'y figure plus). Une façon de simplifier l'écriture d'un
décodeur est de commencer par ne programmer que le décodage des intratrames, avant
d'ajouter celui des trames intermdiaires. C'est d'ailleurs le plan que
choisit le RFC.
Le langage de l'implémentation de référence est le
C. Comme le note la section 6, c'est en raison
de sa disponibilité universelle et de sa capacité à décrire exactement
la précision des calculs qu'il a été choisi. Notez que le code C dans
le RFC n'est pas exactement celui de
l'implémentation de référence (qui est, elle, disponible en http://www.webmproject.org/code/). Plusieurs raisons à cela, notamment le fait que l'implémentation de
référence a été optimisée pour la performance, le code dans le RFC
pour la lisibilité, Mais les deux codes produisent le même
résultat. Rappelons enfin que VP8 n'utilise pas de
flottants, seulement des entiers.
Le code commence en section 7, avec le décodeur booléen. L'idée est que l'encodage est fait en produisant une série de booléens, avec pour chacun une probabilité d'être à zéro ou à un. Si la probabilité était de 0,5, aucune compression ne serait possible (il faudrait indiquer explicitement tous les booléens) mais ici, les probabilités sont souvent très éloignées de 0,5 (en raison des cohérences spatiales et temporelles du flux vidéo) et VP8 consomme donc moins d'un bit par booléen. Travailler sur bits étant typiquement peu efficace sur la plupart des processeurs, le code en section 7.3 les regroupe en octets.
Le reste du RFC est essentiellement composé de code C avec commentaires. Je saute directement à la section 19 / annexe A qui donne la liste complète des données encodées, Tous les objets manipulés par VP8 sont là.
Notez que le projet parent, WebM, utilise actuellement Vorbis pour l'audio (VP8 ne faisant que la vidéo). L'IETF a un projet de développement d'un codec audio, les détails figurent dans le RFC 6366.
Pour plus d'information, on peut consulter le site officiel du projet WebM qui contient entre autres une liste des outils disponibles. Pour le déploiement de WebM, on peut voir la page du Wikipédia anglophone. Une analyse (critique) de VP8 a été faite par Jason Garnett-Glaser.
Parmi les autres mises en œuvre de VP8, un cas curieux, un décodeur en JavaScript...
L'article seul
L'offre EC2 d'Amazon, des machines dans le nuage
Première rédaction de cet article le 9 novembre 2011
Je présente dans cet article le service EC2 d'Amazon, pas seulement parce que j'en suis assez content, mais aussi parce que cette offre ne m'a pas semblé claire du tout lorsque j'ai commencé à l'évaluer, puis à l'utiliser, et que cela vaut donc la peine d'écrire ce que j'ai compris.
L'article complet
Grande perturbation de l'Internet ce sept novembre...
Première rédaction de cet article le 7 novembre 2011
Ce lundi 7 novembre 2011, vers 14h05 UTC, grande perturbation de la Force. Des tas de destinations deviennent injoignables sur l'Internet...
Voici par exemple un des graphes montrant une brusque diminution du
trafic (les heures sont des heures locales, pas UTC) :  . À noter qu'un second
plantage, moins important, a eu lieu vers 15h30 UTC. On voit bien
l'effet des deux plantages sur ce graphique de DNSmon, qui montre l'impact de la
panne sur les serveurs DNS de
. À noter qu'un second
plantage, moins important, a eu lieu vers 15h30 UTC. On voit bien
l'effet des deux plantages sur ce graphique de DNSmon, qui montre l'impact de la
panne sur les serveurs DNS de
.fr (le serveur
c.nic.fr a été le plus impacté) :
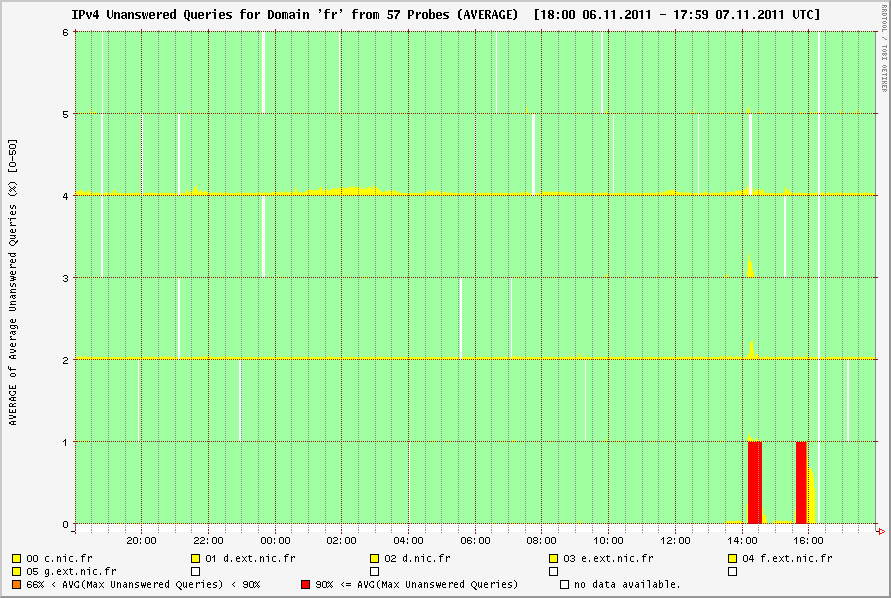 Les utilisateurs ne peuvent plus travailler et plein de gens se plaignent.
Les utilisateurs ne peuvent plus travailler et plein de gens se plaignent.
Le problème venait d'une annonce BGP amusante qui a planté (et fait redémarrer) certains routeurs Juniper. Voir les annonces Twitter d'Absolight et de Neo. Cela ressemble donc beaucoup à des problèmes comme celui de l'attribut 99. Même si c'était plutôt Cisco qui nous avait habitué à ce genre de crashes de grand style.
La bogue ne touchait apparemment que la gamme MX, en version 10.2, 10.3 et certaines 10.4 de JunOS ; Raphaël Maunier me dit que les plus basses versions non affectées sont les 10.4R6, 11.1R4 et 11.2R1). La bogue est apparemment enregistré chez Juniper sous l'identificateur PSN-2011-08-327 (j'ai mis un lien vers un pastebin car le rapport officiel est réservé aux clients de Juniper ; à tout hasard, je garde une copie de PSN-2011-08-327 ici).
Une bonne façon de voir d'un coup d'œil qu'il y a eu une
grande perturbation BGP est de regarder les
archives de RouteViews du mois en cours (merci à Jared Mauch
pour la bonne idée). Pour novembre 2011,
regardez les fichiers updates.20111107.1415.bz2 et
updates.20111107.1430.bz2 (le nom du fichier
donne l'heure en UTC), vingt fois plus gros que la normale et montrant
une avalanche de mises à jour BGP suite au crash de tant de routeurs.
C'est l'occasion de se rappeler que la résilience de l'Internet est un combat permanent. Ainsi, l'un des opérateurs affectés, Level 3 a une part du marché telle que ses pannes entraînent la coupure d'une bonne partie de l'Internet.
Quelques ressources utiles pour les administrateurs réseaux confrontés à ce genre de problèmes :
- La liste Outages et sa liste des observatoires (ce qui suppose qu'assez de liens Internet fonctionne pour qu'on l'atteigne...).
- L'Internet Health Report.
- Le Internet Traffic Report, dont j'ai extrait l'image ci-dessus qui montre la baisse de trafic.
Autres articles sur cette panne :
- Interview de Raphaël Maunier, de NeoTelecoms
- Contrairement à ce que prétend l'article de ZDnet, cela n'a rien à voir avec une mise à jour du logiciel des routeurs (cela serait amusant que tout le monde ait fait la mise à jour en même temps, mais le journaliste incompétent a confondu « BGP update » - mise à jour des tables de routage - avec « software update » - mise à jour du logiciel).
L'article seul
Fiche de lecture : Libres savoirs, les biens communs de la connaissance
Auteur(s) du livre : Ouvrage collectif coordonné par Vecam
Éditeur : C&F Éditions
978-2-915825-06-0
Publié en 2011
Première rédaction de cet article le 5 novembre 2011
Qu'est-ce qu'il y a de commun entre la paysanne mexicaine qui réclame de pouvoir faire pousser des semences de maïs de son choix, le parisien qui télécharge de manière nonhadopienne un film qu'il ne peut pas acheter légalement, la chercheuse états-unienne qui veut publier ses découvertes sans enrichir un parasite qui vendra très cher le journal scientifique, le programmeur brésilien qui développe du logiciel libre, et l'industriel indien qui veut fabriquer des médicaments moins chers ? Tous veulent pouvoir utiliser librement le savoir issu des communs. Les communs, ce sont tous les biens, matériels ou intellectuels, qui n'ont pas été capturés par des intérêts privés et qui sont gérés ensemble. Cet ouvrage collectif fait le tour de la question pour les communs immatériels, ceux dont l'usage par l'un ne prive de rien les autres. À travers 27 articles très divers, un vaste tour d'horizon de la question.
Car même si les cinq personnages cités plus haut n'en sont pas forcément conscients, leur lutte est la même. Depuis des millénaires, il existe des biens gérés en commun. Contrairement à ce que prétendent des textes de propagande comme le fameux « Tragedy of the commons » de Garrett Hardin (d'ailleurs en général utilisé de manière très simplifié par des gens qui ne l'ont pas lu), ces biens communs fonctionnent depuis très longtemps. Mais ils ont toujours eu à faire face aux tentatives d'appropriation par les intérêts privés, tentatives en général appuyées sur la force, comme dans le cas des fameuses enclosures. Les luttes d'aujourd'hui s'enracinent donc dans un très ancien héritage. Le phénomène n'a fait que s'accentuer avec le temps, le capitalisme ne supportant pas la concurrence d'autres systèmes.
Les biens immatériels représentent un cas particulier : contrairement au champ de l'article de Garrett Hardin, leur usage ne les épuise pas et ils peuvent être copiés. Comme le notait Thomas Jefferson, « Celui qui reçoit une idée de moi ne me prive de rien, tout comme celui qui allume une chandelle à la mienne ne me plonge pas dans l'obscurité ». Cette particularité du savoir, des biens communs immatériels, ôte donc toute légitimité à la notion de « propriété intellectuelle ». La propriété avait été conçue pour un monde de rareté et de ressources vite épuisées et c'est une pure escroquerie que de faire croire qu'elle peut s'appliquer au savoir et à la création.
D'autant plus que, à l'époque de Jefferson, la propagation du savoir, limitée par son support matériel, était lente et difficile. Aujourd'hui, des inventions comme l'Internet font de cette propagation illimitée de la connaissance, qui était purement théorique au dix-huitième siècle, une réalité quotidienne. Essayer de limiter la distribution et le partage des biens immatériels, comme le tente par exemple l'industrie du divertissement, c'est « comme si Faust se mettait à chercher un remède contre l'immortalité » (Stanislas Lem dans Solaris).
Revenons au livre « Libres savoirs ». Coordonné par Vecam, il est publié sous la licence Édition Équitable (mais pas encore disponible en ligne). Comme tous les ouvrages collectifs, les articles sont inégaux. Je recommande à mes lecteurs celui d'Adelita San Vicente Tello et Areli Carreón, « Mainmise sur les semences du maïs dans son berceau d'origine », sur la lutte des paysans mexicains pour que les semences mises au point par eux depuis des millénaires ne soient pas confisqués par des compagnies privées qui leur revendront très cher le droit d'utiliser des semences que leurs ancêtres avaient créées.
À noter que tout n'est évidemment pas simple dans le monde des communs, monde traversé par de nombreux débats. Ainsi, Anupam Chander et Madhavi Sunder dans l'article « La vision romantique du domaine public », proposent une vision plutôt critique, en estimant par exemple que la liberté d'accès au savoir profite surtout à ceux qui sont organisés et équipés pour l'exploiter, et que dans des cas comme celui des savoirs traditionnels, permettre leur accès sous une licence libre risquerait de favoriser uniquement les riches sociétés étrangères. (Je n'ai pas dit que j'étais d'accord, hein, juste que j'appréciais que ce livre ne contenait pas que des articles gentillets et unanimistes sur les beautés des biens communs.)
Autre difficulté sur le chemin des communs, leur adaptation à d'autres cultures. Un des points forts du livre est que les auteurs ne sont pas uniquement des gens issus des pays riches. Il y a donc une vraie variété de points de vue et l'article d'Hala Essalmawi « Partage de la création et de la culture », est un passionnant compte-rendu des difficultés, mais aussi des succès, rencontrés lors de l'adaptation des licences Creative Commons au monde arabe. Traductions difficiles, références historiques différentes (les enclosures ont été un traumatisme historique, qui pèse toujours dans la politique dans les pays anglo-saxons ; trouver une référence équivalente n'est pas forcément facile).
Le livre se conclut sur un amusant texte d'Alain Rey sur l'histoire et l'étymologie du terme « commun », ses multiples sens (en français, « commun » est péjoratif dans « ce livre est d'un commun » mais laudatif dans « travaillons en commun sur ce projet »), ses passages dans la politique (communisme)... Une autre façon de voir que le concept de « biens communs » est ancien, mais pas du tout dépassé. Le partage, la gestion commune des biens, sont aujourd'hui plus nécessaire que jamais pour lutter contre l'appropriation des biens par une poignée d'intérêts privés. « Communs » va donc être le drapeau à brandir contre les ACTA, OMPI, COV, et autres HADOPI.
Sinon, un autre bon article (bien plus détaillé) sur ce livre est « Les communs du savoir. Le laboratoire de la globalisation responsable ».
L'article seul
Le RIPE-NCC va-t-il nettoyer le marais des adresses IP ?
Première rédaction de cet article le 2 novembre 2011
À la réunion RIPE de Vienne, le 1er novembre, Axel Pawlik, directeur du RIPE-NCC a fait un exposé sur « What to do about IPv4 Legacy Address Space » ou que faire du marais, ces préfixes IP alloués il y a de nombreuses années, bien avant que les RIR n'existent. Il y a de nombreux préfixes dont le statut juridique et opérationnel est... peu clair.
Aujourd'hui, normalement, les choses sont précises : les RIR comme le RIPE-NCC allouent des adresses IP à leurs membres, les LIR (Local Internet Registry), qui sont typiquement des opérateurs ou des FAI. Cette allocation se fait suivant tout un tas de règles soigneusement mises par écrit et qui détaillent le statut juridique des adresses allouées. Le tout est ensuite publié par le RIR (on y accède typiquement via whois), pour que chacun puisse savoir qui gère quelle partie de l'Internet, et comment le contacter.
Ça, c'est aujourd'hui. Mais autrefois, avant que les RIR existent, à l'époque où journalistes, avocats et ministres ne connaissaient pas l'Internet ? Eh bien, les adresses IP étaient allouées aussi, mais on gardait moins de paperasse, c'était souvent informel, et les organisations qui s'en occupaient ont parfois disparu et parfois changé de métier. Par exemple, en Europe, il y avait souvent des NIR (National Internet Registry) qui servaient d'intermédiaire entre RIR et LIR, et qui ont tous abandonné cette activité. Les adresses qu'ils géraient sont donc parfois dans un limbe juridico-politique. Quant aux titulaires de ces adresses IP du lointain passé, il ont souvent oublié eux-même qu'ils en avaient, ou alors ils ne s'occupent pas des enregistrements qui moisissent dans les bases des RIR, sans être jamais mis à jour. Ce sont ces préfixes alloués dans les temps pré-RIR qu'on appelle le marais (the swamp) ou, plus gentiment, l'héritage (the legacy).
Voyons quelques exemples (tous sont publics et n'importe qui peut
les voir en utilisant un client whois sur le serveur du RIPE-NCC,
whois.ripe.net, ou encore via l'interface Web
dudit NCC, en https://apps.db.ripe.net/search/query.html). D'abord, le
préfixe 192.134.12.0/24. whois nous dit :
inetnum: 192.134.12.0 - 192.134.12.255 ... country: FR admin-c: KA774-RIPE tech-c: KA774-RIPE status: EARLY-REGISTRATION mnt-by: ERX-NET-192-134-12-MNT
Le statut EARLY REGISTRATION (alias ERX) est un des signes de
l'appartenance de ce préfixe au marais. Alloué dans un quasi-vide
juridique, 192.134.12.0/24 flotte... Le
mainteneur de l'objet (l'entité autorisée à apporter des
modifications) a été créé et mis automatiquement par le RIPE-NCC (les
anciens objets de la base RIPE n'avaient pas ce concept de
mainteneur). Est-il à jour, ainsi que les contacts ? whois nous dit :
address: FR ... e-mail: ASHK@frined51.bitnet
Une adresse de courrier électronique Bitnet, ça, c'est un collector... Ce réseau ne fonctionne plus depuis de longues années. Cela indique clairement que l'objet n'est pas géré. Il n'est pas non plus utilisé (aucune route n'y mène).
Autre exemple, 192.93.12.0/24, qui illustre un
autre problème. Lors de la création des RIR, il n'a pas été évident
d'affecter chaque objet de la base à un RIR et certains l'ont été deux fois. Ce préfixe
contient donc des informations issues des deux bases. Non protégé, il
a été automatiquement verrouillé par le RIPE-NCC, comme l'indique la
présence du mainteneur RIPE-NCC-LOCKED-MNT. Le
récupérer ne sera donc pas une mince affaire. Si on regarde le
contact, on constate des numéros de téléphone à huit chiffres, ce qui
indique bien l'absence d'entretien. Comme le précédent, ce préfixe ne
semble pas utilisé, il n'apparaît pas dans les tables de routage
publiques.
Enfin, dernier exemple, 192.93.232.0/24 est
alloué à une société qui semble avoir purement et simplement
disparu. (Il existe une société de même nom mais qui semble n'avoir
aucun rapport. Pour en être sûr, il faudrait une vraie enquête sur place, ce qui
dépasse les moyens et l'envie des RIR.)
Tous ces exemples concernent la France mais le marais est bien sûr présent dans tous les pays de l'OCDE (ceux qui ont été les premiers à se précipiter sur l'Internet et à obtenir des adresses IP).
Alors, après cette longue introduction, qu'a annoncé Axel Pawlik à
Vienne ? Le lancement d'une campagne pour, dans un premier temps,
améliorer l'enregistrement des informations sur ces préfixes du
marais. L'idée est d'encourager les titulaires de ces adresses à enfin
mettre à jour les informations contenues dans la base du RIR. Le
RIPE-NCC, après des années d'inaction sur ce sujet, a fait les choses
en grand, sorti une jolie brochure « Legacy space in the
RIPE-NCC service region », annoncé la création d'une équipe
dédiée, joignable par courrier à legacy@ripe.net,
et appelé sur
son site Web à nettoyer le marais.
Pourquoi cette soudaine activité ? Parce que l'épuisement des adresses IPv4 transforme le marais en or : ces adresses non gérées et souvent non utilisées deviennent tout à coup très valables. Comme l'a dit clairement Pawlik, mêlant la carotte (« Show you are a good Internet citizen ») et le bâton, ces adressses manifestement abandonnées sont des cibles tentantes pour des détourneurs... Pawlik n'a pas explicitement dit que ces adresses pourraient être récupérées par le RIPE-NCC un jour mais on peut penser que c'est une étape ultérieure possible.
Cela ne veut pas dire que tout soit rose si on « régularise » sa situation. Le RIPE-NCC, émanation des opérateurs réseaux, peut aussi en profiter pour « suggérer » qu'on confie désormais ses adresses à un LIR, transformant ainsi des adresses qui étaient, de fait, indépendantes du fournisseur en adresses qui « appartiendront » désormais à un opérateur.
Les conseils que je donnerai donc aux gens qui sont titulaires de préfixes IP du marais :
- D'abord et avant tout, faites un inventaire exact de vos ressources virtuelles comme les adresses IP. Beaucoup d'organisations découvrent par hasard (par exemple à l'occasion de l'arrivée d'un nouvel ingénieur) qu'elles sont les heureuses titulaires d'un /24.
- Ensuite, examinez bien les enregistrements dans la base RIPE. Sont-ils à jour ?
- Enfin, déterminez leur statut et, en fonction de celui-ci, décidez d'une stratégie pour les mettre à jour, limitant ainsi le risque qu'un détourneur ne vous les arrache. Prévoyez du temps, de l'aspirine et des tranquillisants. Lorsque toutes les informations dans la base (noms des personnes, adresses, numéros de téléphone) sont obsolètes, prouver que vous êtes bien le titulaire va être un parcours du combattant.
À noter que l'alerte avait déjà été donnée par
exemple sur la liste IP. Si vous voulez fouiller vous-même dans
la base du RIPE-NCC, un outil pratique est leur recherche plein
texte. La base est également téléchargeable en
FTP sur ftp.ripe.net:/ripe/dbase.
La question se pose aussi dans les autres régions et, en Amérique du Nord, la NSF (qui gérait le réseau académique états-unien qui formait une bonne partie de l'Internet à cette époque) affirme que les adresses IP allouées à cette époque appartiennent bien à leurs titulaires et que le RIR nord-américain, ARIN, créé bien après, n'a aucun droit de les réclamer.
L'article seul
Identifier un attaquant qui a triché sur son adresse IP source
Première rédaction de cet article le 2 novembre 2011
À la réunion OARC de Vienne, le 29 octobre 2011, Duane Wessels a présenté un très intéressant (et très technique) exposé « Tracing a DNS reflection attack » (voir ses transparents). L'exposé présente l'analyse d'une attaque déni de service utilisant les serveurs DNS de la racine. Son originalité est la découverte d'une méthode pour identifier l'origine de l'attaquant, alors même que ce dernier met des adresses IP mensongères dans ses paquets.
Cette méthode utilise le fait que la plupart des serveurs de la racine du DNS sont anycastés. Revenons d'abord sur l'attaque : il s'agissait d'une attaque par réflexion. Le méchant envoie une requête DNS à un serveur. Celui-ci répond à l'adresse IP (mensongère) que le méchant a mis dans la question... et frappe ainsi la victime (p. 3 des transparents).
Comment savoir qui est l'attaquant ? Dans les romans policiers, lorsque le méchant envoie une lettre, il laisse plein de traces dessus : empreintes digitales, ADN, type de papier utilisé, caractéristiques de l'imprimante... Rien de tel dans un paquet réseau. Les bits ne conservent pas l'ADN... Il faut donc suivre en sens inverse le flux de paquets, demandant à chaque opérateur d'analyser d'où vient l'attaque. C'est lent et cela dépend de la bonne volonté de tous les opérateurs sur le trajet.
Duane Wessels, en analysant l'attaque, a fait une observation. Les requêtes du pirate passent parfois subitement d'une instance d'un serveur racine à une autre. Par exemple, p. 17, on voit les requêtes vers le serveur K passer de l'instance du NAP à celle du LINX vers 0233, puis repasser au NAP vers 0240 (et re-changer encore par la suite). C'est le comportement normal de l'anycast : BGP a changé les routes (contrairement à ce qu'indique le transparent p. 19, ce n'est pas forcément suite à une panne) et l'attaque a suivi. L'idée de Duane a donc été : quel est le trafic qui a changé exactement au même moment ? Car ce trafic vient forcément du même point que l'attaque et a été routé pareil. Naturellement, au début, on trouve plein de suspects mais, sur des serveurs fortement anycastés comme ceux de la racine, la liste se réduit vite et on arrive à un seul AS (p. 22). Le trafic d'attaque vient donc de là (un hébergeur situé sur la côte Est des États-Unis).
À noter que les glitches BGP qui ont permis de repérer l'origine étaient accidentels. On pourrait imaginer d'appliquer cette technique volontairement, en modifiant les annonces BGP pour voir où le trafic se déplace, détectant ainsi l'attaquant qui se croyait bien caché.
L'article seul
RFC 6417: How to Contribute Research Results to Internet Standardization
Date de publication du RFC : Novembre 2011
Auteur(s) du RFC : P. Eardley (BT), L. Eggert (Nokia), M. Bagnulo (UC3M), R. Winter (NEC Europe)
Pour information
Première rédaction de cet article le 2 novembre 2011
Nourri de la vaste expérience de ses auteurs (tous chercheurs et tous ayant écrit des RFC), ce document essaie de combler une partie du fossé entre la communauté des chercheurs et la normalisation, en encourageant ces chercheurs à participer à l'IETF, et en leur expliquant ce à quoi ils doivent s'attendre.
L'Internet est bien issu d'un projet de recherche, ARPANET, et a ensuite intégré un bon nombre de résultats de recherche. Normalement, le monde académique devrait se sentir à l'aise dans celui de la normalisation Internet. Mais ce n'est pas toujours le cas. Le chercheur isolé peut même trouver que l'IETF est une organisation mystérieuse et que le processus de normalisation y est très frustrant. C'est pour guider ces chercheurs que ce RFC leur explique ce nouveau (pour eux) monde.
Optimisme scientiste ou simplement désir de plaire aux lecteurs issus de la recherche ? En tout cas, le RFC commence par prétendre que le développement de nouvelles techniques est dû à la recherche scientifique. Après ce remontage de moral, la section 1 explique pourtant aux chercheurs candidats à un travail de normalisation à l'IETF qu'ils ne doivent pas s'attendre à un chemin de roses. Une SDO a d'autres motivations qu'une université. Dans la recherche, le plus important est qu'une solution soit correcte. Dans la normalisation, les problèmes à résoudre sont ceux du monde réel et le caractère pratique et réaliste de la solution a autant, voire plus d'importance, que sa parfaite correction.
Ainsi, l'IETF adopte souvent des solutions dont les limites, voire les défauts, sont connus, simplement parce que des alternatives « meilleures » ne semblent pas déployable sur le terrain. De même, une bonne solution à un problème intéressant peut être écartée, si ce problème ne se pose tout simplement pas dans l'Internet. Enfin, la normalisation progresse souvent par étapes incrémentales, nécessaires pour un déploiement effectif, et cela peut être jugé peu apétissant par des chercheurs qui veulent s'attaquer aux Grands Problèmes.
On voit ainsi régulièrement des malentendus, où des chercheurs arrivent à l'IETF avec des idées trop éloignées du domaine de l'IETF, ou bien trop générales pour qu'un travail concret (l'IETF normalise des bits qui passent sur le câble...) puisse commencer, des idées qui ne peuvent pas être déployées dans l'Internet d'aujourd'hui, ou encore des idées qui résolvent des problèmes qui ne sont pas, ou pas encore, d'actualité. Sans compter des problèmes moins techniques comme l'hésitation à passer leur bébé à l'IETF (perdant ainsi le contrôle de son évolution), la constatation que la normalisation est très chronophage, ou simplement l'impression qu'on ne les écoute pas réellement.
Cela ne veut pas dire que les chercheurs ne doivent même pas essayer. Bien au contraire, ce RFC doit leur permettre de mieux déterminer si et comment ils peuvent présenter leur travail à l'IETF. Il vient en complément de documents plus généraux sur l'IETF, notamment le fameux Tao (RFC 4677)).
Donc, première question à se poser (en section 2) : est-ce que l'IETF est le bon endroit pour ce travail ? Le RFC suggère deux questions simples aux candidats. Si votre travail était pris en compte :
- Est-ce que l'Internet serait meilleur ?
- Quelles machines devraient être mise à jour ?
La première question est une variante du classique « Quel problème essayez-vous de résoudre ? » Après tout, il y a déjà eu des tas de travaux (dont certains normalisés à l'IETF) qui n'ont jamais été déployés. Il est donc raisonnable de se demander si ce travail apportera un bénéfice. Un travail de recherche, même remarquable, n'est pas forcément dans ce cas.
La seconde question, sur les machines à mettre à jour en cas d'adoption de la technique, a pour but de pointer du doigt les problèmes de déploiement. Les chercheurs ont facilement tendance à les ignorer, préférant partir d'une table rase. Dans l'Internet d'aujourd'hui, utilisé par des milliards de personnes et pour qui des investissements colossaux ont été faits, cette approche n'est pas réaliste. Il est donc crucial de se demander « Est-ce que cette nouvelle technique pourra être déployée, et à quel coût ? » Par exemple, est-ce que la nouvelle technique nécessitera de mettre à jour seulement les routeurs, seulement les machines terminales, ou les deux ? Cette analyse est d'autant plus complexe qu'il faudra prendre en compte, non seulement les protocoles, mais également les pratiques opérationnelles et peut-être même certains modèles de business, qui pourraient être remis en cause.
Une fois cette analyse faite, si la conclusion est que le travail semble à sa place à l'IETF, comment convaincre celle-ci de s'y mettre (section 3) ? Il faut trouver le bon endroit dans l'IETF. Celle-ci n'est plus le petit groupe de travail du début, où tout le monde était impliqué dans tous les protocoles. C'est désormais un gros machin, avec des dizaines de groupes de travail différents (eux-même regroupés en zones - areas) et il faut trouver le bon. S'il existe, il faut le rejoindre (l'IETF n'a pas d'adhésion explicite, rejoindre un groupe, c'est simplement s'abonner à sa liste de diffusion). Et s'il n'existe pas ?
Alors, il va falloir construire une communauté d'intérêts autour de la nouvelle proposition. Après tout, la normalisation, contrairement à la recherche, nécessite un accord large et il va donc falloir se lancer dans le travail de persuasion. Le RFC note que cet effort aura des bénéfices, notamment celui d'améliorer la proposition technique, grâce aux remarques et commentaire des participants à l'IETF. Cela oblige également à documenter le protocole d'une manière compréhensible pour les autres (on peut s'inspirer du RFC 4101). C'est à ce stade qu'on peut tenir des réunions informelles (les Bar BoF) pendant les réunions physiques de l'IETF.
Si on n'a pas trouvé de groupe de travail qui convenait, que faut-il faire ? « En créer un ! », vont crier beaucoup de gens. Bonne idée, mais il faut d'abord lire la section 3.4, qui explique les étapes préalables, celles citées dans le paragraphe précédent, et la tenue recommandée d'une BoF (cf. RFC 5434).
Une fois que tout ceci est fait, la situation semble idyllique. L'IETF a accepté de travailler sur la nouvelle technique, un groupe de travail a été créé, il suffit d'attendre tranquillement son résultat ? Mais non. Comme le rappelle la section 4, il faut continuer à suivre le projet. Il faut prévoir pour cela des efforts importants, du temps et de la patience. Les gens qui n'ont jamais travaillé avec une SDO sont presque tous étonnés de la longueur et de la lourdeur du processus. Tout groupe de travail ne produit pas forcément de RFC et le succès va dépendre d'un travail continuel. Bien qu'en théorie, tout puisse se faire à distance, le RFC rappelle qu'une présence physique aux réunions va, en pratique, augmenter les chances de réussite (c'est comme pour les élections, il faut serrer des mains).
Pire, on a parfois l'impression que le processus s'enlise. L'IETF n'a pas de votes et encore moins de chefs qui décideraient tout. Un consensus relatif est nécessaire pour à peu près tout, et l'IETF n'est pas connue pour sa capacité à prendre des décisions... Bref, notre RFC prévient les candidats : deux ans au moins, depuis la création du groupe de travail. Si le projet de recherche qui a donné naissance à la nouvelle technique dure trois ans, cela veut dire qu'il faut commencer le travail de lobbying à l'IETF dès la première semaine du projet, si on veut que la nouvelle technique soit normalisée avant la fin du projet ! Il vaut donc mieux se préparer d'avance à ce que le projet ne soit pas complété par l'auteur lui-même, et soit terminé par d'autres.
Et c'est si tout se passe bien. Mais il y a parfois des chocs de cultures qui ralentissent le projet. Par exemple, le monde de la recherche privilégié la paternité (« l'algorithme X, décrit par Dupont et Durand dans leur article de 2008 ») alors que l'IETF privilégie le travail collectif. Une norme n'appartient pas à son auteur mais à toute la communauté. Il est donc préférable d'avoir une mentalité très ouverte avant de commencer.
Autre point sur lequel le choc des cultures est fréquent : la mise en œuvre de l'idée dans du vrai logiciel qui tourne. L'IETF accorde une grande importance à ce logiciel (le running code), qui montre que l'idée est viable, et que quelqu'un y a cru suffisamment pour dédier une partie de son précieux temps à sa programmation. C'est encore mieux si le programme connait un début de déploiement (le RFC suggère, pour un protocole réseau, d'essayer de le faire adopter dans le noyau Linux, par exemple). Si ces règles semblent contraignantes, il faut se rappeler qu'elles sont dues à de nombreuses expériences douloureuses, de protocoles déployés uniquement sur le papier, et qui avaient donc fait perdre du temps à tout le monde.
Pour rendre ces conseils plus concrets, le RFC contient une section d'exemples, la 5. On y trouve des résumés de l'incorporation dans le processus IETF de deux protocoles issus de la recherche « académique » :
- Multipath TCP, issu du projet Trilogy, présenté à l'IETF pour la première fois en 2008, a donné naissance à un groupe de travail, MPTCP en 2009, dont les RFC ont été publiés en 2011.
- Autre enfant de Trilogy, Congestion exposure a été présenté en 2009, mais le groupe de travail CONEX n'a été créé qu'en 2010, et avec une charte aux ambitions réduites.
L'article seul
RFC 6415: Web Host Metadata
Date de publication du RFC : Octobre 2011
Auteur(s) du RFC : E. Hammer-Lahav, B. Cook
Chemin des normes
Première rédaction de cet article le 1 novembre 2011
Ce court RFC spécifie une convention qui
permet à un client Web de récupérer sur un
serveur une description formelle de
métadonnées sur le site servi (par exemple
l'auteur du site Web, ou bien la licence du
contenu servi). Cela se fait en mettant ces métadonnées au format
XRD dans une ressource nommée
/.well-known/host-meta.
Vous pouvez voir le résultat dans le /.well-known/host-meta de mon site, très inspiré de l'exemple
de la section 1.1 du RFC. Il est vraiment minimal et
n'inclut que des métadonnées globales (le format
XRD permet également de s'en servir pour des
métadonnées locales à une ressource, cf. section 4.2).
Notez que le vocabulaire peut être trompeur. Le RFC 3986 parle de host pour le
example.com de
http://example.com/truc/machin mais ce terme ne
désigne pas du tout une machine. Finalement, le terme marketing flou
de « site » est encore le moins mauvais.
Ce nouveau nom de host-meta a donc été le
premier à être enregistré (cf. section 6.1) dans le registre des ressources
bien connues qui avait été créé par le RFC 5785. (Deux ou trois autres sont venus juste après, et le
RFC 5785 a été depuis remplacé par le RFC 8615.)
Pour le client, par exemple un navigateur Web, récupérer les
métadonnées consiste juste donc à faire une requête
GET sur le nom
/.well-known/host-meta (section 2). Il obtient en échange un
fichier XML au format
XRD, servi avec le type
application/xrd+xml.
Le contenu du document est détaillé dans la section 3. Ce
vocabulaire XRD a été normalisé par
OASIS et sert à beaucoup de choses très
compliquées. Mais l'accent est mis ici sur son utilisation pour
fournir des métadonnées. Tout en gardant le modèle de données de XRD,
le serveur peut envoyer du XML (la syntaxe
habituelle) ou du JSON. Cette dernière syntaxe
est normalisée dans l'annexe A, sous le nom de JRD. On peut l'obtenir
(n'essayez pas sur mon site, il n'est pas configuré pour cela) en
utilisant la négociation de contenu HTTP (champ Accept:
application/json dans la requête) ou en demandant
/.well-known/host-meta.json au lieu de simplement /.well-known/host-meta.
Qui utilise ou va utiliser ces métadonnées ? Pour l'instant, les moteurs de recherche ne semblent pas y accéder mais cela viendra peut-être bientôt (Yahoo et Google ont annoncé travailler sur le sujet). La communauté WebFinger (RFC 7033) est également très impliquée dans ce projet.
Sinon, ce choix d'utiliser une ressource avec un nom spécial (le préfixe
/.well-known est normalisé dans le RFC 8615) est dû au fait qu'un serveur n'a pas
d'URI qui le désigne globalement et on ne peut
donc pas utiliser les techniques qui attachent les métadonnées à une
ressource (par exemple les en-têtes HTTP comme
l'en-tête Link: du RFC 8288), sauf à utiliser des trucs contestables comme de
considérer que /, la racine du site, désigne tout
le site.
L'article seul
RFC 6394: Use Cases and Requirements for DNS-based Authentication of Named Entities (DANE)
Date de publication du RFC : Octobre 2011
Auteur(s) du RFC : R. Barnes (BBN Technologies)
Pour information
Réalisé dans le cadre du groupe de travail IETF dane
Première rédaction de cet article le 28 octobre 2011
Le projet DANE (DNS-based Authentication of Named Entities, anciennement KIDNS - Keys In DNS), vise à améliorer et/ou remplacer les certificats X.509 utilisés dans des protocoles comme TLS (RFC 5246). Ces certificats souffrent de plusieurs problèmes, le principal étant qu'une Autorité de Certification (AC) malhonnête ou piratée peut créer des certificats pour n'importe quelle entité, même si celle-ci n'est pas cliente de l'AC tricheuse. C'est ce qui s'est produit dans les affaires Comodo et DigiNotar et ces deux affaires ont sérieusement poussé aux progrès de DANE. Ce premier RFC du groupe de travail DANE établit les scénarios d'usage : quels problèmes veut résoudre DANE et selon quels principes ?
Revenons d'abord sur le fond du problème (section 1 du RFC) : lors de l'établissement
d'une session TLS (par exemple en HTTPS), le
client se connecte à un serveur dont il connait le nom (par exemple
impots.gouv.fr, cf. RFC 6125), le
serveur (et, plus rarement, le client) présente un
certificat numérique à la norme X.509 (bien
qu'un certificat PGP soit aussi possible,
cf. RFC 6091). Ce certificat suit le profil
PKIX, normalisé dans le RFC 5280, un sous-ensemble de X.509. Comme ce certificat peut avoir
été présenté par un homme du milieu qui a
intercepté la session (par exemple en jouant avec
BGP ou OSPF), il faut l'authentifier,
sinon TLS ne protégerait plus que contre les attaques
passives, laissant ses utilisateurs à la merci des attaques
actives. Cette authentification se fait typiquement aujourd'hui en
vérifiant que le certificat a été signé par une des plusieurs
centaines d'AC qui se trouvent dans le magasin de
certificats de n'importe quel navigateur Web. Le point important, et qui est l'une des deux
principales faiblesses de X.509 (l'autre étant son extrême
complexité), est que n'importe laquelle de ces centaines d'AC peut
signer un certificat. Ainsi, dans l'affaire
DigiNotar, une AC néerlandaise était piratée, le pirate lui
faisait générer des certificats pour *.google.com
ou *.gmail.com
(alors que Google n'est pas du tout client de
DigiNotar) et ces certificats sont acceptés par tous les
navigateurs. Le pirate a vendu ou donné les clés privées de ces
certificats au gouvernement iranien, qui n'a
plus eu qu'à monter une attaque de l'homme du
milieu (facile lorsqu'on est un état policier et qu'on
contrôle tous les FAI du pays) pour détourner les utilisateurs vers un faux
Gmail, qui présentait un certificat
acceptable. La dictature intégriste pouvait alors lire les messages
et emprisonner ou tuer les opposants. (Le fait que l'attaque venait
d'Iran est établi par les requêtes OCSP des
victimes. Cf. le rapport sur l'opération Tulipe
Noire.)
Identifiée depuis longtemps (mais niée par le lobby des AC ou par
l'UIT, à l'origine de la norme X.509), cette
vulnérabilité a mené au projet DANE. L'idée de base est qu'introduire
un intermédiaire (l'AC) est en général une mauvaise idée pour la
sécurité. Pour reprendre l'exemple ci-dessus, il vaudrait mieux
permettre à Google de prouver sa propre identité. Comme quasiment
toutes les transactions sur l'Internet commençent par une requête
DNS, pourquoi ne pas utiliser la zone DNS
google.com pour y mettre le certificat ? L'idée
est ancienne, mais elle ne suscitait guère d'intérêt tant que le DNS
lui-même n'était pas un tant soit peu sécurisé. Le déploiement rapide
de DNSSEC, à partir de
2009, a changé la donne : mettre des clés
cryptographiques ou des certificats dans le DNS devient réaliste. D'où
la création, en février 2011, du groupe de travail DANE de
l'IETF, chargé de trouver une technique de
sécurité qui marche.
Ce RFC ne donne pas encore de solution (au moment de sa parution, celle-ci est très avancée et a des chances sérieuses d'être publiée en 2012). Il explique les scénarios d'usage, pour aider à évaluer la future solution. Pour décrire ces scénarios, on recourt évidemment aux personae traditionnels :
- Alice gère le serveur
alice.example.com, - Bob, le client, se connecte à ce serveur,
- Charlie est l'AC,
- Trent est un émetteur de certificats mais qui n'est pas dans les magasins de certificats d'AC typiques.
Trois scénarios sont ensuite décrits dans la section 3, le œur de ce RFC :
- « Contrainte sur l'AC » (dit aussi « type 0 »),
- « Contrainte sur les certificats » (« type 1 »),
- « Certificats locaux » (« type 2 »),
Dans les deux premiers cas, DANE ne fait qu'ajouter de la sécurité à X.509 et on a toujours besoin de l'IGC actuelle. Le troisième est le plus novateur, permettant de remplacer complètement l'IGC, et ne gardant de X.509 que son format de certificats. (Notez que ces trois scénarios ne se retrouvent pas exactement dans le RFC 6698 sur le protocole qui a quatre types et non pas trois.)
Voyons d'abord le premier scénario (section 3.1) , les contraintes sur l'AC. Dans
un cas comme celui des piratages de Comodo ou de DigiNotar, Alice, qui
est cliente d'une autre AC, Charlie, est inquiète du risque d'un faux
certificat pour alice.example.com, émis par l'AC
voyoute. Elle voudrait dire aux visiteurs de
https://alice.example.com/ que les seuls
certificats légitimes sont ceux émis par Charlie. En d'autres termes,
elle voudrait que la vérification du certificat de son serveur parte
du certificat de Charlie, pas de n'importe quel certificat d'AC du
magasin.
Notez que, si Alice dispose d'un tel système, elle peut aussi s'en servir vis-à-vis de Charlie. Lorsqu'elle demande un certificat à ce dernier, il pourrait vérifier qu'Alice l'a bien listé comme AC.
Donc, Alice va mettre dans le DNS un enregistrement qui dit « je suis cliente de Charlie ». Cet enregistrement doit-il être sécurisé par DNSSEC ? La question est toujours très discutée au sein du groupe DANE. A priori, DNSSEC n'est pas impératif puisque cet enregistrement DNS n'est qu'une sécurité supplémentaire : le X.509 traditionnel fonctionne toujours en dessous. D'un autre côté, cette sécurité supplémentaire est très faible si on ne met pas DNSSEC : un attaquant qui peut monter une attaque de l'Homme du Milieu pour détourner vers son propre serveur peut probablement aussi supprimer les enregistrements DANE au passage. Notons aussi que le fait d'exiger la validation X.50 comme avant limite les possibilités d'attaque par un registre DNS. Avec le type 0 (contrainte sur l'AC), un attaquant devrait contrôler à la fois l'enregistrement DNS et l'Autorité de Cértification.
Second scénario, la contrainte sur le certificat (section 3.2),
alias type 1. Alice est cliente de Charlie mais se demande si Charlie
ne va pas émettre d'autres certificats pour
alice.example.com, par exemple parce que les
machines de Charlie ont été piratées. Elle voudrait donc indiquer aux
visiteurs de https://alice.example.com/> que seul
tel certificat est valable. Alice va donc mettre le certificat (ou un
condensat cryptographique de celui-ci) dans le DNS. Comme avec le type
0, toute la validation classique de X.509 est ensuite appliquée. Dans
ce mode, DANE ne fait qu'ajouter une vérification supplémentaire.
Bien plus « disruptive » est la possibilité de se passer complètement des AC et de dire dans le DNS « voici le certificat à utiliser », sans qu'il doit validé par d'autres mécanismes que DNSSEC. Cette possibilité (section 3.3), dite type 2, est l'équivalent des certificats auto-signés actuels, mais avec possibilité de les vérifier (grâce à DNSSEC). Alice se passe alors complètement de Charlie. (Notez que le cas où Alice est cliente de Trent est équivalent, le certificat de Trent n'étant quasiment dans aucun magasin. Alice va alors publier dans le DNS le certificat de Trent et non le sien.)
Notez que ce mécanisme n'empêche pas Bob d'avoir sa propre politique de validation. On pourrait imaginer un Bob suspicieux vis-à-vis de DNSSEC qui n'accepterait que les enregistrements DANE de type 0 ou 1. Ou un Bob qui aurait une liste noire des certificats à qui il ne fait pas confiance, DANE ou pas DANE.
Cette fois, avec le type 2, DNSSEC est absolument
indispensable. Sans lui, il n'y a plus aucune validation du
certificat. Ne publiez donc pas d'enregistrements de type 2 avant
d'avoir vérifié que DNSSEC était correctement déployé et que vous le
maîtrisez parfaitement. Pour la même raison, le type 2 est celui qui
met le plus de responsabilités chez les opérateurs DNS. Si ceux-ci
trahissent ou sont piratés, tout le système est en danger. Mais
rappelez-vous que, contrairement à ce qui se passe pour X.509, le
risque est uniquement dans les prestataires que vous choisissez. Si
vous choisissez d'utiliser un nom de domaine en
.org, vous savez
qu'Afilias peut tout faire rater, mais que ni
l'AFNIC, ni CNNIC n'ont
ce pouvoir. Alors qu'avec X.509, même en choisissant soigneusement son
AC, on peut être victime de n'importe quelle autre AC, qu'on n'a pas
choisi. Donc, conseil pratique, choisissez bien vos prestataires
(registre DNS, bureau d'enregistrement,
hébergeur DNS, etc).
Mais il est clair que DANE donne plus de responsabilité (on peut même dire de pouvoir) aux acteurs du DNS. Ce point est souvent à la base de la plupart des critiques de DANE.
Autre point à garder en tête lorsqu'on évalue la sécurité de DANE : aujourd'hui, avec X.509, le contrôle de la zone DNS donne déjà souvent accès à des certificats (bien des AC ne font pas d'autres vérifications que l'envoi d'un courrier avec un cookie, ou la publication d'un certain enregistrement).
Voilà, vous connaissez l'essentiel sur DANE. la section 4 couvre toutefois d'autres points, moins centraux, sous forme d'une liste de souhaits pour le futur protocole :
- Capacité à gérer des certificats différents pour une même machine, pour des services tournant sur des ports différents (par exemple un serveur HTTP et un serveur IMAP).
- Pas de possibilité d'attaque par repli.
- Possibilité de combiner plusieurs assertions (par exemple de type 1 et 2, la première servant pour les clients qui refusent de croire au type 2 et qui tiennent à faire une validation X.509 classique).
- Le moins de dépendances possibles, à part bien sûr celle sur DNSSEC.
- Le moins d'options possibles, pour faciliter l'analyse de sécurité (IPsec avait été beaucoup critiqué pour le trop grand nombre de choix qu'il offrait).
Le protocole qui met en œuvre ce cahier des charges a été normalisé en août 2012 dans le RFC 6698.
Pour ceux qui souhaitent approfondir le sujet, j'ai fait un exposé sur la question (avec article détaillé) en novembre 2011 aux JRES à Toulouse.
L'article seul
RFC 6392: A Survey of In-network Storage Systems
Date de publication du RFC : Octobre 2011
Auteur(s) du RFC : R. Alimi (Google), A. Rahman (InterDigital Communications), Y. Yang (Yale University)
Pour information
Réalisé dans le cadre du groupe de travail IETF decade
Première rédaction de cet article le 26 octobre 2011
Cette intéressante étude des systèmes de stockage de données en ligne (le RFC n'utilise pas le terme de cloud, pourtant bien plus vendeur) fait le tour des principales solutions d'aujourd'hui. Son but est de préparer le travail ultérieur du groupe de travail IETF DECADE, dont le rôle est de normaliser une architecture pour l'accès au stockage en ligne, notamment pour le pair à pair. Ce RFC, le premier produit par DECADE, étudie l'offre existante, afin de voir dans quelle mesure elle est réutilisable pour DECADE.
Notons que tous les systèmes existants n'y sont pas : l'accent a été mis sur une sélection de systèmes typiques couvrant à peu près toutes les variantes possibles d'un tel service. C'est ainsi que, par exemple, Swift/OpenStack n'y figure pas. Par contre, le plus célèbre, le S3 d'Amazon est présent. Certains de ceux qui y figurent sont très expérimentaux, peu déployés, mais ont été ajoutés parce qu'ils illustrent un point important.
Il existe des tas de raisons pour stocker ses données dans le nuage. Cela peut être pour y accéder de partout, depuis n'importe quelle machine. Ou bien cela peut être pour rapprocher les données des utilisateurs. Si on distribue du contenu en pair à pair, il vaut mieux qu'il soit déjà dans le nuage, plus près des téléchargeurs, que sur une machine à la maison, connectée en ADSL, où le coût du dernier kilomètre à franchir est élevé.
La section 2 brosse un panorama historique du stockage en
ligne. Par exemple, le goulet d'étranglement que représente le gros
site Web, lorsqu'il a de très nombreux utilisateurs, a été
partiellement levé avec l'introduction des
CDN. Ceux-ci dupliquent le contenu statique des
sites Web, et le rapprochent des utilisateurs, en plaçant des copies
chez les principaux FAI. Mais les CDN ne sont
pas accessibles à l'utilisateur normal. Si je voulais accélérer le
temps de chargement des pages de
http://www.bortzmeyer.org/, je ne pourrais
certainement pas monter un CDN moi-même, un tel travail nécessite des
moyens financiers et administratifs hors de ma portée.
Le pair à pair a ensuite fourni d'autres possibilités. Si on utilise les machines de tout le monde pour distribuer du contenu, pourquoi ne pas également s'en servir pour améliorer l'accès au contenu par une réplication et une copie proche des autres pairs ? Plusieurs systèmes de « caches P2P » ont ainsi été développés pour accélérer le pair à pair (cf. section 4.12). Malheureusement, tous sont spécifiques à une application particulière et ne peuvent donc pas servir aux nouvelles applications. Le monde du pair à pair évoluant vite, il ne peut donc pas bénéficier d'une infrastructure de stockage existante. Le but de DECADE est justement de permettre la création de cette infrastructure.
Pour pouvoir étudier de manière systématique les techniques existantes, la section 3 du RFC liste les composants d'une solution de stockage en ligne. Chaque technique sera alors décrite pour chacun de ces composants :
- Une interface d'accès aux données, permettant les opérations de base, notamment lire et écrire,
- Une interface de gestion des données, permettant des choses comme la suppression d'un bloc de données,
- Une interface de recherche permettant de s'y retrouver dans ses données,
- Un mécanisme de contrôle d'accès, permettant d'avoir des données publiques, des données restreintes à certains utilisateurs (par exemple seulement depuis certains pays), des données privées (accessibles uniquement à des clients identifiés, par exemple après paiement). L'accès peut dépendre de l'opération (lecture pour tous mais écriture seulement pour certains).
- Un mécanisme de découverte des mécanismes d'accès (le mode d'emploi du service),
- Un mode de stockage : les données sont-elles des fichiers (organisés en répertoires hiérarchiques), des objets (contrairement aux fichiers, ils ne sont pas organisés), ou simplement des blocs d'octets, comme le propose le disque dur local ?
Sur la base de ce découpage en composants, on peut décrire les systèmes existants (section 4, mais rappelez-vous que le RFC ne prétend pas les présenter tous et que je n'ai pas repris ici tous ceux listés dans le RFC). Notez que l'ordre de la présentation est celui du RFC, même s'il peut sembler incohérent. D'autre part, un bon nombre des descriptions ressemblent à du copier-coller depuis les descriptions officielles (y compris dans leur côté marketing).
Commençons par le plus connu, Amazon S3. Les utilisateurs créent des containers, les seaux (buckets) puis y déposent des objets. Les accès se font en REST.
Pour montrer les capacités de S3, testons un peu avec un client
Unix en ligne de
commande, s3cmd. On lui indique les
clés avec s3cmd --configure puis on peut créer
un seau (le nom est hiérarchique car un nom de seau doit être unique entre tous les utilisateurs ; on peut aussi préfixer avec l'ID Amazon) :
% s3cmd mb s3://org-bortzmeyer-essais
(où mb signifie make bucket,
créer un seau.)
Puis on peut mettre un fichier dans ce seau :
% s3cmd put tartiflette1.jpg s3://org-bortzmeyer-essais /home/stephane/Downloads/tartiflette1.jpg -> s3://org-bortzmeyer-essais/tartiflette1.jpg [1 of 1] ... 35267 of 35267 100% in 0s 37.21 kB/s done
Il est ensuite possible de récupérer cet objet, par exemple depuis une autre machine :
% s3cmd get s3://org-bortzmeyer-essais/tartiflette1.jpg ... s3://org-bortzmeyer-essais/tartiflette1.jpg -> ./tartiflette1.jpg [1 of 1] 35267 of 35267 100% in 0s 74.04 kB/s done
On a donc vu les deux commandes les plus importantes,
put et get (lire et écrire
des objets).
S3 est devenu très populaire, entre autres en raison de sa simplicité. Pas d'espace de nommage hiérarchique, pas de possibilité de modifier les données existantes, accès en REST... L'interface d'accès permet de lire et d'écrire (les deux opérations illustrées plus haut), on peut détruire les objets, on peut lire le contenu d'un seau (c'est la seule possibilité de recherche), S3 fournit des mécanismes de contrôle d'accès riches, il n'y a pas de vraie découverte (l'utilisateur doit connaître l'URL où envoyer les requêtes, dans l'exemple ci-dessus, on utilise celle par défaut), et enfin, on l'a vu, S3 stocke des objets (aucun mécanisme de dossiers ou répertoires).
Il existe d'autres systèmes analogues à S3 comme Dropbox.
Un exemple d'un service très différent est le BranchCache de Windows, assez répandu en raison de la diffusion de ce système d'exploitation. Les accès ne sont pas explicites comme avec S3, BranchCache vise à stocker et récupérer les données automatiquement dans un cache. Il y arrive en se mettant sur le trajet des requêtes HTTP et SMB. Il intercepte la requête normale, et accède au fichier depuis le cache, si c'était une opération de lecture et que le fichier était déjà disponible.
Autre exemple très différent de S3, le CNF (Cache-and-Forward), une architecture de recherche visant à doter les réseaux d'un mécanisme efficace d'accès aux données. Dans CNF, les routeurs ne sont plus simplement des routeurs qui opèrent au niveau 3 mais des moteurs d'accès des données (store and forward) qui font suivre les requêtes d'accès et gardent le résultat localement, pour les accès ultérieurs. Le contenu très populaire est ainsi petit à petit copié dans les routeurs les plus proches. Un mélange de Usenet et de cache opportuniste (tout le contenu n'est pas copié, contrairement à Usenet ou aux CDN, seulement celui qui est demandé).
Plus dans l'idée d'un accès explicite aux données, le standard CDMI vise à résoudre un problème récurrent du cloud : l'absence de normes pour l'accès aux données, qui font qu'une fois choisi un fournisseur, on en est prisonniers. Si vous bâtissez votre service autour d'un accès à S3, vous ne pouvez plus quitter Amazon. Certes, l'interface de S3 est tellement populaire qu'il existe désormais des offres compatibles (hébergées, ou bien à construire soi-même comme celle d'Eucalyptus) mais ces offres sont à la merci d'un changement unilatéral de l'interface S3 par Amazon. CDMI est donc une tentative pour concevoir et populariser, au sein d'un consortium industriel, la SNIA, une interface standard. Elle ressemble dans ses principes à S3 et repose sur les modes actuelles (REST et JSON).
Comme CDMI est indépendant d'un vendeur particulier, et repose sur des protocoles simples et bien connus comme HTTP, elle est une approche tentante pour le groupe DECADE.
J'ai déjà parlé des CDN. Ils représentent aujourd'hui une des approches les plus populaires, d'accès aux données en ligne. Un bon tour d'horison complet des CDN figure dans « A Taxonomy and Survey of Content Delivery Networks » de Pathan, A.K. et Buyya, R. Le principe est de copier à l'avance le contenu vers des serveurs situés chez les FAI et d'utiliser divers trucs (par exemple fondés sur le DNS) pour que les utilisateurs soient redirigés vers ces serveurs. Le plus connu des CDN est Akamai mais il en existe bien d'autres comme Limelight ou CloudFront. Pour DECADE, l'intérêt des CDN est que c'est une technique très répandue et éprouvée. Mais elle nécessite une relation d'affaires existante entre l'opérateur du CDN et le fournisseur de contenu (contrairement aux caches classiques).
Le CDN ne fournit typiquement d'accès qu'en lecture (l'écriture est réservée au fournisseur de contenu, via le mécanisme que lui offre l'opérateur du CDN).
Plus proche du CNF, le système DTN vise à créer un environnement adapté aux cas difficiles, notamment aux missions spatiales. Dans ces cas où la connectivité est très intermittente (une seule tempête solaire peut tout interrompre pendant des semaines), et où les délais sont énormes, les protocoles TCP/IP classiques ne conviennent plus. D'où le DTN, normalisé dans le RFC 4838, une architecture store and forward qui ressemble davantage à UUCP.
Le DTN repose sur le protocole Bundle (RFC 9171), qui permet de stocker les données en attendant que le destinataire soit à nouveau disponible. Bien sûr, IP est lui aussi store and forward dans la mesure où le routeur garde le paquet en mémoire avant de le passer au routeur suivant. Mais le temps de rétention des données dans IP est typiquement de quelques milli-secondes au maximum, alors qu'il atteint couramment plusieurs jours dans Bundle, imposant le recours à un stockage persistant (au cas où le routeur redémarre). Contrairement à IP, où le routeur a le droit de jeter des paquets, Bundle est plus proche du courrier électronique : le routeur doit prendre soin des données jusqu'à ce qu'il ait pu les transmettre. Il n'est donc pas exagéré de l'inclure dans cette liste des services de stockage en ligne.
Dans la catégorie futuriste, une autre famille de candidats intéressants est celle qu'on va appeler, pour simplifier. les « réseaux fondés sur les objets nommés » (c'est le nom de la première conférence scientifique sur le sujet). C'est une vaste famille, comprenant uniquement des projets de recherche fondamentale, qui ont en commun le fait que toute l'architecture du réseau repose sur des objets de données, ayant un nom, et que le réseau est conçu pour accéder rapidement et de manière sûre à ces objets. Cette famille privilégie donc l'accès au contenu. On y trouve des systèmes comme CCN, ou comme NDN (Named Data Networking) et NetInf (Network of Information), traités plus en détail dans ce RFC.
NDN est un tel système. Le réseau gère des objets nommés et signés cryptographiquement. Les routeurs qui transmettent ces objets ont la possibilité de les garder en cache. Les objets les plus demandés vont donc avoir plus de chance de se retrouver dans un cache proche, réalisant ainsi automatiquement ce que les CDN font manuellement. Comme les autres propositions de la famille Name-oriented networking, tout repose sur l'idée que « data delivery has become the primary use of the network ».
NetInf reprend les mêmes affirmations minitéliennes et y ajoute des fausses explications sur ce que représente un URL (le deuxième champ d'un URL, après le plan, n'identifie pas une machine).
Plus sérieux, OceanStore est une architecture où un ensemble de machines coopèrent en mettant en commun des espaces de stockage. OceanStore met l'accent sur la résilience et l'auto-organisation. Son intérêt pour DECADE est surtout cette capacité à résister aux pannes, et même à une certaine proportion de participants malhonnêtes (qui modifieraient les données, ou bien les effaceraient). OceanStore fournit une interface permettant lecture et écriture des objets mais reste encore très expérimental.
Un des domaines où il y a eu le plus d'utilisations du stockage en ligne est évidemment le partage de photos. Une section est donc consacrée à ce cas particulier, où on voit apparaître des noms connus comme Flickr ou ImageShack, sans compter des services qui, sans être spécialisés dans les photos, sont néanmoins largement utilisés pour cela, comme Tumblr. Une particularité de ces services est l'accent mis sur les fonctions de recherche (qui sont absentes de beaucoup de services de stockage), notamment par le biais d'étiquettes attachées aux photos. On peut ainsi retrouver, parmi des myriades de photos, celles qui concernaient saint-quentin-en-yvelines ou lascaux. Ces services ont en général également des moyens d'organisation des photos (en « albums » ou « galeries », analogues à ce que fournit un système de fichiers).
Ces services fournissent la plupart du temps des moyens de désigner les photos comme privées (personnelles) ou publiques et, dans certains cas, comme limitées à un ensemble de personnes. À noter que le RFC n'évoque pas un problème sérieux du stockage en ligne : le fait que rien n'est privé pour l'opérateur du service. On peut toujours marquer ses données comme privé, l'opérateur y a quand même accès (ainsi que la police et la justice de son pays).
Le RFC n'hésite pas à mélanger technologies très nouvelles (et souvent très expérimentales) et très anciennes. Usenet a ainsi sa section. C'est un système de distribution de messages, rangés hiérarchiquement par sujet (cf. RFC 5537). Ces messages sont automatiquement recopiés entre tous les serveurs Usenet qui participent à ce réseau. L'utilisateur final peut alors y accéder via un protocole comme NNTP. Usenet était donc du P2P longtemps avant que ce terme ne soit à la mode. Si Usenet semble nettement sur le déclin aujourd'hui, il reste un des plus importants exemples de distribution efficace de contenu sur le réseau.
En tant que système de stockage en ligne, Usenet permet de lire et d'écrire (on dit to post), et, dans une mesure très limitée, de détruire des messages (avec l'opération cancel).
S'il y a les caches pair à pair, un autre type de cache largement déployé est le cache Web, qui fait l'objet d'une analyse dans ce RFC. L'idée est surtout d'économiser de la capacité réseau (et de gagner en latence), et le cache Web est donc en général mis en œuvre par le FAI ou par les administrateurs du réseau local. Le protocole HTTP dispose de tout un tas d'options pour contrôler finement le niveau de « cachage ». Le logiciel libre le plus répandu pour cette tâche est Squid.
Ce service ne donne accès aux utilisateurs qu'en lecture, l'écriture est faite automatiquement, comme conséquence de la lecture.
Après ce long catalogue de systèmes très variés, la section 4.15 fait le point : est-ce que DECADE a trouvé ce qu'il cherchait ? La plupart de ces services sont nettement plus client-serveur que pair à pair. Et beaucoup sont spécifiques au « cachage », pas au stockage à long terme (un cache peut toujours perdre des données, par exemple, elles seront récupérées sur le site originel). Pour ces raisons et pour d'autres, il est probable que DECADE devra développer son propre service.
Après l'examen des services, la seection 5 du RFC porte sur un examen des protocoles. Quels protocoles existants pourraient être utiles pour DECADE ? Le premier examiné est bien sûr HTTP (RFC 7230). S'il est surtout connu pour ses fonctions de lecture (téléchargement de ressources Web), HTTP peut servir à bien d'autres choses, à développer des applications REST ou à écrire du contenu nouveau sur le serveur. Un des gros avantages de HTTP est évidemment que les logiciels clients sont déjà disponibles, du navigateur Web au programme en ligne de commande comme cURL, en passant par des bibliothèques pour tous les langages de programmation.
HTTP permet donc les fonctions d'accès aux données (opérations
GET, PUT, etc), de gestion
des données
(le RFC fait une erreur en disant qu'il n'y en a pas, ce qui oublie
DELETE, section 4.3.5 du RFC 7231) et de contrôle d'accès (accès public, ou
accès restreint après authentification). Les données sont nommées « ressources » et sont souvent des fichiers. HTTP étant client-serveur, il
ne convient pas parfaitement à DECADE, qui met plutôt l'accent sur le
pair à pair.
HTTP a servi de base à d'autres protocoles. Pour l'accès aux données en ligne, on pense évidemment à WebDAV (RFC 4918). C'est une extension de HTTP qui lui ajoute des fonctions comme le verrouillage ou comme le regroupement des ressources en collections, qu'on peut gérer collectivement. Ces collections font que le modèle de données de WebDAV devient très proche de celui d'un modèle « système de fichiers ».
WebDAV a également une extension pour avoir des ACL, le RFC 3744. Par contre, il n'est pas évident que ce mécanisme de gestion des droits passe à l'échelle, dans le contexte de l'Internet entier.
Autre protocole d'accès à du stockage en ligne, iSCSI, normalisé dans le RFC 7143. En gros, il s'agit d'un protocole permettant l'envoi de commandes SCSI au dessus de TCP, vers des périphériques de stockage comme des disques durs. iSCSI est typiquement un outil pour réaliser des SAN, bien qu'il puisse aussi servir au dessus de l'Internet (par exemple avec les services de nommage du RFC 4171).
iSCSI fournit des opérations de lecture et d'écriture sur des blocs de données (qui correspondent en général aux blocs du disque dur). iSCSI est de très bas niveau et aucun développeur d'applications n'aurait envie de travailler directement avec ce protocole. En réseau local, on utilise plutôt NFS, dont les dernières versions (RFC 8881) disposent de ce qu'il faut pour travailler sur l'Internet.
NFS fournit des opérations de lecture, d'écriture, de gestion (destruction, renommage) de fichiers. Il a des mécanismes de contrôle d'accès qui se sont particulièrement perfectionnés avec sa version 4, qui a amené les ACL.
Par contre, il n'est pas du tout évident qu'il puisse servir dans un service pair à pair de grande taille, notamment vue la rigidité de certains de ses mécanismes de sécurité (même problème qu'avec WebDAV).
Le dernier protocole envisagé, OAuth (RFC 5849) n'est pas vraiment un protocole d'accès à du stockage en ligne. S'il est mentionné ici, c'est parce qu'il fournit un modèle intéressant pour le contrôle d'accès à ces services de stockage. Les modèles traditionnels n'avaient que deux acteurs, le client et le serveur. Le serveur autorisait (ou pas) le client à accéder aux données. OAuth introduit un troisième acteur, le titulaire des données. Celui-ci peut donner une autorisation d'accès à un client tiers, sans lui fournir pour autant toutes ses lettres de créance (mots de passe, clés privées, etc). OAuth permet donc de déléguer l'accès.
Que peut-on synthétiser de l'examen de ces protocoles ? Ils sont surtout conçus pour du client-serveur (bien que certains puissent être adaptés au pair à pair). Et HTTP est tellement répandu et bien connu qu'il peut fournir un bon point de départ à DECADE. Par contre, aucun de ces protocoles ne prend en compte la nécessité d'accès avec faible latence, qui est nécessaire pour la diffusion de vidéo en streaming.
Enfin, si presque tous les protocoles fournissent les mécanismes de base, comme lire et écrire, la grande majorité n'a aucun mécanisme de contrôle de l'allocation des ressources, un des objectifs de DECADE (il s'agit de permettre un accès à ses ressources, sans que les pairs ne puissent tout consommer).
Bref, résume la section 6, conclusion de ce RFC, s'il existe de nombreux systèmes de stockage en ligne, ils ont été conçus avec un cahier des charges très différent de celui de DECADE (l'exemple le plus net étant leur conception client-serveur et pas pair à pair). Aucun ne peut donc être choisi tel quel pour le projet.
L'article seul
Le point sur le filtrage DNS
Première rédaction de cet article le 25 octobre 2011
À la réunion DNSEASY/SSR d'octobre 2011 à Rome, une intéressante table ronde portait sur le filtrage du DNS. C'est l'occasion de faire le point sur cette pratique. La réunion ne cherchait pas à obtenir un accord unanime, ni des solutions magiques, mais au moint à définir et délimiter le phénomène.
Comme la réunion se tenait sous la règle de Chatham House, je ne dirai pas ici qui a dit quoi.
Donc, le filtrage DNS est cette pratique qui consiste à substituer aux réponses normales des vrais serveurs DNS des mensonges, de façon à empêcher un utilisateur de communiquer avec les serveurs du domaine filtré. Il est utilisé en entreprise (pour empêcher les employés de regarder Facebook, par exemple) et par les États.
Les points étudiés étaient :
- Aspects politiques, juridiques et éthiques du filtrage (mais rappelez-vous que la majorité des participants étaient des techniciens),
- Efficacité du filtrage (diminue-t-on le nombre de lecteurs de Copwatch en le filtrant ?),
- Conséquences pour DNSSEC (beaucoup d'opposants au filtrage font remarquer qu'il contredit directement une de nos principales techniques de sécurité),
- Effets techniques secondaires (par exemple sur la résilience),
- Effets non-techniques secondaires.
Sur le premier point, l'aspect politique (au sens large), l'accord s'est fait sur l'importance de distinguer qui demande le filtrage. Il peut y avoir :
- du filtrage auto-infligé (je
bloque
google-analytics.comsur mon résolveur car je ne veux pas laisser de trace de ma navigation chez Google). Le consensus est que c'est normal, de même qu'un citoyen a le droit de refuser de lire des livres dont les idées ne lui plaisent pas. - du filtrage décidé par un prestataire (par exemple le FAI) « pour votre propre bien » (difficile de savoir si c'est le cas, très peu de FAI documentent leur politique).
- un filtrage décidé pour vous par votre employeur (dans un pays comme la France, la légalité de ce filtrage reste toujours à discuter ; mais il ne fait pas de doute que la pratique est répandue, voir par exemple comment une employée parle des problèmes avec le filtrage de sa boîte),
- un filtrage imposé par l'État, que ce dernier soit une dictature (cas de la Chine) ou une démocratie (de nombreuses démocraties filtrent, et il n'y a pas de différence technique avec ce que fait le gouvernement chinois).
Bien sûr, il y a des tas de zones grises. Ainsi, lorsque OpenDNS prétend que leur système est opt in et donc politiquement correct, ils oublient de préciser que, si l'administrateur réseaux d'une école choisit de configurer le relais DNS pour interroger OpenDNS, les enseignants vont être filtrés sans l'avoir demandé... Même chose pour les enfants, mais ils sont mineurs donc le problème est encore différent. À propos d'enfants, un participant a demandé si le cas de l'entreprise était analogue à celui de la famille (où les parents peuvent décider de filtrer ce que peuvent voir leurs enfants) ; les employés sont-ils majeurs ? (En système capitaliste, la réponse est clairement non, l'entreprise n'est pas une démocratie.)
Le cas du filtrage par un prestataire est pour moi nettement un problème de violation de la neutralité du réseau. Toutefois, beaucoup de participants au débat ont refusé de poser le problème en ces termes car ce débat sur la neutralité est très chargé. Il pose pourtant les mêmes questions : information du client (les FAI qui filtrent, par exemple le port 53, ne le documentent jamais), et possibilité réelle de changer (la concurrence est souvent insuffisante, par exemple parce qu'il n'existe pas de FAI alternatif, ou bien tout simplement tous les FAI se sont mis d'accord, comme pour les opérateurs mobiles en France qui interdisent tous la voix sur IP).
Certains prestataires se défendent en affirmant que ce filtrage est demandé (ou en tout cas accepté) par la grande majorité de leurs clients (comme disait Camus, « Quelque chose en leur âme aspire à la servitude »). Même si c'est vrai (tout le monde parle de Mme Michu, mais personne ne lui demande jamais son avis), l'opinion dominante était que cela ne change rien : si 0,1 % des clients ne veulent pas de filtrage, ils doivent pouvoir y arriver, par exemple par un système d'opt-out clair et gratuit. Notez, opinion personnelle, que cela finirait par créer un Internet à deux vitesses, un filtré pour la majorité des citoyens, et un libre pour les 0,1 % de geeks qui cliqueront sur l'option « I know what I do, I understand that I may lose hair, be hacked and see awful things, and I accept the responsability » pour désactiver le filtrage.
Un autre cas présenté comme acceptable a été celui d'un FAI qui se vante de fournir du filtrage, comme étant un service. Puisqu'on était à Rome, l'intervenant a pris comme exemple un FAI catholique affirmant qu'il filtrait l'accès à tout ce qui n'était pas approuvé par le Vatican. Le débat sur cette offre est rigolo, mais cet exemple est purement théorique. Comme je l'ai indiqué, les filtreurs n'annoncent jamais qu'ils le font, et un tel FAI n'existe pas (quoiqu'il trouverait peut-être des clients au fin fond des États-Unis).
Une anecdote révélatrice ici : la conférence se tenait dans les locaux de la Poste, qui pratique un filtrage sino-saoudien. Tout utilisateur doit être nommément identifié et l'Internet est peu accessible : seuls les ports 80 et 443 sont ouverts (le port 53 est filtré, donc pas question de contourner les résolveurs DNS officiels). Le port 443 a un système de DPI qui envoie des resets TCP dès qu'il détecte quelque chose qui n'est pas du TLS (par exemple du SSH). Or, quelles que soient leurs opinions sur la légitimité ou non du filtrage (on est dans les locaux de la Poste, on doit accepter leurs règles), la totalité des participants, au lieu d'écouter les exposés, a passé l'essentiel de la première matinée à mettre au point et à déployer (au besoin en créant des comptes pour les voisins) des systèmes de contournement. Pour les gens qui défendaient la légitimité du filtrage, c'était un bonne illustration du principe « le filtrage, c'est pour les autres ».
Le deuxième point étudié concerne l'efficacité du filtrage. S'il
attente aux libertés, est-il au moins efficace ?  (Et, question encore
plus vicieuse, cette efficacité justifie-t-elle son coût ?) La question est
complexe. Bien sûr, pour une minorité de
geeks, la question ne se
pose pas. Ils trouveront toujours, et souvent assez facilement, un
moyen de contourner le filtrage (comme l'a montré l'affaire
Copwatch où les miroirs de
secours sont apparus avant même le jugement). Mais cela
s'appliquera-t-il aux utilisateurs moins avertis, aux M. et Mme
Toutlemonde ? Peut-être pas (sauf si quelqu'un fait un logiciel simple
qui met en œuvre les mesures d'évitement). Notez bien que le
gouvernement répressif ne cherche pas forcément une efficacité à
100 %. Qu'une poignée de types dans leur garage contournent le filtre
n'est pas forcément un problème. D'autant plus que, souvent, le
gouvernement ne cherche pas d'efficacité du tout, il veut simplement
faire du théâtre et donner l'impression qu'il agit.
(Et, question encore
plus vicieuse, cette efficacité justifie-t-elle son coût ?) La question est
complexe. Bien sûr, pour une minorité de
geeks, la question ne se
pose pas. Ils trouveront toujours, et souvent assez facilement, un
moyen de contourner le filtrage (comme l'a montré l'affaire
Copwatch où les miroirs de
secours sont apparus avant même le jugement). Mais cela
s'appliquera-t-il aux utilisateurs moins avertis, aux M. et Mme
Toutlemonde ? Peut-être pas (sauf si quelqu'un fait un logiciel simple
qui met en œuvre les mesures d'évitement). Notez bien que le
gouvernement répressif ne cherche pas forcément une efficacité à
100 %. Qu'une poignée de types dans leur garage contournent le filtre
n'est pas forcément un problème. D'autant plus que, souvent, le
gouvernement ne cherche pas d'efficacité du tout, il veut simplement
faire du théâtre et donner l'impression qu'il agit.
Dans le cas où le filtrage est « auto-infligé » (par exemple parce qu'un utilisateur essaie de se prémunir contre la possibilité d'une vision accidentelle d'images qui le choqueraient), la question de l'efficacité ne se pose pas. Celui qui a voulu le filtrage ne va évidemment pas essayer de le contourner. Dans le cas où le filtrage est réellement mis en place pour protéger l'utilisateur (par exemple contre le malware), l'efficacité a des chances d'être assez bonne, tant que le filtrage n'énerve pas l'utilisateur, le motivant assez pour chercher un contournement. Et dans le cas d'un filtrage obligatoire par l'État ? Si l'État n'est pas trop méchant, l'efficacité du filtrage est faible. On a bien vu, selon un classique effet Streisand, que Copwatch était beaucoup plus lu après la plainte de Guéant qu'avant, où ce site était quasiment inconnu. Si l'État est prêt à cogner, les choses sont différentes. Si on contourne moins le filtrage en Chine qu'en France, c'est parce que le gouvernement chinois a d'autres moyens de persuasion à sa disposition. C'est d'ailleurs une leçon classique en sécurité, bien illustrée par un dessin de XKCD.
Comme la grande majorité des participants était composée de technophiles, la question des liens entre le filtrage DNS et DNSSEC était inévitable. En effet, le filtrage DNS dans les résolveurs va invalider les signatures DNSSEC et sera donc détecté. À première vue, le filtrage va donc en opposition directe à la tentative de sécurisation du DNS qu'est DNSSEC.
En fait, le problème est plus complexe que cela. D'abord, si le
filtrage est fait au niveau du registre (comme lors des cas
des saisies ICE), DNSSEC ne protégera pas. Ensuite, DNSSEC ne gènera
pas si le censeur veut uniquement bloquer l'accès : un
SERVFAIL (parce que la validation DNSSEC aura
échoué) est aussi bon pour lui qu'un NXDOMAIN
(d'ailleurs, un des mécanismes de censure pourrait être de bloquer les
réponses, au lieu de les remplacer par une réponse mensongère). Ce
n'est que si le censeur voulait rediriger discrètement vers une autre
destination que DNSSEC le gênerait. Mais il gênerait aussi
l'utilisateur : le domaine serait inaccessible. DNSSEC permet de
détecter la censure, pas de la contourner.
Néanmoins, DNSSEC est utile : dans beaucoup de pays, le gouvernement ne veut pas qu'on sache qu'il censure (ou, en tout cas, il essaie de rendre plus difficile la preuve) et, même s'il l'avoue, la liste des domaines censurés est en général secrète, ce qui permet de s'assurer que les citoyens ne pourront pas vérifier sa légitimité. DNSSEC permet d'être sûr qu'il y a bien filtrage, et on peut imaginer des logiciels qui utiliseront cette connaissance pour passer automatiquement à un plan B (un navigateur Web pourrait par exemple rereouter les requêtes pour ce domaine via Tor, s'il est sûr que c'est bien un problème de filtrage).
Et la détection qu'offre DNSSEC pourra servir aux opérateurs pour
dégager leur responsabilité. « Vilain opérateur du
.com, vous avez supprimé
example.com ! » « Ah non, regardez les signatures
DNSSEC, ce n'est pas nous, c'est un Homme du
Milieu, sans doute l'opérateur du résolveur. »
À noter aussi que, si on imagine un pays dictatorial qui veut faire du filtrage, mais n'a pas le contrôle de tous les registres (contrairement au gouvernement états-unien), et choisit donc d'opérer dans les résolveurs, mais veut qu'on puisse quand même faire du DNSSEC, il existe toujours des solutions techniques (par exemple forcer les utilisateurs, dans ce pays, à utiliser une clé DNSSEC de la racine qui soit contrôlée par le gouvernement).
Quatrième point étudié pendant l'atelier, les conséquences techniques du filtrage. En fait, la discussion a un peu tourné court. Car, contrairement à un argument parfois entendu, le filtrage ne casse pas en soi le DNS. Il le rend simplement plus lent (traitement supplémentaire) et plus fragile (introduction d'un nouveau composant, qui peut avoir des problèmes). Bref, il peut y avoir des arguments techniques contre le filtrage, mais ils ne sont pas décisifs. Notons tout de même que certains gouvernements font preuve d'une grande schizophrénie en encourageant des travaux visant à améliorer la résilience de l'Internet, tout en prônant ou en imposant le filtrage, qui va certainement diminuer cette résilience.
Enfin, cinquième et dernier point de la discussion, les conséquences non techniques. Elles sont multiples :
- Certains utilisateurs, pour contourner le filtrage, vont utiliser des résolveurs DNS alternatifs comme Google Public DNS ou Telecomix ou comme des résolveurs ouverts par accident. Ces fournisseurs alternatifs ne sont pas forcément de confiance et leur utilisation relève parfois du « je me jette dans le lac pour éviter d'être mouillé par la pluie ». Certains font leur propre filtrage, d'autres analysent vos requêtes, d'autres ajoutent leurs propres TLD.
- Le filtrage peut mener au développement de systèmes de nommage et de résolution radicalement différents. Cela peut être une bonne chose (le filtrage de Napster a certainement puissamment aidé au développement de meilleurs algorithmes P2P). Pour l'instant, il faut bien constater qu'on a surtout du vaporware dans ce domaine.
- Le filtrage apporte ses propres dangers. Le plus évident, compte
tenu de l'expérience des DNSBL, est celui de
filtrage excessif. On aura certainement un jour des
TLD entiers filtrés, volontairement (certaines
entreprises filtrent déjà tout
.ruou tout.cn) ou par accident.
Compte-tenu de ces différents points, quels sont les scénarios possibles (je n'ai pas dit « souhaitables ») pour le futur de DNSSEC ? La discussion en a identifié trois :
- Un scénario modérement pessimiste. En raison du filtrage massif, la validation DNSSEC sur le poste de travail (ce que permet dnssec-trigger) deviendrait à peu près impossible. DNSSEC serait alors limité à protéger les résolveurs/caches des FAI et on ne pourrait pas créer de nouvelles applications sur DNSSEC (elles nécessitent en général une validation locale). Cela ne serait pas sa mort, mais certainement un gros échec.
- Un scénario modérement optimiste. La détection du filtrage par DNSSEC marche (la question des indicateurs à présenter à l'utilisateur pour que cela soit clair reste ouverte), le filtrage, ainsi repéré, fait l'objet d'articles dans Libération ou le Canard enchaîné, ou de protestations au Parlement, le filtrage continue mais reste limité, grâce à la vigilance citoyenne. Des mécanismes de contournement automatiques apparaissent (passer par un relais si DNSSEC montre qu'il y a censure).
- Un scénario optimiste. La démocratie l'emporte, la liberté est rétablie, le filtrage stoppe, et tout est signé avec DNSSEC. On a la sécurité fournie par les signatures. Cela serait très bien, mais c'est hélas peu vraisemblable.
Ah, et puis une dernière chose, qui a fait l'objet d'amusantes
discussions. DNSSEC ne permet pas de distinguer facilement du filtrage d'une
attaque. Si la recherche de l'adresse de
www.example.com fait un
SERVFAIL (Server Failure,
indication par le résolveur DNS qu'il y avait un problème), comment
discerner si example.com a été bloqué par le
résolveur (sur demande de l'ARJEL ou d'un autre
censeur) ou bien si un attaquant essaie de détourner le trafic vers
son propre site ?
Une des suggestions était donc, en cas de censure, de renvoyer un
enregistrement spécial, qui indique qu'il y a eu censure. Le résolveur
pourrait interroger sans validation (avec dig,
c'est l'option +cd) et voir ainsi ce qui s'est
passé, pour annoncer à l'utilisateur qu'il a été filtré pour son bien.
J'avais suggéré, en cas de requête de type A
(adresse IPv4), de renvoyer la valeur spéciale
1.9.8.4. Mais, bon, le préfixe englobant est déjà
alloué .
L'article seul
RFC 6382: Unique Per-Node Origin ASNs for Globally Anycasted Services
Date de publication du RFC : Octobre 2011
Auteur(s) du RFC : Danny McPherson, Ryan Donnelly, Frank Scalzo (Verisign)
Réalisé dans le cadre du groupe de travail IETF grow
Première rédaction de cet article le 25 octobre 2011
Dernière mise à jour le 26 octobre 2011
Ce court RFC propose un changement radical dans la gestion des annonces BGP par les services anycastés. Actuellement, ils utilisent presque tous un seul numéro d'AS pour tous les nœuds d'un nuage anycast. Notre RFC 6382, au contraire, suggère d'utiliser un numéro d'AS par nœud.
Comme l'explique la section 2 de notre RFC,
l'anycast (RFC 4786) est désormais une
technique banale. Elle permet notamment d'augmenter sérieusement la
résistance aux dDoS. Dans le monde du
DNS, l'anycast est
particulièrement répandu (par exemple,
.fr n'a plus que deux
serveurs unicasts, tous les autres sont
anycastés).
L'anycast fonctionnant en injectant la même route, via BGP, depuis des points différents du réseau, on peut se demander s'il faut que tous ces points annonçent le préfixe depuis le même AS, ou bien si chacun doit utiliser un AS différent ? Aujourd'hui, la quasi-totalité des services anycastés utilisent un seul numéro d'AS pour tous leurs points de présence (POP). VeriSign (la boîte des auteurs du RFC) est un des rares acteurs à le faire, pour certains de leurs serveurs. Cela a notamment l'avantage de préserver une ressource rare : les numéros d'AS n'étaient codés que sur seize bits. Cela facilite également la configuraion des routeurs. Et, aujourd'hui, cela évite des ennuis avec les systèmes d'alarme BGP, qui pourraient couiner en voyant le même préfixe avoir plusieurs AS d'origine. Hurricane Electric fournit ainsi une liste des préfixes annoncés par plusieurs AS. Même chose chez Cymru. Comme illustré par un exposé à NANOG en 2001, c'était plutôt considéré comme une erreur.
Mais cette politique a aussi des défauts : lorsqu'un routeur BGP
voit arriver une annonce pour un préfixe anycasté,
il ne sait pas exactement de quel nœud elle vient. Cela peut
compliquer le débogage des problèmes. Certains services ont un
mécanisme pour identifier le serveur (RFC 5001
pour le DNS, ou bien le traditionnel quoique non normalisé
hostname.bind dans la classe
CH). Et, évidemment, on peut toujours utiliser
traceroute pour trouver où se trouve telle
instance anycast. Essayons avec un serveur DNS
anycasté, d.nic.fr, depuis une
machine située dans le Missouri :
% dig +nsid @d.nic.fr SOA fr. ... ; NSID: 64 6e 73 2e 6c 79 6e 32 2e 6e 69 63 2e 66 72 (d) (n) (s) (.) (l) (y) (n) (2) (.) (n) (i) (c) (.) (f) (r) ...
C'est donc dns.lyn2.nic.fr qui a répondu.
Et on confirme (l'AFNIC utilise les Locodes pour nommer ses machines, donc LYN = Lyon) qu'on touche l'instance de
Lyon (cette machine a surtout des instances
en métropole et dans les DOM-TOM et aucune aux États-Unis) :
# tcptraceroute d.nic.fr 53 Selected device eth0, address 208.75.84.80, port 43778 for outgoing packets Tracing the path to d.nic.fr (194.0.9.1) on TCP port 53 (domain), 30 hops max 1 208.75.84.1 0.000 ms 0.000 ms 0.000 ms 2 host123.datotel.com (208.75.82.123) 0.000 ms 0.000 ms 0.000 ms 3 stl-c1-g1-15.datotel.com (208.82.151.29) 10.000 ms 0.000 ms 0.000 ms 4 stl-e2-g0-2.datotel.com (208.82.151.13) 0.000 ms 0.000 ms 0.000 ms 5 vlan100.car2.StLouis1.Level3.net (4.53.162.121) 0.000 ms 0.000 ms 0.000 ms 6 ae-4-4.ebr2.Chicago1.Level3.net (4.69.132.190) 10.000 ms 9.999 ms 10.000 ms 7 ae-5-5.ebr2.Chicago2.Level3.net (4.69.140.194) 0.000 ms 9.999 ms 9.999 ms 8 ae-6-6.ebr2.Washington12.Level3.net (4.69.148.145) 10.000 ms 19.999 ms 19.999 ms 9 ae-5-5.ebr2.Washington1.Level3.net (4.69.143.221) 19.999 ms 19.999 ms 29.998 ms 10 ae-44-44.ebr2.Paris1.Level3.net (4.69.137.61) 89.994 ms 99.994 ms 109.994 ms 11 ae-22-52.car2.Paris1.Level3.net (4.69.139.227) 109.994 ms 99.994 ms 99.994 ms 12 JAGUAR-NETW.car2.Paris1.Level3.net (212.73.207.162) 109.993 ms 99.995 ms 99.994 ms 13 dns.lyn2.afnic.cust.jaguar-network.net (78.153.224.126) 119.993 ms 119.993 ms 139.992 ms 14 d.nic.fr (194.0.9.1) [open] 109.994 ms 119.993 ms 109.993 ms
Les machines de l'AFNIC ayant un enregistrement DNS indiquant leur position physique (RFC 1876), on peut même être plus précis :
% dig LOC dns.lyn2.nic.fr ... dns.lyn2.nic.fr. 172800 IN LOC 45 43 20.568 N 4 51 39.816 E 1.00m 1m 10m 10m
et on sait alors où est la machine.
Autre essai, avec un serveur de la racine du DNS,
L.root-servers.net, largement
anycasté. Depuis un fournisseur en France :
% dig +nsid @l.root-servers.net SOA . ... ; NSID: 6c 79 73 30 31 2e 6c 2e 72 6f 6f 74 2d 73 65 72 76 65 72 73 2e 6f 72 67 (l) (y) (s) (0) (1) (.) (l) (.) (r) (o) (o) (t) ( -) (s) (e) (r) (v) (e) (r) (s) (.) (o) (r) (g)
On touche lys01.l.root-servers.org. Comme son
opérateur, l'ICANN, utilise (comme beaucoup),
les codes aéroport pour nommer les machines, on
voit qu'elle est également à Lyon (LYS est l'aéroport de
cette ville). Depuis une machine d'un autre
FAI français, la même requête renvoie
lux01.l.root-servers.org, ce qui situe le
nœud anycast au Luxembourg. Et, en testant depuis la
machine missourienne citée plus haut, on atteint
lax12.l.root-servers.org soit Los Angeles.
Ces techniques sont toutefois imparfaites. Or, les services anycast ont des vulnérabilités paticulières. Par exemple, l'injection de routes pirates dans BGP par un méchant est plus difficile à détecter (cf. section 5). L'anycast a besoin d'outils de débogage puissants, pour venir à bout des problèmes de routage, volontaires ou involontaires, qui peuvent se manifester. Pire, on peut avoir des cas où les différentes instances d'un même nuage anycast ne répondent pas exactement la même chose, et il est dans ce cas crucial de pouvoir identifier sans aucune ambiguïté celles qui sont différentes.
Avant la recommandation officielle, un petit détour de terminologie (section 1). Parmi les termes importants (lire le RFC 4786 pour plus de détails) :
- Bassin d'attraction (catchment), terme emprunté à l'hydrographie (la zone dont toutes les eaux finissent dans une rivière donnée), désigne la partie de l'Internet qui envoie ses paquets à un nœud (une instance anycast) donné,
- Nœud local, instance d'un service
anycast qui ne publie son préfixe que dans une
partie de l'Internet (typiquement, uniquement les participants à un
point d'échange donné, en utilisant la
communauté BGP
no-export). La recommandation de ce RFC s'applique à tous les nœuds, locaux ou globaux, - Nœud global, instance qui annonce son préfixe à l'Internet entier.
Venons-en maintenant à la nouveauté de ce RFC. Il tient en une
phrase (section 3), « Il faudrait utiliser un numéro d'AS
différent par nœud ». Le but est de fournir un
mécanisme discriminant les annonces. Si on a deux nœuds, un en
Chine (AS 65536) et un en Europe (AS 65551), et qu'on voit le préfixe
anycast 192.0.2.64/26 annoncé
depuis l'AS 65536, on sait qu'on s'adressera à l'instance chinoise. On
peut même filtrer sur l'AS d'origine pour éviter cela. L'utilisation de numéros
d'AS différents permettra de choisir sa politique de routage.
Est-ce sans inconvénient ? Actuellement, le principal problème
risque d'être les systèmes d'alarme
qui s'inquiéteraient de ces différentes origines. Ainsi, BGPmon, par défaut, considère qu'une
annonce depuis un autre AS que celui indiqué comme origine, est une
attaque possible (possible hijack) et il alarme. Toutefois, le même BGPmon permet
d'indiquer plusieurs AS d'origine supplémentaire, ce qui lui permet de
gérer la nouvelle politique. (Une société comme
PCH a environ soixante localisations physiques
dans le monde, Netnod en a cent : les enregistrer toutes comme origine possible, auprès
d'un système d'alarme BGP, pourrait être fastidieux. À noter que la
fonction auto-detect de BGPmon simplifie cela : comme
l'explique l'auteur « Just click on the prefix to edit it, then click on
the little green icon next to the 'Additional Origin AS' section.
It will then show a popup with all additional origin ASn's we have in
our database. You can then copy paste that line into the 'Additional
Origin AS' field. ». Un exemple est donné par un serveur de
.com, m.gtld-servers.net.)
Autre inconvénient possible : la consommation excessive de numéros d'AS. Toutefois, depuis le RFC 4893, ceux-ci peuvent désormais être codés sur 32 bits et le risque d'épuisement disparait.
Après cette nouvelle recommandation de consommer un numéro d'AS par site, la section 4 du RFC rassemble divers conseils aux gérants de services anycast :
- Publier des informations sur la localisation physique de la
machine (la méthode n'est pas précisée mais on peut penser aux
enregistrements
LOCdu RFC 1876, peut-être en les attachant au nom obtenu par la requête NSID), - Publier dans les IRR les informations sur les AS auxquels le nœud anycast s'interconnecte (par exemple en RPSL, RFC 4012).
Et la section 6 contient l'examen de divers points pratiques liés au déploiement de cette nouvelle politique. Les opérateurs de services anycast critiques ont été largement consultés avant la publication du RFC, ce qui ne veut pas dire qu'ils déploieront cette recommandation tout de suite (aucun n'a annoncé de plan précis et l'ISC a au contraire annoncé qu'ils ne le feraient pas, voir plus loin leur analyse). En gros, la nouvelle politique fera davantage de travail au début (obtenir les numéros d'AS - ce qui nécessitera probablement un changement dans la politique des RIR, ajouter une colonne pour le numéro d'AS dans la base de données des instances anycast, penser à indiquer le bon numéro d'AS lorsqu'on fait une demande de peering, changer les centaines de peerings existants, etc) mais simplifiera la surveillance du service, en permettant de trouver plus facilement l'origine d'une annonce.
Et pour finir, un exemple de ce que donne un excellent outil
d'analyse existant, le RIS, avec le serveur de
.com déjà cité (annoncé par trois AS) : http://www.ris.ripe.net/dashboard/192.55.83.0/24.
Pour avoir un autre point de vue, l'ISC a expliqué le fonctionnement de l'anycast chez eux, une explication détaillée de la supériorité de leur système, ainsi que leur liste de peerings.
Une autre question n'est pas couverte dans le RFC mais mérite une
mention (merci à Olivier Benghozi et Guillaume Barrot pour leurs explications) : pourquoi
n'avoir pas utilisé plutôt les communautés BGP (RFC 1997), des étiquettes qu'on peut attacher aux annonces et
qui sont transitives ? La raison principale est qu'elles sont
fréquemment effacées en entrée des AS (sans compter les systèmes qui,
par défaut, ne les transmettent pas du tout comme
IOS, cf. un
article sur leur utilisation). Même problème avec d'autres attributs facultatifs
de BGP comme AGGREGATOR (qu'on aurait pu, en le détournant un peu, utiliser à ce but).
Merci à Jean-Philippe Pick pour sa relecture et pour les informations.
L'article seul
Les soldats de l'or gris
Première rédaction de cet article le 22 octobre 2011
Il y a déjà eu des tas de romans où un méchant quelconque arrivait à prendre le contrôle des esprits, et à faire faire ce qu'il voulait à ses victimes transformées en zombies. Le problème, avec les progrès de la science, est qu'il est possible que nous soyions tout proches d'une réalisation effective de cette idée. C'est le thème du roman « Les soldats de l'or gris » de Sébastien Bohler, où la CIA et les services secrets chinois vont essayer d'être les premiers à profiter d'une récente percée scientifique...
L'opération « Or gris » du titre fait bien sûr référence à la matière grise du cerveau. On peut faire plein de choses de cet organe si on sait le contrôler. Dans le roman (mais aussi apparemment dans la réalité), la CIA a déjà tenté plusieurs fois ce contrôle, comme dans le fameux projet MK-Ultra. Tous ces essais ont échoué. Mais le développement des nanotechnologies, associé à celui de la cartographie cérébrale, permet d'aborder le problème différemment. Si on arrive à placer certains anticorps sur des nanobilles, et à les envoyer au bon endroit du cerveau où elles libéreront les anticorps, peut-on convaincre un espion de changer de camp ? Un soldat de ne plus avoir peur de rien ? Une femme de dire oui à une proposition sexuelle (c'est sérieux, c'est même en note de pied de page dans le roman, lisez donc « The role of the anterior cingulate cortex in women's sexual decision making »).
Dans le roman, c'est possible. Dans la réalité... je ne sais pas trop, mais l'auteur est neurobiologiste et il connait le sujet. Si les informaticiens ricaneront en lisant les efforts de la CIA pour pirater l'informatique chinoise, rendus difficiles par le fait que, raconte un agent chinois, « Nous sommes à même de percer leurs défenses informatiques, qui reposent sur des codes-sources accessibles comme Microsoft ou [sic] Windows, alors que notre Kylin a un code confidentiel », l'amateur se régalera des descriptions de la biologie du cerveau, des efforts scientifiques dans ce domaine, et du fonctionnement du milieu scientifique.
Dans le récit, un jeune chercheur arrive à maîtriser les nanobilles comme personne avant lui... et le sujet de la manipulation du cerveau, qui concernait surtout les philosophes, devient d'actualité.
Si le roman démarre maladroitement, tout le reste est passionnant, avec tous les ingrédients d'un roman d'espionnage, plus les nouvelles possibilités qu'offrent le contrôle du cerveau (non, je ne dévoilerai pas ce qu'on peut faire, lisez le roman, vous ne le lâcherez pas.)
L'article seul
RFC 6385: General Area Review Team (Gen-ART) Experiences
Date de publication du RFC : Octobre 2011
Auteur(s) du RFC : M. Barnes (Polycom), A. Doria (Lulea University of Technology), H. Alvestrand (Google), B. Carpenter (University of Auckland)
Pour information
Première rédaction de cet article le 19 octobre 2011
Comme souvent à l'IETF, les expériences les plus réussies ne sont pas documentées, ou alors le sont longtemps après. Les examens des Internet-Drafts par Gen-ART (General Area Review Team) ont commencé en 2004 mais viennent juste d'être formalisées. Gen-ART, dont l'expérience est décrite dans ce nouveau RFC, est un groupe d'experts volontaires qui regardent les Internet-Drafts lorsqu'ils sont prêts de devenir un RFC. Le terme de « Gen-ART » apparait de plus en plus souvent dans les discussions à l'IETF, mais que recouvre-t-il exactement ?
Les procédures de l'IETF sont loin d'être toutes documentées. Il y a la théorie, et la pratique. Par exemple, l'IESG est censée examiner les Internet-Drafts avant leur publication au cours de ses réunions à distance, les telechats. Mais la quantité de documents à examiner est telle que toute aide est la bienvenue. Un groupe de volontaires s'est donc constitué et s'est mis tout seul (rappellons que tout le processus IETF est public, il n'y a pas besoin d'une autorisation spéciale pour créer un groupe, lire des documents et publier les résultats) à lire les documents qui allaient passer à l'IESG, pour débrousailler le tas de papier. Ce RFC est le compte-rendu de l'expérience de ce groupe, qui prend désormais de plus en plus de place, au point que certains croient même qu'il s'agit d'un projet officiel.
La section 1 du RFC résume d'où vient Gen-ART, et insiste sur ce caractère non officiel. Gen-ART fait ce que tout le monde a le droit de faire : lire les Internet-Drafts (ils sont publics) et les commenter publiquement. Son autorité est purement morale, provenant de la qualité de ses examens et du prestige de ses membres.
La section 2 est consacrée à ces membres : un groupe d'experts auto-désignés, en général auteurs de plusieurs RFC, et expérimentés dans la normalisation IETF. La section 12 donne la liste actuelle (qu'on trouve aussi en ligne). Bien que le RFC n'en parle pas, on peut noter que la relecture est parfois faite par un autre membre de l'IETF, sur délégation d'un membre de Gen-ART (évidemment en toute transparence). C'est ainsi que j'ai fait ma première (et unique, pour l'instant) revue Gen-ART, en décembre 2010, comme délégué de Francis Dupont. Il s'agissait du document draft-cheshire-dnsext-dns-sd, très contesté (ma conclusion était peu favorable, et le document est toujours, aujourd'hui, en discussion). L'auteur avait répondu à mon analyse.
La section 3 résume ensuite le but poursuivi par Gen-ART : décharger l'IESG d'une partie du fardeau (parfois vingt Internet-Drafts en un seul telechat), de façon à ce que l'examen de l'IESG puisse se concentrer sur les quelques documents à problème, en ignorant la majorité qui va bien. Bien qu'il existe tout un tas de comités et de groupes à l'IETF, personne ne vise cette tâche à part Gen-ART.
La section 4 décrit comment fonctionne Gen-ART, quels documents sont relus, et qu'est-ce que produit Gen-ART. Le rapport final indique si l'Internet-Draft :
- est prêt à devenir un RFC, et de quel type (expérimental, pour information, chemin des normes...),
- ou bien est presque bon mais mérite quelques changements,
- ou encore s'il va dans le bon sens mais a besoin d'être sérieusement revu,
- ou, pourquoi pas, s'il est tellement catastrophique qu'il vaut mieux arrêter là.
Les critères pour décider sont ceux classiquement utilisés à l'IETF :
- Les principes de l'architecture de l'Internet (RFC 1958 et RFC 3439),
- Les considérations de politique technique (RFC 3426),
- Sur la forme, la liste des choses à vérifier dans un futur RFC, les instructions aux auteurs (RFC 7322), les instructions sur la section IANA (RFC 5226) et sur la section Sécurité (RFC 3552).
Gen-ART étant issu de la « zone générale » (General Area, celle qui s'occupe de tout ce qui ne rentre pas dans une catégorie particulière), le groupe de relecteurs fait notamment attention à tout ce qui n'est pas sous la responsabilité d'une autre zone. Par exemple, dans un Internet-Draft sur un nouveau protocole de routage, on peut supposer que la zone Routage (Routing Area) s'est occupé de la qualité technique du protocole. Cela laisse donc à vérifier, un tas de choses, certaines de haut niveau et d'autres triviales. Le RFC cite, entre autres :
- Une bonne explication de l'intérêt du futur RFC pour l'Internet,
- Un anglais correct,
- Des exemples conformes aux règles (RFC 2606, RFC 3849, RFC 5612, RFC 5737, etc).
La section 4 décrit ensuite le processus suivi lors des relectures. Il faut notamment noter que les RFC ne sont pas affectés aux relecteurs en fonction de leur spécialité : le but étant d'avoir un regard général, un expert en sécurité peut se retrouver avec un Internet-Draft sur le routage. Le processus bureaucratique, lui (maintien de la liste des relecteurs, détails très précis sur les conditions d'affectation d'un document à un relecteur), est en section 5.
Quels sont les résultats de Gen-ART ? La section 6 fait le bilan : environ 2 000 relectures ont été faites en sept ans, avec une équipe comportant environ douze relecteurs, chacun recevant plus d'un Internet-Draft par mois. Ces relectures ont permis de faire passer le pourcentage de documents considérés comme « prêts pour publication » au moment du telechat IESG de 25 % à 75 %.
Par delà les chiffres, quel est le ressenti des participants ? La section 7 rassemble tout un tas de témoignages très variés, notant par exemple que la qualité moyenne est bonne mais que Gen-ART a déjà servi à arrêter de très mauvais documents.
Mais le mécanisme des relectures Gen-ART est-il parfait ? La section 8 propose de l'améliorer, notant les points faibles. Le principal est l'absence presque complète d'automatisation. Gen-ART n'a actuellement pas d'outils spécialisés (un des buts de la section 5 était, en décrivant précisement le processus, de faciliter l'écriture d'un cahier des charges pour le développement de ces outils).
Vous pouvez aussi visiter le site Web de Gen-ART et prendre connaissance de sa FAQ.
L'article seul
dnssec-trigger, un outil pour mettre DNSSEC à la disposition de M. Toutlemonde
Première rédaction de cet article le 15 octobre 2011
Une des faiblesses de la sécurité de l'Internet est que le mécanisme d'annuaire principal, le DNS, n'est pas très sécurisé. Il est trop facile de tromper un serveur DNS en lui injectant de fausses informations (faille dite Kaminsky). Mais il y a pire : souvent, c'est le serveur DNS mis à la disposition de l'utilisateur, par le FAI ou par le service informatique local, qui le trompe. Une solution technique existe, à ces deux problèmes : DNSSEC. Mais pour que DNSSEC protège M. Toutlemonde, les vérifications que permet ce protocole doivent être faites sur la machine de M. Toutlemonde, la seule en qui il peut avoir un peu confiance. C'est ce que permet le nouveau logiciel dnssec-trigger.
Depuis que DNSSEC existe (sa version actuelle a été normalisée dans le RFC 4033), il y a un débat sur l'endroit où doit se faire la validation, c'est-à-dire la vérification, par des calculs cryptographiques, que l'information reçue est bien authentique. Comme cette validation nécessite des calculs complexes et, jusqu'à la signature de la racine et de nombreux TLD, vers 2010-2011, nécessitait une configuration complexe, il semblait logique de faire la validation sur les résolveurs DNS que tout FAI, tout réseau local, met à la disposition de M. Toutlemonde. Le problème est que ces résolveurs sont souvent les premiers à mentir, comme on l'a vu de nombreuses fois, l'une des dernières étant l'affaire Earthlink. Bien que ce soit une violation claire de la neutralité de l'intermédiaire, d'autres FAI se livrent à ce genre de pratiques.
Il reste donc à faire la validation sur la machine de M. Toutlemonde. Pour un PC moderne, les calculs cryptographiques nécessaires ne représentent qu'une tâche bien légère (cela peut être différent pour un smartphone). Mais la validation directement sur le PC de l'utilisateur pose deux problèmes : elle nécessite l'installation et la configuration correcte d'un logiciel supplémentaire (même si cela ne prend que quelques minutes, l'expérience prouve que c'est beaucoup trop difficile pour M. Toutlemonde) et, si tout le monde en faisait autant, les serveurs DNS souffriraient sous la charge accrue. En effet, comme il n'y aurait plus de cache partagé (rôle que jouent aujourd'hui les serveurs résolveurs des FAI, qui gardent en mémoire la réponse aux questions déjà posées), les serveurs des différentes zones DNS recevraient bien plus de requêtes.
Cette question est connue depuis un certain temps (voir par exemple une discussion technique approfondie en 2011). Mais la nouveauté est qu'on a désormais un logiciel qui résout ces deux problèmes. dnssec-trigger est un outil génial. Développé aux NLnetLabs, partiellement financé par l'AFNIC, il va permettre de donner la puissance de DNSSEC à M. Michu, en lui permettant de valider sur sa machine, tout en n'écroulant pas les serveurs de l'AFNIC (ou les autres serveurs faisant autorité) sous la charge, comme cela se produirait si chacun avait un résolveur normal sur sa machine.
Comment fonctionne dnssec-trigger ? C'est un logiciel qui tourne sur plusieurs systèmes d'exploitation, plutôt ceux qui sont michuiens ou toutlemondesques (Ubuntu, Fedora, Microsoft Windows, Mac OS). Il s'intègre au système de gestion du réseau de ces systèmes (les programmeurs apprécieront l'exploit que cela représente, vue la variété de ces systèmes), par exemple NetworkManager, et, lorsque celui-ci lui signale une nouvelle connexion réseau, il teste les résolveurs indiqués (le réseau les indique typiquement avec DHCP). Pourquoi les tester ? Parce que, dans la nature, on trouve de tout sur les réseaux. Idéalement, les résolveurs devraient fonctionner. Mais très fréquemment (surtout dans les réseaux pourris fournis par les hôtels, les gares, etc), le résolveur est sérieusement cassé : il bloque DNSSEC, ou bien il bloque les réponses plus grandes que 512 octets (ce qui revient quasiment à bloquer DNSSEC) ou carrément il bloque toutes les requêtes qui utilisent EDNS0 (RFC 6891). Ces résolveurs ne peuvent pas aider l'utilisateur, ils ne sont qu'un obstacle. dnssec-trigger tente alors de joindre directement les serveurs faisant autorité (ce qui marche si le réseau ne bloque pas le port 53). Si cela échoue, il essaie plusieurs techniques (expérimentales et pas forcément présentes dans la version actuelle du logiciel) comme de joindre un résolveur public qui marche, ou comme de tunneler les requêtes sur le port 443. Ces techniques de contournement sont bien connues des hackers mais l'intérêt de dnssec-trigger est de les automatiser pour M. Michu.
Une fois ces tests terminés, dnssec-trigger reconfigure au vol le résolveur Unbound (dnssec-trigger pourrait aussi marcher avec BIND, qui a les mêmes capacités mais Unbound est meilleur sur la plupart des plans ; notez que la version Windows de dnssec-trigger inclus Unbound) de façon à :
- Utiliser les résolveurs officiels du réseau comme forwarders, c'est-à-dire qu'ils recevront les requêtes DNS et pourront garder les réponses dans leur cache, limitant ainsi le trafic réseau. C'est donc la meilleure approche, la plus « développement durable ». La validation sera bien faite sur le poste de travail, sur la machine de M. Toutlemonde, mais le trafic sur les serveurs DNS faisant autorité ne sera pas différent de ce qu'il est aujourd'hui, puisqu'on utilise les mêmes caches. (Le fait que la validation fonctionne, qu'on ait obtenu la réponse DNS directement d'un serveur faisant autorité, ou indirectement via un résolveur/cache, est le résultat d'une très utile propriété de DNSSEC : il protège le message, pas le canal.)
- Si les résolveurs officiels sont vraiment trop nuls,
dnssec-trigger va dire à Unbound de fonctionner comme résolveur
indépendant. La charge sur tous les serveurs DNS va alors augmenter
mais c'est inévitable (les serveurs des gros TLD comme
.frsont déjà surdimensionnés, pour faire face au risque de DoS distribuées). - Si le lien direct vers les serveurs faisant autorité ne passe pas (cas où un pare-feu se trouve sur le trajet et bloque le port 53, celui du DNS), dnssec-trigger va alors dire à Unbound de tenter différents trucs pour passer quand même, comme d'utiliser un résolveur ouvert et accessible sur un autre port (ce dernier service est en cours d'évaluation).
Avec ce logiciel, on aura donc enfin le beurre et l'argent du beurre. On pourra donc valider en local, sur sa machine, sans pour autant massacrer les serveurs DNS sous les requêtes. Mais je parle au futur car dnssec-trigger est encore en béta-test. Il faut des volontaires pour le tester sur plein de réseaux différents (surtout les pénibles, aéroports, hôtels, etc). Ensuite, il reste à l'intégrer dans les systèmes d'exploitation, pour que M. Toutlemonde n'ait rien à installer (les discussions ont déjà commencé avec Fedora).
Après cet appel au peuple, un peu de technique. dnssec-trigger a
quatre parties, un démon qui doit tourner en
permanence, dnssec-triggerd, un composant
enregistré auprès du gestionnaire de réseau (NetworkManager sur Ubuntu, le script
d'installation le détecte en général seul et se débrouille) pour être
prévenu des changements de connectivité, un logiciel de contrôle,
dnssec-trigger-control et bien sûr le résolveur
validant, actuellement Unbound (toute la cuisine de communication
sécurisée entre dnssec-trigger et Unbound, incluant des
certificats X.509 pour l'authentification, est
faite automatiquement à l'installation de dnssec-trigger). On peut
regarder l'état du système de résolution :
% dnssec-trigger-control status at 2011-10-15 16:27:42 cache 212.27.40.240: OK cache 212.27.40.241: OK state: cache secure
Ici, on voit que dnssec-trigger a été informé (par NetworkManager) que le réseau local a deux résolveurs, qu'ils ont été testés et trouvés corrects, et que dnssec-trigger est donc heureux (secure) et utilise un cache. C'était sur un réseau local connecté à Free. On a eu de la chance ici car les deux résolveurs de Free sont composés de plusieurs machines ayant des configurations différentes (!) et il est fréquent qu'une des adresses ne gère pas DNSSEC. Ici, ce n'est heureusement pas le cas, dnssec-trigger a donc indiqué à Unbound d'utiliser ces deux résolveurs, ce qu'on peut vérifier, en demandant à Unbound :
# unbound-control forward 212.27.40.241 212.27.40.240
Et tcpdump nous le confirme :
17:06:26.848768 IP 192.168.2.26.37031 > 212.27.40.241.53: 31541+% [1au] A? ubuntu-archive.mirrors.proxad.net. (62) 17:06:26.871841 IP 212.27.40.241.53 > 192.168.2.26.37031: 31541 1/2/3 A 88.191.250.131 (146)
Les requêtes DNS (ici une demande de l'adresse
IPv4 de
ubuntu-archive.mirrors.proxad.net) sont bien
envoyées au forwarder,
212.27.40.241 (qui pourra répondre à partir de
son cache), et pas directement aux serveurs
faisant autorité.
Si l'un des résolveurs indiqués ne gère pas DNSSEC (ici,
192.134.4.163 est un BIND
avec la configuration dnssec-enable no;),
dnssec-trigger utilise les autres :
% dnssec-trigger-control status at 2011-09-20 10:01:09 cache 192.134.4.163: error no RRSIGs in reply cache 192.134.4.162: OK state: cache secure
On est quand même secure, seul
192.134.4.162 sera utilisé comme
forwarder.
dnssec-trigger sait gérer les annonces RA (Router Advertisment) du RFC 8106 et peut donc utiliser des résolveurs IPv6. Ici, toujours chez Free :
% dnssec-trigger-control status at 2011-10-15 17:04:32 cache 2a01:e00::1: OK cache 2a01:e00::2: error no EDNS cache 212.27.40.240: OK cache 212.27.40.241: OK state: cache secure
Un des deux résolveurs IPv6 ne gère pas EDNS0 (je l'ai dit, c'est un problème courant chez Free) donc dnssec-trigger n'utilise que les résolveurs qui marchent :
# unbound-control forward 212.27.40.241 212.27.40.240 2a01:e00::1
tcpdump nous confirme que la résolution se passe bien en IPv6 (ici,
demande de la clé de .org,
nécessaire pour valider le nom www.bortzmeyer.org
qui avait été demandé) :
17:07:13.651758 IP6 2a01:e35:8bd9:8bb0:1a03:73ff:fe66:e568.31040 > 2a01:e00::1.53: 54769+% [1au] DNSKEY? org. (32) 17:07:13.771831 IP6 2a01:e00::1.53 > 2a01:e35:8bd9:8bb0:1a03:73ff:fe66:e568.31040: 54769 6/0/1 DNSKEY, DNSKEY, DNSKEY, DNSKEY, RRSIG, RRSIG (1334)
Jusqu'à présent, nous n'avons vu que des résolveurs assez sympa. Mais, lorsqu'on se promène de hotspot en hotspot, on tombe sur bien pire. Ici, aucun des résolveurs officiels ne gère DNSSEC :
% dnssec-trigger-control status at 2011-10-07 09:04:06 authority 128.63.2.53: OK cache 10.150.6.1: error no RRSIGs in reply cache 10.150.2.1: error no RRSIGs in reply state: auth secure
Mais dnssec-trigger a vu qu'il pouvait parler directement aux serveurs
faisant autorité (il indique avoir testé avec
128.63.2.53, un des serveurs de la
racine, le H). On est donc bien secure
mais l'indication cache a été remplacée par
auth. Désormais, le seul cache est celui d'Unbound
sur la machine.
Pire, voici un hotspot qui ne laisse même pas parler aux serveurs faisant autorité (ici le serveur racine K) :
% dnssec-trigger-control status at 2011-10-07 09:02:21 authority 193.0.14.129: error no EDNS cache 192.168.16.1: error no EDNS state: nodnssec insecure
dnssec-trigger affiche alors un avertissement disant qu'il ne sait pas faire (dans cette version, qui n'a pas encore les techniques de contournement) et laisse le choix à l'utilisateur de se connecter de manière non sûre (ce qui a été choisi ici) ou bien de se déconnecter. Notez qu'on est en sécurité dans ce dernier cas, et dnssec-trigger affichera secure... :
% dnssec-trigger-control status at 2011-10-07 09:06:49 no cache: no DNS servers have been supplied via DHCP state: disconnected secure
Un cas beaucoup plus vicieux est celui d'un hotspot où les résolveurs ne gèrent pas DNSSEC, mais on a accès aux serveurs faisant autorité, sauf que le portail captif ne marche pas si on n'utilise pas les résolveurs officiels...
at 2011-10-07 09:08:46 authority 193.0.14.129: OK cache 10.150.6.1: error no RRSIGs in reply cache 10.150.2.1: error no RRSIGs in reply state: auth secure
dnssec-trigger utilise alors l'accès direct aux serveurs faisant autorité, qui marche (vérifié ici avec dig) :
; <<>> DiG 9.7.3 <<>> @193.0.14.129 DNSKEY . ... ;; flags: qr aa rd; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: . 172800 IN DNSKEY 256 3 8 ...
Mais dès qu'on essaie d'aller sur le Web, on
est redirigé d'autorité vers un portail captif nommé
bsc-lsh3.essec.fr et on reçoit un message
d'erreur disant qu'il n'existe pas. En effet, ce nom n'est pas présent
dans le vrai DNS :
; <<>> DiG 9.7.3 <<>> A bsc-lsh3.essec.fr ... ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 28170
mais il l'est dans les serveurs officiels du hotspot :
... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 2500 ;; flags: qr aa rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: bsc-lsh3.essec.fr. 28800 IN A 194.254.137.123
Seule solution, régler le problème à la main. dnssec-trigger fournit un GUI pour le faire, mais on peut aussi utiliser la ligne de commande :
... On dit à dnssec-trigger d'utiliser temporairement les résolveurs officiels ... % dnssec-trigger-control hotspot_signon ... On se connecte au portail captif, acceptant les conditions d'utilisation ... ... On re-teste ... % dnssec-trigger-control reprobe ... Et cette fois, on a bien du DNSSEC ...
Pour la petite histoire, voici quel était le cahier des charges original de dnssec-trigger, ceci était le compte-rendu d'une série de réunions informelles et de discussions en ligne.
My wishlist for Xmas: an easy (easy as in "works for M. Smith or M. Jones") way to have an Unbound resolver which:
- uses the DHCP-assigned name servers as forwarders after testing them (ldns-test-edns may be useful here), to save traffic on authoritative name servers
- or talks directly to the authoritative name servers (including the root) if the DHCP-assigned name servers are broken (no EDNS, mangles DNSSEC, etc) and if there is a clean path to the auth. name servers (again, something to test, because of the GF in China, because of broken "transparent" DNS proxies)
- or tunnels DNS requests to a forwarder hardwired somewhere (or configured by the user) is there is no other solution.
À propos d'anglais, si vous préférez lire en anglais, ou simplement si vous voulez voir davantage de copies d'écran, Jan-Piet Mens a écrit sur le même sujet en anglais. Il y a également l'exposé d'Olaf Kolkman au RIPE 63. Voir aussi L'article de Dmitry Kohmanyuk (mais son titre contient une grosse erreur : le principe de dnssec-trigger est justement de tout faire pour éviter de demander aux serveurs faisant autorité).
L'article seul
RFC 6410: Reducing the Standards Track to Two Maturity Levels
Date de publication du RFC : Octobre 2011
Auteur(s) du RFC : R. Housley (Vigil Security), D. Crocker (Brandenburg InternetWorking), E. Burger (Georgetown University)
Première rédaction de cet article le 12 octobre 2011
Ce très court RFC met fin (provisoirement ?) à un très long et très agité débat au sein de l'IETF. Après de longs efforts, il réussit à réformer une vache sacrée du processus de normalisation des protocoles TCP/IP. Les RFC spécifiant ces protocoles avaient trois étapes sur le chemin des normes. Il n'y en a désormais plus que deux.
D'innombrables documents, cours et articles ont expliqué le
cheminement d'un RFC sur le chemin des normes,
tel que le décrit le RFC 2026. Un premier point
essentiel du RFC 2026 est que tous les RFC ne
sont pas sur le chemin des normes. Ils peuvent être simplement « expérimentaux » ou bien « pour information ». Un deuxième point
essentiel était que le chemin des normes comprenait trois étapes,
chacune marquant une progression vers le statut de norme complète et
achevée. L'étape atteinte par chaque RFC (pas encore adaptée à ce nouveau
RFC) est visible en http://www.rfc-editor.org/category.html.
Ce schéma était simple et bien décrit. Mais il a été peu appliqué en pratique. D'abord, même parmi les participants à l'IETF, peu ont vraiment compris les subtiles nuances entre les trois étapes. A fortiori, à l'extérieur, peu de gens prenaient leurs décisions techniques en fonction des niveaux atteints sur le chemin des normes ! (Je me souviens de réunions d'un groupe de travail anti-spam où la lobbyiste d'AOL pouvait ergoter sans fin sur les niveaux de maturité de normes comme SMTP, uniquement pour donner un habillage pseudo-juridique aux décisions déjà prises par AOL.) Enfin, on constate qu'avancer sur ce chemin était trop pénible. Certaines normes l'ont fait, car elles étaient poussées par un acteur décidé qui avait intérêt à un statut le plus élevé possible mais, dans d'autres cas, personne ne s'en est occupé et des tas de normes très stables et très déployées sont restées à une étape intermédiaire. C'est ainsi que EPP, bien que récent, a atteint l'étape suprême avec le RFC 5730, simplement parce que VeriSign a poussé très fort, alors que HTTP (RFC 2616) est coincé en étape Projet-de-norme, parce que personne n'a le courage de lobbyer pour qu'il avance. Même chose pour SMTP (RFC 5321) qui, comme HTTP, est indubitablement largement déployé et avec succès ! Bref, l'état actuel de ses RFC sur le chemin des normes ne reflète que très peu la qualité, la stabilité, la popularité et la maturité d'un protocole.
L'IETF a donc, non sans douleur, réfléchi depuis plusieurs années à une simplification du processus, en réduisant le nombre d'étapes à deux. Il y a eu de nombreuses discussions à ce sujet, certains voulant en profiter pour faire une refonte complète du système de normalisation à cette occasion. C'est finalement un choix plus conservateur qui a été fait : le changement reste limité. C'est déjà bien qu'il ait lieu, certains commençaient même à être sceptiques quant aux capacités de l'IETF à réformer ses processus.
Le RFC 2026 réclamait, pour bouger de la première étape (proposition de norme), un rapport explicite sur l'interopérabilité des mises en œuvre de la norme. Et pour atteindre la troisième (norme tout court), un déploiement massif était nécessaire. Ces deux critères sont désormais fusionnés en un seul, qui permettra le passage de la nouvelle première étape, à la nouvelle deuxième (et dernière) étape. Il faudrait plutôt dire la seconde étape, d'ailleurs, si on suit les règles du français soutenu, où « deuxième » implique qu'il y a d'autres étapes ensuite.
Les règles précises figurent en section 2. Il n'y a désormais que deux niveaux sur l'échelle :
- Proposition de norme (proposed standard). Il ne change pas de nom par rapport au premier niveau de l'ancien RFC 2026 car sa définition est exactement la même. Les critères pour atteindre ce niveau n'ont pas changé.
- Norme Internet (Internet standard). C'est la fusion des deux anciens niveaux Projet de norme (Draft standard, on notera que ce nom mal choisi avait entraîné de nombreuses confusions avec les Internet-Drafts) et Norme tout court (Standard ou Full standard).
Lors de son passage de la première à la seconde étape, une norme peut être révisée de façon mineure (c'est bien l'un des buts de ce chemin des normes que de permettre l'amélioration des normes, à la lumière de l'expérience). Mais, si l'utilisation réelle montre des problèmes sérieux, qui nécessitent une révision plus fondamentale du protocole, il faudra repartir de la première étape.
Donc, désormais, pour avancer de la première à la seconde étape, il faudra :
- Deux mises en œuvre indépendantes du protocole, qui interopèrent et sont effectivement déployées,
- Pas d'errata enregistrés sur la norme, si les erreurs ainsi notées peuvent gêner l'interopérabilité,
- Pas de fonctions inutilisées dans la norme, dans la mesure où cette mauvaise graisse accroît la complexité d'un protocole,
- Si la technologie normalisée requiert l'usage de brevets (ce qui n'est pas interdit par les règles de l'IETF, cf. RFC 8179), alors il faut également démontrer qu'au moins deux implémenteurs ont réussi à obtenir une licence pour l'usage des parties brevetées (en pratique, indépendamment des coûts, l'obtention d'une licence est en effet souvent un cauchemar bureaucratique).
Et pour les RFC actuels, on fait quoi ? La section 2.3 traite de la transition et précise que les RFC à l'étape Norme-tout-court passent automatiquement à l'état Norme-Internet. Ceux à l'étape Proposition-de-norme y restent (rappelez-vous que cette étape n'a pas changé). Et ceux à l'étape (supprimée) Projet-de-norme y restent provisoirement, en attendant une reclassification par l'IESG (qui aura le droit, dans deux ans, de les passer tous, d'autorité, à l'état de Norme-Internet).
Ce RFC supprime également certaines obligations, bonnes sur le principe mais qui, en pratique, bloquaient certains RFC sur le chemin des normes, sans bonne raison (section 3). C'est ainsi qu'il n'est plus nécessaire :
- De faire une revue annuelle des documents sur le chemin des normes pour voir s'ils peuvent avancer (cette revue n'a jamais eu lieu).
- De publier un rapport d'interopérabilité formel pour montrer qu'il y a plusieurs implémentations qui peuvent agir ensemble. Dommage, c'était une institution sympathique et utile. De tels rapports restent possibles, quoique facultatifs, et le RFC 5657 contient plein d'informations concrètes à ce sujet.
L'article seul
RFC 6286: AS-wide Unique BGP Identifier for BGP-4
Date de publication du RFC : Juin 2011
Auteur(s) du RFC : E. Chen, J. Yuan (Cisco Systems)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 11 octobre 2011
Un tout petit RFC pour régler un bête problème de définition dans le protocole BGP. L'identifiant d'un routeur BGP devait être une adresse IPv4. Avec l'épuisement de ces adresses, tous les routeurs n'en auront pas forcément une et ce RFC accepte explicitement comme identificateur n'importe quel numéro unique (à l'intérieur d'un AS).
Cet identifiant est défini par la norme BGP (RFC 4271, section 1.1) comme un nombre de 32 bits, qui doit être une des adresses IPv4 du routeur (cela assurait son unicité en réutilisant un nombre déjà alloué ; cette unicité est vérifiée lors de l'établissement de la connexion). La section 2.1 de notre RFC supprime l'obligation d'être une adresse IPv4, et ajoute celle que le numéro soit unique au sein de l'AS (ou, plus exactement, de la confédération, s'il y a plusieurs AS). Cette unicité par AS était nécessaire pour les cas où un routeur fait de l'agrégation de routes qu'il relaie (section 3).
Ce changement ne modifie donc pas le protocole BGP, ni le comportement de chacun des pairs BGP. Simplement, dans le cas d'un réseau purement IPv6, où aucun des routeurs n'avait d'adresse IPv4, ils pourront désormais prendre un nombre quelconque comme identifiant, sans violer de RFC.
L'article seul
echoping cherche un nouveau mainteneur
Première rédaction de cet article le 9 octobre 2011
Ce n'est jamais évident, pour le mainteneur d'un programme, d'avouer qu'il n'assume pas et qu'il doit passer la main. Mais c'est le cas pour moi en ce qui concerne la maintenance d'echoping, un petit utilitaire de test réseau, que je n'ai clairement pas le temps et l'attaque de maintenir.
echoping est un logiciel libre qui permet de tester les performances des applications distantes en envoyant des requêtes (plusieurs protocoles sont gérés) et en affichant le temps écoulé. Non, utiliser time ou des commandes équivalentes ne convient pas, notamment parce que ces commandes incluent des temps qu'on ne souhaite pas forcément mesurer comme le temps de chargement du programme ou comme celui de la résolution DNS. echoping, au contraire, ne déclenche son chronomètre qu'une fois que tout est prêt. À ma connaissance, il n'existe pas de programme généraliste équivalent.
echoping cherche donc un nouveau maître. Il faut s'y connaître en C, en réseaux, et avoir un peu de temps : le programme est simple (un seul mainteneur suffit très largement) mais a quand même pas mal de bogues pas résolus.
echoping est un très vieux programme (début en 1995) mais est toujours utile. Il a des fonctions originales comme l'affichage de la médiane (alors que la quasi-totalité des programmes de mesure n'affichent que la moyenne), comme la possibilité de greffons pour ajouter un nouveau protocole sans changer le moteur principal, etc.
L'article seul
Install Ubuntu / Linux on a Dell Latitude E6410
First publication of this article on 9 October 2011
I just installed Ubuntu on a Dell Latitude E6410 laptop. This article documents a few things about this machine and the issues I had.
L'article complet
RFC 6390: Guidelines for Considering New Performance Metric Development
Date de publication du RFC : Octobre 2011
Auteur(s) du RFC : A. Clark (Telchemy Incorporated), B. Claise (Cisco Systems)
Réalisé dans le cadre du groupe de travail IETF pmol
Première rédaction de cet article le 6 octobre 2011
Le groupe de travail IETF PMOL était chargé de travailler à la définition de métriques de haut niveau, proche de l'utilisateur (le groupe IPPM s'occupant, lui, des couches plus basses). Désormais fermé, il condense son expérience dans ce RFC, qui explique comment définir de nouvelles métriques, comme PMOL l'avait fait dans les RFC 5814 sur MPLS et RFC 6076 sur SIP. La section 3 résume ce but de ce RFC, définir un cadre utile.
La section 1 rappelle l'importance de la mesure, pour pouvoir améliorer les performances d'un système. Pour que ces mesures soient vraiment efficaces, il faut qu'elles s'appuient sur des métriques normalisées, une métrique étant une définition rigoureuse de la grandeur qu'on veut mesurer. Il faut aussi définir une méthode concrète pour faire la mesure et un format pour publier cette mesure. Pour les métriques « applicatives » de PMOL, ces mesures concernent des choses comme le temps de transfert d'un fichier, le temps de réponse d'un serveur DNS à une requête, etc (section 2.3).
Comme la plupart des RFC, on commence avec un peu de terminologie (section 2). D'abord, l'IETF aura désormais une Direction des Performances (Performance Metrics Directorate). C'est quoi ? Comme les autres Directions, c'est un organe transversal, composé d'experts du domaine, qui doit garder un œil sur tout travail IETF lié à la définition de métriques de performance. Ensuite, le RFC définit la qualité de service (QoS pour Quality of service) et la qualité du vécu (QoE pour Quality of Experience). J'ai déjà écrit sur la différence entre QoS et QoE et je trouve les définitions du RFC très embrouillées, et ne permettant pas de saisir la différence entre les deux concepts (la QoE vient d'une norme UIT, la E.800). Heureusement, la section 4 clarifie cette question. En gros, la QoS est une mesure scientifique de paramètres qui influencent le service rendu (par exemple, la latence ou la gigue), la QoE est la vision de l'utilisateur, qui peut être influencée par divers facteurs, y compris psychologiques. Bien sûr, la QoE va dépendre en partie de la QoS (par exemple, un taux de perte de paquets élevé va sérieusement baisser le débit TCP atteignable) mais le lien n'est pas évident (la norme UIT P.800 donne un exemple de reconstruction de QoE à partir de la QoS). Il y a aussi des facteurs techniques à la différence entre QoS et QoE, comme l'application utilisée : elle peut, indépendamment du bon ou mauvais comportement du réseau, influencer la QoE. Il y a enfin le contexte : tel problème de VoIP passera inaperçu pendant une communication de bavardage mais sera intolérable s'il s'agit d'un appel d'urgence.
La section 5 est le cœur du RFC, les conseils concrets sur la définition de nouvelles métriques. Premier point, déterminer le public visé (section 5.1). Qui va utiliser la métrique et pourquoi ? Est-elle destinée au laboratoire ou bien aux mesures sur des réseaux de production ? Quelle degré d'approxmation peut être accepté ? Et autres questions fondamentales.
Ensuite, la métrique elle-même (section 5.2). Pour qu'elle soit utile, il faut étudier si son absence causerait une sérieuse perte d'information, et si elle est corrélée au vécu de l'utilisateur (par exemple, un taux de pertes élevé - cf. RFC 7680 - entraine une baisse très nette de la capacité du « tuyau » TCP, attristant ainsi l'utilisateur). Mais certaines applications peuvent tolérer des pertes isolées tout en étant intolérantes à des moments de pertes massives. Dans ce cas, une meilleure métrique incluerait non seulement le taux de pertes moyen, mais sa distribution dans le temps (voir par exemple le RFC 3611).
Les grandeurs ne sont pas toujours mesurées, elles peuvent aussi être calculées à partir d'autres grandeurs (section 5.3). On trouve ainsi des compositions spatiales de métriques (RFC 5835, RFC 6049), comme lorsqu'on déduit le taux de pertes sur un chemin en faisant le produit du pourcentage de paquets qui passent, sur toutes les composantes du chemin. Il y a aussi des compositions temporelles (RFC 5835), par exemple le calcul d'un minimum en prenant le plus petit résultat d'une série de mesures.
Une fois qu'un a bien défini ce qu'on voulait, on peut écrire la spécification de la métrique (section 5.4). Il faut un nom (mais voir le RFC 6248 qui explique pourquoi il n'y a plus de registre de ces noms), une description (qui inclus les critères d'utilité présentés plus haut), une méthode de mesure, les unités de mesure, et des indications sur le choix des points de mesure (le temps de réponse à une requête SIP n'est pas le même sur l'UAC (logiciel client, le softphone) et l'UAS (logiciel serveur du fournisseur SI de l'abonné). La méthode de mesure doit permettre de répondre aux questions-pièges. Par exemple, la métrique « taux de perte de paquets » semble triviale à définir. On retire de 1 le résultat de la division du nombre de paquets arrivés par le nombre de paquets envoyés. Mais cette définition sommaire est insuffisante. Si des paquets sont dupliqués (c'est possible avec IP), comment les traite-t-on ? Et, pour compter le nombre de paquets arrivés, on les attend combien de temps ? Un retardataire est-il une perte (voir aussi la section 5.5.2) ? Un autre exemple est que la méthode de mesure peut décider délibérement d'éliminer les outliers, ces valeurs très éloignées de la moyenne, qui sont fréquentes sur les réseaux informatiques. C'est ainsi que les opérateurs Internet font en général payer leurs clients en « 95 percentile » (on élimine 5 % de valeurs qui sortent trop du rang, les outliers).
Outre ces points essentiels de la spécification, la définition d'une métrique peut aussi inclure une mise en œuvre (par exemple sous forme de code), des valeurs attendues pour certains cas (pour évaluer la qualité du résultat), etc. Plus délicat, la définition peut inclure des indications sur l'usage de la métrique, par exemple sur les valeurs « raisonnables ». Un utilisateur typique à qui on dit qu'il y a « 1 % de pertes » sur le réseau ne sait pas forcément quoi en faire. Lui dire que les performances de TCP commencent à baisser sérieusement dès 0,5 % de pertes, serait plus utile. De même, annoncer dans un système de transport de la voix un niveau sonore de -7 dBm0 n'est guère utile à l'utilisateur non expert en téléphonie si on n'ajoute pas que les valeurs normales sont entre -18 et -28 dBm0 et que le son est donc ici bien trop fort.
Notre RFC 6390 fournit un exemple complet de définition d'une métrique, en prenant le taux de perte du RFC 3611 comme exemple. Notez que cette définition est un peu floue quant au sort des paquets arrivant tardivement.
Dans le monde réel, aucune mesure n'est parfaite : divers problèmes limitent la qualité des mesures effectuées. La section 5.5 décrit ces problèmes : précision de l'horloge, présence ou non d'une middlebox (RFC 3303) qui fausse les résultats, etc.
Et enfin, la métrique ainsi normalisée doit préciser les différents paramètres utilisés, pour que les utilisateurs puissent comparer deux mesures différentes.
La section 6 est plutôt orientée vers le processus social de développement d'une nouvelle métrique : si on a une idée d'une métrique à normaliser, comment agir dans l'IETF pour augmenter les chances de succès ? Elle insiste par exemple sur la check-list des caractéristiques à vérifier (la métrique est-elle bien définie, par exemple) et sur la rôle de la Direction des Performances, qui va évaluer le futur RFC.
Un peu d'histoire (section 1.1): l'IETF avait déjà travaillé, dans des temps anciens, sur des métriques pour les applications. Ce furent le RFC 4710, centré sur les terminaux mobiles, ou les RFC 3611 ou RFC 6035 sur la téléphonie. Mais, pendant longtemps, les principales métriques développées étaient uniquement pour les couches 3 et 4. Notre RFC 6390 vise donc à élargir le bestiaire des métriques.
L'article seul
Et moi, qu'ai-je à dire sur la neutralité du réseau ?
Première rédaction de cet article le 2 octobre 2011
Ah, la neutralité du réseau Internet... Vaste sujet, où ça part vite dans tous les sens, où la bonne foi est assez rare, où définir les principes est une chose mais où les traduire en termes concrets est étonnamment difficile... Que puis-je ajouter à un sujet sur lequel tant d'électrons ont déjà été agités ? Je vais quand même essayer de trouver quelques points de ce débat qui n'ont pas été trop souvent abordés.
L'article complet
Apprendre le langage assembleur avec l'aide du compilateur
Première rédaction de cet article le 28 septembre 2011
Dernière mise à jour le 29 septembre 2011
Tout programmeur le sait, programmer en langage assembleur est difficile. Avant d'avoir pu écrire un Hello world, on doit maîtriser beaucoup de détails. Même chose pour des opérations triviales comme de la simple arithmétique. Mais le compilateur peut nous aider dans notre démarche de formation : il a souvent une option pour produire du code assembleur lisible, permettant au débutant d'écrire dans un langage de plus haut niveau, avant de voir le code produit par son programme.
Supposons qu'on veuille mettre 3 dans une variable, en langage assembleur. Et l'incrémenter de 1. Mais l'assembleur, c'est dur. On va donc écrire en C, car c'est plus facile :
% cat plus.c
main()
{
int a;
a = 3;
a++;
}
Et le compilateur gcc le traduit en langage assembleur
(option -S)
pour nous (le -O0 est pour éviter toute
optimisation), ici pour i386 :
% gcc -O0 -S -l plus.c
% cat plus.s
.file "plus.c"
.text
.globl main
.type main, @function
main:
pushl %ebp
movl %esp, %ebp
subl $16, %esp # C'est moi qui ait ajouté les commentaires
movl $3, -4(%ebp) # Mettre 3 dans la mémoire (movl = Move Long)
addl $1, -4(%ebp) # Ajouter 1 à ce qui est dans la mémoire
leave
ret
.size main, .-main
.ident "GCC: (Debian 4.4.5-8) 4.4.5"
.section .note.GNU-stack,"",@progbits
Pour lire ce code, il faut se souvenir que :
- un entier fait quatre octets (d'où le -4 devant l'identificateur de l'adresse %ebp)
- $ désigne un littéral donc $3, c'est 3
Des options de gcc comme -fverbose-asm permettent d'avoir davantage de
détails dans le code assembleur. On peut donc ensuite faire des
programmes C de plus en plus compliqué et apprendre l'assembleur en
voyant ce que fait le compilateur.
Si on veut du vrai langage machine à partir du code assembleur :
% as -alhnd plus.s
Encore plus fort, si on veut un listing avec le code machine et le code C en commentaire, pour mieux suivre ce qu'a fait le compilateur :
% gcc -O0 -c -g -Wa,-a,-ad plus.c ... 4:plus.c **** a = 3; 26 .loc 1 4 0 27 0006 C745FC03 movl $3, -4(%ebp) 27 000000 5:plus.c **** a++; 28 .loc 1 5 0 29 000d 8345FC01 addl $1, -4(%ebp)
Et avec d'autres processeurs (et donc d'autres langages assembleur) que le i386 ? André Sintzoff propose, pour les ARM :
; generated by ARM C/C++ Compiler, 4.1 [Build 481]
; commandline armcc [-S -O0 plus.c]
...
main PROC
MOV r1,#3 ; mettre 3 dans le registre r1
ADD r1,r1,#1 ; ajouter 1 à ce registre
MOV r0,#0 ; mettre 0 comme valeur de retour de la fonction
BX lr ; aller à l'adresse contenue dans le registre lr
ENDP
...
Et avec MIPS (sp = stack pointer, fp = frame pointer), un code très verbeux :
...
main:
.frame $fp,16,$ra # vars= 8, regs= 1/0, args= 0, extra= 0
.mask 0x40000000,-8
.fmask 0x00000000,0
subu $sp,$sp,16
sw $fp,8($sp)
move $fp,$sp
li $v0,3 # 0x3
sw $v0,0($fp)
lw $v0,0($fp)
addu $v0,$v0,1
sw $v0,0($fp)
move $sp,$fp
lw $fp,8($sp)
addu $sp,$sp,16
j $ra
.end main
...
Pour ceux qui veulent apprendre le langage assembleur en partant d'un langage de plus haut niveau, Olivier Bonaventure me recommande le livre « The Art of Assembly Language Programming », qui part d'un langage de haut niveau proche du C pour aller progressivement vers l'assembleur. Sinon, le livre de Hennessy & Patterson, « Computer Architecture: A Quantitative Approach » démarre aussi sur une description du langage assembleur en partant du C.
L'article seul
Les hommes frénétiques, d'Ernest Pérochon
Première rédaction de cet article le 28 septembre 2011
Dernière mise à jour le 24 octobre 2013
La littérature de science-fiction française de l'entre-deux-guerres recèle plein d'ouvrages curieux comme « La guerre des mouches » de Jacques Spitz, ou comme « Quinzinzinzili » de Régis Messac. Mais un des plus curieux est ce délirant récit d'une incroyable guerre mondiale, « Les hommes frénétiques », d'Ernest Pérochon.
Car l'auteur n'y va pas avec le dos de la cuillère : comme beaucoup de ceux qui avaient vécu les horreurs de la Première Guerre mondiale, Pérochon extrapole les progrès techniques à la guerre suivante. Mais ce ne sont pas simplement des avions plus gros et des bombes plus puissantes, que l'auteur imagine. Les physiciens mettent au point des tas d'armes nouvelles, toutes plus extravagantes les unes que les autres, afin d'augmenter le rendement des massacres, et leurs efforts culminent avec les féériques, des phénomènes mal décrits (l'auteur ne cherche pas à jouer les savants) mais spectaculaires, que les techniciens des deux camps lancent dans les régions adverses, et qui transforment les hommes en divers monstres. « Des maux inouïs, follement variés, s'abattirent sur l'humanité. ». À ne pas lire le soir, les cauchemars sont garantis.
Pérochon, qui n'a écrit que ce seul livre de science-fiction, n'apprécie pas la science dont la guerre précédente a bien montré l'absence de scrupules et la volonté sans faille à servir les armées. Les scientifiques de son livre sont tous des fous dangereux... ou des naïfs encore plus dangereux.
Une version en ePub gratuite de ce livre est
en http://editions-opoto.org/les-hommes-frenetiques/.
L'article seul
Gestion des documents structurés dans un VCS : exemple avec Subversion
Première rédaction de cet article le 26 septembre 2011
Dernière mise à jour le 27 septembre 2011
Ceux qui utilisent un VCS pour stocker des documents structurés (par exemple du XML) ont souvent le problème d'éditeurs trop intelligents qui reformattent brutalement le document, lui conservant son sens sous-jacent (encore heureux !) mais changeant complètement la représentation textuelle. Les VCS typiques, conçus pour du texte, croient alors que le document est différent et annonçent des changements qui ne sont pas réellement importants. Une des solutions à ce problème est de canonicaliser les documents et de demander au VCS de vérifier que cette canonicalisation a bien été faite. Comment on fait avec le VCS Subversion ?
Le problème n'est pas spécifique avec XML. Si une équipe de
développeurs C utilise
indent (ou le vieux logiciel cb) pour
pretty-printer leur code,
mais qu'ils ont mis des options différentes dans leur
~/.indent.pro (au passage, voici le mien), chaque
commit va engendrer des diff
énormes mais non significatifs. Mais le problème est plus fréquent
avec XML, où les auteurs utilisent rarement des éditeurs de
texte et passent en général par un logiciel spécialisé,
qui n'hésite pas à changer le fichier considérablement. C'est
typiquement le cas avec le format SVG, qu'on
édite rarement à la main. Si un membre de l'équipe utilise
Inkscape et l'autre
Sodipodi, les diffs entre
leurs commits ne seront guère utilisables. C'est un
problème que connait le projet CNP3,
enregistré dans la bogue #24. Ce problème a
aussi été discuté sur
StackOverflow.
Bien sûr, le problème n'est pas purement technique. Il y a aussi une part de politique : mettre d'accord les développeurs, fixer des règles. Mais la technique permet-elle ensuite de s'assurer qu'elles sont respectées ?
Avec le VCS Subversion, oui, c'est possible,
et c'est même documenté. Le
principe est d'avoir un script dit pre-commit,
que le serveur Subversion exécutera avant le
commit et qui, si le code de
retour indique une erreur, avortera le
commit. Voici un exemple, avec un
pre-commit qui teste qu'on soumet du
XML bien formé :
% svn commit -m 'Bad XML' bad
Sending bad
Transmitting file data .svn: Commit failed (details follow):
svn: Commit blocked by pre-commit hook (exit code 1) with output:
/tmp/bad:1: parser error : Opening and ending tag mismatch: x line 1 and y
<x a="3">toto</y>
^
Vous pouvez voir ce script en pre-commit-check-xml-well-formed.sh. Il est très inspiré du
script d'exemple (très bien documenté) fourni avec Subversion. Il utilise
xmllint pour déterminer si le fichier XML est
bien formé. Sinon, xmllint se termine avec un code de retour différent
de zéro, et, à cause de set -e, le script entier
se termine sur une erreur, ce qui empêche le commit
d'un fichier incorrect.
Si le dépôt Subversion est en
/path/example/repository, le script doit être
déposé dans le sous-répertoire hooks/ du dépôt,
sous le nom de pre-commit. Il doit être
exécutable (autrement, vous verrez une mystérieuse erreur sans
message, avec un code de retour de 255).
Plus ambitieux, un script qui teste que le XML soumis est sous
forme canonique (cette forme est normalisée dans un texte du W3C). Pour cela, il va canonicaliser le fichier
soumis (avec xmllint --c14n) et, si cela donne un
fichier différent de celui soumis, c'est que ce dernier n'était pas
sous forme canonique. Le commit est alors rejeté :
% svn commit -m 'Not canonical XML' bad Sending bad Transmitting file data .svn: Commit failed (details follow): svn: Commit blocked by pre-commit hook (exit code 3) with output: File "bad" is not canonical XML
Voici un exemple du travail de xmllint pour canonicaliser du XML :
% cat complique.xml
<?xml version="1.0" encoding="utf-8"?>
<toto >
<truc a="1" >Machin C </truc >café</toto>
% xmllint --c14n complique.xml
<toto>
<truc a="1">Machin C </truc>café</toto>
Le script de pre-commit est en pre-commit-check-xml-canonical.sh.
On peut se dire qu'il serait plus simple que le script canonicalise le fichier, qu'il l'était avant ou pas, épargnant ainsi ce travail aux auteurs. Mais Subversion ne permet pas de modifier un fichier lors d'un commit (cela impliquerait de changer la copie de travail de l'utilisateur). On ne peut qu'accepter ou refuser le commit.
Rien n'interdit d'utiliser le même principe avec du code, par
exemple en C. On peut envisager de tester si le
code est « propre » en le testant avec splint
dans le pre-commit. Ou bien on peut voir si le
code C a été correctement formaté en le reformatant avec
indent et les bonnes options, et voir ainsi s'il
était correct.
Et avec les DVCS ? Par leur nature même, ils rendent plus difficile la vérification du respect de règles analogues à celles-ci. Je ne connais pas de moyen de faire ces vérifications avec les DVCS existants. Il faudrait le faire lors d'un push/pull car un dépôt n'a aucune raison de faire confiance aux vérifications faites lors du commit par un autre dépôt. J'ai inclus à la fin de cet article des explications fournies par des lecteurs, pour d'autres VCS. Il me manque encore git. Un volontaire ?
Enfin, tout ceci ne résout pas tous les problèmes, par exemple pour l'édition SVG citée plus haut : les éditeurs SVG comme Inkscape aiment bien rajouter aussi des éléments XML à eux et, là, le problème du diff est plus délicat. Des outils comme Scour deviennent alors nécessaires, pour nettoyer le SVG.
D'autres exemples de scripts pre-commit sont
fournis avec Subversion en http://svn.apache.org/repos/asf/subversion/trunk/contrib/hook-scripts/. Parmi
eux, on note un programme
écrit en Python (rien n'oblige les scripts
pre-commit à être en
shell), qui vérifie un certain nombre de
propriétés (configurées dans son enforcer.conf)
sur des sources Java.
Pour le cas du VCS distribué darcs, Gabriel Kerneis propose : « On peut créer un patch qui définit un test. Si les autres développeurs appliquent ce patch, alors darcs exécutera automatiquement le test à chaque fois qu'ils voudront enregistrer un nouveau patch :
darcs setpref test 'autoconf && ./configure && make && make test'
darcs record -m "Add a pre-record test"
Mais comme vous le notez, cela ne prémunit pas d'un envoi de patch qui ne passe pas le test. Sur le répertoire central de référence (à supposer qu'il y en ait un), ou chacun sur son propre répertoire de travail, peut aussi ajouter un hook qui vérifiera que les patchs sont corrects avant de les appliquer :
# à vérifier que si le prehook échoue, le apply échoue bien - je ne
# l'ai jamais utilisé en pratique
echo 'apply prehook make test' >> _darcs/prefs/defaults
echo 'apply run-prehook' >> _darcs/prefs/defaults
Il est même possible d'effectuer la canonicalisation à l'aide de
prehook :
echo 'record prehook canonicalize.sh' >> _darcs/prefs/defaults
echo 'record run-prehook'
Voir les détails des options prehook (et posthook). Malheureusement (ou heureusement ?), il n'est pas possible de distribuer les prehooks et les posthooks sous forme de patch, comme avec setpref. Mais on peut toujours ajouter un test avec setpref qui vérifie si les prehooks sont présents et échoue sinon... »
Pour Mercurial, André Sintzoff explique :
« Il y a aussi des hooks qui sont notamment décrits
dans
la documentation.
Le precommit hook permet de contrôler avant le commit comme avec Subversion
Comme tu le fais remarquer, c'est local à l'utilisateur donc pas
obligatoire.
La solution est donc de se baser sur les hooks changegroup et
incoming qui contrôlent l'arrivée de nouveaux changesets dans un
dépôt via pull ou push.
Il suffit donc de mettre un hook changegroup avec la vérification qui va bien.
Bien entendu, il vaut mieux pour l'utilisateur d'utiliser un precommit
hook pour contrôler sur son dépôt local. »
Enfin, pour git, le bon point de départ
semble être http://book.git-scm.com/5_git_hooks.html.
Merci beaucoup à Gabriel Kerneis et André Sintzoff pour leurs contributions.
L'article seul
Faut-il un marché des adresses IPv4 ?
Première rédaction de cet article le 23 septembre 2011
Vu l'épuisement des adresses IPv4, la question revient régulièrement (mais n'a encore débouché sur rien de concret) de la pertinence d'un marché des adresses IPv4. Le capitalisme peut-il résoudre tous les problèmes, y compris celui de l'épuisement d'une ressource virtuelle ?
La question de départ est que les politiques des RIR, à l'heure actuelle, interdisent la vente et revente d'adresses IP (le « second marché », comme il y en a pour les noms de domaine). Les adresses sont en théorie allouées sur la base d'un besoin documenté (en français : en remplissant des papiers plein de mensonges, qu'on appelle des « prévisions optimistes »). L'idée est qu'un marché des adresses IP rendrait disponibles des adresses IP actuellement bloquées chez les premiers arrivants qui se sont largement servis.
Une bonne introduction au début est fournie par deux articles de l'excellent Ars Technica, un plutôt pour de Timothy B. Lee, « The case for a free market in IPv4 addresses » (le marché est tout de suite plus sympa lorsqu'on rajoute l'adjectif free...) et un plutôt contre de Iljitsch van Beijnum, « Trading IPv4 addresses will end in tears ».
Les deux articles résument bien les arguments essentiels. Pour :
- Ce marché aura lieu de toute façon, autant qu'il soit organisé (cela permettra au moins que les bases de données des RIR, telles qu'on peut y accéder par le protocole whois, restent à jour, en suivant les transferts de blocs d'adresses). Cet argument avait déjà été utilisé, par exemple par Geoff Huston,
- Sans ce marché, les adresses IP des premiers goinfres qui ont tout pris resteront bloquées, puisque lesdits goinfres n'ont pas de motivation pour les libérer. (Regardez les titulaires actuels dans le registre IANA. Les blocs marqués LEGACY sont ceux alloués sans contrôle et sans règles, avant la création des RIR.)
Et contre :
- Il est tout à fait injuste que les indiens et les chinois paient les riches pays de l'OCDE. Pour les récompenser d'avoir tout raflé au début ?
- Techniquement, ce marché risque d'augmenter le nombre d'entrées dans la DFZ, par désagrégation des blocs existants (vente d'un bloc en plusieurs morceaux),
- Ce marché prendra du temps et des efforts à être organisé, temps et efforts qui seraient mieux consacrés à migrer vers IPv6.
En français, on peut aussi lire le très bon article de Spyou, « Adresse IP à vendre ». Et en anglais, les excellents articles de l'Internet Governance Project comme celui consacré à l'achat des adresses IP de Nortel par Microsoft. On note que ce sujet de la politique d'attribution des adresses IP est très rarement discuté dans les organismes officiels de gouvernance, comme l'ICANN ou l'IGF, sans doute parce que c'est un sujet concret, et que ces organismes préfèrent pipeauter que de travailler.
L'article seul
BEAST et TLS, la fin du monde ?
Première rédaction de cet article le 23 septembre 2011
Dernière mise à jour le 25 septembre 2011
La presse a comme d'habitude annoncé n'importe quoi à propos de la faille de sécurité TLS qui a été officiellement publiée le samedi 24, vers 00h00 UTC (mais l'article n'est pas encore disponible officiellement). Les titres les plus sensationnalistes se sont succédés, « Le protocole SSL aurait été craqué », « Une faille dans le chiffrement SSL et des millions de sites HTTPS vulnérables », « Des pirates [sic] brisent le cryptage [re-sic] SSL utilisé par des millions de sites » et autres fariboles du même genre. C'est la loi habituelle des médias officiels : parler sérieusement et étudier son sujet ne rapportent rien. Faire de la mousse est bien plus efficace... et sera de toute façon oublié dans deux jours. Mais, derrière cette ridicule campagne de presse, qu'y a-t-il comme information fiable ?
La faille a été « pré-annoncée » par ses découvreurs, Juliano Rizzo et Thai Duong, qui ont pris soin de s'assurer que leur exposé à une conférence de sécurité peu connue ne passerait pas inaperçu. Leur plan comm' a été mis au point avec autant de soin que leur logiciel, même le nom de celui-ci (BEAST pour Browser Exploit Against SSL/TLS) a probablement fait l'objet d'une étude soignée, suivant les mœurs habituels dans le monde de la sécurité informatique. L'article n'a pas été officiellement publié mais des copies (apparemment incomplètes) ont fuité, par exemple sur Google Doc ou bien dans cette archive RAR. Comme, à l'heure où j'écris, il n'y a pas eu de publication scientifique sérieuse complète, on ne peut que deviner. Donc, en se fiant aux différentes rumeurs qui circulent et au code qui a été publié pour corriger la faille, que sait-on ?
L'attaque est apparemment de type « texte en clair choisi ». L'attaquant génère du texte de son choix et le fait chiffrer. L'observation du résultat lui donne alors des indications sur la clé de chiffrement utilisée. Les bons protocoles de chiffrement ne sont pas vulnérables à cette attaque, mais TLS 1.0 (et seulement cette version, normalisée dans le RFC 2246) a quelques particularités dans le chiffrement en mode CBC qui le rendent vulnérables. Ces vulnérabilités ont été corrigées dans la version 1.1 du protocole, publiée dans le RFC 4346 il y a plus de cinq ans (aujourd'hui, on en est à la 1.2, normalisée dans le RFC 5246). La section 1.1 du RFC 4346 expliquait les changements avec TLS 1.0 et notait déjà « The implicit Initialization Vector (IV) is replaced with an explicit IV to protect against CBC attacks. ». Mais corriger un protocole à l'IETF est une chose, déployer le correctif en est une autre.
Outre le changement de protocole, on pouvait aussi corriger le problème en bricolant les données à certains endroits, ce que fait la bibliothèque OpenSSL depuis... avant 2004 ! C'est d'ailleurs la publication de ce problème par l'équipe d'OpenSSL qui avait mené à TLS 1.1. (Un article plus détaillé sur ce sujet est celui de Gregory Bard en 2004. Le premier message rendant publique cette vulnérabilité est de 2002.) On le voit, il n'y a rien de nouveau, la plupart des failles de sécurité sont connues depuis longtemps lorsque la presse fait semblant de nous révéler des choquantes nouveautés.
Est-ce que cela veut dire que la nouvelle attaque n'est que du pschiiit ? Non, il y a au moins deux nouveautés, une mise en œuvre logicielle de l'attaque, et qui fonctionne (le fameux BEAST), et un certain nombre d'astuces et d'optimisations qui font toute la différence entre une faille connue et une faille attaquée. Le passage de la théorie à la pratique est donc un évenement important.
Faut-il alors paniquer ? Comme d'habitude, non. La faille ne semble pas triviale à exploiter. Il faut que l'attaquant puisse produire des données (le texte en clair choisi) sur le poste de la victime. BEAST peut utiliser plusieurs techniques pour cela (un navigateur Web moderne est un monstre bien trop compliqué et qui fournit plein de failles de sécurité à un attaquant), par exemple un code Java envoyé à la victime. Il faut aussi que l'attaquant puisse monter une attaque de l'homme du milieu, par exemple en prenant le contrôle d'un réseau WiFi mal protégé. L'attaque est donc possible mais pas simple et quelques précautions la rendent très difficile : ne faire que du HTTPS avec les sites sensibles, ne pas se connecter à ces sites sensibles depuis un réseau inconnu (genre le Wifi de Starbucks)... Ce sont des simples règles de défense en profondeur (certes, TLS était censé protéger contre le réseau WiFi dangereux, mais il n'est pas interdit de porter ceinture et bretelles).
Mais, puisque j'ai dit que la version 1.1 de TLS, qui corrige la faille fondamentale, date de 2006, et que le contournement dans OpenSSL, qui fonctionne même en version TLS 1.0, date de 2004, pourquoi l'attaque est-elle encore possible en 2011 ? Pour un simple problème de déploiement. D'abord, pour OpenSSL : cette bibliothèque est de loin la plus utilisée dans les serveurs HTTP, nettement devant GnuTLS. Mais chez les navigateurs Web, c'est plutôt NSS qui domine, et cette bibliothèque n'a pas le contournement. Le patch fait par les auteurs de Chromium à la bibliothèque qu'ils utilisent met d'ailleurs en œuvre la même technique qu'avec OpenSSL (une variante existe ; le patch pour Firefox est discuté dans la bogue #665814). Le problème est pourtant connu depuis longtemps (bogue Firefox #480514).
Actuellement, un très grand nombre de navigateurs Web
n'a
pas TLS 1.1 et aucune mesure prise uniquement sur le serveur ne
pourra résoudre cela. Si l'administrateur du serveur veut interdire le
vieux et dangereux TLS 1.0 (avec le module Apache de
GnuTLS, c'est apparemment GnuTLSPriorities
NORMAL:!VERS-TLS1.0), il cassera tout puisque la plupart
des navigateurs ne pourront pas se connecter. Une autre
approche pour le gérant de site Web est plutôt de ne pas utiliser les
algorithmes de chiffrement en CBC. Elle est
détaillé dans l'article
de PhoneFactor (c'est cette méthode qu'utilisent les serveurs
HTTP de Google). Côté client, une bonne
compilation de techniques limitant les risques est disponible sur StackExchange.
C'est donc moins sexy qu'une nouvellement découverte faille du protocole mais la réalité est là : le problème principal est celui d'une non-mise à jour des logiciels, pour parer aux vulnérabilités connues. Les raisons de cette non-mise à jour sont nombreuses. Une d'elles est que gérer les nouvelles versions du protocole peut empêcher les connexions avec les serveurs bogués. En effet, le protocole TLS est conçu pour que les anciens clients puissent interagir avec les nouveaux serveurs et réciproquement, mais cela suppose que toutes les implémentations respectent la norme (qui décrit avec précision comment assurer la compatibilité des différentes versions, cf. annexe E du RFC 5246). Or, il existe beaucoup de programmes bogués, qui bloquent toute évolution du protocole (la faille de renégociation de TLS, corrigée par le RFC 5746, connaît des problèmes de déploiement similaires, un tiers des serveurs étaient encore vulnérables en 2010). Résultat, la plupart des serveurs TLS coupent TLS 1.1 et 1.2 pour éviter tout problème comme le montre l'excellente enquête de Qualys publiée à Blackhat.
Pour savoir la version maximale que permet un serveur TLS, vous
pouvez utiliser l'outil en ligne de commande
gnutls-cli, livré avec GnuTLS (l'outil équivalent
d'OpenSSL ne semble pas capable de distinguer les différentes versions mineures
de TLS.) GnuTLS va tenter d'utiliser la version la plus élevée
possible. Avec un GnuTLS récent, qui gère TLS 1.2, contre un Apache
récent, lui-même avec GnuTLS :
% gnutls-cli --verbose --port 443 svn.example.org ... - Version: TLS1.2
Avec un serveur traditionnel (ici, celui de l'IETF) :
% gnutls-cli --verbose --port 443 www.ietf.org ... - Version: TLS1.0
Vous pouvez aussi utiliser sslscan pour tester un serveur mais, comme openssl, il ne sait pas distinguer les différentes versions de TLS 1.0.
Vous pouvez aussi tester votre propre site TLS en ligne depuis Qualys (il ne
semble pas gérer SNI, hélas). Quelques lectures pour approfondir le sujet : une bonne
explication pédagogique notamment du CBC, une autre
explication bien faite, notamment dans le contexte de
Tor, une très
bonne explication détaillée du problème, la déclaration
des développeurs de GnuTLS, un article
détaillé d'un des développeurs de Google Chrome, un très
bon résumé et analyse des conséquences pour le logiciel
OpenVPN, un bon résumé par
Microsoft, un autre chez
SANS, un article
plus détaillé de Bard (qui notait déjà les points essentiels, à savoir que la
vulnérabilité était close par TLS 1.1 ou bien par l'astuce de
l'enregistrement vide de OpenSSL), l'analyse du gourou TLS de l'IETF (très
clair, et un des rares articles écrits après
l'exposé de Rizzo et Duong), le très intéressant
récit du développement de BEAST par un de ses auteurs, un article
consacré uniquement aux techniques permettant de limiter l'effet de la
faille, la discussion
dans le groupe de travail TLS de l'IETF et, bien sûr, l'article
original, « Here Come The ⊕ Ninjas », dès
qu'il sera officiellement publié... En français, l'article
de SecurityVibes est intéressant. Ceux qui aiment lire le code
source pourront trouver une exploitation (je ne l'ai pas testée) de la
faille en
Java en http://pastebin.com/pM3ZbCdV ou bien dans l'archive RAR citée plus haut.
Merci à Mathieu Pillard pour ses commentaires.
L'article seul
RFC 6377: DKIM And Mailing Lists
Date de publication du RFC : Septembre 2011
Auteur(s) du RFC : M. Kucherawy (Cloudmark)
Réalisé dans le cadre du groupe de travail IETF dkim
Première rédaction de cet article le 22 septembre 2011
La sécurité, c'est compliqué. Ce n'est pas tout de définir des normes techniques comme DKIM, pour sécuriser le courrier électronique. Il faut encore étudier leurs conséquences pour tous les cas. Le courrier électronique ayant débuté il y a très longtemps, et n'ayant pas vraiment été spécifié dans tous les détails (son architecture n'a été officiellement décrite qu'en 2009, avec le RFC 5598), il représente un défi particulier pour tous ceux qui essaient de le sécuriser a posteriori. C'est ainsi que ce nouveau RFC s'attaque au cas particulier des listes de diffusion et étudie comment elles réagissent avec le mécanisme d'authentification DKIM.
D'abord, à quoi sert DKIM ? Normalisé dans le RFC 6376, DKIM permet de signer un message électronique. Sans lui, il
est trivial de fabriquer un faux message (prétendant venir de votre
banque et vous demandant de saisir votre mot de passe sur un
formulaire Web) et il n'y a aucun moyen d'acquérir des
certitudes sur ce message, où (presque) tout peut être faux. Avec
DKIM, un domaine de courrier peut signer le
message et ainsi en prendre la responsabilité. Si le message est signé
par mabanque.example, vous pouvez être sûr, pas
forcément de sa véracité, mais en tout cas d'un lien avec votre
banque. Contrairement à PGP, conçu pour
authentifier une personne, DKIM permet d'authentifier un domaine qui a
une responsabilité dans l'envoi de ce message.
Mais les listes de diffusion posent des problèmes spécifiques (section 1). DKIM avait été conçu avec l'idée que le message n'était pas modifié en cours de route. S'il l'est, c'est considéré comme une attaque qu'il faut détecter. Or, les gestionnaires de listes de diffusion ne respectent pas ce principe. Par exemple, il est fréquent (bien que ce soit une très mauvaise idée, cf. le RFC 4096) que le sujet soit modifié pour y inclure le nom de la liste entre crochets. De même, l'ajout d'instructions de désabonnement à la fin de chaque message est commun. De telles modifications sont peut-être honnêtes (dans l'esprit de celui qui les a décidés, ce ne sont pas des tentatives de fraude) mais, pour un logiciel de vérification, elles suffisent à invalider la signature.
Si les intermédiaires qui relaient un message le laissaient rigoureusement intact, ce serait non seulement une bonne idée pour les utilisateurs, mais cela permettrait à DKIM de continuer à fonctionner. Comme, parmi les intermédiaires, les MLM (Mailing List Managers) sont souvent les plus intrusifs, que peut faire DKIM pour gérer ce problème ?
- Est-ce une bonne idée de signer avec DKIM un message envoyé à une liste de diffusion ?
- Est-ce que le MLM devrait vérifier ces signatures en entrée ?
- Est-ce que le MLM devrait retirer les signatures existantes ?
- Et/ou mettre la sienne ?
Ce RFC ne normalise pas de réponse officielle à ces questions : il explique le problème et pointe du doigt les compromis à faire. La recommandation générale est « dans le cas typique, le MLM a intérêt à signer les messages qu'il relaie, et les vérificateurs à la destination ont intérêt à tenir compte de cette signature ». Le lecteur attentif aura noté que cette recommandation laisse plein de questions ouvertes...
Avant de détailler les problèmes, la fin de la section 1 rappelle
quelques éléments importants sur le courrier
électronique et les MLM (voir le
RFC 5598 pour une présentation générale de
l'architecture du courrier et sa section 5.3 sur les MLM). Les MLM (les gestionnaires de listes de
diffusion) n'ayant jamais fait l'objet d'une normalisation officielle
(le RFC 5598 a été écrit longtemps après), leur
comportement varie énormément. Lorsqu'un MLM fait une opération, il
est bien difficile de trouver un RFC qui dit noir sur blanc s'il est
en droit de la faire ou non. Une notion aussi simple que celle
d'identité (qui est l'auteur du message) n'est
pas évidente et DKIM a donc sagement décidé de ne
pas lier le domaine signant (celui qui est
indiqué par d= dans une signature DKIM) avec une
des « identités » présentes dans les en-têtes du message. Ainsi, le
domaine signant n'est pas forcément celui présent dans le champ
From:. Il peut refléter, par exemple, un domaine
qui a relayé le courrier et, en le signant, a affirmé une certaine
responsabilité pour ce message. Donc, si un MLM signe avec son domaine
un message venu d'un autre domaine, cela ne pose
pas de problème : c'est dans l'esprit de DKIM.
C'est l'interprétation qui va poser problème. Si j'écris un message
sur la liste smtp-fr@cru.fr avec mon adresse
professionnelle (bortzmeyer@nic.fr), qui est
responsable ? L'« auteur », mentionné dans le champ
From:, ou bien l'ex-CRU, qui
gère le MLM, ou
encore la personne mentionnée (ce terme est d'ailleurs malheureux)
comme « propriétaire » de la liste smtp-fr (aujourd'hui, Christophe Wolfhugel). Selon
le cas, un vérificateur sera plus intéressé par l'un ou l'autre des
responsables.
Je l'ai dit, la normalisation des fonctions des MLM n'a été faite
qu'a posteriori, n'est pas complète, et n'a pas été largement
adoptée. C'est ainsi que des normes comme le champ
List-ID: (RFC 2929) ou les
en-têtes donnant les mécanismes de désabonnement (RFC 2369) ne sont que partiellement déployés.
Bref, que conseille ce RFC ? Avant d'en arriver aux conseils pratiques, en section 4 et 5, il faut encore bien se mettre à jour sur la terminologie (section 2) et les principes de fonctionnement des MLM (section 3). En section 2, il faut d'abord lire les RFC sur DKIM, le RFC 5585, qui sert d'introduction et le RFC 6376 sur la norme elle-même. Ensuite, notre RFC introduit quelques termes nouveaux comme « gentil avec DKIM » (DKIM-friendly), qui désigne un MLM dont les actions n'invalident pas les signatures DKIM. À noter que cela ne dépend pas que du logiciel mais aussi de sa configuration (si on lui fait ajouter un pied de page en bas de chaque message, les signatures portant sur le corps du message sont invalidées), et des options du signeur (si le MLM modifie le sujet mais que le signeur n'a pas signé le sujet, le MLM sera considéré comme gentil avec DKIM).
Alors, comment fonctionnent les MLM ? Le problème, note la section 3, est qu'il y en a plusieurs sortes. Les différents rôles qui décrivent les acteurs du système de messagerie (auteur, signeur, récepteur, etc) sont évidents lorsque le message est un envoi direct d'Alice à Bob. Mais le MLM perturbe ce bel ordonnancement théorique. Déjà, il y a quatre types de MLM :
- Les alias, qui transmettent le message sans
autre changement que l'ajout de quelques en-têtes de trace (comme
Received:). La section 3.9.2 du RFC 5321 les mentionne. Ils ne changent que l'enveloppe SMTP, pas le message (en tout cas pas dans les parties signées). Les alias se mettent typiquement en œuvre sur Unix dans les fichiersaliases(directivesalias_databaseetalias_mapsde Postfix). Ces MLM sont gentils avec DKIM et n'invalident jamais les signatures (on notera que c'est le contraire avec SPF, RFC 7208, puisque ce dernier authentifie l'enveloppe et pas le message). - Les réexpéditeurs (resenders), qui reçoivent un message, lui font parfois subir quelques modifications, et renvoient ce message à la liste des abonnés. Ce sont les MLM typiques comme Mailman ou Sympa.
- Les auteurs. Ce sont les MLM qui créent le message, plutôt que de renvoyer un message qu'on leur a transmis. Pensez à une newsletter, ou au spam. Ils n'ont guère de problème avec DKIM puisqu'ils contrôlent toute la chaîne, depuis la rédaction initiale.
- Les synthétiseurs
(digesters) qui prennent plusieurs messages reçus
et les assemblent en un seul message, de type
MIME
multipart/digest(certains abonnés préfèrent lire ainsi). Cette synthèse est un nouveau message, mais composé à partir de messages pré-existants.
Dans les deux derniers cas, le MLM crée un nouveau message. Dans le second, le plus difficile, son rôle est moins clair. Si on veut approfondir ces nuances philosophiques, on peut consulter les sections 3.6.4 du RFC 5322 et 3.4.1 du RFC 5598.
Quels sont les effets exacts des MLM sur les messages signés ? La section 3.3 les détaille :
- Le sujet (
Subject:) est parfois modifié, pour ajouter le nom de la liste entre crochets. Cette pratique est très contestée (personnellement, je ne l'aime pas du tout, car elle modifie le message pour rien : si on veut trier le courrier, il est plus simple de le faire automatiquement via Sieve ou un système équivalent) mais, comme le note le RFC, contestée ou pas, elle ne va pas disparaître du jour au lendemain. Comme le sujet est un des éléments les plus importants de l'en-tête (c'est souvent ce que l'utilisateur regarde en premier) et qu'il est donc recommandé de le signer, ce comportement des MLM pose un problème. - En revanche, les en-têtes spécifiques aux listes de diffusion,
comme le
List-ID:du RFC 2929 ne posent a priori pas de problème, car ils sont rarement mis par les MUA et DKIM n'a pas de problème avec l'ajout de nouveaux champs. - Mais il peut aussi y avoir des changements dans le corps du message. Ils sont parfois mineurs (par exemple l'ajout de trois lignes d'instructions de désabonnement à la fin de chaque message). Mais cela suffit à rendre la signature DKIM invalide. DKIM permet de limiter la portée de la signature du corps (par exemple, de ne signer que les N premiers octets), ce qui permet l'ajout ultérieur de contenu (au prix d'une sérieuse baisse de sécurité). Si les changements sont plus significatifs (par exemple traduire le message HTML en texte seul), alors la signature sera invalide quoiqu'il arrive.
- Enfin, certains MLM suppriment les fichiers attachés (présents dans une partie MIME du message), les remplaçant par exemple par l'URL d'un service d'hébergement où le fichier a été déposé. Cela cassera également la signature.
Bref, à l'heure actuelle, les MLM sont souvent méchants avec DKIM. Dans le futur, cela évoluera peut-être mais on ne peut pas en être sûr, notamment parce que DKIM n'est pas assez important pour que les programmeurs de MLM changent leurs pratiques juste pour lui.
Une fois ces pratiques des MLM étudiées, le RFC a deux parties de conseils. L'une est consacrée aux MLM qui ne connaissent pas DKIM. Cette section 4 fournit donc des conseils aux signeurs et aux validateurs pour le cas où le message est passé par un tel MLM. L'autre, la section 5, est composée de conseils aux MLM qui connaissent DKIM et veulent bien faire. Voyons d'abord la section 4. Si un message signé va passer par un MLM non-DKIM, que faire ?
Idéalement, si l'auteur sait qu'un message va passer par un MLM non-DKIM, il devrait décider de signer ou pas, selon le comportement du MLM. La signature est risquée car le MLM peut faire une des modifications citées plus haut, rendant la signature invalide et inquiétant les récepteurs. (En théorie, une signature invalide doit être ignorée - RFC 6376, section 6.1 - sauf si le domaine émetteur publie en ADSP une politique plus stricte.) Le problème de cette approche est que l'émetteur ne connaît pas forcément les détails de tous les MLM et autres logiciels par lesquels son message risque de passer. Les administrateurs système qui activent DKIM sur leur infrastructure vont donc devoir décider sans connaître toute l'information. Les politiques strictes de signature et de vérification n'ont donc de sens qu'en cas de contrôle complet de la chaîne entre l'émetteur et le récepteur (ce qui exclut les MLM). Ne mettez donc pas une politique ADSP discardable si le courrier de ce flux de messages risque de passer par un MLM.
Cette absence d'information sur les MLM et autres logiciels intermédiaires touche également les vérificateurs. Une solution possible est d'exclure de la vérification les courriers passés par les listes. Ce serait évidemment un gros travail, sans compter la maintenance d'un tel système (lorsqu'une nouvelle liste apparait). Les vérificateurs ont donc tout intérêt à respecter l'un des principes de base de DKIM : ne pas jeter un message simplement parce que sa signature est invalide.
Et pour les MLM modernes et qui gèrent DKIM ? Que doivent-ils faire
? La section 5 expose, dans l'ordre du voyage du message, les recommandations qui leur sont
destinées. Ajouter des en-têtes (comme List-ID:)
ne pose pas de problèmes. C'est un comportement gentil (sauf dans le
cas où ces en-têtes étaient déjà présents et signés, ce qui est
rare).
Par contre, ajouter un texte à la fin du message, on l'a vu, casse
la signature. L'IETF n'a pas de politique
officielle à ce sujet et il n'existe pas de RFC
qui dise noir sur blanc « Thou SHALL NOT change the text,
even by a single byte ». Même si un tel RFC existait, rien
ne dit que les MLM suivraient ses consignes d'autant plus qu'il
n'existe pas d'en-tête standard pour des informations telles que les
conditions d'usage de la liste. DKIM a normalement une
technique pour ce cas : l'option l= qui indique
la portée de la signature (en nombre d'octets). L'ajout de texte après
la valeur indiquée par l= n'invalide pas la
signature. Mais cette méthode est déconseillée : un de ses
inconvénients est qu'un attaquant peut, lui aussi, ajouter ce qu'il
veut au message, sans craindre d'être détecté.
Notre RFC suggère donc, plutôt que d'ajouter à la fin de chaque
message un texte comme « Le spam et les remarques désagréables sont
prohibées sur cette liste. Les règles d'utilisation complètes sont
présentées en
http://www.example.com/lists/the-list/terms-of-use
», d'envoyer de telles informations de temps en temps via un message
automatique. Certes, ce sera ennuyeux (pensez à tous les messages de
Mailman le premier du mois) mais cela pourra
être filtré facilement.
Le problème d'ADSP (RFC 5617) est encore plus fort. ADSP permet de publier dans le DNS des directives de validation du genre « Je signe tout et correctement, vous pouvez jeter tout ce qui n'est pas bien signé ». Si un domaine publie une politique ADSP discardable, il interdit quasiment tout usage d'un MLM. Les seules solutions sont encore dans le futur. Par exemple, le RFC imagine des MLM qui connaissent ADSP et qui, lors de la réception d'une demande d'abonnement, testent la politique et, si elle est stricte, refusent l'abonnement. Mais la politique ADSP peut changer à tout moment, donc ce n'est pas une solution parfaite. Va-t-il falloir retester régulièrement ?
L'auteur d'un message signé est de toute façon toujours dans une
position difficile : il ne sait pas ce qui va arriver à son message et
il ne connaît pas les réglages des logiciels intermédiaires. La
section 5.5 recommande donc de séparer le courrier en deux : celui qui
sera forcément de bout-en-bout devrait être signé avec une identité et
une clé différente du courrier général, qui sera peut-être relayé par
un MLM. Ainsi, si mabanquecherie.example est le
domaine d'une banque, le courrier envoyé directement au client ne
devrait pas avoir le même d= que celui utilisé
pour le travail quotidien des employés.
Et sur le MLM lui-même, s'il connaît DKIM, quelles sont les bonnes
pratiques (section 5) ? La
plupart des MLM procèdent à une forme d'authentification, souvent
plutôt faible (par exemple, une vérification du
From: vis-à-vis de la liste des abonnés). Avec
DKIM, on pourrait avoir apparaître de nouvelles politiques, plus sûres
(par exemple une exigence que le message soit signé et que le domaine
indiqué par d= soit celui du champ
From:). Évidemment, aujourd'hui, très peu de
messages seront signés, donc le gérant du MLM va devoir décider quoi
faire des autres. En tout cas, une vérification positive est bon signe
et le RFC demande que le MLM ajoute dans ce cas un en-tête indiquant
une authentification réussie (RFC 7001).
Et que faire des signatures DKIM existantes, déjà présentes lorsque le MLM reçoit le message original ? Si le MLM est sûr de ne rien changer au message, il peut laisser ces signatures, qui apportent une information intéressante. Mais s'il modifie le message, il est sans doute plus prudent de les supprimer, pour éviter tout risque qu'un message arrive au destinataire final avec une signature invalide (ce que certains destinataires considéreront, en violation de la norme DKIM, comme une incitation à jeter le message).
Ensuite, il reste une autre décision à prendre pour le MLM : doit-il apposer sa propre signature ? Le RFC le recommande fortement, afin de bien marquer que le gérant du MLM accepte sa responsabilité pour le message qu'il transmet. Le risque est évidemment que certains destinataires interprètent cette signature comme signifiant que le message a été authentifié dès le début. Toutefois, DKIM en lui-même ne peut rien faire dans ce cas : il y aura toujours des gens pour mal interpréter une signature et lui attribuer un poids qu'elle n'a pas.
Continuons le trajet du message : nous approchons de la fin avec les conseils aux vérificateurs. En gros, le RFC demande que ceux-ci traitent les messages des listes comme n'importe quel autre message (dans l'état actuel du déploiement des RFC 2919 et RFC 2369, il n'y a pas de moyen fiable de savoir si un message est passé par un MLM).
Les listes de diffusion de l'IETF signent tous les messages
sortants, depuis
juillet 2011, avec d=ietf.org (les
signatures originelles sont apparemment retirées). Barry Leiba
a bien résumé ce que cela apporte : « What it does is allow you to assure yourself that the message was,
indeed, from an IETF mailing list (well, from an IETF email server),
and that it wasn't that someone tried to spoof that. That, in turn,
allows you to confidently increase your trust that the message is not
spam in proportion to your confidence in the IETF's spam-filtering
capabilities. ». Voici une telle signature :
DKIM-Signature: v=1; a=rsa-sha256; c=relaxed/simple; d=ietf.org; s=ietf1;
t=1311614276; bh=qLpIZcZ8XeP5xTrgVPRjnXlZjXWiz9DqXpACtarsL0Q=;
h=Date:From:To:Subject:Message-ID:MIME-Version:List-Id:
List-Unsubscribe:List-Archive:List-Post:List-Help:List-Subscribe:
Content-Type:Content-Transfer-Encoding:Sender;
b=ppseQobrat1rQ+Brsy2LSpMAA79YgaFJ7PK2EG1N4w0zS2IZBqDQiXYHJxG/wv4wl
GOd42GtThBVxB5BmBhkTn8M1Rqz+ZhW2pLPlcI1zHcmLmJHLMt1wC6R3wiCi4bipVd
CszNeb58HSYGNDQmvnW9dAxi38pL/kjunJTpmVT4=
Le RFC mentionnait à plusieurs reprises les MLM qui comprennent DKIM. À ma connaissance, aujourd'hui, il n'y a que Sympa dans ce cas. DKIM y a été introduit dans la version 6.1. Quelqu'un connaît d'autres implémentations ?
Un bon article de fond en français sur la coexistence entre DKIM et
les listes de diffusion est l'article de Serge Aumont aux
JRES, « DKIM
et les listes de diffusion ». Sinon, concernant les modifications d'en-tête par les MLM, un
article toujours utile, quoique centré sur les modifications du
Reply-To:, est « "Reply-To" Munging Considered Harmful ».
Merci à Serge Aumont pour sa relecture.
L'article seul
RFC 6376: DomainKeys Identified Mail (DKIM) Signatures
Date de publication du RFC : Septembre 2011
Auteur(s) du RFC : D. Crocker (Brandenburg InternetWorking), T. Hansen (AT&T Laboratories), M. Kucherawy (Cloudmark)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dkim
Première rédaction de cet article le 22 septembre 2011
Le courrier électronique, on le sait,
n'offre, en natif, aucun mécanisme
d'authentification des utilisateurs. Il est
donc assez facile d'envoyer un courrier prétendant venir de
Bill.Gates@microsoft.com. DKIM, spécifié dans
notre RFC, est la dernière tentative de combler ce manque. (La
première version de DKIM était normalisée dans le RFC 4871. Cette nouvelle version n'apporte pas de changements cruciaux.)
Notons d'abord que, si le courrier électronique, tel que décrit dans les RFC 5321 ou RFC 5322, ou bien leurs prédécesseurs, n'offre pas d'authentification des utilisateurs, ce n'est pas parce que leurs concepteurs étaient imprévoyants ou trop confiants dans la nature humaine. C'est tout simplement parce que le problème est très complexe, ne serait-ce que parce qu'il n'existe pas de fournisseur d'identité unique sur Internet, qui pourrait jouer le rôle que joue l'État avec les papiers d'identité.
Mais l'absence d'authentification devient de plus en plus regrettable, d'autant plus qu'elle est activement exploitée par les spammeurs et les phisheurs pour leurs entreprises malhonnêtes. Non seulement il est difficile de retrouver le véritable envoyeur d'un message, mais une personne tout à fait innocente peut voir son identité usurpée. Ces problèmes de sécurité sont documentés dans le RFC 4686.
De nombreuses tentatives ont eu lieu pour tenter de traiter ce problème. Certaines ont connu un déploiement non négligeable comme PGP (normalisé dans le RFC 4880), surtout connu pour ses services de chiffrement mais qui peut aussi servir à l'authentification.
PGP est surtout utilisé dans des environnements à forte composante technique, au sein de groupes d'experts qui se connaissent. D'autres protocoles ont tenté de traiter le problème de l'authentification de la masse d'utilisateurs de Hotmail ou de Wanadoo.
DKIM aborde
le problème différemment. Comme SPF, il vise surtout à authentifier le
domaine dans l'adresse électronique, en d'autres
termes à garantir que le courrier vient bien de
microsoft.com, laissant à
Microsoft le soin de dire si la partie gauche
(Bill.Gates) est authentique ou pas. En deux
mots, DKIM permet à un domaine de proclamer qu'il a une part
de responsabilité dans un message, et donc que ce domaine
peut répondre dudit message. On trouve une introduction générale à
DKIM dans le RFC 5585 et une réfutation de
beaucoup d'erreurs à propos de DKIM en « The truth about:
Trust and DKIM ».
Mais, contrairement à SPF, DKIM ne procède pas par énumération des adresses IP des MTA autorisés à émettre du courrier pour le compte d'un domaine mais par signature cryptographique.
Le principe de DKIM est le suivant (les exemples sont tirés de l'excellente annexe A du RFC). Un message émis ressemble à :
From: Joe SixPack <joe@football.example.com> To: Suzie Q <suzie@shopping.example.net> Subject: Is dinner ready? Date: Fri, 11 Jul 2003 21:00:37 -0700 (PDT) Message-ID: <20030712040037.46341.5F8J@football.example.com> Hi. We lost the game. Are you hungry yet? Joe.
DKIM (qui peut être installé dans le MUA mais sera en général plutôt dans le MTA, cf. section 2.1 et annexe B) le signe et ajoute un en-tête DKIM-Signature (section 3.5 pour sa syntaxe) :
DKIM-Signature: v=1; a=rsa-sha256; s=brisbane; d=example.com;
c=simple/simple; q=dns/txt; i=joe@football.example.com;
h=Received : From : To : Subject : Date : Message-ID;
bh=2jUSOH9NhtVGCQWNr9BrIAPreKQjO6Sn7XIkfJVOzv8=;
b=AuUoFEfDxTDkHlLXSZEpZj79LICEps6eda7W3deTVFOk4yAUoqOB
4nujc7YopdG5dWLSdNg6xNAZpOPr+kHxt1IrE+NahM6L/LbvaHut
KVdkLLkpVaVVQPzeRDI009SO2Il5Lu7rDNH6mZckBdrIx0orEtZV
4bmp/YzhwvcubU4=;
Received: from client1.football.example.com [192.0.2.1]
by submitserver.example.com with SUBMISSION;
Fri, 11 Jul 2003 21:01:54 -0700 (PDT)
From: Joe SixPack <joe@football.example.com>
To: Suzie Q <suzie@shopping.example.net>
Subject: Is dinner ready?
Date: Fri, 11 Jul 2003 21:00:37 -0700 (PDT)
Message-ID: <20030712040037.46341.5F8J@football.example.com>
Hi.
We lost the game. Are you hungry yet?
Joe.
L'en-tête en question spécifie l'algorithme de chiffrement utilisé
(ici SHA-256 et RSA), le domaine signant (ici
example.com), un sélecteur
(ici brisbane) qui servira à sélectionner la
bonne clé (section 3.1), les en-têtes effectivement signés (ici Received :
From : To : Subject : Date : Message-ID, cf. la section 5.4
sur le choix des en-têtes à signer), la signature elle-même et
l'identité de l'émetteur (ici
joe@football.example.com). (La différence entre
le domaine, identifié par d= et l'« identité »
indiquée par i= est subtile.)
L'identité est indiquée dans la signature pour éviter les longs
débats sur l'identité la plus pertinente parmi toutes celles présentes
dans un message (cf. le RFC 4407 pour un des
exemples d'algorithme qui croit naïvement qu'il existe une et une
seule bonne identité). Le signeur n'est donc pas forcément
l'émetteur (section 1.2). Notre RFC note que le
MUA doit en tenir compte et doit afficher
l'adresse qui est authentifiée, pas seulement celle qui se trouve dans
le champ From: et qui peut être différente.
Le programme qui veut vérifier la signature (en général un
MTA mais cela peut être le
MUA) va devoir récupérer la clé de
signature. DKIM ne souhaitant pas dépendre des lourdes et chères
autorités de certification, la clé est récupérée via le
DNS (section 3.6.2 ; d'autres
méthodes que le DNS sont en cours de normalisation mais ça n'avance pas). Pour le message ci-dessus, la requête DNS
sera brisbane._domainkey.example.com et un
enregistrement DNS de type TXT contiendra la clé. Pour voir une clé
réelle, vous pouvez taper dig TXT
beta._domainkey.gmail.com. ou dig TXT
ietf1._domainkey.ietf.org. DKIM n'impose pas d'utiliser
DNSSEC et la sécurité de la clé ainsi ramassée
peut être faible (cf. section 8.5 : DKIM ne prétend pas être aussi
fort que PGP).
Un des problèmes difficiles en cryptographie est que les messages
sont souvent modifiés en cours de route. Par exemple, un logiciel
imposé par le direction de l'entreprise va ajouter automatiquement un
stupide message pseudo-légal comme « Ce message e-mail et les pièces
jointes sont transmis à l'intention exclusive de ses destinataires et
sont confidentiels et/ou soumis au secret professionnel. Si vous
recevez ce message par erreur, merci de le détruire et d'en avertir
immédiatement l'expéditeur par téléphone ou par mail. Toute
utilisation de ce message non conforme à sa destination, toute
diffusion ou toute publication, totale ou partielle, est interdite,
sauf autorisation. L'intégrité de ce message n'étant pas assurée sur
Internet, nous ne pouvons être tenu responsables de son contenu. »
(notons que le dernier point devient faux avec DKIM). Ou
bien une liste de diffusion va mettre des
instructions de désabonnement (pour ces listes, voir aussi le RFC 6377). DKIM traite ces problèmes avec deux
méthodes : une canonicalisation (section 3.4 du RFC) du message (plusieurs algorithmes sont
disponibles, plus ou moins violents) pour limiter les risques qu'une modification triviale ne
fausse le calcul de la signature et l'option l=
qui permet d'indiquer sur quelle distance le message est signé. Si on
indique l=1000, seuls les mille premiers octets seront signés et une
liste pourra ajouter un message automatiquement à la fin, cela
n'invalidera pas la signature. (Cette technique est déconseillée, voir
la section 8.2.)
Malheureusement, DKIM encourage également (section 5.3) à remplacer les caractères codés sur 8 bits (comme l'UTF-8 ou le Latin-1) par des horreurs comme le Quoted-Printable, pour limiter les risques qu'une conversion automatique en Quoted-Printable, comme le font certains MTA, n'invalide la signature. Des années d'efforts pour faire passer les caractères 8-bits dans le courrier sont ainsi négligées.
DKIM a nécessité la création de plusieurs registres à l'IANA (section 7) comme le registre des méthodes pour récupérer la clé (aujourd'hui, seulement le DNS).
Parmi les limites de DKIM (qui sont celles de beaucoup de solutions de sécurité, un domaine complexe où il faut faire beaucoup de compromis), il faut aussi se rappeler qu'un attaquant actif peut tout simplement retirer complètement une signature. Tant que les domaines ne publient pas leur politique de sécurité (en suivant le RFC 5617) et donc annoncent « Nous signons toujours », cette attaque passera inaperçue.
Quels sont les changements depuis la première version de DKIM,
normalisée dans le RFC 4871 ? L'annexe E les
résume. Premier point, les changements sont mineurs : comme le note
l'annexe C.2, les anciennes et nouvelles implémentations de DKIM
peuvent communiquer sans problèmes. Mais la sortie de ce nouveau RFC
ne s'est pas faite sans mal. Il y avait des désaccords sérieux sur
l'avis à donner en terme de quels en-têtes devraient être signés, sur
le lien entre le domaine signant et les autres domaines de l'en-tête
(typiquement celui dans le from:), la façon de
traiter les attaques par ajout d'en-têtes (non couverts par la
signature originale), etc. Beaucoup d'erreurs ont été
détectées dans le RFC 4871 et corrigées ici, la
plus grosse étant celle qui avait fait l'objet d'une mise à jour
d'urgence dans le RFC 5672, désormais
inutile. D'autre part, le nouveau RFC comporte davantage de texte
d'introduction et d'architecture. Enfin, l'option de signature
g= (qui contrôlait la granularité de la clé) a été abandonnée.
Il y a aussi une différence
complète entre les deux RFC, en ligne.
Aujourd'hui, tous les messages sortant de Gmail sont signés avec DKIM et des implémentations de DKIM existent pour plusieurs logiciels (comme le DKIM milter de sendmail). Le rapport d'implémentation du RFC 4871 en donne une bonne liste. Mais peu de domaines signent et encore moins de domaines vérifient les signatures aujourd'hui (le RFC 5863 discute les questions de déploiement).
Enfin, notons que
DKIM est une technologie d'authentification,
pas d'autorisation. Cette distinction est cruciale. DKIM peut prouver
que le message vient bien de
Nicolas.Sarkozy@elysee.fr (plus exactement, DKIM
peut dire que le message a bien été approuvé par elysee.fr), il ne peut pas dire si
la personne en question est digne de confiance ou si elle va
réellement se préoccuper de « la France qui se lève tôt ».
L'article seul
RFC 6369: ForCES Implementation Experience Draft
Date de publication du RFC : Septembre 2011
Auteur(s) du RFC : E. Haleplidis, O. Koufopavlou, S. Denazis (University of Patras)
Pour information
Première rédaction de cet article le 21 septembre 2011
Le protocole ForCES (Forwarding and Control Element
Separation) sert à la communication
entre les éléments d'un même routeur. Il permet
à la « tête » du routeur (le CE Control Element) de
donner des instructions aux « jambes » (les FS Forwarding
Element), par exemple de dire où envoyer le trafic pour
2001:db8::/32. Le fait que ce protocole soit
normalisé pourrait permettre dans le futur d'acheter des routeurs en
plusieurs parties, par exemple un PC avec
du logiciel libre pour le CE et des
ASIC matériels spécialisés pour les FE, le tout
communiquant dans la joie. Ce RFC fait le court
bilan
d'une des équipes qui a le plus travaillé à la programmation de
ForCES, à l'Université de Patras.
Le cahier des charges de ce système figure dans le RFC 3654. ForCES est normalisé dans le RFC 5810 et son architecture est décrite dans le RFC 3746. Il a déjà fait l'objet de deux rapports d'interopérabilité (dans le RFC 6053 et le RFC 6984), vérifiant que les trois mises en œuvre de ForCES coopéraient correctement. L'une de ces mises en œuvre était celle de l'Université de Patras. Les auteurs de cette implémentation tirent, dans ce nouveau RFC, les leçons de leur expérience, afin qu'elle puisse profiter à d'autres.
Petit rappel de ForCES (section 1) : le CE (Control Element) est la partie intelligente du routeur, celle qui fait tourner les protocoles compliqués comme OSPF. Le FE (Forwarding Element) peut être réalisé en logiciel mais, sur les routeurs haut de gamme, il s'agit plus souvent d'un circuit matériel, puisqu'il doit faire passer des millions de paquets à la seconde. Le LFB (Logical Function Block) est une fonction dans le FE, que le CE contrôle. Par exemple, la fonction « comptage des paquets » (à des fins de surveillance et de statistique) est un LFB. Un LFB fait partie d'une classe, qui a des instances (un routeur a souvent plusieurs exemplaires d'un LFB de chaque classe). Pour décrire un LFB, on utilise le modèle du RFC 5812 et éventuellement la bibliothèque de fonctions du RFC 6956. Le protocole ForCES gouverne la communication entre CE (le maître, qui donne des ordres) et FE (l'esclave, qui obéit). S'il y a des discussions entre CE ou bien entre FE, elles se font en dehors de ForCES. De même, le mécanisme par lequel sont configurés CE et FE n'est pas normalisé. Le protocole ForCES peut être transporté entre FE et CE de diverses manières, mais celle recommandée est le transport du RFC 5811.
Le RFC suit l'architecture de ForCES (section 3). La configuration initiale du FE et du CE (non spécifié par ForCES) doit permettre de fixer l'identificateur de chaque élément, le transport utilisé et l'adresse IP (si le transport se fait sur IP).
Le transport standard de ForCES, normalisé dans le RFC 5811, utilise SCTP. Lors des tests d'interopérabilité, ce transport avait même été utilisé entre un site en Chine et un en Grèce mais, évidemment, dans un routeur réel, les distances sont moins longues. (Comme ForCES permet de séparer FE et CE, ils ne sont pas forcément dans la même boîte, et il peut même y avoir des choses bizarres, comme un pare-feu entre eux.) Bien moins connu que son concurrent TCP, SCTP pose un problème au programmeur : les bibliothèques existantes ne permettent pas toujours de l'utiliser simplement. La section 4 contient un tableau des disponibilités pour C, C++ et Java. Par exemple, pour Java sur Windows, il n'y a pas grand'chose à attendre. (Les auteurs ont également eu des difficultés avec un autre problème Java, la gestion des types non signés, pour laquelle ils recommandent Java Unsigned Types.)
Le protocole n'est pas trivial à programmer. En effet, la liste des classes de LFB possibles n'est pas figée. De nouveaux LFB peuvent apparaître à tout moment. En outre, un message peut comporter plusieurs opérations, et plusieurs LFB par opération. C'est bien sûr une... force du protocole (il est très puissant et complet) mais cela le rend plus complexe. Il est donc très difficile de créer du code générique, capable de traiter tous les messages. C'est sans doute la principale difficulté que rencontre l'implémenteur de ForCES. La section 3.4 fournit des pistes possibles, ainsi que des algorithmes d'encodage et de décodage des messages. Les informations dans le message pouvant être emboîtées, l'utilisation de la récursion est recommandée.
L'article seul
RFC 6393: Moving RFC 4693 to Historic
Date de publication du RFC : Septembre 2011
Auteur(s) du RFC : M. Yevstifeyev
Pour information
Première rédaction de cet article le 19 septembre 2011
L'expérimentation des ION (IETF Operational Notes, une série de documents IETF plus légers que les RFC) ayant été abandonnée, ce RFC reclassifie officiellement le RFC 4693, qui créait les ION, comme n'ayant qu'un intérêt historique.
Ce nouveau RFC, de même que la décision d'abandon, ne s'étend guère sur les raisons de l'échec et ne tire pas de bilan.
L'article seul
Fiche de lecture : Kamerun !
Auteur(s) du livre : Thomas Deltombe, Manuel Domergue, Jacob Tatsitsa
Éditeur : La découverte
978-2-7071-5913-7
Publié en 2011
Première rédaction de cet article le 17 septembre 2011
Ce livre est de loin le plus détaillé qui existe sur une guerre coloniale un peu oubliée, celle qui a été menée au Cameroun de 1955 à 1971. Éclipsée par la guerre d'Algérie qui se déroulait au même moment, la lutte des troupes françaises contre les nationalistes de l'UPC s'est même prolongée après l'indépendance (théorique) du pays, dans une relative indifférence. Si cette guerre sans nom avait déjà été mentionnée (par exemple par François-Xavier Verschave dans ses ouvrages), on ne peut pas dire qu'elle soit bien connue des français d'aujourd'hui, ni d'ailleurs des camerounais, qui n'ont eu droit qu'à la version officielle. Ce fut pourtant une des très rares guerres coloniales gagnées par l'armée française. Mais les méthodes utilisées font que celle-ci a préféré ne pas trop se vanter de cette victoire.
Le Cameroun (l'orthographe « Kamerun » est celle choisie par les nationalistes) était une colonie allemande, que les français et les anglais se sont partagé après la première Guerre mondiale. En théorie, il s'agissait juste d'un mandat de la SDN, puis de l'ONU et la Cameroun n'était pas officiellement une colonie. En pratique, l'exploitation du pays ne fut guère différente de ce qui arriva dans les autres colonies d'Afrique. Dans les années 50, un mouvement nationaliste, analogue à celui qui apparaissait dans d'autres pays occupés, se développa, et se rassembla dans l'Union des Populations du Cameroun (UPC, dirigée par Ruben Um Nyobe, qui sera assassiné en 1958). Tout de suite, les colons français décidèrent que cette UPC n'était pas fréquentable, ne pouvait pas être retournée (comme l'a été le RDA de Houphouët-Boigny) et la guerre commença très rapidement. Ce fut une guerre coloniale classique, avec regroupements forcés de la population, massacres un peu partout, utilisation massive de collaborateurs locaux pour accomplir le sale boulot, tortures et assassinats. Cette guerre se déroulant sans témoins (l'ONU, normalement en charge de la tutelle, avait choisi de fermer les yeux), il est très difficile, même aujourd'hui, d'en tirer un bilan quantitatif. Le nombre total de morts de la guerre restera ainsi sans doute à jamais inconnu. (Les auteurs notent avec honnêteté quand ils n'ont pas pu établir un fait ou un chiffre ; c'est ainsi que l'utilisation du napalm par l'aviation française, dénoncée par les nationalistes, n'a pu être prouvée.) Il n'y a sans doute pas eu de tentative de génocide, mais il ne s'agissait pas non plus d'une « simple opération de police » contre « des bandits isolés » mais d'une vraie guerre, notamment en Sanaga-Maritime et en pays bamiléké.
Cette guerre resurgit aujourd'hui à travers l'enquête menée par les auteurs, deux journalistes et un historien. Ils ont fouillé les archives (qui ne contiennent pas tout, notamment les opérations menées par les forces supplétives sont nettement moins documentées), et interrogé de nombreux témoins et combattants. Il était temps : au moins un d'entre eux, le général Lamberton, est mort juste avant que les auteurs ne lui demandent ses souvenirs. Il ne « parlera » que via les notes qu'il prenait en marge des livres de sa bibliothèque... Mais beaucoup d'autres ont parlé, des deux côtés, et permettent ainsi de mieux comprendre l'ampleur de la guerre qui fut menée pour empêcher une vraie indépendance.
Car le Cameroun a fini par devenir indépendant : l'UPC sérieusement affaiblie, la France a fini par accorder l'indépendance à sa colonie, en 1960, avec un gouvernement qui, contrairement à l'UPC, comprenait les intérêts français, un vrai gouvernement françafricain. L'« indépendance » n'a pas mis fin à la guerre. Celle-ci a au contraire continué, menée cette fois officiellement par l'armée camerounaise, encadrée de près par l'armée française. Les derniers maquis n'ont été détruits que dix ans après.
Aujourd'hui, tout cela semble bien lointain, les acteurs de l'époque sont morts ou sont aujourd'hui à la retraite. Mais le système françafricain tient toujours, ainsi qu'un de ses mythes fondateurs comme quoi les indépendances en Afrique noire auraient été acquises pacifiquement. C'est donc une bonne chose que les auteurs aient sérieusement enquêté sur cette guerre, avant que toutes les traces soient effacées. « Quand le lion aura sa propre histoire, l'histoire ne sera plus écrite par le chasseur. »
Le livre est completé par un site Web, où on trouve par exemple les vidéos des interviews réalisés pour le film.
Rue89 avait publié un très bon article sur ce livre.
L'article seul
Install Ubuntu / Linux on a Dell Vostro 3350
First publication of this article on 16 September 2011
Last update on of 22 October 2011
I just installed Ubuntu on a Dell Vostro 3350 laptop. This article documents a few things about this machine and the issues I had.
L'article complet
Où doit-on mesurer la capacité réseau, chez le FAI ou plus loin ?
Première rédaction de cet article le 14 septembre 2011
Dernière mise à jour le 1 janvier 2012
Pendant les discussions sur la mesure de la capacité (souvent improprement nommée « débit » ou « bande passante ») d'un accès à l'Internet (par exemple au sein du « groupe de travail multilatéral sur la qualité de service » de l'ARCEP, créé suite à la septième proposition de l'ARCEP sur la neutralité du réseau), un point qui revient souvent est celui de l'endroit où doit se terminer la mesure. Cet endroit doit-il être chez le FAI ou plus loin dans l'Internet ?
Le but est de vérifier les offres commerciales existantes. Si un FAI annonce sur des grands panneaux publicitaires un débit (sic) de 100 Mb/s, est-ce vrai ? Une étude de la FCC, aux États-Unis, « Measuring broadband America », semblait indiquer que non, que la capacité réelle était bien plus basse. Il est donc normal que les autorités de régulation veulent effectuer des mesures indépendantes de la capacité réellement vendue au client. A priori, le problème est simple. On met une sonde (matérielle ou logicielle) chez le client, une terminaison de mesure quelque part dans l'Internet (avec la plupart des logiciels cités plus loin, c'est le même programme qui tourne aux deux extrémités, ce qui permet de voir le lien des deux côtés) et on regarde (il existe plusieurs outils libres pour faire cette mesure, voir par exemple mon article sur le RFC 6349).
Mais la position de la terminaison est cruciale :
- Si celle-ci est située sur le réseau du FAI, on rate complètement la mesure du point le plus important : l'interconnexion du FAI avec l'extérieur. La plupart du temps, les exagérations dans la publicité (promettre 100 Mb/s qu'on ne pourra pas délivrer) se situent justement dans cette interconnexion, qui coûte très cher au FAI, et sur laquelle il est donc tentant d'économiser. Beaucoup d'entre eux ont donc des réseaux internes relativement rapides et des connexions lentes avec le reste du monde. Ne pas mesurer cette connexion extérieure nous priverait de l'information la plus importante. (C'est pourtant ce que fait Grenouille et c'est justement une des plus grosses limites de leurs mesures.)
- Mais le FAI ne contrôle pas tout l'Internet. Si les mesures ont des conséquences (par exemple, obliger le FAI à publier des chiffres défavorables, ou bien lui imposer de changer sa publicité), il peut sembler injuste de tester le FAI sur des points qu'il ne contrôle pas. Si on mesure un débit avec l'Université de Yaoundé, et que le maximum atteignable est très bas, ce n'est pas la faute du FAI français.
Le débat sur ce sujet est souvent confus. Certes, le problème est compliqué. Mais c'est aussi que certains acteurs n'ont pas intérêt à ce que des mesures sérieuses soient faites. Certaines critiques de telle ou telle méthode sont parfois inspirées par un souci de rigueur scientifique, mais on voit aussi des critiques visant à faire dérailler tout le processus, en gros pour dire « on ne peut pas faire de mesure parfaite alors n'en faisons pas, et faisons confiance aux publicités ».
Comment résoudre ce problème ? Je ne vois pas de solution parfaite. Le mieux serait sans doute de publier les deux indicateurs : « capacité réseau interne » et « capacité avec certains points externes ». Comme souvent en métrologie, on ne peut pas espérer s'en tirer avec un seul chiffre, même si c'est ce que les publicitaires préféreraient.
Après la parution initiale de cet article, plusieurs personnes ont fait des remarques, nuançant tel ou tel point. Merci sur Twitter à lucasdicioccio, AlexArchambault, Grunt_ et bitonio. Les points à compléter :
- La capacité au retour n'est pas forcément la même qu'à l'aller, soit parce que le lien lui-même est asymétrique (ADSL), soit parce que le chemin n'est pas toujours le même au retour. C'est pour cela qu'il faut effectuer la mesure en envoyant des données dans les deux directions. (Il faut que je teste les logiciels mentionnés dans mon article sur le RFC 6349 pour voir comment ils gèrent cela.)
- J'ai écrit que la connectivité externe était sans doute la plus importante, pour l'abonné de base qui veut joindre Netflix ou Wikipédia. Cela ne serait pas vrai si les techniques pair-à-pair (avec des optimisations comme Alto) étaient plus répandues. Malheureusement, ces techniques sont diabolisées, réprimées par des organisations comme l'HADOPI, et pas encouragées par les acteurs commerciaux, qui ne pensent que « accès au contenu », terme qui est pour eux synonyme de TF1. Comme l'a souvent noté FDN, beaucoup des problèmes de performance de l'Internet disparaitraient si on arrêtait de l'utiliser comme un Minitel.
- En parlant de connectivité interne et externe, j'ai supposé qu'il n'y avait que ces deux cas. En fait, comme l'explique bien Éric Daspet, dans son article cité plus loin, il y a de nombreuses sortes de connectivités externes : si le FAI français ne peut clairement pas être responsable de ce qui se passe loin de lui (cas de l'université de Yaoundé), en revanche, il est responsable de ses liens immédiats. S'il refuse de peerer avec Google, les lenteurs d'accès de ses abonnés à YouTube sont bien de sa faute.
Pour une définition plus rigoureuse de la notion de capacité, et pour une explication de ses différences avec la bande passante, on peut consulter le RFC 5136. Quant au débit, il représente l'utilisation effective du réseau, la capacité étant son potentiel maximum. Un bon article scientifique sur ce problème de mesure de la capacité fournie par le FAI est « Broadband Internet Performance: A View From the Gateway ». Suite à mon article, Éric Daspet a écrit « Où doit-on mesurer la capacité réseau », qui revient notamment en détail sur la responsabilité du FAI dans les connexions extérieures (par une bonne politique de peering, etc). Enfin, un autre débat qui a eu lieu dans le même groupe de travail ARCEP est également discuté sur mon blog, dans « Que doit-on mesurer, la QoS ou la QoE ? ».
La consultation publique lancée par l'ARCEP fin 2011 utilise une autre terminologie (voir notamment la question n° 19). La machine visée par la mesure est nommée mire et le projet soumis à consultation a trois sortes de mires, mire proches (situées dans un endroit bien connecté à beaucoup de FAI), mires lointaines (Yaoundé...) et mires commerciales (gros services très populaires comme YouTube). On notera qu'il n'existe pas de mires internes, situées sur le réseau du FAI.
L'article seul
Exposé sur le nommage aux Bell Labs
Première rédaction de cet article le 13 septembre 2011
Le 13 septembre 2011, j'ai fait un exposé aux Bell Labs (centre de recherche d'Alcatel-Lucent à Nozay) sur le thème « Nommage : avoir le beurre, l'argent du beurre, et le sourire de la crémière », consacré aux différents systèmes de nommage dans les réseaux informatiques et à leurs propriétés, souvent contradictoires. Je parlais bien sûr des noms de domaine et du DNS mais aussi de plusieurs autres, en essayant de mettre l'accent sur leurs propriétés, de manière à pouvoir choisir le système adapté.
Voici les transparents de l'exposé :
- Version PDF adaptée à la lecture sur écran,
- Version PDF adaptée à l'impression,
- Source en LaTeX.
J'avais déjà développé ces idées dans un article de mon blog.
L'article seul
RFC 6365: Terminology Used in Internationalization in the IETF
Date de publication du RFC : Septembre 2011
Auteur(s) du RFC : P. Hoffman (VPN Consortium), J. Klensin
Réalisé dans le cadre du groupe de travail IETF appsawg
Première rédaction de cet article le 12 septembre 2011
L'internationalisation des protocoles développés par l'IETF est depuis quinze ans un des sujets chauds de cette organisation. Réussir à rendre tous les protocoles Internet adaptés aux différentes langues, écritures et cultures nécessite d'avoir un socle linguistique commun et c'est le rôle de ce RFC, qui décrit la terminologie en usage à l'IETF. Il remplace le RFC 3536 dans le rôle du texte « l'internationalisation pour les débutants ». Le texte est long car le sujet est complexe.
Cette terminologie est d'autant plus importante que les discussions sur le sujet sont souvent victimes d'un vocabulaire flou et mal utilisé. Ainsi, on voit parfois apparaître le terme de « caractère latin » sans que celui-ci soit bien défini. Seulement ASCII ou bien également les caractères composés, utilisés par exemple en français ? Autre exemple, à l'ICANN, les discussions sur les IDN sont souvent rendues incompréhensibles par une confusion fréquente entre des concepts aussi différents que « langue » et « écriture ». Si vous lisez dans un article ou un rapport des termes absurdes comme « noms de domaines multilingues », faites lire ce RFC 6365 à l'auteur de ce texte, il en a besoin...
Ce RFC est en anglais et fixe une terminologie anglophone. Dans mon article, je vais donner le terme anglais défini et la traduction française que j'utilise (sans consulter les normes officielles, qui ne sont pas toujours de grande qualité et souvent faites par des gens qui ignorent le domaine). Mais le lecteur doit bien être conscient du fait qu'il n'existe pas forcément de terminologie standard en français. Même en anglais, le consensus est loin d'exister sur tous ces termes, et le caractère ultra-sensible des questions de langue n'arrange rien.
Petit rappel de l'objectif poursuivi, en section 1 : comme le dit
le RFC 2277, document fondateur,
l'internationalisation concerne les humains,
pas les protocoles. On ne va donc pas traduire le
GET de HTTP. Par contre, lorsqu'un protocole manipule des chaînes de
caractères qui vont être lues ou écrites par des humains, il faut
que cela soit possible quelle que soit la langue ou l'écriture
utilisée. Cette politique de l'IETF est donc différente de celle, qu'on entend souvent
à l'ICANN, comme quoi tout le monde n'a qu'à parler anglais, langue
internationale de toute façon.
Avoir un vocabulaire commun est évidemment essentiel pour les discussions au sein de l'IETF, et pour la qualité et l'homogénéité des documents produits (les RFC). Ce RFC 6365 sert aussi de tutoriel sur l'internationalisation en expliquant les concepts de base aux membres de l'IETF, un public d'ingénieurs qui n'est pas forcément très sensible à cette question. Notre RFC rappelle ainsi que, dans beaucoup de groupes de travail de l'IETF, lorsque quelqu'un soulève la question de l'internationalisation du protocole en cours de développement, les réponses « faut-il vraiment s'en préoccuper ? » sont souvent nombreuses. Il y a donc un certain fossé à combler.
Voyons maintenant les définitions générales (section 2). Le RFC ne pouvait pas tout couvrir et un des plus grands débats dans le groupe avait été l'étendue de la liste des termes à définir. Le choix a été fait de se restreindre, pour augmenter la probabilité que les non-spécialistes de l'internationalisation lisent le texte. Je ne reprends ici qu'une partie des termes, ceux que je trouve indispensables, ou bien dont la définition est mal connue.
Une langue (language) est une façon de communiquer entre humains, notamment par la parole ou l'écriture. Lorsqu'une forme écrite et une forme parlée existent pour une langue, elles sont parfois très proches... et parfois très distantes. Ce terme n'inclus pas les langages de programmation.
Une écriture (script) est un ensemble de caractères graphiques qui sont utilisés pour la forme écrite d'une ou de plusieurs langues. C'est le cas de l'écriture latine, cyrillique, arabe (attention dans ce cas, arabe est également le nom d'une langue) et han. L'IETF s'occupant surtout de l'écrit (la langue parlée peut être transmise par des protocoles comme RTP mais elle n'est typiquement pas interprétée par ces protocoles), presque toujours, les protocoles IETF s'occupent d'écritures, pas de langues. C'est ainsi que les IDN sont des noms de domaines multi-écritures et surtout pas multilingues. (Le RFC note explicitement que « multilingue » est un de ces termes flous et passe-partout, qu'il faut éviter.)
(La définition de l'internationalisation dans notre RFC est d'ailleurs modeste, « permettre ou améliorer l'utilisation de caractères non-ASCII dans les protocoles IETF », par rapport celle du W3C, plus ambitieuse, « permettre l'adaptation facile à n'importe quelle langue, écriture ou culture ».)
La relation entre les langues et les écritures est complexe : il y a beaucoup moins d'écritures que de langues et la plupart des écritures peuvent servir à plusieurs langues. D'autre part, si certaines langues n'ont jamais été écrites qu'avec une seule écriture (le français avec l'écriture latine, le russe avec la cyrillique), d'autres ont changé, comme le turc ou le vietnamien. L'effondrement de l'URSS a eu entre autres pour conséquence l'abandon du cyrillique par plusieurs langues comme le mongol. Autre exemple, le malais est passé récemment (et la transition n'est pas terminée) du jawi à l'alphabet latin.
On voit parfois le terme alphabet pour désigner une écriture mais, comme toutes ne sont pas alphabétiques (cf. section 4.1), ce terme est plutôt à éviter.
Un système d'écriture (writing system) est un ensemble de règles pour utiliser une écriture dans le cas d'un langage donné. Ainsi, le français et l'anglais utilisent la même écriture, mais avec des règles différentes (par exemple pour la ponctuation).
Un caractère (character) est un membre de l'ensemble des éléments qui servent à représenter les données écrites. Le terme est plus flou qu'il n'y parait car il existe des tas de cas qui défient la classification comme le digramme « ll » du catalan. En anglais, les informaticiens disent souvent char au lieu de character, vu que c'est le type de données utilisé dans plusieurs langages de programmation. En tout cas, un caractère n'est pas une représentation graphique, un glyphe. Par exemple, il n'y a qu'un seul caractère A alors qu'il en existe de nombreuses représentations possibles (il y a un excellent article sur ce sujet dans le livre de Hofstadter, « Metamagical Themas »).
En parlant de glyphe, sa définition dans le RFC est « l'image d'un caractère rendue sur une surface ». On aura donc un glyphe différent si on affiche avec une résolution différente. Unicode a une autre définition, basée plutôt sur l'encodage d'une police particulière, et où le glyphe est donc le même quel que soit le périphérique de sortie. Dans la définition d'Unicode, chaque glyphe a un code de glyphe, qui est un index dans une police donnée (et qui n'est pas standard : deux auteurs de polices peuvent utiliser des codes de glyphes différents).
Un jeu de caractères (repertoire) est simplement un ensemble de caractères, rigoureusement défini (c'est par exemple à ce stade qu'on décide si œ est un seul caractère ou deux).
Un jeu de caractères codé (Coded Character Set, CCS) est un ensemble de règles qui définissent un jeu de caractères et une représentation codée (typiquement, par un nombre entier unique par caractère). Unicode ou ISO-8859-6 définissent un CCS.
L'encodage (character encoding scheme) est la représentation en machine des caractères, c'est-à-dire la définition de quelle chaîne de bits représente tel caractère. Si des normes comme ISO 8859 ne définissent qu'un seul encodage possible, Unicode en a plusieurs (le plus connu étant UTF-8, qui est le protocole par défaut dans l'Internet, cf. RFC 2277).
Le transcodage (transcoding) est la traduction d'un encodage dans un autre, comme le font les outils Unix iconv ou recode.
Je laisse en anglais le terme charset car il est purement technique et n'est pas la même chose qu'un jeu de caractères tel que défini plus haut. Ce terme de charset est très utilisé dans les normes IETF (notamment MIME) et les charsets peuvent être enregistrés dans un registre IANA selon les règles du RFC 2978. Un charset est un moyen de passer d'une séquence d'octets à une chaîne de caractères abstraits. C'est donc la combinaison d'un jeu de caractères codé et d'un encodage. charset doit être considéré comme un mot-clé, à utiliser sans regarder de trop près son étymologie, et le RFC déconseille notamment de le remplacer par character set, qui peut avoir d'autres définitions en anglais. On va donc dire que charset est un néologisme spécifique à l'IETF.
La section suivante, la 3, liste les organismes de normalisation qui ont à voir avec l'internationalisation (ou plutôt une partie d'entre eux). Par exemple, l'ISO a une norme de jeu de caractères, ISO 10646, qui fait même partie des rares normes ISO disponibles gratuitement en ligne (dans sa version anglaise, uniquement, et après acceptation d'un long texte juridique menaçant, c'est pour cela que je ne mets pas de lien ici). Cette norme est synchronisée avec Unicode et il n'y a donc pas de raison de la lire, Unicode offre davantage de choses. Le groupe de travail SC2/WG2 qui produit la norme ISO a un site Web qui donne des aperçus du travail en cours.
D'autres normes ISO ont un rapport direct avec
l'internationalisation comme ISO 639 qui gère
un catalogue de langues, avec des codes alphabétiques (comme
fr pour le français) ou ISO 3166 qui gère une liste de pays, avec leurs codes (comme
fr pour la France). Ces normes forment la base
des étiquettes de langue (cf. RFC 5646), utilisées par exemple dans le
Web pour indiquer la langue d'une page.
Le consortium Unicode est un autre organisme de normalisation, qui gère le jeu de caractères du même nom, ainsi qu'un certain nombre de travaux qui lui sont liés, comme la définition d'expressions rationnelles pour Unicode. On l'a vu, Unicode et ISO 10646 sont synchronisées et, techniquement, on peut se référer à l'une ou l'autre norme, sans conséquences pratiques. Ce RFC 6535 ne le dit pas mais c'est pour des raisons politiciennes qu'ISO 10646 était plus souvent cité, l'ISO, organisation privée, tout comme le consortium Unicode, étant parfois considérée par certains comme plus ouverte (alors que l'essentiel de ses documents n'est pas distribué en ligne).
Le Web est une des applications où l'internationalisation est la plus avancée, ayant été prise en compte pratiquement dès le début. C'est le rôle du W3C, qui gère des normes comme XML (dont le modèle de caractères est Unicode depuis la première version).
Enfin, et c'est important dans le contexte de l'internationalisation, il existe aussi un certain nombres d'organismes nationaux qui ont parfois une activité touchant à ce sujet.
Comme le cœur de l'internationalisation des protocoles est la définition d'un jeu de caractères commun, la section 3.2 liste le vocabulaire spécifique d'Unicode. Il faut par exemple savoir ce que sont UCS-2, UTF-16 et UCS-4/UTF-32, que le BMP (Basic Multilingual Plane) est composé des 65 536 premiers caractères d'Unicode (qui sont traités à part par certains encodages), qu'UTF-8, normalisé dans le RFC 3629, est l'encodage recommandé pour tous les protocoles IETF, mais que l'IETF a un encodage spécifique pour les noms de domaines, Punycode, normalisé dans le RFC 3492. Encodant n'importe quel chaîne Unicode avec uniquement des caractères ASCII, Punycode peut sembler une solution tentante au problème d'internationalisation d'un vieux protocole, mais il vient aussi avec ses propres problèmes (cf. RFC 6055).
On l'a dit, il existe souvent des SDO nationales qui, avant l'avènement d'Unicode, ont souvent développé des jeux de caractères locaux, permettant de représenter les écritures utilisées dans leur pays. La section 3.3 rappelle ainsi que ces jeux de caractères sont encore souvent très utilisés, comme Shift-JIS pour le japonais.
Ce sont ces jeux de caractères, et leurs encodages (dans la plupart
des définitions, le jeu de caractères et l'encodage sont
intrinsèquement liés ; Unicode est une exception), qui sont
enregistrés sous le nom de charsets à
l'IANA, dans https://www.iana.org/assignments/character-sets. Cette liste
n'est pas connue pour sa grande rigueur : beaucoup de noms ont été
ajoutés au pifomètre. Elle ne s'appuie pas toujours sur des normes
reconnues.
Le plus connu des charsets est évidemment US-ASCII, historiquement le jeu par défaut de l'Internet, depuis le RFC 20. Sa domination a officiellement pris fin lors de la sortie du RFC 2277, qui le remplaçait comme charset par défaut par son sur-ensemble UTF-8. À noter que la norme ASCII originale était uniquement un jeu de caractères, et que le terme « ASCII » utilisé à l'IETF lui ajoute un encodage spécifique aux protocoles Internet (champ de huit bits, le bit de plus fort poids toujours à zéro, les sept autres stockant le code ASCII) qui n'a été formellement décrit qu'avec le RFC 5198, bien plus tard...
Ces histoires de caractères font surgir plein d'autres problèmes de terminologie. D'où la section 4, qui lui est consacrée. Ainsi, un point de code (code point) est le numéro que la plupart des normes attribuent à chaque caractère, pour le référencer sans ambiguité. C'est en général un nombre entier strictement positif mais, dans la norme ASCII originale, c'était un couple de nombres, identifiant la ligne et la colonne d'une table. « A » était ainsi 4/1 (ligne 4, colonne 1), en ASCII, alors qu'il est 65 en décimal et U+0041 en Unicode.
Et connaissez-vous les caractères combinants (combining characters) ? Il s'agit d'une particularité d'Unicode, qui met en cause la définition typographique de « caractère » puisqu'un caractère combinant se... combine avec son prédécesseur (par exemple, U+0301 est l'accent aigu combinant, donc U+0065 suivi de U+0301 fait un « é »).
Autre concept important pour les chaînes de caractères, la canonicalisation (normalization ; notez que, en anglais, « canonicalization a un sens très précis dans Unicode, et distinct de celui de normalization, qui justifie l'emploi d'un mot séparé). C'est le processus par lequel une chaîne de caractères est mise sous une forme canonique, permettant les comparaisons (autrement, comparer U+00E9 avec U+0065 U+0301 pourrait échouer alors que, dans les deux cas, il s'agit d'un é).
Quant à la casse (case), c'est le fait pour un caractère d'exister en deux formes, une majuscule et une minuscule. Souvent, la correspondance entre les deux formes est un-un (chaque minuscule a une et une seule majuscule, et réciproquement) mais ce n'est pas toujours le cas. Pire, le changement de casse peut dépendre de la langue. Cette dépendance est mise en œuvre, par exemple, en Java et, outre qu'elle est très coûteuse en ressources, elle produit forcément des résultats différents selon la locale (voir section 8 pour ce terme).
Enfin, place au tri (sorting) et au classement (collation). Le classement est le fait de d'ordonner les caractères. C'est un sujet très vaste. Même en ASCII, il existe au moins deux classements distincts (un par les numéros, A, B, C, D..., a, b, c, et un selon l'ordre alphabétique, A, a, B, b, C, c...). En ISO 8859-1, le cas des caractères composés n'est pas traité de manière uniforme car le classement dépend de la langue (comparez un annuaire téléphonique en France et en Suède pour voir où sont placés les noms propres commençant par un caractère composé). Sans connaître la langue, on ne peut pas espérer classer les caractères Unicode d'une manière qui ne surprenne pas l'utilisateur. Quant au tri, c'est le processus effectif de mise des caractères dans l'ordre du classement. Il fait l'objet d'innombrables algorithmes qui ont fait la joie et le malheur de centaines de milliers d'étudiants en programmation.
Même les adjectifs utilisés pour les différents types de caractères ne sont pas toujours connus. La section 4.1 explique par exemple que le terme d'idéogramme ne décrit pas vraiment correctement les écritures comme la chinoise. Si U+260E est bien une icône (☎, un téléphone), beaucoup de caractères chinois sont utilises phonétiquement, sans coder une idée.
En tout cas, en français, une chose est sûre, on ne devrait pas parler de « caractère accentué » pour des signes comme ç qui n'ont pas d'accent. Le terme Unicode de diacritique (diacritic) convient mieux. Et, évidemment, il ne s'agit pas de caractères spéciaux.
Unicode soulève un autre problème intéressant : la liste des caractères est très longue et il est souvent utile d'en définir des sous-ensembles. Mais attention : contrairement à ASCII ou aux ISO 8859, qui étaient statiques, Unicode grossit tout le temps (la dernière version a été la 6). Un sous-ensemble défini en intension comme « toutes les lettres majuscules » grossira donc lui aussi à chaque nouvelle version d'Unicode (une question qu'il a fallu résoudre pour IDN, voir le RFC 5892).
On l'a dit, le but de l'internationalisation est d'aider les humains, de leur rendre la vie plus facile. Il faut donc un peu se pencher sur les interfaces utilisateur, même si celles-ci sont traditionnellement hors de la portée de l'IETF (qui normalise « au dessus du câble et en dessous de l'application »). En effet, certaines caractéristiques des interfaces utilisateur peuvent affecter les protocoles. D'où l'importance d'apprendre quelques nouveaux termes.
Une méthode d'entrée (input method) est un mécanisme qui permet d'envoyer du texte à une application. Le périphérique d'entrée est souvent un clavier mais les claviers ayant des tailles limitées, les différentes méthodes d'entrée fournissent des mécanismes pour saisir d'autres caractères. Le clavier sur lequel je suis en train de taper n'a pas de majuscules avec diacritiques donc, pour faire un É, je tape Compose (touche dite Windows, sur mon clavier) puis E puis ' (le signe sous le 4). Plus complexe, et ayant bien plus de caractères qu'il n'y a de touches sur un clavier, l'écriture chinoise peut être saisie par plusieurs méthodes différentes : taper les sons au clavier, par exemple.
Les protocoles IETF ont bien de la chance : ils n'échangent que des bits, sans se soucier de savoir comment les afficher. Un serveur HTTP, par exemple, n'a aucun besoin de connaître l'écriture arabe ou la chinoise (ou même de comprendre Unicode), il se contente d'envoyer les octets. Mais le navigateur Web, lui, va devoir afficher les textes pour l'utilisateur. Il s'appuie pour cela sur les règles de rendu (rendering rules), qui sont les algorithmes d'affichage du texte à l'écran. Avec certaines écritures, c'est encore relativement simple : chaque caractère est représenté par un glyphe dans une police de caractères et on pousse simplement ce glyphe vers le périphérique de sortie. Mais dans d'autres écritures, il faut modifier le caractère selon le contexte (par exemple, avec l'écriture arabe, selon qu'il est au début ou à la fin de la phrase). Et, bien sûr, une des choses les plus difficiles pour un moteur de rendu, est de gérer le bidi. Comme je l'ai dit, les protocoles IETF n'ont pas besoin de connaître ces subtilités (un serveur HTTP envoie des textes en alphabet arabe comme ceux en alphabet latin : dans l'ordre de saisie). Mais il est bon que leurs concepteurs soient au courant de ce qui attend les logiciels de l'utilisateur.
Après ces définitions indispensables, quelle est la situation actuelle du texte dans les protocoles IETF ? La section 6 étudie la question. Il n'y a pas de règle générale, car certains protocoles IETF étaient internationalisés depuis le début (comme XMPP), d'autres ne l'ont été qu'après un long et pénible processus (cas du courrier électronique, créé sans penser à l'internationalisation et largement déployé, donc difficile à changer, lorsqu'on a voulu l'adapter à un monde vaste et varié).
Il y a donc encore du vocabulaire à apprendre. Ainsi, les
éléments de protocole (protocol
elements) sont les éléments qui nomment une partie du
protocole. Certains ne sont pas textuels, comme les numéros de
port dans TCP, d'autres
le sont (comme les commandes SMTP, par exemple
EHLO et MAIL FROM) mais ne
sont pas vus par l'utilisateur et donc, ne sont pas sujets à
l'internationalisation (d'ailleurs, EHLO n'est
pas de l'anglais non plus...).
Quant à l'encodage sur le câble (on-the-wire encoding), il désigne les bits qui passent effectivement sur le réseau. Cet encodage est souvent très différent de la forme texte que verront les humains.
Mais il ne pose pas de problèmes d'internationalisation, au
contraire du texte analysé (parsed
text) qui désigne le texte libre qu'un programme va analyser
pour essayer d'y trouver des éléments de protocole. Le cas le plus
connu est sans doute la convention d'ajouter un
Re: (pour Reply) dans le sujet
d'un message. Un tel système est clairement très fragile, la
localisation de ce préfixe suffisant à empêcher
l'analyse. Il ne devrait pas apparaître dans les protocoles
récents.
Lorsqu'un protocole transporte du texte, et que la connaissance de
la langue dans laquelle est écrit ce texte est importante (par exemple
pour déterminer l'ordre de classement), il faut utiliser une
identification de langue (language
identification). C'est un mécanisme par lequel on indique la
langue utilisée, en se servant des étiquettes de
langue du RFC 5646. Ainsi, HTTP va
utiliser l'en-tête Content-Language: gsw-FR dans la
réponse, pour indiquer que le document servi est en alsacien.
Le texte contenu dans les échanges normalisés par un protocole IETF
est souvent décrit par ASN.1. Ce langage permet
plusieurs sortes de chaînes de caractère, de la traditionnelle
IA5String, qui contient les caractères ASCII, à
UTF8String qui, comme son nom l'indique, peut
stocker tout Unicode. Ainsi, lorsque le RFC 5280 utilise ce type pour des champs d'un
certificat X.509, il permet à ce format d'avoir
des noms de CA ou d'utilisateurs complètement internationalisés.
Il existe également toute une terminologie spécifique aux IDN. On la trouve dans le RFC 5890 et résumée dans la section 7.
Plus nouveau est le problème des variantes (variants). Il date du RFC 3743 et peut se définir comme « des chaînes de caractères que certains humains, dans certaines conditions, considèrent comme équivalents ». Dans le RFC 3743, il ne s'agissait que de la différence entre les sinogrammes traditionnels et les sinogrammes simplifiés, pour lesquels une solution était recommandée dans le RFC 4713. Mais la question des variantes peut surgir dans bien d'autres cas :
- Des caractères que l'œil peut confondre comme le 1 et le l de l'alphabet latin, ou comme le a latin et le а cyrillique.
- Des caractères qui sont « le même » d'un certain point de vue, mais à qui Unicode a quand même affecté des numéros différents. Un exemple typique est le σ grec, qui s'écrit ς à la fin d'un mot, alors qu'il s'agit du même sigma. Autre exemple, le ي arabe (le yeh), qui est codé différemment dans d'autres langues, par exemple ی en persan.
- Et bien sûr les variantes orthographiques. Est-ce que color et colour, ou bien theatre et theater sont le même mot en anglais ? Et strasse et straße en allemand ? Concrètement, un protocole Internet doit-il les considérer comme liés, comme faisant partie du même lot, l'un étant une variante de l'autre ?
La question des variantes a donc deux sous-questions : comment classer les caractères et les chaînes en lots (où les membres d'un lot sont considérés variantes l'un de l'autre) ? Et, surtout, le protocole doit-il intégrer cette notion, ou bien considérer plus traditionnellement que deux chaines de caractère sont différentes si elles ont des numéros Unicode différentes, point ?
Dernière section avec des définitions, la section 8 est consacrée aux termes divers. On y trouve, par exemple, le profil local (locale), qui est l'ensemble des informations qui varient selon le lieu ou la culture, et qui sont nécessaires pour que le programme, non seulement parle la langue de l'utilisateur, mais lui présente des informations comme la date ou la monnaie locale.
Les profils locaux sont une source de questions philosophiques sans fin. Par exemple, pour afficher un texte, faut-il utiliser le profil de l'auteur du texte ou bien celui du lecteur ? Et le profil doit-il dépendre de la personne, ou bien de sa localisation physique ? (Si je suis à Tokyo, je veux l'heure locale mais mes textes toujours en français.)
Autres termes utile, ceux de translittération (transliteration), de transcription (transcription) et de romanisation (romanization). La translittération est la conversion d'une écriture dans une autre, en général lettre par lettre. Elle est réversible, la plupart du temps, puisque chaque lettre a été convertie. Cela marche bien entre écritures alpabétiques. La transcription, elle, suit les sons (et non pas les lettres) et va donc être différente selon la langue cible. C'est c'est ainsi que le nom du fondateur du parti bolchevique russe, Ульянов, peut être translittéré Ul'yánov (le résultat exact dépend de la norme suivie car il existe plusieurs normes de translittération de cet alphabet) mais est transcrit Ulyanov en anglais et Oulianov en français. Avec les écritures comme le chinois, la translittération n'est en général pas possible et il n'y a que des transcriptions, comme le pinyin. On nomme romanisation une conversion (translittération ou transcription, même si le RFC n'indique que la première possibilité) vers l'alphabet latin.
Quels sont les changements depuis le précédent RFC, le RFC 3536 ? L'annexe C les résume. Il y a des clarifications, pas de retraits mais plusieurs ajouts, notamment sur la question des variantes. La section 7, sur la terminologie spécifique aux IDN, est toute nouvelle.
Il existe bien sûr d'autres documents qui ont développé un vocabulaire cohérent sur l'internationalisation, et qui ont donc inspiré ce RFC. On peut citer la norme Unicode, le « Character Model for the World Wide Web » du W3C, et les RFC 2277, RFC 5646 et RFC 5890. Patrick Andries a un excellent glossaire de l'internationalisation en français.
L'annexe A contient une bibliographie sur le sujet de l'internationalisation, où on trouve des ouvrages de référence comme la somme sur les écritures du monde, « The world's writing systems ». Sur le sujet d'Unicode, je recommande ces livres :
- « Unicode 5.0 en pratique » de Patrick Andries
- « Unicode explained » de Jukka Korpela
Enfin, on trouve plein de choses en français sur le site de Patrick Andries.
L'article seul
RFC 6366: Requirements for an Internet Audio Codec
Date de publication du RFC : Août 2011
Auteur(s) du RFC : JM. Valin (Mozilla), K. Vos (Skype Technologies)
Pour information
Réalisé dans le cadre du groupe de travail IETF codec
Première rédaction de cet article le 7 septembre 2011
Début 2010, l'IETF avait lancé un travail pour la normalisation d'un codec libre pour l'Internet, c'est-à-dire qui ne serait pas plombé par des brevets ou autres appropriations intellectuelles et pourrait donc être utilisé par n'importe quel protocole Internet. Ce RFC est le premier produit par le groupe de travail, et contient le cahier des charges du futur codec (qui a finalement été publié dans le RFC 6716).
Comme toujours avec ce groupe de travail, cela n'a pas été sans mal. Par exemple, le RFC mentionne des codecs « à battre », c'est-à-dire où le nouveau codec doit être meilleur que ceux-ci, pour être pris en considération. Certains demandaient que les codecs à battre soient uniquement ceux qui sont déjà à peu près libres, d'autres voulaient qu'on compare le nouveau codec avec tous ses concurrents, même plombés. Vue la difficulté de la tâche technique, une telle comparaison aurait sérieusement menacé le projet. Finalement, les codecs libres ont été pris comme référence, mais avec mention des autres, en demandant que, à défaut de les battre, le nouveau codec ne soit pas trop pire qu'eux (section 5.2).
Le but est donc d'avoir un codec libre pour les applications Internet, comme la téléphonie sur IP, la téléconférence, l'exécution de musique en temps réel (concert où les musiciens ne sont pas au même endroit), etc. La section 3 liste, pour chaque application envisagée, ses caractéristiques propres. Car certaines applications sont bien plus exigeantes que les autres. Commençons par l'ordinaire téléphonie à deux. Un codec à large bande (16 kHz) est nécessaire, mais le cahier des charges ajoute la possibilité de fonctionner avec seulement 8 kHz, par exemple pour les vieux téléphones. En large bande, la consommation de capacité réseau attendue va de 12 à 32 kb/s. La latence imposée par le codec doit rester inférieure à 40 ms, mais 25 ms sont souhaitées. (Pour des détails sur les bandes et les latences, voir la section 5.1 du RFC.) Pas besoin d'être haute-fidélité, encore que le RFC note que le codec ne doit pas massacrer les musiques d'attente au point de les rendre désagréables.
Plus exigeantes, la conférence (ou le bavardage en temps réel entre joueurs d'une même partie), où plusieur voix se mêlent. Comme ces applications ont en général davantage de capacité réseau, le codec doit cette fois fonctionner à plus de 24 kHz, pour un débit de 32 à 64 kb/s. Comme les participants à une conférence ont souvent les mains occupées par autre chose et ne tiennent pas le téléphone près de la bouche ou de l'oreille, les problèmes d'écho sont plus sévères qu'en conversation à deux. La latence doit donc être encore plus basse (moins de 30 ms, avec le souhait de descendre à 10), car elle influence la qualité de la suppression d'écho.
Mais, surtout, un système de conférence va mixer les voix de plusieurs participants. Le codec ne doit donc pas gêner le mixage.
Les applications dites de téléprésence sont encore plus demandeuses en terme de qualité, pour arriver à reproduire quelque chose qui ressemble à la présence physique.
Encore plus dur pour un codec, la téléopération (commande d'un robot à distance, par exemple). Si le retour d'information est par la voix (l'opérateur entend ce qui se passe près du robot), une très faible latence est nécessaire.
Et la diffusion de musique en train d'être jouée par plusieurs musiciens ? Des mesures faites avec des musiciens imposent une latence totale de moins de 25 ms (50 si on est prêt à accepter de sérieux problèmes de synchronisation dans l'orchestre). Compte tenu de la latence des autres composants (à commencer par le réseau), cela contraint la latence propre au codec à rester en dessous de 10 ms. Chaque milli-seconde gagnée dans le codec nous donne 200 km de distance en plus, compte-tenu de la vitesse de la lumière dans la silice de la fibre optique. On peut avoir un concert où les musiciens sont dans le même pays, mais pas s'ils sont dispersés aux quatres coins du monde. Et, pour cette application, il faut évidemment une grande qualité, donc un débit soutenu (facilement 128 kb/s).
Il y a bien sûr d'innombrables autres applications où un codec audio est utile mais ce tour d'horizon couvre bien les exigences essentielles.
Le futur codec est conçu avant tout pour être utilisé sur l'Internet. Il s'agit d'un environnement difficile pour un codec audio. La section 4 du RFC liste les contraintes qui découlent de cet environnement. D'abord, les pertes de paquets sont un phénomène normal sur l'Internet et le codec doit y réagir proprement (voir section 5.3). Notamment, lorsque les paquets recommencent à arriver après une ou plusieurs pertes :
- Il faut que le codec puisse lire les paquets, sans avoir besoin d'informations contenues dans les paquets précédents (qui sont perdus), comme demandé par le RFC 2736,
- Il faut que le décodeur puisse se resynchroniser rapidement.
Cela implique que la taille d'un paquet soit inférieure à la MTU (pour éviter la fragmentation : la perte d'un des fragments entraîne celle du paquet original tout entier), et qu'il n'y ait pas d'information implicite, car contenue dans un paquet précédent. Par exemple, si on change les paramètres d'encodage, les paquets suivants ne doivent pas considérer que le changement a été reçu : il pouvait être dans le paquet perdu. Les paramètres permettant le décodage doivent donc être dans chaque paquet (ou pouvoir être récupérés rapidement).
Cela n'interdit pas au décodeur de faire des prédictions sur les paquets suivants mais il doit pouvoir les corriger rapidement en cas de pertes. En gros, un codec résistant aux pertes de paquet doit être conçu comme un compromis entre l'efficacité (qui pousse à ne pas répéter les informations et à faire de chaque paquet un delta du précédent) et la robustesse (qui pousse à faire des paquets autonomes, pouvant être interprétés même si on a perdu les précédents).
Autre particularité de l'Internet, c'est un réseau qui fait « au mieux », et qui ne garantit pas la capacité réseau disponible. Le codec doit donc s'ajuster dynamiquement (augmentant et diminuant son débit), sans que cela ne s'entende après le décodage.
Les protocoles de la famille TCP/IP fournissent des mécanismes qui peuvent aider le codec à prendre ses décisions, comme l'ECN du RFC 3168, et il est donc recommandé des les utiliser.
Enfin, le nouveau codec arrivera dans un monde où il existe déjà des protocoles applicatifs qui ont besoin de lui, et il devra donc s'interfacer gentiment avec ces protocoles comme RTP (RFC 3550 et RFC 2736). Si le codec nécessite de négocier des paramètres entre les deux machines qui communiquent, cette négociation devra utiliser les protocoles de signalisation existants comme SDP (RFC 3261 et RFC 4566) dans le cas de SIP, et Jingle (XEP-O167) dans le cas de XMPP.
La section 5 en vient aux exigences détaillées. Le but est que le rapport entre la qualité du son et le débit utilisé soit meilleur qu'avec les codecs existants comme Speex, iLBC (RFC 3951) et G.722.1 (norme UIT du même nom). Ces trois codecs sont a priori implémentables sans payer de royalties mais seul Speex est vraiment libre et c'est donc le seul que le nouveau codec doit battre. En outre, il serait souhaitable que le nouveau codec fasse ex-aequo avec AMR-NB en bande étroite (8 à 16 kb/s) et AMR-WB en bande large (12 à 32 kb/s). Cette qualité doit être mesurée pour plusieurs langues, y compris les langues à tons pour lesquelles une bonne qualité de son est impérative.
À noter que la seule exigence est de faire mieux que ces codecs : le RFC ne demande aucune interopérabilité avec eux (section 6.10).
Concernant la résistance aux pertes de paquets, le codev devra bien se comporter jusqu'à 5 % de pertes et la voix rester compréhensible jusqu'à 15 % de pertes. Comme la qualité ne dépend pas que du pourcentage global de pertes, mais aussi de leur répartition (continue ou au contraire en brusques trous noirs), la qualité devra être évaluée avec des traces réelles, et avec des répartitions de pertes telles qu'on les observe dans un accès ADSL typique.
Les codecs peuvent être gourmands en ressources machines, par exemple exiger un processeur très rapide. Or, il devra être mis en œuvre sur une grande variété de machines (de l'ordinateur généraliste au petit téléphone), qui ne disposeront parfois pas de FPU et dont les éventuels DSP auront des caractéristiques très différentes. Le RFC demande donc que le codec puisse être implémentable en virgule fixe. Du point de vue quantitatif, notre RFC exige une limite à la consommation de processeur. Pour un x86 récent, l'encodage et le décodage d'un signal en mono ne devrait prendre que 40 MHz en bande étroite (soit 2 % du temps d'un cœur à 2 Hz), et 200 MHz en très large bande. Ces chiffres peuvent paraître bas mais il faut se rappeler que le codec va aussi tourner sur des machines dont le processeur est bien plus lent que celui du PC de bureau typique.
Il est facile d'ammonceler dans un cahier des charges des exigences irréalistes, et ensuite de laisser les pauvres implémenteurs se débrouiller. Ce problème est fréquent dans les SDO où les participants à la normalisation sont des bureaucrates et des politiciens qui ne feront pas le travail de mise en œuvre eux-mêmes. L'IETF se méfie traditionnellement de ce risque et une des méthodes utilisées pour s'en préserver est l'implémentation de référence, une mise en œuvre du logiciel réalisée pour s'assurer que c'est possible, et qui est souvent publiée en même temps que le RFC. Notre RFC encadre cette implémentation de référence du futur codec en lui interdisant de tirer profit de fonctions spécifiques de tel ou tel matériel : elle doit être le plus portable possible. Par exemple, le RFC interdit de dépendre de l'arithmétique saturée, pour pouvoir tourner sur les processeurs qui n'ont pas cette fonction comme certains ARM. Par contre, les « vraies » implémentations, elles, auront tout intérêt à exploiter à fond les particularités du matériel sur lesquelles elles tournent.
Outre la consommation de processeur, le nouveau codec ne doit pas être trop encombrant en mémoire (code et données), pour pouvoir être lancé sur des systèmes embarqués. Pour les données (l'état à garder en mémoire pour faire fonctionner le codec), le RFC met une limite à 2*R*C octets, où R est le taux d'échantillonage et C le nombre de canaux.
Et ce n'est qu'une petite partie des problèmes auxquels un codec sur l'Internet fait face. La section 6 charge la barque avec diverses considérations et des souhaits (les exigences précédentes étaient considérées comme impératives). Par exemple, s'il y a mixage (pour une téléconférence, par exemple), il serait bien de limiter le coût de l'opération. L'implémentation naïve du mixage est de décoder tous les flux audios, les mélanger et réencoder le résultat. Une approche où un décodage complet ne soit pas nécessaire est souhaitée. Autre souhait : un bon support de la stéréo, là encore en évitant l'approche naïve, qui consiste à encoder séparement les deux canaux. Comme ceux-ci ont probablement beaucoup de redondances, cette propriété devrait être utilisée pour limiter le débit utilisé. Il serait également très bien de gérer les erreurs dans les paquets (bits dont la valeur a changé). La plupart des applications Internet ne le font pas car le phénomène est rare. En général, un paquet arrive intact ou n'arrive pas. Mais des transformations non désirées se produisent parfois (avec des protocoles comme UDP Lite, il n'y a pas de somme de contrôle, cf. RFC 3828) et le RFC demande que la question soit étudiée, en insistant que, dans tous les cas, c'est la robustesse du codec aux pertes de paquets qui est prioritaire.
Plus rigolo, et pour les amateurs de polars, la section 6.9 demande que le codec n'élimine pas et ne dégrade pas le bruit de fond des appels : ce bruit peut servir à identifier l'origine d'un appel, et, dans le cas d'appels au 112, cela peut être crucial. Un bon exemple figure dans le génial film de Kurosawa, « Entre le ciel et l'enfer », où policiers et employés du tramway arrivent à reconnaître près de quelle ligne de tramway se trouve le criminel qui appelle, juste en écoutant le bruit de fond, et en remarquant un léger bruit, caractéristique d'un endroit où le câble est abîmé par un accident récent. (Les cinéphiles savent qu'il y a un exemple plus léger dans « La double vie de Véronique ».)
Restent les traditionnelles questions de sécurité : la section 7 rappelle l'évidence (le décodeur doit faire attention aux attaques par débordement de tampons) mais aussi l'importance d'avoir une consommation de ressources bornée : quels que soient les paquets entrants, le temps de processeur utilisé et la mémoire consommée ne doivent pas croître sans limites (autrement, une DoS serait possible en envoyant des paquets créés pour cela).
Plus subtil, le problème de la fuite d'informations lorsque la communication est normalement protégée par du chiffrement. Des attaques ont déjà été décrites où des informations importantes sur la conversation pouvaient être extraites d'un flux audio chiffré (« Spot me if you can: Uncovering spoken phrases in encrypted VoIP conversations » et « Phonotactic Reconstruction of Encrypted VoIP Conversations: Hookt on fon-iks »). Le codec peut compliquer certaines de ces attaques, par exemple en ayant un mode où le débit est constant, quelle que soit la conversation.
L'article seul
Un tunnel IPv6-in-v4 sur un tunnel GRE...
Première rédaction de cet article le 3 septembre 2011
Dernière mise à jour le 14 septembre 2011
Si vous voulez connecter un réseau local à l'Internet IPv6, mais que vous êtes coincé derrière un FAI qui ne fournit encore, en 2011, qu'IPv4, que faire ? La solution évidente est de configurer un tunnel vers un fournisseur de connectivité IPv6. Ce cas est bien connu et on trouve d'innombrables HOWTO et articles de blog sur ce sujet. Mais, que faire si le routeur d'entrée du site n'a pas IPv6, et que la machine qui pourrait servir de routeur IPv6 n'a pas d'adresse IPv4 publique ? Simple, il suffit de créer un deuxième tunnel, entre le routeur d'entrée de site et le routeur IPv6, et de faire tourner le second tunnel sur le premier...
Le cas réel m'est arrivé à l'université de Yaoundé 1 pour une formation sur IPv6. Le Cameroun a pour l'instant zéro connectivité IPv6. L'université n'a que peu d'adresses IPv4 publiques mais il y en avait quand même une de disponible pour établir un tunnel « IPv6 dans IPv4 » (protocole 41) avec un fournisseur de connectivité IPv6 comme l'excellent Hurricane Electric. Le seul problème est que, pour des raisons matérielles, le réseau où se trouvaient les machines à adresse publique ne permettait pas de nouvelle installation. Dans ce réseau, un routeur Cisco 2800 aurait pu servir de routeur IPv6 (l'excellente interface Web de Hurricane Electric fournit des instructions IOS qu'on n'a qu'à copier/coller ou bien on peut utiliser ce tutoriel). Mais ce Cisco-là n'avait pas IPv6, protocole qui nécessite une licence spéciale (baptisée Advanced quelque chose) et une image d'IOS nouvelle. Après une heure passée à naviguer dans les options incompréhensibles du site Web de Cisco, pour essayer de trouver un moyen de mettre à jour la machine, nous avons renoncé.
Bon, il faut donc mettre le routeur IPv6 sur un PC Debian. Il y a encore plus de documentation pour ce système, et cela a l'avantage d'utiliser du logiciel libre. Mais il y avait des limites matérielles : pas de PC avec deux cartes Ethernet disponible, pas de possibilité de le mettre dans la salle machines, etc, qui ont mené à une deuxième décision : le routeur IPv6 sur PC reste dans les salles où se trouvent les autres PC de l'université, et on va créer un tunnel entre lui et le Cisco, « apportant » l'adresse IPv4 publique dont a besoin Hurricane Electric jusqu'à ce PC.
Donc, les acteurs vont être :
- Hurricane Electric (POP de
Londres, le plus proche), adresse IPv4
216.66.80.26et IPv62001:470:1f08:1c8f::1. - Le routeur IPv6 de l'Université, un PC
Debian/Linux, adresse IPv4
sur le réseau local
172.16.0.76et adresse IPv4 publique41.204.94.222, en IPv6,2001:470:1f08:1c8f::2. Le réseau alloué à l'unversité de Yaoundé est2001:470:1f09:1c8f::/64(avec les adresses IPv6, ouvrez l'œil : 1f08 n'est pas 1f09). - Le Cisco 2800 situé à l'entrée de l'Université, adresse IPv4
41.204.93.101.
Le problème est donc de permettre à la machine d'HE (Hurricane
Electric) d'atteindre 41.204.94.222. J'ai choisi
un tunnel GRE (RFC 2784)
pour sa simplicité, et son caractère normalisé (tout le monde sait
faire du GRE). Si le tunnel, au lieu d'être limité à l'université,
s'était étendu sur un réseau public, il aurait été plus prudent de le
protéger par la cryptographie. Mes
followers sur Twitter ont voté massivement pour OpenVPN mais, ici, GRE suffit.
Pour l'intérieur du tunnel GRE, j'ai choisi les adresses IP
192.0.2.1 (pour le Cisco) et
192.0.2.2 (pour le PC). Attention si vous tentez
une expérience similaire : il faut vraiment y aller par étapes, en
testant soigneusement le résultat à chaque étape. Autrement, le
débogage est cauchemardesque.
On va d'abord dire au Cisco de créer son côté du tunnel GRE, sur l'interface Tunnel0 :
int tunnel 0 ip address 192.0.2.1 255.255.255.0 tunnel source 41.204.93.101 tunnel destination 172.16.0.76 exit ip route 41.204.94.222/32 tunnel0
Ainsi, IOS envoit désormais les paquets qu'il reçoit pour
41.204.94.222 à 172.16.0.76,
en GRE. Côté du PC destinataire, on va configurer l'interface tun0 :
ip tunnel add tun0 mode gre remote 41.204.93.101 local 172.16.0.76 ttl 255 ip link set tun0 up ip addr add 192.0.2.2 dev tun0 ip route add 192.0.2.1/24 dev tun0
puis mettre l'adresse IPv4 publique sur une interface
dummy0 :
ifconfig dummy0 up ifconfig dummy0 41.204.94.222/32
Attention, avec ce système, le routage est asymétrique. Un paquet
entrant passera par l'interface tun0 alors que la
réponse sortira par le normal eth0. On peut
changer la table de routage pour forcer le passage par le tunnel GRE,
ou bien on peut tout simplement débrayer le contrôle du routage
asymétrique (qui est activé par défaut sur Debian, pour limiter les
risques d'usurpation d'adresses IP) en mettant les variables
sysctl
net.ipv4.conf.all.rp_filter et
net.ipv4.conf.default.rp_filter à 0. Autrement,
vous verrez les paquets être mystérieusement jetés par Linux.
Et voilà, le tunnel GRE fonctionne. Depuis tout l'Internet, on peut
pinguer 41.204.94.222, bien que la machine soit
reléguée loin du routeur d'entrée, dans une zone uniquement RFC 1918. Un autre avantage de GRE est que tcpdump le
connait et l'analyse très bien, rendant bien plus facile le
débogage. Voici un exemple de paquet qui passe par le tunnel. On a
capturé le trafic sur l'interface Ethernet et on voit les paquets GRE
entre 41.204.93.101 (le routeur Cisco) et
172.16.1.2 (le PC à l'autre bout du tunnel
GRE). Ici, le trafic dans le tunnel était une connexion
SMTP depuis 66.216.133.144
vers 41.204.94.222 :
12:11:21.894937 IP 41.204.93.101 > 172.16.1.2: GREv0, length 56: \
IP 66.216.133.144.26892 > 41.204.94.222.25: \
Flags [S], seq 1940136218, win 8192, options [mss 1380,nop,wscale 8,nop,nop,sackOK], length 0
Via l'interface Web d'Hurricane Electric (qui teste la connectivité effective avec l'adresse donnée, donc la configuration préalable de GRE était nécessaire), on peut créer le tunnel IPv6-dans-IPv4. Reste à le configurer sur le PC (le Cisco n'a plus rien à faire, il laissera passer ce qu'il prend pour des paquets IPv4 normaux).
Les instructions de HE sont simples, on utilise une interface
nommée he-ipv6 :
ip tunnel add he-ipv6 mode sit remote 216.66.80.26 local 41.204.94.222 ttl 255 ip link set he-ipv6 up ip addr add 2001:470:1f08:1c8f::2/64 dev he-ipv6 ip route add ::/0 dev he-ipv6
La première ligne configure le tunnel IPv6-dans-IPv4. Notez que, grâce
à l'autre tunnel, celui en GRE, la machine croit que
216.66.80.26 est directement joignable.
On a donc bien deux tunnels emboîtés :
% ip tunnel show tun0: gre/ip remote 41.204.93.101 local 172.16.0.76 ttl 255 he-ipv6: ipv6/ip remote 216.66.80.26 local 41.204.94.222 ttl 255 6rd-prefix 2002::/16
À partir de là, IPv6 passe : on peut faire un ping6 -n
www.ietf.org, on peut regarder le serveur Web du RIPE-NCC et voir
en haut à droite qu'on utilise bien IPv6, etc. Là encore, si cela ne
marche pas, les outils classiques, tcpdump,
ping et traceroute sont
là. Voici le trafic sur le câble physique Ethernet, vu par tcpdump :
12:11:24.217673 IP 41.204.94.222 > 216.66.80.26: \
IP6 2001:470:1f09:1c8f:21c:23ff:fe00:6b7f > 2001:660:3003:2::4:20: \
ICMP6, echo request, seq 3, length 64
12:11:24.364372 IP 41.204.93.101 > 172.16.1.2: GREv0, length 128: \
IP 216.66.80.26 > 41.204.94.222: \
IP6 2001:660:3003:2::4:20 > 2001:470:1f09:1c8f:21c:23ff:fe00:6b7f: \
ICMP6, echo reply, seq 3, length 64
On y voit 2001:470:1f09:1c8f:21c:23ff:fe00:6b7f
(la machine interne) pinguer
2001:660:3003:2::4:20 (un serveur quelque part
sur l'Internet). On voit bien le routage asymétrique. La requête a été
encapsulée une seule fois, dans le tunnel Hurricane Electric (de
41.204.94.222 vers
216.66.80.26). La réponse, en revanche, a été
encapsulée deux fois, dans le tunnel Hurricane Electric, puis dans le
tunnel GRE. On note que tcpdump n'a pas de problème avec cette double
encapsulation et arrive à décapsuler sans problème, affichant ce qui
passe dans le tunnel.
Si on regardait, toujours avec tcpdump, non pas sur l'interface
physique eth0 mais sur les interfaces virtuelles
du tunnel (option -i de tcpdump), on verrait
directement le trafic IPv6.
Mais, pour l'instant, seul le routeur IPv6, notre brave PC/Debian,
peut profiter de l'Internet en IPv6. Les autres machines du réseau
local n'y ont pas droit. Notre PC n'est pas encore un routeur. Pour
cela, il faut d'abord activer le routage IPv6 en mettant les variables
sysctl
net.ipv6.conf.all.forwarding et
net.ipv6.conf.default.forwarding à 1 (cela peut
se faire avec la commande sysctl - option -w - ou bien en éditant
/etc/sysctl.conf et en rechargeant les paramètres avec sysctl -p). Autrement,
la machine jetterait sans remords les paquets IPv6 qui ne lui sont pas
destinés.
Ensuite, il faut créer une route vers le réseau local, soit en dotant le routeur d'une adresse de ce réseau, soit simplement en ajoutant une route :
ip route add 2001:470:1f09:1c8f::/64 dev eth0
Enfin, il faut prévenir les machines du réseau local qu'un routeur
IPv6 est là pour les servir. Cela se fait en envoyant des RA
(Router Advertisment, RFC 4862). J'ai installé le paquetage Debian
radvd qui fournit ce service. La configuration
est triviale :
# /etc/radvd.conf
interface eth0
{
AdvSendAdvert on;
prefix 2001:470:1f09:1c8f::/64 {};
};
Et c'est magique : toutes les machines du réseau local, par le biais
de ces RA, reçoivent le préfixe du réseau et l'adresse du
routeur. Désormais, tout le monde peut faire un traceroute6 www.afnic.fr.
La plaie traditionnelle des tunnels est qu'ils diminuent la MTU (à cause des quelques octets nécessaires pour l'en-tête du protocole d'encapsulation). Cela va donc souvent imposer de la fragmentation qui, en raison de l'incompétence de certains ingénieurs système qui bloquent l'ICMP, marche souvent mal sur l'Internet. Alors, avec deux tunnels emboîtés, cela risque d'être encore pire. Mais, si tout est correctement configuré (en gros, si on laisse ICMP passer sur tout le chemin), tout se passe bien. Testons depuis l'extérieur en demandant à ping des paquets plus gros que d'habitude pour qu'ils dépassent, avec les octets des en-têtes, la MTU :
% ping6 -s 1450 2001:470:1f09:1c8f:21d:92ff:fe7f:e0ab PING 2001:470:1f09:1c8f:21d:92ff:fe7f:e0ab(2001:470:1f09:1c8f:21d:92ff:fe7f:e0ab) 1450 data bytes From 2001:470:0:67::2 icmp_seq=1 Packet too big: mtu=1480 From 2001:470:0:67::2 icmp_seq=3 Packet too big: mtu=1456 1458 bytes from 2001:470:1f09:1c8f:21d:92ff:fe7f:e0ab: icmp_seq=5 ttl=59 time=138 ms 1458 bytes from 2001:470:1f09:1c8f:21d:92ff:fe7f:e0ab: icmp_seq=6 ttl=59 time=141 ms
Tout s'est bien passé. Les messages packet too big
montrent que les paquets ICMP émis par le routeur d'entrée du tunnel
(deux messages, un par tunnel) sont bien arrivés, ping en a tenu
compte et tout fonctionne. (Pour les paquets émis depuis le réseau
local, on pourrait s'épargner cela en configurant
radvd pour n'indiquer qu'une MTU assez petite
pour passer dans le tunnel.)
PS : ce réseau étant de nature expérimental, ne vous étonnez pas si vous testez les adresses et que cela « ne marche pas ».
Quelques lectures possibles :
- Le HOWTO sur GRE,
- « Setting up GRE tunnel between cisco ios routers » qui explique bien le côté IOS de la chose (et dont la seconde partie montre comment sécuriser le tunnel GRE avec IPsec).
Merci à Janvier Ngnoulaye pour sa patience et sa participation active et compétente.
L'article seul
RFC 6335: Internet Assigned Numbers Authority (IANA) Procedures for the Management of the Transport Protocol Port Number and Service Name Registry
Date de publication du RFC : Août 2011
Auteur(s) du RFC : M. Cotton (ICANN), L. Eggert
(Nokia), A. Mankin (Johns Hopkins
Univ.), J. Touch
(USC/ISI), M. Westerlund
(Ericsson), S. Cheshire (Apple)
Réalisé dans le cadre du groupe de travail IETF tsvwg
Première rédaction de cet article le 3 septembre 2011
Ce RFC parle autant de gouvernance que de technique. Il refond considérablement les procédures utilisées pour enregistrer les numéros de port à l'IANA. Bien que moins médiatisé que l'enregistrement des noms de domaine, ou même que celui des adresses IP, cet enregistrement des ports a déjà suscité des conflits, et peut en faire encore plus maintenant qu'une des plages utilisées approche de la saturation. L'ancien mécanisme d'enregistrement était peu documenté, avait plusieurs limites techniques, et était éclaté entre plusieurs registres ayant des règles différentes. Le nouveau vise à unifier tout cela et à suivre de bons principes, soigneusement explicités.
D'abord, de quoi s'agit-il (section 3) ? Les ports sont des numéros, codés sur 16 bits, qui
servent à démultiplexer les paquets IP entrant
dans une machine (port de destination 62981 -> processus 7653, qui
fait tourner dig, etc) et à identifier le
protocole utilisé (port 80 -> HTTP, port 22
-> SSH, etc). Les noms de services, eux,
sont des courts identificateurs alphabétiques, qui servent à
s'abstraire du numéro de port, en permettant aux applications
d'utiliser un nom de service pour récupérer dynamiquement un numéro de
port (par exemple avec les enregistrements SRV
du DNS, ou bien avec un appel à getservbyname()). Sur Unix, vous
avez une liste (incomplète) de ces noms, avec le numéro de port
correspondant, dans le fichier /etc/services. Pendant longtemps, les registres
officiels stockaient à la fois un nom de service et un numéro de
port. Désormais, ils pourront ne contenir qu'un nom de service.
Le port n'est pas indiqué dans l'en-tête IP mais dans celle du protocole de couche 4 au dessus. On peut donc techniquement utiliser le même numéro de port pour des applications différentes, si l'une utilise UDP et l'autre TCP. La procédure d'enregistrement, elle, est désormais la même pour tous les protocoles de transport.
Les en-têtes de couche 4 incluent deux ports, celui de source et celui de destination, et, avec les adresses IP source et destination et l'identificateur du protocole de transport, ils servent aussi à identifier une connexion de manière unique.
Du fait que l'ancien système d'enregistrement à l'IANA allouait en
même temps un nom de service et un numéro de port, bien des
applications savent utiliser ce nom de service. Par exemple, avec
telnet, on peut se connecter à un serveur de
courrier avec
telnet mail.example.net 25 (le numéro de port)
mais aussi avec telnet mail.example.net smtp (le
nom du service). Le port ainsi enregistré est dit « bien connu » (80
pour HTTP...) Mais attention : de nos jours, il est courant de
faire tourner une application sur un port autre que celui prévu à
l'origine (parce que le pare-feu ne laisse
passer que le port 80, pour échapper à la détection, ou encore
parce qu'on veut faire tourner deux mises en œuvre différentes
du protocole sur la même machine, ou derrière le même routeur NAT). Enfin,
certaines applications n'ont pas de port fixe et comptent sur les
enregistrements SRV du DNS (RFC 2782), ou bien sur d'autres méthodes (comme les
trackers dans BitTorrent).
Un dernier points sur les numéros de port : comme ils sont stockés sur seulement 16 bits, il n'y a que 65 536 valeurs possibles. C'est très peu. La première plage, celle des ports bien connus, est déjà pleine à 76 %. Un des objectifs de la politique d'allocation des ports est donc d'épargner cette ressource limitée, notamment en conseillant fortement aux applications d'utiliser uniquement un nom de service, sans réserver de numéro de port.
Le plan du RFC commence par expliquer la situation actuelle et pourquoi elle n'est pas satisfaisante. Mais je préfère partir de la nouvelle situation, celle qui est désormais l'officielle, et parler du passé tout à la fin de cet article.
D'abord, les noms de services (section 5). Ce sont les clés d'accès au registre des services. Les applications les utilisent pour chercher un numéro de port, typiquement via les enregistrements SRV du RFC 2782. Il peut y avoir plusieurs services qui se partagent un numéro de port, par exemple :
- Parce que
l'un est une extension de l'autre (cas de TURN
- RFC 8656, qui est une extension de
STUN - RFC 8489 ; le
fait d'avoir un service nommé
turnpermet à une application d'obtenir tout de suite un serveur ayant l'extension TURN, sans tester plusieurs serveurs STUN), - Par accident (un exemple typique
est la coexistence de deux services
wwwethttpqui pointent vers le même port 80 ; seulhttpest correct, aujourd'hui), - Ou suite à la sortie de notre RFC qui introduisait des nouvelles règles de syntaxe pour les noms de services, rendant parfois nécessaire la création d'alias (l'ancien et le nouveau nom).
Les noms de services dans le registre sont enregistrés sur une base « premier arrivé, premier servi », tel que décrit dans le RFC 5226 (voir aussi la section 7.2). Contrairement aux numéros de port, il n'y a pas de pénurie et donc pas de raison de faire des économies, sauf si l'IANA détecte un problème (comme un enregistrement massif de noms) auquel cas elle peut passer au mécanisme Expert review, où un examen de fond est fait. Les noms doivent être courts (quinze caractères maximum) et informatifs, et éviter les redondances (comme de mettre protocole ou port dans le nom).
La syntaxe des noms (une nouveauté de ce RFC) est décrite en
section 5.1. En résumé, seuls les lettres
d'ASCII, les chiffres et le
tiret sont admis. Il faut au moins une lettre,
pour éviter des noms de service comme 23, qui pourrait être pris pour
un numéro de port. 98 % des noms du registre étaient déjà conformes à
cette syntaxe
avant ce RFC, les 2 % restants ont dû changer de nom pour se plier à
la nouvelle syntaxe. C'est ainsi que, par exemple,
z39.50 (pour le protocole du même
nom) est
devenu z39-50.
Dans le cas le plus courant, l'application va traduire ces noms en
numéro de port via une requête DNS. Prenons
l'exemple de XMPP. Si le serveur de
messagerie instantanée de Google Talk veut contacter un utilisateur dont
l'adresse XMPP est martinedurand@dns-oarc.net,
le serveur de Google va faire une requête SRV pour le service
xmpp-server, protocole TCP (RFC 6120, section 3.2.1). Il trouvera :
% dig SRV _xmpp-server._tcp.dns-oarc.net ... ;; ANSWER SECTION: _xmpp-server._tcp.dns-oarc.net. 3600 IN SRV 0 0 5269 jabber.dns-oarc.net.
et saura donc qu'il doit se connecter au port 5269. (Le fait que le champ « service » du RFC 2782 doive être un nom de service enregistré n'était pas clair : c'est notre nouveau RFC qui impose cette règle.)
L'enregistrements des numéros de port est plus complexe, en raison du risque de pénurie (section 6). Il y a trois plages de numéros de port :
- Les ports « système », dits aussi « bien connus », de 0 à 1023.
- Les ports « utilisateur », de 1024 à 49151.
- Et les ports « dynamiques », dits aussi « éphémères », de 49152 à 65535. Contrairement aux deux précédentes plages, ils ne font jamais l'objet d'un enregistrement à l'IANA.
Il y a trois statuts possibles pour un numéro de port :
- Affecté : il apparaît alors dans le registre,
- Non affecté,
- Réservé : ils ne sont pas affectés et ne doivent normalement pas l'être. Par exemple, les ports extrêmes de la plage des bien connus, 0 et 1023, sont réservés, au cas où il faille un jour étendre cette plage ; on les utiliserait alors comme indiquant un échappement.
Aujourd'hui, 76 % des ports système et 9 % des ports utilisateur sont affectés.
Il existe aussi des ports voués à des usages expérimentaux (section 6.1, voir aussi le RFC 3692), les ports 1021 et 1022. Comme des tas de protocoles peuvent s'y bousculer, les applications qui utilisent ces ports doivent s'assurer qu'elles se connectent bien au service attendu (par exemple, le client peut vérifier que le serveur envoie un nombre magique caractéristique de l'application).
Comment enregistre-t-on un nouveau numéro de port ? La section 7 décrit les grands principes. Le plus important est la nécessité d'allouer lentement, pour éviter d'épuiser ce qui reste de cette ressource (si vous développez un nouveau protocole, rappelez-vous que la méthode recommandée est de ne pas réclamer de numéro de port du tout, mais d'utiliser un nom de service). Environ 400 ports par an sont affectés, et le chiffre est stable depuis des années. Cela devrait permettre de tenir jusqu'à la fin du 21ème siècle.
Compte-tenu de cela, les nouveaux principes, exposés en section 7.2 sont :
- Un seul numéro de port par application : si celle-ci est composée de plusieurs services, l'application doit néanmoins tout mettre sur le même numéro de port et démultiplexer elle-même.
- Même chose en cas de mise à jour d'un service : on n'alloue pas de nouveau numéro de port. La technique recommandée est que le service inclue un champ Version dans ses messages, pour qu'il puisse les séparer facilement.
- Affectation uniquement pour le protocole de transport indiqué (c'est une grande nouveauté par rapport aux précédentes règles). Si l'application ne fonctionne que sur TCP, aucune allocation de port n'est faite pour UDP.
- Rien n'est éternel et une allocation de numéro de port peut être reprise par l'IANA.
Les ports « repris » auront le statut Réservé (sur l'Internet, il n'est pas prudent de réallouer des ports trop tôt, on ne peut jamais être sûr de ce qui traîne dans des vieilles applications, cf. section 8.3). Le jour où une plage de numéros de port est épuisée, l'IANA pourra recycler ces vieux numéros en les affectant.
Tout le détail des procédures bureaucratiques est en section 8. Si on veut un numéro de port ou un nom de service, il faut remplir un formulaire (section 8.1.1) indiquant les coordonnées du demandeur (pour les normes au sens propre, ce demandeur sera l'IETF), une description du protocole prévu et le nom du protocole de transport (TCP, UDP, etc). Si on veut un numéro de port, on peut préciser lequel (et l'IANA le donnera, sauf bonne raison contraire). Les ports rigolos comme 42, 666 ou 1984 (utilisé par un logiciel de surveillance) sont déjà pris.
Rappelez-vous qu'il y aura une grosse différence entre demande d'un numéro de port et demande d'un simple nom de service. Les premiers feront l'objet d'une Expert Review (cf. RFC 5226), le seconds seront distribués sans trop de formalité. Pour les numéros de port, cela dépendra en outre de la plage visée. La plage dynamique ne permet pas de réservation du tout, la plage utilisateur est recommandée pour les nouvelles réservations, la plage système, celle des ports bien connus, est tellement pleine que l'enregistrement est découragé, un avis d'expert ne suffira pas, il faudra un IETF review et encore, après avoir expliqué en détail pourquoi ne pas utiliser un port de la plage utilisateur.
Nouveauté de notre RFC, il y a désormais des procédures explicites pour le retrait d'un enregistrement (section 8.2 ; cela concerne surtout les numéros de port, les noms de service peuvent rester enregistrés sans que cela ne gène personne). Le demandeur original peut demander un retrait, s'il n'a plus besoin de l'enregistrement. Mais l'IANA peut aussi le faire d'autorité, si cela semble vraiment nécessaire.
Dans tous les cas, l'IANA tentera de déterminer si le port est encore utilisé.
En revanche, le transfert d'un enregistrement (numéro de port ou nom de service) d'un protocole à un autre est formellement interdit (section 8.4), même entre adultes consentants. Pas de marché des numéros de port, qui aurait permis à ceux qui avaient déposé des numéros il y a longtemps de gagner de l'argent en les vendant maintenant qu'ils sont rares. Si on veut récupérer un numéro de port, il faut le faire désaffecter, puis candidater pour l'avoir.
Il y aura sans doute des désaccords et des crises (comme dans l'affaire CARP). La procédure habituelle de gestion des conlits à l'IETF (section 7 du RFC 5226) sera donc utilisée.
Un peu d'histoire, maintenant. Quels étaient les procédures avant notre RFC ? Les règles IANA étaient dans le RFC 2780 et notre RFC remplace ses sections 8 et 9. Il y avait aussi des règles spécifiques aux différents protocoles de transport : RFC 3828 pour UDP-Lite, RFC 4340 pour DCCP, et RFC 4960 pour SCTP. Mais elles n'étaient pas complètes (une partie de la procédure était également dans les formulaires Web de soumission à l'IANA, une autre partie était dans le texte du registre), et aussi bien l'IANA que ses « clients » se plaignaient de leur flou (section 1). La section 7.1 de notre RFC 6335 tente de résumer a posteriori les règles (largement informelles) qui étaient utilisées (affectation du port pour TCP et UDP simultanément, pas d'enregistrement des noms de service séparément des ports, SCTP et DCCP traités à part, etc).
En outre, les enregistrements SRV du RFC 2782 ajoutaient leurs propres concepts (nom de service, notion mal définie dans le RFC 2782) et leur propre registre. Ainsi, comme les procédures de l'IANA ne permettaient pas d'enregistrer un nom de service sans obtenir en même temps un numéro de port, on a vu apparaître un registre informel des noms de service (qui a fusionné avec l'officiel, cf. section 10). Un des changements importants de ce RFC 6335 est d'unifier les procédures d'enregistrement et les registres.
La syntaxe admissible pour les noms de service n'avait même jamais
été spécifiée (section 2). Les formulaires de l'IANA donnaient une limite de
longueur (arbitraire et, d'ailleurs, pas toujours respectée dans le registre) à 14 caractères, mais sans préciser si des
caractères comme le + ou le
/ étaient autorisés. On trouvait donc des noms
avec des caractères non-alphanumériques
comme whois++ (RFC 2957) ou sql*net.
D'autre part, il n'existait aucune procédure écrite pour les opérations postérieures à l'enregistrement : changement, ou suppression (volontaire ou forcée).
PS : si vous vous intéressez aux questions d'enregistrement de paramètres pour les protocoles, voyez la nouvelle liste de discussion happiana.
L'article seul
RFC 6352: vCard Extensions to WebDAV (CardDAV)
Date de publication du RFC : Août 2011
Auteur(s) du RFC : C. Daboo (Apple)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF vcarddav
Première rédaction de cet article le 1 septembre 2011
Dernière mise à jour le 18 août 2014
De même que le format de fichiers iCal, décrivant des événements, avait son protocole CalDAV pour synchroniser des agendas entre machines, le format vCard décrivant des informations sur une personne a désormais son protocole CardDAV, pour synchroniser des carnets d'adresses.
Lorsque ce RFC sera largement déployé, on pourra donc sauvegarder, distribuer, partager son carnet d'adresses de manière standard. Cela se fait en définissant, comme pour CalDAV, des extensions au protocole WebDAV (RFC 4918).
Ce n'est pas qu'on manquait de protocoles pour l'accès à un
carnet. Comme le rappelle la section 1, on avait
LDAP (RFC 4510), IMSP et
ACAP (RFC 2244), ainsi que
SyncML. Mais bâtir sur
WebDAV (RFC 4918) permettait de récupérer les fonctions
perfectionnées de ce protocole. Le nouveau CardDAV permet d'avoir
plusieurs carnets d'adresses, d'en protéger l'accès par des
autorisations (RFC 3744), de faire des recherches côté
serveur (sans avoir besoin de récupérer tout le carnet d'adresses chez
le client), etc. WebDAV étant lui-même bâti sur
HTTP, on récupère aussi les fonctions de HTTP
comme la sécurité avec TLS (RFC 2818). CardDAV utilise le format vCard. Ce
format avait été normalisé dans le RFC 2426 et
se trouve désormais dans la RFC 6350. CardDAV dépend
de certaines extensions à WebDAV et tout serveur WebDAV ne conviendra
pas forcément. La section 3 résume les exigences de CardDAV (serveur
permettant de créer des collections avec MKCOL
- RFC 5689 et exemple d'usage en section 6.3.1, versionnement - RFC 3253, etc). Par contre, il
n'y a pas encore dans le protocole CardDAV de
mécanisme de notification asynchrone (« Machin a changé de numéro de
téléphone »). Le RFC ne le précise pas mais il y a un
inconvénient à utiliser WebDAV, la complexité. Notre RFC 6352 fait 56 pages, et il faut avoir compris WebDAV avant...
La section 4 du RFC explique le modèle de données utilisé pour le carnet : chaque
carnet d'adresses est une collection WebDAV et
chaque entrée dans le carnet est une ressource WebDAV, adressable et
verrouillable séparement. En même temps que les carnets d'adresses, un
serveur CardDAV peut aussi gérer avec WebDAV d'autres ressources (un
exemple serait un serveur où le carnet d'adresses de Lisa serait en
/addressbooks/lisa et son agenda, via
CalDAV, en
/calendars/lisa). Le serveur publie le fait qu'il
gère CardDAV en ajoutant addressbook à la réponse
à la requête HTTP OPTIONS.
La section 5 passe ensuite à ces ressources. Chacune d'elles est une entrée du carnet, typiquement exprimée en format vCard (le serveur peut gérer également d'autres formats).
Emprunté au RFC (section 6.1), voici un exemple de connexion à un serveur CardDAV :
(Le client demande) OPTIONS /addressbooks/ HTTP/1.1 Host: addressbook.example.com (Le serveur répond) HTTP/1.1 200 OK Allow: OPTIONS, GET, HEAD, POST, PUT, DELETE, TRACE, COPY, MOVE Allow: MKCOL, PROPFIND, PROPPATCH, LOCK, UNLOCK, REPORT, ACL DAV: 1, 2, 3, access-control, addressbook DAV: extended-mkcol Date: Sat, 11 Nov 2006 09:32:12 GMT Content-Length: 0
Le client sait désormais que le serveur gère CardDAV (le
addressbook dans l'en-tête
DAV).
Différentes propriétés WebDAV (RFC 4918, section 4 ; les propriétés sont les
métadonnées de WebDAV) permettent de se
renseigner sur les carnets d'adresses. Elles sont formatées en
XML. Ici,
addressbook-description (section 6.2.1 ; son nom
indique bien à quoi elle sert) peut valoir, par exemple (notez l'attribut xml:lang qui illustre les capacités d'internationalisation de CardDav) :
<carddav:addressbook-description xml:lang="fr-CA"
xmlns:carddav="urn:ietf:params:xml:ns:carddav">
Adresses de Oliver Daboo
</carddav:addressbook-description>
Et pour créer des entrées dans le carnet d'adresses, ce qui est
quand même la tâche la plus importante de CardDAV ? CardDAV étant
fondé sur HTTP, on utilise évidemment une requête
PUT (de même que la lecture se ferait par un GET). La section 6.3.2 nous fournit un exemple,
avec l'entrée au format vCard :
PUT /lisa/addressbook/newvcard.vcf HTTP/1.1 If-None-Match: * Host: addressbook.example.com Content-Type: text/vcard Content-Length: xxx BEGIN:VCARD VERSION:3.0 FN:Cyrus Daboo N:Daboo;Cyrus ADR;TYPE=POSTAL:;2822 Email HQ;Suite 2821;RFCVille;PA;15213;USA EMAIL;TYPE=INTERNET,PREF:cyrus@example.com NICKNAME:me NOTE:Example VCard. ORG:Self Employed TEL;TYPE=WORK,VOICE:412 605 0499 TEL;TYPE=FAX:412 605 0705 URL:http://www.example.com UID:1234-5678-9000-1 END:VCARD
Le If-None-Match dans la requête (RFC 7232,
section 3.2) est là pour garantir qu'une
ressource du même nom n'existe pas déjà. Cela évite d'effacer une
ressource existante. Le .vcf à la fin de l'URL
est l'extension commune des fichiers vCard.
Les carnets d'adresses sont évidemment des choses assez personnelles, on a donc des moyens de les protéger (section 7). Un serveur CardDAV permet de définir des ACL, comme normalisé dans le RFC 3744.
Récupérer un carnet d'adresses avec GET est
simple mais ne laisse guère de choix. La section 8 présente des
mécanismes plus sophistiqués. CardDAV a la méthode HTTP
REPORT du RFC 3253 pour produire des
extractions du carnet. Mais il a aussi des fonctions de recherche et de
tri. Celles-ci posent le problème des règles de
comparaison (rappelez-vous qu'un fichier vCard est de
l'Unicode et peut contenir des caractères de
toute sorte). La section 8.3 précise donc :
- Ces règles sont exprimées en utilisant la terminologie du RFC 4790, qui fournit une liste de règles,
- Parmi ces règles, le serveur doit accepter au moins les comparaisons
ASCII
i;ascii-casemapdu RFC 4790 et les comparaisons Unicodei;unicode-casemapdu RFC 5051, - Les opérations possibles sont au minimum le test d'égalité et le test de sous-chaîne (« strauss » doit trouver « strauss-kahn »), avec ses options « au début de la chaîne » et « à la fin de la chaîne ».
Voici un exemple de commande REPORT en ajoutant
une condition pour ne sélectionner que les entrées du carnet dont le
NICKNAME est exactement égal à « me » :
La requête :
REPORT /home/bernard/addressbook/ HTTP/1.1
Host: addressbook.example.com
Depth: 1
Content-Type: text/xml; charset="utf-8"
Content-Length: xxxx
<?xml version="1.0" encoding="utf-8" ?>
<carddav:addressbook-query xmlns:dav="DAV:"
xmlns:carddav="urn:ietf:params:xml:ns:carddav">
<dav:prop>
<dav:getetag/>
<carddav:address-data>
<carddav:prop name="VERSION"/>
<carddav:prop name="UID"/>
<carddav:prop name="NICKNAME"/>
<carddav:prop name="EMAIL"/>
<carddav:prop name="FN"/>
</carddav:address-data>
</dav:prop>
<carddav:filter>
<carddav:prop-filter name="NICKNAME">
<carddav:text-match collation="i;unicode-casemap"
match-type="equals">
me
</carddav:text-match>
</carddav:prop-filter>
</carddav:filter>
</carddav:addressbook-query>
La réponse :
HTTP/1.1 207 Multi-Status
Date: Sat, 11 Nov 2006 09:32:12 GMT
Content-Type: text/xml; charset="utf-8"
Content-Length: xxxx
<?xml version="1.0" encoding="utf-8" ?>
<dav:multistatus xmlns:dav="DAV:"
xmlns:carddav="urn:ietf:params:xml:ns:carddav">
<dav:response>
<dav:href>/home/bernard/addressbook/v102.vcf</dav:href>
<dav:propstat>
<dav:prop>
<dav:getetag>"23ba4d-ff11fb"</dav:getetag>
<carddav:address-data>BEGIN:VCARD
VERSION:3.0
NICKNAME:me
UID:34222-232@example.com
FN:Cyrus Daboo
EMAIL:daboo@example.com
END:VCARD
</carddav:address-data>
</dav:prop>
<dav:status>HTTP/1.1 200 OK</dav:status>
</dav:propstat>
</dav:response>
</dav:multistatus>
Écrire un client CardDAV n'est pas trivial, pas seulement à cause
de la longueur du RFC mais aussi parce qu'il existe plusieurs
pièges. La lecture de la section 9 est donc recommandée. Elle rappelle
par exemple que le client peut ne demander qu'une
partie des données (dans l'exemple ci-dessus, le
client demande à ne voir que VERSION,
UID, NICKNAME,
EMAIL et FN). Cela lui évite
de devoir télécharger des données qui peuvent être de grande taille
comme PHOTO ou SOUND. Par
contre, cette astuce ne marche qu'en lecture, pas en écriture : un
PUT doit transmettre la totalité de la
vCard et le protocole ne fournit pas de moyen de ne
mettre à jour qu'un seul champ. Le client doit donc récupérer toute la
vCard, changer un champ et renvoyer toute la
vCard modifiée.
Piège classique dans ce cas, la « mise à jour perdue ». Que se
passe-t-il si les données ont été changées entre leur récupération et
le renvoi ? Ce changement risque d'être écrasé. Pour éviter cela, le
client a tout intérêt à utiliser l'option
If-Match: de la requête HTTP, en indiquant comme
paramètre un Etag récupéré précedemment (les
Etags sont décrits dans la section 2.3 du RFC 7232). Ainsi, dans le cas cité ci-dessus, le
renvoi du vCard modifié sera refusé, préservant la
mise à jour qui avait été faite parallèlement. (Emmanuel Saint-James
me fait remarquer qu'on aurait aussi pu utiliser
If-Unmodified-Since:, si le serveur CardDAV met
les informations dans une base de données qui stocke la date de
modification, par exemple le système de fichiers Unix ; cette
possibilité n'est pas mentionnée par le RFC.)
Comment configure-t-on un client CardDAV (section 9.3) ? On a vu que
l'URL utilisé était arbitraire, au choix de
l'implémenteur. Le client doit donc être configuré avec cet URL. Il
existe bien deux mécanismes de découverte automatique, décrits dans le
RFC 5397 et dans le RFC 6764, mais qui ne sont pas
forcément présents partout. (iOS utilise celui du RFC 6764 donc si
vous voyez des requêtes /.well-known/carddav
passer, c'est lui.)
Et le nom du serveur ? La section 11 décrit un
enregistrement SRV pour le trouver. Le nom
_carddav._tcp.domain.example permet donc de
trouver le serveur CardDAV du domain
domain.example (et _carddavs
pour utiliser TLS). Si l'enregistrement SRV
vaut :
_carddav._tcp SRV 0 1 80 addressbook.example.com.
Cela indique que ce serveur est
addressbook.example.com et qu'il est accessible
sur le port 80.
Si ces
enregistrements SRV sont présents, et si la propriété
current-user-principal-URL du RFC 5397
est utilisée, il n'y a plus à configurer que le nom de domaine, le nom
de l'utilisateur et un mot de passe.
Et si on veut accéder au carnet d'un autre utilisateur, ce qui peut
arriver en cas de carnets partagés ? La section 9.4 rappelle
l'existence de la propriété
principal-property-search du RFC 3744,
qui peut permettre de demander un REPORT en
cherchant le carnet sur divers critères. Ici, on cherche le carnet de
Laurie :
REPORT /home/bernard/addressbook/ HTTP/1.1
Host: addressbook.example.com
...
<dav:principal-property-search xmlns:dav="DAV:">
<dav:property-search>
<dav:prop>
<dav:displayname/>
</dav:prop>
<dav:match>Laurie</dav:match>
</dav:property-search>
<dav:prop>
<carddav:addressbook-home-set
xmlns:carddav="urn:ietf:params:xml:ns:carddav"/>
<dav:displayname/>
</dav:prop>
</dav:principal-property-search>
Notez que, CardDAV s'appuyant sur XML, il hérite de ses capacités d'internationalisation (section 12), notamment l'usage d'Unicode.
Et question sécurité ? Des failles dans CardDAV ? La section 13 tente de prévenir les problèmes : d'abord, CardDAV hérite des questions de sécurité de HTTP. Si on n'utilise pas HTTPS, les requêtes et réponses circulant sur le réseau peuvent être lues et/ou modifiées. C'est particulièrement important si on utilise l'authentification HTTP de base, avec envoi d'un mot de passe.
Ensuite, une fois les utilisateurs authentifiés, encore faut-il éviter qu'un utilisateur ne tripote les carnets des autres. L'extension « ACL » du RFC 3744 permet d'atteindre cet objectif. Elle permet d'avoir des carnets publics, partagés ou complètement privés. Le serveur doit ensuite veiller au respect de cette classification.
Le schéma XML complet pour les éléments CardDAV figure en section 10. Question implémentations, on peut regarder la liste gérée par les gens de Zimbra, celle de Trinity, celle de Wikipédia. Parmi les programmes qui gèrent CardDAV, citons le serveur Davical, Radicale ou Evolution. le client Kontact de KDE n'est plus maintenu. Pour Firefox, c'est en discussion. Merci à Mathieu Dupuy pour les détails.
L'article seul
RFC 6350: vCard Format Specification
Date de publication du RFC : Août 2011
Auteur(s) du RFC : S. Perreault (Viagenie)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF vcarddav
Première rédaction de cet article le 1 septembre 2011
vCard, désormais en version 4 avec ce RFC est le format standard de carnet d'adresses sur l'Internet. Tous les logiciels de gestion de carnet d'adresses peuvent (ou devraient pouvoir) lire et écrire du vCard. Ce RFC met à jour la norme vCard.
vCard est simplement un modèle de données (très léger) et une syntaxe pour représenter des données permettant de contacter des individus ou organisations. Par exemple, une entrée vCard pour mon employeur, l'AFNIC, pourrait être :
BEGIN:VCARD
VERSION:4.0
FN:Association Française pour le Nommage Internet en Coopération
KIND:org
GENDER:N
NICKNAME:AFNIC
LANG;PREF=1:fr
LANG;PREF=2:en
ADR:;;Immeuble International;Saint-Quentin-en-Yvelines;;78181;France
LOGO:http://www.afnic.fr/images/logo.png
TEL;VALUE=uri:tel:+33-1-39-30-83-00
EMAIL:afnic@afnic.fr
GEO:geo:2.0455,48.7873
BDAY:19980101
TZ:Paris/Europe
URL:http://www.afnic.fr/
NOTE;LANGUAGE=en:@AFNIC on Twitter\,
AFNIC on Facebook.
END:VCARD
Ce texte peut ensuite être lu et interprété par les logiciels de
gestion de carnet, être envoyé via l'Internet, etc. Un exemple courant
est l'envoi d'une vCard dans le courrier, via MIME et
le type text/vcard (section 10.1 pour
l'enregistrement de ce type). Le cas échéant, il
est relativement compréhensible par un humain (s'il comprend l'anglais
et quelques sigles), ce qui justifie le type MIME
text indiqué plus haut.
La version de vCard dans ce RFC est largement terminée depuis mi-2010. Mais de nombreux détails avaient été discutés jusqu'au dernier moment. Si la syntaxe ne pose guère de problèmes (on notera qu'il existe une variante XML normalisée, dans le RFC 6351, et une autre en JSON, dans le RFC 7095), le modèle de données peut susciter des discussions sans fin.
Pour prendre des exemples de cette discussion, voici quelques sujets qui avaient été abordés lors de la réunion du groupe de travail à l'IETF de Pékin en 2010 :
- La nouvelle propriété
RELATEDqui peut valoirspouse,friend, etc. Une jolie liste des valeurs possibles esthttp://gmpg.org/xfn/11. On pourra coder toutes les relations Facebook en vCard. - La longue discussion passionnée à propos du remplacement de
l'ancien attribut
SEXde vCard 3 parGENDER. La moitié des participants se sont exprimés, ce qui est rare à l'IETF. Le sexe est déterminé biologiquement et, en toute première approximation, peut être considéré comme binaire (homme ou femme). Le genre est construit socialement et peut prendre bien plus de valeurs.GENDERpourra donc être du texte libre (une des propositions discutées à Pékin avait été de créer un registre IANA des différents genres possibles...) et les exemples du RFC (avec des valeurs comme grrrl, intersex ou complicated) illustrent la difficulté du problème. Le changement dans vCard permet donc de mieux prendre en compte des cas comme celui des transsexuels ou, tout simplement, des gens qui ont une autre identité que celle que leur impose la biologie. L'ironie de la longue et animée discussion est qu'il n'y avait que des hommes dans la salle. (GENDERest désormais décrit en détail dans la section 6.2.7 du RFC, avec notamment sa façon subtile de combiner deux champs, un énuméré et un en texte libre.) - Plus triste, une discussion avait eu lieu sur la propriété
DEATHpermettant, si nécessaire, d'indiquer la date de la mort de l'entitée considérée. Elle a finalement été retirée. Mettre du vCard sur une pierre tombale aurait pourtant été curieux... Cela a finalement été possible quelque temps après, avec l'approbation du RFC 6474. - Et les adresses de courrier électronique en
Unicode du RFC 6532 ont évidemment
suscité bien de la perplexité. Finalement, la propriété
EMAILpermettra de telles adresses (voir la section 6.4.2 pour les détails).
J'espère que cette liste amusante vous aura donné une idée des
problèmes que pose la définition d'un modèle de données
standard. Retournons maintenant à la technique. D'abord, le niveau
lexical (sections 3.1 et 3.2) : les fichiers vCard sont en
UTF-8 (la possibilité d'autres encodages a été
retirée, avec cette version de vCard), et sont composés de lignes terminées par
CRLF (c'est-à-dire les deux caractères U+000D et U+000A). Comme pour
les en-têtes du courrier électronique, on peut
continuer sur plusieurs lignes : si une ligne commence par un espace
ou une tabulation,
c'est une continuation (regardez la NOTE dans
l'exemple plus haut). Du fait de ces continuations, un outil
mono-ligne comme grep n'est pas bien adapté
pour chercher dans des vCards.
Ensuite, la syntaxe (section 3.3). Elle est
très simple et indiquée en ABNF (RFC 5234). Une « carte » commence par la ligne
BEGIN:VCARD, continue par une ligne avec le
numéro de version, puis par une ou plusieurs lignes comportant les
données, et se termine avec END:VCARD. Les
données sont composées de propriétés, chaque
ligne étant un nom de propriété (insensible à la
casse, même si la convention recommandée est de les mettre
en majuscules), suivi d'un :,
puis de la valeur de la propriété (celle-ci pouvant elle-même être
structurée, comme dans l'ADR ci-dessus).
Certains caractères sont spéciaux, comme la virgule et, si on veut les avoir comme valeur, doivent subir un échappement avec la barre inverse (section 3.4).
Les données peuvent avoir des paramètres. La section 5 décrit ce
concept. Un paramètre permet de préciser des métadonnées sur une
propriété. Par exemple, LANGUAGE permet
d'indiquer la langue d'un
texte. PREF permet de spécifier, lorsqu'il existe
plusieurs exemplaires d'une propriété, laquelle est préférée (celle
qui a la valeur la plus basse). Ainsi, dans l'exemple de l'AFNIC
ci-dessus, c'est le français qui est la langue
de contact préférée. SORT-AS permet de
définir un tri entre les valeurs (un problème
difficile pour les noms d'humains). TYPE permet
d'indiquer, pour une ADR, si elle concerne la
maison ou le travail. (vCard version 3 avait un mécanisme plus riche,
qui aurait permis, dans l'exemple de l'AFNIC ci-dessus, d'indiquer la
différence entre l'adresse postale - TYPE=postal
et l'adresse physique - TYPE=parcel. Trop confus,
il a été supprimé.) Et il existe plusieurs autres paramètres.
La sémantique est décrite dans la suite de
cette section 3.3 et, pour chaque propriété, dans les sections 4, 5 et 6.
Notons qu'une seule propriété est obligatoire (à part VERSION),
FN, le nom de l'entité décrite dans la vCard. Pour chaque propriété, la
section 4 indiquera si des valeurs multiples sont autorisées. Par
exemple, on peut avoir plusieurs NICKNAME
(surnom), mais un seul (facultatif) GENDER (genre).
Je ne vais évidemment pas lister toutes les propriétés que décrit la section 5 (voir le registre IANA pour une liste à jour). Pour chacune, elle donne son nom, sa cardinalité (zéro, zéro-ou-une, une, zéro-ou-plus, une-ou-plus occurrence) et son type. Pour ce dernier, il y a de nombreuses possibilités comme, par exemple, du texte libre, un URI, une date ou un temps (en utilisant la norme ISO 8601 et pas le plus simple RFC 3339), un booléen, un nombre entier, une langue (représentée selon le RFC 5646), etc.
À certains égards, la section 6 est la plus importante du RFC. C'est la liste de toutes les propriétés possibles actuellement, avec leurs caractéristiques. Quelques exemples, non limitatifs :
Nindique le nom, sous forme d'une série de composants (dont la plupart sont facultatifs). Pour les humains, je rappelle surtout que le fait d'avoir Prénom + Nom est très loin d'être universel.KINDindique quelle est la catégorie de l'entité décrite par cette « carte » (personne physique, organisation - comme dans l'exemple de l'AFNIC plus haut, etc).PHOTOest l'URI (éventuellement de plandata:, c'est-à-dire fournissant directement le contenu) d'une photo de la personne.LOGOjoue un rôle analogue pour les organisations.BDAYest la date de naissance de l'entité.IMPPindique le moyen de contacter l'entité par messagerie instantanée.LANGpermet d'indiquer, sous la forme d'une étiquette de langue commefroupt-BR, la langue à utiliser pour contacter l'entité.GEOest la localisation physique habituelle de l'entité, en suivant de préférence la syntaxe du RFC 5870. (Notez le « de préférence ». Analyser la syntaxe d'une vCard est très simple, mais accéder à la sémantique est bien plus complexe, en raison du choix qui est laissé pour le codage d'informations comme le numéro de téléphone ou la position physique.)KEYpermet de distribuer des clés cryptographiques (attention à comment on a récupéré le vCard avant de leur faire confiance...)
Notez que la liste n'est pas figée dans le temps (c'est une
nouveauté de vCard version 4). Des propriétés ou
paramètres nouveaux pourront être enregistrés, selon la procédure
décrite dans la section 10.2. Il faudra d'abord les discuter sur la
liste vcarddav@ietf.org, puis il y aura un examen
par un expert. Si accepté, le nouvel élément sera enregistré à l'IANA.
Le reste du RFC est consacré à des points d'utilisation des
vCard. Par exemple, la section 7 est consacrée à la synchronisation
des vCards entre deux engins (par exemple l'ordinateur du bureau et le
smartphone). Que faire si une entrée a été modifiée sur un carnet et détruite dans un autre ? Deux mécanismes sont fournis pour
aider à une fusion intelligente des deux carnets, une propriété
UID qui identifie de manière unique et non
ambigüe une entité (de préférence en utilisant le RFC 9562) et PID qui identifie une
propriété. Les section 7.1.1 et 7.1.2 détaillent l'algorithme à
utiliser lorsqu'on synchronise deux carnets. Par exemple, si on a
identifié, grâce à UID, une entrée dans les deux
carnets, et qu'une propriété est différente entre les carnets, alors, si la
cardinalité d'une propriété est de 1, ou bien si le PID est le même,
les deux propriétés doivent être fusionnées. Sinon, le synchroniseur
est libre de fusionner, ou tout simplement de mettre les deux
propriétés côte-à-côte. La section 7.2 donne des exemples détaillés de
fusions. À noter qu'il existe un protocole pour la synchronisation des
cartes avec un serveur, CardDAV, normalisé
dans le RFC 6352.
Le message d'enregistrement du type MIME text/vcard, qui
commençait la procédure, avait été fait en
août 2010.
Publier ainsi de l'information, parfois sensible, sur l'Internet,
n'est pas sans conséquences. La section 9 couvre les risques de
sécurité de vCard. Par exemple, la carte en elle-même n'offre aucune
garantie d'authentification ou d'intégrité. Rien ne prouve qu'une
carte indiquant FN:Theo de Raadt vient réellement
de de Raadt. Et même si la
carte était authentique au départ, rien n'indique qu'elle n'a pas été
modifiée en cours de route, sauf si elle a été transportée de manière
fiable (par exemple dans un message signé avec PGP). Bref,
ne vous fiez pas aveuglément à n'importe quelle vCard trouvée sur
l'Internet !
Autre risque, celui pour la vie privée. Ce
n'est pas par hasard ou par oubli que vous ne trouverez pas
BDAY ou ADR sur ma carte, un
peu plus loin. Une carte doit donc ne comporter que des informations
publiques, ou bien être uniquement transportée de manière sûre (par
exemple via un canal chiffré) et vers des gens
de confiance.
Les changements de vCard depuis la version 3 (qui était normalisée
dans les RFC 2425 et RFC 2426) sont décrits dans l'annexe A. La liste est
longue et pas facile à résumer (ce n'est qu'une accumulation de
changements ponctuels). Le changement que je trouve le plus
spectaculaire est la possibilité d'enregistrer de nouveaux éléments
sans changer de RFC, juste par un processus
d'enregistrement IANA. Sinon, voir la section 6.7.9 pour le rôle de la propriété
VERSION pour gérer le fait que les cartes en
circulation aient des versions différentes.
Si vous voulez en savoir plus sur vCard, le site Web du groupe de travail est très riche, quoique plutôt difficile d'accès (il est conçu pour le travail du groupe, pas pour la pédagogie).
Et du point de vue pratique, quels outils le programmeur a à sa
disposition s'il veut lire et/ou écrire du vCard ? Il existe une
bibliothèque pour les programmeurs
C (le paquetage se nomme libvc-dev sur
Debian), qui est utilisée dans des applications
comme rolo. Elle n'est distribuée avec aucune
documentation digne de ce nom et pas d'exemples. Pour les programmeurs
Perl, il existe
Text::vCard. Attention
à son analyseur : très laxiste, il accepte des vCards bourrées
d'erreurs de syntaxe.
Voici un exemple d'usage de cette bibliothèque Perl :
#!/usr/bin/perl
use Text::vCard::Addressbook;
for $file (@ARGV) {
my $address_book = Text::vCard::Addressbook->new({
'source_file' => $file});
$number = 0;
foreach my $vcard ($address_book->vcards()) {
print "Got card for " . $vcard->fullname() . "\n";
$number++;
}
if (!$number) {
print "No correct vCard in $file\n";
}
}
En Python, vous avez vobject dont voici un exemple d'utilisation pour afficher le vCard sous une forme plus lisible par un humain :
import vobject
with open("contacts.vcf") as f:
for vcard in vobject.readComponents(f):
print("Name:", getattr(vcard, "fn", None).value if hasattr(vcard, "fn") else "")
for email in getattr(vcard, "email_list", []):
print(" Email:", email.value)
for tel in getattr(vcard, "tel_list", []):
print(" Tel:", tel.value)
for adr in getattr(vcard, "adr_list", []):
print(" Adr:", adr.value)
print()
Ah, et si vous voulez me contacter, voici une carte pour moi :
BEGIN:VCARD VERSION:4.0 FN:Stéphane Bortzmeyer N:Bortzmeyer;Stéphane;;; UID:urn:uuid:a06340f8-9aca-41b8-bf7a-094cbb33d57e GENDER:M KIND:individual EMAIL:stephane+blog@bortzmeyer.org TITLE:Indigène de l'Internet PHOTO:http://www.bortzmeyer.org/images/moi.jpg LANG;PREF=1:fr LANG;PREF=2:en IMPP;PREF=1:xmpp:bortzmeyer@dns-oarc.net IMPP;PREF=2:xmpp:bortzmeyer@gmail.com URL:http://www.bortzmeyer.org/ KEY:http://www.bortzmeyer.org/files/pgp-key.asc END:VCARD
Merci à Simon Perreault pour sa relecture.
L'article seul
Les (amusantes) versions annoncées par les serveurs DNS
Première rédaction de cet article le 29 août 2011
Les serveurs DNS ont souvent une option (complètement non officielle) pour obtenir le numéro de version du logiciel utilisé. Par souci de dissimulation, ou tout simplement pour s'amuser, certains administrateurs système décident d'afficher à la place un petit texte, souvent humoristique.
Cette option est une simple convention : aucun
RFC ne l'a jamais normalisé. Mais, si vous
interrogez un serveur DNS pour le nom
version.bind, type TXT,
classe CH, vous obtenez cette information :
% dig @ns1.dns.example CH TXT version.bind ... ;; ANSWER SECTION: version.bind. 0 CH TXT "9.6.2-P3" ...
Comme son nom l'indique, cette option vient à l'origine de
BIND mais on la trouve dans bien d'autres
serveurs, comme NSD. BIND permet de la débrayer, ou bien de remplacer le
texte (option version dans le bloc
options, par exemple version "No information";). On voit ainsi des choses comme :
% dig @dns.sncf.fr. CH TXT version.bind ... ;; ANSWER SECTION: version.bind. 0 CH TXT "S.N.C.F. French Railways"
Si on lance DNSdelve à
l'assaut de tout .fr pour
regarder les textes ainsi diffusés, on trouve de nombreuses
perles. Par exemple :
- Des classiques purement informatifs comme « No version info available », « [Private Information] », « You are not cleared for that information » ou « Not Allowed »,
- Des textes plus menaçants comme « None of your business », « request logged and reported to abuse! », « mind your own business! » ou « This information is restricted, Your query has been logged. », « Your attempt to obtain details of this service has been duly noted! » ou « Guess, bitch »,
- Des références geeks comme « All your base are belong to us », « Nobody here but us chickens! », « WE ARE THE BORG. RESISTANCE IS FUTILE » ou « This is not the port you're looking for. »,
- Des textes écrits par le service juridique comme « If you have a legitimate reason for requesting this info, please contact hostmaster@Level3.net »,
- Diverses formes d'humour comme « Do you realy want version of this server ? Is your mother know what you do ??? Probably no ! », « Toaster connected to coffee cup », « This space is intentionally left blank », « My version is so secret that even I don't know what I'm running on », « Uppps, I lost my version number » ou « Insert your credit card » ou simplement « 0.0 ».
Merci à Nicolas Delvaux pour le programme. Et une dernière pour la route :
% dig +short @rigel.illyse.org CH TXT version.bind "OpenOffice DNS server 1.0"
Pour ceux qui se souviennent du pare-feu d'OpenOffice... Autre exemple rigolo en dehors de .fr :
% dig +short @ns1.conostix.com CH TXT version.bind "'\; DROP DATABASE mysql\; --"
L'auteur a tenté une injection SQL avec le DNS...
L'article seul
RFC 6346: The A+P Approach to the IPv4 Address Shortage
Date de publication du RFC : Août 2011
Auteur(s) du RFC : R. Bush (Internet Initiative Japan)
Expérimental
Première rédaction de cet article le 28 août 2011
Pendant longtemps, le problème technique posé à l'IETF par l'épuisement des adresses IPv4 était traité par la perspective d'une migration vers IPv6, et les efforts de l'IETF allaient vers la création de jolis mécanismes de transition vers ce nouveau protocole. Mais la migration est très loin d'être terminée (sur beaucoup de sites, elle n'a même pas réellement commencé) et, dans des régions comme l'Asie, les adresses IPv4 ne sont plus seulement difficiles à obtenir et chères, elles sont tout simplement toutes utilisées. Il faut donc maintenant, en urgence, mettre au point des mécanismes qui permettront de vivre pas trop mal en attendant le déploiement d'IPv6. C'est le cas du mécanisme A+P (Address plus Port) de ce RFC.
Tous ces mécanismes sont pour le court terme. À moyen et à long terme, la solution correcte, comme avant, reste le passage à IPv6. Toutefois, pour tous les paresseux et les irresponsables qui n'ont pas encore commencé cette migration, il est trop tard : même s'ils se réveillaient demain, ils n'auraient pas le temps de terminer leur transition vers IPv6 avant que le manque d'adresses IPv4 ne devienne un vrai blocage pour leur activité.
A+P, présenté dans ce RFC, propose une solution pour limiter les dégâts, chez les derniers utilisateurs d'IPv4. Cet article va être relativement court, par manque de temps pour explorer en détail cette technologie, mais aussi parce que je suis sceptique : c'est très gentil d'essayer de maintenir la tête des utilisateurs IPv4 hors de l'eau encore quelques mois ou quelques années, mais cela va coûter pas mal d'efforts, qui seraient mieux employés à leur apprendre à nager (à déployer IPv6).
Donc, quels sont les principes d'A+P ? Comme les miracles n'existent pas, l'idée de base est un compromis. On va sacrifier quelques bits du numéro de port pour les donner à l'adresse IP. Ce faisant, on réduit la capacité des applications à allouer beaucoup de connexions ouvertes (chacune nécessitant un port) mais il n'y a plus guère le choix. Comme le note le RFC, « the need for addresses is stronger than the need to be able to address thousands of applications on a single host » ou, en termes plus brutaux, « en cas de famine, on ne réclame pas d'assaisonnement sur tous les plats ».
Cette famine fait que le partage d'adresses IPv4, déjà largement réalisé au sein d'une même maison ou entreprise, va forcément s'étendre et que des clients différents, sans lien entre eux, partageront la même adresse IP. L'idée d'A+P est que, même si l'adresse ne sera plus unique, le couple {adresse, partie du port} restera unique par client. Avec 65536 ports possibles, on peut mettre 65536 clients sur une même adresse IP (si chacun se contente d'un seul port), 256 (avec 256 ports chacun), ou un seul (avec le système actuel où le client a 65536 ports)... L'un des intérêts d'A+P est qu'il limite (sans toutefois le supprimer) le recours au NAT et à tous ses inconvénients.
En effet, une alternative à A+P serait de déployer des gros routeurs NAT (CGN, pour Carrier-grade NAT) dans les réseaux des FAI, routeurs qui traduiraient pour plusieurs clients (au contraire du routeur NAT typique d'aujourd'hui, qui n'opère que pour un seul client). La section 1.1 explique pourquoi c'est une mauvaise idée : le CGN ne maintient pas la connectivité de bout en bout, qui est au cœur d'Internet. Par exemple, le déploiement d'une nouvelle application qui échange des adresses serait bloqué tant que le routeur CGN (qui est sous le contrôle du FAI) n'est pas mis à jour avec un nouvel ALG. Les techniques qui permettent de rendre les routeurs NAT actuels un peu moins insupportables (configuration manuelle de la redirection de port, UPnP) ne marchent en effet pas sur un CGN. Enfin, les routeurs CGN stockent un état considérable (des centaines ou des milliers de clients) et sont donc un point de faiblesse du réseau : si un routeur CGN redémarre, tout est perdu.
La section 3 détaille les contraintes que s'impose A+P, afin d'éviter ces défauts :
- Maintien, dans la mesure du possible, du principe de bout en bout (ne pas utiliser l'épuisement des adresses v4 comme excuse pour limiter l'usage que les utilisateurs peuvent faire de l'Internet),
- Compatibilité avec l'existant, par exemple, les anciennes applications doivent marcher comme avant,
- Ne pas garder trop d'état dans le réseau du FAI,
- Traçabilité des utilisateurs, c'est-à-dire capacité à fliquer quel ordinateur a fait telle action,
- Ne pas décourager la migration vers IPv6, comme, dit le RFC, le fait le NAT444 (ou « double-NAT »).
Ce cahier des charges est-il réaliste ? Le reste de la section 3 raconte comment fonctionne A+P. Il y a trois fonctions :
- Traduction : pour gérer les anciennes applications, qui allouent des ports sans restriction, et tournent sur une machine qui imagine être la seule au monde à avoir cette adresse IP, il faudra une fonction de traduction analogue au NAT actuel,
- Encapsulation et décapsulation : s'il y a des anciens routeurs sur le trajet, il faudra encapsuler les paquets. Ce sera le travail du PRR (Port Range Router),
- Signalisation : les machines nouvelles (qui connaissent A+P), ont besoin de savoir quelle plage de ports leur a été allouée.
Le traducteur devra faire bien attention, contrairement au NAT actuel, à n'utiliser en sortie que des ports appartenant à la plage allouée.
La signalisation est le gros morceau (section 3.3.1). A+P peut utiliser plusieurs protocoles pour cela (à ma connaissance, tous sont encore au stade de brouillon). Le protocole doit permettre d'informer une machine A+P de l'adresse IPv4 publique à utiliser, des plages de ports réservées pour elle, de la durée pendant laquelle ces allocations restent valables, etc. L'allocation des ports peut être statique (« tu as de 20 000 à 31 000 ») ou dynamique par des nouveaux protocoles comme UpNPv2.
Si on a un site client réduit, avec une seule machine, qui connaît
A+P, et un
équipement A+P chez le FAI, et que l'adresse IPv4
publique donnée au site client est {192.0.2.1,
ports 20 000 à 31 000}, un paquet sortant du site client est émis tel
quel (la machine sait n'utiliser comme port source que ceux alloués) et le paquet rentrant est traité ainsi dans l'équipement A+P :
- En regardant le port de destination, on trouve à quel client est destiné ce paquet (routage par le port, l'adresse IP ne suffisant plus, car elle est partagée entre plusieurs clients),
- On lui transmet.
Dans ce cas, pas besoin de traduction. Évidemment, dans la réalité, ce sera plus compliqué : il y aura plusieurs machines sur le site du client et, surtout, ces machines ne connaîtront pas toutes A+P et émettront donc des paquets avec des ports source quelconques. Cette fois, on ne pourra pas se passer de traduction : une machine chez le client (et non pas chez le FAI) va alors traduire ces paquets pour mettre l'adresse source allouée et changer le port source pour un des ports alloués. Au retour, ce même traducteur fera l'opération inverse, très proche de celle des routeurs NAT d'aujourd'hui.
Est-ce que tout cela marche vraiment en pratique ? La section 3.4 rend compte des essais effectués à France Télécom. Les plus gros problèmes sont survenus avec des mises en œuvre de BitTorrent, qui veulent accepter des connexions entrantes sur un port précis mais, globalement, il n'y a pas eu trop de problèmes.
Si vous aimez les considérations pratiques, la section 5 est vouée aux problèmes de déploiement. Par exemple, pour des sites client en ADSL ou connectés par le câble, le modèle le plus logique est que les fonctions de traduction soient dans la box, le FAI allouant les plages de ports et les communiquant audit CPE. (Pour un réseau 3G, c'est plus complexe, car le smartphone ne peut pas forcément assurer beaucoup de fonctions.)
Comment le FAI décide-t-il de l'allocation des ports (section 5.2) ? Une solution évidente est de diviser équitablement. Si on met cent clients par adresse IP, chacun a 655 ports et se débrouille avec. Le risque de cette allocation statique est alors que les clients les plus gourmands soient limités, alors que les autres ont des ports libres. L'idéal serait donc que l'allocation soit dynamique, s'ajustant à la demande.
Comme avec le NAT, certains protocoles vont poser des problèmes particuliers. Ainsi, ICMP (section 5.3.2), n'ayant pas le concept de port, va être difficile à faire passer. Pour les messages d'erreur transportés par ICMP, comme ils incluent le début du paquet qui a provoqué l'erreur, on peut y trouver un numéro de port et router par ce biais. Pour les messages d'écho (ceux qu'utilise ping), il n'y a pas d'autre solution que de bricoler avec des champs comme l'identificateur du message ICMP, ou comme le numéro de séquence ICMP, en les utilisant comme numéros de port.
Parmi les autres problèmes concrets que devra résoudre la machine A+P, il y a enfin la fragmentation, source traditionnelle d'ennuis. Ici, le routage se faisant en fonction du port de destination, un réassemblage des fragments entrants est nécessaire, pour déterminer ledit port.
A+P, on l'a vu, est un système complexe. Il a quelques limitations, documentées en section 5.3.4. La principale est que les ports bien connus, notamment le célébrissime port 80, utilisé par les serveurs HTTP, ne seront pas forcément disponibles. Si le client qui a obtenu une plage de ports située au début (du côté des ports bien connus, en dessous de 1024) est heureux (et on peut même envisager de le faire payer plus cher pour ce « privilège »), les autres n'ont pas de solution, s'ils veulent faire tourner un serveur HTTP sur leur machine.
Enfin, A+P marche mal ou pas du tout avec IPsec, bien qu'il soit possible de contourner le problème avec les techniques du RFC 3715.
Et question sécurité, ça se passe comment ? La section 7 fait la liste des questions de sécurité liées à A+P. La première est la difficulté de suivre à la trace un utilisateur. Pour savoir qui a osé commettre un délit aussi grave que de partager de la culture, il faut que l'espion qui surveille le trafic ait noté le numéro de port source (cf. RFC 6302), et que l'équipement A+P ait enregistré qui avait la plage où se trouve ce numéro. A+P est donc plus efficace pour le flicage qu'un CGN ou qu'un NAT traditionnel, qui doit noter une information bien plus évanescente (qui avait ce port à ce moment-là). Reste à savoir si c'est un avantage...
Quel est l'état des implémentations de A+P au moment de la
publication de ce RFC ?
L'ISC a A+P dans son routeur logiciel (surtout connu pour DS-Lite) AFTR (qui ne semble
actuellement pourvoir faire que de l'allocation de ports statique), France
Télécom / Orange a également un logiciel libre en http://opensourceaplusp.weebly.com/, et il existe le logiciel
4RD de la société ipinfusion.com.
Pour le futur, Iskratel et, dans une moindre
mesure, Cisco et
Juniper, ont indiqué qu'ils y travaillaient.
L'article seul
RFC 6360: Conclusion of FYI RFC Sub-Series
Date de publication du RFC : Août 2011
Auteur(s) du RFC : R. Housley (Vigil Security)
Pour information
Première rédaction de cet article le 22 août 2011
Les RFC, textes sacrés de l'Internet, comportaient un sous-ensemble, dénommé FYI (For Your Information), qui visait un public plus large que les ingénieurs réseaux et les programmeurs. Cette sous-série n'a pas été un grand succès, malgré la qualité des documents produits, et est officiellement abandonnée.
Lancée par le RFC 1150 en 1990, la sous-série FYI visait à élargir le lectorat des RFC et à fournir de l'information utile et techniquement correcte (puisque écrite directement par les experts) à un large public, celui de tous les utilisateurs de l'Internet (les autres RFC n'étant lus que par des geeks barbus). Trente-huit RFC ont été publiés dans cette sous-série, chacun recevant un numéro FYI. Ainsi, le RFC 1178 (FYI 5) expliquait comment choisir un nom pour son ordinateur, le RFC 1359 (FYI 16) détaillait l'intérêt et les bénéfices de se connecter à l'Internet (tout le monde n'était pas encore convaincu), et le dernier de la sous-série, le RFC 3098 (FYI 38) expliquait à quel point c'était mal de spammer. Parfois, le RFC était mis à jour, son successeur héritant de son numéro de FYI. Rappelez-vous qu'un RFC n'est jamais modifié, donc le nom « RFC 1594 » désigne toujours le même document alors que le nom « FYI 4 » a désigné plusieurs RFC successivement, depuis le RFC 1325, intéressant document historique, puisque c'est une FAQ pour les nombreux nouveaux utilisateurs de l'Internet (le dernier RFC pointé par « FYI 4 » a été le RFC 2664).
Depuis 2001, aucun numéro de FYI n'avait été attribué et le groupe de travail qui les gérait ne s'est pas réuni. Ce RFC 6360 ne formule pas d'hypothèse sur cet arrêt mais on peut penser que les experts n'avaient pas forcément le temps ou la compétence d'écrire pour les utilisateurs, et que le modèle des RFC (documents très stables et accessibles sur le long terme) n'était pas forcément adapté à des publications de ce type dans un Internet changeant très vite. Bref, la sous-série a tourné court. Dans d'autres organisations, on aurait continué pendant longtemps la fiction mais l'IETF préfère (et parfois réussit) nettoyer. Ce RFC 6360 marque donc officiellement la fin des FYI. Les documents existants restent accessibles mais il n'y aura pas de nouveautés.
Pour ceux qui veulent accéder à ces excellents documents, la liste
est disponible en http://www.rfc-editor.org/fyi-index.html.
L'article seul
RFC 6349: Framework for TCP Throughput Testing
Date de publication du RFC : Août 2011
Auteur(s) du RFC : B. Constantine (JDSU), G. Forget (Bell
Canada), R. Geib (Deutsche
Telekom), R. Schrage (Schrage Consulting)
Pour information
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 22 août 2011
La mesure des performances du réseau intéresse évidemment fortement
les utilisateurs (combien de temps me faudra-t-il pour télécharger
justin-bieber.flac ?) et les décideurs qui
cherchent à savoir, par exemple, quelle capacité offre un
FAI, s'il délivre bien le service promis, ou encore s'il
limite artificiellement les débits. La plupart des métriques définies
rigoureusement,
et des outils qui les mettent en œuvre, concernent des
phénomènes de bas niveau, comme le taux de perte de paquets (RFC 7680), C'est ainsi que, lorsqu'il existe des
SLA formalisés, ils portent en général sur ces
phénomènes proches du réseau. Ces métriques sont utiles et relativement faciles à
mesurer objectivement, mais elles sont très éloignées de l'expérience
ressentie par l'utilisateur final. Ce dernier voudrait plutôt
savoir comment l'intégration de toutes ces métriques de bas niveau se
traduit en un petit nombre de chiffres faciles à comprendre. Ce n'est
pas une tâche triviale que de passer des métriques de base au ressenti
utilisateur, et ce RFC est une première étape sur le chemin.
L'idée est de préciser les conditions de mesure de débit sur une connexion TCP, de bout en bout (donc tenant compte du comportement de tous les liens et équipements intermédiaires). Le débit mesuré en TCP donne une première idée de la capacité du réseau, qui est elle-même souvent la première métrique qui intéresse les utilisateurs (c'est en tout cas en général celle qui est mise en avant dans les publicités). Mais cette mesure contient de nombreux pièges et l'un des buts de ce RFC est de les lister. Au final, ce RFC ne permet pas de répondre simplement à la question de M. Toutlemonde « ça va moins ramer avec le fournisseur X qu'avec son concurrent Y ? », mais il avance quand même dans cette direction.
On grimpe donc d'une couche et on passe des mesures traditionnelles (taux de pertes, comme cité plus haut, ou bien capacité du lien au niveau 2) vers le niveau 4. Le désir de mesurer rigoureusement le débit atteignable avec TCP oblige à apporter quelques restrictions. Par exemple, le cadre de mesure décrit dans ce RFC se limite aux réseaux dont tous les aspects sont contrôlés par un fournisseur unique, avec des garanties explicites. Cela concerne donc plutôt la clientèle « entreprises ». La section 2 détaille tout ce qui n'est pas un objectif de ce RFC :
- Le comportement de TCP en dehors de l'équilibre (voir plus loin),
- La comparaison des mises en œuvre de TCP,
- La mesure en continu d'un réseau de production (pour cela, il vaut mieux utiliser la MIB TCP du RFC 4898).
Le but est au contraire de pouvoir mesurer, de manière objective et reproductible, les performances TCP d'un chemin donné, en fonction d'un certain nombre de réglages, bien définis. Les outils existants comme iperf ou ttcp permettent d'ajuster ces réglages.
Passons maintenant à la technique (la section 1.1 liste la terminologie employée) : TCP utilise à tout moment deux fenêtres, une pour l'envoyeur (congestion windows) et une pour le récepteur (receive window). Le débit théorique est limité par la bande passante (capacité de la couche 2) et par le RTT. Leur produit, le BDP (Bandwidth*Delay Product), va déterminer la taille des tampons optimaux (le tableau en section 3.3.1 donne des valeurs numériques). Ce BDP est, en gros, le nombre d'octets qui peuvent se trouver en transit à un moment donné. Ensuite, la fenêtre de congestion sera ajustée pour tenir compte du taux de pertes. Le nombre d'octets en route à un moment donné dépendra de la fenêtre la plus petite (si on a une grande congestion window mais que l'autre partie annonce une petite receive window, le débit restera faible : un émetteur TCP n'est pas censé noyer son pair sous les octets non désirés).
Toutes ces variables vont déterminer le débit effectivement atteint. Avant de tenter de mesurer celui-ci, le RFC insiste bien sur le fait que les tests de bas niveau (couches 2 et 3) doivent quand même être faits, pour déterminer que le réseau fonctionne bien. Le RFC note qu'un taux de pertes de paquets de 5 %, ou bien une gigue dans le délai d'acheminement de 150 ms, sont trop élevées pour que les mesures de débit TCP aient un sens. La méthodologie du RFC 2544 (bien que conçue à l'origine pour un environnement de laboratoire) peut être utilisée pour ces tests de bon fonctionnement.
Ensuite, notre méthodologie ne concerne que les connexions TCP ayant atteint l'état d'équilibre (section 1.2). Rappelons qu'une connexion TCP établie peut avoir trois comportements par rapport à la congestion : l'état d'équilibre où TCP essaie de remplir le tuyau au maximum, le démarrage en douceur, utilisé au début de la connexion, où TCP commence à sonder prudemment le réseau, en augmentant doucement son débit, et le troisième comportement, la récupération en cas de pertes, où TCP réduit brusquement son débit, avant de repartir plus ou moins doucement. En pratique, un certain nombre de connexions utilisées pour HTTP, par exemple, n'atteindront jamais cet équilibre, car elles durent trop peu de temps. C'est un bon exemple de la distance entre les mesures techniques et le vécu de l'utilisateur !
Dans un réseau idéal, à l'équilibre, TCP devrait avoir un débit très proche de la bande passante offerte.
La section 3 du RFC présente la méthodologie de mesure détaillée, avant que la section 4 ne décrive les métriques utilisées. La mesure impose d'utiliser un équipement capable de saturer le lien (donc, pas un vieux PC). Les mesures à plus de 100 Mb/s peuvent donc exiger une machine dédiée. La mesure exige ensuite les étapes suivantes :
- Déterminer la PMTU (en utilisant le RFC 4821, pour tenir compte des nombreux réseaux mal configurés
qui bloquent ICMP) pour ensuite
configurer le logiciel de test de manière à ce que les paquets soient
assez petits pour éviter toute fragmentation
(qui changerait drastiquement les performances). Par exemple, avec
iperf (cité plus loin), l'option
--msspermet de changer la taille des segments (des paquets TCP). - Déterminer le RTT minimum et la bande passante offerte par les couches basses. Cela servira à optimiser des paramètres comme le tampon d'envoi. Sur un réseau de production, cette mesure doit se faire aux heures creuses, pour être sûr d'obtenir vraiment la valeur « réelle ». Il existe plusieurs façons de mesurer le RTT. Le choix dépend de la précision souhaitée. Si on se contente de la milli-seconde, les paquets ICMP echo de ping conviennent (mais c'est quand même la technique la moins fiable, surtout s'il y a un traitement différencié pour ICMP dans le réseau, ou dans les machines de test). Si on veut se promener du côté de la micro-seconde, il faudra peut-être un dispositif de mesure spécialisé (voir section 5), et des protocoles comme celui du RFC 5357. Il y a aussi l'analyse des paquets capturés, avec un outil comme tcptrace, ou les statistiques gardées par TCP lui-même (RFC 4898). Quant à la mesure de la « bande passante » (un terme que je n'aime pas mais qui est utilisé par le RFC), elle devrait être faite suivant les règles du RFC 5136. Il ne faut pas oublier de la mesurer dans les deux directions, surtout avec les liens asymétriques comme l'ADSL.
- En enfin, faire les tests avec TCP, après avoir configuré le
logiciel de test. La section 5 recommande un test d'au moins trente
secondes, pour lisser les variations du réseau (avec iperf, c'est
l'option
--time, avec ipmt, c'est-d). Compte-tenu de la variété des mécanismes de tripotage du réseau qui existent, il peut être prudent de faire plusieurs mesures (par exemple de voir si une seule connexion obtient bien N fois ce qu'obtenait chacune des connexions d'un groupe de N connexions simultanées, cf. section 5.1).
Les métriques utilisées sont définies dans la section 4 du RFC. Elles sont au nombre de trois. La première est le ratio du temps de transfert, soit le rapport entre le temps nécessaire pour transférer N octets par rapport à la situation idéale (compte-tenu de la bande passante). Le calcul exact de cette situation idéale figure en section 4.1.1. Par exemple, pour une ligne T3 à 44,21 Mb/s exploitée en PPP, une MTU de 1500 octets, vus les en-têtes TCP, on arrive à 42,8 Mbps. Si on mesure un débit maximal de 40 Mbps, le ratio sera donc de 1,07 (rappelez-vous que c'est un rapport des temps de transfert, pas des débits). Pour un Ethernet 1 Gb/s, le cas idéal, qu'aucune amélioration du logiciel ne permettra de dépasser, est de 949 Mbps. L'utilisation de jumbo frames permettrait bien sûr de faire mieux.
La seconde métrique est l'efficacité de TCP. C'est le pourcentage des octets qui n'ont pas été retransmis. Il vaut donc 1 en l'absence de pertes (ou de retards qui mèneraient TCP à croire à une perte de paquets).
Plus subtile, la troisième métrique est le retard dû aux tampons. C'est le rapport entre l'excès de RTT (par rapport au RTT minimum, celui imposé par les caractéristiques de la ligne) et le RTT minimum. Par exemple, si le RTT minimum (qui, sur les lignes à grande distance, est souvent dépendant essentiellement de la vitesse de la lumière) est de 25 ms, et qu'on observe un RTT moyen de 32 ms pendant un transfert TCP, le retard dû aux tampons est donc de 28 %.
La première métrique est celle qui est la plus directement pertinente pour l'utilisateur. Les deux autres fournissent surtout un moyen de diagnostic : si le ratio du temps de transfert est mauvais, l'examen de l'efficacité et du retard dû aux tampons nous indiquera peut-être pourquoi.
Voilà, la norme est définie. La section 5, elle, revient sur les conditions pratiques de mesure. Entre autres, elle expose les règles du choix entre une seule connexion TCP et plusieurs. Ce choix dépend des caractéristiques du réseau (si le produit bande passante * délai est de 2 Moctets, une seule connexion TCP ne pourra pas remplir le tuyau, cf. le tableau des valeurs numériques en section 5.1).
Reste l'interprétation des résultats (section 5.2). Les résultats devraient toujours être accompagnés de la valeur des paramètres indiqués plus haut (ce que font les outils existants, cf. plus loin). Le RFC demande évidemment que les valeurs des trois métriques citées plus haut soient affichées, ce qui n'est pas (encore ?) le cas avec les logiciels Unix de mesure existants. Une fois qu'on a ces valeurs, si elles ne correspondent pas aux valeurs idéales, on peut se livrer aux joies du débogage : la congestion avec des tampons de petite taille dans les routeurs fera sans doute grimper les pertes de paquets, ce qui se traduira par une mauvaise efficacité TCP. Si les routeurs ont de quoi stocker les paquets en attente, c'est le RTT qui augmentera, ce qui se verra dans le retard dû aux tampons. Mais il peut aussi y avoir ralentissement délibéré par le réseau (policing), tampons trop petits sur les machines de test (qui ont, après tout, une mémoire limitée, qui peut être trop faible pour les réseaux à haute performance d'aujourd'hui). Les machines Unix ont de tels tampons aussi bien globalement pour tout le système que par socket. On peut fixer ces derniers (la valeur idéale est le BDP, le produit bande passante*délai) dans le programme, mais aussi les laisser s'ajuster automatiquement (service auto-tuning, qui existe dans Linux et FreeBSD ainsi que, depuis moins longtemps, Windows et Mac OS). Il faut également regarder du côté du mécanisme de window scaling (RFC 7323) sans lequel il est impossible d'exploiter les réseaux à très fort BDP qu'on trouve aujourd'hui. Et, bien sûr, émettre des paquets ayant la taille maximale possible sans fragmentation est aussi une bonne tactique.
Bien d'autres réglages de TCP sont possibles, comme l'option d'estampille temporelle (RFC 7323) qui permet à TCP de mieux calculer le RTT (et qui protège contre les numéros de séquence TCP qui reviennent à leur valeur initiale, un problème qui devient sérieux au delà de 100 Mb/s), les accusés de réception spécifiques (SACK) du RFC 2018, qui permettent de limiter les retransmissions, etc.
À titre d'exemple, voici des exemples de mesure, plus ou moins compatibles avec notre RFC, dans le cas de certains outils libres. Le premier est iperf. Existant sous forme de paquetage pour divers systèmes Unix (ici, Debian), il est facile à installer. On doit le lancer côté client et côté serveur (c'est un point commun entre tous ces outils : il faut un compte sur les deux machines ; on ne peut donc pas les utiliser pour tester son débit possible avec YouTube).
# Serveur % iperf -s ------------------------------------------------------------ Server listening on TCP port 5001 TCP window size: 85.3 KByte (default) # Client % iperf --print_mss --client test.bortzmeyer.org ------------------------------------------------------------ Client connecting to test.bortzmeyer.org, TCP port 5001 TCP window size: 16.0 KByte (default) ------------------------------------------------------------ [ 3] local 192.0.2.69 port 46908 connected with 203.0.113.232 port 5001 [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.0 sec 173 MBytes 145 Mbits/sec [ 3] MSS size 1448 bytes (MTU 1500 bytes, ethernet)
On peut aussi changer la taille de la fenêtre TCP. Les 145 Mb/s obtenus ci-dessus sont probablement indépassables mais, parfois, ce changement améliore les performances. Il peut aussi les dégrader, ici, on choisit une fenêtre très petite :
% iperf --window 1K --client test.bortzmeyer.org ... TCP window size: 2.00 KByte (WARNING: requested 1.00 KByte) ------------------------------------------------------------ ... [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.0 sec 27.3 MBytes 22.9 Mbits/sec
Cet exemple illustre l'importance de documenter, lorsqu'on publie les
résultats de la mesure, les options utilisées. Ici, on a divisé la
capacité utile par sept... (Quant au message d'avertissement, il vient
de l'habitude du noyau Linux de fixer la taille
de la fenêtre à une valeur double de celle qui est demandée.)
iperf permet théoriquement de faire fonctionner plusieurs sessions TCP
simultanées (option --parallel) mais j'avoue
n'avoir pas réussi à la faire fonctionner.
Un autre outil traditionnel est ttcp. Très
ancien, il a depuis été remplacé par des versions plus récentes. Je
vais utiliser nuttcp, également en paquetage dans tous les bons
systèmes. Son serveur a la désagréable habitude de passer en
arrière-plan immédiatement (et il ne semble pas y avoir d'option pour
changer cela), et on risque donc facilement d'oublier un serveur qui
tourne. Le mieux est donc de toujours le lancer avec l'option
-1 qui ne permet qu'un seul test.
# Serveur % nuttcp -1 # Client % nuttcp -v -t 203.0.113.232 nuttcp-t: v6.1.2: socket nuttcp-t: buflen=65536, nstream=1, port=5001 tcp -> 203.0.113.232 nuttcp-t: time limit = 10.00 seconds nuttcp-t: connect to 203.0.113.232 with mss=1448, RTT=2.173 ms nuttcp-t: send window size = 16384, receive window size = 87380 nuttcp-t: available send window = 12288, available receive window = 65535 nuttcp-t: 166.5708 MB in 10.00 real seconds = 17056.72 KB/sec = 139.7286 Mbps nuttcp-t: retrans = 0 nuttcp-t: 2666 I/O calls, msec/call = 3.84, calls/sec = 266.60 nuttcp-t: 0.0user 0.0sys 0:10real 0% 0i+0d 592maxrss 0+2pf 893+0csw
On note des chiffres proches de ceux de iperf, ce qui est
rassurant. nuttcp a le même genre d'options que iperf
(-l pour changer la taille des tampons,
-w pour la fenêtre TCP, etc). Il peut utiliser
plusieurs sessions TCP (option -N) mais ne semble pas
permettre de fixer la MSS.
Un outil plus récent, encore un peu expérimental mais qui a bien marché sur mes machines est ipmt. On lance le serveur ainsi :
% tcptarget IPv6 (and IPv4) protocol Using port 13000 ...
Et le client avec :
% ./tcpmt test2.bortzmeyer.org IPv4 protocol Time Packets Total | Kbit/s Avg 10 Avg 33496.429 486 486 | 5045 5045 5045 33497.345 179 665 | 2283 3805 3805 33498.467 134 799 | 1394 2950 2950 ...
et les résultats sont affichés en continu (utile si le réseau change).
Enfin, le traditionnel Netpipe ne semble plus guère maintenu et fonctionne mal sur les Unix récents.
Le RFC mentionne aussi d'autres outils comme
tcptrace, outil d'analyse des sessions
capturées au format pcap et qui, avec ses
options -r et -l, permet de
calculer des choses comme le RTT.
Un petit avertissement de sécurité, pour finir (section 6). Les mesures de ce RFC sont des mesures actives, susceptibles de perturber sérieusement le réseau. Le principe étant d'occuper tout le tuyau, la mesure ressemble fort à une DoS. Soyez donc prudent (RFC 4656 et RFC 5357).
L'article seul
CNP3, un livre libre de formation sur les réseaux informatiques
Première rédaction de cet article le 21 août 2011
Dernière mise à jour le 7 août 2022
Si on veut apprendre les réseaux informatiques, il existe d'innombrables articles et tutoriels sur l'Internet. Ce dernier, non seulement est une formidable réalisation de la science et de la technique des réseaux, mais c'est également un irremplaçable outil de diffusion du savoir. Mais on n'apprend pas un sujet complexe comme celui-ci en partant de zéro et en lisant les articles de Wikipédia. Cette encyclopédie est excellente quand on connait 90 % d'un sujet et qu'on a besoin de s'instruire sur les 10 % manquants. Mais ce n'est pas un outil pédagogique. L'apprenant a besoin d'une progression, d'un cadre, d'exercices bien calculés, bref, d'un livre de cours. Et, là, la situation est moins favorable.
Bien sûr, il existe des tas de livres d'apprentissage des réseaux informatiques. Outre que beaucoup sont écrits par des gens des télécoms, qui ne comprennent pas forcément bien les spécificités des réseaux d'ordinateurs, comme l'Internet, ces livres ont un défaut commun : il n'en existe à ma connaissance aucun qui soit distribué sous une licence libre. Résultat paradoxal : peu de livres expliquant le fonctionnement de l'Internet sont distribués via l'Internet.
Mais tout cela peut changer : grâce à Olivier Bonaventure et ses collègues de l'Université catholique de Louvain, un tel livre libre existe. Il se nomme Computer Networking : Principles, Protocols and Practice (CNP3 pour les intimes) et en est à sa troisième édition (voyez son site officiel). Quels sont les points importants de ce livre ?
- Licence libre, en l'occurrence la Creative Commons Attribution-ShareAlike 3.0 (obligation de citer les auteurs et obligation de garder le livre libre, dans le même esprit que la GFDL, la licence de mon blog).
- Livre écrit par des gens qui connaissent bien l'Internet (Olivier Bonaventure est un contributeur à l'IETF et son équipe a fait de très intéressantes recherches, notamment sur le protocole BGP).
- Exemples et exercices réels et concrets.
- Exemples et exercices utilisant des techniques accessibles à tous sur leur machine Unix : requêtes faites avec curl et dig, programmes en Python. Le côté pratique, expérimental, est très marqué, en contraste avec beaucoup de livres de réseau qui assomment leur lecteur avec des réseaux de Petri.
CNP3 a été réalisé en petit comité (« cathédrale » et pas « bazar », pour reprendre une terminologie fameuse d'Eric Raymond). Cela garantit l'indispensable (pour un livre de cours) homogénéité et augmente les chances que quelque chose de concret soit produit (contrairement à plein de « livres » sur Wikibooks, qui ne dépassent pas le stade de l'intention et du remue-méninges). Résultat, je ne suis pas forcément d'accord avec certains choix pédagogiques (comme ces curieuses « primitives » réseau) mais, dans ce domaine, il est crucial de choisir une ligne et de s'y tenir.
Les outils pratiques utilisés sont classiques et les formats
utilisés sont naturellement des standards ouverts : texte en format
ReST, images en SVG,
git comme VCS (le source
est en ligne) et
suivi des bogues (voir la liste
actuelle en https://github.com/cnp3/ebook/issues
J'encourage donc tous les gens qui connaissent déjà les réseaux informatiques à participer au travail de relecture du texte, et ceux qui ne connaissent pas ce sujet à l'apprendre avec le livre, pour aider à indiquer les obscurités ou les approximations que les experts ne voient pas forcément.
L'article seul
RFC 6333: Dual-Stack Lite Broadband Deployments Following IPv4 Exhaustion
Date de publication du RFC : Août 2011
Auteur(s) du RFC : A. Durand (Juniper Networks), R. Droms (Cisco), J. Woodyatt (Apple), Y. Lee (Comcast)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF softwire
Première rédaction de cet article le 14 août 2011
Il existe une myriade de techniques de coexistence entre l'ancien protocole IPv4 et le nouvel IPv6, à tel point qu'on peut même avoir du mal à faire son choix (voir mon exposé à ce sujet). Et le groupe de travail Soft Wires (réseaux virtuels variés) de l'IETF en invente de temps en temps des nouvelles. Pour ne pas s'affoler devant cette multitude, il faut se rappeler que chacune de ces techniques a un but bien précis et sert dans un cas donné. DS-Lite (Dual-Stack Lite), objet de ce RFC, vise les FAI récents, qui n'ont jamais eu d'adresses IPv4 publiques en quantité et dont le réseau interne est en IPv6 depuis le début.
Donc, DS-Lite est à l'opposé de, par exemple, 6rd (RFC 5969), qui vise les FAI existants qui n'ont pas le courage de mettre à jour leur réseau IPv4. DS-Lite vise un autre problème : si, en 2011, je crée un nouveau FAI en Asie (APNIC a été le premier RIR dont le stock d'adresses IP est tombé à zéro), je n'obtiendrai dans le meilleur des cas qu'une poignée d'adresses IPv4 publiques. Mais le reste de l'Internet (et même le réseau local de mes clients, et leurs applications) est majoritairement en IPv4. Mon beau réseau tout neuf, qui pourra être IPv6 depuis le début puisqu'il n'aura pas à porter le poids de l'héritage, ne me servira donc à rien (sauf à voir ce blog, qui est accessible en IPv6). Ce cas n'était pas prévu à l'origine ; il y a eu largement assez de temps pour faire une transition plus simple de IPv4 vers IPv6 mais beaucoup d'acteurs ont traîné les pieds, nous amenant à la situation actuelle, où il faut déployer IPv6 sans pouvoir compter sur des adresses v4 publiques en quantité suffisante. DS-Lite arrive alors à la rescousse.
Le principe de DS-Lite est donc de connecter à l'Internet IPv4 (et bien sûr aussi IPv6) des machines IPv4 (les machines des clients) au dessus d'un FAI v6, et sans avoir beaucoup d'adresses IPv4 publiques. (Les machines purement IPv6 ne sont donc pas concernées, elles ont une connexion native normale, seules les machines/applications qui utilisent encore IPv4 doivent passer par ce bricolage.) Le principe : le réseau local du client a des adresses privées v4. La box encapsule les paquets v4 au dessus du réseau v6 (tunnel IPv4-dans-IPv6) jusqu'à un NAT géant (CGN) qui traduit ces adresses en adresses publiques (il faut donc avoir au moins quelques adresses IPv4 publiques). DS-Lite réutilise donc deux techniques éprouvées, le tunnel et le NAT.
Pour suivre la description détaillée, un peu de vocabulaire (section 3). DS-Lite nécessite deux composants :
- Le B4 (Basic Bridging Broadband element, le B4 étant un jeu de mots car il se prononce comme before, indiquant que ce composant est avant le tunnel), qui est dans le réseau de M. Toutlemonde, et tunnele les paquets IPv4 de ce M. Toutlemonde vers :
- L'AFTR (Address Family Transition Router, ce qui se prononce comme after, indiquant que cet élément est après le tunnel), le CGN (routeur NAT géant) qui traduit des adresses IPv4 privées de M. Toutlemonde vers la poignée d'adresses IPv4 publiques qu'a pu obtenir le FAI.
Entre le B4 et l'AFTR, il n'y a qu'IPv6 : tous les paquets IPv4 doivent être tunnelés. Enfin, pour suivre ce RFC, il peut être utile de réviser le vocabulaire de la double-pile (RFC 4213) et du NAT (RFC 4787).
Voici un schéma d'une communication avec le serveur Web d'adresse
192.0.2.23. L'adresse IPv4 publique utilisée par
l'AFTR est 203.0.113.201. Le réseau IPv6 du FAI
utilise 2001:db8::32. Le réseau local reçoit des
adresses en 10.0.0.0/24 :
La section 4 décrit plus en détail les scénarios envisageables pour DS-Lite. Rappelez-vous d'un des points les plus importants des techniques de transition/coexistence v4/v6 : on n'est pas obligés de les déployer toutes, bien au contraire. Chacune s'applique à des cas spécifiques. Les avantages essentiels de DS-Lite, vus par le RFC :
- Une machine v4 ne communique qu'avec des machines v4 et une v6 qu'avec des v6. La traduction d'adresses se fait uniquement à l'intérieur d'une même famille (contrairement au NAT64 du RFC 7915).
- DS-Lite découple le déploiement d'IPv6 dans chacun des trois réseaux : celui du client final, celui du FAI et celui de l'Internet global. Plus besoin d'attendre que quelqu'un d'autre commence ou s'y mette.
- Le FAI n'a pas les limitations d'IPv4 dans son réseau interne (un vrai problème pour certains gros FAI, qui n'ont même pas assez d'adresses v4 pour leur propre réseau interne).
- Le tunnel entre le B4 et l'AFTR peut être situé où le FAI le désire. Le mode le plus courant sera sans doute avec le B4 dans le CPE et l'AFTR en sortie du réseau du FAI mais ce n'est nullement obligatoire. Cette souplesse permet à la solution de grossir tranquillement. Par exemple, si seuls les clients d'une certaine région utilisent DS-Lite, on met l'AFTR dans cette région puis, si on étend la solution à tout le monde, on reporte simplement le ou les AFTR plus loin et plus près du centre du réseau (cf. annexe A).
- Comme, du point de vue IPv4, les B4 sont directement connectés à l'AFTR, on peut envisager des techniques de contrôle du NAT par l'utilisateur (par exemple, réserver un port donné), peut-être avec le protocole PCP (Port Control Protocol, RFC 6887).
J'ai indiqué qu'un déploiement typique mettrait le B4 dans le CPE, dans la box. Ce n'est pas la seule possibilité. Mais ce sera sans doute la plus fréquente (l'annexe B décrit les différentes architectures, avec le détail des adresses). La section 4.2 décrit les caractéristiques d'un CPE ayant une fonction DS-Lite : il inclut un serveur DHCP pour distribuer des adresses IPv4 privées (RFC 1918) sur le réseau local, il ne fait pas de NAT lui-même (contrairement aux CPE d'aujourd'hui), il n'a pas d'adresse IPv4 publique, et, en IPv6, il est simplement un routeur ordinaire, sans traduction, ni particularités (connexion IPv6 native pour les clients qui en sont capables).
S'il n'y a pas de CPE (cas typique d'un smartphone connecté à un réseau 3G), la section 4.3 prend le relais : dans ce cas, la machine connectée doit être son propre B4.
La section 5 décrit en détail la fonction B4. Elle comprend la tunnelisation des paquets IPv4 vers l'AFTR. Au fait, comment le B4 connait-il son AFTR (section 5.4) ? Il doit être configuré avec l'adresse IPv6 de celui-ci, ou bien la récupérer via DHCP avec l'option du RFC 6334.
Pour le service DNS, le B4 doit connaître les adresses IPv6 des serveurs récursifs du FAI (rappelez-vous que la machine qui fait le B4 n'a typiquement pas d'adresse IPv4 publique), par exemple via DHCPv6. Les machines du réseau local, n'ayant pas forcément IPv6, il faut leur fournir un serveur récursif v4. Le RFC recommande que le B4 joue ce role et s'annonce lui-même comme récurseur (et suive alors les recommandations du RFC 5625).
Enfin, le B4 a besoin d'une adresse IPv4 à lui, pour les paquets
dont il est l'origine. La plage 192.0.0.0/29 a
été réservée pour cela (cf. section 10), le 192.0.0.2 étant pour
le B4. Ce préfixe a d'ailleurs été élargi ultérieurement à d'autres systèmes que DS-Lite dans le RFC 7335.
La section 6 fait la même chose (décrire tous les détails) pour la
fonction AFTR, qui est à la fois la terminaison du tunnel
IPv4-and-IPv6 et le CGN (Carrier-Grade NAT). Par
exemple, l'AFTR n'a pas de fonction DNS à assurer (le B4 fait la
résolution sur IPv6). Il a lui aussi une adresse bien connue,
192.0.0.1, et c'est celle qu'on verra sans doute
souvent lors des traceroute.
Pour que tout cela marche bien, il y a quelques détails techniques à régler. La section 7 couvre ceux qui concernent le réseau : notamment, le tunnel doit respecter les règles des RFC 2473 et RFC 4213. Et la section 8 couvre les détails liés au NAT : possibilité pour un AFTR d'avoir plusieurs plages d'adresses IPv4 publiques, pour des ensembles de B4 différents, conformité impérative aux RFC sur le NAT, comme les RFC 4787, RFC 5508 et RFC 5382, précisions sur la possibilité pour l'AFTR d'être aussi un ALG (découragée, vue le nombre de clients que sert un AFTR, et le nombre de protocoles applicatifs présents et futurs), rappel que tout partage d'adresses, que ce soit par DS-Lite ou une autre méthode, engendre des ennuis (RFC 6269), etc.
L'annexe A du RFC est particulièrement intéressant pour les administrateurs réseaux car il détaille les scénarios de déploiement possibles. Il couvre des questions comme le placement des AFTR dans le réseau, ou la fiabilité requise des AFTR (ils ont un état donc on ne peut pas juste en multiplier le nombre).
Comme tout nouveau protocole, DS-Lite va soulever des questions de
sécurité nouvelles, qu'étudie la section 11 du RFC. En soi, les
problèmes de sécurité liés au NAT sont bien connus (RFC 2663
et RFC 2993). Mais déplacer la fonction NAT depuis une
machine située chez l'utilisateur vers le réseau du FAI crée des
nouveaux défis. Par exemple, les adresses IPv4 publiques, qui
n'étaient partagées qu'entre les membres d'une même famille ou les
employés d'une même entreprise, vont désormais être partagées entre
des clients du même FAI, clients qui ne se connaissent pas. Si la
HADOPI voit 203.0.113.201
commettre un crime grave (par exemple partager des œuvres
d'art), et qu'elle veut couper l'utilisateur de cette adresse, la
probabilité de bavure devient bien plus élevée. Enregistrer les
adresses IP ne suffit donc plus, il faut noter l'adresse IP
et le port (RFC 6302) et que l'AFTR enregistre ses tables de
correspondance (identité du tunnel, protocole, adresses et
ports), comme précisé en section A.4.
Vu le partage intensif d'adresses (bien plus important qu'avec les NAT sur le CPE), le nombre de ports devient une ressource critique. L'AFTR doit donc faire attention à empêcher les utilisateurs de monter une DoS (volontairement ou par accident) en s'attribuant tous les ports possibles. Par exemple, l'AFTR peut limiter le rythme d'allocation des ports, ou bien mettre une limite absolue au nombre de ports qu'un B4 peut s'allouer.
Enfin, l'AFTR doit veiller à ne pas se transformer lui-même en un outil facilitant les DoS. Par exemple, il ne doit pas permettre à l'autre extrémité du tunnel d'injecter des paquets IPv4 avec d'autres adresses sources que celles prévues (autrement, les réponses à ces paquets frapperaient un innocent).
Notre RFC ne mentionne pas les inconvénients et problèmes de DS-Lite : c'est un mécanisme complexe, avec plusieurs composants qui doivent travailler en bonne intelligence. DS-Lite dépend notamment d'un composant très sollicité, le CGN. Sera t-il suffisant lorsque des dizaines ou des centaines de réseaux locaux utiliseront le même AFTR ? En outre, comme indiqué plus haut, DS-Lite souffre des problèmes liés au partage d'adresses : les lois HADOPI ou LCEN ne seront pas contentes.
Si, à ce stade, vous êtes convaincu de l'intérêt de DS-Lite dans
votre cas, où trouver des implémentations ? Il existe un AFTR en
logiciel libre à l'ISC, disponible en http://www.isc.org/software/aftr. Comcast
a aussi produit un code pour Linksys
(apparemment pas très stable mais suffisant pour des tests) et un pour
Mac OS (nommé ComcastDSLiteClient). L'ISC a rassemblé une documentation globale sur le B4. Enfin, les routeurs
d'A10 ont la fonction d'AFTR. Verrons-nous bientôt la
fonction de B4 dans tous les routeurs et boxes ?
Impossible à dire pour l'instant.
Merci à Fabien Delmotte pour ses connaissances sur les mises en œuvre de DS-Lite.
L'article seul
Le port source 53 du DNS, et les vieux fichiers de configuration
Première rédaction de cet article le 27 juillet 2011
L'informatique est à la fois un domaine de changements permanents (et souvent futiles) et d'extrême conservatisme. Sur bien des points, lorsque quelque chose marche, ou semble marcher, on n'y touche surtout pas. On voit ainsi parfois des survivances du passé bien vivantes, comme la persistance de résolveurs DNS qui utilisent le port source 53.
Les chiffres, d'abord. En regardant (avec DNSmezzo) un sous-ensemble des serveurs
DNS faisant autorité pour
.fr, on observe que 1,8 % des clients
(les résolveurs) envoient toutes leurs requêtes
depuis un seul port source, le 53. Ces clients
représentent environ 1 % des requêtes (ce sont donc des petits
résolveurs, en moyenne). Ce n'est pas beaucoup, c'est
moins que le pourcentage de requêtes envoyées via
IPv6, mais, en 2011,
c'est surprenant.
En effet, utiliser toujours le même port source a un gros inconvénient : cela rend plus facile d'injecter une réponse DNS mensongère, permettant ainsi un empoisonnement du cache du résolveur (par exemple, avec la méthode Kaminsky). Normalement, le port source doit être aléatoire (RFC 5452, pensez à tester le vôtre). En outre, utiliser le port source 53 peut poser des problèmes avec certains pare-feux, qui demandent que le port source des clients soit supérieur à 1023 (les ports plus bas étant réservés aux serveurs).
Alors, pourquoi est-ce que certains (le plus gros résolveur de la liste est le principal FAI d'un pays d'Afrique) utilisent quand même le port source 53 ? Parce que c'était la méthode recommandée, à une époque très lointaine. Au début des années 1990, on recommandait d'utiliser un port source inférieur ou égal à 1023 pour les services critiques, car, sur une machine Unix, seul un logiciel lancé par root pouvait utiliser ce port source (rlogin avait une méthode de « sécurisation » équivalente). Aujourd'hui, évidemment comme chacun est root sur son PC Linux, sa tablette et son téléphone, cela semble ridicule mais cela a longtemps été une recommandation souvent donnée et très suivie. Lorsque les premiers pare-feux sont apparus, vers la même époque, il était courant de filtrer sur le port source (ce qui est bien plus contestable, puisque ce port est complètement contrôlé par l'assaillant présumé).
Cette recommandation se retrouvait dans le comportement du résolveur DNS le plus utilisé, BIND, qui, jusqu'à la version 8.1 (sortie en 1997), utilisait le port source 53 par défaut. Le script de conversion des anciens fichiers de configuration rajoutait ceci en commentaire :
/* * If there is a firewall between you and nameservers you want * to talk to, you might need to uncomment the query-source * directive below. Previous versions of BIND always asked * questions using port 53, but BIND 8.1 uses an unprivileged * port by default. */ // query-source address * port 53;
Ce message s'est donc retrouvé dans un grand nombre de fichiers de
configuration, named.conf (y compris dans ceux
distribués par défaut dans des paquetages comme
celui de Debian), fichiers dont la syntaxe n'a
pas changé depuis.
Apparemment, un certain nombre d'administrateurs
systèmes avaient décommenté la ligne
query-source. Et, depuis désormais quatorze ans,
ils recopient fidèlement leur named.conf de
machine en machine, sans avoir jamais mis en cause ce réglage, et
sans s'être renseigné sur les évolutions de l'Internet. Bel exemple du
poids du passé.
L'article seul
RFC 6280: An Architecture for Location and Location Privacy in Internet Applications
Date de publication du RFC : Juillet 2011
Auteur(s) du RFC : R. Barnes, M. Lepinski (BBN Technologies), A. Cooper, J. Morris (Center for Democracy & Technology), H. Tschofenig (Nokia Siemens Networks), H. Schulzrinne (Columbia University)
Réalisé dans le cadre du groupe de travail IETF geopriv
Première rédaction de cet article le 24 juillet 2011
Aujourd'hui, de nombreuses applications des réseaux informatiques dépendent de la localisation physique de l'appareil mobile. La récolte de ces données de localisation (« le 31 mai 2011, à 08:04, l'appareil était en 40,756° Nord et 73,982° Ouest, ±150m »), leur transmission à travers le réseau, et leur traitement par le service qui héberge l'application posent de graves questions de protection de la vie privée, surtout quand on lit les conditions d'utilisation de ces services (si on pouvait comprendre le jargon juridique, elles se résumeraient à « nous faisons ce que nous voulons, nous nous occupons de tout, ne vous inquiétez pas »). D'où ce RFC qui essaie de définir une architecture de gestion de la vie privée pour ces informations de localisation.
Un exemple d'une telle application est Pages Jaunes sur Android : elle permet d'obtenir des réponses qui dépendent du lieu, tel que l'a indiqué le téléphone. Ainsi, si on tape « pizzeria », on obtient en haut du classement les pizzerias les plus proches physiquement. Résultat, les Pages Jaunes savent où vous êtes et on imagine facilement les conséquences pour la vie privée de ce genre de suivi (« L'utilisateur est allé quatre fois dans une clinique spécialisée cette semaine. »). Outre les Pages Jaunes, plusieurs intermédiaires connaissent également votre position (l'opérateur du réseau, qui sait par quelle borne vous vous connectez, les tiers qui écoutent, si le trafic n'est pas chiffré, et le téléphone lui-même qui peut garder cette information très longtemps, comme le fait l'iPhone). À noter que cette information est collectée en permanence, sans action explicite de l'utilisateur (section 1.2). Dans les romans policiers, finies les longues filatures sous la pluie pour savoir où passe le suspect. Le cyber-policier moderne ne bouge plus de sa chaise et obtient via le réseau toutes les informations nécessaires, chaque citoyen emportant avec lui volontairement l'outil qui permet de le suivre à la trace.
Le RFC (section 1) ne prétend même pas qu'il va régler ce problème, qui est consubstantiel de la récolte et diffusion d'informations de localisation : il affirme juste qu'il tente de limiter les dégâts.
Il y a deux autres points importants à comprendre sur cette « architecture de protection de la vie privée » : d'abord, ce n'est qu'une architecture, pas un protocole, encore moins un logiciel. Elle définit un cadre et des principes, elle ne fournit pas de solutions clé en main. Ensuite, s'agissant d'un travail de l'IETF, elle ne traite que l'aspect technique. Si on suit ce RFC, et les standards futurs qui le développeront, on peut faire un système relativement protecteur de la vie privée. Mais la technique ne suffit pas : le respect du RFC ne garantit pas la sécurité, c'est une norme technique, pas une politique. Des lois de protection de la vie privée (et qui soient d'application générale, pas annulables par des conditions d'utilisation d'un service commercial), bien appliquées et une vigilance citoyenne permanente sont nécessaires si on veut empêcher la vie privée de devenir une marchandise comme les autres.
Ce RFC 6280, œuvre du groupe de travail Geopriv, qui travaille sur tous les problèmes situés à l'intersection de la localisation et de la vie privée, tourne autour de la notion d'« objet de localisation » (une bonne introduction à Geopriv est le RFC 3693). Cet objet stocke la localisation et les règles d'utilisation de cette information. Lorsque l'objet est transmis, les conditions d'utilisation voyagent avec lui (section 1.1). Ainsi, celui qui reçoit une information de localisation ne peut pas prétendre ignorer les règles qui s'y attachent. Ces règles sont, par exemple, « ne transmets ces données à personne » ou, plus subtil, « ne transmets les informations à mon entreprise que pendant les heures de travail ».
Lier les règles d'usage aux informations de localisation est contraignant mais permet de d'assurer que le destinataire a accès à ces règles. Le RFC cite l'exemple des licences libres comme Creative Commons, qui imposent une telle liaison. Il y a eu de nombreuses polémiques (par exemple au sujet de la GFDL), sur l'opportunité d'imposer l'inclusion du (long) texte de la licence dans chaque document couvert par cette licence mais le but est le même : couper court à toute tentative de jouer l'ignorance. Un autre exemple donné par le RFC est celui des classifications utilisées par les militaires (« Secret », « Confidentiel », etc). Tous les documents sont marqués avec leur niveau de sécurité et tout militaire qui les manipule sait donc exactement ce qu'il peut faire ou ne pas faire avec ce document. (Un exemple détaillé figure dans les règles de classification du ministère de la défense états-unien.)
La solution radicale serait évidemment d'arrêter la collecte et la transmission de ces informations. Mais, outre qu'elles peuvent permettre d'améliorer certains services (comme dans l'exemple des pizzérias plus haut), des systèmes comme le GSM ne peuvent pas fonctionner sans connaître la localisation de l'utilisateur (pas moyen de lui faire suivre un appel entrant si on ne sait pas quelle borne le dessert en ce moment). Comment limiter les dégâts ? Historiquement, les décisions en matière de vie privée étaient prises uniquement par le récepteur des données, qui en faisait à peu près ce qu'il voulait. Le seul choix de la personne concernée était de partager ses données ou pas, et ce choix binaire ne permettait pas d'indiquer ce qu'il acceptait qu'on fasse des données (section 1.3). Comme, évidemment, les intérêts des personnes ne coïncident pas avec ceux des entreprises privées et organisations étatiques qui reçoivent les données, les abus étaient inévitables. Par exemple, un utilisateur envoie volontairement son adresse électronique sur un site Web pour recevoir ensuite des informations, mais il ne pouvait jamais s'opposer à ce que cette adresse soit ensuite revendue à des spammeurs. (Aujourd'hui, il est courant de voir une case à cocher « J'accepte de recevoir du spam, pardon, que mon adresse soit revendue à des tiers » mais il faut noter que c'est le site Web destinataire qui définit les choix possibles, pas le titulaire de l'adresse.) Geopriv pose donc comme principe que l'utilisateur, pas le destinataire, définit les usages acceptables, et les indique avec les données. À noter que ce n'est qu'une indication. Il n'existe pas de moyen technique de s'assurer que ces choix de l'utilisateur seront respectés, une fois les données transmises. Sur un réseau distribué comme l'Internet, il n'y a pas de possibilité de concevoir un mécanisme technique de respect de ces règles. Celui-ci doit être assuré par des moyens autres, comme la loi (loi Informatique & Libertés, par exemple), des régulateurs efficaces et/ou le marché (note personnelle : pour des raisons idéologiques, le marché est mentionné par le RFC comme mécanisme possible de rétroaction sur les entreprises qui violeraient les usages spécifiés par l'émetteur ; l'expérience déjà ancienne de l'Internet en matière de protection de la vie privée montre bien la vanité de cette idée). Le mécanisme technique de Geopriv sert donc juste à s'assurer que le destinataire des données était conscient des règles et donc, s'il les a violées, qu'il était de mauvaise foi (ce qui est important pour d'éventuelles poursuites judiciaires).
Avec la section 3 commence la partie la plus technique du RFC : elle décrit l'architecture utilisée. Les deux objectifs de cette architecture sont :
- S'assurer que les données de localisation ne soient distribuées qu'aux entités autorisées,
- S'assurer que ces entités soient au courant des conditions d'usage.
Comme on l'a vu, s'assurer que les entités réceptrices ne peuvent pas techniquement violer les règles est un non-but : il n'est pas réalisable techniquement. Pour atteindre les deux objectifs, il y a deux classes de règles :
- Les contrôles d'accès qui indiquent les entités autorisées,
- Les règles d'usage, qui indiquent ce que celles-ci ont le droit de faire.
Un exemple figure en section 3.1, décrivant le « cycle de vie » des données. Alice se déplace. Son mobile apprend sa position (par le réseau de communication, ou bien par GPS) et elle veut partager cette information avec ses amis via un service de présence (un tiers, qu'on suppose de confiance). Avec cette information viennent les règles d'usage qu'Alice a définies, par exemple que les amis ne peuvent pas garder cette information plus de N jours. Si un ami, mettons Bob, veut transmettre l'information sur la localisation d'Alice à des amis à lui, il devra également vérifier si les règles d'usage lui permettent (rappelez-vous que ce RFC définit une architecture de sécurité, pas des moyens techniques de protection ; comme le savent ceux qui ont essayé de mettre en œuvre des DRM, il n'existe aucun moyen technique d'empêcher Bob de tricher et de faire suivre ces données à des gens non autorisés).
Décrire ensuite tout ce qui se passe nécessite un vocabulaire élaboré (section 3.2). On y trouve de nombreux rôle (un même acteur pouvant tenir plusieurs rôles) :
- Le sujet (target) est la personne dont on veut protéger la vie privée (Alice, dans l'exemple précédent),
- L'engin (device) est la machine que porte le sujet (par exemple son smartphone) ; techniquement, c'est lui qui est localisé, pas le sujet (pensez au nombre de films où un personnage jette son téléphone pour ne pas être repéré),
- Le décideur (rule maker) est celui qui définit les règles d'usage ; c'est souvent le sujet, mais cela peut être le responsable sécurité de son entreprise,
- Le localisateur (location generator) est le matériel ou logiciel qui détermine la localisation ; cela peut être un récepteur GPS ou bien la partie GSM de l'appareil, qui obtient sa localisation à partir du réseau GSM,
- Les serveurs de localisation (location server), terme impropre : un serveur de localisation est une entité susceptible de transmettre l'information de localisation, en appliquant les règles d'usage. Dans l'exemple plus haut, Alice, le serveur de présence, et Bob connaissaient tous les trois la localisation d'Alice et étaient susceptibles de la transmettre (et donc étaient des serveurs de localisation potentiels),
- Les destinataires de la localisation (location recipient) sont toutes les entités qui connaissent la localisation du sujet et s'en servent mais ne la transmettent pas forcément. Bob, le serveur de présence, les autres amis qui ne relayaient pas l'information, sont tous des destinataires de localisation.
J'ai simplifié en mettant un seul décideur et un seul localisateur mais il peut y avoir des cas plus complexes.
Pour mettre en œuvre l'architecture de sécurité Geopriv, on a besoin de deux formats de données :
- Les objets de localisation (LO pour Location Object, cf. RFC 5491), qui stockent une position, exprimée en géodésique (geodetic, c'est-à-dire longitude, latitude, altitude) ou bien en civil (civic, comme 120, rue de la Gare, 75013, Paris..., voir par exemple le RFC 5139),
- Les règles d'usage (PR pour Privacy Rules, et RFC 4745 pour un exemple de langage pour exprimer ces règles).
En utilisant cette terminologie, la section 4 du RFC décrit le cycle de vie de l'information de localisation. Elle passe par trois étapes :
- Détermination de la localisation (un fix, dans la terminologie GPS),
- Distribution de la localisation, par les serveurs de localisation,
- Utilisation de la localisation, par les destinataires.
Les trois étapes sont ensuite étudiées une à une, chacune posant des problèmes spécifiques de protection de la vie privée.
La section 4.1 parle de la détermination. Elle peut être faite par l'engin lui-même (GPS, observation des étoiles et bien d'autres, y compris pour le cas trivial où l'utilisateur rentre manuellement l'information), par le réseau auquel il se connecte, ou bien via une coopération entre tous les deux. Dans le premier cas, guère de problème de sécurité dans cette étape, l'engin étant tout seul (les satellites GPS ne dialoguent pas avec l'engin, ils ne savent pas qui les utilise). Bien plus délicat est le cas où c'est le réseau qui détermine la position. C'est ce qui se produit en GSM (le réseau sait avec quelle base parle l'engin, et l'intensité du signal, ainsi que sa direction, peuvent donner une idée plus précise de la position de l'engin) mais évidemment aussi en connexion filaire, où le réseau sait exactement où on se trouve. Tout mécanisme du genre GeoIP est également un cas de détermination de la position par le réseau. Il n'y a pas forcément besoin d'un protocole réseau. Mais le point important est qu'un tiers (pas seulement le sujet) connait dès le début la position de l'engin. Enfin, le troisième cas est celui de la détermination assistée par le réseau. Par exemple, un engin va mesurer un certain nombre de choses comme la force du signal radio, l'adresse MAC obtenue, etc, et les envoyer à un localisateur qui en déduira une position précise. Cette fois, il y a un protocole réseau (entre l'engin et le localisateur), qu'il faut protéger, par exemple contre l'écoute.
L'étape de détermination est le premier endroit où on peut appliquer des mesures de protection, comme l'utilisation d'identificateurs qui ne permettent pas un lien simple avec l'utilisateur, et comme le chiffrement pour empêcher l'écoute, dans le cas où la détermination emploie un dialogue sur le réseau.
La deuxième étape est la distribution de l'information de localisation (section 4.2). C'est là que les règles d'usage commencent à jouer un rôle, en limitant la redistribution. Voici quelques exemples de règles :
- Ne retransmettre cette information qu'aux machines dont le nom
se termine en
example.com, - Ne transmettre de l'adresse que la ville et le pays (pas la rue),
- Dans la même idée de dégradation délibérée de la précision, ne transmettre de la longitude et latitude que des valeurs arrondies à la minute d'angle la plus proche (environ deux kilomètres)...
Les deux derniers exemples montrent qu'un serveur de localisation a deux armes à sa disposition, ne pas transmettre la localisation du tout, ou bien la transformer pour limiter les risques.
Pour cette étape de distribution, les choses les plus importantes sont de toujours transmettre les règles d'usage avec la localisation, et de respecter ensuite ces règles. Ces règles pouvant dépendre de l'identité de celui à qui on transmet, utiliser des techniques d'authentification fiables est donc impératif. De même, il faut veiller à ce qu'un tiers non-autorisé ne puisse pas accéder aux données qui circulent sur le réseau, donc le chiffrement est fortement souhaité. On est là dans un domaine plus traditionnel pour l'IETF, la conception de protocoles réseaux sûrs.
Enfin, la troisième étape du cycle de vie de l'information de localisation est l'utilisation de l'information (section 4.3). Le destinataire doit respecter les règles d'usage, qu'il a reçu avec l'objet de localisation. Normalement, ce respect est obligatoire et des mesures administratives ou légales doivent être déployées pour s'assurer que ce soit le cas. Cette étape ne comprend pas de transmission de l'information et ne nécessite donc pas de protocole réseau.
La section 6 du RFC fournit des exemples de scénarios concrets
d'utilisation de cette information de localisation. Le premier
scénario est très simple : un engin détermine sa position et la
transmet à une application Web dans une requête
HTTP de type POST ou bien
une requête SIP de type
INVITE. Le serveur fournit le service demandé,
sans stocker l'information de localisation. Dans ce cas ultra-simple,
pas de place pour les architectures compliquées, les rôles sont bien définis (le RFC oublie
toutefois de rappeler que la connexion entre l'engin et le serveur
doit être protégée contre l'écoute).
Plus complexe, en section 6.2, le cas où un navigateur Web qui fait appel à des API de détermination de sa position (comme la Geolocation API, dont l'implémentation fait souvent appel à l'aide du réseau d'accès) et exécute du code JavaScript qui va appeler des services d'assistance à la détermination de la position (voyez un bon tutoriel en « Geocoding A User's Location Using Javascript's GeoLocation API »). Notez qu'une partie des risques peut provenir d'une action du navigateur après avoir obtenu sa position. Par exemple, s'il demande à Google Maps une carte des environs, Google Maps, bien que n'étant pas partie lors de la détermination de la position, la connaîtra désormais. Il y a plus de deux acteurs, cette fois (notez que, même sur une machine unique, il peut y avoir plusieurs composants logiciels ne se faisant pas mutuellement confiance) et donc davantage de complexité.
Enfin, le troisième scénario est plus critique puisqu'il concerne un appel d'urgence, domaine très régulé, puisque beaucoup d'opérateurs ont l'obligation légale de fournir automatiquement la localisation de l'appel. Ici, la distribution de l'information se fera typiquement en utilisant LoST (RFC 5222).
Comme tout RFC, notre RFC 6280 inclut une section sur les problèmes de sécurité (section 5). Ici, elle sert surtout de rappel car tout le RFC est consacré à la sécurité. Parmi les rappels : le fait qu'il existe déjà des protocoles fournissant les fonctions de sécurité importantes (IPsec et TLS, par exemple) et que les solutions de localisation devraient les utiliser. Autre rappel : la sécurité de bout en bout est préférable à la sécurité transitive et il est donc recommandé qu'on sécurise l'ensemble du trajet, pas juste chaque étape (pensez au cas de Bob faisant suivre un objet de localisation : l'a-t-il modifié ?). Une bonne étude générale des problèmes de sécurité de Geopriv est dans le RFC 3694.
L'article seul
RFC 6317: Basic Socket Interface Extensions for Host Identity Protocol (HIP)
Date de publication du RFC : Juillet 2011
Auteur(s) du RFC : M. Komu (Helsinki Institute for Information Technology), T. Henderson (The Boeing Company)
Expérimental
Réalisé dans le cadre du groupe de travail IETF hip
Première rédaction de cet article le 23 juillet 2011
Il ne sert à rien de disposer d'un nouveau protocole si les applications ne s'en servent pas. Et, pour qu'il y ait une chance qu'elles s'en servent, il faut qu'elles aient une API standard pour cela. Ce RFC spécifie une possible API pour le protocole HIP (RFC 9063), un protocole qui sépare l'adresse IP de l'identité d'une machine. Celle-ci est désormais une clé cryptographique et l'API permet d'établir des connexions en connaissant la clé.
Cette API ne concerne pour l'instant que le langage C. Son utilité principale commence lorsque l'identificateur HIP a été obtenu (par exemple par le DNS, cf. RFC 8005) et lorsque l'adresse IP est connue. Elle prévoit toutefois d'autres cas. Spécifique à HIP, elles pourrait toutefois être étendue dans le futur à d'autres protocoles réalisant une séparation du localisateur et de l'identificateur, comme SHIM6 (RFC 5533). Notez que cette API utilise déjà certaines extensions créées pour SHIM6 et spécifiées dans le RFC 6316.
À quoi ressemblent les identificateurs que manipule cette API ?
Nommés HIT pour Host Identity
Tag, ce sont des résumés cryptographiques des clés publiques des
machines (clés nommées HI pour Host
Identity). Stockés sur 128 bits, ils sont, pour faciliter
leur traitement, représentés sous forme d'adresses
IPv6, en utilisant le préfixe ORCHID décrit
dans le RFC 4843. Par exemple,
2001:10::1 est un HIT.
Certaines applications, ignorantes de ce qui se passe dans les couches basses, n'auront pas besoin d'être modifiées pour HIP (cf. RFC 5338). Les autres doivent suivre notre RFC, dont la section 1 expose les principes généraux :
Bien, commençons par le commencement, la résolution de noms
(section 3). D'abord, le cas où l'application a un
résolveur à sa disposition (section
3.1). Celui-ci, en échange d'un nom de domaine, fournit les
informations qu'il a trouvées, typiquement dans le
DNS : HIT ou HI, adresses IP et peut-être des
serveurs de rendez-vous (RFC 8004). L'application a donc uniquement à appeler
getaddrinfo() et elle récupère des
HIT, qu'elle utilise pour remplir les informations transmises à la
prise. Le résolveur a fourni à HIP les informations auxiliaires comme
la correspondance entre un HI et des adresses IP.
Et si on n'a pas de résolveur HIP (section 3.2) ? Cette API permet à une application, de fournir quand même tous les détails nécessaires pour réussir une connexion (notamment les adresses IP associées à un HI).
La section 4 définit formellement la nouvelle API. D'abord, les
structures de données. Le
nouveau type sockaddr est défini ainsi :
typedef struct in6_addr hip_hit_t;
struct sockaddr_hip {
uint8_t ship_len;
sa_family_t ship_family;
in_port_t ship_port;
uint32_t ship_flags;
hip_hit_t ship_hit;
};
Le résolveur prend des nouvelles options (section 4.2). La nouvelle famille
AF_HIP, passée à
getaddrinfo(), indique que l'application veut
uniquement parler HIP et que toutes les sockaddr
doivent donc être de ce type, quant à l'option
AI_NO_HIT, elle indique au contraire que
l'application ne veut pas entendre parler de HIP.
Une fois la connexion HIP établie, l'application peut se servir de
getsockname() et
getpeername() pour trouver des
informations sur la machine paire (section 4.3). Elles permettent par
exemple d'accéder au HIT de celle-ci (ce qui est utile si
l'application acceptait n'importe quel HIT).
Si la machine dispose de plusieurs identités, le choix du HIT
utilisé comme source est laissé à l'initiative du système. Si
l'application veut l'influencer, elle peut se servir de mécanismes
analogues à ceux du RFC 5014 : une option de
setsockopt(),
HIT_PREFERENCES (section 4.4), et deux valeurs possibles :
HIT_PREFER_SRC_HIT_TMP: donner la préférence aux HIT temporaires (dits aussi « anonymes », cf. sections 5.1.2 et 7 du RFC 5201),HIT_PREFER_SRC_HIT_PUBLIC: donner la préférence aux HIT publics.
Si HIP_HIT_ANY signifiait qu'on exigeait une
connexion HIP mais avec n'importe qui,
HIP_ENDPOINT_ANY indiquait qu'on n'avait même pas
cette préférence et que des connexions non-HIP étaient
possibles. Mais, après coup, on veut parfois savoir ce qu'on a obtenu
et la nouvelle fonction sockaddr_is_srcaddr()
(section 4.5) permet de savoir si le pair avec lequel on s'était
connecté utilisait HIP ou pas. (Il y a aussi une fonction
hip_is_hit() qui teste simplement si une valeur
de 128 bits est bien un HIT.)
On l'a vu, cette API permet, dans une large mesure, à une
application de se connecter en HIP en ignorant presque tout de ce
protocole : il suffit d'indiquer AF_HIP au lieu
de AF_INET6 et ça roule. La traduction des HIT en
localisateurs est notamment effectuée automatiquement, l'application
ne se souciant pas de ces derniers. Toutefois, certaines
applications peuvent vouloir davantage de contrôle, notamment sur le
choix des localisateurs (les adresses IP). La section 4.6 est faite
pour elles. Elle s'appuie sur les options SHIM6
du RFC 6316. Par exemple, l'option
SHIM_LOC_PEER_PREF permet, avec
setsockopt(), de définir le localisateur préféré
et, avec getsockopt(), de découvrir le
localisateur utilisé.
Quelques points sur la sécurité viennent compléter ce RFC, en
section 6. Ainsi,
l'option HIP_ENDPOINT_ANY dit explicitement qu'on
accepte des pairs non-HIP, pour les connexions entrantes ou
sortantes. On peut donc se retrouver sans la sécurité associée à HIP
(notamment l'authentification du pair). Les applications soucieuses de
sécurité devraient donc utiliser HIP_HIT_ANY et
pas HIP_ENDPOINT_ANY.
Aujourd'hui, cette extension de l'API traditionnelle ne se retrouve pas encore dans Linux, ni dans un des BSD. Pour cela, un programme comme echoping n'a donc pas encore de possibilité d'utiliser HIP (cf. bogue #3030400.)
L'article seul
RFC 6314: NAT Traversal Practices for Client-Server SIP
Date de publication du RFC : Juillet 2011
Auteur(s) du RFC : C. Boulton (NS-Technologies), J. Rosenberg (Skype), G. Camarillo (Ericsson), F. Audet (Skype)
Pour information
Première rédaction de cet article le 23 juillet 2011
Aujourd'hui, il est rare pour une machine individuelle (ordinateur de bureau, ordinateur portable, smartphone, tablette, etc) d'avoir un vrai accès Internet. Presque toujours, la malheureuse machine est limitée à une adresse IP privée et coincée derrière un NAT qui traduira cette adresse à la volée. Cela ne gêne pas trop certains protocoles (SSH sortant, par exemple) mais est beaucoup plus gênant pour d'autres, notamment le protocole de téléphonie sur IP SIP. Ce RFC décrit l'ensemble des techniques que doivent mettre en œuvre les clients SIP pour arriver à passer quand même. C'est la meilleure lecture pour commencer à se pencher sur le problème « pourquoi a-t-on si souvent des problèmes avec SIP ? ».
Pour comprendre pourquoi SIP (RFC 3261) est particulièrement affecté, il faut se rappeler qu'il utilise des références : le client SIP indique au serveur à quelle adresse répondre, par exemple à quelle adresse envoyer les paquets audio du protocole compagnon RTP (RFC 3550). En présence d'un NAT, la machine ne connait pas son adresse IP telle que vue de l'extérieur et, de toute façon, le NAT traditionnel (qui agit sur le port, pas seulement sur l'adresse en dépit de son nom) bloque les paquets entrants, ne sachant pas que le flux RTP est lié à la connexion SIP. Pire, les différents routeurs NAT ont des comportements différents et il est donc difficile de trouver une solution qui marche partout (RFC 4787).
Ces problèmes du NAT sont bien connus et documentés. L'essentiel du code réseau d'un client SIP est consacré à contourner le NAT. Des solutions partielles ont été développées comme STUN (RFC 5389), TURN (RFC 5766), ICE (RFC 8445) ou bien des solutions spécifiques à SIP comme le RTP symétrique (RFC 4961), ou le SIP sortant (RFC 5626). Toutes ces solutions sont partielles et il manquait un document de haut niveau, décrivant le mécanisme général. Ce RFC 6314 ne propose donc pas « encore un nouveau protocole » mais explique la marche à suivre et les bonnes pratiques pour passer outre les routeurs NAT.
SIP peut être utilisé dans des contextes très différents : ce RFC se focalise sur l'utilisation en « client-serveur » où un client SIP (par exemple un softphone) appelle un fournisseur SIP qui routera l'appel vers le destinataire. Le SIP pair-à-pair (actuellement expérimental) n'utilisera pas forcément les mêmes techniques.
La section 3 détaille le problème que rencontrent les clients SIP en présence du NAT. Si le routeur NAT contient un ALG, celui-ci peut interférer avec SIP, par exemple en interdisant les communications chiffrées, ou bien en imposant que le même chemin soit emprunté à l'aller et au retour. Comme documenté dans les RFC 4787, RFC 3424 et RFC 8445, les ALG sont donc une solution limitée.
Et s'il n'y a pas d'ALG ? Dans ce cas, voyons comment SIP établit
une connexion avec son fournisseur, par défaut. Le client envoie une
requête sur UDP et le serveur est censé
répondre au couple {adresse, port} de l'en-tête
Via: de cet en-tête. Mais, après le passage
du routeur NAT, cette adresse et son port, mis là par le client
original, ne correspondent plus à rien d'utile. Même si le paquet de
réponse atteint le NAT, il sera typiquement jeté par lui. Même si le
client SIP s'était connecté en utilisant TCP,
les appels qu'il recevra (INVITE) ne seront pas routés sur cette connexion TCP
mais envoyés à l'adresse indiqué ce qui, là encore, ne marchera pas
(sans compter d'autres problèmes comme la fermeture automatique de la
session par le NAT après un délai de garde).
Cela, c'était pour la signalisation, pour le protocole SIP lui-même. Mais un coup de téléphone complet nécessite aussi de faire passer les données, les paquets audio. Ceux-ci voyagent en général via la protocole RTP (RFC 3550, le protocole à utiliser, les ports où envoyer les données, etc, étant indiqués via SDP (RFC 4566) ou bien via une requête SIP spécifique (RFC 3264). Même si la session SIP a été bien établie, ces paquets RTP risquent fort de ne pas arriver, les adresses et les numéros de port qu'indiquent SDP ou SIP n'ayant pas de signification en dehors du réseau local.
Donc, pour résumer cette section 3, SIP a deux problèmes avec le NAT :
- Pour la signalisation (SIP à proprement parler), requêtes entrantes et sortantes (pours des raisons différentes),
- Et pour les données (en général SDP + RTP).
Soyons maintenant positifs et voyons les solutions (section 4). Pour la signalisation, la section 4.1 expose les méthodes possibles :
- Pour les requêtes sortantes, la réponse symétrique, où la réponse est envoyée au port d'origine (comme le font d'autres protocoles UDP comme le DNS), port ouvert sur le NAT par l'envoi de la requête. Cette méthode est décrite dans le RFC 3581.
- Pour les requêtes entrantes (RFC 5626), le fournisseur SIP doit garder trace du port utilisé et s'en servir pour acheminer les appels entrants.
Pour le transport des données, la section 4.2 cite :
- Le RTP symétrique (RFC 4961) qui permet d'ouvrir un trou dans le NAT depuis l'extérieur, avant de demander au pair d'y envoyer le trafic.
- RTCP (section 6 du RFC 3550) et le RFC 3605 pour indiquer le port à utiliser.
- Et surtout la solution totale, la combinaison de STUN (RFC 5389) et TURN (RFC 5766), orchestrés par ICE (RFC 8445). STUN permet de découvrir l'adresse IP publique qui va être utilisée pour les communications externes, TURN va relayer le trafic pour les cas où le routeur NAT est particulièrement désagréable et empêche STUN de fonctionner (TURN est très coûteux en ressources puisque chaque paquet de données doit être ainsi relayé, mais il marche dans tous les cas), et ICE a pour rôle d'essayer successivement et intelligement plusieurs méthodes de traversée de NAT (STUN, TURN et d'autres) pour choisir la plus adaptée.
La section 5 illustre ensuite ces méthodes par divers exemples. En
voici un très simple, pour la signalisation, où le client, 192.168.1.2
est derrière un NAT (qui réécrit son adresse en
172.16.3.4) et s'enregistre auprès d'un
fournisseur SIP, Example.com. La requête est :
REGISTER sip:example.com SIP/2.0
Via: SIP/2.0/UDP 192.168.1.2;rport;branch=z9hG4bKnashds7
Max-Forwards: 70
From: Bob <sip:bob@example.com>;tag=7F94778B653B
To: Bob <sip:bob@example.com>
Call-ID: 16CB75F21C70
CSeq: 1 REGISTER
Supported: path, outbound
Contact: <sip:bob@192.168.1.2 >;reg-id=1
;+sip.instance="<urn:uuid:00000000-0000-1000-8000-AABBCCDDEEFF>"
Content-Length: 0
Le client SIP a utilisé le paramètre rport (RFC 3581) dans l'en-tête Via: pour indiquer que le serveur doit répondre au port d'où
vient la requête (et que le routeur NAT a ouvert). La réponse est :
SIP/2.0 200 OK
Via: SIP/2.0/UDP 192.168.1.2;rport=8050;branch=z9hG4bKnashds7;
received=172.16.3.4
From: Bob <sip:bob@example.com>;tag=7F94778B653B
To: Bob <sip:bob@example.com>;tag=6AF99445E44A
Call-ID: 16CB75F21C70
CSeq: 1 REGISTER
Supported: path, outbound
Require: outbound
Contact: <sip:bob@192.168.1.2 >;reg-id=1;expires=3600
;+sip.instance="<urn:uuid:00000000-0000-1000-8000-AABBCCDDEEFF>"
Content-Length: 0
et le paramètre received du champ
Via: indique l'adresse IP source qu'avait vue le
serveur. (Une autre solution aurait été d'utiliser TCP.) Les amateurs
de scénarios plus complexes seront comblés, avec le reste de la
longue section 5.
À noter qu'un argument souvent présenté en faveur de Skype, par rapport à SIP, est son meilleur comportement en présence de NAT hostiles (parfois très hostiles, par exemple ne laissant passer que HTTP). Il est amusant de noter que deux des auteurs du RFC travaillent chez Skype. Mais, surtout, si les clients SIP ont souvent moins de succès que Skype lors de la traversée de routeurs très fermés, c'est pour trois raisons :
- Tous les logiciels SIP ne mettent pas encore en œuvre l'intégralité des recommandations résumées dans ce RFC 6314. La qualité des clients et serveurs SIP existants est très variable.
- Skype utilise également des méthodes non-standard (par exemple il peut tunneler la voix sur HTTP, bricolage très contestable mais qui est parfois la seule voie restée ouverte),
- Et Skype utilise également des méthodes de parasite, comme d'enrôler comme relais des machines qui n'ont rien demandé ce qui, à juste titre, suscite des protestations.
L'article seul
RFC 6319: Issues Associated with Designating Additional Private IPv4 Address Space
Date de publication du RFC : Juillet 2011
Auteur(s) du RFC : M. Azinger (Frontier Communications), L. Vegoda (ICANN)
Pour information
Première rédaction de cet article le 20 juillet 2011
Il y a bien longtemps que la pénurie d'adresses IPv4 est une réalité. Longtemps avant leur épuisement complet, ces adresses étaient très difficiles à obtenir, nécessitant un long processus bureaucratique (et le remplissage de nombreux documents), ou tout simplement l'abonnement à une offre qualifiée de « professionnelle » ou « gold » dont le seul intérêt était d'avoir quelques adresses de plus. Résultat, beaucoup d'organisations ont choisi des adresses IP privées et des systèmes de relais ou de traduction d'adresses pour se connecter à l'Internet. Si l'organisation ne grossit pas par la suite, tout va bien. Mais si elle devient plus importante et dépasse la taille permise par les plages d'adresses privées existantes, que se passe-t-il ?
La section 3 du RFC détaille les mécanismes utilisés pour se connecter à l'Internet malgré l'absence d'adresses IP publiques. La principale est sans doute le NAT (RFC 2993 et RFC 3022). Le NAT a de multiples inconvénients, notamment pour les applications pair-à-pair, même si certaines techniques (comme ICE, RFC 8445) permettent de contourner partiellement le problème.
On peut emboîter plusieurs niveaux de NAT, mettant par exemple un traducteur dans la maison ou le bureau et un autre sur le réseau du FAI (on nomme souvent ce double-NAT NAT444). Si le FAI contrôle le CPE et donc les adresses IP qu'il alloue (cas de la Freebox par défaut, par exemple), cela peut marcher. C'est bien plus délicat si le CPE alloue les adresses qu'il veut car, alors, rien ne garantit qu'elles ne seront pas en conflit avec celles utilisées dans le réseau interne du FAI. Bref, le NAT444 ajoute de la complexité et des problèmes. Enfin, toute traduction d'adresses effectuée hors du réseau local de l'abonné soulève les problèmes liés au partage d'adresses que le RFC 6269 documente.
Le plus large bloc privé est le 10.0.0.0/8
(cf. RFC 1918). Il a parfois été suggéré
d'allouer de nouveaux blocs pour agrandir l'espace privé mais ce
projet a très peu de chances de se matérialiser désormais, vu l'épuisement des adresses
IPv4. Ce bloc 10.0.0.0/8 comprend
16 777 216 adresses IP. Qui peut en consommer autant ? Comme le résume
la section 2 de notre RFC, les gros opérateurs, par exemple un
câblo-opérateur national (comme
Comcast, non cité mais qui est effectivement
dans ce cas), un opérateur de téléphonie mobile
3G, un gros fournisseur
VPN, l'intranet d'une
grosse entreprise, peuvent tous se trouver à l'étroit dans ce /8.
Quelles sont les possibilités une fois les adresses du RFC 1918 épuisées ? La section 4 les passe en revue. La première (section 4.1) est évidemment de passer enfin à IPv6, ce qui aurait dû être fait depuis longtemps. Le RFC note à juste titre que déployer IPv6 sur un réseau dont la taille est telle qu'il arrive à épuiser un /8 entier n'est pas une opération triviale. Elle va prendre du temps et c'est pour cela que ces opérateurs auraient dû commencer il y a des années. Si cela n'a pas été fait, l'opérateur peut se trouver dans le cas où les adresses du RFC 1918 sont épuisées et où il n'a matériellement pas le temps de déployer IPv6.
Notons que les adresses IPv6 utilisées ne sont pas forcément globales, on peut aussi déployer IPv6 avec des ULA (RFC 4193). Toutefois, celles-ci ne sont que pseudo-uniques donc, dans des cas comme celui du fournisseur de VPN, le risque de collision existe.
Bon, et pour les administrateurs réseaux qui, en 2011, n'ont toujours pas déployé IPv6, quelles solutions ? La section 4.2 liste les solutions purement v4. Obtenir de nouvelles adresses était la solution classique. Mais ajourd'hui, où les RIR qui ont encore des adresses IPv4 les épuisent vite et passent à la politique d'allocation finale, cela ne parait pas très réaliste.
La seconde solution est d'acquérir des adresses IP d'autres organisations, comme l'avait fait Microsoft dans une opération fameuse. Cette opération peut désormais être légale vis-à-vis des RIR comme le montre l'étude comparée de leurs politiques de transfert. Les possibilités pratiques d'un tel transfert sont très incertaines. Y aura-t-il assez d'adresses sur ce « marché » ? Et à quel coût ? Personne ne le sait trop. Mais le RFC est pessimiste : on ne trouvera probablement pas de larges blocs d'adresses continus ainsi, il est plus probable qu'il n'y aura qu'une poussière de /24 et /23. (Le RFC discute aussi la possibilité de locations de tels blocs, encore pire car sans garantie sur ce qui arrivera au terme de la location.)
Il y a bien sûr une autre possibilité. Après tout, qui a dit qu'il fallait être honnête et respecter les règles de vie en société ? Comme le montre l'exemple d'innombrables hommes d'affaires, on réussit bien mieux en violant ces règles et en écrasant les autres. La section 4.2.2 du RFC est donc consacrée à la solution libérale : prendre ce qui vous intéresse sans se poser de questions, ici, utiliser des adresses IP non encore allouées, ou bien allouées à quelqu'un mais pas annoncées dans la table de routage mondiale. L'article de Duane Wessels montre bien que l'espace non alloué est déjà utilisé. C'est évidemment très mal de faire cela : les rares blocs non encore alloués vont l'être bientôt (et cela fera une collision avec ceux du voleur, avec des conséquences imprévisibles), et ceux qui ne sont pas annoncés dans la table de routage publique le seront peut-être demain. Même si ce n'est pas le cas, la collision est toujours possible (cela dépend de la façon dont est configuré le réseau qui utilisait ces adresses mais, par exemple, les adresses internes fuient souvent, par exemple dans les en-têtes de courrier). La section 2.3 du RFC 3879 discute plus en détail ce problème. Il y a aussi bien sûr des risques juridiques à jouer avec les adresses des autres. Cela peut expliquer pourquoi les voleurs d'adresses préfèrent utiliser des préfixes alloués à des opérateurs peu dangereux juridiquement, par exemple en Afrique.
Quelle solution pourrait-on développer ? La section 5 examine
plusieurs possibilités : la première est d'agrandir le RFC 1918 en y ajoutant des préfixes actuellement marqués comme
publics. Cela réduirait encore plus le stock d'adresses IPv4
disponibles. Plusieurs propositions avaient été faites de réserver,
par exemple un /8 supplémentaire. Par exemple, le réseau
1.0.0.0/8 était tentant car son utilisation
publique soulevait des problèmes. Comme
indiqué plus haut, il est clair
que cela se fait déjà, de manière officieuse. Aucune de ces
propositions n'a été adoptée officiellement et leurs
chances semblent désormais nulles. (Voir la discussion
à NANOG.)
Il y a en effet pas mal de systèmes qui traitent les adresses du RFC 1918 de manière spéciale, et où ces adresses sont codées en dur. Il y a peu de chances de pouvoir mettre à jour tous ces systèmes. Déjà, dé-bogoniser les plages allouées est très difficile.
Dernière possibilité, réaffecter une plage réservée,
240.0.0.0/4, qui avait été mise de côté pour des
usages futurs qui ne se sont jamais concrétisés. Le problème est que
beaucoup de systèmes déployés traitent de manière spécifique ces
adresses et qu'il y a peu de chance de pouvoir les changer tous. En
pratique, elles seront donc largement inutilisables. Par exemple, sur Linux :
% sudo ifconfig eth1 240.0.0.1/24 SIOCSIFADDR: Invalid argument
(Mais ça marche sur FreeBSD et NetBSD). L'Internet-Draft draft-fuller-240space documente ce problème pour quelques systèmes.)
Bref, même si le RFC ne le rappelle pas, il n'y a pas vraiment d'autre solution que de migrer vers IPv6.
L'article seul
RFC 6336: IANA Registry for Interactive Connectivity Establishment (ICE) Options
Date de publication du RFC : Juillet 2011
Auteur(s) du RFC : M. Westerlund (Ericsson), C. Perkins (University of Glasgow)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF mmusic
Première rédaction de cet article le 20 juillet 2011
Le protocole de traversée des NAT, ICE (normalisé dans le RFC 5245), offre la possibilité d'ajouter des options, identifiées par un nom (section 14 du RFC 5245). Mais aucun registre n'existait pour stocker les noms de ces options et éviter des collisions. C'est désormais fait.
Il n'y a pas encore une seule option utilisée par les mises en œuvre d'ICE. Mais une est en cours de développement et cela a motivé la création de ce registre. Donc, une option a un nom, composé d'une série de caractères alphanumériques (on peut aussi utiliser le + et le /). Ce nom est enregistré en suivant la règle « spécification (écrite et publique) obligatoire » de la section 4.1 du RFC 5226, et en indiquant diverses métadonnées comme les coordonnées de la personne ou de l'organisme qui enregistre.
Et c'est tout, le registre (actuellement vide) se trouve en https://www.iana.org/assignments/ice-options/ice-options.xml.
L'article seul
RFC 6304: AS112 Nameserver Operations
Date de publication du RFC : Juillet 2011
Auteur(s) du RFC : J. Abley (ICANN), W. Maton (NRC-CNRC)
Pour information
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 14 juillet 2011
Le système AS112, autrefois décrit dans ce RFC, est à la fois un utile composant du DNS, améliorant les performances et reduisant la charge du réseau, un banc d'essai pour des nouvelles techniques comme l'anycast, et une expérimentation sociale, celle d'un service 100 % acentré. Il est désormais documenté dans le RFC 7534.
Comme beaucoup de bonnes choses sur l'Internet, la documentation arrive comme les carabiniers, longtemps après. Car l'AS112 tourne depuis des années. Pour comprendre son rôle, il faut d'abord se pencher sur le problème à résoudre.
Un certain nombre de sites connectés à
l'Internet utilisent des adresses IP privées, tirées du RFC 1918. Bien des logiciels, lorsqu'ils voient
passer un nouveau client, font une résolution
DNS pour obtenir le nom du client en fonction
de son adresse IP (résolution dite PTR). C'est
par exemple le cas du serveur de courrier
Postfix, chez qui ce comportement n'est pas
débrayable. Lorsque l'adresse IP est privée, il ne sert à rien de
poser la question au DNS public. Par définition, celui-ci ne peut pas
savoir que MaPetiteEntreprise utilise
192.168.1.0/24 et a attribué
192.168.1.33 à
posteclientX.mapetiteentreprise.com. La bonne
pratique est donc que l'administrateur réseaux
d'un site qui utilise ces adresses privées doit configurer des
serveurs DNS pour répondre aux requêtes PTR (cf. RFC 6303). Pour voir cela, on peut utiliser l'option -x de dig, qui permet de faire
automatiquement une résolution d'adresse en nom. Le domaine
in-addr.arpa (RFC 5855) accueille la forme inversée des
adresses (192.168.1.33 devient
33.1.168.192.in-addr.arpa). Testons ici une adresse publique :
% dig -x 192.134.4.20 ... ;; ANSWER SECTION: 20.4.134.192.in-addr.arpa. 172800 IN PTR rigolo.nic.fr.
Mais beaucoup d'administrateurs réseaux sont négligents, surchargés
de travail, incompétents ou les trois à la fois. Ils ne configurent
pas ces serveurs DNS et, résultat, la requête PTR sort de leur réseau
et va taper sur les serveurs DNS de la racine puis à ceux de in-addr.arpa. (Une bonne partie du trafic semble ainsi venir des réseaux 3G, où le smartphone ne reçoit qu'une adresse privée et où le résolveur DNS qui lui est indiqué ne connait pas les zones correspondantes.) Ceux-ci ont normalement
autre chose à faire que de répondre à des requêtes qui sont, dès le
départ, des erreurs. Ils délèguent donc à l'AS112, un ensemble de
serveurs de noms qui est chargé de répondre « ce nom n'existe pas » à
toutes ces requêtes parasites. L'AS112 est donc un puits où finissent
les erreurs.
On peut voir la délégation de l'AS112 avec dig :
% dig NS 168.192.in-addr.arpa ; <<>> DiG 9.7.1 <<>> NS 168.192.in-addr.arpa ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 56273 ;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 3 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;168.192.in-addr.arpa. IN NS ;; ANSWER SECTION: 168.192.in-addr.arpa. 300 IN NS blackhole-2.iana.org. 168.192.in-addr.arpa. 300 IN NS blackhole-1.iana.org. ;; ADDITIONAL SECTION: blackhole-1.iana.org. 3500 IN A 192.175.48.6 blackhole-2.iana.org. 3500 IN A 192.175.48.42 ;; Query time: 29 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) ;; WHEN: Wed Jul 6 12:34:19 2011 ;; MSG SIZE rcvd: 141
La délégation va être conservée dans les mémoires caches des
résolveurs DNS et la racine ou in-addr.arpa ne seront donc plus embêtés, après la
première requête.
Mais qui sont ces machines 192.175.48.6 et
192.175.48.42 ? Des très gros serveurs payés par un mécène
et installées à un endroit bien connecté ? Pas du tout. C'est ici que
rentre en jeu l'AS112. Ce dernier est composé d'un réseau informel de
dizaines de machines un peu partout dans le monde et qui annoncent
toutes être 192.175.48.6 et
192.175.48.42. Chacune de ces machines encaisse une partie
de la charge. L'AS112 n'a pas de chef, juste un site Web et, depuis aujourd'hui, un
RFC, ce RFC 6304.
L'AS112 doit son nom au numéro de système autonome qui lui a été attribué. Ses serveurs utilisent l'anycast (RFC 4786) pour distribuer la charge entre eux. Avant Global Anycast, c'était donc le premier projet d'anycast entre serveurs faiblement coordonnés.
Les détails pratiques, maintenant. La liste des zones servies
figure en section 2.1. Elle comprend
10.in-addr.arpa pour le réseau
10.0.0.0/8,
de 16.172.in-addr.arpa à
31.172.in-addr.arpa pour le
172.16.0.0/12, et
168.192.in-addr.arpa pour le
192.168.0.0/16, les préfixes du RFC 1918. Elle inclus aussi
254.169.in-addr.arpa pour le préfixe « local au
lien » du RFC 5735. Pour aider à l'identification du
nœud qui répond, les serveurs de l'AS112 servent également la
zone hostname.as112.net, ici à Paris :
% dig +nsid TXT hostname.as112.net ; <<>> DiG 9.7.3 <<>> +nsid TXT hostname.as112.net ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 1078 ;; flags: qr rd ra; QUERY: 1, ANSWER: 5, AUTHORITY: 2, ADDITIONAL: 3 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;hostname.as112.net. IN TXT ;; ANSWER SECTION: hostname.as112.net. 267 IN TXT "Unicast IP: 193.17.192.194" hostname.as112.net. 267 IN TXT "See http://as112.net/ for more information." hostname.as112.net. 267 IN TXT "See http://noc.hivane.net/cgi-bin/dsc-grapher.pl for local information." hostname.as112.net. 267 IN TXT "Paris, FR" hostname.as112.net. 267 IN TXT "Hivane Networks" ;; AUTHORITY SECTION: hostname.as112.net. 267 IN NS blackhole-2.iana.org. hostname.as112.net. 267 IN NS blackhole-1.iana.org. ;; ADDITIONAL SECTION: blackhole-1.iana.org. 241 IN A 192.175.48.6 blackhole-2.iana.org. 241 IN A 192.175.48.42 ;; Query time: 1 msec ;; SERVER: 217.70.184.225#53(217.70.184.225) ;; WHEN: Wed Jul 6 12:36:14 2011 ;; MSG SIZE rcvd: 348
On note que les préfixes IPv6 n'y figurent
pas. Une des discussions les plus vives sur ce RFC, et qui explique le
temps très long qu'il a mis à sortir, portait sur la délégation de
préfixes d'ip6.arpa à l'AS112. Aucune décision
n'a encore été prise et, pour l'instant, notre RFC 6304
décrit l'état actuel de l'AS112 (on peut avoir une liste à jour sur
le site officiel).
La section 2.2 décrit les serveurs de noms qui reçoivent la
délégation, joliment (mais incorrectement, puisqu'ils répondent)
nommés blackhole-1.iana.org et
blackhole-2.iana.org (en dépit de leurs noms, les
serveurs de l'AS112 ne sont pas gérés par
l'IANA, cf. section 7). Dans le champ
MNAME du SOA de la zone
déléguée, on trouve également prisoner.iana.org
dont la tâche principale est de répondre aux mises à jour dynamiques
(RFC 2136) que certaines machines envoient audit MNAME.
Ce RFC 6304 n'est pas seulement la description d'une
technique mais également un HOWTO sur la
configuration d'un serveur de l'AS112. De tels textes, prévus pour les
administrateurs système, sont rares dans les
RFC. La section 3 décrit ainsi tout
ce que doit savoir le volontaire qui va créer un nouveau
nœud. Il doit connaître BGP (RFC 4271), nécessaire pour
l'anycast (RFC 4786) et la gestion d'un serveur DNS faisant
autorité. Les serveurs de l'AS112 peuvent être situés n'importe où
mais ils sont surtout utiles dans les endroits bien connectés,
notamment les points d'échange. Ils peuvent
être locaux (annonçant les routes avec la communauté
BGP no-export, 0xFFFFFF01,
cf. RFC 1997), ou
globaux (servant le monde entier). Et naturellement, ils doivent se
coordonner (via une liste de diffusion) avec les
autres serveurs de l'AS112.
L'AS112 n'impose pas de système d'exploitation particulier (section 3.3) mais tous les serveurs existants semblent utiliser Unix et tous (c'est difficile à dire, puisque l'AS112 ne contrôle pas tout ce qui se passe sur les serveurs) se servent de BIND. Il est recommandé que la machine AS112 soit dédiée à cette tâche : ces serveurs reçoivent parfois un trafic intense qui pourrait perturber leurs autres activités.
Le serveur signale son existence et sa disponibilité en
BGP. Il faut donc coupler le serveur de noms au
serveur BGP, pour que l'arrêt du serveur DNS entraîne l'arrêt de
l'annonce (le RFC ne fournit pas de script pour cela). Un exemple de
comment cela peut se réaliser sur Linux, avec
les adresses de l'AS112 attachées à une interface dummy, est
(code utilisé sur un serveur anycast réel, quoique
pas de l'AS112) :
# Load the variables (the machine is a RedHat)
. /etc/sysconfig/network-scripts/ifcfg-eth0
# Test if the name server actually works. Do not use ps: the server
may be there but unresponsive
TMP=(`dig +short +time=1 +tries=1 @${IPADDR} SOA example.`)
MASTER=${TMP[0]:=somethingwaswrong}
# Normal reply or not?
if test ${MASTER} != "nsmaster.nic.example."
then
# Disable the interface: Quagga will stop announcing the route
ifdown dummy0
# Raise an alarm, send SMS, etc
fi
Le serveur BGP annonce le préfixe
192.175.48.0/24 qui couvre les adresses de tous
les serveurs et l'origine est évidemment 112.
Les exemples du RFC supposent que le serveur BGP est
Quagga mais cela peut évidemment marcher avec
d'autres. Dans l'exemple ci-dessous, tiré du RFC (section 3.4), le router
ID est 203.0.113.1 et le serveur BGP a
deux pairs, 192.0.2.1 et
192.0.2.2. Voici un extrait du
bgpd.conf (la version intégrale est dans le
RFC) :
hostname my-router
...
router bgp 112
bgp router-id 203.0.113.1
network 192.175.48.0/24
neighbor 192.0.2.1 remote-as 64496
neighbor 192.0.2.1 next-hop-self
neighbor 192.0.2.2 remote-as 64497
neighbor 192.0.2.2 next-hop-self
En farfouillant sur le site officiel (pas très bien organisé, je trouve), on peut trouver d'autres exemples.
Le serveur AS112 a ensuite besoin d'un serveur DNS faisant autorité
(section 3.5), évidemment compatible avec toutes les règles du DNS
(RFC 1034). Les exemples de configuration du RFC
sont fondés sur BIND. Voici un extrait du
named.conf (la version intégrale est dans le
RFC) :
options {
listen-on {
...
// the following addresses correspond to AS112 addresses, and
// are the same for all AS112 nodes
192.175.48.1; // prisoner.iana.org (anycast)
192.175.48.6; // blackhole-1.iana.org (anycast)
192.175.48.42; // blackhole-2.iana.org (anycast)
};
recursion no; // authoritative-only server
};
// RFC 1918
zone "10.in-addr.arpa" { type master; file "db.empty"; };
...
// RFC 5735
zone "254.169.in-addr.arpa" { type master; file "db.empty"; };
// also answer authoritatively for the HOSTNAME.AS112.NET zone,
// which contains data of operational relevance
zone "hostname.as112.net" {
type master;
file "db.hostname.as112.net";
};
Un exemple équivalent pour NSD (utilisé sur le nœud AS112 de Paris) est disponible en as112-nsd.conf. Pour simplifier son écriture, il a été
produit à partir d'un source en M4, as112-nsd.conf.m4.
Que contiennent les fichiers de zone db.empty
et db.hostname.as112.net ? Conformes à la syntaxe
de la section 5 du RFC 1035, ils sont communs à
BIND et NSD. Le premier, comme son nom l'indique, est un fichier de
zone vide, puisque le serveur AS112 ne connait évidemment rien : il ne
peut que répondre NXDOMAIN (ce nom n'existe pas)
à toutes les requêtes. Il ne contient donc que les informations
obligatoires à toute zone (SOA, avec une adresse
de contact appropriée) et NS. L'autre zone sert au débogage de l'AS112,
lorsqu'on veut obtenir des informations sur le serveur AS112
courant. Un contenu typique est juste composé d'enregistrements TXT :
TXT "Human AS112 server" "Minas Tirith, Gondor"
TXT "Forbidden to orcs and nazguls."
TXT "See http://www.as112.net/ for more information."
et parfois d'une localisation (cf. RFC 1876). Le résultat sur un site réel étant :
% dig ANY hostname.as112.net. ; <<>> DiG 9.7.3 <<>> ANY hostname.as112.net. ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 41528 ;; flags: qr rd ra; QUERY: 1, ANSWER: 7, AUTHORITY: 2, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;hostname.as112.net. IN ANY ;; ANSWER SECTION: hostname.as112.net. 604796 IN LOC 37 58 22.590 N 23 44 43.890 E 100.00m 100m 10m 10m hostname.as112.net. 604796 IN TXT "See http://as112.net/ for more information." hostname.as112.net. 604796 IN TXT "Unicast IP: as112.grnet.gr" hostname.as112.net. 604796 IN TXT "Greek Research & Technology Network" "Athens, Greece" hostname.as112.net. 604796 IN SOA flo.gigafed.net. dns.ryouko.imsb.nrc.ca. 1 604800 60 604800 604800 hostname.as112.net. 604796 IN NS blackhole-2.iana.org. hostname.as112.net. 604796 IN NS blackhole-1.iana.org. ;; AUTHORITY SECTION: hostname.as112.net. 604796 IN NS blackhole-1.iana.org. hostname.as112.net. 604796 IN NS blackhole-2.iana.org. ;; Query time: 0 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) ;; WHEN: Wed Jul 6 12:51:53 2011 ;; MSG SIZE rcvd: 391
(La version intégrale des deux fichiers de zone figure dans le RFC.)
Une fois le nœud installé, il faut évidemment le tester (avec
dig, par exemple). Si les réponses aux requêtes
PTR sont correctes, mais pas celles aux requêtes pour le nom
hostname.as112.net, c'est sans doute un problème
de routage (on est envoyés sur un autre nœud de l'AS112) et il
faut alors sortir traceroute et les
looking glasses (section 3.6). Des
tests dignes de ce nom doivent être faits depuis plusieurs
FAI, et doivent tester les trois adresses IP de
l'AS112.
Le bon fonctionnement de l'AS112 ne dépend pas uniquement de sa configuration initiale mais aussi de sa gestion et surveillance quotidiennes. La section 4 est consacrée aux questions opérationnelles. Le nœud doit être surveillé automatiquement, pour s'assurer qu'il répond toujours. S'il doit être arrêté (par exemple pour une maintenance prévue), il faut s'assurer que l'annonce BGP stoppe (autrement, BGP annonce un trou noir, d'où aucune réponse ne reviendra). Autre point important de la gestion opérationnelle d'un serveur de l'AS112, des statistiques, obtenues à partir d'outils comme DSC ou dnstop. Quelle est l'utilisation réelle de l'AS112 ? Ces statistiques n'étant pas consolidées globalement, c'est difficile à dire. Certains opérateurs publient leurs chiffres mais pas tous. Par exemple, le serveur d'Ottawa voit mille requêtes par seconde (cf. « AS112 Intro » par l'un des auteurs du RFC), celui géré par le RIPE-NCC dans les mille cinq cents, et celui à Paris deux fois plus (voir les graphiques), ce qui fait quand même quelques mégabits par seconde. La majorité des types demandés est évidemment du PTR mais il y a aussi un flux important de TXT, apparemment dus à la technologie SD (Service Discovery) d'Apple (voir des statistiques plus détaillées à la fin).
Le nouveau serveur peut alors être annoncé sur les listes appropriées (par exemple, chaque point d'échange a en général la sienne). Enfin, bien que chaque serveur de l'AS112 puisse fonctionner indépendemment des autres, il est évidemment préférable de se coordonner avec les petits camarades (section 5) en écrivant à la liste officielle.
Et dans le futur ? La section 6 explore l'avenir possible de l'AS112. Idéalement, il devrait disparaître petit à petit au fur et à mesure que les administrateurs réseaux prennent soin de ne pas laisser fuir les requêtes PTR pour les réseaux privés, comme recommandé dans le RFC 6303. Le déploiement de logiciels respectant ce principe dès le début pourrait aider. Toutefois, aujourd'hui, les opérateurs de l'AS112 n'observent pas de tendance à la baisse du trafic. Même des années après le déploiement de serveurs mettant en œuvre le RFC 6303, il est probable que le trafic de l'AS112 ne tombera pas à zéro et que ce service restera donc nécessaire.
Il pourrait même s'étendre à IPv6 (cela a
été fait début 2015) : les
serveurs pourraient répondre en IPv6 (et pas seulement en IPv4 comme
aujourd'hui). Un préfixe a déjà été alloué pour cela, 2620:4f:8000::0/48 mais il n'est pas encore publié. Et les serveurs pourraient servir des données de
ip6.arpa. Rien n'est encore décidé, gardez un
œil sur http://www.as112.net/ si vous voulez être
au courant. Un bon exposé du problème est « AS112-bis. » et un plan
de déploiement IPv6 est en http://public.as112.net/node/26. Quant aux nouveaux domaines
délégués, la solution finalement adoptée a été décrite dans le RFC 7535.
Enfin, qu'en est-il de la sécurité ? Comme le rappelle la section 8, les requêtes DNS auxquelles répond l'AS112 ne devraient jamais y arriver, normalement. Elles auraient dû rester sur le réseau local. En sortant, elles exposent de l'information interne, qui était peut-être privée (qu'il y ait un serveur qui y réponde ou pas ne change guère ce risque).
Plus rigolo, comme ces requêtes sont en général involontaires (comme indiqué, elles auraient dû rester privées), les réponses sont inattendues. Plus d'un IDS a donc crié que l'AS112 essayait d'attaquer le réseau. Le RFC 6305 a été écrit pour fournir une réponse toute faite aux administrateurs incompétents qui accusaient l'IANA ou l'AS112.
Comme l'AS112 n'a pas de chef et que l'anycast ne permet pas de limiter le nombre de participants, il est tout à fait possible de fantasmer sur l'hypothèse d'un nœud AS112 voyou, qui donnerait exprès de mauvaise réponses. Ce problème (purement théorique) n'a pas vraiment de solution. Signer les zones avec DNSSEC semble franchement excessif.
L'annexe A du RFC expose la longue histoire de l'AS112, de ses
débuts en 2002 (les adresses IP
privées datent de 1996) à son état actuel,
après la redélégation en 2011 de
in-addr.arpa, autrefois sur les serveurs de la
racine (RFC 5855). L'AS112 a été le premier
déploiement massif de l'anycast et a donc joué un
rôle primordial dans l'évaluation de cette technologie.
On voit que neuf ans ont donc été nécessaires pour documenter ce projet. Une des raisons du retard était la longue discussion pour savoir si le RFC devait documenter l'état actuel de l'AS112 (ce qui a finalement été fait) ou son état souhaité (avec, par exemple, les nouvelles zones IPv6).
À noter que, d'après la liste officielle des sites, il existe au moins un serveur AS112 en France, chez Hivane, désormais (novembre 2011) connecté au France-IX. Malgré cela, les requêtes françaises pour les serveurs de l'AS112 voyagent souvent loin. C'est un problème banal comme le montrait l'excellente présentation « Investigating AS112 Routing and New Server Discovery ».
Voici quelques analyses sur le trafic de ce serveur français, faites avec DNSmezzo. Le fichier pcap fait 6,8 Go. Il y a 43 701 087 paquets DNS dont 21 858 845 sont des requêtes. Les données ont été prises un vendredi, de 13h40 à 15h30 (heure locale). Regardons d'abord les types de données demandés :
dnsmezzo=> SELECT (CASE WHEN type IS NULL THEN qtype::TEXT ELSE type END),
meaning,
count(results.id)*100/(SELECT count(id) FROM DNS_packets WHERE query) AS requests_percent FROM
(SELECT id, qtype FROM dns_packets
WHERE query) AS Results
LEFT OUTER JOIN DNS_types ON qtype = value
GROUP BY qtype, type, meaning ORDER BY requests_percent desc;
type | meaning | requests_percent
-------+----------------------------------------+------------------
PTR | a domain name pointer | 57
TXT | text strings | 35
SOA | marks the start of a zone of authority | 6
CNAME | the canonical name for an alias | 0
MX | mail exchange | 0
AAAA | IP6 Address | 0
40 | | 0
DS | Delegation Signer | 0
...
La première place des PTR est normale. Celle des
TXT est plus surprenante. En regardant les noms
utilisés
(cf._dns-sd._udp.Y.X.243.10.in-addr.arpa...), on
voit qu'ils sont dus à la technique Service
Discovery d'Apple, un système normalement confiné au réseau
local mais qui bave beaucoup à l'extérieur.
Et quels sont les domaines les plus populaires ?
dnsmezzo=> SELECT substr(registered_domain,1,46) AS domain,
count(id)*100/(SELECT count(id) FROM DNS_packets WHERE query) AS requests_percent
FROM dns_packets WHERE query GROUP BY registered_domain ORDER BY requests_percent DESC LIMIT 30;
domain | requests_percent
------------------+------------------
10.in-addr.arpa | 78
192.in-addr.arpa | 12
172.in-addr.arpa | 7
169.in-addr.arpa | 1
151.in-addr.arpa | 0
i~-addr.arpa | 0
83.in-addr.arpa | 0
| 0
gfi.private | 0
local.de | 0
grupofdez.com | 0
....
On voit que le réseau 10.0.0.0/8 est nettement le
plus populaire. On notera les trois derniers, sans doute des erreurs
de configuration.
Et quels sont les résolveurs les plus actifs ? En agrégeant les préfixes IPv4 en /28 :
dnsmezzo=> SELECT set_masklen(src_address::cidr, 28) AS client, count(id)*100/(SELECT count(id) FROM DNS_packets WHERE query) AS requests_percent
FROM dns_packets WHERE query GROUP BY set_masklen(src_address::cidr, 28)
ORDER by requests_percent DESC LIMIT 30;
client | requests_percent
--------------------+------------------
CENSURE.160/28 | 29
CENSURE.0/28 | 10
CENSURE.16/28 | 8
CENSURE.96/28 | 6
...
Oui, j'ai préféré ne pas donner les adresses. Je dirai simplement que ces quatre plus gros sont des opérateurs de téléphonie mobile, deux français et deux extrême-orientaux (les mystères du routage...).
Merci à Clément Cavadore pour les données et pour sa relecture.
L'article seul
RFC 6305: I'm Being Attacked by PRISONER.IANA.ORG!
Date de publication du RFC : Juillet 2011
Auteur(s) du RFC : J. Abley (ICANN), W. Maton (NRC-CNRC)
Pour information
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 14 juillet 2011
Un RFC très inhabituel, non seulement par
son titre amusant mais aussi parce que le public visé n'est pas le
programmeur qui va mettre en œuvre des normes, ni même
l'administrateur réseaux qui s'occupe de grands réseaux complexes,
mais un public bien plus large, celui des gens qui gèrent un petit
réseau, ont installé comme pare-feu ou
IDS une boîte noire à laquelle ils ne
comprennent rien, et qui voient arriver des messages d'alerte comme
quoi leur petit réseau serait attaqué par un mystérieux
prisoner.iana.org. Ce RFC a été écrit pour
fournir à l'IANA et aux opérateurs de serveurs
de l'AS112 (décrit dans le RFC 7534) une réponse toute faite à envoyer à ces angoissés.
En effet, l'« attaque » en question n'est pas une attaque et ne
vient pas de l'IANA ou de
l'AS112. Elle est entièrement de la faute des
administrateurs de ces réseaux soi-disant attaqués. Un certain nombre
de petits réseaux utilisent, soit parce qu'il n'y a plus d'adresses IPv4 disponibles, soit parce qu'ils
croient à tort que cela leur apporte une certaine sécurité, des
adresses IP privées, tirées
du RFC 1918. Ces adresses étant spécifiques à un
certain réseau, n'ayant pas de signification globale, les requêtes
DNS demandant les noms associés à ces adresses
ne devraient jamais sortir du réseau local (section 2 du RFC) et être toujours traitées
par un serveur DNS interne. Mais, en pratique, c'est loin d'être le
cas, et les serveurs de in-addr.arpa, le domaine
utilisé pour la résolution d'adresses IP en noms (section 3), reçoivent un trafic
important et inutile. Pour le traiter sans charger ces serveurs, les
domaines servant aux plages d'adresses du RFC 1918 sont déléguées à l'AS112 (RFC 7534) qui est chargé de répondre « ce domaine
n'existe pas » à toutes ces requêtes.
Mais, comme les requêtes de ce type sont des erreurs (rappelez-vous qu'elles n'auraient normalement jamais dû sortir), les réponses qu'envoie l'AS112 sont souvent inattendues pour le réseau local. Et, si le pare-feu ou l'IDS sont bizarrement configurés (ce qui est fréquent sur ces réseaux mal gérés), la réponse DNS à leur question leur apparait comme une tentative d'attaque ! S'ils se plaignent, l'idée est de simplement leur renvoyer ce RFC 6305 à lire.
Ce RFC explique donc en termes simples ce que sont les adresses
privées, ce qu'est la résolution d'adresses en noms, les raisons
pour lesquelles est déployé l'AS112 (section 4 du RFC), et les noms et
adresses des serveurs de l'AS112 (section 5) notamment le
prisoner.iana.org qui donne son titre au
RFC. Pour augmenter les chances que Google
trouve cet article, je cite ici ces informations :
PRISONER.IANA.ORG(192.175.48.1),BLACKHOLE-1.IANA.ORG(192.175.48.6),- Et
BLACKHOLE-2.IANA.ORG(192.175.48.42).
La section 6 explique ensuite le mécanisme par lequel la fausse
alerte est déclenchée : un résolveur DNS du réseau local envoie la
requête, par exemple PTR 1.2.20.172.in-addr.arpa,
elle arrive aux serveurs de l'AS112, qui répondent, mais leurs
réponses sont, pour des raisons diverses, bloquées. Normalement, le
pare-feu ne couine pas pour chaque paquet bloqué mais, ici, les
requêtes étant souvent déclenchées automatiquement par un logiciel,
elles peuvent être nombreuses, provoquant de fréquentes réponses, qui
peuvent ressembler à une attaque. Deux autres phénomènes expliquent
cette perception : si la réponse est bloquée, la machine à l'origine
de la requête va réessayer, souvent très vite. Et si le résolveur DNS
refait ces essais avec
des numéros de port croissant régulièrement,
les réponses ressembleront à un balayage de
ports.
Que devrait donc faire l'administrateur du site au lieu de harceler l'IANA ou les opérateurs de l'AS112 ? La section 7 lui donne quelques pistes, pour résoudre le problème qu'il a causé :
- Convaincre les machines terminales de ne pas chercher à résoudre les adresses en noms. Cela coupe le problème à la source, mais c'est évidemment assez difficile à faire dans un grand réseau, où l'administrateur du pare-feu ne contrôle pas forcément chaque machine. Par exemple, une bonne partie du trafic de l'AS112 provient des réseaux de téléphonie mobile et l'opérateur du pare-feu ne peut évidemment pas intervenir sur chaque téléphone.
- Bloquer sur le pare-feu non pas les réponses de l'AS112 mais les questions envoyées à ce service. Cela résoudrait complètement le problème de l'AS112 mais, sur le site, les résolutions des adresses en noms se bloqueraient, ce qui pourrait avoir des conséquences gênantes.
- Configurer les résolveurs du réseau local pour répondre avec autorité pour les zones correspondant aux adresses privées. C'est sans doute la solution la plus simple et le plus efficace à la fois. Elle est décrite avec plus de détails dans le RFC 6303.
- Plus geek, mettre en place une instance locale de l'AS112 (RFC 7534).
L'article seul
RFC 6303: Locally-served DNS Zones
Date de publication du RFC : Juillet 2011
Auteur(s) du RFC : M. Andrews (ISC)
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 14 juillet 2011
Autrefois, les serveurs DNS récursifs, ceux qui, installés sur un réseau local ou chez un FAI pour ses abonnés, répondent aux requêtes DNS des clients finaux, ne servaient par défaut aucune zone. Tout était demandé aux serveurs DNS faisant autorité, sauf des zones locales configurées à la main. Le problème est que certaines zones privées très répandues étaient oubliées, et que le récurseur allait alors embêter les serveurs faisant autorité avec ces requêtes qui auraient dû rester locales. Ce nouveau RFC demande donc que, par défaut, sans aucune configuration explicite, les récurseurs fassent autorité pour certaines zones locales.
Un exemple typique est celui d'un réseau local numéroté avec les
adresses IP privées du RFC 1918, mettons 172.27.0.0/16. Les machines
dudit réseau reçoivent en DHCP l'adresse d'un
serveur DNS récursif local. Celui-ci, avant la sortie de notre RFC 6303, ne connaissait pas
27.172.in-adr.arpa, le domaine utilisé pour les
résolutions d'adresses IP en noms. Il va donc transmettre ces requêtes
aux serveurs publics, en l'occurrence ceux de l'AS112 (RFC 7534), les
faisant travailler pour rien. La bonne pratique, depuis toujours, est
que l'administrateur système local ajoute la zone
27.172.in-adr.arpa à son récurseur. Mais
incompétence, manque de temps et négligence (quelqu'un d'autre
paie...) se conjuguent pour faire que c'est rarement déployé. L'idée
de notre RFC 6303 est donc de déplacer le travail depuis les
nombreux administrateurs réseaux vers les nettement moins nombreux
auteurs de logiciels serveurs.
La section 3 du RFC décrit le changement chez les
résolveurs. Ceux-ci devront répondre avec autorité
NXDOMAIN (code de réponse 3), indiquant que le
nom demandé n'existe pas. Une façon triviale d'implémenter ce
comportement est de servir des zones vides, plus exactement, ne
contenant que des SOA et des
NS (exactement ce que fait l'AS112, cf. RFC 7534). La valeur recommandée pour le SOA et pour
les NS est le
nom de la zone et, pour l'adresse de contact,
nobody@invalid. Le SOA est nécessaire pour le
cache des réponses négatives (et pour les machines qui tiennent à
tenter des mises à jour dynamiques du DNS, qui ont également besoin
des NS). Sous forme d'un fichier de zone
standard, cela donne (avec un TTL de trois heures) :
@ 10800 IN SOA @ nobody.invalid. 1 3600 1200 604800 10800 @ 10800 IN NS @
Ce comportement doit être débrayable, de préférence zone par zone, pour le cas des sites qui utilisent les adresses privées et ont configuré leurs serveurs DNS pour résoudre ces adresses en noms.
La liste initiale des zones à servir figure en section 4. Elle
sert de point de départ au registre IANA, https://www.iana.org/assignments/locally-served-dns-zones/locally-served-dns-zones.xml,
qui est la source faisant autorité (les auteurs de logiciels devraient
donc le consulter avant des nouvelles publications de leur
logiciel). Le registre est mis à jour
(cf. section 6) par le
processus « IETF review » décrit dans le RFC 5226, avec un appel au conservatisme : une fois
ajoutée au registre, une zone ne pourra jamais être retirée, puisqu'il
faudrait mettre à jour tous les logiciels. Il faut donc réfléchir
longtemps avant d'ajouter une zone.
Aujourd'hui, ce registre inclut notamment
les zones
in-addr.arpa correspondant au RFC 1918 et celles correspondant aux réseaux du registre
documenté dans le RFC 6890 , qui ne sont pas
censés apparaître publiquement (comme les réseaux réservés pour la
documentation). Il y a aussi des zones ip6.arpa
(domaine utilisé pour la résolution d'adresses
IPv6 en noms), comme celles des
ULA du RFC 4193 (premier
RFC à avoir normalisé cette pratique pour les résolveurs DNS, pour le
domaine d.f.ip6.arpa), celles des adresses
locales au lien (RFC 4291, section 2.5.6, un
exemple étant 8.e.f.ip6.arpa), et celle du réseau
réservé pour la documentation (RFC 3849).
En revanche, certaines zones ne sont pas incluses (section 5) comme les anciennes adresses locales au site d'IPv6 (RFC 4291, sections 2.4 et 2.5.7) ou comme des zones plus controversées comme les TLD numériques (pour traiter le cas des logiciels qui feraient des résolutions pour ces adresses, en les prenant pour des noms).
Suivre les recommandations de ce RFC peut-il avoir des effets
négatifs ? La section 2 examine le cas. Comme les serveurs sont
incités à ne servir les zones privées que si elles n'ont pas été
configurées explicitement, les sites qui utilisent le RFC 1918 et ont peuplé les zones en
in-addr.arpa ne devraient pas avoir de
problème. La section 2 conclut que le problème ne
se posera que dans un seul cas, les sites qui utilisent une délégation
(typiquement depuis une racine locale, non connectée à l'Internet), sans que les
résolveurs ne le voient. Ceux-ci devront explicitement reconfigurer
leurs résolveurs pour ne pas servir les zones vides désormais
installées par défaut.
Aujourd'hui, plusieurs récurseurs mettent déjà en œuvre ce RFC. C'est le cas par exemple d'Unbound (testé avec la 1.4.9). Un commentaire dans le fichier de configuration livré avec ce serveur dit :
# defaults are localhost address, reverse for 127.0.0.1 and ::1 # and nxdomain for AS112 zones. If you configure one of these zones # the default content is omitted, or you can omit it with 'nodefault'.
Le commentaire ne semble pas tout à fait correct, Unbound sert aussi
par défaut des zones qui ne sont pas gérées par l'AS112 (comme les
adresses réservées à la documentation).
Voici
sa réponse par défaut, lors d'une tentative de trouver le nom
correspondant à l'adresse IP 172.27.1.1 :
% dig -x 172.27.1.1 ... ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 8856 ;; flags: qr aa rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1 ;; AUTHORITY SECTION: 27.172.in-addr.arpa. 10800 IN SOA localhost. nobody.invalid. 1 3600 1200 604800 10800 ;; Query time: 67 msec ;; SERVER: ::1#53(::1) ;; WHEN: Fri Jul 8 17:47:21 2011 ;; MSG SIZE rcvd: 111
À noter que localhost est mis comme nom de
serveur maître, pas 27.172.in-addr.arpa comme le
demande le RFC (et je n'ai pas trouvé de moyen de le configurer). Pour le cas cité dans la section 2, où on veut interroger les serveurs
faisant normalement autorité, on peut simplement mettre dans la
configuration :
local-zone: "27.172.in-addr.arpa" nodefault
et la zone 27.172.in-addr.arpa ne sera plus
traitée comme spéciale, elle ne suivra plus ce RFC.
BIND (testé en version 9.8.0-P2) reconnait un certain nombre de zones automatiquement remplies et prévient au démarrage :
08-Jul-2011 19:43:59.410 automatic empty zone: 2.0.192.IN-ADDR.ARPA 08-Jul-2011 19:43:59.410 automatic empty zone: 100.51.198.IN-ADDR.ARPA 08-Jul-2011 19:43:59.410 automatic empty zone: 113.0.203.IN-ADDR.ARPA ...
Mais cette liste ne comprend pas encore les zones du RFC 1918. Voici le résultat en interrogeant les zones spéciales pour BIND :
% dig -x 192.0.2.1 ... ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 22522 ;; flags: qr aa rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1 ... ;; AUTHORITY SECTION: 2.0.192.in-addr.arpa. 86400 IN SOA 2.0.192.in-addr.arpa. . 0 28800 7200 604800 86400 ;; Query time: 1 msec ;; SERVER: ::1#53(::1) ;; WHEN: Fri Jul 8 19:45:03 2011 ;; MSG SIZE rcvd: 86
On note que BIND ne respecte pas encore le RFC (l'adresse de contact
n'est pas nobody@invalid) et que sa liste de
zones spéciales n'est pas encore celle du registre IANA. Toutefois,
tout cela est modifiable. Regardez la section « Built-in
Empty Zones » de l'ARM (Administrator Reference
Manual). Par exemple, vous pouvez changer l'adresse de
contact avec empty-contact nobody@invalid dans la
section options. Vous
pouvez désactiver le comportement spécial pour une zone avec
disable-empty-zone 2.0.192.in-addr.arpa dans la
même section (l'équivalent du nodefault d'Unbound). Et
bien d'autres possibilités.
L'article seul
Van Jacobson et le réseau centré sur le contenu
Première rédaction de cet article le 13 juillet 2011
J'ai déjà eu l'occasion de le dire : en matière de recherche sur les réseaux informatiques, j'apprécie les gens qui développent des idées originales, ne se limitent pas à penser dans le cadre existant, et déblaient le terrain pour les développements futurs. L'Internet tel qu'il est aujourd'hui n'est pas éternel, et il faut travailler à son remplaçant. Seulement, parmi les gens qui annoncent être des penseurs radicaux et des réformateurs audacieux, pour un vrai pionnier qui innove, il y a cent powerpointeurs, qui tiennent des grands discours, mais ne font rien de concret, et dont les idées ne dépassent jamais le stade « dos de l'enveloppe ». Le « réseau centré sur le contenu », prôné notamment par Van Jacobson, est de quelle catégorie ?
Pour mes lecteurs qui préfèrent les visions positives, je vais d'abord parler du projet de Van Jacobson et de ses collègues du PARC, le Content-Centric Networking (CCN), car c'est un projet très intéressant. Mais, comme rien n'est parfait en ce bas monde, je mentionnerai aussi d'autres efforts médiatiques qui utilisent ce même slogan de « réseau basé sur le contenu », et qui sont davantage dans la lignée des « raseurs de table » habituels (ceux qui prétendent faire « table rase » de l'Internet existant et repartir de zéro).
L'article fondateur du projet est « Networking Named Content ». Parmi les auteurs, Van Jacobson, légende de l'Internet, inventeur de traceroute, et auteur de pas mal de RFC comme le RFC 1144, sur la technique de compression qui porte son nom. Il est surtout connu pour ses travaux sur le contrôle de congestion (cf. RFC 2001). Mais je vais essayer de ne pas utiliser d'argument d'autorité et de lire son article (après tout, il n'est qu'un des nombreux co-auteurs) objectivement.
Donc, que dit l'article en question ? Il part de l'affirmation
comme quoi les communications sur l'Internet, dominées autrefois par
des interactions entre machines (typiquement,
telnet) le sont aujourd'hui par de l'accès au
contenu (je sais, c'est très Minitel, comme
approche). Il faut donc réorganiser les protocoles Internet autour de
cette idée. Cela change par exemple le système de nommage et d'adressage, où on ne
nomme jamais une machine, mais toujours des données (le
quoi plutôt que le où). La
forme exacte des noms n'est pas complètement définie (c'est un projet
de recherche, rappelez-vous) mais en gros, la machine qui a une copie
de /parc.com/media/art annonce ce préfixe
localement et une machine qui veut
/parc.com/media/art/carla-bruni.mp3 pourra alors
le trouver (imaginez des URL annoncés en BGP...)
Le routage est donc modifié. Au niveau local, CCN fonctionne en
diffusant à la cantonade (« qui a une copie de
carla-bruni.mp3 ? »). Au niveau global, les
protocoles de routage peuvent eux-même être réécrits en terme de CCN
(les routes étant le contenu auquel on cherche à accéder). À noter que
cela ne marche qu'avec les protocoles de routage qui gardent toute
l'information (comme OSPF). Ceux qui condensent
(comme RIP) ne conviennent pas au CCN, où le
même contenu peut se trouver à plusieurs endroits. Les
FAI sont encouragés à déployer des caches
locaux, pour accélérer le processus. Du point de
vue pratique, CCN peut fonctionner directement sur la
couche 2 ou bien sur IP,
pour faciliter la transition.
L'idée de base me semble très contestable. Toutes les utilisations de l'Internet ne rentrent pas dans ce cadre. Même sur le Web, ce modèle de « récupération d'un contenu » ne colle pas du tout à l'utilisation de Facebook, de Twitter ou de Google Maps.
Un problème courant des nouveaux systèmes de nommage est la
sécurité. Aujourd'hui, je fais confiance à http://www.rue89.com/planete89/2011/07/12/baleines-algues-moules-un-ocean-radioactif-au-large-de-fukushima-213849
parce que les protocoles Internet garantissent que ce contenu vient
bien des serveurs de Rue89. Dans un réseau
« orienté contenu », on perd cette garantie. Comment la récupérer ?
C'est l'objet de l'excellent article « Securing
Network Content ». Pour comprendre le problème,
voyons le contenu accessible sur le bon vieil Internet en http://www.bortzmeyer.org/files/exemple-de-contenu.txt. Si on
obtient ce fichier par un autre biais que le Web, par exemple par
courrier, on ne peut pas le valider, on n'a pas de moyen de savoir
qu'il est authentique. Il existe plusieurs solutions à ce problème
dont la plus courante est d'utiliser des noms auto-validants. Par
exemple, si je décide que les identificateurs du contenu sont des
condensats cryptographiques dudit contenu (un
certain nombre de protocoles pair-à-pair comme
Freenet font effectivement cela), le nom
http://www.bortzmeyer.org/files/exemple-de-contenu.txt
devient (en SHA-256),
c4eb57876451fa515f483a4fa1ae7e2845c3cfcede5582f5133fb5e6a4245205. Ce
nom est auto-validant (si je récupère le contenu par un autre biais,
je peux calculer le condensat et vérifier qu'il correspond) mais il a
deux défauts (on ne peut pas avoir tous
les avantages en même temps) : il n'est pas très convivial et
il ne permet pas de résolution facile (étant dans un espace plat, on
est obligé d'utiliser un serveur centralisé, un protocole d'inondation, ou bien une
DHT pour le résoudre). CCN utilise une autre
approche : on signe le lien entre un localisateur (par exemple un URL)
et le contenu.
Prenons un exemple avec une technologie classique,
PGP. Le condensat
cryptographique du fichier cité plus haut a
été calculé avec sha256sum exemple-de-contenu.txt
et le texte du lien a été signé avec gpg --sign --detach
lien-nom-contenu.txt. Vous pouvez donc, lorsque vous avez
le lien (lien-nom-contenu.txt) et sa signature (lien-nom-contenu.txt.sig) vérifier la signature, puis
récupérer le fichier http://www.bortzmeyer.org/files/exemple-de-contenu.txt, calculer son condensat, et vérifier que tout est
normal. Naturellement, dans un vrai CCN, tout
ceci sera fait automatiquement. Mais cet exemple permet de montrer le principe.
Bien sûr, la faiblesse évidente de ce concept de CCN est cette idée de tout centrer sur le contenu : ce modèle convient bien à la récupération de pages Web statiques ou à celle de fichiers (musique, film) en pair-à-pair. Pas étonnant que ce thème ait du succès, puisque ces deux utilisations sont les seules que connaissent les commerciaux, les journalistes et les hommes politiques. Mais l'Internet sert à bien d'autres choses, notamment les usages conversationnels où on ne récupère pas du contenu mais on mène un dialogue. Ces usages sont par exemple la connexion SSH ou bien la messagerie instantanée. Ces conversations rentrent très mal dans un modèle « centré sur le contenu ». Les auteurs en sont conscients. Ils ont même consacré un très bon article, « VoCCN: Voice-over Content-Centric Networks » à cette question. Dans cet article, ils décrivent VoCCN, un mécanisme permettant de faire passer de la voix (un bon exemple des applications conversationnelles) sur CCN. Le principe est de considérer le téléphone de l'appelé comme un contenu « en devenir », donc de lui donner un nom et de récupérer le contenu associé à ce nom. C'est astucieux mais cela me semble peu naturel et cela illustre bien le syndrôme « lorsque le seul outil qu'on a est un marteau, tous les problèmes ressemblent à des clous ». Les auteurs ont décidé arbitrairement que tout était contenu, et la réalité doit se plier à ce modèle.
Le projet du PARC, contrairement à l'écrasante majorité des projets
« table rase », ne produit pas uniquement du PowerPoint. Sur le site Web officiel, on peut trouver
des descriptions
plus détaillées et plus concrètes, du protocole, des
noms
ou de leur représentation en URI de plan
ccnx:. Le code source
mettant en œuvre ces idées est disponible
(attention, c'est très expérimental, réservé aux barbus curieux) : il
se compose d'une bibliothèque de bas niveau en
C et d'une autre en Java
pour les accès « normaux ».
À partir de là, je vais être nettement moins positif. Car un projet ne se limite pas aux articles scientifiques (que personne ne lit), il a aussi une face publique, des articles de vulgarisation, des discours à la télé et, là, les choses se gâtent sérieusement.
Prenons par exemple un article qui se veut scientifique sur la
forme mais qui est bien faible sur le fond, « Towards
a Content-Centric Internet », financé par plusieurs
projets de l'Union européenne. Que trouve-t-on dans
cet article à l'apparence austère mais qui rassemble tous les clichés
des raseurs de table ? Il commence évidemment par l'affirmation comme
quoi la majorité des usages de l'Internet est de la récupération de
contenu (j'ai expliqué pourquoi c'est faux). Contrairement aux
articles des chercheurs du PARC, il se
contredit plusieurs fois, comme lorsqu'il donne comme exemple d'un
utilisateur voulant « récupérer un contenu indépendemment de sa
localisation », l'exemple d'un utilisateur qui veut « lire les
nouvelles sur le site de la BBC ». Il est vrai
que l'article mélange allègrement localisation physique et emplacement
dans le réseau. Comme beaucoup d'articles de raseurs de table, il
peint un portrait erroné de la situation actuelle, par exemple en
confondant nom d'un service et machine physique (lorsque j'écris à
page@gmail.com, gmail.com ne
désigne pas une machine). L'article part ensuite
dans les habituelles promesses creuses qui font bien dans les
colloques (« more efficient use of the available resource »,
« provide a business environment that encourages
investment »). Parfois, le texte touche à la poésie
(« A Content Object is an autonomous, polymorphic/holistic
container »). Les dessins sont du même style (vides de
contenu mais donnant l'impression d'une profonde sagesse, avec leurs
boîtes qui s'interconnectent ; la figure 3 est particulièrement
réussie de ce point de vue).
Comme beaucoup de réformateurs qui veulent changer radicalement l'Internet, ils lui reprochent surtout son côté trop libre. C'est ainsi qu'ils citent six fois le fait que leur approche « centrée sur le contenu » permettra de rendre les DRM plus efficaces (évidemment, si on voit le réseau comme un moyen de distribuer du contenu vers du temps de cerveau disponible, on arrive vite aux DRM).
Mais, au moins, les auteurs de cette vulgaire brochure commerciale ont le sens des réalités. Ils finissent par avouer « It is currently very difficult to imagine what a network architecture that support objects would look like. ». Je ne peux pas dire mieux.
Encore meilleur (ou pire, selon le point de vue), l'article publicitaire qu'avait décroché les tenants du « réseau centré sur le contenu » dans Network World, « 2020 Vision: Why you won't recognize the 'Net in 10 years ». Cet article choisit la voie facile. D'abord, il compare l'Internet actuel (actuel, donc plein de défauts) avec un réseau idéal et très loin dans le futur (alors que, si on veut être honnête, il faut comparer le réseau des raseurs de table à l'Arpanet de Baran et Licklider, celui qui résistait aux attaques nucléaires). Le record étant lorsque Van Jacobson (dans une citation peut-être tronquée) dit qu'il va mettre fin au spam.
Naturellement, il y a zéro cahier des charges, ce qui permet de vagues promesses (« Meilleure sécurité ») sans indiquer ce qu'on abandonnera en échange (la sécurité est toujours un compromis...) Les seules fois où le cahier des charges est explicite, il va du côté sino-saoudo-hadopien : accord préalable avant d'envoyer des données, flicage obligatoire.
L'article de Network World ne fait pas de la publicité que pour CCN mais aussi pour d'autres projets, qui sont montrés comme s'ils allaient dans le même sens alors que les raseurs de table n'ont en commun que leur chasse aux subventions et présentent des projets incompatibles. L'exemple caricatural dans cet article est l'éloge de MPLS dans un article qui mentionne souvent Van Jacobson, inlassable pourfendeur de MPLS.
Et enfin, l'article mélange des techniques qui nécessitent en effet une refonte complète du réseau et de techniques qui pourraient parfaitement être développées sur l'Internet existant (exemple : nouveaux mécanismes d'adressage et de localisation du contenu). Bref, une soupe catastrophique. Incompétence de journaliste, dont les chercheurs du PARC qui travaillent sur le CCN ne devraient pas etre tenus responsables ? Qui sait ? Van Jacobson est souvent cité dans l'article, avec des déclarations sensationnalistes, prétentieuses et inquiétantes comme « The security is so utterly broken that it's time to wake up now and do it a better way. The model we're using today is just wrong. It can't be made to work. We need a much more information-oriented view of security, where the context of information and the trust of information have to be much more central. »
L'article seul
RFC 6301: A Survey of Mobility Support In the Internet
Date de publication du RFC : Juillet 2011
Auteur(s) du RFC : Z. Zhu (UCLA), R. Wakikawa (TOYOTA ITC), L. Zhang (UCLA)
Pour information
Première rédaction de cet article le 10 juillet 2011
Dernière mise à jour le 12 juillet 2011
Dans le monde des réseaux informatiques, on distingue en général le nomadisme (pouvoir changer d'endroit et avoir à peu près les mêmes services) et la mobilité (pouvoir changer d'endroit en maintenant les sessions existantes, comme si on n'avait pas bougé). Aujourd'hui, où beaucoup d'équipements sont mobiles (smartphone, tablette, ...), la mobilité suscite beaucoup d'intérêt. D'où ce RFC qui évalue l'état actuel du déploiement des techniques de mobilité sur l'Internet. (Disons-le tout de suite, il est très faible.)
Je vais me permettre de commencer par une polémique et des opinions personnelles : dans la famille de protocoles TCP/IP, la mobilité, c'est comme le multicast. Beaucoup de RFC, très peu de paquets. Le sujet passionne les experts, pose plein de problèmes techniques amusants, permet d'écrire des algorithmes rigolos... mais touche très peu les utilisateurs. Comment cela, les utilisateurs ne veulent pas se connecter à l'Internet depuis leur maison, puis continuer au bureau ? Si, ils le veulent, mais il n'est pas du tout évident que la mobilité au niveau IP soit nécessaire pour cela. Aujourd'hui, la technique de mobilité la plus courante est DHCP... La machine reçoit une nouvelle adresse IP et ce sont les applications qui gèrent les déconnexions/reconnexions. Prenons l'exemple du client de messagerie instantanée Pidgin et supposons que je me promène avec mon ordinateur portable, connecté via clé USB 3G dans le train, via le Wifi au Starbucks, puis via un câble Ethernet au bureau. J'aurai une adresse IP différente à chaque fois et les sessions IRC ou XMPP seront donc coupées lors des changements. Est-ce grave ? Pas tellement. Pidgin se reconnectera automatiquement à chaque fois et la seule conséquence pratique sera les messages de déconnexion et de reconnexion que verront les abonnés de chaque canal IRC / pièce XMPP. On a là un bon exemple du fait qu'une gestion de la mobilité par l'application cliente (section 5.5 de notre RFC) est suffisante et qu'il n'y a pas besoin d'un service réseau (compliqué et amenant des problèmes de sécurité) pour cela. Même chose avec une application Web : chaque requête HTTP peut utiliser une adresse source différente, l'utilisateur ne s'en rendra pas compte (à part éventuellement une obligation de se réauthentifier si le cookie est lié à l'adresse IP, ce qui se fait parfois pour limiter la réutilisation d'un cookie volé). Les applications qui reposent sur HTTP (les clients Twitter, par exemple) arrivent également à maintenir une « session » lors de changements d'adresse IP.
Bien sûr, une telle gestion par l'application ne couvre pas tous les cas. Un gros transfert de fichiers avec curl ou wget ne peut pas fonctionner ainsi, puisque ce transfert utilise une seule connexion TCP, donc dépend de l'adresse IP source utilisée au départ (cf. section 6.2). (Avec rsync, et un script qui le relance jusqu'à completion, ça marcherait.) Et, évidemment, les sessions SSH ne peuvent pas être maintenues lorsqu'on change d'adresse. Mais il reste quand même énormément de cas où il n'y a pas de vrai problème lié à la mobilité et cela explique largement, à mon avis, pourquoi les techniques de mobilité IP sont si peu déployées. J'arrête là les opinions personnelles et je reviens au RFC.
La section 1 explique que ce RFC est motivé par le fait que la mobilité est depuis longtemps un sujet de recherche actif à l'IETF et que, depuis quelques années, le déploiement des engins mobiles a explosé (smartphones, tablettes, etc). Le besoin est donc nettement plus marqué maintenant que dix ans auparavant, lorsqu'un ordinateur portable était un machin encombrant et lent. Pourtant, les solutions normalisées par l'IETF ont été peu déployées.
Ces solutions utilisent un vocabulaire rappelé en section 2 et dans le RFC 3753. Notons notamment les termes d'identificateur (identifier) qui indique une valeur qui ne change pas lors des déplacements, de localisateur (locator), qui, lui, change lorsqu'on se déplace (en IP classique, c'est le cas de l'adresse IP), de correspondance (mapping), la fonction qui permet de trouver un localisateur en connaissant l'identificateur, de correspondant (CN pour Correspondent Node, la machine avec laquelle l'engin mobile communique), etc.
La section 3 expose les principes de base de la gestion de la mobilité. Le CN doit pouvoir, dans l'Internet actuel :
- trouver l'adresse IP actuelle du mobile (solutions dites de type 1),
- ou bien connaître un identificateur du mobile et pouvoir lui envoyer des données en utilisant cet identificateur (solutions de type 2), nettement plus fréquentes.
Un exemple de solution de type 1 est d'utiliser le
DNS. Si le mobile met à jour (par exemple par
mise à jour dynamique, cf. RFC 2136) le DNS
lorsqu'il se déplace, on utilise le nom de domaine comme identificateur, l'adresse IP comme
localisateur et le DNS comme correspondance. Le CN peut donc toujours
trouver l'adresse IP actuelle par un simple
getaddrinfo(). La plupart des
techniques normalisées par l'IETF sont, elles, de type 2. Dans
celles-ci, l'adresse IP sert d'identificateur (permettant de maintenir
les sessions TCP, par exemple dans le cas de SSH). Les paquets envoyés
par le CN sont alors transmis à cette adresse IP stable, où un
équipement doit ensuite les renvoyer au mobile, alors que les paquets
émis par le mobile vers le CN voyagent directement. On parle de
routage en triangle. Peu satisfaisant du point de vue des
performances, il est en revanche excellent pour la protection de la
vie privée : le CN, la machine avec laquelle correspond le mobile, ne
sait pas où on est et ne sait pas si on bouge. (Notons que le RFC, et
c'est plutôt choquant, ne mentionne pas une seule fois ces questions
de protection de la vie privée, même pas dans la section 7 sur la sécurité.)
La section 4 présente ensuite les protocoles de mobilité existants. Je ne vais pas les reprendre tous ici (la liste en compte vingt-deux !) mais simplement en choisir arbitrairement quelques uns. On trouve dans cette liste des ancêtres comme le protocole Columbia de 1991, ou des protocoles plus récents comme le Mobile IP de 1996. Certains des protocoles étudiés n'ont pas été conçus uniquement pour la mobilité, mais la facilitent. C'est le cas de HIP (2003), ILNP (2005) ou LISP (2009).
Columbia, par exemple, le premier conçu, ne fournissait la mobilité qu'à l'intérieur du campus. Dans chaque cellule radio, un routeur spécial, le MSS (Mobile Support Station), assurait le routage des paquets dont l'adresse IP source appartenait au préfixe spécial « mobilité ». Le mobile gardait donc son adresse et les MSS s'arrangeaient entre eux pour acheminer le paquet.
Le principal protocole standard de mobilité est aujourd'hui Mobile IP, normalisé dans les RFC 3344, RFC 6275 et RFC 5454. Il fonctionne en IPv4 ou en IPv6, sur la base des mêmes principes. Chaque mobile a un Home Agent, qui ne bouge pas, et qui fournit au mobile une adresse stable (Home Address). Le mobile a aussi une adresse IP liée à son point d'attache actuelle, l'adresse CoA (Care-of Address). Le mobile prévient le Home Agent de tout changement de CoA. Le correspondant, le CN, écrit toujours à l'adresses Home Address, charge au Home Agent de faire suivre. Mobile IP est donc de type 2 et, par défaut, fait du routage en triangle (une optimisation permet de le supprimer dans certains cas). Il existe aujourd'hui de nombreuses mises en œuvre de Mobile IP, aussi bien pour les mobiles que pour les Home Agents mais très peu de déploiements.
Un exemple de protocole de type 1 est E2E. Dans ce cas, l'identificateur stable du mobile est un nom de domaine, et c'est une simple requête DNS qui indique au correspondant quelle adresse IP utiliser. Le mobile, lorsqu'il change d'adresse IP, utilise les mises à jour dynamiques du DNS pour modifier cette information.
HIP n'était pas conçu uniquement pour la
mobilité. Toutefois, en séparant identificateur et
localisateur, il facilite celle-ci (RFC 5206). Pour trouver une adresse IP
à partir d'un HI (Host Identifier, les
identificateurs stables des nœuds HIP), on peut utiliser le DNS
mais aussi des « serveurs de rendez-vous » spécifiques à HIP (RFC 5204). La mobilité avec HIP nécessite que le CN
soit un nœud HIP également. Lorsqu'un mobile HIP se déplace, il
doit prévenir à la fois les CN et le serveur de rendez-vous (message
HIP UPDATE, section 5.3.5 du RFC 5201).
Autre protocole de séparation de l'identificateur et du
localisateur qui facilite la mobilité,
LISP. Bien plus récent, il est encore peu
déployé, et ses extensions de mobilité sont seulement sous forme d'un
projet de RFC, draft-meyer-lisp-mn.
Armé de ces descriptions, le RFC, dans se section 5, explique les différents choix qui ont été faits pour chaque protocole. C'est la section la plus intéressante du RFC. (La section 6.3 examine plus en détail les avantages et inconvénients de chaque approche.) Par exemple, une approche était de réutiliser le routage, en gardant l'adresse IP fixe pour le mobile, et en comptant sur des protocoles proches de ceux de routage pour assurer l'acheminement du paquet jusqu'au bonne endroit. Le protocole Columbia fonctionnait ainsi. Mais de telles solutions ne marchent bien qu'en réseau local : pas question de changer les routes de l'Internet chaque fois qu'un mobile se déplace.
Deuxième approche : une fonction de correspondance entre un identificateur stable et l'adresse IP actuelle. Au lieu de prévenir le monde entier lorsque son adresse change, le mobile n'aurait plus à prévenir qu'un seul point (le serveur DNS, ou le serveur de rendez-vous, pour les solutions de type 1 ou bien le Home Agent, pour celles de type 2.) Si le CN n'est pas prévenu du changement (cas de Mobile IP, par défaut), on perd en performances (routage en triangle) mais on gagne en intimité et surtout on n'a pas besoin que le CN comprenne le protocole de mobilité (avec Mobile IP, le mobile peut parler à des machines IP normales, qui ignorent tout de ce protocole).
Ce dernier point, couvert en détail dans la section 5.2, est crucial : qui doit être mis au courant de la mobilité ? Il y a quatre parties concernées : le mobile, son correspondant (CN), le réseau (les routeurs) et le composant qui donne un coup de main (Home Agent, serveur DNS, etc). Si le CN doit être mis au courant (cas de HIP, par exemple), il faut mettre à jour toutes les machines avec qui le mobile est susceptible de communiquer, ce qui ne semble pas très réaliste (d'autant plus que les gros serveurs Internet auraient à garder un état considérable, pour se souvenir de tous leurs clients récents). La plupart des approches, à commencer par Mobile IP, gardent donc une adresse IP stable et le CN est une machine ordinaire, qui ne sait même pas qu'elle parle à un mobile. Il existe aussi quelques protocoles où ni le CN, ni le mobile, ne sont au courant et où le réseau fait tout. Dans le futur, toutefois, de plus en plus de machines seront mobiles et il est possible que le premier choix (rendre le CN conscient que son partenaire se déplace) redevienne attirant.
Autre choix à faire, la mobilité doit-elle être contrôlée par le réseau ou par l'utilisateur (section 5.3) ? Dans les réseaux de téléphonie mobile, le terminal ne gère pas la mobilité, le réseau fait tout pour lui, et ça marche. Mais cela prive l'utilisateur de tout contrôle sur la façon dont est gérée la mobilité. (Songez aux scandaleux tarifs d'itinérance, rendus possibles par le fait que l'utilisateur ne peut pas empêcher que tout passe par son opérateur habituel.)
Les différences entre les protocoles de mobilité s'expliquent aussi par le fait que certains visent une solution mondiale, qui doit marcher pour des centaines de millions de mobiles se déplaçant partout dans le monde (ce qui soulève de sérieux problèmes de scalability) alors que d'autres (comme Columbia, cité plus haut), ne cherchent qu'une mobilité locale, problème bien plus facile (section 5.4).
Enfin, les vingt-deux protocoles examinés dans ce RFC ne couvrent
pas tout. On peut aussi baptiser « mobilité » des solutions simples
comme un serveur OpenVPN - qui jouera un rôle
équivalent à celui du Home Agent - plus un client OpenVPN sur chacune des
machines de l'utilisateur, avec une adresse IP fixe chacune. Il existe aussi des approches radicalement différentes
(section 5.5) comme GTP (qui ne marche qu'à l'intérieur d'un fournisseur donné) ou comme des solutions fondées sur les
applications, comme je l'ai prôné au début de cet article. Par
exemple, SIP dispose d'une extension pour gérer
la mobilité (cf. Schulzrinne, H. et E. Wedlund, « Application-Layer
Mobility Using SIP », dans Mobile Computing and Communications
Review, 2010) où un nouveau message
INVITE est envoyé lorsque le mobile change
d'adresse IP pendant une communication.
Je l'ai dit, les protocoles spécifiques de mobilité sont pour l'instant un échec complet. Mais que prévoient les auteurs du RFC pour le futur ? La section 6 analyse d'abord cet échec (section 6.1). Peu ou pas de déploiement en production, donc. Mais pourquoi ? Le RFC estime que c'est en partie le résultat du fait que les machines mobiles ne sont devenues banales que depuis très peu de temps. Mais il reconnait aussi que les protocoles de mobilité sont des usines à gaz complexes et lentes. Certains suggèrent même de simplifier le problème en ignorant les questions de performance et de sécurité (cf. section 7 sur les problèmes de sécurité spécifiques à la mobilité) dans un premier temps (ce conseil vient directement de l'excellente section 3 du RFC 5218).
Puis la section 6 explore les pistes à suivre. Une très bonne lecture pour les concepteurs de protocoles et les étudiants en réseaux informatiques.
Pour la mobilité des téléphones et la fréquence des déconnexions, changements d'adresse IP, etc, je recommande le bon article « A Day in the Life of a Mobile Device ».
L'article seul
Mon génome à poil sur l'Internet
Première rédaction de cet article le 7 juillet 2011
Dernière mise à jour le 18 juillet 2011
Je viens de faire faire une analyse génomique personnelle en utilisant le service de 23andMe. Je vous rassure tout de suite, je ne mets pas mon génome en donnée ouverte sur ce blog, malgré le titre de l'article.
Au début de l'analyse du génome humain, il fallait des années et des sommes considérables pour analyser le génome d'un seul individu. Les prix de l'analyse baissant à vue d'œil, un particulier peut désormais faire analyser son propre génome. J'ai utilisé le service de 23andMe (pour tester vos connaissances en génétique, demandez-vous, « pourquoi 23 ? ») et cela ne m'a coûté que 200 dollars (une fois mon analyse faite, les prix ont été divisés par deux...). Pour ce prix là (et 60 dollars de frais postaux), on obtient son génome sous forme d'un fichier de données brutes (plus exactement, on obtient un ensemble de SNP, voir le résumé technique à la fin) et tout un tas d'analyses faites par 23andMe. Parmi lesquelles :
- Des informations de santé : risques (estimés) de développer certaines maladies, lorsque leur cause est partiellement génétique, réponses probables de l'organisme à certains médicaments (ce qu'on nomme la médecine personnalisée),
- Des informations sur ses ancêtres, leur région probable d'origine,
- Et plein d'autres données, comme s'il n'y avait pas déjà assez de choses à lire sur l'Internet...
Je n'ai pas l'intention de distribuer sur l'Internet mon génome complet (certains l'ont fait et on trouve même un site rassemblant tous ces génomes publics, SNPedia), les risques n'étant pas encore bien mesurés. Vous allez donc devoir vous contenter de certains extraits.
23andMe propose des outils d'analyse sur le site Web. J'apprends ainsi que mes risques médicaux les plus élevés sont le cancer de la prostate et surtout la dégénérescence maculaire (presque quatre fois le risque moyen). Du point de vue des remèdes, je n'ai pas de résistance génétique au SIDA (mais j'en ai une aux norovirus), et le traitement PEG-IFNalpha/RBV contre l'hépatite C n'aura sans doute que peu d'effet sur moi...
Je trouve, dans la rubrique sur les ancêtres, que les miens viennent sans doute d'Europe du Nord (les Alpes et les Pyrénées étant la frontière génétique de l'Europe du Nord). Mes lignées paternelles et maternelles sont proches, et la comparaison avec les génomes de gens célèbres qui ont été analysés montre des traits communs avec Warren Buffett... Les beaux graphiques de cette rubrique exigent malheureusement le logiciel non-libre Flash.
Enfin, question physique, j'apprends que mon génome indique des yeux sans doute bleus (c'est pas faux), une tolérance au lactose (j'ai avalé un bol de céréales avec du lait, pour fêter ça), et que je résiste bien au café (qui augmente le risque d'attaque cardiaque pour certaines personnes), ...
À chaque fois, on a droit à une page détaillée sur la maladie, des explications, des pointeurs vers les articles scientifiques, etc. On peut donc passer sa vie à s'informer sur son corps.
Pour les maladies plus graves, et pour lesquelles on ne connait pas de remède, comme l'Alzheimer, le rapport n'est pas accessible directement, il faut confirmer deux fois qu'on veut bien le lire : 23andMe estime sans doute que le jeu n'en vaut pas la chandelle puisqu'il n'y a pas d'action préventive possible. Autant rester dans l'ignorance (je n'ai pas insisté).
Dans le plus pur style 2.0, on peut partager
son génome avec d'autres utilisateurs de 23andMe, ceux marqués comme
« amis », ceux marqués comme « famille ». Je vous préviens tout de
suite, je ne partage qu'avec les gens que je connais vraiment. Notez bien que, les gènes de
parents proches étant... proches, vos frères et parents peuvent en
savoir beaucoup sur votre génome, simplement en analysant le
leur... Pareil en sens inverse, les risques pour ma santé s'appliquent
aussi à ma famille. La lecture de https://www.23andme.com/help/#privacy est très
intéressante (toute la FAQ aussi,
d'ailleurs).
Bon, évidemment, tout ce genre d'analyses est à prendre avec de sérieuses pincettes (« comme les prévisions météo à dix jours », me souffle une biologiste). D'abord, l'« étude » est entièrement automatisée (pour cent dollars, vous n'avez pas un expert de l'analyse génomique qui se penche sur votre génome...). C'est donc du prêt-à-porter plutôt que de la confection. Ensuite, d'autres indices, moins high-tech, peuvent vous renseigner aussi bien. Pour la dégénérescence maculaire, la connaissance de l'historique familial permet d'avoir une idée du risque, certes approximative, mais presque aussi bonne que les analyses génétiques.
Si vous vous demandez comment se passe le prélèvement, 23andMe vous envoie un colis avec l'éprouvette spéciale, dans laquelle il faudra baver pendant dix à vingt minutes en se stimulant l'intérieur de la joue (pour augmenter la production de salive). Il vaut mieux que personne d'autre ne regarde à ce moment, on a vraiment l'air bête. L'éprouvette est spéciale car le voyage international d'échantillons biologiques est très réglementé (présence obligatoire d'un élément absorbant, au cas où l'éprouvette fuit, par exemple). Il faut ensuite remplir pas mal de papiers. Le prix inclut le voyage retour par DHL.
23andMe propose aussi, en cochant une case, de passer ses données à la recherche scientifique. Je ne l'ai pas encore fait.
À noter que d'autres entreprises proposent de la « génomique directe » comme deCODE. Un bon suivi de cet industrie est fourni par le site Genomes Unzipped.
Et question bricolage, faire ses propres analyses, faire des
mashups et tous ces trucs
modernes ? 23andMe permet de récupérer l'intégralité des données
(option Download raw data). Au moment
du téléchargement, 23andMe vous met en garde, notamment sur le fait
que le fichier, stocké sur une machine non sécurisée, est
vulnérable... Moi, j'ai rapidement fait un gpg --encrypt
--user bortzmeyer
genome_Stephane_Bortzmeyer_Full_20110707000202.txt - un
simple chmod 600 ... ne
m'aurait pas satisfait. Notez que la sécurité des échanges semble
assez convenable,
HTTPS partout, demande systématique de la
question secrète lorsqu'on veut récupérer les données brutes,
etc. Cela n'indique évidemment rien sur la sécurité chez 23andMe,
aussi bien en cas d'attaque qu'en cas de malhonnêteté de la part de l'entreprise.)
Une fois les données récupérées (vingt-quatre mégaoctets, décomprimées), voici à quoi ressemblent les données brutes (merci à Victoria Dominguez pour son aide sur cette section) :
# rsid chromosome position genotype rs4477212 1 72017 AA rs3094315 1 742429 AG rs3131972 1 742584 AG rs12124819 1 766409 AA rs11240777 1 788822 AG rs6681049 1 789870 CC ...
Le format semble être spécifique à 23andMe (un identificateur, le numéro du chromosome, la position dans le chromosome - en nombre de bases depuis le début - et les valeurs des bases, A, T, C ou G). Il ne semble pas possible d'avoir les données dans un format que comprennent la plupart des outils d'analyse, comme le format FASTA. Les données (des SNP) sont constituées des différences avec le génome humain de référence, dit « build 36 ». C'est donc un format équivalent à diff. On pourrait penser que, pour retrouver mon génome complet, il suffit d'appliquer ce patch au génome de référence. Mais la génomique est bien plus compliquée que cela. Par exemple, dans mes données envoyées par 23andMe, le chromosome 1 va jusqu'à la position 247 185 615 alors que seules 224 999 719 ont été séquencées. Il y a donc pas mal de trous, empêchant une reconstruction facile.
Évidemment, on ne peut pas en faire grand'chose, pour l'instant. Mais l'analyse dans son garage approche. Déjà, des sites proposent une analyse des données existantes, en documentant le cas des clients de 23andMe, par exemple celui de James Lick. Un de ces jours, je lirai le livre de Marcus Wohlsen, « BioPunk: DIY Scientists Hack the Software of Life ».
À noter un article similaire écrit deux ans plus tard, sans information supplémentaire.
L'article seul
RFC 6274: Security Assessment of the Internet Protocol version 4
Date de publication du RFC : Juillet 2011
Auteur(s) du RFC : F. Gont (UK CPNI)
Pour information
Réalisé dans le cadre du groupe de travail IETF opsec
Première rédaction de cet article le 6 juillet 2011
Le protocole IPv4, qui représente toujours la très grande majorité du trafic réseau sur l'Internet, n'avait jamais fait l'objet d'un rapport synthétique sur sa sécurité. Certes, il existe d'innombrables articles portant sur la sécurité d'IPv4, des avis des CSIRT, de très nombreuses mentions dans les RFC et ailleurs. Mais tout ceci était dispersé dans de nombreux documents, et pas forcément facilement accessible lorsqu'on se mettait à lire les normes. D'où ce RFC 6274 qui rassemble en un seul endroit tout ce qu'il faut savoir sur la sécurité d'IPv4. Pas de révélations dans ce document, les problèmes qui y sont décrits sont très classiques, souvent résolus depuis des années mais, comme ils n'avaient pas forcément été documentés dans un RFC, il y avait un risque sérieux qu'un programmeur, voulant mettre en œuvre IPv4 en partant de zéro, retombe dans des failles anciennes. Ce RFC vise donc à éviter toute régression. Avant sa publication, un programmeur qui ne lisait que les RFC était à peu près sûr de créer des failles de sécurité béantes.
Parfois, c'est même pire : des failles connues ne sont pas résolues dans certaines implémentations, ou bien le sont d'une manière qui rend le remède pire que le mal (beaucoup de programmeurs ne connaissent de la sécurité que de vagues notions et des légendes entendues et jamais contestées).
L'introduction (section 1) note qu'IPv4 avait été conçu dans un environnement très différent de ce qu'il est aujourd'hui. Toutefois, elle ne reprend pas l'idée courante mais fausse comme quoi les failles de sécurité d'IPv4 découleraient d'une vision optimiste et naïve de la nature humaine, d'une époque où seuls des bisounours utilisaient l'Internet et où il n'était donc pas nécessaire de prévoir des mécanismes de sécurité. En réalité, même si on refaisait l'Internet aujourd'hui en partant de zéro, une bonne partie des problèmes se poserait de la même façon : sécuriser un réseau multi-organisations et multi-national n'est pas de la tarte, que ce soit aujourd'hui, ou bien il y a vingt-cinq ans ! Quoi qu'il en soit, l'Internet est aujourd'hui une ressource critique, dont dépendent bien des choses dans le monde. Sa sécurité est donc un enjeu majeur.
À propos de légendes, le RFC prend position sur le récit « Internet a été conçu pour résister à une attaque nucléaire » en estimant que ce n'est pas exact, que la principale motivation n'était pas de fournir un système de communications invulnérable aux militaires, mais de partager l'accès à des mainframes (voir l'article de D. Clark, « The Design Philosophy of the DARPA Internet Protocols », Computer Communication Review Vol. 18, No. 4, 1988).
Les problèmes de sécurité découverts depuis ont parfois affecté une mise en œuvre particulière (c'est une loi générale du logiciel : « il y a des bogues ») et parfois les concepts de base du protocole, rendant bien plus difficile la solution. La bibliographie du RFC donne une idée des problèmes les plus importants.
Comme il n'est pas réaliste de couvrir tous les problèmes de sécurité de l'Internet, ce RFC se focalise (section 1.2) sur ceux d'IP lui-même, excluant les protocoles de transport comme TCP ainsi que les protocoles de routage comme BGP ou ceux de démarrage comme DHCP. Les RFC cruciaux pour cette évaluation de la sécurité sont donc :
- RFC 791 sur IP,
- RFC 815 sur le réassemblage de paquets fragmentés,
- RFC 919 sur la diffusion,
- RFC 1122, qui note toutes les exigences pour les machines terminales,
- RFC 1812, qui note toutes les exigences pour les routeurs,
- RFC 2474 et RFC 2475 sur les services différenciés (traitement « à la tête du paquet »),
- RFC 3168 sur ECN,
- RFC 4632 sur le mécanisme d'adressage,
- Et quelques autres (voir le RFC).
La section 2 du RFC rappelle les concepts de base d'IP, inchangés depuis ses débuts (et parfois depuis l'époque d'Arpanet). Reprenant l'article fondateur de Clark cité plus haut, il cite les trois principes essentiels :
- Pas d'état dans les routeurs, ceux-ci traitent chaque paquet sans tenir compte des paquets précédents,
- Un service minimum au niveau IP, notamment sans garantie de délivrance (ce qui fait qu'une grande partie du travail doit être fournie par des protocoles situés au dessus, comme TCP),
- Un service minimum fourni par les couches inférieures, auxquelles IP ne demande pas grand'chose, lui permettant de fonctionner sur n'importe quel réseau.
Maintenant, allons-y, avec deux longues sections, dont je ne transmets ici qu'une partie : la section 3 examine un par un les champs de l'en-tête du paquet IP et les différentes façons dont ils peuvent impacter la sécurité. La section 4 examine les différents mécanismes de traitement de paquets IP et ce qui peut en résulter.
La section 3 commence par rappeler le schéma du RFC 791 décrivant tous les champs qu'on trouve dans l'en-tête d'un paquet
IP. En théorie, tous les paquets doivent obéir à certains invariants,
le premier cité par le RFC étant que la taille du paquet doit être
d'au moins vingt octets (la taille minimale d'un en-tête et donc d'un
paquet). Mais, comme l'a observé toute personne qui a analysé du
trafic réseau avec des dissecteurs mal écrits, on
trouve de tout sur l'Internet et notamment plein de paquets mal
formés. Notre RFC 6274 donne donc à chaque fois des
conseils de tests de santé à faire sur chaque paquet avant de le
traiter. Le premier test est donc longueur(paquet) >= 20. À
chaque fois, si le test échoue, le paquet devrait être abandonné et un
compteur de problèmes incrémenté. Allons-y maintenant pour les autres
tests (oui, cela va être long), dans l'ordre des champs.
L'en-tête a un champ Version qui, pour IPv4, doit valoir... 4
(section 3.1). En théorie, on peut imaginer des techniques de
couche 2 où les paquets de différentes versions
d'IP soient démultiplexés par ce champ (une telle technique existe
dans la section 3.2 du RFC 6214, publié le premier avril
2011). En pratique toutefois, tous les
réseaux existants fournissent un autre moyen de démultiplexer (par
exemple le champ EtherType dans
Ethernet, qui vaut 0x0800 pour IPv4 et 0x86DD
pour IPv6) et donc, une fois le paquet reçu par l'implémentation IPv4,
le champ Version doit donc forcément valoir 4 et il faut vérifier cela. Oublier ce test
permettrait certaines attaques où un méchant mettrait une autre
valeur pour exploiter le fait que certains équipements
accepteraient le paquet et d'autres (avec un peu de chance, les
IDS) l'ignoreraient.
Champ suivant, IHL (Internet Header Length), la
longueur de l'en-tête du paquet IP (contrairement à
IPv6, celle-ci n'est pas constante, en
raison de la présence possible d'options). Comme elle est exprimée en
nombre de mots de quatre octets, le test de longueur minimale est
cette fois
longueur(en-tête) >= 5. Comme l'en-tête est
forcément plus petit que le paquet, on doit aussi vérifier
longueur(en-tête) * 4 <= longueur(paquet). Ces
tests peuvent sembler un peu bêtes mais il y a déjà eu des attaques
jouant sur des longueurs bizarres, pour forcer une implémentation à
lire des zones mémoire où elle n'aurait pas dû aller. Là encore, en
cas d'échec des tests, abandon du paquet et incrémentation du compteur
des paquets invalides.
Tout est évidemment plus compliqué lorsqu'un champ a changé de sémantique, ce qui est le cas de l'ancien ToS (Type of Service) devenu DSCP avec le RFC 2474 (section 3.3). Normalement, toutes les mises en œuvre d'IP devraient traiter ce champ selon la nouvelle définition mais cela ne semble pas être le cas. Donc, une application peut mettre une valeur qui semblera inoffensive si elle est interprétée comme ToS mais lui donnera une priorité si cette même valeur est interprétée comme DSCP. Une protection possible est d'effacer ce champ lorsqu'un paquet arrive dans un domaine administratif (la qualité de service différenciée n'a de toute façon de sens qu'à l'intérieur d'un même domaine, au sein d'une même entreprise, par exemple).
Les bonnes intentions faisant parfois les belles failles de sécurité, la section 3.3.2.2 est consacrée à ECN (RFC 3168), une technique de lutte contre la congestion, qui peut dans certains cas être exploitée contre la sécurité (par exemple en faisant croire qu'on gère la congestion par cette technique, même si ce n'est pas vrai, simplement pour diminuer la probabilité de voir ses paquets jetés par les routeurs).
On a déjà parlé de longueur, de celle indiquée par la couche 2, de celle indiquée par le champ IHL pour indiquer la longueur de l'en-tête... Il y a aussi un champ Total Length qui indique la longueur du paquet (en-tête compris). Quels sont les pièges de sécurité liés à ce champ (section 3.4) ? D'abord, ce champ pouvant indiquer des tailles jusqu'à 65535 octets, les mises en œuvre d'IP doivent préparer des tampons d'entrée/sortie assez grands pour cela. Normalement, les correspondants ne doivent pas envoyer de paquets de plus de 576 octets avant qu'on leur ai signalé qu'on pouvait traiter plus (par exemple par le biais de l'option MSS de TCP, ou par l'EDNS du DNS). Mais il existe certains cas où les autres machines envoient des paquets plus grands sans prévenir (cas de NFS) et, de toute façon, un attaquant ne suivra pas forcément les règles.
Plus rigolo, un attaquant peut transmettre un paquet plus grand que la taille indiquée dans le champ Longueur, par exemple dans l'espoir d'obtenir un débordement de tampon. Si la couche 2 lui permet, il peut même envoyer des paquets plus grands que 65535 octets. Ce genre de paquets se trouve réellement dans la nature et peuvent être le résultat d'une programmation maladroite, ou bien d'une tentative d'attaque (comme celle citée en « US-CERT Vulnerability Note VU#310387: Cisco IOS discloses fragments of previous packets when Express Forwarding is enabled »). Le récepteur doit donc être paranoïaque. Allouer un tampon de la taille indiquée par le champ Longueur, puis y copier le paquet sans vérification serait très imprudent. Il faut utiliser au contraire la taille indiquée par la couche 2.
Le champ suivant la longueur, ID, identifie le fragment (section 3.5), pour permettre le réassemblage en cas de fragmentation. Sur certains systèmes, la façon dont est choisie ce nombre peut révéler bien des choses sur l'emetteur (voir « Idle scanning and related IP ID games »). Sur les systèmes anciens, l'ID était unique par paquet, choisi de manière incrémentale et donnait donc au récepteur une indication, par exemple sur le nombre de machines derrière un routeur NAT. Comment peut-on limiter ces risques de fuite d'information ? Une des solutions est de mettre le champ ID à zéro pour tout paquet qui a le bit DF (Don't Fragment). Ces paquets ne pouvant être fragmentés, le fait d'avoir tous le même ID n'est pas gênant. Linux a été le premier à faire cela. Mais certains équipements mal conçus (les affreuses middleboxes) fragmentaient quand même ces paquets, qu'on ne pouvait plus réassembler. Depuis, Linux (et Solaris) mettent un ID fixe, mais différent pour chaque adresse, ce qui limite les fuites d'information. En effet, l'ID n'a pas besoin d'être unique par machine, il suffit qu'il soit unique par tuple {source, destination, protocole}. Le mieux serait donc de générer aléatoirement (pour empêcher les fuites d'information) un ID unique par « session » pour chaque tuple. Attention à bien lire le RFC 4086 avant de choisir son générateur aléatoire. Ce problème de choix entre un identificateur prévisible (qui est donc indiscret) et un identificateur aléatoire (qui risque donc d'être réutilisé plus vite) est très proche de celui du choix du port source décrit dans le RFC 6056.
Le cas est plus complexe pour les protocoles sans connexion comme UDP (utilisé notamment pour le DNS qui, depuis le déploiement de DNSSEC, a plus souvent des paquets fragmentés). Dans certains cas, des paquets corrompus risquent d'être réassemblés et les protections des couches supérieures risquent de ne pas être suffisantes pour détecter cette corruption (pour le DNS, il faut au moins activer la somme de contrôle UDP, ce qui limite les risques).
Passons maintenant au champ Flags de l'en-tête (section 3.6). Il contient trois bits dont deux sont définis : DF (Don't Fragment) et MF (More Fragments). De manière amusante, le bit DF peut être utilisé pour empêcher la détection par un IDS. Si l'attaquant sait que, après l'IDS, la MTU baisse, il peut envoyer des paquets ayant le bit DF dont certains sont trop gros pour cette MTU. L'IDS va les lire mais la machine de destination ne les verra jamais, puisqu'ils ont été jetés par le routeur précédent (qui n'avait pas le droit de les fragmenter). L'IDS et la machine de destination verront alors des données différentes, ce qui peut permettre de rendre indétectable une charge utile malveillante. Si ce cas semble extrêmement tordu (depuis quand met-on des tunnels après les IDS ?), il faut préciser qu'il existe des variantes de cette attaque, basées sur les bogues de certains logiciels (par exemple qui jettent les paquets ayant à la fois MF et DF, alors que ces paquets peuvent atteindre la destination), qui permettent d'obtenir le même résultat.
Juste après, un autre champ lié au réassemblage, le champ Fragment Offset (section 3.7). Si certaines des attaques décrites dans ce RFC peuvent sembler purement théoriques, celles portant sur des jeux avec l'algorithme de réassemblage des fragments sont très courantes en pratique. Ce champ indique la position du fragment dans le datagramme original et les valeurs bizarres de ce champ sont fréquentes dans la nature. Par exemple, un fragment peut prétendre être situé plus loin que le 65535ème octet du paquet original (le champ est assez grand pour cela, on peut aller jusqu'à 131043 octets), ce qui peut mener à des débordements de tampon au cours du réassemblage. Cela a déjà été utilisé par exemple dans l'attaque nommée (bien à tort) ping of death (« CERT Advisory CA-1996-26: Denial-of-Service Attack via ping » et « The Ping of Death Page » en 1996. Cette attaque est très mal nommée parce qu'elle n'a rien à voir avec ping, ni même avec ICMP. un paquet IP de n'importe quel protocole peut convenir. Si vous faites un interview d'un candidat à un poste d'administrateur réseaux, c'est une bonne question à poser : « faut-il filtrer ICMP sur le pare-feu ? ». S'il répond « oui, à cause du ping of death », vous savez qu'il n'y connait pas grand'chose en sécurité des réseaux.
Et le bon vieux champ TTL (Time To Live, section 3.8), pose-t-il aussi des problèmes de sécurité ? Oui. Il peut transmettre de l'information (type de système d'exploitation à la source, puisque la valeur par défaut du TTL peut en dépendre, distance de la source, d'après la diminution observée, etc). Son rôle dans la découverte de la topologie du réseau est bien connu puisqu'elle est utilisée par l'outil traceroute (qui lance des paquets de TTL croissant, pour repérer les routeurs qui reçoivent un paquet de TTL nul et refusent donc de le transmettre).
Il peut, comme dans le cas de DF, être utilisé pour faire en sorte qu'un IDS et la machine de destination ne voient pas la même chose, par exemple en mettant un TTL plus bas aux paquets destinés seulement à l'IDS. S'il y a un routeur après l'IDS, ces paquets ne seront pas vus par la machine cible. L'outil Scrub d'OpenBSD peut aider contre cette attaque.
Mais le TTL a aussi des usages positifs en terme de sécurité. Par exemple, mis à la valeur maximale (255), il peut permettre de s'assurer qu'un paquet vient bien du réseau local, en vérifiant que le TTL est bien 255 à l'arrivée (cette technique est décrite en détail dans le RFC 5082).
Le champ suivant le TTL indique le protocole utilisé par les couches supérieures (UDP, TCP, SCTP, etc). Il n'a rien de dangereux mais certaines attaques dans le passé utilisaient ce champ avec des implémentations boguées (section 3.9).
Ensuite vient la somme de contrôle de l'en-tête. Là encore, on peut s'en servir pour échapper à certains contrôles faits par des équipements qui ne testent pas cette somme. En mettant délibérement une valeur invalide, on crée un paquet qui sera vu par certaines machines et pas par d'autres, trompant ainsi les IDS.
Puis viennent les adresses IP, les deux champs suivants, qui indiquent respectivement les adresses source et destination (section 3.11 et 3.12). Normalement, tout le monde connait leur principale faiblesse en matière de sécurité : elles ne sont pas authentifiées et l'émetteur du paquet (ou un intermédiaire) peut mettre ce qu'il veut, surtout dans la source. Les adresses identifient normalement une interface réseau (la notion d'« adresse IP d'une machine » n'existe pas en IP). Sauf que rien n'empêche de mettre ce qu'on veut. (Un rappel au passage : le logiciel le plus souple et le plus facile d'usage pour fabriquer de faux paquets, en bricolant les champs qu'on veut, est Scapy. Utilisez-le, vous en serez content.) Normalement, un filtrage est réalisé par le réseau d'accès (RFC 2827 et RFC 3704, mais aussi « NISCC Technical Note 01/2006: Egress and Ingress Filtering ») pour empêcher les mensonges les plus éhontés de sortir sur l'Internet mais, en pratique, très peu de fournisseurs d'accès font ce test. (Le Spoofer Project mesure ce pourcentage.) Une autre technique de protection est la surveillance des adresses utilisées sur le réseau local, par exemple avec arpwatch.
On a donc vu d'innombrables attaques où les adresses IP source des attaquants étaient fausses. Le RFC fournit quelques exemples comme « CERT Advisory CA-1996-01: UDP Port Denial-of-Service Attack », « CERT Advisory CA-1996-21: TCP SYN Flooding and IP Spoofing Attacks » ou « CERT Advisory CA-1998-01: Smurf IP Denial-of- Service Attacks ».
Cette absence d'authentification des adresses IP se retrouve à d'autres endroits que l'en-tête IP, par exemple, dans les paquets ICMP qui sont censés transporter une partie du paquet original : rien n'indique que cette information soit fiable (RFC 5927).
Conséquence pratique, il ne faut surtout pas authentifier une machine sur la seule base de l'adresse IP qu'elle présente. Par exemple, dans le cas d'une dDoS, on voit parfois des administrateurs réseaux naïfs croire qu'ils ont découvert l'origine de l'attaque lorsqu'ils ont fait un whois sur l'adresse IP source, sans penser une seconde qu'elle puisse être trompeuse...
À noter que le RFC ne rappelle pas qu'on peut « authentfier » une adresse IP si le protocole de transport impose des aller-retours, ce qui est en général le cas avec TCP (si les numéros de séquence initiaux sont bien choisis au hasard, l'attaquant doit recevoir ou voir passer les paquets de réponse, pour arriver à établir une connexion).
IPv4 a ensuite un champ Options, le dernier du paquet. Il est de taille variable car les options sont... optionnelles (section 3.13). Bien que plusieurs options aient été normalisées, elles sont très peu utilisées en pratique, en partie parce qu'elles ne passent pas partout, en partie parce que leur présence peut ralentir sérieusement le paquet (beaucoup de routeurs traitent le paquet « normal » en ASIC et transmettent les paquets ayant des options au processeur principal, bien plus lent : cela peut être exploité pour DoSer le routeur en envoyant plein de paquets avec options).
Les options étant de taille variable (le curieux lira avec
amusement la section 3.1 du RFC 791, qui
explique les deux méthodes d'encodage d'une option), il y a une
nouvelle possibilité d'attaque par débordement de tampon, si l'indication de la longueur de
l'option est fausse. Là encore, quelques tests sont indispensables,
les options du cas 2 ont une longueur d'au moins deux octets
(option-length >= 2), et cette longueur ne
doit pas nous mener en dehors du paquet (option-offset +
option-length <= IHL * 4). Si vous êtes étudiant, faites
attention : écrire un analyseur de paquets IP est un
TP classique et le professeur sadique risque
fort d'envoyer à votre analyseur des paquets délibérement mal formés
pour vous prendre en défaut.
Autre piège pour le code d'analyse, les types utilisés : certaines options ont des pointeurs, stockés sur un octet, et le RFC 791 ne précise pas si cet octet est signé ou non. Si on ne fait pas attention, on peut se retrouver avec des pointeurs négatifs.
Ça, c'était le problème des options en général. Après, certaines options spécifiques ont leurs propres problèmes de sécurité. LSSR (Loose Source and Record Route, option de numéro 13) permet de contourner le routage et donc certaines règles des pare-feux, permet de joindre des machines normalement injoignables (par exemple si elles ont une adresse IP privée et sont derrière un routeur NAT), etc. Ces risques sont tels, par rapport aux bénéfices de cette option, que notre RFC 6274 recommandent de jeter sans autre forme de procès tous les paquets ayant cette option, dans la configuration par défaut des équipements. Un exemple d'attaque contre OpenBSD est décrit dans « OpenBSD Security Advisory: IP Source Routing Problem ». Mêmes remarques, et même recommandation pour l'option SSSR (Strict Source and Record Source, numéro 137). Cette option a déjà été utilisé pour des attaques (par exemple « Microsoft Security Program: Microsoft Security Bulletin (MS99-038). Patch Available for "Spoofed Route Pointer" Vulnerability" ».
L'option Record Route (section 3.13.2.5) est encore pire puisque le routeur doit alors écrire dans le paquet lui-même. Comme avec les deux précédentes, il est vital de vérifier que les pointeurs ne pointent pas n'importe où. (Le problème touche d'autres protocoles qu'IP ; par exemple, lors du dévelopement de DNSmezzo ou de grong, j'ai pu constater que les pointeurs utilisés dans la compression des paquets DNS sont souvent invalides et ne doivent pas être suivis aveuglément.) En outre, cette option est indiscrète, puisqu'elle permet de réveler les routeurs par lesquels est passé un paquet. La taille très limitée du champ Options limite ce risque (on ne peut pas stocker plus de quelques routeurs) et rend cette option peu utile.
Un grand nombre de ces options peuvent être considérées comme n'étant que d'un intérêt historique (mais le code pour les traiter est parfois toujours là dans la pile IP et peut provoquer des problèmes de sécurité). C'est le cas de Timestamp (numéro 68, section 3.13.2.7), qui indique au routeur de marquer l'heure de passage du paquet dans le paquet. Comme Record Route, elle est indiscrète et devrait donc être ignorée par défaut. Comme Record Route, elle entraine une écriture dans le paquet, à l'endroit indiqué par un pointeur et il faut donc, si on a activé cette option, vérifier le pointeur.
Je passe sur un certain nombre d'options pittoresques pour arriver à DoD Basic security Option (numéro 130). Cette option militaire, normalisée dans le RFC 1108, indique le niveau de sécurité du paquet (« confidentiel », « secret », « très secret », etc). Contrairement à la plupart des options IPv4, elle est largement mise en œuvre et déployée. Par exemple, SELinux, Cisco IOS et Solaris l'ont et beaucoup de réseaux comptent dessus. Elle a même inspiré un équivalent IPv6, décrit dans le RFC 5570.
Après cette longue liste des champs de l'en-tête IP, la section 4 de notre RFC 6274 s'attaque aux mécanismes actifs de traitement des paquets. De nouvelles failles se cachent là. Les principales touchent le processus de fragmentation et réassemblage (section 4.1). Lorsqu'un paquet IPv4 est trop gros pour le lien qu'il va emprunter, l'émetteur, ou bien le routeur intermédiaire, fragmentent ce paquet en paquets plus petits. La machine de destination (pas les routeurs) va devoir réassembler un paquet entier. Historiquement, ce processus est à l'origine de très nombreuses failles de sécurité. En effet, le réassemblage est une opération très complexe et qui était mal normalisée. C'est une opération qui nécessite de maintenir un état (dans un protocole, IP, qui est normalement sans état), le réassembleur ne connait pas les caractéristiques du chemin suivi par les paquets et ne sait donc pas combien de temps il peut attendre des fragments manquants, et les fragments peuvent arriver dans le désordre.
Quelles sont les conséquences de sécurité de la fragmentation ? D'abord, l'allocation mémoire : la machine de destination ne sait pas combien de temps elle doit attendre les fragments manquants. Elle doit donc réserver un espace mémoire pour le paquet et le garder jusqu'à être sûr que les fragments manquants n'arriveront jamais. Le RFC 1122 conseille de rester ainsi pendant 60 à 120 secondes, ce qui est très long si on reçoit beaucoup de paquets et peut mener à un épuisement de la mémoire si un attaquant génère des paquets fragmentés et délibérement incomplets. C'est encore pire si on suit le conseil du RFC 815 qui est d'allouer de la mémoire suffisante pour le plus grand paquet possible (la taille du paquet n'est connue qu'avec le dernier fragment).
Autre problème, le champ ID et sa taille limitée : sur un lien à 1 Gb/s, un flot continu de paquets IP de 1 kb (ce qui peut arriver avec de la vidéo en temps réel), chacun fragmenté en deux, va mener à une réutilisation du champ ID en moyenne au bout de 0,65 secondes seulement. Il y aura donc collision entre les fragments de deux paquets différents et le réassemblage mènera à la corruption (dont on espère qu'elle sera détectée par les protocoles des couches supérieures). Si des paquets sont injectés par un attaquant, il peut ainsi facilement créer une DoS.
Certains des problèmes de sécurité des fragments proviennent d'erreurs ou d'ambiguités dans la spécification. Ainsi, il est possible d'avoir des fragments qui se recouvrent (un fragment va de l'octet 0 à l'octet 959 inclus, un autre fragment de 1200 à 1919 inclus et encore un autre fragment va de 960 à 1279. Pour les octets de 1200 à 1279, doit-on utiliser le deuxième ou le troisième fragment ? Différents mises en œuvre d'IP ont fait des choix différents et ce point a été exploité par des outils qui fragmentent le paquet afin qu'il échappe à l'IDS (en utilisant le fait que l'IDS et la machine de destination n'utiliseront pas la même stratégie.) Un exemple d'un tel outil est Frag.
La section 4.1.2 rassemble un ensemble de conseils sur la fragmentation. S'ils étaient appliqués, IP serait plus sûr :
- Avoir deux espaces mémoire différents, pour le réassemblage et pour les paquets arrivant entiers, afin d'empêcher qu'une attaque par fragmentation ne bloque le service « normal » (Linux fait ceci),
- Réduire le temps d'attente (les 60 à 120 secondes officielles sont beaucoup trop),
- Jeter les fragments qui ont coupé l'en-tête du protocole de niveau supérieur (ces en-têtes sont assez petits pour ne jamais être fragmentés en temps normal, une telle coupure indique presque à coup sûr une tentative d'échapper au pare-feu ou à l'IDS),
- Et bien d'autres.
Le RFC 1858 et son successeur RFC 3128 fournissent des détails sur ces points.
Autre grande question, la transmission des paquets IP par un routeur (section 4.2). Par définition, un routeur reçoit des paquets qui ne lui sont pas destinés et qu'il doit transmettre. Cela peut soulever des problèmes de sécurité. Par exemple (section 4.2.3) , si un routeur doit faire une requête ARP (RFC 826) pour trouver l'adresse MAC de la machine suivante, et qu'il garde le paquet à transmettre en attendant la fin de la résolution ARP, un attaquant peut épuiser les ressources du routeur en envoyant plein de paquets vers des destinations inexistantes. Il est donc suggéré de jeter immédiatement les paquets lorsqu'une résolution ARP est nécessaire, en espérant que l'émetteur les renverra, s'ils étaient importants.
Enfin, l'adressage IP peut aussi recéler des pièges (section
4.3). Ainsi, un préfixe est réservé à des fins expérimentales, le
240/4 (ancienne « classe E », section 4.3.4). Le
RFC, suivant
une vieille pratique, recommande de jeter sans hésitation les paquets
dont l'adresse source est dans ce bloc. Ce conseil est d'ores et déjà
largement suivi, et est la raison pour laquelle on ne peut pas espérer
récupérer ces nombreuses adresses IPv4 pour faire face à l'épuisement.
Voilà, et on n'a couvert qu'IP et pas les autres protocoles de la famille. Reste maintenant à faire le même travail pour IPv6. Qui s'y colle ?
Si cette lecture peut donner l'impression qu'IPv4 est une incroyable erreur de sécurité, bourrée de vulnérabilités, il faut aussi se rappeler, comme l'analyse le RFC 5218, que ce sont certains raccourcis pris par IP qui ont permis ce succès. Aujourd'hui, il est certain qu'IPv4 ne serait pas accepté par l'IESG et c'est pourtant le protocole qui a fait décoller l'Internet.
À noter que ce RFC est très largement inspiré du rapport « Security Assessment of the Internet Protocol », du Centre for the Protection of National Infrastructure (CPNI) britannique. D'autre part, la bibliographie du RFC est recommandée, c'est un rappel de toutes les fameuses failles de sécurité d'IP.
L'article seul
Que doit-on mesurer, la QoS ou la QoE ?
Première rédaction de cet article le 4 juillet 2011
Dernière mise à jour le 1 janvier 2012
Lors de discussions sur la mesure des performances de l'Internet (par exemple au sein du « groupe de travail multilatéral sur la qualité de service » de l'ARCEP), il est fréquent de voir des désaccords sur le fait de mesurer la QoS (Quality of Service) ou bien la QoE (Quality of Experience). La première concerne des mesures plutôt techniques, proches du fonctionnement du réseau. La seconde cherche à mesurer la satisfaction de l'utilisateur, ce fameux M. Toutlemonde. Quelle est la bonne approche ?
Si on vise à fournir une information à ce brave monsieur, le problème semble simple : il faut mesurer la QoE car c'est la seule qui l'intéresse. M. Toutlemonde ne veut probablement pas connaître la latence (RFC 7679 et RFC 2681), la capacité (RFC 5136) ou le taux de perte de paquets (RFC 7680). Ce qu'il veut, prétendent les gens qui parlent pour lui (M. Toutlemonde n'est jamais présent aux réunions mais on le cite tout le temps), c'est télécharger des films ou de la musique le plus vite possible. Certes, les métriques citées plus haut ont une influence nette sur sa QoE mais elle est indirecte et peu compréhensible.
Donc, cela semble réglé, la QoE est la seule chose qui importe. Seuls des barbus pas lavés comprennent quelque chose aux métriques techniques du RFC 2330 et il ne faut donc pas exposer ce pauvre M. Toutlemonde à des notions techniques. Mais, en fait, c'est plus compliqué que cela.
D'abord, la QoE a la particularité de se mesurer de bout en
bout. On l'a dit, ce qui intéresse M. Toutlemonde, c'est « je clique
pour voir un film, combien de temps attendre avant de le voir ». La QoE ne peut pas
donc se mesurer de manière objective sans avoir accès à l'ordinateur de
l'utilisateur, puisqu'elle dépend de toute la chaîne. Ainsi, si le PC
Windows de M. Toutlemonde est farci de
virus et que cela le ralentit, la QoE est moins
bonne, quelle que soit la capacité de la fibre optique. Cela réduit fortement l'applicabilité de la
QoE. Même dans un monde de Minitels où l'opérateur contrôlerait le
terminal de l'utilisateur, il faudrait encore tenir compte des
performances du serveur (si on regarde france.fr
le jour de son inauguration, ça va très lentement, quels que soient
les efforts des FAI pour fournir un bon
réseau). On ne sait donc plus très bien qui est responsable des
mauvaises performances.
Ensuite, la mesure de la QoE suppose la définition d'une activité typique (j'ai entendu des vagues propositions du genre « le surf sur les cent sites Web les plus populaires »). Cette définition est une mauvaise idée dans son principe. Contrairement à la téléphonie, où le réseau était conçu pour une application, et où il était donc facile de mesurer la qualité du réseau (avec des techniques comme PESQ), l'Internet sert à beaucoup de choses différentes. Un échantillon d'activités serait arbitraire : pourquoi les gens qui font du jeu en ligne ou de la messagerie instantanée, qui ont surtout besoin d'une faible latence, accepteraient-ils l'échantillon soi-disant représentatif des téléchargeurs, qui ont surtout besoin de capacité ?
Pire, cette idée d'« activité typique » empêcherait toute comparaison temporelle, puisque l'échantillon d'activités changerait d'une année sur l'autre, au gré des modes.
Enfin, l'échantillon typique a un énorme défaut si on veut l'utiliser pour des mesures qui seront publiées, genre « le classement des meilleurs FAI » : il encourage les opérateurs à optimiser leur réseau uniquement pour ce qui est mesuré. Si on intègre Facebook (très à la mode où moment où j'écris cet article) dans l'échantillon, tous les FAI feront des efforts pour avoir une bonne connectivité avec Facebook et oublieront le reste.
Dernier problème avec la QoE, l'absence de normalisation. Autant les métriques techniques sont rigoureusement définies (par le groupe de travail IPPM de l'IETF ou bien, si on y tient, par le SG-12 de l'UIT, qui produit des documents comme la Recommandation Y.1540, « Internet protocol data communication service - IP packet transfer and availability performance parameters »), autant les mesures de QoE sont souvent d'une grande subjectivité, définies de manière floue, et jamais discutées collectivement (contrairement aux normes comme les RFC cités plus haut). La plupart ne dépassent pas le niveau « ce soir, ça rame !!! » des forums de discussion bas de gamme. C'est évidemment plus compréhensible que « la latence unidirectionnelle est de 132 milli-secondes pour des paquets de Type-P TCP-80 » mais la technique doit être rigoureuse, avant d'être attirante.
Pour que des mesures massives et objectives soient possibles, il faut donc se concentrer sur des métriques techniques, reflétant le fonctionnement du réseau, comme celles indiquées plus haut. On peut toujours ajouter ensuite des mesures « de plus haut niveau », plus proches du ressenti de l'utilisateur, mais cela ne peut être qu'une fois qu'on dispose de mesures solides proches du réseau.
Un autre débat dans le même groupe ARCEP est discuté dans « Où doit-on mesurer la capacité réseau, chez le FAI ou plus loin ? ».
La consultation publique lancée par l'ARCEP fin 2011 utilise un vocabulaire différent en parlant de mesures techniques pour la QoS et de mesures orientées vers les usages pour la QoE.
L'article seul
RFC 6241: Network Configuration Protocol (NETCONF)
Date de publication du RFC : Juin 2011
Auteur(s) du RFC : R. Enns (Juniper Networks), M. Bjorklund (Tail-f Systems), J. Schoenwaelder (Jacobs University), A. Bierman (Brocade)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF netconf
Première rédaction de cet article le 1 juillet 2011
Netconf est un protocole de configuration de matériel réseau (typiquement des routeurs ou des commutateurs). Ce RFC est la nouvelle version publiée par le groupe de travail IETF sur Netconf. (La precédente était le RFC 4741.)
Si on doit gérer un seul routeur, le faire à la main est raisonnable. Mais, si on doit en gérer des dizaines ou des centaines, cela devient impossible sans automatisation. Il existe depuis longtemps de nombreux outils pour gérer un grand nombre d'équipements réseaux, Rancid étant le plus connu. (L'excellent article de Joe Abley, Managing IP Networks with Free Software en donne un bon aperçu. Le RFC 3535 rend compte d'un atelier de l'IAB qui a discuté de ces questions en 2002.) Netconf vise à rendre l'écriture de ces outils plus simple.
Netconf spécifie donc un protocole de RPC permettant à un gérant (manager) de modifier la configuration de l'équipement (device) en lui envoyant du XML.
Le contenu exact de ce document XML n'est pas entièrement spécifié par Netconf car il dépend de l'équipement configuré (la section 1.2 de notre RFC explique ce point). Un langage de description des modèles, Yang (RFC 6020), existe pour décrire les possibilités.
Extrait du RFC, voici un exemple (hypothétique) où on fixe à 1500
octets la
MTU de l'interface réseau
eth0 :
<rpc message-id="101"
xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<edit-config>
<target>
<running/>
</target>
<config>
<top xmlns="http://example.com/schema/1.2/config">
<interface>
<name>eth0</name>
<mtu>1500</mtu>
</interface>
</top>
</config>
</edit-config>
</rpc>
Il est difficile de ne pas penser à l'acronyme NIH en lisant ce RFC. Netconf définit un protocole de RPC alors qu'il existe déjà SOAP et XML-RPC, Netconf définit en section 6, un mécanisme d'extraction de sous-arbres XML alors que XPath existe déjà...
Quels sont les changements depuis le RFC
original ? L'annexe F les résume. Pas de grand changement, des bogues
signalées contre le RFC 4741 et quelques
ajouts : un malformed-message ajouté aux messages
d'erreur possibles, une option remove ajoutée aux
opérations possibles, l'ajout de la notion de « nom d'utilisateur »,
le schéma XSD de modélisation des opérations remplacé par un module
YANG, etc.
À noter qu'un Wiki, http://trac.tools.ietf.org/wg/netconf/trac/wiki, fournit plein
d'informations sur Netconf, notamment sur les mises en œuvre
existantes du protocole, dont certaines en logiciel libre. Parmi les
autres, les routeurs Juniper peuvent déjà être
configurés avec Netconf (et une bibliothèque
Java est fournie). Ça marche aussi sur
un Cisco.
L'article seul
RFC 6302: Logging recommendations for Internet facing servers
Date de publication du RFC : Juin 2011
Auteur(s) du RFC : A. Durand (Juniper Networks), I. Gashinsky (Yahoo! Inc.), D. Lee (Facebook), S. Sheppard (ATT Labs)
Réalisé dans le cadre du groupe de travail IETF intarea
Première rédaction de cet article le 1 juillet 2011
Ce court RFC prend position clairement en faveur d'un enregistrement, par les serveurs Internet, du numéro de port source du client, en plus de l'adresse IP. Cette recommandation est là pour tenir compte de la pratique de plus en plus répandue du partage d'adresses IP, notamment en raison de la pénurie des adresses IPv4.
En effet, depuis l'épuisement de ces adresses v4 début 2011, le partage d'adresses IP entre machines, par exemple via un routeur NAT, est de plus en plus fréquent. Or, de nombreux serveurs enregistrent dans un journal les adresses IP de leurs clients. Voici un exemple avec Apache :
2001:db8:1:4::1972 - - [29/Jun/2011:12:11:27 +0200] "GET /racine-dns-28-juin-2011.html HTTP/1.1" 200 9392 "-" "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.100 Safari/534.30" www.bortzmeyer.org
et un avec Postfix :
Jun 29 12:04:30 aetius postfix/smtpd[29360]: connect from foo.bar.example[198.51.100.79]
(Les adresses ont été changées.)
Noter les adresses IP seules n'a guère de sens puisque ces adresses n'identifient plus une machine unique. Le RFC recommande donc que le port source soit également noté. Le processus de discussion qui a mené à ce RFC avait commencé au moins deux ans avant, à la réunion d'Hiroshima.
Évidemment, la meilleure solution au partage d'adresses serait le déploiement d'IPv6. Mais comme il va prendre des années, il faut bien gérer la situation existante. Cela implique des solutions comme le NAT44 (le NAT traditionnel, cf. RFC 3022 et mon article sur les différentes formes de NAT), le NAT64 (RFC 6146) ou bien DS-Lite (RFC 6333). Ce partage d'adresses pose des tas de problèmes (documentés dans le RFC 6269) mais celui qui nous intéresse ici est le problème de l'enregistrement de l'adresse du client.
Prenons un NAT44 classique. Le client a une adresse privée (RFC 1918), mettons
192.168.42.1 et utilise le port source 52645. Il passe à travers un routeur NAT
et ressort avec l'adresse publique
203.0.113.68 et le port source 61921. Le routeur
a mémorisé l'association entre les deux tuples, interne
{192.168.42.1, 52645} et externe
{203.0.113.68, 61921}. Le serveur auquel se
connecte ce client ne verra que le tuple externe. Si le serveur
enregistre uniquement l'adresse 203.0.113.68, il
ne pourra pas distinguer les requêtes faites par la machine
192.168.42.1 de celles faites par les autres
machines situées derrière le même routeur NAT. Ce n'est pas forcément
très grave pour du NAT fait à la maison (après tout,
l'HADOPI coupera tout le monde, papa, maman et
petit frère, si la fille
aînée a téléchargé illégalement) mais c'est bien plus gênant pour du
CGN, technique récente où plusieurs abonnés
sans lien entre eux partagent une adresse IP.
Solution ? Que le serveur enregistre également le port source (ici, 61921). C'est désormais une recommandation officielle de l'IETF (voilà pourquoi ce document se nomme également « BCP 162 » pour Best Common Practices). Cette information, jointe à celle contenue dans le routeur NAT, permettra de retrouver le client original.
Notez le point mis en évidence : tout ceci n'a un sens que si le routeur NAT enregistre aussi les correspondances entre tuples {adresse, port} interne et externe. Le RFC prend soin de préciser que ses recommandations ne s'appliquent qu'aux serveurs, pas aux routeurs NAT qui, en pratique, à l'heure actuelle, n'enregistrent pas cette information (cf. section 3 sur ce point).
La recommandation exacte du RFC figure en section 2. Je la reprends ici :
- Si (et c'est un gros si) le serveur enregistre l'adresse IP de ses clients, il doit aussi noter le port source,
- Ainsi qu'une heure précise à la seconde près, et en utilisant une horloge qui soit synchronisée, par exemple via NTP (RFC 5905), et de préférence en UTC,
- Et des informations comme le protocole de transport utilisé, au cas où le serveur en accepte plusieurs (les correspondances dans le routeur NAT dépendent en général du protocole de transport).
Vous avez bien noté que le RFC ne prend pas position sur la question de savoir si un serveur devrait enregistrer l'adresse IP de ses clients (note au passage : il existe des serveurs qui n'enregistrent pas cette adresse, justement pour éviter de « fliquer » leurs propres clients ; cela leur évite également la responsabilité d'un fichier sensible, puisque contenant des données à peu près nominatives). Il dit juste que, si le serveur le fait, il devrait également noter le port source et l'heure. Enregistrer l'adresse IP seule ne sert pas à grand'chose (sauf, je suppose, si le but est justement de ne pas garder de données trop nominatives. Au passage, un peu de publicité pour le service No Log.)
De la même façon, le RFC évite prudemment les questions de rétention des données (lesquelles, pour combien de temps). Chaque administrateur système doit consulter la loi locale (en France, la LCEN, loi liberticide qui contient des obligations très rigoureuses à ce sujet).
Enregistrer l'heure précise est nécessaire car le serveur ne sait évidemment pas à quel rythme sont réutilisés les numéros de port par le routeur NAT.
Voyons maintenant la mise en œuvre concrète de ces recommandations, avec les deux logiciels cités plus haut. Postfix a cette possibilité depuis assez longtemps (malgré les moqueries assez bêtes de son auteur au début) :
smtpd_client_port_logging = yes
Cela donne :
Jun 29 12:04:39 aetius postfix/smtpd[30055]: connect from foo.bar.example[198.51.100.79]:48525
Par contre, son concurrent sendmail ne semble pas avoir cette capacité (il
faudrait peut-être modifier le source, en
sendmail/srvrsmtp.c ou bien utiliser un
milter smfi_connect, peut-être avec la macro ${client_port}.) Et je n'ai pas d'informations sur d'autres serveurs comme exim.
Pour Apache, cela se fait en ajoutant un
%{remote}p dans le
LogFormat :
LogFormat "%h %{remote}p %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\" %v" combined
ce qui donnerait :
2001:db8:1:4::1972 42425 - - [29/Jun/2011:12:11:27 +0200] "GET /racine-dns-28-juin-2011.html HTTP/1.1" 200 9392 "-" "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.100 Safari/534.30" www.bortzmeyer.org
(Le 42425 en deuxième champ.) Attention, si on analyse ses fichiers avec un programme de statistique comme analog, il faut changer également sa configuration, pour qu'il ne soit pas surpris par le champ supplémentaire.
J'ai montré un exemple avec une adresse IPv6. C'est sans doute inutile pour ce protocole (pas de traduction d'adresse/port en IPv6) mais c'est plus simple de mettre la même configuration pour les deux. Le paragraphe suivant présente un exemple où IPv4 et IPv6 sont traités différemment.
Si on veut faire plus joli, et écrire les adresses dans le style habituel des tuples {adresse, port} (adresse, deux-points, port dans le cas d'IPv4 et avec des crochets dans le cas d'IPv6, cf. RFC 3986), c'est plus compliqué. La solution que j'utilise (merci à @bitonio et @siddartha) passe par la définition d'une variable puis son utilisation dans la définition du format. (Une autre solution, due à @Grunt_, aurait été d'avoir un virtual host pour IPv4 et un pour IPv6.) Cela se configure ainsi :
LogFormat "[%h]:%{remote}p %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\" %v" combinedv6
LogFormat "%h:%{remote}p %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\" %v" combinedv4
SetEnvIf Remote_Addr : remote-v6
CustomLog /var/log/apache2/access.log combinedv6 env=remote-v6
CustomLog /var/log/apache2/access.log combinedv4 env=!remote-v6
Pour reconnaître une adresse IPv6, je cherche simplement la présence d'un deux-points. Si on veut faire mieux, il existe de jolies expressions rationnelles pour tester les familles d'adresses. Quoi qu'il en soit, le résultat est :
[2001:db8:1:4::1972]:42425 - - [29/Jun/2011:12:11:27 +0200] "GET /racine-dns-28-juin-2011.html HTTP/1.1" 200 9392 "-" "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.100 Safari/534.30" www.bortzmeyer.org 192.0.2.202:53124 - - [01/Jul/2011:08:29:15 +0200] "GET /6269.html HTTP/1.1" 200 37392 "-" "Netvibes (http://www.netvibes.com)" www.bortzmeyer.org
Là aussi, il faut penser aux programmes d'analyse, dont la plupart ne sont pas capables de traiter des cas où le format varie d'une ligne à l'autre. La première solution, moins jolie, était peut-être plus raisonnable.
L'article seul
RFC 6296: IPv6-to-IPv6 Network Prefix Translation
Date de publication du RFC : Juin 2011
Auteur(s) du RFC : M. Wasserman (Painless Security), F. Baker (Cisco Systems)
Expérimental
Première rédaction de cet article le 30 juin 2011
Avec ce RFC, encore expérimental, IPv6 gagne la possibilité de faire de la traduction d'adresses, c'est-à-dire d'avoir dans un réseau local des adresses internes, qui seront dynamiquement traduites en adresses externes par le routeur de sortie, qui pourra également faire l'opération inverse (de l'extérieur vers l'intérieur).
Cette traduction est souvent nommée NAT (Network Address Translation) mais ce terme n'est pas correct : la traduction habituelle en IPv4, celle que tout le monde doit supporter pour sa connexion Internet à la maison et pour son accès 3G, NAT44, ne traduit pas uniquement l'adresse. Pour faire face à la pénurie d'adresses IPv4, elle met en correspondance plusieurs adresses internes (typiquement du RFC 1918), avec une adresse externe, en utilisant les numéros de port pour démultiplexer les paquets entrants. Cette technique devrait donc s'appeler NAPT (Network Address and Port Translation) et pas NAT. Elle a des tas d'inconvénients, décrits dans le RFC 6269.
En IPv6 au contraire, sujet de notre RFC, il n'y a pas de pénurie d'adresses et pas de raison de faire du NAPT. Le protocole de traduction proposé dans ce RFC 6296 mériterait donc, lui, de s'appeler NAT (ou peut-être NAT66), mais, comme ce terme est désormais très galvaudé, ses auteurs ont plutôt choisi NPT pour Network Prefix Translation. NPTv6 permet une correspondance univoque (1:1) entre les adresses internes et les adresses externes, évitant ainsi le partage d'adresses dont le RFC 6269 décrit les défauts. Pour diverses raisons (cf. RFC 2993 et section 5 de notre RFC), l'IETF n'encourage pas les systèmes de traduction mais, si un utilisateur tient à en faire, ce RFC lui fournit un protocole bien étudié. Il n'évite pas tous les problèmes de la traduction (RFC 4864, RFC 5902) mais les limite.
N'utilisant pas les ports, NPTv6 fonctionne donc avec tous les protocoles de transport, contrairement au NAT44 traditionnel (cf. section 6). Il est sans état (chaque paquet est traduit indépendemment des autres) donc le routeur qui fait la traduction n'a pas de problèmes comme le remplissage de la table (fréquent avec NAT44). Ainsi, un réseau peut être servi par deux traducteurs (par exemple pour la redondance) sans qu'ils aient à partager un état. Mais ce caractère sans état a aussi d'autres conséquences :
- NPT est juste une technique de traduction, il ne fournit pas de filtrage, ce n'est pas un pare-feu (les routeurs NAT44 mélangent les deux fonctions de traducteur et de pare-feu avec état), si on veut un pare-feu, il faut donc le faire en plus (cf. RFC 6092),
- il permet le maintien du principe de la connexion de bout en bout, y compris pour les connexions « entrantes », mais, comme toute technique de traduction, NPT a des problèmes avec les applications qui incluent les adresses IP dans les données,
- même problème avec les services qui incluent l'adresse IP dans le calcul d'un MAC comme l'option d'authentification de TCP (RFC 5925).
Voilà pour un résumé très rapide des propriétés de NPT v6.
Mais pour quelles raisons peut-on avoir envie de déployer un système de traduction ? La section 1.1 de notre RFC propose de les résumer en un principe : indépendance vis-à-vis de l'adresse. Ce principe comprend plusieurs propriétés :
- Les adresses internes au réseau local étant distinctes de celles du réseau extérieur, aucune nécessité de renuméroter si on change de FAI (RFC 5887).
- Le site peut choisir son opérateur, sa connexion, ses opérateurs multiples, même (multi-homing sans BGP),
- Pas besoin d'obtenir des adresses PI pour avoir des adresses à soi,
- Et pour le FAI, pas besoin de BCP 38 (RFC 2827), les adresses annoncées étant traduites en ses adresses.
« Adresses internes + traduction » est donc potentiellement un « PI du pauvre ». En IPv4, beaucoup de sites utilisaient le NAT pour atteindre cette indépendance, même lorsqu'elles pouvaient obtenir suffisamment d'adresses IP. Le RFC 4864 décrit d'ailleurs un concept proche nommé « autonomie du réseau ».
NPTv6 est donc un mécanisme qui permet de réaliser cette indépendance du réseau. Meilleur que le NAT44 (pas de manipulation des ports, fonctionne donc avec tous les protocoles de transport, comme SCTP, permet les connexions entrantes, purement « algorithmique » donc sans état), il peut donc être un ajout intéressant à la boîte à outils de l'administrateur de réseaux IPv6.
Pour être tout à fait complet, il faut aussi rappeler ses inconvénients (RFC 2993) :
- Comme il modifie l'en-tête IP, il est incompatible avec les techniques de sécurisation de cet en-tête comme l'AH d'IPsec (RFC 4302),
- Comme toute traduction d'adresses, il ne marche pas avec les protocoles qui transmettent des adresses IP dans les données comme SIP ; ceux-ci auront besoin d'un ALG,
- La configuration du DNS va être pénible car il faudra prévoir une vue externe et une interne (split DNS).
Bref, NPTv6 n'est pas une solution parfaite et c'est pour cela que ce RFC reste au statut Expérimental.
Si on décide de poursuivre cette voie, il faut choisir les adresses à utiliser en interne. Les ULA du RFC 4193 semblent la solution idéale, maximisant l'indépendance.
Voici pour les grands principes. Quelques détails pratiques
maintenant. Prenons l'exemple simple de la section 2.1 : un réseau
interne, utilisant un préfixe ULA,
fd01:203:405:/48, est connecté à l'Internet via
un unique FAI, et un routeur qui fait du NPTv6. Le préfixe
PA alloué par le FAI et routable publiquement
est 2001:0db8:1:/48 (notez que NPT n'impose pas
que les deux préfixes aient la même longueur, cf. section 3.7). Lorsqu'un paquet « sort »
(va du réseau local vers l'Internet), l'adresse IP source est
remplacée par une adresse IP prise dans le préfixe du FAI. Les autres
champs de l'en-tête IP ne sont pas modifiés. En sens inverse,
lorsqu'un paquet « entre » (vient de l'Internet vers le réseau local),
c'est l'adresse de destination qui est touchée, pour être remplacée
par une adresse du réseau local.
La partie identifiant la machine sur le réseau local (80 bits dans
cet exemple) n'est en général pas conservée telle quelle. Ainsi, si fd01:203:405:1::1234 écrit à
2a00:1450:8007::13, Gmail, le
destinataire, verra le paquet venant de
2001:0db8:1:d550::1234
En effet, la traduction est neutre pour la somme de contrôle. Si on suit l'algorithme standard du RFC 1071, on veut obtenir la même somme de contrôle avant et après traduction. Les protocoles qui utilisent une somme calculée sur une partie de l'en-tête IP (c'est le cas de TCP) ne seront donc pas affectés. Astuce amusante, pour atteindre cet objectif de neutralité, 16 bits de l'adresse sont réservés pour pouvoir y faire les modifications qui annuleront les autres changements faits dans l'adresse. L'algorithme exact de calcul est dans les sections 3.1 et suivantes. Une mise en œuvre en C figure en annexe B. À noter qu'elle ne prétend pas être optimale, faisant par exemple les calculs de somme de contrôle avec du code portable et pas de l'assembleur adapté à une machine particulière.
On peut avoir des cas plus compliqués que ce simple réseau, par exemple du multi-homing, où le réseau local est connecté à deux FAI (section 2.4). Chacun de ces deux FAI alloue un préfixe PA différent. Les liens avec les deux FAI passent par deux routeurs NPT différents, tous les deux configurés avec le même préfixe interne mais différents préfixes externes. Une machine du réseau local ne pourra pas savoir sous quelle adresse elle apparaitra à l'extérieur, sauf à utiliser une technique comme STUN (RFC 8489). La décision de sortir par un FAI ou l'autre peut être prise comme on veut. Par contre, par rapport à du vrai multi-homing, avec adresses PI et BGP, un changement de FAI de sortie entraîne un changement de l'adresse IP vue par l'extérieur et coupe donc toutes les sessions en cours.
Continuons avec les considérations de déploiement et de configuration (section 4). Le plus probable est que NPTv6 sera mis en œuvre dans les routeurs, comme dans l'exemple ci-dessus, et, pour les particuliers et petites organisations dans le CPE. Les obligations du RFC 7084 s'appliquent donc à l'engin qui fait la traduction.
Cela implique entre autres que le traducteur NPT soit capable de faire des virages en épingle à cheveux (renvoyer vers le réseau local un paquet qui était à destination du réseau local, cf. RFC 4787), afin que des machines du réseau local puissent se parler en utilisant leurs adresses publiques. Comme NPT ne tripote pas les ports, la plupart des autres exigences des RFC du groupe BEHAVE ne s'appliquent pas à lui.
Et pour les applications, quelles sont les conséquences (section 5) ? Plusieurs des problèmes classiques de la traduction, qui avaient déjà été décrits dans le RFC 2993 sont toujours présents. Les applications ne verront pas les mêmes adresses, selon qu'elles sont situées d'un côté ou de l'autre du traducteur. Par exemple, si un ordinateur portable se déplace de part et d'autre du traducteur, il verra ses connexions s'interrompre, son adresse IP ayant changé. Mais les problèmes les plus fréquents et les plus sérieux seront pour les protocoles applicatifs qui utilisent des références, c'est-à-dire qui indiquent dans les données à quelle adresse IP envoyer les paquets. Les cas les plus connus sont FTP et SIP. Si un client SIP envoie à un autre son adresse interne, pour recevoir un flux RTP, cette adresse ne sera pas traduite, et le flux ne joindra pas la destination. Que peut-on faire pour limiter les dégâts ?
- Comme avec le NAT44, les applications peuvent utiliser STUN pour apprendre leur adresse,
- Dans le futur, un mécanisme de référence général, résistant aux traductions, sera peut-être développé.
Et la sécurité du NPTv6 ? La section 7 résume les points importants. Le principal est que, contrairement au NAT classique, avec état, NPT n'empêche pas les connexions entrantes. C'est une bonne chose mais cela peut dérouter certains administrateurs réseaux qui croyaient que la traduction les protégeait de l'extérieur. Ce n'est pas le cas avec NPTv6 et si on veut une telle protection, il faut installer un pare-feu explicite (alors que le NAT traditionnel mélange les deux rôles de traduction et de protection), comme décrit dans le RFC 6092.
Curieusement, cette idée de traduction d'adresses sans état, selon une cardinalité 1:1, est très ancienne. Si notre RFC 6296 semble être le premier RFC à la décrire, elle avait été à la base du projet GSE, auquel l'annexe A rend hommage. GSE, décrit dans le draft draft-ietf-ipngwg-gseaddr, était un des projets qui avaient été élaborés pour le successeur d'IPv4. Contrairement au projet retenu (le futur IPv6) qui conservait les concepts de base de son prédécesseur, GSE repensait nettement le problème de l'adressage dans l'Internet. Celui-ci était divisé en deux, les réseaux de transit et les réseaux de bordure. Dans GSE, seuls les réseaux de transit avaient des adresses publiques et annoncées dans la table de routage globale. Les réseaux de bordure avaient des adresses stables et uniques mais qui n'étaient pas routées. Les adresses étaient traduites lors du passage du réseau de bordure au réseau de transit et réciproquement. Le but était surtout de limiter la croissance de la table de routage (problème qu'IPv6 avait finalement décidé de ne pas traiter). En décembre 2010, sur l'Internet, il y a 36 000 systèmes autonomes dont 15 000 n'annoncent qu'un seul préfixe (et sont donc probablement des réseaux de bordure). Seuls 5 000 systèmes autonomes apparaissent dans des chemins (en dehors de l'origine) et sont donc des réseaux de transit.
Et les implémentations publiquement disponibles ? (Merci à François Romieu et Samuel Thibault pour leurs informations.) Il y a map66 et aussi nfnat66 (NAT66 pour Netfilter), qui utilise netfilter et est présenté en français dans l'exposé de Guy Leduc et plus en détail dans la thèse de Terry Moës, « IPv6 address translation in a Linux kernel ». Ne m'en demandez pas plus, je n'ai pas testé. (À noter qu'il en existe aussi pour des techniques de traduction IPv6<->IPv6 différentes, par exemple avec état.)
Mais c'est une autre mise en œuvre qui a été intégrée dans le
noyau Linux en août 2012 (commit
8a91bb0c304b0853f8c59b1b48c7822c52362cba) et qui a donc été livrée avec la sortie de la version
3.7 en décembre 2012. Regardez les fichiers en
net/ipv6/netfilter comme ip6table_nat.c.
L'article seul
Attaque contre les serveurs DNS de la racine - juin 2011
Première rédaction de cet article le 29 juin 2011
Dernière mise à jour le 8 juillet 2011
Les attaques dDoS contre les serveurs DNS de la racine ne sont pas quotidiennes mais ne sont pas non plus des évenements exceptionnels. Le mardi 28 juin, une nouvelle attaque a eu lieu.
L'article complet
RFC 6297: A Survey of Lower-than-Best-Effort Transport Protocols
Date de publication du RFC : Juin 2011
Auteur(s) du RFC : M. Welzl (University of Oslo), D. Ros (Institut Télécom / Télécom Bretagne)
Pour information
Réalisé dans le cadre du groupe de travail IETF ledbat
Première rédaction de cet article le 29 juin 2011
Aujourd'hui, de nombreuses applications se battent pour accéder à une ressource critique, la capacité du réseau. Tout le monde veut télécharger plus vite et les applications tentent d'obtenir le meilleur débit possible pour recevoir le dernier épisode de Dr House ou bien la page de ses amis sur Facebook. Pourtant, il existe une catégorie d'applications plus philosophes, qui cherchent à être le moins dérangeantes possibles et à ne transférer des octets que lorsqu'absolument personne d'autre n'a besoin du réseau. Ce RFC examine les techniques utilisées par ces applications tranquilles.
Il existe bien des cas où il n'y a pas d'urgence à transférer des données. Des mises à jour quotidiennes de gros fichiers ou bases de données non critiques, le transport des nouvelles Usenet (cf. RFC 5537), du téléchargement qu'on laisse tourner tout le temps, par exemple. Ces transferts, même s'ils n'ont pas besoin d'être « temps-réel » rentrent actuellement en compétition avec les transferts pressés. Si on télécharge tranquillement, sans être pressé, un gros film, et qu'on a un besoin urgent d'un fichier pendant ce temps, le fichier n'aura, pendant son transfert, que la moitié de la capacité, l'autre étant prise par le film. Il serait donc intéressant d'avoir des applications gentilles, modestes, qui cèdent systématiquement la place aux applications normales, dès que le réseau est encombré. L'IETF a un groupe de travail pour ce sujet du trafic « d'arrière-plan », dit aussi « moins que au mieux » (le trafic normal dans l'Internet étant acheminé « au mieux » - best effort). Ce groupe se nomme LEDBAT (Low Extra Delay Background Transport), et voici son premier RFC, qui étudie les techniques existantes pour atteindre cet objectif.
On pourrait même imaginer des tarifs intéressants ou des conditions d'accès au réseau plus favorables pour ces applications. Après tout, l'essentiel des coûts d'un réseau sont fixes : une fois la fibre posée et allumée, une fois les routeurs et commutateurs installés et configurés, le coût d'exploitation est le même que des bits passent ou pas. Ce qui coûte cher, en exploitation, c'est la congestion, lorsque la capacité du réseau est trop faible, que le service commence à se dégrader, et que les clients réclament une mise à jour de l'infrastructure, qui ne sera pas gratuite. Par contre, si le réseau est inutilisé à certains moments, y faire passer nos transferts de données gentils ne coûte rien. Dans tous les cas, tarifs intéressants ou pas, avoir des applications modestes aideraient certains services gourmands (comme le transfert de fichiers en pair-à-pair) à se faire accepter : on n'hésitera plus à laisser tourner BitTorrent en permanence si on est sûr qu'il cédera toujours aux applications habituelles.
La référence pour le trafic normal est TCP, le protocole de transport qu'utilisent quasiment tous les transferts de données et qui fait au mieux pour utiliser toute la capacité du réseau, ou pour la partager équitablement si elle est insuffisante (RFC 5681). Notre RFC vise donc le trafic « moins que TCP » tel que, s'il y a compétition entre trafic normal et notre trafic d'arrière-plan, le trafic normal ait la part du lion.
Le trafic d'arrière-plan est nommé dans ce RFC LBE pour less than best-effort. Un système LBE doit donc réagir à la congestion plus vite que TCP, pour abaisser son débit. Il y a quatre catégories de systèmes LBE :
- Ceux qui agissent uniquement au niveau de l'application, et utilisent donc un TCP normal. C'est plus difficile à faire que ça n'en a l'air, car, si on applique strictement le modèle en couches, les applications n'ont pas connaissance de la congestion. Mais ce sont aussi les plus faciles à déployer, puisqu'on a juste à installer une nouvelle application.
- Ceux qui s'appuient sur un protocole de transport modifié. Il en existe deux catégories, ceux qui se basent sur les délais d'acheminement des paquets (et non sur le taux de pertes, comme le fait TCP), et les autres. Ces protocoles de transport peuvent éventuellement réutiliser une partie de TCP (par exemple son format d'en-tête), facilitant ainsi leur déploiement. (Plusieurs des exemples se nomment « TCP quelque chose » pour cette raison. Wikipédia a une bonne page sur les variantes de TCP.)
- Ceux qui s'appuient sur le réseau. Ce sont évidemment les plus durs à déployer, car ils nécessitent que tous les routeurs du trajet soient modifiés.
Les sections suivantes fournissent divers exemples (je ne les reprends pas tous ici) de chaque catégorie.
Les solutions dans les applications font l'objet de la section 4. A
priori, on pourrait croire que les solutions de
shaping comme l'option
--bwlimit de rsync
atteignent notre objectif de « trafic d'arrière-plan », ne rentrant
jamais en compétition avec TCP. Mais ce n'est pas le cas. Les
solutions de shaping sont :
- trop modestes lorsque le tuyau est inutilisé. Si je transfère
avec
rsync --bwlimit 64, le débit ne dépassera jamais 64 ko/s. - trop gourmandes si le tuyau est encombré. rsync essaiera d'avoir ses 64 ko/s dans tous les cas.
Bref, ces options ne sont pas réellement LBE (voir Crovella, M. et P. Barford, « The network effects of prefetching », Proceedings of IEEE INFOCOM 1998, pour une meilleure description d'une solution de limitation de débit) .
De même, essayer de faire tourner les applications LBE aux heures creuses ne convient pas à toutes les applications (par exemple le transfert de fichiers en pair-à-pair). Autre solution, le BITS de Windows, qui surveille en permanence le débit pour ralentir ces transferts de fichiers en arrière-plan si le débit devient trop important. (Le RFC ne fournit pas d'éléments d'évaluation précis de ce service.)
Comment réaliser une application modeste ? Une première possibilité (section 4.1) est d'agir sur la fenêtre de réception, sur la machine destinataire. Le récepteur diminue la fenêtre TCP, par exemple lorsque le délai d'acheminement des paquets augmente (sur Unix, cela doit être mis en œuvre dans le noyau, je ne crois pas que l'application ait accès à cette fenêtre, mais cela ne nécessite pas de modifier le protocole TCP, c'est juste un changement unilatéral de comportement). C'est par exemple ce qui est fait en Spring, N., Chesire, M., Berryman, M., Sahasranaman, V., Anderson, T., et B. Bershad, « Receiver based management of low bandwidth access links ».
Dans les deux catégories de nouveaux protocoles de transport, voyons d'abord ceux fondés sur le délai d'acheminement. Le principe est de mesurer le temps que mettent les paquets à faire le trajet. Si cette durée augmente, c'est sans doute parce que le réseau est encombré et que donc la congestion approche. On diminue donc le débit (TCP, lui, attend bien plus, que les paquets soient effectivement jetés). La section 2 cite comme exemple TCP Vegas, un des premiers à pouvoir partager un lien avec TCP en étant systématiquement moins gourmand que lui, même si, curieusement, ce n'était pas son but initial. TCP Vegas permet au contraire souvent un meilleur débit, lorsqu'il est seul. Cela illustre le fait que ce n'est pas en diminuant le débit (cf. la discussion sur rsync) qu'on atteint l'objectif de modestie.
TCP Vegas est toujours la référence dans ce domaine. Mais, depuis, il existe des améliorations comme TCP Nice (voir Venkataramani, A., Kokku, R., et M. Dahlin, « TCP Nice: a mechanism for background transfers », qui reprennent le même principe de diminuer le débit lorsque le RTT diminue (sans attendre que les pertes de paquets commencent). À noter que TCP Nice a une mise en œuvre dans Linux (citée dans l'article ci-dessus).
Autre cas de protocole fondé sur le délai, TCP-LP, qui utilise le délai en aller simple et pas le RTT comme les deux précédents. C'est normalement un meilleur indicateur (on n'est pas perturbé par le trafic de retour, qui peut n'avoir rien à voir puisque le chemin de retour peut être différent, et/ou moins congestionné) mais il est plus difficile à mesurer (TCP-LP utilise l'option d'estampillage temporel des paquets de TCP, cf. RFC 7323).
Tous ces schémas ont un défaut commun : les études (par exemple McCullagh, G. et D. Leith, « Delay-based congestion control: Sampling and correlation issues revisited ») montrent que le délai d'acheminement n'a qu'un faible rapport avec l'approche de la congestion. Le délai varie souvent pour des raisons qui n'ont rien à voir avec l'encombrement (les tampons devraient être bien plus grands pour mesurer ce délai sans ce bruit ; les liens radio vont varier le délai quel que soit l'encombrement ; etc). En outre, les horloges des machines sont souvent insuffisantes pour mesurer le délai avec une bonne précision, surtout sur un réseau local où les paquets voyagent vite et où l'essentiel du délai est dû au traitement dans les machines, pas au réseau. Enfin, certaines techniques d'optimisation de TCP faussent encore plus cette mesure.
En pratique, ces problèmes peuvent mener à réduire le débit sans raison. Ces « faux positifs » atteignent quand même l'objectif (être moins gourmand que TCP) mais les problèmes de mesure peuvent aussi mener à des faux négatifs, où le protocole de transport ne détecte pas une congestion bien réelle.
Enfin, tout protocole fondé sur le délai d'acheminement donne un avantage aux derniers arrivants : sur un tuyau déjà très encombré, le flot récent voit des délais importants dès le début et ne se rend donc pas compte de la congestion.
Il existe aussi des protocoles de transport LBE (modestes) n'utilisant pas le délai d'acheminement (section 3). Ils jouent sur le rythme d'envoi (qui dépend de la réception des accusés de réception) pour, par exemple, diminuer la fenêtre d'envoi plus vite que TCP. C'est le cas de 4CP ou de MulTFRC (une extension du TFRC du RFC 5348).
Enfin, il y a les solutions qui utilisent une assistance du réseau (section 5). Sur le papier, ce sont les plus efficaces (pas besoin de mesures indirectes, comme celle du délai d'acheminement, le routeur sait parfaitement si le réseau est encombré ou pas) mais aussi les plus dures à déployer car elles nécessitent une modification de tous les routeurs.
Un exemple d'une telle technique est NF-TCP (Arumaithurai, M., Fu, X., et K. Ramakrishnan, « NF-TCP: A Network Friendly TCP Variant for Background Delay- Insensitive Applications ») qui combine ECN (RFC 3168) et RED (RFC 7567) pour diminuer la priorité des flots NF-TCP dans les routeurs dès que la congestion menace.
Armé de la connaissance de toutes ces techniques (on voit que l'imagination des chercheurs et ingénieurs a été intense sur ce sujet), que va faire le groupe de travail LEDBAT ? La section 6 explique que LEDBAT a déjà un système, décrit un l'Internet-Draft, fondé sur le délai d'acheminement » (ceux de la section 2). Ce n'est pas à proprement parler un protocole mais un algorithme, qui pourra être utilisé dans les protocoles concrets. Il a depuis été publié dans le RFC 6817.
L'article seul
RFC 6269: Issues with IP Address Sharing
Date de publication du RFC : Juin 2011
Auteur(s) du RFC : M. Ford (Internet Society), M. Boucadair (France Telecom), A. Durand (Juniper Networks), P. Levis (France Telecom), P. Roberts (Internet Society)
Pour information
Réalisé dans le cadre du groupe de travail IETF intarea
Première rédaction de cet article le 29 juin 2011
Pour pas mal de raisons, il est fréquent aujourd'hui qu'une adresse IP soit partagée entre plusieurs machines. Le cas le plus typique est celui des N machines d'une petite entreprise, forcées d'utiliser une seule adresse IP publique, via un routeur NAT. Ce RFC est le premier document qui discute en détail de ce partage d'adresses, et de ses innombrables inconvénients.
Le RFC met surtout l'accent (section 1) sur une cause du partage d'adresses : l'épuisement de la réserve d'adresses IPv4, qui, n'étant pas compensée par un déploiement massif d'IPv6, mène à ce que le partage d'adresses soit très fréquent, et le sera sans doute davantage dans le futur (la plupart des solutions d'attente d'IPv6 utilisent intensivement ce partage). En fait, aujourd'hui, il est rare que M. Michu puisse bénéficier d'une vraie connexion Internet : il partage en général son adresse avec d'autres M. Michu ; par exemple, à la maison, M. Michu n'a aucune chance d'obtenir plus d'une adresse IPv4, même si plusieurs personnes vivent dans ce foyer et utilisent toutes des appareils connectés à l'Internet (ce qui est banal aujourd'hui dans les grandes villes du Nord). Le CPE fait office de routeur NAT et les machines de M. Michu et de sa petite famille sont contraintes de se contenter d'adresses IP privées (RFC 1918). Mais l'avenir (déjà réalisé en Europe sur les connexions ultra-civilisées de la 3G, et, en Asie, dès à présent sur toutes les connexions) nous réserve pire : le partage d'adresses IP, non pas au sein du foyer ou de la petite entreprise, mais entre abonnés, ce qu'on nomme parfois le CGN, pour Carrier-Grade NAT et qu'on pourrait qualifier de « partage d'adresses généralisé ». (L'annexe A résume les différents types de partage d'adresses.) Le « facteur multiplicatif » (annexe B) entre le nombre d'adresses privées et celui d'adresses publiques vaut typiquement entre 3 et 10 pour une maison européenne typique (une seule adresse publique mais plusieurs machines connectées, smartphones, ordinateurs, consoles de jeu, etc). Il pourrait dépasser 1000 avec les CGN (plusieurs adresses IP publiques mais des milliers d'abonnés se partageant ce mince gâteau).
Le RFC insiste sur le fait que le déploiement d'IPv6 est la seule solution correcte aux problèmes engendrés par le partage d'adresses. C'est vrai mais il faut noter que le partage d'adresses a commencé bien avant la famine, qu'il est pratiqué par des entreprises qui disposent de suffisamment d'adresses IPv4 (en général au nom de pseudo-arguments de « sécurité ») et qu'on le trouve pratiqué massivement en Afrique et en Asie alors que le continent africain est celui qui a la plus grande réserve d'adresses IPv4 officielles disponibles. Donc, le non-déploiement d'IPv6 n'est pas la seule raison de l'utilisation du partage d'adresses.
J'ai mentionné le NAT tout à l'heure. Si le partage d'adresses se fait en général (mais pas toujours) via le NAT, l'inverse n'est pas forcément vrai. On peut avoir du NAT sans partage d'adresses, si chaque adresse interne est mise en correspondance avec une et une seule adresse externe. Évidemment, en IPv4, c'est rare, vu le manque d'adresses, mais cela sera peut-être plus fréquent avec IPv6.
À noter que ce RFC ne discute que du problème : il ne propose pas de solution, celles-ci étant renvoyées à des documents ultérieurs (qui ne seront peut-être pas nécessaire si le déploiement d'IPv6 rend inutile ces solutions). Il ne se penche pas non plus sur les problèmes qui sont spécifiques à une technique utilisant le partage d'adresses, essayant au contraire de voir les questions communes à toutes ces techniques. Ainsi, qu'on utilise, pour gérer le passé en attendant le déploiement d'IPv6, NAT64, DS-Lite ou encore d'autres importe peu : toutes ont en commun les même défauts liés au partage d'adresses.
Des problèmes, notamment de sécurité, liés au partage d'adresses avaient déjà été discutés dans les RFC sur le NAT comme les RFC 2663 et RFC 2993 (section 2 de notre RFC). Mais le partage généralisé, entre utilisateurs n'ayant rien en commun, va aggraver ces problèmes. Cette situation se rencontre souvent aujourd'hui en Asie, et dans les hotspots WiFi publics. Mais elle sera hélas sans doute demain le lot de beaucoup d'utilisateurs.
Bien, arrivé à ce stade, vous avez le droit de penser que j'ai beaucoup répété qu'il y avait des problèmes, sans dire lesquels. Patientez encore un peu. L'analyse des problèmes qui commence en section 3 est faite en cherchant d'abord si le problème affecte l'organisation qui déploie le partage d'adresses (et donc ses abonnés ou employés), ou bien des tiers (comme la police par exemple ou bien comme un CDN qui essaie de distribuer du contenu en fonction de l'adresse). Le tout est stocké dans un grand tableau synthétique (figure n° 1) et détaillé dans les sections suivantes. Pour ne prendre que trois exemples de ce tableau, le fait que les requêtes DNS traduisant une adresse en nom perdent de leur signification affecte aussi bien l'utilisateur que les tiers (ceux qui traduisent une adresse IP entrante en nom). Par contre, la perte de traçabilité qui résulte du partage (si on détecte un comportement illégal lié à une adresse IP, on ne retrouve plus facilement la machine en cause) n'affecte que les tiers (les organisations répressives comme la HADOPI). Au contraire, la perte de fiabilité de la connexion (car l'engin qui fait les traductions d'adresses est un nouveau composant dans la connexion, qui peut avoir des bogues ou des pannes, cf. section 18) ne concerne que l'utilisateur, les tiers ne seront pas touchés.
Les sections suivantes du RFC détaillent successivement chacun de
ces problèmes (je ne les présente pas dans l'ordre, j'essaie de mettre
les plus importantes en premier). La section 5 s'attaque aux problèmes liés à
l'allocation de port. Avec le partage
d'adresses, plusieurs adresses « internes » sont mises en
correspondance avec une seule adresse « externe ». Comment, dans ces
conditions, différencier les paquets IP qui arrivent, à destination de
cette adresse IP externe ? On utilise le numéro de port
TCP ou UDP pour cela et
c'est donc le couple {adresse, port} qui identifie la machine et non
plus l'adresse seule. Ce
numéro de port n'étant stocké que sur 16 bits, cela met une limite stricte à
l'ampleur du partage. Si 500 machines partagent une adresse (facteur
multiplicatif de 500), cela ne
fait qu'un peu plus de 131 ports chacune (et même moins car certains
doivent être réservés, cf. RFC 4787), ce qui est vite épuisé sur une machine un tant
soit peu active, qui ouvre de nombreuses connexions (une seule page
Web peut se traduire par l'ouverture de dizaines de connexions). D'autant plus que
ce n'est pas le nombre de connexions actives qui compte, mais celui
des connexions TCP dans l'état TIME-WAIT, celui
dans lequel les connexions fermées restent pendant quatre minutes
(RFC 1337).
Voyons les ports « sortants », ceux alloués pour les connexions initiées de l'intérieur (section 5.1). Les études (Alcock, S., « Research into the Viability of Service-Provider NAT ») semblent indiquer que la distribution de la consommation est très inégale : une minorité d'utilisateurs consomme beaucoup de ports. Cela encourage à répartir les numéros de port à partir d'un pool central, et pas à attribuer de manière fixe des plages de ports à chaque client (cf. annexe A). Mais la seconde solution serait bien plus simple et moins coûteuse. Et la première est vulnérable à une attaque DoS : une seule machine infectée par du malware et qui ouvre des connexions le plus vite possible peut épuiser le pool. Ceci dit, l'allocation statique de plages de ports a aussi ses risques (cf. RFC 6056). Tous ces problèmes existaient avec le partage limité à un foyer ou une entreprise mais sont évidemment plus graves en cas de partage généralisé puisqu'un utilisateur peut être bloqué par un autre utilisateur qu'il ne connait pas.
Et pour les ports des connexions entrantes (section 5.2) ? L'étude
citée ci-dessus montre qu'elles sont fréquentes (la majorité des
utilisateurs) mais consomment moins de ports. Comment négocier entre
la machine de l'utilisateur et le routeur NAT l'allocation d'un port
« entrant » ? Aujourd'hui, les méthodes les plus courantes sont
l'allocation manuelle (la plupart des CPE
permettent de configurer des ports entrants, du genre « toute
connexion arrivant pour le port 80 de l'adresse publique doit être traduite vers
192.168.1.13:8080 ») ou bien un protocole comme
UPnP. Le CGN complique
sérieusement les choses puisqu'il n'est pas dédié à un utilisateur et
qu'on doit donc sérieusement étudier sa sécurité avant de permettre à
un utilisateur de se réserver les ports 22 ou 80 ! C'est encore pire
si le CPE et le CGN doivent coopérer pour rendre le service, puisqu'il
n'existe aucun protocole standard pour cela. Actuellement, sur
l'abonnement 3G typique en Europe, on n'a pas
accès à l'allocation de ports entrants et le
smartphone ne peut donc pas
héberger de serveur. Cet engin bien plus puissant que les
ordinateurs des débuts de l'Internet est donc limité à un rôle de
Minitel plus perfectionné.
Il existe des solutions potentielles à ces problèmes mais aucune n'est vraiment satisfaisante. À titre d'exemple, le RFC cite les enregistrements SRV qui pourraient permettre de faire savoir que tel service réside sur tel port de la machine coincée derrière le partage d'adresses. Parmi les limites de cette solution, notons qu'elle ne s'applique pas au protocole le plus demandé, HTTP, qui n'utilise pas les SRV...
Jusqu'à présent, j'ai surtout parlé du problème des applications « serveur », celles qui écoutent des connexions inattendues sur un port bien connu, un serveur SSH, par exemple. On peut se dire que de tel cas sont rares sur la machine de M. Michu, qui n'installe en général pas de serveur SSH, ni même HTTP. Mais il y a toute une catégorie d'applications qui a besoin d'écouter des connexions entrantes sans être pour autant un « serveur » à proprement parler. La section 6 est une bonne occasion de les mentionner. En effet, cette section examine tous les cas où le partage d'adresses gène les applications. Cela concerne bien sûr les serveurs traditionnels, vus en section 5.2, mais aussi, entre autres :
- Les applications qui indiquent des adresses et des ports dans leur trafic, ce qui concerne typiquement FTP et SIP. Un ALG sera nécessaire pour les gérer.
- Les applications qui n'utilisent pas du tout de port (ping...) et pour qui il faut donc trouver d'autres moyens de démultiplexage. Une section entière, la 9, détaille les problèmes posés à ICMP, puisque ce protocole n'a pas de notion de port. Outre ping, ce protocole est utilisé, par exemple par les applications pair-à-pair pour mesurer la « distance » avec un pair, ce qui ne marche plus dans le cas d'un partage généralisé.
- Un cas analogue est celui des applications qui n'utilisent pas TCP ou UDP, mais, par exemple, SCTP ou encore le protocole 41 (encapsulation IPv6 dans IPv4, pour gérer le cas des réseaux qui n'ont toujours pas IPv6). Très rares sont les techniques de partage d'adresses qui gèrent d'autres protocoles que TCP et UDP. Ces techniques contribuent donc à l'ossification de l'Internet (la grande difficulté à déployer de nouveaux protocoles).
- Les applications qui tiennent pour acquise l'unicité des adresses IP (voir aussi le RFC 6250). Par exemple, une application Web qui lie les cookies à une adresse IP, pour augmenter la sécurité, n'a pas de sens si cette adresse est partagée entre des dizaines d'utilisateurs qui ne se font pas forcément confiance.
Résultat, les applications passent aujourd'hui beaucoup de temps à mettre en œuvre des techniques de contournement, cherchant à récupérer leur connectivité que le NAT contrarie. Il suffit de regarder le code source de n'importe quelle application de téléphonie sur l'Internet pour voir le résultat : le code est plus complexe, et dépend de systèmes difficiles comme ICE (RFC 8445). Avis personnel : il est donc faux de dire que le NAT fait faire des économies. Le NAT est un déplacement de coûts, depuis les administrateurs réseaux vers les développeurs d'applications, contraints à des prodiges d'astuces pour assurer la connectivité.
Un des principaux problèmes que pose fondamentalement le partage
d'adresses est la traçabilité (notez que ce n'est pas un problème pour
tout le monde). Il est fréquent de suivre les actions d'une machine et
de son propriétaire via l'adresse IP. 192.0.2.66
s'est connecté à
www.anonymous.org. 203.0.113.13
a envoyé du
spam. 198.51.100.254 a
participé à une attaque DoS. Évidemment, si les
adresses IP sont partagées, cette traçabilité n'existe
plus. Aujourd'hui, avec le NAT local classique, on peut au moins
relier une adresse IP à un foyer ou une entreprise. Avec du partage
d'adresses généralisé, cela ne sera plus le cas (section
12). Actuellement, une requête de la police auprès d'un
FAI pour obtenir l'identité d'un abonné dont la
machine s'est fait repérer inclus l'adresse IP et l'heure (pour les
cas d'adresses IP dynamiques, changeant régulièrement). Le partage
généralisé oblige à inclure d'autres informations dans la requête,
comme le numéro de
port, que peu de serveurs enregistrent aujourd'hui. Attention, identifier un abonné à partir du couple
{adresse IP, port} est délicat, car la table de correspondance change
bien plus vite que les baux DHCP typiques. La
requête doit donc inclure une heure très précise et, pour cela,
s'appuyer sur une horloge bien synchronisée. Comme cela risque de ne
pas suffire (et cette solution implique que le serveur enregistre le
numéro de port source, ce qui est inhabituel aujourd'hui), faudra t-il
que le routeur NAT enregistre également l'adresse IP de destination ?
Cela étendrait le domaine du flicage très loin...
Et le FAI doit garder des
journaux de taille colossale pour pouvoir
répondre aux questions comme « Qui utilisait le couple
{198.51.100.254, 23152} le 23 mai à 11:28:05 ? »,
les obligations légales de surveillance imposant en général de
conserver ces données pendant six à douze mois.
Cela ne sera probablement pas réaliste pour tous les FAI, sauf à créer
des obligations légales qui acculeraient bien des opérateurs à la
faillite. Noter l'adresse IP de destination aggraverait évidemment le
problème.
Comment cela va t-il se passer alors ? Une solution est de baisser les bras et de ne pas divulguer l'identité de l'abonné. Cela peut poser des problèmes légaux au FAI, des lois comme la LCEN en France leur faisant obligation de surveiller leurs abonnés, comme un hôtelier des vieux films policiers surveillait les entrées et sorties de ses clients. Une autre solution est de divulguer les coordonnées de tous les abonnés qui avaient une session active à ce moment là et de laisser la police trier. On imagine le nombre d'innocents qui seront alors harcelés.
À noter que la situation décrite par cette section 12 ne sera pas forcément perçue comme un problème par tout le monde. Ainsi, certains utilisateurs pourraient trouver des avantages à un système qui rend plus compliquée la tâche des surveillants. Si, à cause du partage d'adresses, une société privée de surveillance comme TMG, qui collecte les adresses IP de partageurs de fichiers, a des problèmes, tant mieux, se diront-ils. Le partage d'adresses pourrait alors fournir, sinon l'anonymat, au moins un certain brouillage de pistes. Ce n'est pas faux mais c'est à mettre en rapport avec les inconvénients de ce partage d'adresses.
Le partage d'adresses perturbe une mesure importante pour le bon
fonctionnement de l'Internet, celle de la MTU
du chemin (section 10). Bien des systèmes mesurent cette MTU du chemin
(RFC 1191) pour optimiser le transfert de données. Mais cette
PMTU est en général stockée par adresse IP et
le partage généralisé peut donc fausser les mesures : deux machines
derrière la même adresse IP peuvent ne pas avoir la même PMTU. Cela
peut permettre des attaques par déni de service où une des machines
derrière l'adresse publique générerait des paquets ICMP
packet too big (type 3 et code 4 d'ICMP)
indiquant une taille ridiculement basse... qui sera utilisée pour tous
les malheureux situés derrière la même adresse.
Il y a d'autres questions de sécurité liées au partage d'adresses. La section 13 les expose successivement. Par exemple, bien des mesures de sécurité sont prises sur la base de l'adresse IP. Un exemple est le logiciel fail2ban qui met automatiquement en liste noire (et donc filtre) les adresses IP qui sont à l'origine de comportements agressifs (comme des connexions SSH répétées). Si cette adresse IP est partagée, des innocents vont aussi se voir bloquer l'accès. Même chose pour les listes noires des expéditeurs de spam.
Des problèmes peuvent également survenir avec des logiciels qui estiment qu'une adresse IP identifie une machine (section 14). Un des exemples est l'optimisation TCP du RFC 2140, qui consiste à partager l'information entre toutes les connexions TCP vers la même machine. Cette optimisation ne fonctionnera plus si la même adresse IP sert à des machines connectées de manière très différente (avec le NAT résidentiel d'aujourd'hui, ce n'est pas trop un problème car toutes les machines de la même maison ont à peu près la même connectivité).
Autre conséquence négative du partage d'adresses : la géolocalisation (section 7). Les adresses IP sont souvent utilisées pour donner une idée (fort imparfaite) de la localisation d'une machine. C'est un système très contestable, déjà aujourd'hui, comme le note le RFC. Mais le partage généralisé d'adresses le rendra encore moins utile, puisque c'est l'adresse du routeur CGN qui sera vue par le serveur, et qu'elle peut n'avoir qu'un très lointain rapport avec le client. Bon, personnellement, je trouve qu'on en arrive à un fort niveau de pinaillage ici : les problèmes posés par le partage d'adresses sont assez graves pour qu'on ne charge pas la barque en mentionnant des conséquences négatives sur un système qui était déjà mal fichu, comme la géolocalisation. Même remarque pour la section 8, qui fait remarquer que le partage généralisé empêchera de compter le nombre d'utilisateurs uniques en comptant le nombre d'adresses IP - ce qui est déjà largement le cas, ou la 11 qui note que le fait d'utiliser le numéro de port pour démultiplexer les paquets arrivant dans le routeur NAT pose un problème avec la fragmentation, puisque seul le premier fragment contient le numéro de port.
L'article seul
RFC 6293: Requirements for Internet-Draft Tracking by the IETF Community in the Datatracker
Date de publication du RFC : Juin 2011
Auteur(s) du RFC : P. Hoffman (VPN Consortium)
Pour information
Réalisé dans le cadre du groupe de travail IETF genarea
Première rédaction de cet article le 24 juin 2011
Dernière mise à jour le 6 juillet 2012
Une des particularités de l'IETF est son extrême ouverture. Tout le monde peut suivre le travail en cours, les documents de travail (les Internet Drafts) sont publiquement accessibles, l'état de chaque document dans le processus de publication peut être suivi sur le Web. Bref, sans avoir à se ruiner en déplacements physiques, le participant à l'IETF a accès à tout ce qu'il faut. Mais ce système a aussi ses insuffisances, notamment parce qu'il ne permet pas d'accès personnalisé et que seuls certains participants ont un accès en écriture. Ce RFC est donc le cahier des charges d'un nouveau système de suivi des Internet Drafts, système qui a finalement été déployé début juillet 2012.
Le système de suivi du travail de l'IETF repose sur un
ensemble d'outils non-officiels maintenus par des volontaires, http://tools.ietf.org/, et par un site officiel de suivi, le
« Datatracker » (http://datatracker.ietf.org/. Le
Datatracker permet de s'identifier, pour certaines
actions, mais cette possibilité n'était pas ouverte aux participants
ordinaires, seulement à ceux chargés d'une tâche comme le pilotage
d'un groupe de travail. (Notez que « participant IETF » = « public »
puisque l'IETF n'a pas d'adhesion formelle, tout le monde en est
membre dès qu'il participe, cf. section 1.3.)
Le Datatracker donne accès à plein
d'informations sur les documents en cours (la section 1 résume les possibilités de l'actuel Datatracker). Prenons l'exemple de
l'Internet Draft que demandait
l'ICANN sur la syntaxe des noms de
TLD,
draft-liman-tld-names. On peut connaître son état
en visitant http://datatracker.ietf.org/doc/draft-liman-tld-names/ : au 23
juin 2011, la version actuelle est la n° 5, datant du 12 avril, et il est en état I-D Exists, qui est
l'état normal de tout Internet Draft. Il n'est donc
pas en vue d'une publication comme RFC, juste
en discussion. Si on veut suivre les évolutions du document, nul
besoin de tout relire (comme c'est le cas dans d'autres organisations,
où les diff ne sont pas fournies lors de la
sortie d'un nouveau document), le Datatracker est
serviable. Voici les différences entre les versions 4 et 5 : http://tools.ietf.org/rfcdiff?url1=draft-liman-tld-names-04&difftype=--html&submit=Go!&url2=draft-liman-tld-names-05
(dans ce cas précis, elles étaient purement administratives).
Si je
m'intéresse plutôt au document sur le protocole de résolution de noms
d'Apple appelé (bien à tort) Multicast
DNS, je trouve l'information en http://datatracker.ietf.org/doc/draft-cheshire-dnsext-multicastdns/. Le
document (actuellement en version 14) est approuvé par
l'IESG mais a besoin d'une nouvelle
version. Les opinions des membres de l'IESG sont accessibles en http://datatracker.ietf.org/doc/draft-cheshire-dnsext-multicastdns/ballot/
(Discuss signifiant une objection.).
Ce niveau de transparence est bien au delà de ce que font les autres SDO comme l'UIT ou l'AFNOR où tout le travail est fait derrière des portes closes, pour éviter que le public n'y participe. Mais on peut encore faire mieux.
Par exemple (section 1.1), on pourrait imaginer qu'un utilisateur veuille s'identifier pour retrouver les informations sur la liste des Internet Drafts qu'il suit, liste déterminée manuellement ou via une recherche. Il peut aussi vouloir recevoir une notification si une nouvelle version d'un de ces documents apparait.
La section 2 décrit plus précisement les exigences du nouveau Datatracker :
- Possibilité de se créer un compte automatiquement (et pas manuellement sur demande, comme aujourd'hui, ce qui n'est pas très 2.0), et ses propres listes de documents à suivre,
- Possibilité de modifier l'affichage dans le Datatracker (par exemple l'ordre de présentation des documents, la liste des attributs affichés, etc),
- Gestion de grandes listes (des dizaines de documents suivis),
- Définition des listes par des attributs comme « Tous les Internet Drafts du groupe de travail XXX », « Tous ls Internet Drafts écrits par Machin », « Tous les Internet Drafts qui citent le RFC yyyy », etc,
- Publication sous forme de flux Atom, notification par courrier, peut-être demain notification des changements via XMPP.
D'autres idées, dont la mise en œuvre n'est pas requise pour la première phase, figurent dans les annexes A et B. Par exemple, suivi des changements dans les registres IANA (ça, cela me serait très utile).
Le cahier des charges est donc fini, il ne restait plus que le développement et le déploiement, qui a été finalisé le 3 juillet 2012. Tout le monde peut désormais en bénéficier.
L'article seul
RFC 6272: Internet Protocols for the Smart Grid
Date de publication du RFC : Juin 2011
Auteur(s) du RFC : F. Baker, D. Meyer (Cisco Systems)
Pour information
Première rédaction de cet article le 22 juin 2011
Le titre de ce RFC ne rend pas complèment compte de son but. Ce document est en fait une présentation complète de la suite de protocoles TCP/IP, celle qui fait tourner l'Internet. Conçu pour des ingénieurs qui viennent d'une autre culture que celle des barbus Unix, récapitulant tout ce qu'il faut savoir sur les protocoles de la famille, ce texte est utilisable comme base d'un cours, ou comme introduction à TCP/IP. Il a été conçu pour le projet Smart Grid.
En effet, ce projet de distribution de l'électricité en faisant appel à des équipements plus proches des ordinateurs que des traditionnels transformateurs et compteurs, équipements qui communiqueraient beaucoup entre eux, cherche une architecture réseau. Un certain nombre de consultants, souvent ignorants de ce qui s'est fait depuis trente ans sur l'Internet, prône le développement en partant de zéro de nouvelles techniques, non prouvées et coûteuses à créer, alors que TCP/IP fournit déjà tout ce qu'il faut. Ce RFC explique TCP/IP pour les débutants, et fournit une liste des protocoles, dont peut être tirée un futur profil Smart Grid (un profil étant un sous-ensemble adapté à une tâche donnée). Voir la section 1 à ce sujet.
Comme je ne connais pas assez Smart Grid, et que le RFC ne contient quasiment rien de spécifique à ce projet (l'annexe A rassemble les informations purement Smart Grid), je vais adopter une autre perspective en utilisant ce RFC comme moyen de présenter les protocoles d'Internet, à un ingénieur qui ne les connaîtrait pas. Ces protocoles sont désignés dans le RFC sous le nom d'IPS, Internet Protocol Suite. À partir d'ici, si vous connaissez déjà l'IPS, vous avez le droit de partir et d'aller voir un film (par exemple Le chat du rabbin) ou de lire un livre (par exemple Le chat du rabbin).
L'IPS est décrite dans les fameux RFC. Outre la normalisation des protocoles, certains RFC sont là pour décrire l'implémentation par exemple les RFC 1122 et RFC 1123 sur les machines terminales et le RFC 1812 sur les routeurs. (Avec une version des spécificités IPv6 dans le RFC 8504.) Une des particularités de l'IPS est qu'elle offre des choix : ainsi, il existe plusieurs protocoles de transport comme TCP (RFC 793) ou SCTP (RFC 9260) et même un « non-protocole », UDP (RFC 768), où l'application doit faire tout le travail de la couche 4. La section 2 de ce RFC va présenter l'architecture de l'IPS, la section 3 une liste de protocoles et la section 4 l'organisation non-technique de l'Internet (relations d'affaires, etc).
Donc, c'est parti, comment tous ces protocoles tiennent-ils ensemble ? L'Internet Protocol Suite suit la classique organisation en couches (section 2.1). Si le principe est celui du modèle OSI, le découpage des couches n'est pas forcément le même, ni la terminologie. Ainsi, l'OSI parle (en anglais) de end system lorsque l'IPS dit host (que je traduis par machine terminale) et l'OSI dit intermediate system où l'IPS dit router.
En partant du haut, de ce qui est le plus proche des utilisateurs, on trouve la couche Applications (section 2.1.1). L'IPS ne fait pas de distinction forte entre les couches 5, 6 et 7, considérant plutôt une seule couche Applications.
Ensuite, toujours en allant vers le bas, l'IPS a une couche de Transport (section 2.1.2). Le terme de transport est très galvaudé. Énormément d'ingénieurs l'utilisent pour dire « les couches du dessous qui ne m'intéressent pas ». Un concepteur d'un réseau optique va parler du transport pour la fibre sous-jacente, alors que le développeur d'une application Web va considérer que le protocole HTTP est le transport, pour son application. Mais dans l'IPS, « transport » a un sens bien précis, c'est la plus basse couche qui va de bout en bout. Des protocoles archi-connus comme TCP (RFC 793) ou très exotiques comme NORM (RFC 5740) mettent en œuvre ce transport. Comme plusieurs flots de données simultanés peuvent exister entre deux adresses IP, le démultiplexage se fait sur la base d'un numéro de port géré par la couche transport. Deux flots différentes auront ainsi des couples {port source, port destination} différents. Les différents protocoles de transport fournissent en outre des services tels que garantie de délivrance des données (ou pas), gestion de messages séparés (ou bien flot d'octets continu, ce que fait TCP), contrôle de la congestion.
Continuons à descendre vers les couches bases, la couche Réseau (section 2.1.3) vient ensuite. Au contraire du choix qui existe en couche Transport, il n'y a qu'un seul protocole de couche Réseau, IP (ou deux, si on considère IPv4 et IPv6 comme différents). IP fournit un service de datagrammes : chaque paquet est indépendant des autres, porte donc les adresses IP de source et de destination, et il n'y a pas besoin d'établir un circuit avant d'envoyer des données. IP fournit également un service de fragmentation, permettant de découper un paquet trop gros avant de le réassembler à la fin.
IP peut fonctionner sur d'innombrables protocoles de couche 2. L'IETF n'en normalise aucun (à l'exception possible de MPLS, RFC 4364, tout dépend comment on place ce protocole dans le modèle en couches). La plupart du temps, ces protocoles des couches basses (section 2.1.4) sont normalisés par l'IEEE : 802.3, 802.11, 802.16, etc. IP peut aussi tourner sur IP, via des tunnels comme GRE (RFC 2784).
La famille TCP/IP a souvent été critiquée pour son manque de sécurité (section 2.2). En fait, toute la sécurité dans l'Internet ne dépend pas de TCP/IP. Le hameçonnage, par exemple, est une question d'éducation et d'interface utilisateur, deux points très importants mais qui ne sont pas du ressort de l'IETF. D'autres problèmes (comme la faille BGP dite « attribut 99 ») ne relèvent pas non plus de la sécurité du protocole puisqu'ils sont causés par une bogue dans un programme mettant en œuvre le protocole.
D'autres questions de sécurité viennent de l'organisation de l'Internet, pas de ses protocoles. Ainsi, il n'existe pas de chef de l'Internet, qui pourrait ordonner que les vieilles versions des logiciels, versions ayant des bogues connues, soient immédiatement retirées du service. On constate qu'elles traînent souvent dans la nature. De même, les nouvelles techniques de sécurité ont souvent du mal à être déployées, puisqu'aucune autorité ne peut imposer leur emploi. Il faut au contraire convaincre chaque administrateur réseaux. (Des exemples de protocole de sécurité dont le déploiement a été faible sont SPF - RFC 4408 et IPsec - RFC 4301. Un exemple d'un protocole de sécurité qui a mis très longtemps à être déployé est DNSSEC - RFC 4033.)
Cela ne veut pas dire que l'IETF baisse les bras sur la sécurité. Chaque nouveau protocole doit inclure une analyse de sécurité, et le RFC 3552 guide les auteurs pour cette tâche.
Les problèmes de sécurité de la couche physique se traitent en général par des moyens physiques (enterrer et protéger les câbles, par exemple). Pour les autres couches, le problème est posé en termes de trois services : Confidentialité, Intégrité et Disponibilité. On souhaite que les conversations privées restent privées (Confidentialité), on souhaite que les données soient authentifiées au départ, puis arrivent sans modifications (Intégrité) et on souhaite que l'Internet marche (Disponibilité). Voici deux exemples :
- Une attaque classique contre TCP est d'envoyer des faux paquets RST (ReSeT), faux car utilisant une adresse IP source fabriquée, pour casser la connexion en cours. Il existe plusieurs protections, comme l'authentification TCP (RFC 5925), ou bien une sécurité au niveau en dessous comme IPsec. (Le RFC laisse entendre que TLS est une autre solution mais il ne protège pas du tout contre ces attaques.)
- Une autre attaque contre TCP est le SYN flooding où l'attaquant tente d'ouvrir suffisamment de connexions TCP pour épuiser les ressources de l'attaqué (la liste des connexions est typiquement de taille finie). Il existe aussi des protections comme les SYN cookies du RFC 4987.
- Dans les deux cas précédents, l'attaque portait sur la Disponibilité. Un exemple d'attaque contre la Confidentialité serait un accès non autorisé au réseau.
Dans beaucoup de cas, une première étape vers la sécurisation est la création d'un canal sûr entre la source et la destination (TLS ou IPsec le permettent.) Mais attention, ce n'est pas suffisant de sécuriser la communication, car le pair peut lui-même être malveillant, délibérement ou à son insu.
Enfin, l'infrastructure de l'Internet compte également des protocoles qui sont officiellement dans les applications mais sont en pratique nécessaires au bon fonctionnement. La section 2.3.1 mentionne le DNS, système de correspondance entre un nom de domaine et des données (typiquement des adresses IP). Bien sûr, l'Internet peut fonctionner sans le DNS. Mais, en pratique, cela serait vite insupportable (contrairement à ce qu'on lit parfois, la plupart des sites Web ne sont pas accessibles via leur adresse IP, voir section 5.4 du RFC 7230). Et la section 2.3.2 mentionne les outils de gestion de réseau comme les deux protocoles de gestion SNMP et Netconf (RFC 4741). (Dans le projet français PREMIO, SNMP est utilisé.)
La section 3 du RFC attaque ensuite les protocoles spécifiques. L'idée, là encore, est d'utiliser pour la Smart Grid des protocoles bien conçus, éprouvés, et disposant de mises en œuvre nombreuses et de qualité, souvent en logiciel libre.
Cette section commence avec la sécurité, La section 3.1 se penche d'abord sur l'AAA. Dans le contexte de l'Internet, cela concerne les protocoles qui autorisent l'accès au réseau, Radius (RFC 2865 et Diameter (RFC 6733). Ces protocoles utilisent souvent un mécanisme d'authentification nommé EAP (RFC 4017 ; opinion personnelle, EAP est d'une grande complexité), qui permet à son tour plusieurs méthodes (RFC 5216, RFC 5433).
Une fois qu'on a accès au réseau, reste à protéger les communications. Au niveau 3, une solution générale est IPsec (RFC 4301), qui « cryptographie » tout le trafic IP, fournit intégrité et authentification, aussi bien que confidentialité (IPsec est une architecture, pas un protocole, donc la liste des services peut dépendre du protocole). Pour l'échange des clés cryptographiques, cela peut se faire à la main (sans doute la technique la plus courante aujourd'hui) ou bien via le protocole IKE (RFC 5996). À noter que notre RFC 6272, bien que se voulant pratique, mentionne rarement de choix lorsque plusieurs protocoles existent. Toutefois, pour IPsec, il note que ESP (RFC 4303) est de très loin le plus utilisé et qu'on peut oublier les autres.
La sécurité peut-elle être assurée dans la couche 4 ? Oui, grâce au très connu protocole TLS (RFC 5246). TLS chiffre toute la communication de l'application. Il ne protège pas contre les attaques situées plus bas, mais est bien plus simple à déployer qu'IPsec.
Enfin, la sécurité peut être appliquée au niveau des applications, où on a le maximum de souplesse. La famille TCP/IP a plusieurs mécanismes dans sa boîte à outils pour cela :
- CMS (RFC 5652) est une syntaxe pour avoir des messages authentifiés et/ou confidentiels, en utilisant la cryptographie. Cette syntaxe peut ensuite être utilisée dans des applications comme les mises à jour de logiciels (RFC 4108) ou bien le courrier électronique (RFC 5751 sur S/MIME, à noter qu'il existe une syntaxe concurrent, celle d'OpenPGP, RFC 4880, non mentionnée par le RFC).
- Si on préfère le format XML, le RFC 3275 décrit un moyen de signer XML.
- L'authentification peut utiliser OAuth (RFC 5849).
Toujours dans la boîte à outils, la famille TCP/IP a aussi un protocole de connexion sécurisée à distance, SSH (RFC 4253), qui peut aussi servir de mécanisme pour faire des tunnels sûrs (en concurrent d'IPsec, donc).
Toute solution fondée sur la cryptographie a besoin d'un mécanisme de gestion des clés. L'IETF en a au moins deux, PKIX (RFC 5280), fondé sur X.509, et Kerberos (RFC 4120), le second étant plutôt limité au cas où tout les participants sont dans le même domaine administratif.
Après ces considérations sur la sécurité, place à la description des protocoles de couche 3. L'Internet en a actuellement deux, IPv4 et IPv6 (section 3.2). IPv4 est décrit en détail dans la section 3.2.2. Je passe rapidement, pour arriver à IPv6 en section 3.2.3. IPv6 est normalisé dans le RFC 2460. À noter que, pour le cas de la Smart Grid, dont certains équipements peuvent avoir des capacités et des connexions peu performantes, les RFC comme le RFC 4919 peuvent être également utiles.
Les adresses IPv6 sont décrites dans le RFC 4291. Elles peuvent être distribuées aux machines terminales via le protocole DHCP (RFC 8415) ou bien sans serveur par un système d'auto-configuration (RFC 4862). Deux machines IPv6 dans le même réseau se trouvent par le protocole NDP (RFC 4861).
Le routage des paquets IPv6 se fait d'abord par la distribution des informations entre routeurs, puis par l'utilisation de ces routes lors de la transmission de chaque paquet. La route la plus spécifique (le préfixe le plus long) est utilisée. Pour distribuer les routes, les routeurs peuvent utiliser divers protocoles comme OSPF (RFC 5340 et qui peut router IPv4 comme IPv6, grâce au RFC 5838) et BGP (RFC 2545). OSPF est utilisé à l'intérieur d'un domaine administratif et fait partie des protocoles « à état des liens » dont l'avantage est que chaque routeur a une vue complète du réseau (au lieu de router par « on-dits »). BGP est utilisé entre domaines administratifs et c'est donc lui qui lie les routeurs de l'Internet.
Il y a aussi des protocoles de routage spécifiques aux réseaux de capteurs, les équipements peu puissants dont je parlais plus haut. OSPF, où chaque routeur doit garder en mémoire tous les liens de tout le réseau, ne convient pas forcément pour cette tâche. Parmi les concurrents plus adaptés, on trouve par exemple AODV (RFC 3561) ou d'autres protocoles en cours de définition (voir le cahier des charges dans les RFC 5548, RFC 5673, RFC 5826 et RFC 5867).
Depuis l'épuisement des adresses IPv4, la migration vers IPv6 est nécessaire mais elle n'est pas instantanée et il faut donc gérer la coexistence entre les deux protocoles. Il existe plusieurs mécanismes pour cela mais tous ne sont pas recommandés (cf. RFC 6180). Le plus simple et le plus conseillé est la « double-pile » : le réseau et les machines ont à la fois IPv4 et IPv6, jusqu'à ce qu'on puisse éteindre la dernière adresse v4 (RFC 4213). Si on ne peut pas disposer d'une connectivité IPv6 native, l'approche recommandée est de tunneler le trafic v6 à travers l'Internet, par exemple par les techniques du RFC 5569. Enfin, si une des deux machines participant à la communication est purement v4 ou purement v6, il faut utiliser les techniques de traduction. Celles-ci recélant des pièges inattendus, le mieux est de préférer la traduction faite au niveau des applications (par des relais applicatifs). Sinon, l'IETF a normalisé un cadre général de traduction v4<-> v6 dans le RFC 6144, avec des déclinaisons dans des protocoles comme celui du RFC 6146.
Continuant à monter vers les couches hautes, la section 3.3 présente les protocoles de transport de l'IPS (Internet Protocol Suite). Le plus connu est TCP, responsable sans doute de la très grande majorité du trafic de l'Internet. TCP garantit aux applications qui l'utilisent la délivrance des octets, dans l'ordre et sans perte. Si le RFC qui le normalise date de trente ans, TCP a subi pas mal de travaux et de modifications et il vaut donc mieux commencer par lire le RFC 7414 pour tout savoir de ce protocole. Par exemple, pour la sécurité de TCP, le RFC 4987 est une bonne lecture.
Autre protocole de transport, UDP (RFC 768), un protocole minimal qui n'assure presque aucune fonction : l'application qui l'utilise doit tout prévoir, le contrôle de congestion (ne pas envoyer trop de paquets pour ne pas surcharger le réseau), la détection des pertes (et réessayer si nécessaire), etc. Le RFC 8085 guide les applications à ce sujet.
Il existe d'autres protocoles de transport qui n'ont guère eu de succès comme SCTP (RFC 9260) ou DCCP (RFC 4340), une sorte d'UDP avec contrôle de congestion.
Pour les protocoles d'infrastructure, la section 3.4 mentionne :
- Le DNS : des noms hiérarchiques
(
www.example.comest un sous-domaine deexample.com, lui-même sous-domaine de.com) et un protocole de résolution de noms en données (RFC 1034). Il existe un mécanisme de sécurisation, décrit par le RFC 4033. - DHCP (RFC 2131 en IPv4 et RFC 8415 en IPv6) permet d'attribuer des adresses IP (et de distribuer d'autres informations comme l'adresse du serveur de temps) aux différentes machines d'un réseau local depuis un point central. Il facilite donc beaucoup la vie de l'administrateur réseaux. Sans lui, lorsqu'on voudrait renuméroter les machines, il faudrait se connecter à chaque machine pour changer sa configuration. (Regardez comment on faisait en 1992.)
- Je viens de parler du serveur de temps. Le protocole NTP (RFC 5905) permet justement de mettre à l'heure les horloges de toutes les machines de l'Internet et s'assurer qu'elles soient d'accord. C'est une tâche plus compliquée qu'elle n'en a l'air.
Et la gestion de réseaux (section 3.5) ? Les deux protocoles concurrents sont SNMP (RFC 3411 et RFC 3418) et Netconf (RFC 4741). Lequel choisir ? Notre RFC 6272 ne fournit pas d'indications à ce sujet... La seule information de comparaison donnée est que SNMP utilise l'encodage ASN.1 alors que Netconf utilise XML.
Une machine qui démarre a souvent besoin d'informations sur son environnement, par exemple les coordonnées d'une imprimante ou bien d'un serveur de courrier. C'est le domaine des protocoles de découverte (section 3.6). C'est depuis longtemps une faiblesse de la famille TCP/IP. Le problème n'est pas complètement résolu de manière standard. Le RFC cite un protocole comme SLP (RFC 2608, qui n'a jamais été très utilisé) ou comme le protocole d'Apple, Bonjour. D'autres protocoles sont en cours de déploiement comme COAP (Constrained Application Protocol, RFC 7252), qui utilise HTTP pour demander à un serveur ces informations, en utilisant les adresses « bien connues » du RFC 8615.
Enfin, le RFC 6272 cite également (section 3.7) un certain nombre d'applications, qui ne font pas partie de l'IPS à proprement parler, mais qui peuvent être utiles à des déploiements sur TCP/IP. Par exemple, la famille TCP/IP a un protocole standard d'établissement de sessions multimédia, SIP (RFC 3261 et beaucoup d'autres). SIP est surtout utilisé pour la téléphonie sur IP mais a d'autres usages. SIP ne fait que la signalisation (appeler, raccrocher, etc) et la description de la session (voix, vidéo, codecs utilisés, est faite avec le format SDP (RFC 4566). En pratique, SIP a pas mal de problèmes sur l'Internet, face à la fermeture croissante du réseau par des mécanismes comme le NAT (le RFC 2993 décrit le problème et le RFC 5626 propose des solutions).
Autre application qui peut servir, XMPP (RFC 6120), un protocole d'échange de données XML en temps réel dont l'utilisation la plus connue est pour la messagerie instantanée (RFC 6121). XMPP est très riche et dispose de nombreuses extensions (par exemple pour du dialogue à plusieurs, dans des « pièces » virtuelles).
Après cette longue présentation des différents protocoles de la famille, le RFC expose l'architecture non-technique de l'Internet, c'est-à-dire son organisation sociale. Rien de nouveau pour les professionnels de l'Internet mais rappelez-vous que ce RFC est conçu pour des gens d'une culture très différente. La section 4 explique donc que l'Internet est un réseau de réseaux (c'est en cela que son ancêtre, l'Arpanet, était très différent : il était mono-réseau). Ces réseaux s'interconnectent entre eux (sinon, un abonné d'un réseau ne pourrait pas joindre un abonné d'un autre, ce qui était courant avec les technologies pré-Internet). Cette interconnexion est le cœur de l'architecture sociale de l'Internet dont le but est que tout le monde puisse parler à tout le monde (note personnelle au passage : cette interconnexion généralisée semble une banalité aujourd'hui. Mais, dans les années 1990, il était fréquent d'entendre des messieurs sérieux expliquer qu'il n'était pas nécessaire qu'une entreprise doive se connecter à d'autres que ses sous-traitants.)
On peut présenter les différents réseaux qui composent l'Internet en disant qu'il y a une différence entre les réseaux de transit et les autres. Les réseaux de transit forment le cœur de l'Internet. Leur seule activité est de connecter les autres réseaux. Ils vendent ce service aux réseaux d'accès et réseaux d'organisations. Les réseaux d'accès sont ceux du FAI typique, qui connecte M. Toutlemonde (particuliers et petites organisations) moyennant un paiement de trente € par mois. L'accès se fait via ADSL, RTC, 3G ou bien d'autres techniques. Les réseaux d'organisation sont ceux des entreprises, associations, collectivités locales ou universités, qui fournissent de l'accès à leurs employés et étudiants.
Si je fais de chez moi (abonné à Free) un traceroute vers ce blog, je passe successivement par le réseau d'accès du groupe Iliad (Free et Proxad), puis par le réseau de transit Cogent, puis j'arrive chez Datotel, le réseau d'entreprise où le serveur est hébergé :
% traceroute www.bortzmeyer.org traceroute to www.bortzmeyer.org (208.75.84.80), 30 hops max, 60 byte packets 1 freebox (192.168.2.254) 5.984 ms 7.027 ms 7.068 ms ... 4 cha75-6k-1-v906.intf.nra.proxad.net (78.254.255.197) 35.671 ms 35.726 ms 35.766 ms 5 bzn-crs16-1-be1502.intf.routers.proxad.net (212.27.58.65) 35.806 ms 37.060 ms 37.125 ms 6 bzn-6k-2-po57.intf.routers.proxad.net (212.27.59.217) 38.222 ms * * 7 th2-crs16-1-be1005.intf.routers.proxad.net (212.27.56.5) 39.893 ms 23.638 ms * 8 te4-8.330.ccr01.par04.atlas.cogentco.com (149.6.164.221) 44.829 ms 45.136 ms 49.465 ms 9 te0-1-0-4.mpd21.par01.atlas.cogentco.com (130.117.2.77) 55.562 ms 53.303 ms 54.986 ms ... 16 host46.datotel.com (208.82.151.46) 127.897 ms 127.465 ms 127.109 ms 17 stl-d2-g5-1.datotel.com (208.82.151.26) 128.295 ms 126.546 ms 127.575 ms 18 host125.datotel.com (208.75.82.125) 127.461 ms * * ...
(Les étoiles représentent des cas où un paquet a été perdu.) Notez que le routeur chez moi, la Freebox, avait une adresse privée (RFC 1918).
Le RFC ne parle pas des relations de peering entre réseaux. À ce sujet, un très intéressant document est le rapport de PCH.
À noter que le RFC n'expose que l'architecture sociale, pas la gouvernance de l'Internet, vaste sujet mais fort loin des problèmes opérationnels...
Souvent, les traceroutes sont interrompus subitement et plus rien n'est visible. C'est souvent le résultat d'un pare-feu mis sur le trajet. Notre RFC note que ces équipements sont très fréquents dans l'Internet d'aujourd'hui, mais aussi qu'ils sont très controversés. En effet, leur efficacité n'est pas prouvée, la plupart des attaques provenant de l'intérieur (soit parce qu'une personne située dans l'organisation mène l'attaque, soit parce qu'une machine interne a été infectée par un logiciel malveillant, le pare-feu ne protégeant souvent pas contre les attaques par « charge utile »). Bref, le pare-feu ne doit être utilisé que comme composante d'une solution de sécurité, pas comme l'alpha et l'oméga de la sécurité. Il existe plusieurs RFC ayant un rapport avec les pare-feux comme le RFC 2647 (mesures de performance), RFC 2979 (règles que doivent suivre les pare-feux), RFC 5207 (un exemple des problèmes que peuvent poser les pare-feux pour un nouveau protocole), etc.
Autre source de problèmes lorsqu'on circule dans l'Internet, les NAT. Cette technique a été inventée vers 1993 pour pallier le manque d'adresses IPv4 en traduisant des multiples adresses privées du réseau interne vers la seule adresse IP publique. En IPv6, le NAT est devenu inutile, vue l'abondance d'adresses. Mais comme certaines personnes s'imaginent que le NAT joue aussi un rôle pour la sécurité, en servant de pare-feu, il reste très présent et gêne souvent les communications. Les NAT sont décrits dans les RFC 2663 et RFC 3022, leurs conséquences néfastes pour les communications sont expliquées dans le RFC 3027, des idées pour les développeurs d'applications dans un monde où il y a beaucoup de NAT ont été rassemblées dans le RFC 3235, d'autres techniques de contournement sont dans le RFC 5128, quant à la position officielle de l'IAB sur les NAT, elle est dans le RFC 3424.
Sur le projet Smart Grid, si celui-ci n'a pas encore d'architecture réseau normalisée, il a déjà des documents. On peut consulter « Smart Grid Architecture Committee: Conceptual Model White Paper » (document uniquement en format privateur MS-Word, ce qui donne une idée de l'écart de culture avec l'Internet) et IEC 61850.
L'article seul
Inventer un meilleur système de nommage : pas si facile
Première rédaction de cet article le 19 juin 2011
Dernière mise à jour le 22 juin 2011
On voit apparaître en ce moment des tas de projets de faire un
système de nommage meilleur que l'actuel système utilisé dans
l'Internet, c'est-à-dire la combinaison de
noms de domaines
arborescents (comme munzer.bortzmeyer.org) et du
DNS pour la résolution de ces noms en autres
données, comme les adresses
IP. Comme je connais deux ou trois choses sur le DNS, on
me demande parfois mon avis sur ces projets. Il est souvent difficile
de les analyser car ils se donnent rarement la peine d'expliciter leur
cahier des charges : quel est le but exact ? Quel est le problème
qu'ils essaient de résoudre ? Ce n'est jamais dit. À la place, ces
projets se contentent en général de dire que le DNS est mauvais, sans
préciser en quoi. Il y a une bonne raison pour cette absence fréquente
de cahier des charges précis : on ne peut pas tout avoir à la fois. Le
système actuel optimise certains critères, un autre système pourrait
choisir d'en optimiser d'autres, mais aucun système ne pourrait être
parfait et tout optimiser à la fois. Comme on n'a pas de succès
médiatique en proposant un système qui est simplement meilleur sur
certains points et moins bon sur d'autres, la plupart des projets
choisissent de passer discrètement sous silence leur cahier des
charges.
Impossible de faire une liste complète de tous ces projets, et il en apparait de nouveaux régulièrement. Un des plus beaux exemples d'esbrouffe médiatique était le projet DNS-P2P qui n'a produit en tout et pour but qu'un seul message de 140 caractères et plus rien ensuite, mais qui a réussi à générer énormément de buzz. Parmi les projets plus récents, et peut-être plus sérieux, on trouve INS ou Namecoin.
Ces projets suivent en général le même cheminement : constatation de problèmes bien réels avec le système actuel (par exemple la censure par les autorités ou bien l'arrachage d'un nom de domaine à sa titulaire par les requins de l'appropriation intellectuelle), annonce spectaculaire d'un nouveau système rempli d'adjectifs (acentré, pair-à-pair, libre, décentralisé), compréhension, dès qu'on commence à réflechir cinq minutes, que le problème est plus compliqué qu'il n'en avait l'air sur Facebook, abandon. Pour essayer de limiter ce gâchis, j'ai fait cet article pour expliquer quelles sont les propriétés souhaitables d'un système de nommage et pourquoi il est difficile, voir impossible, de les concilier.
Voici une liste, que j'espère exhaustive, des propriétés qu'on souhaiterait avoir pour notre beau système de nommage :
- Identificateurs parlants. Tout le monde
préfère
www.rue89.comàBE25 EAD6 1B1D CFE9 B9C2 0CD1 4136 4797 97D6 D246. Pour certains, « identificateurs parlants » peut aussi amener à souhaiter des identificateurs structurés, permettant l'analyse (par exemple,rue89= domaine enregistré,com= TLD) et de reconnaître le fait qu'il y a un rapport entrefoo.example.cometbar.example.com. - Identificateurs uniques au niveau
mondial. On n'a certainement pas envie de changer ses
signets ou ses cartes de visite lorsqu'on passe
de France en Corée. De
même, si on fait de la publicité pour
fr.wikipedia.org, on n'a certainement pas envie de dire « sauf si vous êtes chez le FAI Untel, auquel cas c'estfr.wp.encycloou si vous utilisez Namecoin, auquel cas c'estfr/wikipedia». On veut que le même nom marche partout et à coup sûr (propriété que ne fournissent pas les moteurs de recherche.). - Identificateurs stables. La disparition d'un URL est une des plaies du Web. On veut évidemment qu'un identificateur, donné comme référence dans un livre ou un article scientifique, soit toujours valable dix ans après.
- Identificateurs sûrs. Le terme est un peu flou. Disons qu'on voudrait que les mécanismes d'avitaillement et de résolution des identificateurs ne puissent pas être subvertis trop facilement par un méchant. (Comme peut l'être le DNS avec la faille Kaminsky ou comme le sont les noms de domaine dans les pays où il n'y a pas de sécurité juridique du titulaire.)
- Identificateurs résolvables. Dans la plupart des cas, on ne s'intéresse pas à l'identificateur pour lui-même, on veut l'utiliser pour obtenir une autre information (une adresse IP, par exemple, pour pouvoir s'y connecter). Il faut donc un mécanisme de résolution, pas juste d'avitaillement (d'enregistrement). Ce point est délicat parce que, d'une certaine façon, tout type d'identificateur est résolvable. Il suffit de tout mettre dans une DHT, par exemple (en oubliant les problèmes de sécurité, cruciaux avec les DHT). Ou, au contraire de l'approche pair-à-pair de la DHT, on peut passer par un serveur Web qui fait des recherches dans une base centrale et envoie un résultat. Donc, quand je dis « identificateur résolvable », je veux dire, « de manière raisonnable » (oui, c'est très flou mais c'est clair pour moi qu'un serveur Web centralisé n'est pas une solution raisonnable).
- Identificateurs enregistrables facilement, pas cher et sans possibilité de refus arbitraire. Idéalement, on voudrait un système d'enregistrement « pair-à-pair » c'est-à-dire où il n'existe pas d'autorité jouant un rôle particulier. L'expérience prouve en effet que ces autorités tendent toujours à abuser de leur pouvoir.
Or, et c'est le point important, on ne peut pas avoir toutes
ces propriétés à la fois. Par exemple, si on veut des
identificateurs parlants comme milka.fr pour une
personne prénommée Milka, on va susciter des jalousies et on court les
risques de se le faire prendre par une grosse société ayant beaucoup
d'avocats. Ces identificateurs ne seront pas stables. Autre problème
de stabilité :
si un identificateur est parlant, il risque d'y avoir des pressions
pour le modifier, si le mot acquiert un autre sens, ou si on change
d'avis (un URL comme
http://example.org/monblog/jean-michel-michu-est-un-clown
posera un problème de stabilité si vous souhaitez adoucir le ton plus
tard...) Des
identificateurs numériques arbitraires comme
1f8efda3-df57-4fd4-b755-8808a874dd38 ne suscitent
pas de convoitises, ne risquent pas de devoir être modifiés, mais ne sont plus parlants... De même, pour avoir
des noms enregistrables en pair-à-pair complet, la seule méthode
réaliste semble être de les tirer au hasard dans un espace de grande
taille (pour éviter tout risque de collisions), ce qui les rendra très
peu parlants.
Regardons quelques exemples de familles d'identificateurs et voyons leurs propriétés :
- Les noms de domaine sont uniques au niveau mondial, parlants, relativement stables, mais pas assez en raison des convoitises qu'ils suscitent et de l'absence de sécurité juridique pour les titulaires. Grâce au DNS (RFC 1034), ils sont facilement résolvables et, grâce à DNSSEC, cette résolution peut être assez sûre. Aussi bien pour l'unicité que pour la sécurisation avec DNSSEC, ils sont enregistrés via une autorité, le registre, dont le contrôle fait régulièrement l'objet de conflits.
- Les URI (RFC 3986) sont de tellement de sortes différentes qu'on ne peut pas formuler d'opinion générale sur eux. Pour les URL, une de leurs composantes essentielles est un nom de domaine et ils héritent donc des propriétés des noms de domaine.
- Les clés PGP du RFC 9580 (ou, d'une manière générale, tous les identificateurs qui sont des clés cryptographiques publiques comme les identificateurs HIP ou bien les clés SSH du RFC 4251), ne sont pas parlants du tout (suite de chiffres très longue), sont quasi-uniques (la probabilité de collision est infime), bien que créés sans registre (tirage au sort dans un espace de très grande taille), et fournissent une grande sécurité : prouver qu'on est bien le titulaire d'un identificateur est facile, en signant avec la clé privée, et personne ne peut vous prendre votre identificateur, même pas l'État. Ils ne sont pas résolvables directement, mais peut-être demain les mettra-t-on tous dans une DHT qui permettra de trouver facilement les données correspondants (c'est encore un sujet de recherche). Ils sont très stables, sauf percée de la cryptanalyse.
- Les UUID du RFC 9562 sont également quasi-uniques, générés sans registre, et peu parlants. Mais ils n'ont pas la sécurité des clés cryptographiques.
- Les ISBN sont stables, peu parlants, nécessitent un registre, et ne sont pas résolvables à l'heure actuelle. Quelqu'un connait-il un service sur le Web qui prend un ISBN et donne les métadonnées du livre comme son titre et le nom de l'auteur ? Ce service doit évidemment fonctionner avec des livres qui ne sont plus en vente. Worldcat ne convient pas, il ne renvoie que la langue et la date de publication sur tous les ISBN que j'ai testé. Quant à OpenLibrary, il ne semble connaître aucun livre en français.
- Ils ne sont pas généralement considérés comme de vrais
identificateurs mais il faut quand même dire un mot des mots-clés
utilisés dans une recherche, par exemple via
Google. En effet, beaucoup de gens les
utilisent comme identificateurs et, au lieu de dire « Allez en
http://www.sarkozy.fr/» disent « tapez Sarkozy dans Google ». Cette méthode est très mauvaise car ces « identificateurs » sont parlants, résolvables (via le moteur de recherche) mais n'ont aucune stabilité. Aujourd'hui, c'est tel site qui répond à telle recherche, demain ce sera un autre. - Les adresses IP sont très peu stables (la plupart du temps, elles dépendent du FAI), peu parlantes, nécessitent un registre (à l'exception des ULA du RFC 4193) mais sont très facilement résolvables via les tables de routage distribuées par des protocoles comme BGP.
- Les identificateurs EUI-64 (adresses
Ethernet, adresses MAC, etc) sont peu parlants, attribués par un registre
(deux niveaux de registre, l'IEEE et
l'entreprise), uniques mais non résolvables. Et ils n'offrent aucune
sécurité (sur Linux, vous pouvez changer votre
adresses MAC avec
ifconfig.) - Les DOI ne sont pas parlants, dépendent d'un registre, n'ont pas de stabilité particulière (la stabilité ne dépend pas que de la technique mais aussi de pratiques sociales : des identificateurs comme les DOI qui dépendent entièrement d'une société privée ont un avenir très incertain) et ne sont pas résolvables (au début de la bulle DOI, il était question de les résoudre avec le protocole Handle du RFC 3650 mais ce projet n'a jamais débouché et tous les résolveurs de DOI aujourd'hui dépendent de l'URL d'un serveur centralisé, donc du DNS).
- Les tags du RFC 4151
sont assez parlants (au choix de leur auteur), uniques, et extrêmement
stables. Celui de cet article est
tag:bortzmeyer.org,2006-02:Blog/no-free-lunch. Comme ils incluent une date (février 2006 pour les tags de ce blog, reflétant le début de leur utilisation), l'absence de stabilité des noms de domaine sous-jacents n'est pas un problème. Le registre du.comou bien le gouvernement du registre (celui des États-Unis) peut me prendre mon nom de domaine en.commais le tag formé avec celui-ci restera à moi. Par contre, les tags n'offrent aucune résolvabilité. En pratique, ils ne sont utilisés que pour fournir des identificateurs uniques et stables dans la syndication, pour que le lecteur de flux de syndication puisse savoir s'il a déjà vu un article.
Comme le montre cette liste, il n'existe pas d'identificateur idéal, qui aurait toutes les propriétés souhaitables (cf. RFC 1737 pour un exemple de cahier des charges pour des identificateurs idéaux). Le verrons-nous apparaître dans le futur, grâce aux progrès de la recherche fondamentale ? Peut-être mais je ne crois pas, le problème est trop fondamental. Bien que cela n'ait pas été démontré mathématiquement, je pense que faire un système qui ait toutes ces propriétés, c'est comme de violer le premier ou le second principe de la thermodynamique. Lorsque quelqu'un arrive avec une telle proposition, il existe une infime possibilité qu'il soit un génie qui ait découvert une nouvelle voie. Mais il est bien plus probable qu'il soit un escroc ou tout simplement un ignorant qui n'a pas fait la moindre recherche avant de concevoir son système.
Dans l'état actuel de l'art, il faut donc rejeter tout projet qui ne dit pas clairement quelles propriétés il veut. Si les auteurs du projet ne veulent pas lister explicitement les propriétés de leur système de nommage, c'est parce qu'ils ont peur de montrer que leur système n'est pas idéal et ne fait pas tout.
Ce problème de l'impossibilité de tout optimiser à la fois est souvent présenté sous le nom de triangle de Zooko (par exemple dans un excellent texte de Dan Kaminsky). Mais je trouve que le triangle de Zooko oublie plusieurs propriétés importantes donc j'ai préféré faire ma liste de propriétés.
Merci à O. Marce pour ses remarques. Parmi les bonnes lectures sur le sujet, je recommande l'article d'Emmanuelle Bermès, « Des identifiants pérennes pour les ressources numériques ; L'expérience de la BnF ». Il y a aussi mon exposé sur les identificateurs. Enfin, j'ai fait également un exposé sur ce problème, dont les transparents sont en ligne.
L'article seul
Déboguer les problèmes réseau : la taille compte
Première rédaction de cet article le 17 juin 2011
Tout administrateur réseaux le sait :
lorsqu'il y a un problème de connectivité IP, le premier
outil à dégainer est ping. C'est en général un
bon réflexe. Mais malheureusement beaucoup de ces administrateurs ne
dépassent pas le stade de ping nom-machine et ne
regardent jamais le manuel. Ils se
privent ainsi d'options intéressantes, comme celle qui permet de faire
varier la taille des
paquets de test. Ils ont tort car cette taille
a une influence importante sur le test.
Prenons un exemple réel, sur un réseau CPL qui marchait mal (adaptateur CPL défaillant, a été changé par la suite). Le Web est peu utilisable (trop lent, certaines images ne chargent pas du tout). Pourtant, ping ne montre aucun problème :
% ping 208.75.84.80 PING 208.75.84.80 (208.75.84.80) 56(84) bytes of data. 64 bytes from 208.75.84.80: icmp_seq=1 ttl=46 time=132 ms 64 bytes from 208.75.84.80: icmp_seq=2 ttl=46 time=131 ms 64 bytes from 208.75.84.80: icmp_seq=3 ttl=46 time=131 ms 64 bytes from 208.75.84.80: icmp_seq=4 ttl=46 time=131 ms 64 bytes from 208.75.84.80: icmp_seq=5 ttl=46 time=132 ms 64 bytes from 208.75.84.80: icmp_seq=6 ttl=46 time=131 ms 64 bytes from 208.75.84.80: icmp_seq=7 ttl=46 time=131 ms 64 bytes from 208.75.84.80: icmp_seq=8 ttl=46 time=131 ms 64 bytes from 208.75.84.80: icmp_seq=9 ttl=46 time=130 ms 64 bytes from 208.75.84.80: icmp_seq=10 ttl=46 time=131 ms ^C --- 208.75.84.80 ping statistics --- 10 packets transmitted, 10 received, 0% packet loss, time 9033ms rtt min/avg/max/mdev = 130.773/131.526/132.131/0.521 ms
L'excellent logiciel mtr ne montre rien de
plus. tcpdump montre peu de trafic (donc la
ligne n'est pas surchargée) et de longues attentes (puis ça
repart). Mais si on fait varier la taille des paquets avec l'option
-s de ping, on voit bien le problème :
% ping -s 1450 208.75.84.80 PING 208.75.84.80 (208.75.84.80) 1450(1478) bytes of data. 1458 bytes from 208.75.84.80: icmp_seq=1 ttl=46 time=168 ms 1458 bytes from 208.75.84.80: icmp_seq=5 ttl=46 time=167 ms 1458 bytes from 208.75.84.80: icmp_seq=6 ttl=46 time=167 ms 1458 bytes from 208.75.84.80: icmp_seq=9 ttl=46 time=169 ms 1458 bytes from 208.75.84.80: icmp_seq=10 ttl=46 time=167 ms 1458 bytes from 208.75.84.80: icmp_seq=13 ttl=46 time=168 ms 1458 bytes from 208.75.84.80: icmp_seq=15 ttl=46 time=168 ms 1458 bytes from 208.75.84.80: icmp_seq=18 ttl=46 time=167 ms ^C --- 208.75.84.80 ping statistics --- 19 packets transmitted, 8 received, 57% packet loss, time 18013ms rtt min/avg/max/mdev = 167.407/168.034/169.066/0.639 ms
Avec des paquets de 1450 octets (la taille par défaut utilisée par ping est de 56 octets), le taux de perte, qui était nul, passe à plus de 50 %. On comprend pourquoi le Web avait des problèmes : si les requêtes HTTP sont souvent petites, les réponses, elles, ont en général la taille maximum permise par le réseau (1500 octets pour Ethernet). Si un problème frappe spécifiquement les gros paquets, un ping naïf marchera alors qu'une navigation Web échouera.
Mais pourquoi est-ce que les gros paquets auraient plus de mal à passer que les petits ? Une raison possible est un parasite aléatoire. Si le signal parasite frappe au hasard, les gros paquets auront une probabilité plus élevée d'être touchés (sur Ethernet, en raison de la somme de contrôle des paquets, si un seul bit est modifié, le paquet entier est jeté). Ce genre de choses arrive rarement sur les réseaux filaires mais est bien plus fréquent en WiFi.
Autre exemple de comportement différent selon la taille, les problèmes du point d'échange Sfinx en juin 2011 (ticket Sfinx n° 2215418). Un mtr ordinaire montre un certain pourcentage de pertes, dont la cause est inconnue :
% mtr --report --report-cycles 100 -4 f.root-servers.net
Loss% Snt Last Avg Best Wrst StDev
...
3. vl387-te2-6-paris1-rtr-021.n 0.0% 100 1.4 2.2 1.4 33.1 4.4
4. te0-1-0-3-paris1-rtr-001.noc 0.0% 100 94.2 18.5 1.5 98.7 24.5
5. isc-f-root-server-2.sfinx.tm 7.0% 100 1.9 4.7 1.8 179.3 20.6
6. f.root-servers.net 6.0% 100 1.9 2.7 1.8 10.0 1.8
En augmentant la taille des paquets grâce à l'option
--psize, le taux de pertes augmente nettement :
% mtr --report --report-cycles 100 --psize 1000 -4 f.root-servers.net
Loss% Snt Last Avg Best Wrst StDev
...
3. vl387-te2-6-paris1-rtr-021.n 0.0% 100 1.6 1.7 1.5 19.6 1.8
4. te0-1-0-3-paris1-rtr-001.noc 0.0% 100 2.0 19.3 1.7 130.3 24.7
5. isc-f-root-server-2.sfinx.tm 17.0% 100 2.1 5.3 2.1 179.4 21.2
6. f.root-servers.net 17.0% 100 2.7 3.5 2.6 10.5 1.9
Cela indique clairement un problème situé dans les couches 1 ou 2, par exemple une mauvaise adaptation Ethernet (half-duplex au lieu de full-duplex). Merci à Johan Remy pour son aide sur ce point.
Autre cas où faire varier la taille est utile, l'étude de problèmes de performances : dans certains cas, c'est le nombre de paquets par seconde qui est le facteur limitant de la performance du réseau, dans d'autres (réseaux lents, par exemple vieux modems), c'est le nombre de bits par seconde et, dans ce cas, le test avec des gros paquets donnera une vision plus réaliste des performances réelles.
Enfin, faire varier la taille des paquets de tests est nécessaire lorsqu'on veut déboguer des problèmes de MTU. En raison de la fréquence des tunnels et d'une incompréhension du rôle d'ICMP par les gérants de pare-feux, c'est le plus souvent IPv6 qui est affecté par ce genre de problèmes. Voici un exemple. Tout se passe bien ?
% ping6 -n e.ext.nic.fr PING e.ext.nic.fr(2a00:d78:0:102:193:176:144:6) 56 data bytes 64 bytes from 2a00:d78:0:102:193:176:144:6: icmp_seq=1 ttl=59 time=22.3 ms 64 bytes from 2a00:d78:0:102:193:176:144:6: icmp_seq=2 ttl=59 time=22.7 ms 64 bytes from 2a00:d78:0:102:193:176:144:6: icmp_seq=3 ttl=59 time=22.2 ms 64 bytes from 2a00:d78:0:102:193:176:144:6: icmp_seq=4 ttl=59 time=22.3 ms 64 bytes from 2a00:d78:0:102:193:176:144:6: icmp_seq=5 ttl=59 time=22.3 ms ^C --- e.ext.nic.fr ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 4004ms rtt min/avg/max/mdev = 22.221/22.407/22.772/0.211 ms
Hélas non. Si on augmente la taille des paquets, cela se passe bien jusqu'à une certain valeur :
% ping6 -n -c 5 -s 1400 e.ext.nic.fr PING e.ext.nic.fr(2a00:d78:0:102:193:176:144:6) 1400 data bytes 1408 bytes from 2a00:d78:0:102:193:176:144:6: icmp_seq=1 ttl=59 time=24.8 ms 1408 bytes from 2a00:d78:0:102:193:176:144:6: icmp_seq=2 ttl=59 time=24.9 ms 1408 bytes from 2a00:d78:0:102:193:176:144:6: icmp_seq=3 ttl=59 time=24.8 ms 1408 bytes from 2a00:d78:0:102:193:176:144:6: icmp_seq=4 ttl=59 time=27.0 ms 1408 bytes from 2a00:d78:0:102:193:176:144:6: icmp_seq=5 ttl=59 time=24.9 ms --- e.ext.nic.fr ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 4005ms rtt min/avg/max/mdev = 24.867/25.339/27.024/0.861 ms
Mais plus après :
% ping6 -n -c 5 -s 1470 e.ext.nic.fr PING e.ext.nic.fr(2a00:d78:0:102:193:176:144:6) 1470 data bytes --- e.ext.nic.fr ping statistics --- 5 packets transmitted, 0 received, 100% packet loss, time 4018ms
C'est caractéristique des problèmes de MTU. Lorsque la liaison réseau est correcte (pas de filtrage d'ICMP nulle part), la réduction de la MTU (ici, la machine cible est derrière un tunnel) ne gêne pas :
% ping6 -s 3000 -c 5 2001:470:1f11:3aa::1 PING 2001:470:1f11:3aa::1(2001:470:1f11:3aa::1) 3000 data bytes From 2001:470:0:6e::2 icmp_seq=1 Packet too big: mtu=1480 3008 bytes from 2001:470:1f11:3aa::1: icmp_seq=1 ttl=56 time=102 ms 3008 bytes from 2001:470:1f11:3aa::1: icmp_seq=2 ttl=56 time=103 ms 3008 bytes from 2001:470:1f11:3aa::1: icmp_seq=3 ttl=56 time=103 ms 3008 bytes from 2001:470:1f11:3aa::1: icmp_seq=4 ttl=56 time=103 ms 3008 bytes from 2001:470:1f11:3aa::1: icmp_seq=5 ttl=56 time=102 ms --- 2001:470:1f11:3aa::1 ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 4004ms rtt min/avg/max/mdev = 102.757/102.968/103.097/0.138 ms
Notez le « Packet too big » qui montre que le paquet ICMP a été bien reçu.
Un point important pour tous ces tests : le routage dans l'Internet
n'est pas forcément symétrique. Rien ne dit que les paquets de réponse
suivront le même trajet que les paquets de requête. Cela peut rendre
le débogage très délicat : par exemple, une session HTTP où les
requêtes (petites) empruntent un chemin et les réponses (grandes) un
autre, sera parfois difficile à déboguer avec un ping -s
où les paquets auront la même taille à l'aller et au retour (merci à
Thomas Mangin pour la précision).
Autre point, question outils. Comme certains réseaux (ou systèmes)
traitent différemment les protocoles, le test avec ICMP, que fait
ping, peut ne pas être représentatif. Un outil comme
hping permet le même genre de manipulations
avec les autres protocoles par exemple hping --syn -p 80 --data
1200 example.com va tester en TCP
avec des paquets de 1200 octets. hping dispose de nombreuses autres options
(merci à Florian Crouzat pour la suggestion).
Bref, pour résumer, lors des entretiens d'embauche d'un
administrateur réseaux, pensez à l'interroger sur le rôle de l'option
-s. C'est un bon test !
L'article seul
BGP et les trous noirs
Première rédaction de cet article le 17 juin 2011
Le 16 juin, le routeur de Renater au point d'échange Sfinx est devenu un trou noir, un routeur qui annonce des routes mais ne transmet pas les paquets ensuite. Pourquoi les mécanismes de secours normaux de BGP n'ont-ils servi à rien ?
Le protocole BGP (RFC 4271) permet les échanges de routes entre opérateurs
Internet. Chaque routeur annonce à ses pairs les routes qu'il connaît
directement ou indirectement (par exemple « Je sais joindre 2001:db8:42::/48 »). Si les pairs sélectionnent ces routes,
ils enverront ensuite les paquets à destination de ces préfixes au
routeur qui les a annoncés. Ce système est normalement très
robuste. Si un routeur stoppe, plante, est débranché, ou est
physiquement détruit, la session BGP avec les pairs stoppe et
ceux-ci refont tourner l'algorithme de sélection de routes et
choisissent d'autres routes. C'est en bonne partie sur ce mécanisme
que repose la résistance de l'Internet aux pannes.
Mais ce mécanisme n'a pas fonctionné le 16 juin (ticket Renater n° 2214325). Pour une raison inconnue, le routeur fonctionnait toujours, maintenait les sessions BGP mais ne transmettait plus les paquets, qui étaient simplement jetés. On parle de « trou noir » bien qu'on pourrait aussi dire que le routeur est un « allumeur » : il attire le trafic mais n'assume pas son rôle par la suite. Symptôme avec traceroute : juste avant ou juste après le routeur en question (selon la façon dont il traite les paquets dont le TTL a expiré), on ne voit plus que des étoiles :
traceroute vers rigolo.nic.fr (2001:660:3003:2::4:20) de 2001:..., port 33434, du port 45934, 30 sauts max, 60 octet/paquet ... 3 te2-2-72-nb-stdenis-2.ipv6.nerim.net (2001:7a8:1:72::2) 0.487 ms 0.450 ms 0.465 ms 4 te2-2-94-nb-voltaire-1.ipv6.nerim.net (2001:7a8:1:94::1) 0.658 ms 0.701 ms 0.699 ms 5 te2-4-20-nb-voltaire-2.ipv6.nerim.net (2001:7a8:1:20::2) 0.712 ms 0.726 ms 0.695 ms 6 renater-th2.sfinx.tm.fr (2001:7f8:4e:2::103) 2.916 ms 0.900 ms 1.333 ms 7 * * * 8 * * * 9 * * *
(Merci à Laurent Dolosor pour le traceroute.)
BGP ne fournit pas de solution à ce problème. Tant que la session
fonctionne, il considère que le routeur tiendra ses promesses et
transmettra les paquets. Le fait d'être
multi-homé n'aide donc pas,
puisque les routes alternatives ne seront pas essayées. Les seuls mécanismes sont, chez les pairs du
routeur défaillant, de détecter
l'absence de trafic et/ou la non-transmission des paquets et de fermer
les sessions BGP. Ce n'est pas facile à automatiser (d'autant plus
qu'on risque de couper des sessions BGP à tort si le système de
détection est trop sensible).
Cela ne suffit pas si un serveur de routes
est utilisé, il faut alors aussi couper la session avec le serveur de
routes (ce qui est très violent car cela fait perdre plein d'autres
routes que celles du routeur allumeur), soit filtrer spécifiquement
les annonces de l'opérateur impacté (par exemple avec route-map sur IOS ou route-filter sur JunOS,
mais attention, cette méthode impose de penser à supprimer les filtres une fois le problème disparu).
L'idéal est que l'opérateur du routeur à problèmes éteigne la machine coupable, ramenant ainsi le problème à un cas connu (pair BGP arrêté).
Un article sur un problème similaire (peut-être inspiré par la même panne) est (original en anglais) « When Null0 and BGP May Cause Problems » et « Quand Null0 et BGP peuvent causer problème » (en français).
L'article seul
Le nom de domaine du Tchad en panne pendant deux mois
Première rédaction de cet article le 15 juin 2011
Dernière mise à jour le 27 février 2012
Il est fréquent qu'un des deux ou trois cents
TLD actuellement présents ait des problèmes
techniques. La très forte résilience du DNS
fait que, la plupart du temps, on ne s'en aperçoit pas. Mais il y a
des limites à tout et, depuis au moins le 23 mai, et jusqu'au 20 juillet,
.TD, TLD du
Tchad a été intégralement en panne.
Le problème a été publié par Steinar Haug sur la liste
dns-operations. .TD a deux serveurs de
noms, tous les deux répondaient SERVFAIL, le code
de réponse DNS qui indique que le serveur a un problème :
# Merci à Gilles Massen, Mathieu Arnold et Kim Minh Kaplan pour l'aide
# avec le code. Plus un script shell est court, plus on reçoit de
# suggestions d'amélioration.
% for ns in $(dig +noall +auth @f.root-servers.net td. | tr -s \\t | cut -f 5); do
echo "Testing $ns"
dig @$ns SOA td.
done
Testing bow.intnet.td
...
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 58428
...
Testing bow.rain.fr
...
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 28968
...
Aucun nom en .TD ne peut donc être trouvé (voir à
la fin de cet article pour un bémol). On
note que ce n'est pas une panne matérielle, la machine
bow.intnet.td, apparemment située à
N'Djaména, d'après les temps de réponse, est joignable et répond (mais
incorrectement ; interrogez-la sur un autre domaine comme
intnet.td et vous aurez une réponse correcte).
Il faut noter que le TLD .TD est négligé
depuis de nombreuses années. Cela fait longtemps que
bow.rain.fr ne répond plus correctement. Le TLD
ne tenait donc plus qu'à une seule machine, qui a lâché à son
tour.
Le 20 juillet, la machine incorrecte a été reconfigurée et répond dorénavant correctement :
Testing bow.intnet.td. ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 52886 ;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 2, ADDITIONAL: 2 ... ;; ANSWER SECTION: td. 4838400 IN SOA bow.intnet.td. yaser.intnet.td. 2011072001 28800 7200 4838400 4838400 ;; AUTHORITY SECTION: td. 86400 IN NS proof.rain.fr. td. 86400 IN NS bow.intnet.td. ;; ADDITIONAL SECTION: bow.intnet.td. 86400 IN A 193.251.147.253 ;; Query time: 533 msec ;; SERVER: 193.251.147.253#53(193.251.147.253) ;; WHEN: Thu Jul 21 08:59:07 2011 ;; MSG SIZE rcvd: 141
Le second serveur annoncé, proof.rain.fr, refusait encore de répondre aux requêtes pour .TD :
;; ->>HEADER<<- opcode: QUERY, status: REFUSED, id: 59819
Notez que la racine, elle, annonce un autre serveur, et qui marche, bow.rain.fr. Le 20 février 2012, .td a été reconfiguré avec trois serveurs, dont un
à l'AFNIC, et qui marchent tous :
% dig +nssearch td SOA ns1.nic.td. cctldchad.gmail.com. 2012022312 10800 3600 4838400 3600 from server 2001:660:3006:1::1:1 in 2 ms. SOA ns1.nic.td. cctldchad.gmail.com. 2012022312 10800 3600 4838400 3600 from server 192.134.0.49 in 2 ms. SOA ns1.nic.td. cctldchad.gmail.com. 2012022312 10800 3600 4838400 3600 from server 193.251.147.237 in 593 ms. SOA ns1.nic.td. cctldchad.gmail.com. 2012022312 10800 3600 4838400 3600 from server 85.31.71.189 in 887 ms.
En septembre 2012, le TLD .td est retombé en
panne complète... Le niveau de sérieux et de responsabilité ne semble
pas avoir augmenté.
De nombreuses personnes ont tenté de joindre les administrateurs du
TLD à la Société des télécommunications du Tchad (SOTEL), l'opérateur
historique, récemment privatisé. Les adresses de courrier en
.TD ne marchent évidemment plus, les numéros de
fax et de téléphone dans la base IANA sont souvent
incorrects (résultat de la négligence du TLD). Par des contacts
personnels, des relais, des adresses @gmail.com
ou @yahoo.fr sont utilisées. Pas moyen de trouver
quelqu'un qui veuille et puisse agir.
J'insiste que le problème n'est pas technique : la machine répond donc la liaison Internet fonctionne. Ce n'est pas non plus un manque de compétences techniques, sur Internet, on trouve plein de gens compétents qui peuvent aider gratuitement (comme sur la liste dns-operations citée plus haut). Non, c'est un problème organisationnel, de négligence et d'irresponsabilité. Personne ne considère que c'est son problème, et que c'est à lui de réparer.
Ce n'est pas non plus un problème dû à la pauvreté. Certes, le Tchad est un pays très pauvre (il y a du pétrole mais l'argent ne va pas aux projets utiles). Mais des pays aussi pauvres comme Haïti ont réussi à monter une infrastructure DNS robuste. Ne pas avoir de serveurs DNS secondaires un peu partout est inexcusable puisque de nombreuses organisations proposent un service d'hébergement gratuit aux TLD (citons, parmi plusieurs autres, PCH, l'AFNIC, l'ISC, etc).
Une petite note technique pointue pour conclure. Dans certains cas,
les noms en .TD marchent toujours (cela dépend du
comportement exact de votre résolveur DNS). En effet, vous pouvez voir
que la machine bow.intnet.td/193.251.147.253
répond toujours pour les sous-domaines de .TD :
% dig @193.251.147.253 ANY sotel.td ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 42424 ... ;; ANSWER SECTION: sotel.td. 86400 IN SOA bow.intnet.td. yaser.intnet.td. 2009022801 21600 3600 604800 86400 sotel.td. 86400 IN NS bow.intnet.td. sotel.td. 86400 IN NS bow.rain.fr. sotel.td. 86400 IN MX 10 mail.intnet.td.
En effet, le même serveur de noms a été configuré pour faire autorité
pour le TLD et pour les sous-domaines. Mauvaise pratique mais que l'on
voit parfois. .TD a été retiré de cette machine
mais les sous-domaines sont restés. Comme, dans le protocole DNS, le
résolveur envoie la question complète (par exemple
www.sotel.td) aux serveurs faisant autorité, dans
certains cas, cela peut encore marcher. L'échec est par contre complet
lorque le nom n'existe pas, car aucun serveur faisant autorité n'est
trouvé et on doit alors patienter jusqu'à l'expiration du délai de
garde.
Enfin, comme souvent avec les opérateurs de télécommunication historiques
qui se sont approprié le TLD (un cas courant en Afrique francophone),
le serveur du TLD est mis comme serveur des sous-domaines, même s'il
ne donne pas les réponses correctes. Regardez
youtube.td :
% dig @193.251.147.253 NS youtube.td ... ;; ANSWER SECTION: youtube.td. 86400 IN NS bow.intnet.td. youtube.td. 86400 IN NS ns1.google.com. youtube.td. 86400 IN NS ns2.google.com.
Outre les serveurs de Google, propriétaire de
YouTube, on retrouve
bow.intnet.td. Or, celui-ci ment. Demandons à un
serveur de Google l'adresse IP de
www.youtube.td :
% dig @ns1.google.com A www.youtube.td ... ;; ANSWER SECTION: www.youtube.td. 86400 IN CNAME youtube-ui.l.google.com. youtube-ui.l.google.com. 300 IN A 209.85.146.93 youtube-ui.l.google.com. 300 IN A 209.85.146.91 youtube-ui.l.google.com. 300 IN A 209.85.146.190 youtube-ui.l.google.com. 300 IN A 209.85.146.136
On obtient des adresses chez Google. Mais posons la même question au serveur de la SOTEL :
% dig @193.251.147.253 A www.youtube.td ... ;; ANSWER SECTION: www.youtube.td. 86400 IN A 210.32.239.216 www.youtube.td. 86400 IN A 10.34.239.216
Il nous répond par des adresses IP situées en Chine, pour l'une, et appartenant à une plage privée, pour l'autre...
À noter qu'un problème similaire a frappé le Gabon fin 2011.
Merci à Alain Thivillon pour ses bonnes remarques.
L'article seul
Expérimentation avec la distribution Android CyanogenMod
Première rédaction de cet article le 15 juin 2011
Il y a deux sortes d'utilisateurs d'Android : ceux qui sont mous et paresseux et qui acceptent leur téléphone tel qu'il est et les vrais courageux qui installent une variante non-officielle de ce système d'exploitation. Je voulais faire partie des premiers, pour ne pas passer mes journées à m'occuper de mon smartphone mais Android en a décidé autrement en crashant et en ne me laissant pas d'autre choix pour redémarrer que de tout effacer. Puisque c'était fait, j'en ai profité pour tester d'autres systèmes, cette semaine, CyanogenMod.
J'avais déjà fait un essai avec MIUI, une distribution
Android très particulière. Après, je suis passé
à la distribution non-officielle la plus connue, la plus stable, la
plus normale, CyanogenMod. Voici d'ailleurs une
copie d'écran :
 Cela n'a pas un grand intérêt puisque CyanogenMod est très
configurable et qu'il n'y a donc pas deux téléphones CyanogenMod qui
se ressemblent.
Cela n'a pas un grand intérêt puisque CyanogenMod est très
configurable et qu'il n'y a donc pas deux téléphones CyanogenMod qui
se ressemblent.
Pourquoi CyanogenMod ? Il y a plein de raisons. Par exemple, il est
très configurable, notamment sur la consommation d'énergie. On peut
pousser le téléphone à fond, ce qui le rend très rapide ou bien au
contraire lui demander d'être calme, ce qui économise la batterie (un
très gros problème sur le HTC Desire, où elle
est de bien faible capacité). Voici l'écran de réglage, avec le mode
POWERSAVE activé et la vitesse du
CPU limitée
(underclocking) :
 .
.
D'autre part, contrairement à des systèmes ultra-fermés comme MIUI, on a les sources, en https://github.com/cyanogenmod, on a un système de gestion de
bogues public,
on a tout ce qui fait un système ouvert.
Comment on installe CyanogenMod ? Évidemment, il faut avoir rooté son téléphone. Ensuite, il y a plusieurs méthodes : on peut le télécharger depuis ROM manager (mais ce dernier est pénible avec ses publicités et sa liste d'images incomplète). J'ai préféré télécharger CyanogenMod directement sur une machine Unix puis le copier sur la carte SD du téléphone :
sudo cp ~/Downloads/update-cm-7.0.3-Desire-signed.zip /media/usb0/
Puis ROM Manager permet de flasher l'image (je sais, on dit ROM dans le monde Android mais ce terme me semble tout à fait incorrect). Puis on redémarre et on voit un robot bleu qui fait du skate. La documentation dit qu'on n'est pas obligé de vider le téléphone avant mais il ne faut pas la croire. Si vous testez et que vous avez des bogues bizarres (robot bleu au démarrage mais dont la flèche tourne sans interruption sans jamais s'arrêter, ou bien réglage des paramètres du système qui plante), il faut me croire et faire un Hard Reset et Clear Storage dans le Boot Loader avant d'installer CyanogenMod (cela n'efface que la mémoire du téléphone, pas la carte SD). Wiper le téléphone est donc la seule solution sûre, quoiqu'en dise la documentation.
Et si on veut des applications non-libres qui sont normalement livrées avec Android mais ne peuvent pas l'être avec une distribution non-officielle, comme par exemple les Google Apps ? On peut les télécharger sur le site de CyanogenMod et les installer avec ROM Manager.
Quelques bons articles sur CyanogenMod :
Et si on a du mal et qu'on cherche de l'aide ? Il y a un canal
IRC (extrêmement bavard),
#cyanogenmod, sur
le serveur Freenet. Et il y a un ensemble des forums Web
en http://forum.cyanogenmod.com/.
Il y a bien sûr d'autres distributions possibles comme Amon-RA/oxygen ou Leedroid (pour lequel j'ai eu plusieurs recommandations) mais ce sera pour une autre fois.
L'article seul
Ward
Première rédaction de cet article le 14 juin 2011
Comme l'ont déjà vu les lecteurs de ce blog, j'admire la variété des langues humaines et le nombre de moyens différents de s'exprimer. Certaines personnes trouvent sans doute que cette variété est encore insuffisante, ou bien ils ne peuvent pas résister au désir de l'effort intellectuel de création d'une nouvelle langue, et cela forme une langue construite comme le wardwesân, objet et outil de ce roman.
Car l'auteur, Frédéric Werst, a fait fort : il a créé une langue, le wardwesân, lui a donné évidemment grammaire et vocabulaire, puis a imaginé de lui donner une culture : celle du peuple Ward, dont le roman fournit l'histoire, la poésie, les sciences politiques, la religion et la philosophie. Et tous ces textes sont en wardwesân (avec, je vous rassure, la traduction en français à côté, mais l'auteur dit qu'il a écrit en wardwesân et traduit ensuite en français).
C'est évidemment un exploit extraordinaire, d'autant plus que l'auteur a intégré plusieurs niveaux de langue, des dialectes régionaux, et même une évolution. (Sur les langues construites, je recommande l'excellent livre d'Arika Okrent.)
Pour arriver à lire ces textes, la tâche est facilitée par le fait que les Wards utilisent l'alphabet latin ou, plus exactement, que l'auteur n'a pas poussé le travail jusqu'à leur inventer une écriture... Une grammaire est fournie mais le wardwesân rassemble bien des particularités qui ne rendent pas l'apprentissage immédiat. J'ai bien aimé le temps « gnomique » des verbes (qui sert à exprimer une vérité générale et n'indique donc pas de personne), l'absence de verbe « être » ou les « sept clés » (comme « ab », ci-dessous).
On trouve quelques articles sur le wardwesân en ligne comme :
- Un exposé de sa grammaire (en anglais),
- Le Times a publié un article en anglais sur ce roman, avec une rencontre avec l'auteur mais il ne semble pas accessible via le site Web officiel. On le trouve néanmoins ailleurs,
- Un article enthousiaste (en français) dans Mediapart.
Faisons un petit essai de traduction (très sommaire) avec un récit mythologique, « Be Weris wern », p. 98 (la rose de Weris), texte qui fait l'éloge du multilinguisme. On y trouve la phrase « Jānz aen arzigh zaeph an kell ab zemph altōn ar permenta zēs an merwan jaba zamō karamagan altōn ar mena thōon bard na zaren ek zarnen xevaeth zantanōn. ». Voyons par étapes :
- jenz : alors
- aen : loin, hors
- arzigh : sans doute pétale, vu le contexte, mais je ne l'ai pas trouvé dans le dictionnaire
- zaeph : chaque
- an : répétition du co-verbe de la phrase précédente. Le co-verbe, p. 372, est presque l'équivalent du verbe français (mais n'exprime pas certaines choses comme le nombre)
- kell : nombre
- ar : le, la, les (pour une entité collective, ici les fidèles)
- ab : liaison
- zemph : langue (au sens anatomique)
- altōn : ? Le dictionnaire inclus dans le roman est très court
- permenta : perma, c'est un fidèle, donc c'est sans doute un pluriel. Les règles du pluriel en wardwesân sont... inexistantes. La seule façon de trouver le pluriel d'un mot ou de le reconnaître, c'est de voir le dictionnaire mais celui inclus dans le roman n'indique que très rarement les pluriels.
- zēs : son, ses
- merwan : fabriquer
- jaba : afin que
- zamō : ils
- karamagan : karamagon est l'éloge, peut-être un pluriel
- mena : ? (men est le ciel donc peut-être les cieux)
- thōon : sans
- bard : limite
- na : opinatif, une particularité du wardwesân qui permet de se passer de verbe conjugué
- zaren : ?
- ek : et
- zarnen : langue (au sens linguistique)
- xevaeth : variété
- zantanōn : zanta étant le chant, c'est sans doute chanter
On arrive donc à :
- Jānz aen arzigh zaeph an kell : De chaque pétale...
- zemph altōn ar permenta zēs an merwan : il fabrique une langue pour les fidèles
- jaba zamō karamagan altōn ar mena thōon bard ... zantanōn : afin qu'ils chantent les éloges des cieux sans limite
- na zaren ek zarnen xevaeth : dans une variété de langues et de ?
Ce que l'auteur traduit, bien plus joliment, dans cette belle conclusion : « Alors il fit de chaque pétale une langue pour ses adorateurs, afin que ceux-ci chantent sans fin les louanges du Ciel en diverses langues et diverses couleurs. »
L'article seul
RFC 6264: An Incremental Carrier-Grade NAT (CGN) for IPv6 Transition
Date de publication du RFC : Juin 2011
Auteur(s) du RFC : S. Jiang, D. Guo (Huawei), B. Carpenter (University of Auckland)
Pour information
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 14 juin 2011
Verra-t-on un jour la fin des RFC sur les plans de transition d'IPv4 vers IPv6 ? Sans doute pas tant que la transition traîne. En effet, la lenteur imprévue du déploiement d'IPv6 remet en cause les plans initiaux (qui reposaient sur l'idée qu'il resterait des adresses IPv4 pendant toute la phase de transition) et nécessite le développement de nouveaux plans, pour répondre à une situation différente.
Le plan présenté ici est une variante des plans reposant sur l'idée de CGN (Carrier-Grade NAT), ces routeurs NAT installés, non pas dans la box de M. Michu, pour son usage et celui de sa famille, mais installés chez le FAI, pour l'usage partagé de plusieurs clients du FAI. Le CGN a l'avantage de nécessiter zéro logiciel ou configuration chez l'utilisateur (qui n'a probablement pas le temps et l'envie de maîtriser ces mécanismes). Ces solutions reposant uniquement sur le travail du FAI sont donc tentantes pour répondre au problème de la trop lente migration chez les utilisateurs. (Toutefois, mon impression personnelle est que beaucoup de réseaux de M. Michu, plein de gadgets récents, sont plus avancés vers IPv6 que pas mal de réseaux de FAI, conçus il y a des années.)
La nouveauté par rapport aux autres plans reposant sur le CGN est l'introduction de mécanismes pour éviter que ce CGN ne se transforme en impasse, et pour le faire évoluer vers de l'IPv6 natif complet. En effet, dans la plupart des cas, le terme de CGN fait penser à un mécanisme pour retarder la transition, le NAT444, qui permet au FAI paresseux de continuer à utiliser IPv4 même alors qu'il ne peut plus distribuer ne serait-ce qu'une seule adresse IPv4 publique à ses clients. Ce CGN-là ne fait pas progresser vers IPv6 (section 1 du RFC).
D'où cette idée de proposer un plan de migration reposant sur le CGN mais prévoyant dès le début les moyens d'en sortir. Ce RFC ne contient pas de nouveaux protocoles, il ne fait que combiner les protocoles existants.
Dans un certain nombre de FAI, la situation est actuellement la suivante (section 2) :
- Plus d'adresses IPv4 publiques,
- Un réseau interne purement IPv4, par manque de proactivité du FAI (qui aurait dû déployer IPv6 depuis longtemps), et qu'on ne peut pas migrer en cinq minutes,
- La prise de conscience qu'IPv6 est nécessaire, et à relativement court terme.
Dans d'autre cas, FAI ayant fait son travail à l'avance et ayant déployé IPv6 depuis longtemps, ou bien FAI tout récent et préférant l'approche radicale de déployer un réseau purement IPv6, avec NAT64 (RFC 6144, et section 2.6 de notre RFC) pour assurer la liaison avec le vieux protocole, ces hypothèses ne sont plus vraies et l'approche de ce RFC ne s'applique donc pas. Comme toujours avec la transition vers IPv6, il faut analyser son réseau et déterminer la ou les meilleures stratégies de transition : chacune s'applique à un cas bien particulier.
Le dessin n° 1 en section 2.1 résume bien l'approche « CGN progressif » (Incremental Carrier-Grade NAT). En partant de chez M. Michu (ou plutôt M. Li car le cas décrit est plus proche de ce que vivent les FAI asiatiques), on a :
- Les machines de M. Li, certaines en IPv6 mais pas toutes,
- Un nouveau composant, le HG (Home Gateway), une box capable d'assurer certaines fonctions comme de tunneler le trafic IPv6 vers le routeur NAT situé plus loin dans le réseau du FAI,
- Le tunnel IPv6-sur-IPv4 qui commence à la HG et se termine au routeur CGN,
- Le réseau purement IPv4 du FAI,
- Le CGN, une très grosse boîte,
- Des serveurs restés purement v4 sur le réseau du FAI (serveur Web du portail, par exemple),
- L'accès à l'Internet, en IPv4 et en IPv6.
Les deux composants nouveaux, que n'a pas forcément le FAI aujourd'hui, sont le HG et le CGN. Le HG doit obéir au RFC 7084. Autrement, tous les équipements (routeurs classiques et machines terminales) ne changent pas (cf. section 2.5).
Quelle technique de tunnel choisir entre le HG et le CGN ? La section 2.2 rappelle les possibilités. Les tunnels configurés manuellement du RFC 4213 paraissent peu pratiques. Ceux du RFC 3053 peuvent ne pas être très utilisables par l'utilisateur résidentiel. Cela laisse 6rd (RFC 5969) et peut-être GRE (RFC 2784). Si le FAI a déjà une infrastructure MPLS, il peut aussi considérer RFC 4798, mais cela suppose que MPLS aille jusqu'au HG, ce qui est peu probable. Bref, le RFC recommande 6rd.
La section 2.3 peut alors décrire en détail le fonctionnement de la HG (Home Gateway, la box). Lorsqu'elle reçoit un paquet de l'intérieur :
- Si c'est un paquet IPv4, elle le fait suivre sur l'infrastructure v4 normale du FAI (peut-être après traduction), jusqu'au CGN qui fera alors une traduction v4-v4 (il aura donc pu y avoir deux traductions),
- Si c'est un paquet IPv6, elle l'encapsule pour l'envoyer, via le tunnel, jusqu'au CGN (le gros routeur/traducteur situé plus loin dans l'infrastructure du FAI).
Et le CGN (Carrier-Grade NAT, un routeur NAT qui sert plusieurs clients) ? La section 2.4 lui est consacrée. Lorsqu'il reçoit un paquet IPv4 venu d'une HG (rappelons que tout ce RFC est consacré au cas où l'infrastructure du FAI est purement IPv4), deux cas :
- C'est un paquet v4 normal, et on le transmet après traduction (puisque le FAI n'a pas assez d'adresses IPv4 publiques, le paquet a certainement une adresse source privée) ; comme tout routeur NAT, le CGN mémorise la correspondance port<->adresse,
- C'est un paquet IPv6 encapsulé dans du v4. Le CGN le décapsule, et le transmet.
Voilà, sur le papier, c'est tout simple. Quelles sont les conséquences pratiques ? La section 2.7 discute divers points. D'abord, comme toute solution à base de NAT, notre schéma a tous les inconvénients du partage d'adresses. Pire, comme le CGN est situé loin de l'utilisateur, et que celui-ci ne peut pas le configurer, des techniques permettant d'avoir des connexions entrantes comme les correspondances statiques ou comme UPnP ne fonctionnent plus. D'autre part, le tunnel v6-sur-v4 entre le HG et le CGN posera les habituels problèmes de MTU (dont le RFC se débarasse avec une pirouette).
L'originalité de l'approche de ce RFC est la possibilité de migrer de cette solution NAT complexe et fragile vers une solution IPv6 propre. Comment ? C'est ce que décrit la section 3, qui prévoit plusieurs étapes, en supposant :
- On installe un CGN pour faire du NAT444. À court terme, cela réduit la demande en adresses IPv4 publiques. Mais cela n'aide pas en soi à migrer vers IPv6. Le HG doit être mis à jour pour utiliser le CGN.
- On déploie 6rd (nouvelle mise à jour du logiciel du CGN),
- On déploie alors tranquillement IPv6 sur le réseau du FAI. Dès que la zone desservie a un routage IPv6, on peut couper 6rd dans le HG, supprimant ainsi le tunnel v6-sur-v4 (IPv4 continuant à être envoyé au CGN). Cette coupure du tunnel peut se faire automatiquement, si le HG a été programmé pour détecter les RA (Router Advertisment) ou réponses DHCP IPv6.
- Cette dernière possibilité suppose une forme de double-pile (v4 et v6) sur le réseau du FAI pendant un temps. Si celui-ci préfère n'avoir qu'un seul protocole à gérer, l'approche est au contraire de basculer du routage purement v4 du début à un routage purement v6. C'est alors IPv4 qui sera tunnelé, via DS-Lite. Le FAI sera alors arrivé jusqu'au bout, il sera purement IPv6.
Comme indiqué, le passage d'une étape à une autre peut être détecté automatiquement par le HG, la box, qui peut par exemple interroger le CGN pour noter les nouvelles fonctions disponibles. Cela éviterait une action explicite sur la HG.
Il reste à étudier les conséquences de ce schéma en terme de
sécurité (section 4). Le NAT en général pose de nombreux problèmes de
sécurité (RFC 2663 et RFC 2993). Le partage massif
d'adresses, par exemple dans un CGN, crée des failles expliquées dans
le projet de RFC draft-ietf-intarea-shared-addressing-issues. Les
protocoles spécifiques utilisés ont également leurs propres questions
de sécurité, documentées dans leur norme respective (par exemple, pour
6rd, dans la section 12 du RFC 5969).
Toutefois, le fait que ce schéma concerne uniquement des mécanismes utilisés à l'intérieur du réseau d'un FAI, la sécurité est simplifiée. On peut certes sécuriser les tunnels avec le RFC 4891 mais ce n'est peut-être pas nécessaire, à l'intérieur d'un réseau unique et géré.
Par construction, il n'y a pas d'implémentation complète de ce RFC, mais des implémentations de certaines des fonctions. Par exemple, DS-Lite est mis en œuvre dans AFTR.
L'article seul
RFC 6266: Use of the Content-Disposition Header Field in the Hypertext Transfer Protocol (HTTP)
Date de publication du RFC : Juin 2011
Auteur(s) du RFC : J. Reschke (greenbytes)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 6 juin 2011
Le protocole HTTP ne sert pas qu'à récupérer
des pages HTML qu'on va afficher à
l'utilisateur. Une part importante de ses usages est la récupération
de fichiers qu'on enregistrera sur le stockage local. Quel nom donner
au fichier local ? HTTP dispose depuis longtemps d'un en-tête dans les
réponses, Content-Disposition:, qui fournissait
des suggestions de noms. Cet en-tête était imparfaitement normalisé et
traité un peu à part. Ce nouveau RFC en fait un élément standard et
rigoureusement défini de la panoplie HTTP.
Cet en-tête était donc décrit dans les RFC 2616 (section 19.5.1, qui prend des pincettes et affirme que cet en-tête n'est décrit que parce qu'il est largement mis en œuvre mais qu'il ne fait pas vraiment partie de la norme) et RFC 2183. La description était incomplète, notamment question internationalisation.
La grammaire formelle de cet en-tête est désormais décrite en section 4. Voici un exemple :
Content-Disposition: Attachment; filename=example.txt
Cette réponse HTTP demande que le fichier soit traité comme un
attachement, à enregistrer, et que le nom suggéré est
example.txt. Le premier terme se nomme le
type (section 4.2) et à la place du
Attachment qu'on a ici, on pourrait avoir
Inline qui suggère au client HTTP d'afficher le
fichier, plutôt que de l'enregistrer (c'est le comportement par défaut
en l'absence de l'en-tête
Content-Disposition). Les types et les noms de
paramètres (ci-dessous) sont insensibles à la casse.
Après le type et un point-virgule, on trouve
des paramètres. Ici, le paramètre
filename était indiqué, pour proposer un nom de
fichier. À noter que ce paramètre peut être complété par un
filename*, doté de possibilités étendues,
notamment celle de suggérer des noms comportant des caractères
non-Latin1 (cf. RFC 8187, section 6 et annexe C). Ce filename* est plus récent et
pas compris de tous les clients HTTP. L'idée est que le serveur
moderne envoie les deux, le client ancien ne gardera que
filename (qui est « sûr ») et le client nouveau
n'utilisera que filename*. Voici un exemple
suivant ces recommandations :
Content-Disposition: attachment;
filename="EURO rates";
filename*=utf-8''%e2%82%ac%20rates
Ce fichier sera enregistré, par un client récent, sous le nom
€ rates.
J'ai utilisé à plusieurs reprises des verbes comme « suggérer » ou
« proposer » car le client HTTP reste maître du choix du nom. Il est
même important qu'il n'accepte pas aveuglément n'importe quel nom
donné par le serveur
(imaginez une machine Unix où le navigateur Web
stockerait le fichier sous le nom /etc/passwd
sans réfléchir). Plus précisement, insiste le RFC (sections 4.3 et 7), le client HTTP
doit :
- N'autoriser l'écriture du fichier que dans les dossiers ou répertoires choisis. Le mieux est d'ignorer complètement tout chemin inclus dans le nom (ne garder que le nom de fichier proprement dit).
- Se méfier de l'extension (dans le premier exemple,
.txt). Avec certains systèmes d'exploitation comme Windows, c'est cette extension (et pas le type MIME - RFC 2046 - envoyé avec le fichier) qui détermine le comportement associé au fichier. Un nom se terminant en.exepeut donc avoir des conséquences ennuyeuses. - Certains caractères sont spéciaux pour le système d'exploitation qui va stocker le fichier (comme le point-virgule ou le tube sur Unix) et il vaut donc mieux les supprimer avant d'enregistrer. Même chose, bien que moins dangereux, pour des noms qui pourraient perturber l'interface utilisateur, comme les espaces pour Unix : ils sont légaux mais pas pratiques à gérer depuis le shell.
Un bon exemple de faille de sécurité provoquée par le non-respect de
ces règles figure en en http://securitytracker.com/id?1024583.
La section 4.4 ajoute qu'il faut ignorer les paramètres inconnus
(pour permettre l'extensibilité ultérieure). Les en-têtes invalides
devraient être ignorés par les clients HTTP. De nombreux détails sur
le traitement de Content-Disposition: par les
clients figurent dans l'excellente page http://greenbytes.de/tech/tc2231/.
Les clients HTTP, par exemple les navigateurs Web, respectent-ils
cette norme ? Actuellement, Firefox,
Opera et Konqueror le
font, ainsi que Chrome depuis sa version 9
(parait-il : ça ne marche pas chez moi) et
Internet Explorer depuis sa version
9. Cela ne signifie pas qu'ils gèrent tout et notamment Firefox 3
semble ignorer le paramètre de nom de fichier international,
filename* (bogue #588781). wget semble ignorer l'indication de nom de
fichier par défaut. Il faut lui ajouter l'option
--content-disposition pour que cela marche. C'est
encore pire pour curl dont l'auteur refuse
de gérer Content-Disposition: et fait semblant de
croire que l'option --remote-name le
remplace. lynx a une amusante bogue : il inclus
le point-virgule qui suit (s'il y a un deuxième paramètre), dans le nom de fichier.
À noter que le registre des en-têtes (section 8.2) et celui des
paramètres de Content-Disposition: (section 8.1) sont utilisés
par d'autres protocoles que HTTP (cf. section 4.5).
L'annexe A résume les changements par rapport au RFC 2616, le premier qui mentionnait cet en-tête
Content-Disposition: dans le cadre de HTTP. Le
principal est l'ajout des capacités d'internationalisation du RFC 8187. Mais il y a aussi quelques détails, comme
la suppression de la restriction qui limitait cet en-tête aux
ressources de type application/octet-stream. L'annexe B, elle, résume les changements depuis le RFC 2183. Ils consistent essentiellement en l'abandon de
paramètres intéressants mais qui, en pratique, n'ont jamais été mis
en œuvre par les clients HTTP, comme
creation-date ou size.
L'annexe C discute l'approche d'internationalisation utilisée dans ce RFC, en comparant avec les alternatives. Un peu d'histoire : les en-têtes HTTP sont historiquement limités à ISO 8859-1 (RFC 2616, section 2.2 ; j'ai bien dit ISO 8859-1 et pas ASCII ; c'est ainsi que ce blog émettait un en-tête en ISO 8859-1, qui avait planté quelques logiciels qui n'avaient pas bien lu le RFC 2616 ; le RFC 7230, depuis, a supprimé cette possibilité). C'est évidemment une limite unsupportable. La solution standard, depuis belle lurette (RFC 2231, en 1997) est d'encoder les caractères Unicode en « notation pourcent ». Le RFC 8187, plusieurs fois cité ici, est l'application de ce principe à HTTP. Mais les clients HTTP, notamment les navigateurs, ont très souvent essayé des approches non-standard. Pourquoi n'ont-elles pas été reconnues dans notre RFC 6266 ?
Par exemple, certains ont implémenté les encodages du RFC 2047, même si ce RFC précisait bien qu'ils ne
devaient pas être utilisés dans les en-têtes. D'autres gèrent
l'encodage pourcent (RFC 3986, section 2.1) dans le paramètre filename,
ce qui encourage les serveurs à l'utiliser ainsi, semant la confusion
chez les navigateurs. Ainsi, si le nom de fichier est
caf%C3%A9.html, certaines navigateurs
l'enregistreront sous le nom café.html et
d'autres sont le nom caf%C3%A9.html. Plus rigolo, certains navigateurs
pratiquent l'examen du nom du fichier et appliquent diverses
heuristiques pour déterminer son contenu (« Hmmm, on dirait de
l'UTF-8 encodé pour-cent... Je vais essayer ça. ») C'est évidemment
très fragile. Le tableau « Test Result Summary » en
http://greenbytes.de/tech/tc2231/ résume fort bien le
comportement actuel des navigateurs Web.
Les programmeurs, enfin, ont tout intérêt à lire l'annexe D, qui rassemble les conseils pour les développeurs de serveurs HTTP et d'applications Web (en pratique, c'est souvent le framework de développement, pas le serveur HTTP, qui génère ces en-têtes). Parmi les conseils :
- Inclure un paramètre
filenamesi l'ASCII suffit (ce devrait être Latin-1 mais le RFC note qu'il n'est pas prudent de compter dessus, trop de programmeurs n'ont pas lu le RFC 2616 et ne gèrent pas correctement le non-ASCII et, de toute façon, le RFC 7230 a modifié la règle depuis), - Inclure un paramètre
filename*si l'ASCII ne suffit pas, tout en sachant que bien des clients Web ne le cherchent pas et n'utiliserons quefilename; le RFC suffère donc de mettre les deux, une version dégradée du nom étant présente dansfilename(cela est possible en français, voir l'exemple ci-dessous, mais pas tellement en arabe), - Utiliser uniquement UTF-8 comme encodage
de
filename*.
Notez que le moteur de recherche de
mon blog produit des en-têtes
« Content-Disposition: » en respectant, je
l'espère, les conseils de cette annexe D...
% wget --server-response 'http://www.bortzmeyer.org/search?pattern=café chocolat&format=atom' ... Server: Apache/2.2.9 (Debian) mod_wsgi/2.5 Python/2.5.2 Content-Disposition: Inline; filename=bortzmeyer-search-caf--chocolat.atom; filename*=UTF-8''bortzmeyer-search-caf%C3%A9-or-chocolat.atom Content-Type: application/atom+xml; charset="utf-8" ...
(Si vous lisez le code
source, c'est dans wsgis/search.py.)
L'article seul
RFC 6270: The 'tn3270' URI Scheme
Date de publication du RFC : Juin 2011
Auteur(s) du RFC : M. Yevstifeyev
Chemin des normes
Première rédaction de cet article le 6 juin 2011
Ce RFC n'aura pas un grand intérêt pratique, vu le petit nombre de terminaux 3270 encore en service ! Mais il était nécessaire pour compléter la liste des plans (schemes) d'URI, qui le mentionnait sans vraiment le décrire.
En effet, le désormais dépassé RFC 1738
mentionnait la possibilité d'avoir des URL
comme tn3270:mainframe.accounting.example mais
sans expliquer leur syntaxe ou leur sémantique. 3270 est une référence
aux vieux terminaux des
mainframes
IBM d'il y a très longtemps. Ces terminaux sont
décrits dans les RFC 1041, RFC 1576 et RFC 2355.
Le RFC 1738 a été remplacé il y a longtemps, par le RFC 3986, qui décrit la syntaxe générique des URI. Mais ce petit point
spécifique du tn3270: n'avait jamais été traité. Notre RFC 6270 comble donc le vide en spécifiant
rigoureusement syntaxe et sémantique des URI
tn3270:. La sémantique est très proche de celle
des URI telnet: du RFC 4248. Le plan
tn3270: est donc désormais, en suivant les règles
du RFC 4395, enregistré dans le registre des plans d'URI.
L'article seul
Exposé « Peut-on éteindre l'Internet » au SSTIC à Rennes
Première rédaction de cet article le 1 juin 2011
Dernière mise à jour le 10 juin 2011
Du 8 au 10 juin s'est tenu à Rennes le Symposium sur la Sécurité des Technologies de l'Information et des Communications (SSTIC), la principale conférence francophone sur la sécurité informatique. J'y ai présenté un exposé sur un thème déjà traité sur mon blog, « Peut-on éteindre l'Internet ? ».
Mon article et les transparents de mon exposé sont disponibles sur le site du SSTIC ainsi qu'ici :
- L'article complet, format PDF :
sstic-article-eteindre.pdf. - Le source de l'article en LaTeX :
sstic-article-eteindre.tex. - Les transparents en PDF, version adaptée à la vue sur écran :
sstic-transparents-ecran-eteindre.pdf. - Les transparents en PDF, version adaptée (plus ou moins) à l'impression :
sstic-transparents-impression-eteindre.pdf. - Source LaTeX des transparents :
sstic-transparents-eteindre.tex.
Il y avait aussi plein d'autres exposés intéressants, voyez le programme. Je ne peux pas tous les décrire ici mais voici une liste très partielle des exposés que j'ai apprécié et qui ont mis leurs supports en ligne :
- Joanna Rutkowska, l'auteur de Qubes, a décrit son exposé qui portait sur la sécurité du poste client.
- Graham Steel a parlé de l'outil Tookan d'attaque des « tokens » sécurisés.
D'autres personnes ont mis en ligne des trucs sur SSTIC comme sid, Éric Freyssinet, N0secure, Serianox, Yvan Vanhullebus, Hervé Schauer, etc.
L'article seul
Petits conseils lorsqu'on pose une question sur un forum
Première rédaction de cet article le 30 mai 2011
Il existe déjà plusieurs documents expliquant comment poser intelligemment une question sur un forum ou une liste de diffusion. Je ne vais pas prétendre les concurrencer, juste mettre en avant quelques points que je trouve particulièrement importants. Il m'est arrivé de voir une question mal posée, et de ne pas réagir parce que je n'avais pas le courage de rédiger une critique argumentée. Désormais, je n'aurai qu'à donner l'URL de ce document. Les exemples sont presque tous tirés du monde TCP/IP et visent particulièrement les gens qui configurent des services Internet.
Le texte de référence est évidemment celui d'Eric Raymond, « How To Ask Questions The Smart Way » (qui dispose d'une bonne traduction en français). (Et je suis sûr que mes lecteurs vont suggérer d'autres textes.) Vous avez tout intérêt à lire le texte de Raymond à la place du mien. Si vous insistez, voici les conseils qui me semblent à la fois particulièrement importants et particulièrement souvent violés.
Donnez les vraies informations. Il n'existe pas de raison impérative de dissimuler les noms et les adresses IP utilisées. Au contraire, si vous indiquez les vraies adresses, les lecteurs pourront les essayer plus facilement. Une des particularités de l'Internet est son ouverture : tout le monde voit la même chose et peut donc tester pour les autres. Si vous donnez les vrais noms, les lecteurs du forum ou de la liste pourront tester avec dig sur leur machine, et résoudre ainsi vos problèmes DNS. Si vous donnez les vraies adresses IP, les lecteurs pourront déboguer votre problème de routage avec traceroute et avec les looking glasses. Autre raison d'utiliser les vrais identificateurs : vous risquez moins de vous tromper (combien de fois ai-je vu des descriptions du problème où deux machines ont la même adresse IP...) Quels sont les cas où il est acceptable de ne pas donner les vraies noms ou adresses ?
- Si le problème est purement théorique. Auquel cas, il n'y a pas
de vrais noms ou de vraies adresses. On voit parfois des gens utiliser
alors des noms qu'ils croient clairs mais qui peuvent entrainer la
confusion avec un vrai domaine (oui,
toto.frexiste vraiment) ou bien des adresses IP privées, tirées du RFC 1918. Dans les deux cas, il vaut mieux utiliser les identificateurs conçus pour cela : les noms d'exemples du RFC 2606 (example.org,toto.example, etc), et les adresses IP de documentation des RFC 5737 et RFC 3849 (192.0.2.0/24,198.51.100.0/24,203.0.113.0/24et2001:db8::/32). Vous évitez ainsi toute confusion avec des identificateurs réels. - Si les exigences de sécurité sont spécialement fortes, ou s'il faut protéger la vie privée de quelqu'un (un client, par exemple). Attention, j'insiste sur le « spécialement fortes ». On voit souvent des gens mettre des faux noms « pour des raisons de sécurité » alors qu'ils sont incapables d'expliquer pourquoi cela poserait un problème de sécurité.
- Steeve Ortuani me signale un autre cas amusant où l'utilisation
des vrais noms a eu des conséquences imprévues : le forum où était
posé la question était bien référencé et les requêtes ultérieures dans
un moteur de recherche, pour
ce nom de domaine, amenaient à la page « Problème DNS avec
example.com». Dans un tel cas, une bonne solution est de dupliquer la configuration du domaine en cause vers un domaine bidon, ne servant qu'aux tests.
Donnez le maximum de détails sur votre environnement : système d'exploitation utilisé, version, type de réseau (Ethernet ? 3G ?). N'oubliez pas que vos lecteurs ne sont pas dans votre tête : pour vous, il est évident que votre machine 192.0.2.34 est un routeur Extreme mais les autres ne le savent pas.
Faites des schémas. Un bon croquis vaut souvent mieux que bien des
discours. Comme il n'existe pas de norme largement répandue pour
transmettre des dessins (les faire sur sa machine est les distribuer
avec un service d'hébergement d'images ?), le mieux est d'utiliser l'art ASCII. Avec le mode picture de l'éditeur Emacs, c'est assez facile. En voici un exemple, avec indication des noms des routeurs (ce qui facilite beaucoup les discussions ultérieures) et des interfaces :
TO THE INTERNET
+--------------------+ Management network 198.51.173.0/28
|SuperNet | +-------------
|(upstream provider) | |
+--------------------+ |
| |
| Serial0 | eth1 (.1)
+---------------+ +----------------+
| nelson | | steve |
|(cisco router) | | (linux router) |
+---------------+ +----------------+
/ | | Ethernet0 (.65) | eth0 (.68)
/ | +----------------------------------------------
/ | Backbone 198.51.173.64/26
PtP links
to customers
198.51.173.32/27
Voir aussi mon article « Faire des schémas avec un langage et pas avec la souris ».
Soyez factuel : donnez les commandes exactes que vous avez
utilisées, les résultats exacts de ces commandes. Faites du
copier/coller, pas de la traduction ou du résumé. Rien de plus
frustrant que de passer dix minutes à chercher à comprendre un message
d'erreur, avant de se rendre compte qu'il s'agissait simplement d'une
mauvaise traduction faite par le demandeur. Quant aux résumés, ils
sont en général encore pires car ils reflètent les suppositions
(souvent erronées) du demandeur, pas les faits précis. Donc, dites
« Je tape ping www.toto.example et j'ai une
réponse ping: unknown host www.toto.example » et
surtout pas « Je pingue la machine mais il ne veut pas » (oui, ça fait
rire mais tous les jours, sur les forums et les listes de diffusion,
on voit des messages à peine meilleurs). Et si le message est trop
long (certaines commandes peuvent être très bavardes) ? Utilisez alors
un pastebin. En tout
cas, ne faites surtout pas de copie
d'écran : elles sont difficiles à lire, on ne peut pas
copier/coller ce qui y est
affiché, elles ne sont pas indexées par les moteurs de recherche, donc d'autres personnes
ne pourront pas tomber sur votre rapport. Et votre fond d'écran n'intéresse que vous.
L'article seul
RFC 6180: Guidelines for Using IPv6 Transition Mechanisms during IPv6 Deployment
Date de publication du RFC : Mai 2011
Auteur(s) du RFC : J. Arkko (Ericsson), F. Baker (Cisco Systems)
Pour information
Première rédaction de cet article le 28 mai 2011
IPv6 fait souvent peur aux administrateurs réseaux par le nombre de techniques de coexistence entre IPv4 et IPv6. Ces techniques sont variées, et inévitables, puisque la transition a pris un retard considérable, ce qui mène à devoir déployer IPv6 alors que les adresses IPv4 sont déjà épuisées. Ce RFC 6180 vise à simplifier la tâche dudit administrateur système en le guidant parmi les techniques existantes.
Il ne s'agit donc pas de normaliser le Nième protocole de transition et/ou de coexistence entre IPv6 et IPv4, plutôt de faire le point sur les protocoles existants, dont le nombre a de quoi effrayer. Mais il ne faut pas paniquer : selon le cas dans lequel on se situe, toutes ces techniques ne sont pas forcément pertinentes et il n'est donc pas nécessaire de les maîtriser toutes.
D'abord, notre RFC 6180 rappelle qu'il n'y a pas le choix : la réserve IPv4 de l'IANA a été épuisée en février 2011 et celle des RIR le sera fin 2011-début 2012. IPv6 est donc la seule solution réaliste. Le point sur la transition est fait dans le RFC 5211 et elle a commencé il y a longtemps, dans les organisations les mieux gérées. Un des points qui la freine est que l'administrateur réseaux normal, celui qui ne suit pas heure par heure les travaux de l'IETF, voit un grand nombre de techniques de coexistence IPv4/IPv6 (le Wikipédia anglophone a excellente page de synthèse sur ces techniques) et se demande « Dois-je donc déployer 6to4 et 6rd et DS-lite et NAT64 et donc maîtriser toutes ces techniques ? ». La réponse est non : selon son réseau, notre malheureux administrateur n'aura à gérer qu'une partie de ces méthodes.
Déjà, il faut comprendre ce que ces termes barbares veulent dire : la section 2 rappelle la terminologie, et les RFC à lire.
La section 3 décrit ensuite les principes suivis dans le RFC : le premier est de garder en tête le but, qui est de pouvoir continuer la croissance de l'Internet sans être gêné par des problèmes comme le manque d'adresses. Pour cela, le but final de la transition doit être le déploiement complet d'IPv6 natif dans tout l'Internet. Lorsque cela sera réalisé, toutes les techniques de transition et de coexistence pourront être abandonnées, simplifiant ainsi beaucoup la situation. Mais pour atteindre ce but lointain, il n'y a pas qu'une seule bonne méthode. Par contre, ces méthodes ont quelques points en commun. Il est par exemple essentiel de s'y prendre à l'avance : les adresses IPv4 sont déjà épuisées et une organisation qui n'aurait encore rien fait du tout, question IPv6, va avoir des problèmes. Donc, aujourd'hui, En tout cas, il n'existe pas de raison valable de retarder le déploiement d'IPv6. Ceux qui n'ont pas encore commencé devraient s'y mettre immédiatement.
Mais cela implique une longue période de coexistence avec IPv4. Pas pour tout le monde : il existe des réseaux un peu particuliers, des déploiements récents, contrôlés par une seule organisation, dans un environnement fermé (une usine, par exemple) et qui n'ont pas besoin d'échanger avec le reste du monde. Ceux-ci peuvent faire de l'IPv6 pur et ne pas lire ce RFC. Mais tous les autres doivent se poser la question « Qu'est-ce que je fais avec mes deux protocoles ? ».
Et cela va durer longtemps. Même si on peut espérer qu'un jour on éteigne la dernière machine IPv4, cela ne se produira pas avant de nombreuses années. Même si un réseau est entièrement IPv6, il faudra bien qu'il puisse communiquer avec des machines v4 à l'extérieur. (Le RFC ne mentionne pas le fait qu'actuellement, l'effort de la coexistence repose entièrement sur ceux qui veulent déployer IPv6. Une date importante sera celle où l'effort changera de camp et où ce sera ceux qui veulent continuer à utiliser IPv4 qui devront travailler pour cela. Cette date surviendra longtemps avant la disparition de la dernière machine IPv4.)
Ceux qui déploient IPv6 doivent donc choisir un modèle de déploiement. Le RFC 5218 rappelait, en s'inspirant de l'expérience de plusieurs protocoles, ce qui marche et ce qui ne marche pas. Certains de ces rappels semblent évidents (ne pas casser ce qui marche aujourd'hui, permettre un déploiement incrémental, puisqu'il n'y a aucune chance de faire basculer tout l'Internet d'un coup) mais sont toujours bons à garder en mémoire.
Voilà, après ces préliminaires, place aux techniques elle-mêmes, en section 4. Le début de cette section précise qu'elle n'est pas exhaustive : il existe d'autres mécanismes de coexistence/transition mais ils sont considérés comme relativement marginaux. Les techniques sont exposées dans l'ordre d'importance décroissante et les premières sont donc les plus recommandées.
Premier mécanisme de coexistence, et le plus recommandé, la double pile. Chaque machine a deux mises en œuvre des protocoles réseau, une pour IPv4 et une pour IPv6 et peut parler ces deux protocoles au choix. Ce modèle s'applique aussi bien sur la machine terminale (où les applications sont donc « bilingues ») que sur les routeurs du FAI (qui font tourner des protocoles de routage pour les deux familles, cf. RFC 6036 pour le point de vue du FAI). C'était le mécanisme de transition originellement envisagé. Le choix de la version d'IP dépend de la machine qui initie la connexion (RFC 6724), et de ce que la machine réceptrice a annoncé (par exemple dans le DNS). Ce mécanisme est simple et évite les problèmes qu'ont, par exemple, les tunnels, comme les problèmes de MTU. Comme le rappelle le RFC 4213, c'est la méthode recommandée.
Cela n'empêche pas ce modèle d'avoir des failles. D'abord, si l'adoption de ce modèle est une décision individuelle de chaque réseau, son utilisation nécessite que les deux réseaux qui communiquent aient adopté ce système. Si un client double-pile veut se connecter à un serveur en IPv6, celui-ci doit avoir une connectivité IPv6 (ce qui dépend de son FAI), doit avoir une application IPv6isée et doit avoir annoncé un AAAA dans le DNS. Autrement, on a IPv6, mais on n'observe guère de trafic. Inversement, lorsqu'un gros fournisseur de contenu active IPv6 (comme l'a fait YouTube en février 2010), le trafic IPv6 fait soudain un bond.
Une deuxième limite de l'approche double-pile est que certaines applications ne réagissent pas proprement lorsqu'un des protocoles fonctionne mais pas l'autre. De nos jours, c'est en général l'IPv6 qui a un problème et la double-pile peut alors entraîner une dégradation du service, l'application perdant bêtement du temps à tenter de joindre le pair en IPv6 au lieu de basculer tout de suite vers IPv4. Le code naïf de connexion d'un client vers un serveur est en effet (en pseudo-code) :
for Address in Addresses loop
try
connect_to(Address)
exit loop
except Timeout
# Try the next one
end try
end loop
Cette approche purement séquentielle peut être pénible si les adresses
IPv6 sont en tête de la liste Addresses et si le
délai de garde est long. Car chaque connexion fera patienter
l'utilisateur plusieurs secondes. (La durée exacte avant le
Timeout dépend de la nature de la
non-connectivité IPv6 - le routeur envoie-t-il
un message ICMP ou pas, de ce que transmet la
couche 4 à l'application, etc.) C'est pour
cette raison que de nombreux gérants de gros services Internet
hésitent à activer IPv6 (par exemple, ce dernier est disponible pour
le service, mais n'est pas annoncé dans le DNS), de peur de pourrir la
vie d'une partie, même faible, de leurs utilisateurs. C'est ainsi que
www.google.com n'a d'enregistrement
AAAA que pour certains réseaux, que
Google estime suffisamment fiables en IPv6. Ce
mécanisme de « liste blanche » où Google décide qui va pouvoir se
connecter à eux en IPv6 est contestable mais n'oublions pas que les
autres « gros » sites Internet ne font rien du tout.
Rendre les applications plus robustes vis-à-vis de ce problème pourrait aider (voir par exemple la technique proposée par l'ISC ou bien le très bon guide de programmation IPv6 d'Étienne Duble), surtout si ces mécanisme de connexion intelligents (tenter en parallèle les connexions v4 et v6) sont emballés dans des bibliothèques standard. Par exemple, la plupart des applications pair-à-pair gèrent relativement bien ce problème, habituées qu'elles sont à vivre dans un monde de connectivité incertaine et intermittente.
Ces défauts sont à garder en tête mais il n'en demeure pas moins que la double-pile reste la meilleure méthode, d'autant plus que de nombreux réseaux ont aujourd'hui IPv6 (le RFC cite les NREN comme Renater ou Internet2, complètement IPv6 depuis longtemps).
Une conséquence amusante de la double-pile est qu'elle nécessite une adresse IPv4 par machine. Cela ne semblait pas un problème au moment où ce mécanisme a été conçu, puisqu'il semblait possible de passer tout le monde en IPv6 avant l'épuisement des adresses v4. Comme cela ne s'est pas fait, on se retrouve aujourd'hui dans une situation où il n'y a plus d'adresses IPv4. La double pile est donc en général utilisée avec une adresse IPv6 publique et une IPv4 privée, NATée plus loin.
La double pile, c'est très bien mais que faire si on n'a pas de connectivité IPv6, et qu'on veut relier son réseau IPv6 au reste de l'Internet v6 ? La section 4.2 expose la solution des tunnels. L'intérêt des tunnels est qu'ils ne nécessitent aucune action sur les routeurs situés sur le trajet. On n'a pas à attendre que son FAI se bouge le postérieur et déploie IPv6. C'est une technique connue et éprouvée, qui est d'ailleurs utilisée pour bien d'autres choses qu'IPv6. L'inconvénient des tunnels est la complexité supplémentaire, et le fait qu'ils réduisent la MTU entraînant tout un tas de problèmes avec les sites qui bloquent stupidement l'ICMP.
Il existe plusieurs types de tunnels : les tunnels manuels du RFC 4213, des tunnels automatiques comme 6to4 (RFC 3056), les serveurs de tunnel présentés dans les RFC 3053 et RFC 5572, et bien d'autres, résumés dans le RFC 5565.
Lorsque le tunnel fait partie d'une solution gérée par un administrateur réseaux compétent, il ne pose pas de problème en soi. Mais certaines solutions techniques (comme 6to4) sont prévues pour être « non gérées » et elles ont toujours posé beaucoup de problèmes. Ainsi, elles peuvent donner aux applications l'impression qu'une connectivité IPv6 fonctionne alors qu'en fait les paquets ne reviennent pas. Beaucoup d'applications tentent alors de se connecter en IPv6 et mettent longtemps avant de s'apercevoir que cela ne marchera pas et qu'il vaut mieux se rabattre sur IPv4. 6to4 a donc beaucoup contribué à la réputation d'IPv6 comme technologie fragile et source d'ennuis. (La solution 6rd - RFC 5969, quoique dérivée de 6to4, n'a pas ces défauts.)
Pour l'instant, IPv6 est peu déployé et ce sont les gens qui veulent utiliser ce protocole qui doivent faire des efforts pour se connecter. Désormais que les adresses IPv4 sont épuisées, on commencera bientôt à voir des déploiements purement IPv6 et il faudra alors faire des efforts pour maintenir les vieux systèmes v4. Les sections 4.3 et 4.4 couvrent ces cas. En 4.3, la question est celle d'un nouvel entrant dans le monde des opérateurs qui n'a pas eu d'adresses IPv4 pour son beau réseau tout neuf et qui a donc déployé un cœur purement v6 ce qui, après tout, simplifie sa configuration. Mais ses clients, et les partenaires auxquels ses clients essaient de se connecter, sont restés en v4. Comment leur donner la connectivité qu'ils désirent ? Il va falloir cette fois tunneler IPv4 sur IPv6. Le modèle recommandé est DS-lite (Dual Stack Lite), dont le RFC n'est pas encore publié. Le principe est que le client recevra uniquement des adresses IPv4 privées, que le CPE fourni par le fournisseur d'accès encapsule les paquets IPv4 qu'émettrait un client, les tunnele jusqu'à un équipement CGN qui décapsulera, puis procédera au NAT44 classique. Le nouveau FAI aura donc quand même besoin de quelques adresses IPv4 publiques. Il existe déjà une mise en œuvre en logiciel libre de la fonction CGN, AFTR.
Autre cas, légèrement différent, est celui où le réseau local connecté à l'Internet n'a pas d'équipement IPv4 du tout. Tout beau, tout neuf, toutes ses machines (et les applications qu'elles portent) sont purement IPv6. Ce n'est pas aujourd'hui très réaliste avec des machines et des applications ordinaires mais cela pourrait arriver avec de nouveaux déploiements dans des environnements modernes. Le problème, décrit en section 4.4, est alors de se connecter quand même à d'éventuels partenaires restés v4. Une des solutions est le passage par un relais (j'en ai fait l'expérience lors d'un atelier de formation et Apache fait un très bon relais pour HTTP, permettant aux machines purement IPv6 de voir tout le ouèbe v4). Une autre solution est NAT64 (RFC 6144).
Puisqu'un certain nombre de trolls ont deversé du FUD sur la sécurité d'IPv6, la section 7, consacrée à ce sujet, est une bonne lecture. Elle rappelle que IPv6 a en gros le même niveau de sécurité qu'IPv4, c'est-à-dire pas grand'chose et que ce sont les implémentations et les déploiements qui apportent des risques, plus que les spécifications. Par contre, chaque technique de transition a ses propres risques de sécurité, en plus de ceux d'IPv6 ou d'IPv4 mais notre RFC ne les détaille pas, renvoyant aux normes décrivant ces techniques.
Conclusion ? La section 5, après cette longue énumération de bricolages variés recentre le débat : l'essentiel est d'activer IPv6. Une fois ce principe posé, cette section rappelle des points mentionnés au début comme le fait qu'il ne faut pas appliquer aveuglément la même technique à tous les réseaux. Ainsi, un réseau tout neuf ne fera sans doute pas les mêmes choix qu'un réseau existant depuis vingt et ayant accumulé plein de technologies historiques.
La section 6 propose une bibliographie pour ceux qui veulent approfondir le sujet : plein de RFC dont les RFC 4213, RFC 4038, RFC 6036, etc. D'autre part, j'avais fait un exposé au GUILDE à Grenoble sur ces sujets (IPv6 et la transition), exposé dont les transparents sont disponibles.
L'article seul
RFC 6256: Using Self-Delimiting Numeric Values in Protocols
Date de publication du RFC : Mai 2011
Auteur(s) du RFC : W. Eddy (MTI Systems), E. Davies (Folly Consulting)
Pour information
Première rédaction de cet article le 26 mai 2011
Comment encoder des valeurs dans un protocole ? Il existe des tas de méthodes mais celle de ce RFC 6256, les « valeurs numériques auto-terminées » (SDNV pour Self-Delimiting Numeric Values) sont encore très peu connues et guère utilisées.
Soit un concepteur de protocoles réseau. Il doit indiquer dans les données qui circulent des valeurs, par exemple un gâteau qui identifie une session ou bien une durée ou une longueur ou bien une clé cryptographique ou des tas de choses encore. Comment transmettre ces valeurs (section 1.1) ? Une technique courante, très utilisée dans les protocoles « binaires » comme IP (RFC 791) ou bien le DNS (RFC 1035) est le champ de taille fixe. On décide que la longueur sera représentée sur 16 bits et les producteurs et les lecteurs de ce champ connaissent cette taille, qu'ils ont lu dans le RFC correspondant. Plus la taille est grande, plus on consomme de ressources réseaux pour la transmettre mais, plus elle est petite, et moins on pourra représenter de valeurs. Dans mon exemple, que fera t-on si les changements dans les techniques ou dans les usages nécessitent de stocker des longueurs supérieurs à 65 536 ? Le problème est fréquent car des protocoles sont souvent utilisés pour des dizaines d'années consécutives, années pendant lesquelles les hypothèses de base ont changé. Le RFC cite ainsi les exemples de la fenêtre TCP (RFC 793, la fenêtre est limitée à 16 bits, soit 65 kilo-octets, ce qui est bien trop peu pour les réseaux à 10 Gb/s d'aujourd'hui, et a nécessité le hack de l'échelle de fenêtre du RFC 1323, désormais en RFC 7323) et du bien connu champ Adresse d'IPv4, qui s'est montré trop petit. Le RFC note bien que les deux décisions avaient semblé raisonnables à l'époque : sur une ligne spécialisé à 64 kb/s, la fenêtre maximale était de huit secondes, ce qui donnait largement aux accusés de réception le temps de revenir. Aujourd'hui, la même taille ne laisse que 50 microsecondes... Même problème pour les adresses IPv4, épuisées par le changement du modèle de l'ordinateur (de « un par entreprise » à « plusieurs par personnes ») et par le succès inespéré de l'Internet. Les SDNV permettent donc d'éviter de prendre des décisions (« 16 bits ? 32 bits ? Allons-y pour 16 bits, ça suffira bien. ») qu'on regrettera ensuite.
Une autre approche, commune à l'IETF, est d'utiliser TLV. C'est le mécanisme le plus souple, mais, pour des valeurs assez petites, il prend plus de place que SDNV.
Le groupe de recherche IRTF DTNRG, qui est occupé notamment à développer des protocoles réseau pour les vaisseaux spatiaux (cf. RFC 4838) a son idée sur la question (la section 4 présente une discussion des alternatives), et cela a donné ce RFC. Par exemple, dans l'espace, vu le RTT, les protocoles qui négocient des paramètres au début de la connexion (comme l'échelle de fenêtre TCP), et qui permettent ainsi d'avoir des champs de taille fixe et de choisir la taille au début de la connexion, ne sont pas envisageables. Mais le problème n'est pas spécifique aux réseaux « DTN » (Delay-Tolerant Networking, les réseaux où l'acheminement d'un bit prend un temps fou, ce qui est le cas dans l'espace où la vitesse de la lumière est une limite gênante, cf. RFC 5325) et on peut retrouver des ancêtres de SDNV dans des encodages ASN.1 ou bien dans certains protocoles UIT. Par contre, en dehors du projet DTN, il ne semble pas que les SDNV aient été utilisés par des protocoles IETF, peut-être parce que leur encodage et décodage est plus lent qu'avec des champs de taille fixe (le protocole WebSocket utilise les SDNV). À noter que notre RFC n'est pas la premier à normaliser SDNV, ceux-ci avaient déjà été décrits dans les RFC 5050 et RFC 5326 mais de manière sommaire. Un description plus complète n'était donc pas du luxe.
SDNV se limite à représenter des entiers positifs ou des chaînes de bits. Pour des types plus complexes, on peut utiliser les encodages d'ASN.1 ou bien MSDTP (décrit dans le RFC 713).
Après ces préliminaires, attaquons-nous à la définition d'un SDNV (section 2). Un SDNV est encodé sous forme d'une série d'octets en n'utilisant que sept bits de chaque octet. Le huitième indique si l'octet est le dernier du SDNV. Ce mécanisme impose un décodage strictement séquentiel, en examinant un octet après l'autre. Quelques exemples :
- Le nombre 3 est représenté par 00000011. Le premier bit, ici à zéro, indique que ce premier octet est aussi le dernier.
- Le nombre 130 est représenté par 1000001 00000010. Le premier bit du premier octet indique que cet octet n'est pas le dernier. Le dernier bit du premier octet est celui qui code 128. (On ne peut pas utiliser le premier bit du deuxième octet, réservé pour indiquer la fin de la série des octets.)
L'annexe A contient d'autres exemples et j'en montre certains à la fin de cet article. Il y a quelques détails pratiques comme les zéros initiaux : le premier nombre est-il 3 où 03 ? Le RFC explique que les zéros initiaux ne sont pas significatifs. Pour les nombres, cela ne change évidemment rien (3 = 03) mais si on voulait représenter des chaînes de bits, c'est plus compliqué et SDNV ne fournit pas de solution satisfaisante (le RFC suggère par exemple d'indiquer explicitement la longueur dans un autre champ, ce qui annule l'intérêt de SDNV ; une autre suggestion est de toujours mettre un bit à 1 au début de toute chaîne).
Les SDNV ont parfois été décrits sous le nom de Variable Byte Encoding (cf. le livre de Manning, Raghavan, et Schuetze, « Introduction to Information Retrieval », qui s'intéressait toutefois à la compression plutôt qu'à la souplesse). On peut remarquer qu'aucune valeur encodée en SDNV n'est un préfixe d'une valeur encodée en SDNV (SDNV est prefix-free, autre façon de dire que les données sont auto-terminées).
Comment encode et décode-t-on ces SDNV ? La section 3 décrit
quelques algorithmes qui peuvent être utilisés à cette fin. La section
3.1 contient un algorithme d'encodage très simple en O(log(N)) où N est le nombre à encoder. Le décodage
est plus sioux : on ne connait en effet pas la valeur du nombre avant
de l'avoir décodé et on ne sait donc pas quel type on doit utiliser
pour stocker le résultat. Même un type de grande taille, genre
uint64_t peut être trop petit. La section 3.2
propose un algorithme de décodage récursif, qui évalue à chaque étape
si le résultat est de taille suffisante et alloue une autre variable
si nécessaire.
Cette histoire de taille de la variable qui stocke le résultat est
un des problèmes pénibles de SDNV. On ne peut pas exiger de chaque
implémentation qu'elle mette en œuvre un système d'entiers infinis (le RFC cite GNU
MP comme exemple). La section 3.3 propose que chaque
protocole qui utilise des SDNV fixe une taille maximale aux entiers
stockés (retombant ainsi partiellement dans les problèmes des champs
de taille fixe). Ainsi, le protocole Bundle
(RFC 5050) fixe cette limite à la valeur
maximale pouvant être représentée avec 64 bits. Le décodeur peut donc
utiliser un uint64_t sans crainte.
Voilà, les SDNV sont donc très simples dans leur principe. Mais quels sont leurs avantages et leurs inconvénients ? La section 4 discute des alternatives : SDNV actuels, TLV, et l'ancien système de SDNV qui avait été utilisé dans des versions antérieures de certains protocoles DTN. En gros, le système le plus souple est TLV mais c'est aussi le moins efficace, en place et en temps. Un avantage de TLV est que, via le champ Type, la sémantique est connue, alors que les SDNV ne sont que des entiers non typés. Autre avantage : la taille du résultat est connue tout de suite et l'allocation mémoire pour le résultat tombe donc toujours juste (l'ancien SDNV avait un système analogue). Mais l'un des problèmes des TLV est que la représentation des champs Type et Longueur. S'ils sont de taille fixe, les TLV héritent certains des problèmes des champs de taille fixe. Notons qu'on peut combiner les techniques, par exemple utiliser SDNV pour le champ Longueur d'un TLV.
Bien que le RFC n'en discute guère, je me permets d'ajouter ici une comparaison essentiellement personnelle entre champs de taille fixe et SDNV. Les champs de taille fixe :
- Sont bien plus faciles à encoder/décoder, dans un langage comme C, c'est même trivial. Ce n'est pas seulement un avantage pour le programmeur, c'est aussi une garantie de rapidité.
- Ont pour principal inconvénient le fait qu'une mauvaise estimation de la taille nécessaire n'est pas corrigeable a posteriori (cas des fenêtres TCP et des adresses IPv4 cités plus haut). Si la capacité du réseau est grande (ce qui n'est typiquement pas le cas dans l'espace), une solution possible est de gaspiller, en utilisant systématiquement des champs très grands, genre 128 bits.
- Ont une taille connue à l'avance (par définition), ce qui permet au programmeur de réserver la bonne taille (cf. section 3.3)
- Sont très sensibles aux erreurs de transmission car les modifications sont indécelables. Au contraire, la modification d'un bit dans un SDNV peut entraîner une erreur de format, qui sera détecté au décodage.
Bref, je trouve personnellement que l'utilisation fréquente de champs de taille fixe dans les protocoles Internet n'est pas due au hasard.
Reparlons de décodage avec la question de la sécurité (section 5). Un décodeur SDNV doit faire attention aux valeurs qui dépassent ses limites, non seulement pour ne pas planter, mais aussi parce que cela peut avoir des conséquences de sécurité (débordement de tampon, par exemple). Autre piège, les entiers gérés par SDNV sont toujours positifs. Une implémentation ne doit donc pas les décoder vers un type signé, ce qui risquerait d'introduire des valeurs négatives dans un processus qui ne s'y attend pas. (TLV a le même problème si on place un champ Longueur dans une variable de type signé.)
Place aux implémentations. Le programme Python sdnv.py, qui utilise le code présent dans l'annexe A du RFC, permet de tester encodage et décodage. L'affichage (pas le calcul) nécessite l'excellent module bitstring :
# Encodage % python sdnv.py -e 3 3 -> 0b00000011 % python sdnv.py -e 130 130 -> 0b1000000100000010 % python sdnv.py -e 4598 4598 -> 0b1010001101110110 % python sdnv.py -e 46598 46598 -> 0b100000101110110000000110 # Décodage % python sdnv.py -d 00000000 00000000 -> 0 % python sdnv.py -d 00000011 00000011 -> 3 % python sdnv.py -d 1000000100000010 1000000100000010 -> 130 [Ajout d'un troisième octet, fait de bits nuls, _après_ le SDNV.] % python sdnv.py -d 100000010000001000000000 100000010000001000000000 (only 2 bytes read) -> 130
À noter que les SDNV disposent d'une page Web officielle. En dehors du code Python du RFC, je n'ai pas vu d'autres implémentations mais on peut probablement en extraire du code DTN.
L'article seul
RFC 6255: Delay-Tolerant Networks (DTN) Bundle Protocol IANA Registries
Date de publication du RFC : Mai 2011
Auteur(s) du RFC : M. Blanchet (Viagénie)
Pour information
Première rédaction de cet article le 26 mai 2011
Le groupe de recherche DTN (Delay-Tolerant Networking, cf. RFC 4838) de l'IRTF a déjà produit plusieurs protocoles comme Bundle (RFC 5050) et Licklider (RFC 5326). Ces protocoles n'avaient pas jusqu'alors de registres officiels pour leurs paramètres, manque que notre RFC 6255 vient de combler.
Jusqu'à présent, les paramètres enregistrés étaient stockés sur
le site Web du groupe. Ils sont désormais à
l'IANA qui en assurera la maintenance: https://www.iana.org/assignments/bundle/bundle.xml.
Ces paramètres sont souvent encodés sous forme de SDNV (Self-Delimiting Numeric Values, RFC 6256 et section 2 de notre RFC). Pour le protocole Bundle (RFC 5050) les paramètres à enregistrer sont décrits en section 3. On peut citer par exemple les options de traitement (processing control flags, section 3.3), dont la liste peut évoluer, la seule contrainte pour l'enregistrement étant la disponibilité d'une spécification stable (pour les politiques d'enregistrement dans les registres IANA, voir le RFC 5226 ; cette politique particulière, « Specification required » est décrite en section 4.1). Ces options ont la forme de bits dans un tableau de taille 64, parmi lesquels le bit 2 indique que le lot (bundle) ne doit pas être fragmenté, le 5 qu'un accusé de réception est demandé, etc.
Autre exemple, les codes de réponse (status report flags, section 3.5) comme « lot accepté » ou « lot transmis ». Comme le tableau de bits est bien plus petit cette fois (huit bits dont seuls trois sont encore libres), les règles d'enregistrement sont plus strictes, un RFC (pas juste n'importe quelle spécification) est exigé.
Les autres protocoles comme Licklider n'ont pas encore leur registre.
L'article seul
RFC 6250: Evolution of the IP Model
Date de publication du RFC : Mai 2011
Auteur(s) du RFC : D. Thaler (IAB)
Pour information
Première rédaction de cet article le 20 mai 2011
Qu'offre l'Internet aux développeurs d'application et aux concepteurs de protocole ? Le modèle de service de l'Internet n'a pas toujours été bien documenté, et les préjugés et idées fausses abondent chez les programmeurs (l'essentiel du RFC est d'ailleurs composé de l'exposé des affirmations erronées sur le modèle Internet.) En outre, l'Internet ayant crû de manière analogue à un écosystème, sans suivre strictement un plan pré-établi, ce modèle a largement changé, sans que ce changement n'ait été intégré par les développeurs. D'où ce RFC, qui ambitionne de documenter le modèle de service de l'Internet tel qu'il est en 2011. Ce RFC devrait être lu par tous les développeurs d'applications, afin qu'ils apprennent le service que leur offre réellement l'Internet.
Tout le monde sait que l'Internet offre un service de
niveau 3 (le protocole
IP). Même si les applications y accèdent en
général via un service de niveau 4 (typiquement
TCP), bien des caractéristiques de la couche 3
apparaissent aux applications (comme les adresses IP). (Le RFC utilise d'ailleurs parfois le terme
« application » pour parler de tout ce qui est au dessus de la couche 3.)
Quelles sont exactement les propriétés
de ce service ? Par exemple, les caractéristiques de la communication
(latence, taux de perte de paquets, etc) mesurées au début sont-elles
constantes (réponse : non) ? Quelle est la taille d'une adresse IP
(ceux qui répondent « quatre octets » peuvent abandonner
l'informatique pour l'élevage des chèvres en
Lozère) ? Si 192.0.2.81 se
connecte chez moi, pourrais-je me connecter à mon tour à cette machine
(réponse : plutôt oui, à l'origine, malheureusement non aujourd'hui) ?
Si certaines applications (par exemple une application qui inclus un
simple client HTTP pour récupérer un fichier
distant) peuvent ignorer sans problème ce genre de questions, pour
d'autres (logiciel de transfert de fichiers
pair-à-pair, client SIP,
etc), ces questions sont cruciales et les développeurs ne connaissent
pas forcément les bonnes réponses.
Revenons à l'histoire, comme le fait la section 1 du RFC. Le modèle original d'IP (et qui est encore souvent enseigné comme tel dans pas mal d'établissements d'enseignement) était partiellement documenté en 1978 dans l'IEN28 (les premières publications sur le TCP/IP actuel, les RFC 791 et RFC 793 ne sont venus qu'après). Un des principes était que les applications étaient très différentes mais que toutes tournaient sur IP, qui à son tour tournait sur tous les réseaux physiques possibles (modèle dit « du sablier », IP représentant le goulet d'écoulement du sablier). Ce modèle a nécessité plusieurs clarifications dans les RFC ultérieurs, par exemple le RFC 1122 en 1989 ou le RFC 3819. Résultat, aujourd'hui, il n'y a pas de document unique qui décrive le modèle de service, ce qu'offre IP aux applications.
Il est d'autant plus nécessaire de comprendre ce modèle qu'il est désormais difficile de le changer. Au début de l'Internet, on pouvait changer un concept et obtenir de tous les développeurs de toutes les applications de s'adapter. Aujourd'hui, la taille de l'Internet et son absence de centre rendent une telle opération impossible. L'Internet s'est ossifié.
Bon, en quoi consiste ce fameux « modèle de service » ? Il est décrit par la section 2. Un modèle de service est défini comme la description du service que rend une couche aux couches supérieures, ici le service que rend IP aux applications. Le schéma n° 1 résume cette notion de couches et la place d'IP dans l'architecture de l'Internet. Et le comportement d'IP ? Sa description officielle était dans la section 2.2 du RFC 791 : un service sans connexion (orienté paquets), acceptant des paquets de taille variable, et les délivrant (mais pas toujours) sans garantir leur ordre ou leur absence de duplication. Bref, un service qui « fait au mieux » (best effort dans la langue de Jack London). Les émetteurs n'ont pas besoin de se signaler aux destinataires ou au réseau avant d'émettre et les récepteurs n'ont pas besoin de signaler quoi que ce soit au réseau avant de recevoir.
On l'a dit, l'architecture réelle n'est plus vraiment celle du RFC 791, qui était de toute façon décrite de manière très brève dans ce RFC. D'autres documents ont approfondi la question comme le RFC 1958 ou comme le rapport « New Arch: Future Generation Internet Architecture » de 2004.
En fait, il est plus facile de décrire ce qu'il n'y a pas dans le modèle de service d'IP. La section 3, consacrée aux préjugés erronés, est donc beaucoup plus longue que la section 2. Je ne vais pas la répéter dans son entièreté mais simplement citer quelqu'uns de ces préjugés, en commençant par ceux concernant la connectivité.
Une des suppositions non dites les plus fréquentes dans les applications est que la possibilité d'envoyer un paquet (reachability) est symétrique (section 3.1.1). Un protocole comme FTP (RFC 959), avec sa notion de « voici mon adresse IP, rappelle-moi », repose largement là-dessus. Si la machine A peut envoyer un paquet à la machine B, le contraire est aussi vrai. Ce principe était largement vrai au début de l'Internet (attention, la possibilité d'envoyer était symétrique mais pas le chemin suivi) mais est tout à fait faux aujourd'hui. C'est même plutôt le contraire : la machine typique est coincée derrière un routeur NAT et un pare-feu qui empêchent tout envoi initié par l'extérieur. L'annexe A du RFC 5694 discute plus en détail ce problème et ses conséquences notamment pour les applications pair-à-pair. Bref, la seule chose que laquelle les applications peuvent relativement compter, est qu'une réponse à une requête initiée depuis l'intérieur a des chances d'arriver (c'est le modèle de HTTP). Les requêtes initiées de l'extérieur sont par contre impossibles dans le cas général (RFC 2993).
À noter que, même en l'absence de boîtiers intermédiaires qui bloquent les paquets, certains liens physiques ne sont pas symétriques, notamment en radio, comme l'illustre la section 5.5 du rapport « The mistaken axioms of wireless-network research ».
Autre supposition fréquente mais erronée, la transitivité. L'idée est que, si une machine A peut joindre B, et que b peut joindre C, alors A peut joindre C (section 3.1.2). Exactement comme pour la symétrie, ce principe était vrai au début, et ne l'est plus maintenant, en raison du NAT et des pare-feux, mais aussi de protocoles physiques comme 802.11 qui ne garantissent pas une telle transitivité.
Autre erreur que font certains développeurs d'applications, parce qu'ils confondent le modèle original de l'Internet et la triste réalité d'aujourd'hui, la conviction que les paquets signalant une erreur arriveront à l'émetteur du paquet qui a déclenché l'erreur (section 3.1.3). Ces paquets signalant une erreur sont typiquement portés par le protocole ICMP. Des exemples de leur usage ? La découverte de la MTU du chemin (RFC 1191 et RFC 1981) ou bien traceroute (RFC 1812).
Pourquoi ne peut-on plus compter sur ces messages ? D'abord, bien des routeurs ont été configurés pour limiter le rythme d'envoi, avant de rendre plus difficile leur utilisation dans une attaque DoS (RFC 2923, section 2.1. Ensuite, bien des pare-feux ont été stupidement configurés par des incompétents et bloquent tout l'ICMP (malgré les recommandations des RFC 2979, section 3.1.1, et RFC 4890). Résultat, il a fallu développer des mécanismes alternatifs pour la découverte de la MTU (RFC 4821).
Autre erreur : certaines applications croient qu'elles peuvent
utiliser la diffusion IPv4 pour transmettre un
message à toutes les machines (section 3.1.5). Autrefois, des adresses
comme 10.1.255.255 (les seize derniers bits tous à un) envoyaient en
théorie un message à toutes les machines du réseau
10.1.0.0/16, et les routeurs devaient faire
suivre ce message au delà du lien local. Comme ce mécanisme facilitait
trop les attaques par déni de service, il a été abandonné par le RFC 2644 en 1999. Depuis, la diffusion ne marche plus que sur le
lien local. Et encore, car certains liens, dits
NBMA, ne la permettent pas. Plus drôle,
certains liens comme 802.11 en mode
ad hoc autorisent la diffusion mais, en
pratique, le message n'atteint pas toutes les machines du lien. Bref,
si on veut écrire à toutes les machines d'un groupe, il vaut mieux le
faire soi-même, sans compter sur la diffusion.
À ce sujet, la section 3.1.6 note que, contrairement à une croyance courante, un ensemble de paquets unicast n'est pas forcément plus coûteux ou moins rapide qu'un multicast ou qu'un broadcast. Sur les liens filaires traditionnels, un seul paquet multicast sera sans doute plus rapide. Ce n'est plus le cas sur les liens radio où le multicast devra être transmis au débit de base, même s'il existe des machines ayant une interface radio plus rapide, et qui a négocié un débit plus élevé.
Un problème subtil est causé par le cas où l'application compte sur la latence des paquets, par exemple pour faire de la visioconférence. Une application qui mesure cette latence peut avoir tendance à mesurer le premier paquet et à la considérer comme représentatif. Mais c'est souvent à tort (section 3.1.6). En effet, pour le premier paquet d'un flot de données, il y a souvent un temps d'établissement (dû à la résolution ARP, par exemple). Et ce sera pire avec les futurs systèmes de séparation de l'identificateur et du localisateur qui, tous, prévoient une forte latence pour le premier paquet, lorsqu'il faut résoudre l'identificateur en localisateur.
Autre caractéristique d'un chemin suivi par les paquets : le taux de réarrangement, qui mesure le fait que certains paquets arrivent avant des paquets partis plus tôt. Des études comme celle de Bennett, J., Partridge, C., et N. Shectman, « Packet reordering is not pathological network behavior » ou comme les RFC 2991 ou RFC 3819, section 15, montrent que le réarrangement a des conséquences pour les applications. Pour un programme de streaming, par exemple, il oblige à augmenter la taille des tampons. TCP voit ses performances se dégrader si les paquets n'arrivent pas dans l'ordre. Mais le réarrangement est un fait : des tas de raisons peuvent le causer (un routeur qui fait de la répartition de charges entre deux liens, par exemple) et les applications doivent s'y attendre.
Et le taux de pertes des paquets ? Sur quoi peut-on compter ? Beaucoup de gens pensent que les pertes sont rares, et probabilistiques (c'est-à-dire que le destin frappe un paquet au hasard, et qu'en reessayant, ça va marcher). Mais ce n'est pas forcément le cas (section 3.1.9). D'abord, si l'application a un comportement non-uniforme (des grands moments de silence, puis de brusques envois de nombreux paquets), les pertes se concentreront pendant ces envois, qui rempliront les files d'attente. Ensuite, il existe des phénomènes qui mènent à la perte préférentielle du premier paquet, comme ces routeurs de cœur qui, pour éviter une attaque DoS (envoi de paquets vers beaucoup d'adresses qui ne répondent pas), ne gardent pas en mémoire les paquets qui déclenchent une résolution ARP. Le premier paquet vers une nouvelle destination sera donc forcément perdu. Un autre exemple d'un comportement analogue est le Wake-on-LAN, où le paquet qui déclenche l'allumage de la machine n'est en général pas gardé.
L'Internet garantit-il qu'un chemin existe, à un moment donné, vers une destination (section 3.1.10) ? Oui, c'est toujours largement vrai. Mais cela cesse de l'être dans des réseaux exotiques comme les DTN (cf. RFC 4838) où deux machines pourront communiquer sans jamais être allumées en même temps. Avec humour, le RFC mentionne également le cas de réseaux où les paquets sont transportés par des animaux, peut-être une allusion au RFC 1149.
Pourquoi ces suppositions, qui étaient en général vraies autrefois, ont cessé de l'être (section 3.1.11) ? Il y a deux classes de raisons, une située dans les couches 1 et 2, et une autre placée dans la couche 3. Pour la première, le RFC 3819 donnait d'utiles conseils aux concepteurs de réseaux physiques. En gros, il indique une liste de services que doivent rendre les couches basses à IP et, si celles-ci ne le font pas, comment la couche d'adaptation à IP peut compenser. Ainsi, les RFC 3077 et RFC 2491 décrivent des mécanismes pour compenser l'absence d'atteignabilité symétrique et donc restaurer les services auquel s'attend IP. Mais toutes les couches basses ne le font pas : par exemple, il n'existe pas de moyen standard, lorsqu'une machine est connectée en WiFi ad hoc, de compenser le manque de symétrie dans les liens. Un mécanisme, situé sous IP, reste à élaborer.
Autre classe de causes pour lesquelles les suppositions d'autrefois ne sont plus forcément respectées, les raisons situées dans la couche 3 elle-même. Cela peut être une conséquence d'une politique de sécurité (RFC 4948), qui mène au filtrage. Cela peut être aussi à cause du NAT. Plusieurs applications font beaucoup d'efforts pour contourner ces problèmes. Cela semble une bonne application du principe de robustesse (« soyez strict dans ce que vous envoyez mais laxiste dans ce que vous acceptez »), et, en effet, les protocoles qui réussissent à contourner les limites de la couche 3 ont en général plus de succès que les autres (RFC 5218). Mais le principe de robustesse a aussi l'inconvénient de masquer les problèmes, et de diminuer la pression pour les résoudre. Par exemple (qui n'est pas dans le RFC), Skype réussit à passer via des hotspots où seul le port 80 fonctionne en sortie, donc les clients de ces hotspots ne râlent pas contre l'opérateur de ce dernier et celui-ci continue donc à fournir un service de daube. Le RFC suggère, pour sortir de ce dilemme, de fournir un mode spécial pour l'application, activable à la demande, où l'application n'utilisera que des techniques propres et officielles, permettant ainsi de déboguer les réseaux mal fichus, sans que leurs problèmes soient masqués.
Cela, c'était pour la connectivité. Et pour l'adresssage ? La section 3.2 rassemble les suppositions erronées les plus fréquentes sur ce sujet.
D'abord, bien des applications considèrent l'adresse IP
comme stable sur une assez longue période (ce qui était vrai
autrefois, où les adresses étaient toutes fixes et configurées
manuellement). Cette supposition (section 3.2.1) se reflète dans
l'API : par exemple,
getaddrinfo() ne fournit pas
d'indication sur la durée de validité de l'adresse récupérée. Même
avec plein de bonne volonté, l'application ne peut pas savoir si
l'adresse IP récupérée en échange du nom peut être conservée pour une
minute, une heure ou un jour (la plupart des applications appelent
getaddrinfo() et ne remettent jamais en cause son
résultat, gardant l'adresse IP pendant toute leur durée de vie, un
phénomène connu sous le nom d'épinglage - pinning -
et qui peut avoir des conséquences pour la sécurité).
Or, aujourd'hui, avec des techniques comme DHCP, les adresses ne sont pas stables et changent, notamment lorsque la machine se déplace. Cela casse des applications comme SSH. Plusieurs protocoles ont été proposés pour conserver un identificateur stable même lorsque le localisateur change (par exemple HIP).
Encore plus répandue, l'idée comme quoi une adresse IP ferait
quatre octets (section 3.2.2). Faites le test lors d'un entretien d'embauche :
demandez au candidat à écrire un petit programme
C qui gère des adresses
IP. S'il déclare une variable de type uint32_t, cela
montre qu'il ne connait pas IP (si la variable est de type
int, cela montre qu'il ne connait pas
C...). Cette idée était juste il y a douze ans, mais ne l'est plus
depuis que l'Internet est redevenu multi-protocole, avec la
coexistence d'IPv4 et
IPv6 (dont les adresses font seize octets).
Plus subtile, la question du nombre d'adresses par interface. Pas mal de programmeurs tiennent pour acquis que « l'adresse IP identifie une interface » (ce qui est faux) et écrivent un code qui ne gère pas vraiment le cas d'adresses multiples. Ce préjugé n'a jamais été réellement justifié (le RFC 791 mentionne explicitement la possibilité d'avoir plusieurs adresses IP par interface) mais il l'est encore moins maintenant, où l'existence de plusieurs adresses IP sur une interface est devenue banale (surtout pour IPv6). On note que HIP, cité plus haut, donnerait raison au préjugé, s'il était déployé massivement : l'identificateur serait en effet unique (par machine virtuelle).
En parlant de l'idée d'une adresse IP par machine, si une machine peut avoir plusieurs adresses IP, est-ce qu'une adresse IP peut être utilisée par plusieurs machines ? Cela mène à la notion d'identité d'une machine. Ce concept n'existe pas réellement dans les protocoles TCP/IP mais pas mal d'applications font comme si (section 3.2.4). Par exemple, une ACL sur un pare-feu, bloquant une adresse IP, signifie que l'administrateur du pare-feu considère que l'ennemi peut être identifié par son adresse IP, ce qui n'est pourtant pas toujours le cas.
Parmi les évolutions technologiques qui empêchent ce préjugé d'être exact : l'anycast (RFC 4786), ou bien certaines solutions de haute disponibilité. Des RFC comme le RFC 2101 ou le RFC 2775 discutent de cette question de l'unicité de l'adresse.
Plus ridicule mais néanmoins fréquente, l'idée que l'adresse IP d'une machine identifie sa position géographique (section 3.2.5). C'est clairement faux aujourd'hui (pensez aux tunnels, par exemple).
Plus subtile, l'idée que l'adresse IP a un rapport avec le routage (section 3.2.6). Par exemple, une application qui déduirait de la proximité de deux adresses la proximité des machines. Avec des protocoles comme Mobile IPv6 ou HIP (déjà cité), cette supposition serait complètement fausse. D'une manière générale, tout système de séparation de l'identificateur et du localisateur casserait cette idée. Dans les textes originels (IEN019 ou IEN023),l'adresse IP était présentée comme un localisateur, alors que TCP, par exemple, l'utilise comme identificateur. C'est là la source de cette confusion d'aujourd'hui.
Ces erreurs sur l'adressage sont fréquentes. La section 3.2.10
fournit une perspective plus large, en partant du RFC 1958, dont la section 4.1 avait été le premier texte à
insister sur l'importance d'utiliser des noms plutôt que des adresses
(celles-ci ayant une sémantique trop floue). Notre RFC 6250 réinsiste fortement sur ce point : c'est bien à tort que des
API comme
getaddrinfo() exposent les adresses
IP aux applications. La plupart du temps, celles-ci ne devraient pas
avoir accès à ces adresses, ce qui éliminerait la tentation de les
utiliser de manière incorrecte. Ceci dit, le conseil du RFC 1958 n'est pas possible à suivre intégralement aujourd'hui :
bien des machines IP (au hasard, mon téléphone portable) n'ont pas de
FQDN à elles.
On l'a vu, le terme « applications », dans ce RFC 6250 est utilisé de manière souple, pour décrire tout ce qui se trouve au dessus de la couche 3. la section 3.3 aborde les problèmes spécifiques à une partie de ces « applications », la couche transport (couche 4). Quelles sont les erreurs courantes à propos de cette couche 4 ?
D'abord, un certain nombre d'acteurs de l'Internet croient qu'il est possible d'ajouter de nouveaux protocoles de transport, des concurrents des classiques TCP et UDP (section 3.2.1), tels que ceux enregistrés à l'IANA. C'était certainement le but originel de l'architecture de TCP/IP. Mais, aujourd'hui, ce n'est plus vrai. L'Internet s'est terriblement ossifié et les nouveaux protocoles de transport ont très peu de chances de passer à travers toutes les middleboxes mal fichues qui abondent sur le réseau. Souvent, on doit même tout tunneler au dessus d'HTTP. C'est au point où le RFC suggère même de ne pas hésiter à normaliser cette utilisation de HTTP (quelque chose que, traditionnellement, l'IETF avait toujours refusé de faire, au nom de la qualité technique des normes). XMPP le fait, par exemple, dans son XEP 0124. SIP n'a pas de méthode standard pour cela, et ça lui a parfois été reproché, alors que le système fermé Skype n'hésite pas à détourner HTTP. Un groupe de travail de l'IETF, HyBi, travaille sur un mécanisme générique d'utilisation de HTTP pour contourner ces middleboxes stupides.
Bref, le point le plus étroit du sablier, celui par lequel tout devait passer, et qui était IP dans l'architecture originale, est de plus en plus souvent TCP, voire HTTP. C'est parfois fait au nom de la sécurité (par des gens qui ne connaissent pas forcément ce sujet). L'IETF continue ses efforts pour casser cette dangereuse évolution mais, au cas où ces efforts ne seraient pas couronnés de succès, il faut se préparer à s'adapter.
En parlant de sécurité, quelles sont les idées reçues sur la sécurité (section 3.4) ? Elles sont évidemment nombreuses (et une analyse plus complète figure dans le RFC 3552). Par exemple, bien des applications se comportent encore comme si les paquets n'étaient jamais modifiés en route, à part pour quelques champs bien définis comme le TTL. Le NAT change malheureusement cette situation. On peut parfois restaurer le comportement correct avec des tunnels (RFC 4380) ou avec IPsec en mode transport (RFC 4301).
À défaut d'être respectés dans leur intégrité, les paquets sont-ils au moins privés (section 3.4.2) ? Pas davantage. Il a toujours été possible d'écouter les communications et pourtant on trouve toujours des protocoles et des applications qui s'obstinent à envoyer des mots de passe en clair. Là encore, IPsec, s'il était déployé, pourrait fournir une solution générique, ne nécessitant pas de changer les applications.
Autre erreur que font souvent les débutants en sécurité : croire
que, puisqu'un paquet prétend venir de
198.51.100.66, alors c'est vrai (section
3.4.3). La vérité est qu'il est relativement facile de mettre une
fausse adresse IP source (la plupart des lecteurs de mon blog le
savent depuis longtemps mais on trouve pourtant régulièrement des
articles qui parlent d'une attaque par déni de service en disant
« elle vient de tel pays » simplement parce que les adresses IP source
indiquent ce pays). Il existe des mécanismes techniques qui pourraient
permettre d'avoir des adresses sûres, par exemples les adresses
cryptographiques du RFC 3972.
En conclusion, que faut-il retenir de ce RFC ? La section 5 fournit les points essentiels :
- Vu le nombre d'applications qui dépendent de TCP/IP pour des travaux critiques, tout changement dans le modèle de service ne devrait être fait qu'avec les plus extrêmes précautions.
- Les invariants (les concepts essentiels sur lesquels on peut compter) devraient être mieux documentés, au lieu de dépendre du savoir informel des vieux sages.
- Chaque couche devrait expliciter clairement le service qu'elle fournit aux couches supérieures, et le service qu'elle attend des couches inférieures.
- Et il faudra de toute façon recommencer le travail de temps en temps, l'évolution étant inévitable.
L'article seul
Expérimentation avec la distribution Android MIUI
Première rédaction de cet article le 19 mai 2011
Dernière mise à jour le 25 mai 2011
Un des charmes du système d'exploitation Android, et des phono sapiens qui l'utilisent, c'est qu'on peut changer ce qu'on veut, y compris installer une distribution « non officielle » d'Android. C'est ce que j'ai fait cette semaine avec une distribution assez peu connue, d'origine chinoise, MIUI.
Parmi toute les distributions « communautaires » d'Android (dont la plus connue, la référence, est CyanogenMod, essayée par ailleurs); quelles sont les particularités de MIUI ?
- Interface entièrement en chinois. Évidemment, si on ne parle pas cette langue, cela peut être un peu déroutant,
- Encore très expérimentale, avec peu de documentation et une impression générale de « mais qu'est-ce que je fais là au lieu d'écouter de la musique sur un iPod ? »,
- Interface utilisateur très proche de celle de l'iPhone,
- Plusieurs points qui plaisent à ses utilisateurs comme le contrôle de la musique même lorsque le téléphone est encore verrouillé, le nombre de bureaux virtuels ajustable, l'utilisation de la lampe depuis l'écran de verrouillage (en utilisant la touche home, la sonnerie qui s'arrête quand on prend le téléphone dans la main.
D'ailleurs, voici un exemple (notez que MIUI est très configurable,
donc un autre téléphone avec cette distribution n'aura pas la même
apparence) :
 Notez l'icône légendée en
chinois (tout n'est pas traduit).
Notez l'icône légendée en
chinois (tout n'est pas traduit).
Comment on installe ce joli logiciel ? Je préviens tout de suite : non seulement les distributions non officielles peuvent annuler la garantie, vous faire perdre des données, planter le téléphone, mais elles peuvent en outre traumatiser votre labrador, faire ricaner le petit neveu du voisin, qui a un iPhone, et pousser 3M à déposer une proposition de loi. Ne dites pas que je ne vous ai pas prévenus. C'est d'autant plus sérieux que MIUI semble très fermée (pas de code source disponible).
Il faut d'abord rooter son téléphone. Ensuite, il
ne faut pas essayer d'installer depuis ROM Manager (dans mon cas, MIUI
était installé mais se bloquait lors du démarrage, adb
logcat sur une machine connectée au téléphone montrait le
système tournant en rond). Ce que j'ai fait à la place :
- Télécharger une image de MIUI (dans le monde Android, on dit une
ROM, pour des raisons mystérieuses) en
http://www.miuiandroid.com/roms/. Pour mon HTC Desire, j'ai utiliséhttp://deodex.miuiandroid.com/miuiandroid-Desire-1.5.13.zipet la mettre sur la carte SD du téléphone. (MIUI est optimisé pour chaque téléphone particulier : cela offre de bonnes performances mais nécessite une image différente, et tous les téléphones ne sont pas gérés.) - Si on ne parle pas la langue d'Audrey Tang, il faut aussi télécharger le
pack en anglais, dans mon cas
http://packs.miuiandroid.com/miuiandroid-1.5.13_Desire-EN-PACK1b_2.3.4.zip. - Une fois les deux fichiers zip sur la
carte SD, j'ai redémarré le téléphone sous le logiciel ClockwordMod
Recovery (démarrer avec la touche Volume down
enfoncée et option
RECOVERYmais on peut aussi, depuis son ordinateur, faire unadb reboot recovery) et choisi l'option « install zip from sdcard ». On installe d'abord MIUI puis le pack anglophone. - On redémarre, et on est dans un autre monde. Il n'y a plus qu'à jouer, par exemple en utilisant les trucs amusants décrits dans « 17 Hidden Tips And Tricks For MIUI Android ROM That You Probably Didn't Know ».
Il y a peu de chances que tout se passe correctement et, même si
c'est le cas, vous aurez probablement des questions à poser. Le canal
IRC #miuiandroid sur
Freenode est sympathique et serviable mais très
bavard, avec plein de blagues incompréhensibles. Autrement, la seule
autre solution est un ensemble de forums Web,
en http://forums.miuiandroid.com/.
À l'usage, comment cela se passe t-il avec MIUI ? Je n'ai pas encore assez de recul pour en juger. Par exemple, MIUI est souvent accusé d'épuiser la batterie en peu de temps mais, pour l'instant, cela ne semble pas être le cas.
Et pour la langue de Bernard-Henri Lévy,
quelles solutions avons-nous pour utiliser ce système ? Les seules ROM
de MIUI sont en chinois et en anglais. Même si on peut comprendre les
messages en anglais, c'est pénible car cela empêche l'utilisation d'un
clavier Azerty, et le correcteur orthographique
s'obstine à remplacer les mots français pas des anglais. Des
volontaires dévelopent une adaptation de MIUI en français, mais c'est
ultra non officiel. L'extension française pour le HTC Desire (oui,
même pour une simple traduction, il faut un fichier par modèle de
téléphone...) se trouve actuellement (il
n'y a pas de site officiel, et les liens dans les forums sont souvent
dépassés) http://ks353739.kimsufi.com/updates/bravo/1.5.13/miui-bravo-1.5.13-patch_fr-signed.zip. Cette
adaptation française permet d'avoir le clavier Azerty et de choisir sa
langue mais elle a aussi des effets de bord curieux comme de faire
revenir une partie de l'interface en chinois. En fouillant un peu
partout et en demandant sur Twitter, on peut
trouver des tas de versions de MIUI avec un meilleur support du
français (si on n'est pas trop exigeant sur la traçabilité de ces
binaires inconnus), par exemple http://forum.frandroid.com/topic/24412-rom-miui-1513-a2sd-faq-optimisation-de-la-rom/
ou bien une version
australienne qui semble très stable.
Bref, un système prometteur, mais encore réservé aux développeurs.
Le site officiel (où on ne trouve pas grand'chose, le moindre
logiciel libre sur Unix a une meilleure page Web, avec plus d'informations) est http://www.miuiandroid.com/. Une bonne présentation générale de MIUI se trouve dans l'article
« What
Is MIUI ROM For Android? [Complete Guide] ». Un autre
bon article est « Why
MIUI rocks and how to install it on your Android
device ».
Merci à Yves-Gaël pour ses nombreuses explications.
L'article seul
RFC 6247: Moving the Undeployed TCP Extensions RFC1072, RFC1106, RFC1110, RFC1145, RFC1146, RFC1379, RFC1644 and RFC1693 to Historic Status
Date de publication du RFC : Mai 2011
Auteur(s) du RFC : L. Eggert (Nokia)
Pour information
Réalisé dans le cadre du groupe de travail IETF tcpm
Première rédaction de cet article le 17 mai 2011
Grand nettoyage à l'IETF, plus précisement au sein du groupe de travail TCP Maintenance and Minor Extensions. Huit RFC sur le protocole TCP sont rangés dans la cave de l'IETF, en étant reclassés comme « Document d'intérêt historique seulement ».
La famille de protocoles TCP/IP est bien vivante. La preuve, il y a régulièrement des protocoles ou des extensions aux protocoles qui apparaissent. Mais, pour que l'évolution fonctionne, il faut aussi que certains disparaissent. C'est ce qui vient d'arriver à huit extensions du protocole TCP, qui avaient été normalisées, avaient parfois suscité beaucoup d'espoirs, mais ont ensuite été des échecs. Peu de déploiements, des sérieux problèmes identifiés a posteriori, et voici ces extensions vouées au statut « Historique ». La plus récente, le RFC 1693, datait de 1994... Ces huit RFC perdent donc tout droit au nom de « norme ». Les raisons de ce reclassement figurent en général dans la section 5 du RFC 4614, qui avait fait un tour d'horizon complet et critique de tous les RFC sur TCP.
Parmi les RFC ainsi rabaissés, notons le RFC 1644, qui normalisait l'extension T/TCP qui semblait à une époque pouvoir fournir un TCP léger et rapide, mais qui a montré de sérieuses failles de sécurité à l'usage.
Conséquence pour l'IANA, certaines options enregistrées dans le registre des options TCP, comme les options 6 et 7, du RFC 1072, sont désormais marquées comme « dépassées ».
L'article seul
Fiche de lecture : The Haskell school of expression
Auteur(s) du livre : Paul Hudak
Éditeur : Cambridge University Press
978-0-521-64408-2
Publié en 2000
Première rédaction de cet article le 17 mai 2011
Allez, encore un livre sur le langage de programmation Haskell. Celui-ci est intermédiaire entre « Real-world Haskell », très concret, ou « Haskell: the craft of functional programming », bien plus abstrait.
L'auteur a choisi une approche pédagogique simple et relativement originale (surtout dans le monde de la programmation fonctionnelle, où les exemples sont plus souvent empruntés aux mathématiques). Il utilise Haskell pour faire des dessins et toutes les notions essentielles du langages sont introduites via leur utilisation dans le monde du graphique. De l'affichage de formes simples :
data Shape = Rectangle Side Side
| ... autres formes
area :: Shape -> Float
area (Rectangle s1 s2) = s1 * s2
jusqu'aux monades qui servent pour modéliser les animations. Cette utilisation du graphique rend les exercices plus rigolos, avec comme récompense de belles images (voyez les démos).
Les graphiques sont rendus en utilisant la bibliothèque SOEGraphics (développée pour ce livre). À l'époque de la parution du livre, elle n'existait que sur Windows mais elle marche désormais ailleurs. Les exemples de code sont disponibles en ligne. On trouve plusieurs autres ressources (transparents pour un cours, correction des exercices) sur le site du livre. Bref, on est vraiment dans le concret.
Deux exemples complets et plus complexes figurent à la fin, un tiré de la musique (et très difficile à lire, même pour un musicien, car le texte en anglais utilise les notations musicales états-uniennes) et un langage de commande d'un robot.
En résumé, un livre que je recommenderai pour apprendre Haskell. On peut utiliser ensuite les deux autres cités plus haut pour approfondir, respectivement l'interface avec le monde réel, et les bases théoriques.
L'article seul
OpenSearch, application à ce blog
Première rédaction de cet article le 15 mai 2011
La norme OpenSearch permet de décrire de manière formelle les capacités de recherche d'un site Web, de façon à faciliter la réalisation d'interfaces utilisateur qui effectuent des recherches. Je viens d'installer une description OpenSearch sur ce blog, qui permet d'utiliser plus facilement son moteur de recherche.
Des tas de sites Web ont un moteur de recherche. Comme chacun utilise une interface légèrement différente, produire une interface qui pourra interroger plusieurs moteurs (comme la fonction de recherche de Firefox, en haut à droite) était très compliqué. OpenSearch a changé cela, en permettant de décrire, en XML, les caractéristiques d'un moteur de recherche. Les logiciels comme Firefox peuvent ensuite s'adapter automatiquement.
La norme officielle est consultable en http://www.opensearch.org/Specifications/OpenSearch/1.1#OpenSearch_description_document. Voici,
à titre d'exemple, un résumé de la description de ce blog :
<OpenSearchDescription xmlns="http://a9.com/-/spec/opensearch/1.1/">
<ShortName>Blog Bortzmeyer</ShortName>
<Description>Recherche dans le blog de Stéphane Bortzmeyer</Description>
<InputEncoding>UTF-8</InputEncoding>
<SearchForm>http://www.bortzmeyer.org/search</SearchForm>
<Url type="text/html" method="GET" template="http://www.bortzmeyer.org/search">
<Param name="pattern" value="{searchTerms}"/>
<Param name="default_connector" value="AND"/>
</Url>
</OpenSearchDescription>
Vous pouvez aussi consulter la version complète. C'est donc assez simple à écrire en suivant la documentation, ou bien
en s'inspirant de descriptions existantes (comme celle
de Facebook). Il existe aussi un service, http://www.searchplugins.net/, qui permet de construire ces
descriptions interactivement et de les installer dans la foulée (il
n'est par contre pas pratique si on veut récupérer le fichier XML de
description : il faut alors regarder le source de la page
HTML et trouver l'URL
dudit fichier XML).
OK, on a maintenant une description du moteur de recherche du
site. Comment dire au navigateur Web de
l'inclure ? Il y a plusieurs solutions. On peut utiliser un peu de
code JavaScript qui appelle
window.external.AddSearchProvider, comme par
exemple en http://www.bortzmeyer.org/others/add-search-engine.html
(regardez le source pour voir comment ça marche). Mais la solution la
plus propre me semble être un élément XHTML
<link> de type search,
comme indiqué dans
la documentation de Firefox. Voici un exemple :
<link rel="search"
type="application/opensearchdescription+xml"
href="http://www.bortzmeyer.org/others/add-search-engine.xml"
title="Blog Bortzmeyer" />
Facebook, déjà cité, a un tel code dans ses pages, regardez le
source. Ces types (comme search, officiellement
enregistré en novembre 2010) pour l'élément
<link> sont normalisés dans le RFC 8288. C'est un tel code qui existe désormais dans
les pages de ce blog, permettant à Firefox d'afficher une option
d'ajout du moteur de recherche « Blog Bortzmeyer », en bas du menu des
moteurs de recherche.
Google Chrome permet également d'ajouter des descriptions OpenSearch (par le biais du code JavaScript déjà cité). Une fois que c'est fait, on peut utiliser ces moteurs de recherche en tapant le début du nom de domaine (dans mon cas, "bortzmeyer", par exemple) puis la touche tabulation (merci à fil pour la remarque).
Plusieurs autres ressources sont disponibles en http://www.opensearch.org/, n'hésitez pas à le parcourir.
Merci à Nicolas Krebs de m'avoir encouragé et à Patrick Mevzek pour ses descriptions de divers sites utiles, qui m'ont donné envie de m'y mettre sérieusement.
L'article seul
Maman, j'ai rooté mon téléphone
Première rédaction de cet article le 15 mai 2011
Voilà, c'est tout à fait banal, des tas de gens l'ont déjà fait mais je n'ai sauté le pas que récemment, je suis passé root sur mon téléphone portable (un HTC Desire). Je contrôle désormais tout de mon système Android.
Pourquoi rooter son téléphone ? Il y a des tas de bonnes raisons mais, dans mon cas, la principale a été une bogue du système Android qui, suite au crash d'une application (Plume, lors d'une purge de son cache), ne démarrait plus ou, plus exactement, était coincé dans la bien connue « boucle de démarrage » (boot loop) : Android démarre, crashe, redémarre, recrashe, etc. Le système d'exploitation installé par HTC sur ce téléphone ne fournissait qu'un seul moyen de s'en sortir, le Hard reset (on démarre le téléphone avec les boutons Power et Volume down enfoncés et on choisit l'option Clear storage qui ramène aux réglages d'usine... et vous fait perdre vos données et configurations). J'avais hésité à rooter le téléphone par souci d'éviter les ennuis, pour avoir un usage pépère du téléphone, et j'ai quand même eu une bogue gravissime. Tant qu'à avoir des problèmes, me suis-je dit, autant avoir des problèmes en étant root.
Pour l'amusement et l'instruction du public, voici les étapes que j'ai suivies :
- La documentation de CyanogenMod est très
bien faite et c'est celle que j'ai suivi :
http://wiki.cyanogenmod.com/index.php?title=HTC_Desire_(GSM):_Full_Update_Guideet marche parfaitement. (Attention, seules les trois premières étapes concernent le rootage, les autres sont pour l'installation de Cyanogen, une version alternative d'Android. C'est fort intéressant mais ce n'est pas du rootage. rooter est nécessaire pour installer un nouveau système mais on peut rooter sans changer de système. Ces trois premières étapes conviennent donc même si on veut installer autre chose que Cyanogen.) - Téléchargement de la version Linux de Unrevoked pour ma Debian. Pas de source disponible, apparemment. Dans le monde du smartphone, pour se libérer et passer root, il faut utiliser un logiciel « boîte noire »...
- Naturellement, on fait des
sauvegardes. Dans mon cas, tout s'est bien
passé (et, de toute façon, tout avait été perdu par le Hard
reset) mais rooter est une opération
dangereuse. Faire des sauvegardes ne peut pas faire de mal. Pour
garder tout ce qui est sur la carte SD du HTC
Desire, je branche sur la machine Debian en
USB, et je rsynce :
sudo rsync -av /media/usb0 HC-Desire-2011-05-13. - Je lance Unrevoked (une interface graphique est obligatoire,
d'où le
-Epour exporter la variable d'environnementDISPLAY:sudo -E ./reflash. On suite alors simplement les instructions de Unrevoked. Cette étape-là est très simple, bien plus que ce qu'on trouve dans certains tutoriels sur le Web. On est désormais root. Les applications qui demandent à passer root produiront une demande d'autorisation sur l'écran (la sécurité des smartphones reste un problème ouvert). - Pour manipuler par la suite les images (le monde Android, bizarremment, appelle cela des ROM alors que cela n'a rien à voir avec les ROM), j'ai installé ROM manager (en utilisant le market Google).
- Avec l'application ROM Manager, j'ai installé ClockworkMod Recovery, qui permet, au démarrage du téléphone, de faire plein de manipulations intéressantes.
Voilà, c'est tout, le téléphone est prêt pour de nouvelles aventures (comme l'installation d'un système alternatif, j'ai commencé avec MIUI).
Un des avantages d'être root est qu'on peut utiliser un outil de
capture d'écran. (Ceux-ci nécessitent un accès à la mémoire physique
de l'écran, donc ne sont pas possibles sur un téléphone non rooté.)
Voici par exemple une copie, faite avec AndroSS, du journal des autorisations (applications
qui sont passées root) :  .
.
Un autre avantage est qu'on dispose d'un émulateur de terminal, et
qu'on peut donc avoir accès à un vrai shell
Unix. Voici un exemple, avec l'émulateur de CyanogenMod :  .
.
L'article seul
RFC 6235: IP Flow Anonymization Support
Date de publication du RFC : Mai 2011
Auteur(s) du RFC : E. Boschi, B. Trammell (ETH Zurich)
Expérimental
Réalisé dans le cadre du groupe de travail IETF ipfix
Première rédaction de cet article le 14 mai 2011
La question de la protection de la vie privée sur l'Internet est, à juste titre, une question très sensible et qui a déjà agité beaucoup d'électrons sur les blogs et autres sites Web, d'autant plus que de grosses et puissantes entreprises, comme Facebook et Google sont à l'œuvre pour réduire cette vie privée à pas grand'chose. Parmi toutes les problèmes pratiques que pose la protection de la vie privée, ce RFC se limite à celui des fichiers de trafic réseau, contenant des données sensibles et qu'on souhaite anonymiser. Le RFC se concentre sur le format IPFIX mais la plupart des problèmes exposés et des recommandations faites peuvent s'appliquer à d'autres formats comme les journaux de connexion ou comme les fichiers pcap. Un RFC utile, donc, pour tous les techniciens qui se soucient de la vie privée de leurs utilisateurs (et qui n'ont donc pas été embauchés par Facebook).
« Anonymiser » n'est pas un bon terme (mais je reprends celui du RFC). Tout le problème est qu'en effet les données ne sont pas réellement anonymes après cette opération : il est devenu simplement plus difficile de les relier à une personne ou une organisation donnée. Mais ce n'est pas impossible : de nombreux travaux de recherche ont montré qu'on pouvait reconstituer une bonne part des données manquantes dans un fichier « anonymisé ». Un exemple est l'excellent article de Bruce Schneier : « Why 'Anonymous' Data Sometimes Isn't » qui montre très bien à quel niveau de perfectionnement les outils de « désanonymisation » sont parvenus.
Avant d'attaquer le RFC lui-même, commençons par un exemple simple. Supposons qu'on ait enregistré le trafic réseau en un endroit donné et qu'on récupère donc un fichier pcap. On peut le dire avec divers outils comme tcpdump et voici un résultat typique :
% tcpdump -n -v -r MYFILE.pcap
...
15:00:24.451549 IP (tos 0x0, ttl 64, id 17621, offset 0, flags [DF], proto TCP (6), length 1059)
192.168.2.1.41949 > 193.159.160.51.80: Flags [P.], cksum 0xd268 (correct), seq 1029:2036, ack 247, win 108, options [nop,nop,TS val 2792071 ecr 1944126014], length 1007
On peut y voir que 192.168.2.1 interrogeait le
serveur HTTP
193.159.160.51 (un des serveurs
d'Akamai, qui héberge
www.wired.com, le site cité précedemment). On sait
que c'était de l'HTTP par le port de
destination (80) mais on aurait aussi pu le déduire en examinant les
données (que tcpdump n'affiche pas, mais qui sont bien dans le fichier
pcap et qu'un outil comme Wireshark peut
afficher de manière très lisible ; ces mêmes données auraient pu nous
dire qu'elle était la page Web exacte qui avait
été consultée). Autre exemple, le journal d'un
serveur HTTP où on trouvera des choses comme :
2001:db8:33::dead:beef:1 - - [10/May/2011:19:49:57 +0200] "GET /aventures-jules.html HTTP/1.1" 200 5306 "-" "Mozilla/5.0 (X11; Linux x86_64; rv:2.0.1) Gecko/20100101 Firefox/4.0.1" www.bortzmeyer.org
qui nous indique que la machine d'adresse IP 2001:db8:33::dead:beef:1 a
consulté la page aventures-jules.html de ce
serveur. Ces informations sont-elles
sensibles ? D'abord et avant tout sont-elles
nominatives, ce qui, dans la loi
Informatique & Libertés ne se limite pas
aux informations comportant le nom d'une personne physique, mais
inclut celles qui permettent de retrouver facilement cette personne
(comme le « numéro de Sécu »). Ici, l'adresse IP source
n'est pas la vraie (les données ci-dessus ont été anonymisées) mais,
si elle l'était, elle permettrait assez facilement de retrouver
l'auteur de cette visite à Wired et donc il est
tout à fait justifié de considérer l'adresse IP comme nominative.
Et c'est embêtant pour les chercheurs et les analystes. Car de telles données de connexion sont très utiles et de nombreux articles scientifiques intéressants ont été produits à partir de données comme celles-ci, collectées dans des grandes opérations comme le DITL. De même, les opérateurs réseaux ont souvent besoin d'analyser ces données pour mieux comprendre ce qui se passe dans leur réseau et pour l'améliorer. Enfin, l'étudiant, le curieux, le programmeur qui met au point un nouvel outil d'analyse ont besoin de telles données (on trouve par exemple plein de fichiers pcap sur pcapr.net). Mais transmettre ces données, les rendre publiques, les envoyer dans un pays qui n'a aucune législation de protection de la vie privée, comme les États-Unis, pose des problèmes éthiques et légaux considérables.
Une façon courante de concilier ces deux demandes est d'anonymiser les données. Par exemple, si on supprime l'adresse IP, on a enlevé la donnée la plus sensible, tout en permettant encore plusieurs analyses (par exemple sur la taille des paquets, sur les ports - donc, souvent, les services - les plus fréquents, etc. Mais en faisant cela, on a interdit certaines analyses, comme par exemple la répartition du trafic (tout le monde consomme t-il pareil, ou bien certains gros consommateurs sont-ils « responsables » de la majorité du trafic ?) Bref, l'anonymisation sera toujours un compromis : plus on retire de données et mieux on a anonymisé. Et plus les données perdent de leur intérêt... Il faudra donc prendre une décision en fonction des risques et des bénéfices. L'IETF n'a évidemment pas le pouvoir de prendre une telle décision mais ce RFC pose au moins les bases techniques nécessaires pour comprendre les choix. Il insiste notamment sur les techniques de désanonymisation, qui font que certaines techniques d'anonymisation ne protègent guère la vie privée.
Pour prendre l'exemple des requêtes DNS, si
on peut croire que l'adresse IP source (qui est celle du résolveur,
par celle du client final) n'est pas une information bien sensible, il
ne faut pas oublier que le contenu de la requête
(le QNAME, pour Query NAME)
peut en dire beaucoup. Par exemple, certains réseaux sociaux utilisent
un sous-domaine qui a le nom de l'utilisateur.
Passons au RFC maintenant. Il a deux parts, une première générale sur les techniques d'anonymisation, leurs forces et leurs faiblesses et une seconde spécifique au format IPFIX (RFC 7011). La première partie intéresse tous les programmeurs et récolteurs de données. Le fait d'avoir un format standard, IPFIX, pour les échanges d'information sur les flots de données (pcap - un standard de fait - est limité aux paquets individuels, une information de plus bas niveau) est évidemment un avantage pour tous ceux qui font circuler de l'information mais cela augmente aussi les risques de divulgation. D'où l'importance particulière de ce problème pour IPFIX.
Commençons par une définition rigoureuse de l'anonymisation (qu'il faudrait normalement écrire entre guillemets à chaque fois, tellement on est loin du vrai anonymat). La section 1 la définit comme la suppression ou la transformation d'une information qui, sans cette suppression ou cette transformation, pourrait permettre d'identifier la personne ou de l'organisation à l'origine d'une communication. Il ne faut pas utiliser l'anonymisation seule (elle a des tas de limites, notamment en raison de la puissance des techniques de désanonymisation) mais elle peut être un outil utile dans un arsenal de mesures de protection de la vie privée.
La section 1.4 rappelle d'ailleurs que ce RFC a le statut « Expérimental » car il considère que toutes les techniques d'anonymisation sont encore peu fiables (voir Burkhart, M., Schatzmann, D., Trammell, B., et E. Boschi, « The Role of Network Trace Anonymization Under Attack »).
La première partie de ce RFC revient sur ces techniques, d'une manière indépendante du format des données (pcap, IPFIX, etc). D'abord, la section 3 classifie les techniques d'anonymisation. Toutes ont en commun de chercher à empêcher la traçabilité, tout en préservant les informations utiles à l'analyse. Elles fonctionnent par mise en correspondance de l'espace des vrais valeurs vers un autre espace, « anonyme », suivant une fonction bien définie. La mise en correspondance est récupérable si on peut inverser cette fonction (ce qu'on ne souhaite évidemment pas, pour l'anonymisation) et commensurable (ou mesurable) si les deux espaces ont la même taille (préservant ainsi toutes les analyses qui cherchent à compter, par exemple le nombre d'adresses IP distinctes). Ainsi, une fonction de généralisation qui ne garderait que les N premiers bits de l'adresse IP (pour empêcher l'identification d'un individu) ne serait pas commensurable (plusieurs adresses IP seraient mises en correspondance avec un préfixe unique). Lorsque la fonction est commensurable, la technique d'anonymisation est appelée une substitution (je change chaque adresse IP par une autre). Notez que la substitution est vulnérable aux attaques par force brute, même si l'attaquant ignore la fonction utilisée, s'il peut injecter le trafic qu'il veut et observer les résultats (une variante des attaques « par dictionnaire »).
L'anonymisation la plus radicale est de retirer complètement un champ des données (méthode du feutre noir, le black-marker, dit le RFC, du nom de l'outil des censeurs du courrier d'autrefois). Ni récupérable, ni commensurable, elle offre le maximum de sécurité mais peut faire perdre des informations précieuses.
Voyons maintenant chaque champ un à un. La section 4, qui détaille les techniques adaptées à chaque champ, commence évidemment par les adresses IP car c'est le champ le plus « nominatif ». Lorsqu'on parle d'anonymisation, on pense tout de suite à celle des adresses IP, et à juste titre (section 4.1). Le problème de leur anonymisation n'est pas simple. Par exemple, une adresse IP est structurée. Même si on supprime les N derniers bits, ceux qui restent, le préfixe, identifient encore un FAI ou une entreprise et donne donc des informations. Il y a quatre moyens d'anonymiser une adresse IP (sans compter évidemment le feutre noir) :
- La troncation, qui supprime les N derniers bits de l'adresse
(pour le programmeur, la troncation est un
ANDavec un nombre de M-N uns et N zéros). C'est ce que permet un logiciel comme Squid avec sa directiveclient_netmask, qui permet de préserver la vie privée des utilisateurs du cache en ne gardant dans le journal que le préfixe de leur adresse IP. La troncation est une généralisation (elle ne conserve pas le nombre d'adresses IP.) - La troncation inverse consiste au contraire à supprimer les N
premiers bits. Ainsi, l'organisme (FAI ou entreprise) est
masqué. C'est aussi une généralisation et deux machines sans lien entre elles (par
exemple
192.0.2.57et203.0.113.57) vont être confondues (ici, si on supprime les 24 premiers bits). Attention, si le réseau sur lequel a été fait la collecte est connu, il n'est pas difficile de retrouver le préfixe des adresses de ce réseau. - La permutation consiste à remplacer chaque adresse IP par une autre. Elle conserve donc le nombre d'adresses IP (mais pas la structure des adresses : deux machines du même réseau local peuvent se retrouver très « loin » l'une de l'autre). La façon la plus fréquente de la réaliser est via une fonction de hachage de l'adresse IP. Attention, si cette fonction est connue, une attaque par force brute (tester toutes les adresses) devient possible, surtout en IPv4. Il est donc recommandé d'introduire un élément secret (par exemple un mot de passe concaténé à chaque adresse avant le hachage).
- La pseudonymisation qui préserve le préfixe est le quatrième moyen. Elle garde les N premiers bits et fait une permutation sur les M derniers. Cela permet de garder l'information sur la « proximité » de deux adresses. Comme à chaque fois, garder de l'information permet de faire certaines études... mais augmente le risque de désanonymisation.
Les adresses MAC identifient également une machine. Elles ne sont pas toujours présentes dans les données collectées (si le point de capture est sur le réseau d'un gros opérateur, les adresses MAC de la source et de la destination ne sont pas disponibles) mais on peut les trouver dans des captures faites localement. Elles peuvent aussi apparaître comme partie d'un identificateur de couches hautes, par exemple dans certaines adresses IPv6 (cf. section 2.5.1 du RFC 4291, et RFC 8981 pour une solution). Donc, il faut également anonymiser ces adresses (section 4.2). Comme les adresses IP, elles ont une structure, mais plus simple (les 24 ou 40 premiers bits indiquent le constructeur). Comme pour les adresses IP, on peut utiliser la troncation (on ne garde typiquement que les bits qui identifient le constructeur), la troncation inverse, la permutation et la pseudonymisation structurée.
Les numéros de port et de protocole de couche 4 n'identifient pas une entité du monde réel (comme une personne) mais peuvent servir à classer les machines (par exemple, le choix des ports sources permet souvent d'identifier le système d'exploitation, cf. RFC 6056). Ils méritent donc parfois une anonymisation (section 4.5) par exemple par permutation. Le RFC ne le mentionne pas, mais il n'est pas sûr qu'une technique d'anonymisation, qu'elle qu'elle soit, puisse fonctionner avec la distribution typique des protocoles : le plus répandu sera forcément TCP (numéro 6).
Les traces de trafic réseau contiennent souvent des nombres (collectivement appelés compteurs) qui peuvent révéler des choses sur leurs émetteurs (section 4.4). On peut donc les anonymiser en diminuant leur précision ou en les quantifiant, c'est-à-dire en les répartissant dans un petit nombre d'intervalles (les corbeilles ou bin dans le texte original du RFC) et en ne gardant qu'une valeur par intervalle.
Plus étonnant, les estampilles temporelles que contiennent les traces (date de passage du paquet, dates de début et de fin du flot) peuvent être également indiscrètes (voir Murdoch, S. et P. Zielinski, « Sampled Traffic Analysis by Internet-Exchange-Level Adversaries »). Par exemple, le séquencement des paquets peut permettre d'identifier une activité (une communication téléphonique n'aura pas du tout la même répartition temporelle des paquets qu'un téléchargement donc, même sans DPI, on pourra identifier le type de trafic). On peut donc essayer d'anonymiser les indications temporelles mais la plupart des méthodes disponibles, à part bien sûr le feutre noir, sont assez faibles contre la désanonymisation (section 4.3). On peut diminuer la résolution des temps (comme on a fait pour les compteurs, par exemple arrondir à la seconde la plus proche), on peut utiliser l'énumération (méthode qui remplace chaque estampille temporelle par un chiffre croissant : elle préserve l'ordre des événements, qui peut être important mais pas les écarts, ce qui interdit de mesurer des grandeurs comme la gigue), etc.
Une fois qu'on a anonymisé les données, il faut indiquer au destinataire comment on l'a fait, pour qu'il puisse faire ses analyses (section 5). Par exemple, si les adresses IP ont été tronquées, le destinataire ne doit pas tenter d'étudier des distributions de trafic par machine, puisque plusieurs machines sont désormais regroupées dans le même préfixe. Il faudra donc indiquer si l'anonymisation était stable ou pas (la stabilité est la propriété de mise en correspondance d'une valeur de départ avec la même valeur d'arrivée ; une anonymisation instable, au contraire, peut diriger vers une autre valeur d'arrivée après un certain temps). Typiquement, un jeu de données est stable, sauf indication contraire, mais deux jeux de données peuvent ne pas l'être entre eux, donc il vaut toujours mieux l'indiquer explicitement.
S'il y a eu troncation, il faut évidemment indiquer la longueur qui a été conservée. S'il y a eu quantification, il faut donner la liste des valeurs et leurs intervalles. S'il y a eu permutation, il ne faut pas donner la fonction utilisée (ou alors, si une clé a été ajoutée, donner la fonction mais sans la clé), afin d'éviter les attaques par dictionnaire (traduire des valeurs et regarder le résultat obtenu).
L'anonymisation soulève d'autres questions de sécurité, décrites en section 9. Elle enfonce le clou que l'anonymisation n'est jamais parfaite (sauf à effacer toutes les données). Elle rappelle que l'anonymisation ne remplace pas la confidentialité. Si des données sensibles sont exportées vers un tiers de confiance, le chiffrement sur le trajet reste nécessaire, même si les données sont anonymisées.
Ici commencent maintenant les questions spécifiques à IPFIX. Si vous ne pratiquez pas ce format, vous pouvez décider d'arrêter là. Sinon, la section 1.1 offre un utile rappel des RFC 5470, RFC 5101 et RFC 7012. IPFIX permet d'envoyer des tuples TLV dont la sémantique est décrite dans un gabarit (Template). Plusieurs gabarits standards figurent dans le registre décrit par le RFC 7012.
La section 6 décrit comment représenter les données anonymisées et
les méta-informations (celles de la section 5 sur le mécanisme
d'anonymisation) dans un flow IPFIX. Les données effacées par le
feutre noir représentent le cas le plus simple : on ne les met pas du
tout dans le flot. Pour les autres, il faut ajouter au flot un
Anonymization Options Template qui décrira les
fonctions d'anonymisation. Les détails de ce gabarit figurent en
section 6.1 et 6.2. Par exemple, un champ
anonymizationTechnique va indiquer l'absence
d'anonymisation s'il vaut 1, la troncation (ou la dégradation de la
précision, qui est à peu près la même chose) s'il vaut 2,
l'énumération s'il vaut 4, etc (des exemples plus complets figurent en
section 8).
Ces considérations d'encodage ont été inscrites dans les registres
IANA d'IPFIX. anonymizationTechnique,
par exemple, est identifié par le nombre 286.
L'anonymisation est typiquement effectuée dans un relais IPFIX (Mediator), en général situé à la frontière administrative du domaine (on n'anonymise pas si les données restent dans l'organisation d'origine). Attention : outre les données proprement dites, le flot contient souvent des méta-informations sur le processus de collecte qui peuvent si on ne prend pas soin de les modifier, casser en partie ou totalement l'anonymisation. Ainsi (section 7.2.3), le temps auquel a été fait l'observation peut permettre de retrouver les estampilles temporelles, même brouillées. L'identité du réseau où a été fait la mesure permet de retrouver une partie de l'adresse IP, même en cas de troncation inverse (cette identité a la même taille qu'une adresse IPv4 et il peut donc être tentant d'utiliser une adresse du réseau local comme identité).
Plus rigolo, la section 7.2.5 recommande de se méfier des adresses IP « spéciales » (RFC 6890). Ces adresses sont en effet souvent utilisées à des fins bien connues, qui font qu'on peut les retrouver, même anonymisées, en examinant leur activité. Cela fournit alors un point de départ au travail du désanonymisateur. Le RFC recommande donc d'exclure ces adresses des données exportées.
Les mises en œuvre d'IPFIX permettent-elles aujourd'hui cette anonymisation ? Je ne crois pas mais, en dehors du monde IPFIX, il existe un grand nombre d'outils d'anonymisation. Citons :
- Celles indiquées dans mon article sur pcapr, pour les fichiers pcap,
- mod_removeip pour Apache,
- Une méthode pour les journaux du serveur Apache.
L'article seul
Les épatantes aventures de Jules
Première rédaction de cet article le 8 mai 2011
Les bandes dessinées pour enfants peuvent souvent être lues par les adultes sans problèmes : c'est ainsi que je peux recommander sans hésitation à tous mes lecteurs, même de plus de treize ans, « Les épatantes aventures de Jules », d'Émile Bravo.
C'est pour enfants, donc c'est drôle, non ? Et bien, c'est une question de point de vue. Oui, il y a beaucoup de gags mais c'est aussi un monde terrifiant que celui que voit le héros : son frère est un psychopathe dangereux, ses parents sont nuls (son père est bête et sa mère inexistante) et les autres adultes ne valent guère mieux. Il y a un curé sadique qui enseigne l'histoire et n'éprouve de plaisirs qu'à traumatiser les enfants avec des récits détaillés de torture (le cours sur le Moyen Âge l'inspire évidemment beaucoup), des savants fous (un très dangereux et une plus sympa), des dangers partout.
Le tout dans un monde où on voyage dans le temps, où on fabrique des clones, et où les extra-terrestres débarquent régulièrement. Finalement, le héros gère bien ces problèmes-là, alors qu'il est très désarmé devant la folie des adultes.
Un dessin très ligne claire, des dialogues « épatants », et c'est parti : une aventure avec Jules ne vous laissera jamais calme et détendu.
L'article seul
NSD, un autre serveur de noms pour servir ses zones
Première rédaction de cet article le 8 mai 2011
Pour la résilience de l'Internet, sa capacité à survivre aux pannes et aux attaques, il est essentiel qu'il existe un certain pluralisme ; que, pour la plupart des fonctions importantes, il existe plusieurs logiciels. Ainsi, si tous les routeurs de l'Internet étaient des Cisco, une bogue dans le code d'IOS, comme celle de l'attribut BGP 99, pourrait arrêter tout l'Internet. Si tous les serveurs DNS étaient des BIND, une bogue comme celle permettant d'arrêter un serveur par une mise à jour dynamique, et le DNS s'arrête. Il faut donc qu'il y ait des alternatives, non pas qu'elles aient forcément moins de bogues, mais simplement parce qu'elles ne seront pas publiées au même moment.
Cela semble du bon sens mais, en pratique, on constate que la plupart des techniciens se simplifient la vie en n'utilisant qu'un seul logiciel, en général le plus répandu. C'est d'ailleurs un bon test des compétences d'un administrateur systèmes : demandez-lui pourquoi il utilise tel logiciel. S'il répond par une formule passe-partout comme « parce que c'est le standard de l'industrie », c'est probablement qu'il n'a même pas envisagé de décider lui-même, et qu'il n'a sans doute pas les compétences nécessaires pour évaluer les différents logiciels existants.
Ainsi, dans le contexte du DNS, la plupart des administrateurs système Unix qui installent un serveur DNS mettent BIND sans réflechir, non pas qu'ils aient étudié plusieurs serveurs et choisi celui-ci (BIND a des tas de qualités, notamment le record de la richesse fonctionnelle), mais simplement parce que l'idée du choix ne traverse même pas leur cerveau de certifié.
Pourquoi envisager NSD comme alternative ?
C'est un logiciel pour serveur faisant autorité,
c'est-à-dire le serveur qui distribue directement le contenu des zones
(par opposition aux résolveurs qui relaient les
requêtes du client final vers les serveurs faisant autorité). Il est
utilisé par plusieurs gros TLD comme
.FR ou
.DE, ainsi que par la
racine (à chaque fois, sur une partie seulement des serveurs, pour les raisons
indiquées plus haut). NSD a
fait le choix de ne pas en faire trop, afin de rester simple et rapide
(tous les tests indiquent des performances deux à trois fois
meilleures que celles de BIND). Le code source est donc logiquement
plus court :
% sloccount nsd-3.2.5 ... Total Physical Source Lines of Code (SLOC) = 25,542 % sloccount bind-9.7.3 ... Total Physical Source Lines of Code (SLOC) = 317,497
Bien sûr que la comparaison est injuste, puisque BIND fait beaucoup plus de choses. Mais c'est justement l'un de mes arguments, plus le code est long (et BIND 9 ne permet pas d'exclure du code à la compilation) et plus il y sans doute de bogues et de failles de sécurité dedans.
Comment configure t-on NSD ? D'abord, un fichier de configuration,
nsd.conf :
server:
ip-address: 2001:db8:1::53
# Toutes les valeurs peuvent avoir une configuration par défaut
...
# Une zone DNS, "bortzmeyer.42" :
zone:
name: "bortzmeyer.42"
zonefile: "primary/bortzmeyer.42"
notify: 2001:db8:43c::1 NOKEY
provide-xfr: 2001:db8:43c::1 NOKEY
outgoing-interface: 2001:db8:1::53
Ici, on indique à NSD qu'il est serveur maître
pour bortzmeyer.42 et qu'il est donc la source
authentique des données. Celles-ci seront trouvées dans le fichier
primary/bortzmeyer.42, qui suit la syntaxe
standard du RFC 1035, section 5 (la même syntaxe
que BIND). Ce serveur a un esclave,
2001:db8:43c::1 et on notifiera cet esclave en
cas de mise à jour de la zone (RFC 1996), tout
en l'autorisant à transférer la zone depuis chez nous (RFC 5936).
Pour atteindre ses performances élevées, NSD calcule beaucoup de
choses à l'avance (ce qui augmente sa consommation mémoire : on n'a rien
sans rien). Même si les versions actuelles de NSD sont moins radicales
que la version 1 (qui stockait en mêmoire les paquets correspondant à
n'importe quelle question possible, il n'y avait plus qu'à en choisir
une et à faire un write()), NSD repose beaucoup sur ces
pré-calculs. Il est donc nécessaire de compiler la zone d'abord :
% sudo nsdc rebuild zonec: reading zone "bortzmeyer.42". zonec: processed 8 RRs in "bortzmeyer.42". zonec: done with 0 errors.
Le résultat est stocké sur disque (l'endroit dépend des options,
disons /var/lib/nsd/nsd.db) et il faut dire à NSD
de le recharger :
% sudo nsdc reload
Et voilà, NSD commence à servir la zone.
Si le serveur NSD est un esclave, on doit indiquer quel est le
maître avec la directive request-xfr :
request-xfr: AXFR 2001:db8:1::53 NOKEY allow-notify: 2001:db8:1::53 NOKEY
Il est prudent de forcer l'adresse IP utilisée pour les requêtes sortantes, pour que les demandes de transfert viennent bien de l'adresse qu'attend le maître :
# À mettre pour chaque zone: outgoing-interface: 2001:db8:43c::1
Une fois le transfert de la zone fait (NSD enregistrera dans le
journal quelque chose comme nsd[27250]: info: Zone bortzmeyer.42 serial 0 is updated to 2011050800), NSD modifiera sa base des
réponses automatiquement.
Notez que NSD, dans sa version 3, peut utiliser les transferts
incrémentaux (IXFR, RFC 1995) lorsqu'il est
esclave, mais ne peut pas les générer lorsqu'il est maître. Dans ce
cas, il faut transférer la zone entière.
On le voit, il est fréquent qu'il y ait des répétitions dans la configuration de NSD. Par exemple, si on est esclave et qu'on sert dix zones ayant toutes le même maître, on va faire beaucoup de copier/coller. Fidèle au principe de ne pas multiplier le code, NSD ne fournit pas de mécanisme de macros. Le mieux est d'utiliser un système externe comme cpp.
Si on compile NSD soi-même, un certain nombre d'options passées à
./configure permettent de retirer complètement du
code qu'on n'utilise pas, ce qui est probablement une bonne chose pour
la sécurité. Faites un ./configure --help pour
voir ces options.
La version 4 de NSD est actuellement en cours de développement. Vous pouvez en savoir plus avec l'exposé fait au RIPE 62. Sinon, il existe un bon article en français sur NSD.
Et, en guise de conclusion, une devise pour l'administrateur systèmes, « Nous vous rappelons qu'il existe d'autres possibilités. »
L'article seul
RFC 6234: US Secure Hash Algorithms (SHA and SHA based HMAC and HKDF)
Date de publication du RFC : Mai 2011
Auteur(s) du RFC : Donald Eastlake (Huawei), Tony Hansen (AT&T Labs)
Pour information
Première rédaction de cet article le 7 mai 2011
Ce long RFC (127 pages, dont la majorité est composé de code source C) est la mise à disposition de la communauté IETF du code de FIPS 180-2, décrivant les algorithmes de cryptographie de la famille SHA-2. Il remplace le RFC 4634.
Cette famille de fonctions de hachage cryptographiques normalisée par le NIST (et donc standard officiel aux États-Unis) a vocation à remplacer l'ancien SHA-1 (RFC 3174). Elle comprend SHA-224 (également décrit dans le RFC 3874), SHA-256, SHA-384 et SHA-512. Tous ont le même principe (section 1) : un document de longueur quelconque est transformé en un condensat cryptographique de longueur fixe (le nom de l'algorithme indique le nombre de bits du condensat), de telle manière qu'il doit extrêmement difficile de fabriquer un document ayant le même condensat qu'un document donné (ou même de fabriquer deux documents ayant le même condensat).
Notre RFC décrit également leur utilisation en HMAC (cf. RFC 2104), et en HKDF (HMAC-based Key Derivation Function, cf. RFC 5869). L'essentiel du RFC est tiré directement de la norme officielle et les assertions sur la sécurité de SHA-2 viennent donc directement du NIST et pas des éditeurs du RFC.
Les sections 2 à 7 du RFC résument le fonctionnement de ces algorithmes, et la section 8 est le code source C les mettant en œuvre.
La licence de ce code source figure dans le
fichier sha.h, listé en section 8.1.1. C'est une licence
BSD-3 (sans la clause de publicité), qui permet tout usage,
commercial ou non, ainsi que toute modification et
redistribution. Elle est donc adaptée au logiciel libre.
Comme copier/coller le code source depuis le RFC en éliminant les
en-têtes et pieds de page n'est pas pratique, on peut récupérer une
archive « propre » en http://www.pothole.com/~dee3/source/sha.tar. Il y
en a plein d'autres mises en œuvre de SHA décrites en http://en.wikipedia.org/wiki/SHA-2#Implementations.
Les changements depuis le RFC 4634 sont résumés dans l'annexe. Le principal est l'ajout de HKDF (HMAC-based Key Derivation Function). Il y a aussi pas mal d'errata dans le code, détectés par le meilleur relecteur des RFC, Alfred Hoenes, et désormais réparés. La licence est nouvelle (BSD-3 désormais) et a nécessité de remplacer le code de getopt.
L'article seul
RFC 6227: Design Goals for Scalable Internet Routing
Date de publication du RFC : Mai 2011
Auteur(s) du RFC : T. Li (Cisco)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF RRG
Première rédaction de cet article le 7 mai 2011
Le problème fondamental du routage dans l'Internet est connu depuis longtemps : le système actuel a du mal à fournir certains services (multi-homing, mobilité, ingénierie de trafic, etc) d'une manière qui passe à l'échelle, c'est-à-dire qui puisse grandir au rythme de la croissance de l'Internet. Un groupe de travail IRTF, le Routing Research Group travaille donc sur ce sujet et ce RFC 6227 est le cahier des charges produit.
Il est très court : il est plus facile de spécifier le problème que de décrire les solutions. Le problème (les services difficiles à fournir tout en passant à l'échelle) a déjà été présenté par le RFC 4984. Reste à concevoir les solutions et, pour cela, à décrire les exigences auxquelles doit se plier la future architecture, et leurs priorités respectives. Logiquement, le cahier des charges s'écrit au début et est publié longtemps avant que le travail ne se termine mais, ici, cela n'a pas été le cas. Les conclusions du travail sur la nouvelle architecture sont déjà sorties (RFC 6115). Simplement, le cahier des charges avait bien été écrit au début mais il a été modifié et raffiné au fur et à mesure de l'avancement du travail et d'une meilleure compréhension du problème, pour n'être publié officiellement que maintenant.
Chaque exigence listée dans ce RFC a une priorité : requise, fortement souhaitée ou souhaitée, et les exigences avec leurs priorités sont résumées dans un tableau dans la section 3.11. D'autre part, les principes traditionnels de l'Internet, tels qu'explicités dans le RFC 1958 s'appliquent toujours (notamment le principe de bout-en-bout qui indique que les deux machines terminales qui communiquent doivent faire l'essentiel du travail, puisque ce sont elles qui doivent décider, par exemple des priorités de trafic).
La « liste au Père Noël » est en section 3. D'abord, compte-tenu de la croissance continue de la table de routage globale (cf. les rapports sur la croissance de la table BGP), il est fortement souhaité (section 3.1) que le nouvelle architecture permettre de séparer la croissance de l'Internet et celle de la table de routage. Actuellement, un nouvel utilisateur qui veut être « multi-homé » proprement ajoute une entrée BGP dans la table de routage globale, qui risque donc de devenir proportionnelle au nombre de tels utilisateurs. Ce n'est clairement pas souhaitable. Notez que le RFC est ambitieux : on ne parle pas de faire croître la table de routage moins vite que le nombre d'utilisateurs, mais de ne pas la faire croître du tout lorsque ce nombre d'utilisateurs augmente.
Autre exigence, concernant l'ingénierie de trafic, c'est-à-dire la possibilité d'envoyer le trafic sur tel ou tel chemin selon des critères qui ne sont pas ceux du système de routage classique, par exemple pour forcer le passage par un lien moins coûteux. Une méthode courante aujourd'hui est d'injecter dans la table de routage globale des préfixes d'adresses IP plus spécifiques. Cela augmente la taille de ladite table. Il est donc fortement souhaité qu'une meilleure solution soit trouvée (section 3.2).
Même chose pour le multi-homing, déjà cité : il est fortement souhaité qu'il puisse aussi passer à l'échelle (section 3.3).
Une bonne partie des problèmes de l'architecture actuelle de l'Internet vient de la confusion de deux rôles dans l'adresse IP : localisateur (indique un point d'attachement dans l'Internet) et identificateur (nomme une machine ou une interface). Il est depuis longtemps reconnu (cela se trouvait déjà dans l'IEN1) que cette confusion est dommageable. Il est donc souhaité qu'on sépare ces deux rôles (section 3.4).
Un certain nombre de gens (note au passage : je n'en fais pas partie) considèrent qu'il est essentiel qu'une machine terminale, voire un réseau entier, puisse se déplacer dans l'Internet, changer de fournisseur, etc, sans remettre en cause son adresse IP et les sessions existantes. Par exemple, une connexion SSH devrait rester intacte si mon smartphone passe du Wi-Fi chez moi avec Free, au 3G chez Bouygues, voire si je passe de Free à la maison à Paris à un accès Verizon en Californie. Comme ces deux scénarios entraînent un changement de l'adresse IP, la connexion SSH cassera. Les mécanismes existants pour permettre ces changements d'attachement sans casser les connexions en cours sont la mobilité IP (RFC 5944), avec introduction d'une machine relais, le home agent, ou bien l'injection de préfixes dans la table de routage lorsque la machine se déplace. Les deux solutions sont imparfaites (la seconde impacte sérieusement la table de routage globale) et on désire donc une meilleure solution pour la mobilité (section 3.5). Le mieux serait qu'elle sépare complètement la mobilité du routage.
Autre problème du système de routage : comme il est très difficile de rénuméroter un grand réseau (cf. RFC 5887), beaucoup d'organisations font tout pour garder des adresses IP à elles, ce qui impacte le système de routage (l'agrégation des préfixes devient plus difficile). Le RFC note bien qu'une rénumérotation complètement automatique est utopique, il estime néanmoins (section 3.6) qu'on peut abaisser sérieusement le coût de renumérotation (cf. RFC 4192) et que c'est fortement souhaitable.
Autre souhait fort : que le nouvelle architecture soit conçue de manière modulaire, de manière à ce qu'on puisse en utiliser seulement une partie et à ce que les différents composants de la solution ne soient pas excessivement couplés (par exemple, si la solution introduit un tunnel, la détermination de la PMTU devrait se faire par les moyens standard, sans introduire un nouveau mécanisme pour les machines terminales).
Ce n'est pas tout que les paquets arrivent : encore faut-il qu'ils arrivent vite. La qualité du chemin trouvé par le système de routage compte donc beaucoup. Il est donc fortement souhaité (section 3.8) que ce dernier trouve une route rapidement (convergence efficace), n'en change tout le temps (routes stables) et que les routes trouvées soient proches de l'idéal (faible élongation - stretch - cette dernière étant définie comme le rapport entre la longueur du chemin effectif et la longueur du chemin le plus court possible, cf. « A Trade-Off between Space and Efficiency for Routing Tables » de Peleg et Upfal).
Autre préoccupation importante, la sécurité (section 3.9). Il est requis que la nouvelle architecture ait une sécurité au moins équivalente à l'ancienne. C'est un des deux seuls points où l'exigence est requise. Les cyniques diront que celle-ci n'est pas trop difficile à atteindre, vu le niveau de sécurité existant.
Enfin, une dernière exigence, elle aussi requise, en section 3.10 : la déployabilité. Il ne sert à rien de concevoir une splendide architecture si celle-ci reste dans les cartons. Or, des expériences malheureuses comme celle d'IPv6 ont montré que déployer des nouvautés dans l'Internet était très difficile. Il faut notamment que le nouveau système soit déployable de manière incrémentale : les premiers adoptants doivent pouvoir l'installer, et même en tirer des bénéfices immédiats. Sinon, chacun attendra que l'autre fasse le premier pas et on n'avancera pas. (Il n'est évidemment pas question de repartir de zéro, vus les investissements réalisés.)
Voilà, il n'y a maintenant plus qu'à trouver des solutions correspondant à ce cahier des charges : le RFC 6115 résume les résultats de cette quête.
L'article seul
Net.Lang, « Réussir le cyberespace multilingue »
Première rédaction de cet article le 6 mai 2011
Dernière mise à jour le 5 mars 2012
L'ouvrage « Net.Lang, réussir le cyberespace multilingue » est désormais publié, malgré les retards pris par plusieurs de ses auteurs (comme moi). Ce livre collectif, évidemment diffusé en plusieurs langues, est également disponible en ligne.
Personnellement, j'ai commis les chapitres sur « normalisation et multilinguisme » ainsi que celui sur « gouvernance et multilinguisme ».
Le livre est publié chez C & F Éditions, maison d'édition qui a publié plein de livres sous licence libre et qui promeut aujourd'hui la licence Édition équitable. Le livre Net.Lang a été lancé grâce au soutien de l'UNESCO et de l'Union latine sous la houlette de Maaya. On peut d'ailleurs trouver le compte-rendu de la réunion de lancement (le projet a évolué depuis).
Je cite le pitch (pour parler français) : « NET.LANG, est un guide pédagogique, politique et pratique permettant d'appréhender et de comprendre les principaux enjeux du multilinguisme dans le cyberespace. Le multilinguisme est la nouvelle frontière du réseau numérique. Ce livre veut en montrer les enjeux, mais aussi proposer des pistes pour une présence équitable des langues dans la société de l'information. Ce livre s'adresse à des acteurs et actrices de la vie politique, économique, culturelle ou sociale confrontés à la place grandissante prise par le cyberespace dans nos sociétés et qui s'interrogent sur la portée de la diversité linguistique dans ce contexte numérique. Promouvoir sa langue, décider de politiques linguistiques, enseigner une ou des langues, travailler sur une langue, traduire ou interpréter des langues, créer du contenu dans plusieurs langues, s'adresser à des personnes d'autres langues... autant de situations pour lesquelles ce livre veut donner des pistes. La vitalité du multilinguisme est une force tant pour le développement de l'internet que pour la construction de sociétés inclusives, partageant les savoirs et les travaillant dans l'objectif du bien vivre ensemble. » L'ISBN de la version française est 978-2-915825-08-4 et celui de l'anglaise 978-2-915825-09-1.
Net.Lang a été présenté lors
de l'émission « Place de la Toile » sur France
Culture le 3 mars 2012, accessible en
podcast. Le site officiel du livre est http://www.net-lang.net/. Prochaine étape, le Salon du Livre à Paris, du
16 au 19 mars, au stand de C&F Éditions.
L'article seul
Changer d'hébergeur : quoi choisir après Slicehost ?
Première rédaction de cet article le 5 mai 2011
Dernière mise à jour le 21 novembre 2011
Ce blog était en partie hébergé par Slicehost mais cette société a été acquise il y a quelque temps par Rackspace qui vient d'annoncer la disparition de l'offre Slicehost. Où aller ?
J'appréciais chez Slicehost la fiabilité, et l'information « zéro connerie » (des faits, pas du discours de marketeux). Le message de Rackspace va exactement en sens inverse (ils ne parlent que d'eux, pas du service, et ils agitent des grands mots, notamment Cloud, pour éviter de parler des conséquences pratiques pour les utilisateurs). Bien sûr, la référence à IPv6 (un des principaux manques de l'ancienne offre de Slicehost, consternant en 2011 mais courant) est amusante mais elle ne va pas suffire à me faire rester chez Rackspace.
Il y a des tas d'hébergeurs de machines (virtuelles ou physiques, sachant que la différence n'est pas toujours aussi tranchée que cela, par exemple dans certaines offres, le processeur est bien dédié mais le stockage virtualisé...). J'ai spécialement besoin d'une machine aux USA car :
- Je fais des tests et des mesures réseau, qui doivent être faites depuis le hub de l'Internet.
- Les lois et les pratiques n'étant pas les mêmes, certaines activités peuvent poser plus ou moins de problèmes selon le pays, il est donc préférable d'avoir une machine en dehors du Sarkozystan. (Note pour mes lecteurs juristes : je suis parfaitement conscient que la question est complexe, du point de vue juridique et politique. Si un utilisateur turc loue à une boîte française un serveur dédié qui est physiquemebnt situés aux États-Unis - ce que permet Gandi avec son centre de Baltimore -, quelle loi s'applique ? Les trois ? Disons donc que mon but principal est, si tout hébergeur en France doit filtrer selon la LOPPSI, de pouvoir avoir un accès réseau indépendant de ce système de filtrage, notamment pour tester.)
Et j'ai déjà une machine en France donc pas besoin de me citer les hébergeurs français, je cherche de la redondance.
Quelles sont les possibilités ? Je cherche donc une machine où je suis root (a priori Debian ou Gentoo), et pas trop chère (c'est un usage surtout personnel) :
- Linode est la référence, celui que tout le monde connait. Pas cher, c'est sûr. Grand choix de systèmes d'exploitation. IPv6 disponible sur une partie de leurs hôtels. J'ai fait un petit essai chez eux et la console Web mise à la disposition des clients est vraiment très bien.
- 6sync est moins connu. Pas cher et à peu près le même choix. J'ai bien aimé le ton rigolo du site Web (par exemple les trois options pour le support, « community », c'est-à-dire « démerdez-vous », « handholding » et « red carpet »). IPv6 est disponible depuis peu.
- Également dans la rubrique « peu connu », Zerigo. Même genre de prix, mais moindre choix des systèmes d'exploitation (pas de Gentoo). IPv6 disponible.
- Host Virtual est apparemment dans la même gamme de prix, fournit IPv6 et un large choix de systèmes d'exploitation (y compris FreeBSD).
- Le record de la page Web pour Geek revient certainement à PRMGR. La forme plaira aux utilisateurs de lynx et, sur le fond, leur offre semble très intéressante (et ce sont les seuls à mentionner NetBSD).
- SVWH est un peu cher et n'a pas IPv6 mais on notera que c'est l'un des seuls qui affiche FreeBSD dans les systèmes d'exploitation disponibles (apparemment uniquement dans certaines conditions).
- RapidXEN semble plus cher que les autres mais fait partie de ceux qui offrent IPv6.
- ARPnetworks semble être le seul à proposer OpenBSD (je n'ai pas l'intention de l'utiliser mais c'est rigolo).
- Pas eu le temps de tester NQhost, qui semble très intéressant.
Et je n'ai pas encore regardé d'autres critères comme l'API (pas indispensable pour moi, je ne passe pas mon temps à créer et détruire des VPS), la fiabilité (difficile à évaluer), les statistiques fournies, la communauté (c'était un des côtés sympa de Slicehost), etc.
Il existe d'autres offres qui semblent moins intéressantes :
- Xlhost est très cher (plus de double des offres précédentes). Pas non plus de Gentoo mais on peut avoir Windows si on y tient.
- L'offre EC2 d'Amazon. Très cher également. À noter que ma décision de ne pas retenir Amazon ne vient pas de leur récente panne (sur laquelle Amazon a produit un très bon rapport) : tout le monde a des pannes et rien n'indique qu'Amazon soit pire que les autres (j'utilise Amazon EC2 pour un autre projet).
- Hurricane Electric est un fournisseur sérieux et connu, mais leurs prix (qui ne sont même pas disponibles publiquement) sont hors de portée du particulier. À noter que c'est Hurricane Electric qui connectait ma machine Slicehost en IPv6, via un tunnel qui a toujours très bien marché.
- VPSzone est très bon marché et affiche plusieurs systèmes d'exploitation. Le formulaire de création d'une machine est très embrouillé ; par exemple, au début, on ne voit que CentOS, il faut insister.
À noter qu'il existe un site de comparaison. Finalement, j'ai fait un tableau de comparaison au dos d'une enveloppe, notant le prix pour deux offres (une toute petite machine, 256 Mo de RAM et 8 Go de disque, tous les hébergeurs n'ont pas une telle offre, et une petite, 512 Mo de RAM et 20 Go de disque), la disponibilité d'IPv6 et celle de Gentoo (dans l'idée que, si Gentoo est disponible, beaucoup d'autres systèmes le seront). Les prix sont très proches pour tous (dans les 20 dollars par mois pour la première et dans les 12 pour la seconde) et n'ont donc pas été un facteur discriminant.
J'ai finalement choisi 6sync et ce blog est désormais hébergé chez
eux (si vous regardez bien, il y a aussi un autre hébergeur en
IPv6). Voici un exemple des graphes qu'on a sur la console Web de
gestion du serveur :
L'article seul
Résolution de noms Internet dans un nouveau langage de programmation
Première rédaction de cet article le 4 mai 2011
Une question philosophique aujourd'hui : si on conçoit un nouveau
langage de programmation, et qu'on dote
celui-ci d'une belle bibliothèque standard, une
des fonctions de base sera certainement la résolution de
noms de domaine en adresses IP. Comment implémenter cette résolution ?
Coder tout soi-même dans son nouveau langage ou bien s'interfacer avec
la bibliothèque existante du système d'exploitation, typiquement en appelant la fonction
standard getaddrinfo() (RFC 3493) ?
La question n'est pas purement théorique. Si on regarde la bogue #1166 d'une des implémentations du langage Go, on voit qu'il a fallu plusieurs mois pour décider puis pour changer. Pourquoi était-ce un problème ?
Parce que résoudre un nom en adresse IP peut utiliser plusieurs
mécanismes, et que le choix entre ces mécanismes peut dépendre de
politiques locales. Ainsi, l'ancienne implémentation dans
Go utilisait uniquement
le fichier /etc/hosts et le
DNS. Mais c'est erroné : la résolution de noms
peut se faire via bien d'autres moyens, comme
LDAP ou NIS. Et de
nouveaux moyens peuvent être ajoutés dans le système, forçant à
ajouter encore du code à la bibliothèque.
Pire, la sélection entre ces différents moyens et, pour chaque
moyen, entre ses différentes options, peut dépendre de réglages locaux
que la bibliothèque standard devrait respecter. Ainsi, sur
Unix, on peut choisir le mécanisme de
résolution via le fichier /etc/nsswitch.conf. Par exemple :
hosts: dns ldap files
cherchera à résoudre les noms d'abord par le DNS puis LDAP puis enfin
via un fichier statique (/etc/hosts). Même en se
limitant au DNS, d'autres réglages sont possibles. Ainsi de la
priorité entre IPv4 et
IPv6 qui se règle en /etc/gai.conf (RFC 6724). Une
implémentation de la résolution de noms doit donc lire et analyser ce
fichier pour servir des adresses IPv4 ou IPv6 selon ce qu'a décidé
l'administrateur système. Le malheureux
mainteneur de la bibliothèque standard du nouveau langage a donc
beaucoup de travail avant de reproduire le comportement exact de
getaddrinfo(). Et, s'il ne le fait pas, un
programme écrit en Go n'aura pas le même comportement qu'un programme
écrit en C (par exemple, l'un utilisera en priorité les adresses IPv4
et l'autre les adresses IPv6).
L'autre solution est donc d'appeler la fonction standard
getaddrinfo(), typiquement en utilisant les
conventions d'interface pour C, que quasiment
tous les langages de programmation savent utiliser (appeler les
bibliothèques écrites en C est indispensable). Cela présente des
inconvénients : C ne garantit pas certaines propriétés que des
langages de plus haut niveau considèrent comme indispensables. Par
exemple, dans un langage à gestion de la
mémoire, comme Go, on ne peut plus garantir que toute la
mémoire sera bien récupérée. Dans un langage parallèle (toujours comme
Go), on ne peut pas toujours être sûr que le sous-programme C est
réentrant.
Malgré ces inconvénients, la majorité des biobliothèques standard
qui font de la résolution de noms semble avoir choisi la même voie :
appeler le sous-programme C getaddrinfo() pour
être sûr d'avoir exactement la même sémantique que lui.
L'article seul
RFC 6168: Requirements for Management of Name Servers for the DNS
Date de publication du RFC : Mai 2011
Auteur(s) du RFC : W. Hardaker (Sparta)
Pour information
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 4 mai 2011
Traditionnellement, les serveurs DNS étaient
gérés par des mécanismes spécifiques au logiciel
utilisé. BIND a son rndc,
Unbound son
unbound-control (voir des exemples à la fin), d'autres logiciels utilisent
d'autres méthodes et on n'avait pas de moyen facile de gérer un ensemble
hétérogène de serveurs. En outre, ces programmes n'étaient pas prévus
pour des autorisations précises (modifier telle zone mais pas telle
autre) et cela rendait difficile de déléguer la gestion d'une
partie du service à un
tiers. L'IETF est donc lancée depuis quelques
années dans un effort pour mettre en place un mécanisme standard de
gestion à distance des serveurs DNS et ce RFC 6168 en est
le cahier des charges formel.
Car c'est un vieux projet ! Une des étapes avait été la publication, il y a plus de quatre ans, du brouillon « Requirments for the Nameserver Communication protocol ». Il y a eu ensuite un groupe de travail restreint, nommé DCOMA, dont j'ai fait partie. Le projet a avancé à une allure de tortue mais, au moins, il a désormais un cahier des charges figé. Avant même le document cité plus haut, un effort de normalisation avait mené à deux MIB, décrites dans les RFC 1611 et RFC 1612, qui n'avaient jamais été réellement déployées et ont été officiellement abandonnées par le RFC 3197.
L'annexe A rassemble quelques études de cas, pour illustrer à quoi
pourrait servir un tel protocole. Par exemple, en A.1 se trouve le cas
de zones locales non-standard comme un .prive ou
.local. Si des TLD locaux
sont une
mauvaise idée, ils n'en sont pas moins très utilisés et des
domaines purement locaux peuvent avoir un sens dans certains
cas. Actuellement, pour qu'un tel système fonctionne, il faut mettre
des directives stub ou
forward dans tous les
résolveurs de l'organisation, et garder ces résolveurs (qui peuvent
être de marques différentes) synchronisés. D'une façon générale, gérer
un pool de résolveurs DNS qui doivent avoir la même
configuration (par exemple les mêmes clés
DNSSEC, cf. annexe A.3) est une tâche courante pour un
FAI et plutôt pénible. Le futur protocole de
contrôle pourrait faciliter l'automatisation de cette tâche.
A.2 propose un autre cas, dans l'optique de résilience maximale
d'une zone DNS : le RFC 2182 recommande à juste
titre qu'une zone DNS soit servie par plusieurs serveurs de noms, ne
partageant pas de SPOF. Une solution fréquente
est l'hébergement réciproque des zones d'un partenaire. Par exemple
(au 12 avril 2011), l'AFNIC héberge un serveur
secondaire de .nl et
SIDN (Stichting Internet Domeinregistratie Nederland) a un serveur secondaire de
.fr. La configuration
correspondante est actuellement maintenue à la main, ou par des
logiciels ad hoc. Ainsi, si un TLD dont le
serveur secondaire est à l'AFNIC, veut tout à coup autoriser le
transfert de zones, ou au contraire le restreindre à certaines
adresses IP, il doit envoyer un message et attendre qu'un technicien
de l'AFNIC
ait changé la configuration. De même, si deux hébergeurs DNS assurent
réciproquement un service de secours en hébergeant les zones de
l'autre, la création d'une nouvelle zone doit actuellement être
automatisée par des moyens spécifiques du logiciel utilisé. À noter
que ce cas nécessite des autorisations à grain fin, comme rappelé en
section 4.4.
Ce cahier des charges concerne à la fois les serveurs faisant
autorité (par exemple ceux de
.FR) que les récurseurs
(par exemple les résolveurs de votre FAI). La
section 2.2 donne des détails sur les types de serveurs qui seront
gérés (les maîtres, les esclaves, et les récurseurs). Les
stub resolvers (la bibliothèque de résolution de
noms sur votre machine) sont exclus du champ d'application de ce
projet. De même, le futur protocole qui mettre en œuvre ces
exigences ne s'occupera que de la configuration des serveurs, pas des
données servies (pour lesquelles il existe déjà des protocoles
standard de transmission, cf. RFC 2136 et RFC 5936).
Le RFC est écrit sous forme d'une suite d'exigences, chacune dans sa propre section. Donc, le numéro de section identifie l'exigence. Voyons les principales.
L'exigence 2.1.1 concerne la taille : parmi les serveurs faisant
autorité, il y en a avec peu
de zones mais beaucoup de données dans ces zones (les serveurs des
TLD par exemple) et d'autres avec beaucoup de
toutes petites zones (un hébergeur DNS qui accueille des centaines de
milliers de mapetiteentreprise.com). La solution
doit convenir pour toutes les tailles.
La solution pourra permettre la découverte automatique des serveurs de noms existant sur le réseau mais ce n'est pas obligatoire (exigence 2.1.2).
Elle devra fonctionner pour des serveurs dont la configuration change souvent (nombreuses zones ajoutées et retirées par heure, par exemple, exigence 2.1.3).
Pour contrôler quelque chose, il faut un modèle décrivant la chose en question. L'exigence 2.1.5 impose donc la création d'un modèle de données d'un serveur de noms. Enfin, 2.1.6 impose que la nouvelle solution n'interfère pas le service principal, le DNS lui-même.
La section 3 décrit les classes d'opérations de gestion à implémenter :
- Contrôle (arrêter, redémarrer),
- Configuration (ajouter une zone, ajouter une clé de confiance DNSSEC, etc),
- Surveillance de l'état du serveur (pour intégrer dans des solutions comme Nagios),
- Déclenchement d'alarmes.
Le futur protocole devra gérer toutes ces classes.
Quelles sont les opérations à faire sur un serveur de noms ? La section 3.1 liste les plus importantes :
- Démarrer et arrêter le serveur,
- Recharger la configuration,
- Recharger une zone (ou toutes les zones),
À noter que l'opération « démarrer le serveur » est la seule qui ne puisse pas être mise en œuvre dans le serveur lui-même.
Comme certaines de ces opérations peuvent être très longues (la seule lecture du fichier de zone d'un gros TLD peut prendre du temps), la même section demande en outre que le futur protocole ait un mécanisme de notification asynchrone (« fais ça et préviens-moi quand c'est fini »).
Et question configuration, que doit-on pouvoir configurer ? La section 3.2 donne une liste :
- Les zones à servir (pour un serveur maître) ; à noter qu'il existe déjà des protocoles standard pour transmettre les données contenues dans ces zones (RFC 5936, RFC 1995 et RFC 2136),
- La liste des zones à servir ; on doit pouvoir ajouter et retirer
des noms à cette liste (« tu fais maintenant autorité pour
foobar.exampleet ton maître est2001:db8:2011:04:11::53»), ce qui n'est pas possible de manière standard actuellement, - Les clés de confiance utilisées dans des protocoles comme DNSSEC,
- Les clés utilisées par TSIG (RFC 8945),
- Les autorisations : qui a le droit de faire des mises à jour dynamiques (RFC 2136), qui a le droit de transférer le contenu de la zone, qui a le droit de faire des requêtes récursives, etc.
Le protocole, on l'a vu, doit également permettre la surveillance du bon fonctionnement du serveur. Des exemples de données utiles sont (section 3.3) :
- État du serveur (« fonctionnement normal », « en cours d'arrêt », etc),
- Statistiques de base, comme le nombre de requêtes traitées, le nombre d'erreurs, etc,
- Liste des zones actuellement servies,
- Alertes de sécurité.
Le serveur doit pouvoir transmettre ces informations à la demande du logiciel de surveillance, mais aussi pouvoir sonner des alarmes sans qu'on lui ait rien demandé (section 3.4) :
- Changement d'état du serveur (« ça y est, je suis prêt » ou au contraire « plus de mémoire, j'arrête tout »),
- Problème de sécurité (tentative de transfert d'une zone refusée, par exemple).
Un tel protocole, riche en fonctions, peut attirer l'attention des méchants : arrêter à distance un serveur de noms, sans avoir besoin de se connecter sur la machine, est tentant. D'où la section 4 qui pose les exigences de sécurité du protocole (voir aussi section 6). La plus importante est l'exigence d'une authentification mutuelle : le serveur de noms doit pouvoir authentifier le logiciel de gestion et réciproquement. Il est également nécessaire que le protocole soit confidentiel : des informations secrètes (comme les clés TSIG) seront parfois transmises par ce canal. Et, une fois l'authentification faite, le protocole doit permettre d'exprimer des autorisations détaillées : tel client peut ajouter des zones mais pas redémarrer le serveur, tel client peut lire toutes les informations mais n'en modifier aucune, etc.
La section 5 est ensuite un pot-pourri d'exigences supplémentaires pour le futur protocole de contrôle des serveurs de noms. On y trouve les grands classiques comme l'extensibilité dans le temps (futures fonctions) et dans l'espace, via des extensions spécifiques à un vendeur (un logiciel donné peut toujours avoir des fonctions très spéciales, trop spéciales pour être normalisées, mais qu'il serait intéressant de contrôler via le protocole).
Pour avoir une idée plus précise des fonctions d'un tel protocole, on peut regarder ce qui existe aujourd'hui. Comme exemple de serveur faisant autorité, essayons BIND. Son outil de contrôle à distance se nomme rndc. Il y a plusieurs moyens de le configurer (la plupart des paquetages binaires de BIND font tout cela automatiquement), ici, je vais générer une clé d'authentification et un fichier de configuration à la main. La clé est une clé secrète partagée, on la génère avec dnssec-keygen :
% dnssec-keygen -a hmac-md5 -n HOST -b 128 samplekey
Le fichier produit, ici
Ksamplekey.+157+06915.private, contient le
secret :
% cat Ksamplekey.+157+06915.private ... Key: 7fCXQYhOXW+jkpEx9DuBdQ== ...
On va alors créer le fichier de configuration de rndc. Comme il contient un secret (la clé), il faudra s'assurer que ce fichier ait les bonnes protections :
options {
default-server localhost;
default-key samplekey;
};
server localhost {
key samplekey;
addresses { ::1 port 9153; };
};
key samplekey {
algorithm hmac-md5;
secret "7fCXQYhOXW+jkpEx9DuBdQ==";
};
Et il faut configurer le serveur de noms, dans son
named.conf. Ici, le protocole de contrôle
n'acceptera que localhost
(::1) sur le port 9153 (la valeur par défaut est 953) :
key samplekey {
algorithm hmac-md5;
secret "7fCXQYhOXW+jkpEx9DuBdQ==";
};
controls {
inet ::1 port 9153
allow {::1;}
keys {samplekey;};
};
Je me répète, attention à la sécurité. Car, s'il peut lire la clé, un utilisateur pourra arrêter BIND, supprimer des zones, etc.
Voyons maintenant des exemples d'utilisation :
% rndc status version: 9.8.0 number of zones: 2 ... server is up and running
Cette commande était bien inoffensive. Mais on peut en faire d'autres comme :
- Recharger une zone (
rndc reload $MAZONE), - Arrêter le serveur (
rndc stop), - Ajouter une nouvelle zone à servir (
rndc addzone example.com '{ type master; file "example.com"; };'), - Et bien d'autres...
À la lumière du cahier des charges, que manque t-il à BIND ? Les
grandes lignes y sont mais il manque pas mal de détails comme les notifications asynchrones, les changements d'ACL et peut-être la finesse des
autorisations. rndc addzone
nécessite une option spéciale dans named.conf
mais elle s'applique à toutes les zones et, de toute façon, on ne peut
pas la lier à certaines clés seulement. Une fois qu'on a un accès au
serveur, c'est un accès total.
Comme exemple de serveur récursif, prenons
Unbound. La configuration se fait dans le
unbound.conf à peu près comme ceci (même adresse
et port qu'avec BIND plus haut) :
remote-control: control-enable: yes control-interface: ::1 control-port: 9153 server-key-file: "unbound_server.key" server-cert-file: "unbound_server.pem" control-key-file: "unbound_control.key" control-cert-file: "unbound_control.pem"
Les certificats X.509 utilisés pour
l'authentification peuvent facilement être créés avec
unbound-control-setup. Le programme de contrôle
du serveur utilise le même fichier de configuration
unbound.conf (contrairement à BIND) :
% unbound-control status version: 1.4.5 verbosity: 4 threads: 1 modules: 2 [ validator iterator ] uptime: 206 seconds unbound (pid 5315) is running...
et on peut faire plein de choses avec ce programme comme arrêter le
serveur (unbound-control stop), afficher d'utiles
statistiques (nombre de requêtes, nombre de succès et d'échecs de
cache, etc, avec unbound-control stats), activer
ou désactiver le relayage vers un autre serveur
(unbound-control forward 2001:db8:42::53), vider
le cache pour une zone donnée (unbound-control flush_zone
example.com, notez qu'unbound_control
a d'autres commandes de vidage, plus ou moins subtiles), etc.
Par rapport aux exigences de notre RFC 6168, on note
que unbound-control ne permet pas de changer les
clés de confiance utilisées par le serveur. Il ne peut pas non plus
afficher les zones définies localement sur le récurseur (mais il
permet d'en ajouter). Et la finesse des autorisations est insuffisante
(la possibilité de créer des zones locales est ouverte à tous ceux qui
ont un accès.) Autrement, il a une bonne partie de ce
qu'il faut pour un récurseur.
Maintenant que le cahier des charges est fait, quelles sont les
solutions pour le mettre en œuvre ? Historiquement, le protocole
officiel de gestion des machines, à l'IETF,
était SNMP. Comme on l'a vu, il y a même eu une
tentative de s'en servir avec les serveurs DNS, tentative qui n'est
pas allé loin. Aujourd'hui, la mode est plutôt à un autre protocole de
gestion, Netconf (RFC 6241). Il existe une proposition, documentée dans
l'Internet-Draft draft-dickinson-dnsop-nameserver-control,
qui utilisera dans le futur Netconf (une version précédente de cette
proposition incluait le protocole, et même une implémentation, mais la version actuelle se concentre sur le modèle de données). Voir la présentation au CENTR à Amsterdam en mai 2011.
Aux diverses réunions IETF sur le sujet, une alternative ne nécessitant pas un nouveau protocole avait souvent été proposée : se servir d'outils de gestion de configuration comme Chef ou Puppet. La principale limite de ces outils est qu'ils ne conviennent qu'à l'intérieur d'une même organisation et ne règlent pas facilement des problèmes multi-organisations.
L'article seul
RFC 6265: HTTP State Management Mechanism
Date de publication du RFC : Avril 2011
Auteur(s) du RFC : A. Barth (UC Berkeley)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpstate
Première rédaction de cet article le 29 avril 2011
Dernière mise à jour le 30 avril 2011
Les cookies, ces célèbres gâteaux du Web ont déjà fait l'objet d'innombrables articles, par exemple pour critiquer les conséquences pour la vie privée d'un mécanisme qui permet de suivre l'utilisateur à la trace (voir par exemple l'introduction de la CNIL). Mais on connait moins leur spécification technique, ou plutôt le fait que, mal spécifiés dès le début, ces gâteaux ont été mis en œuvre de diverses manières et qu'il est très difficile de décrire intégralement leur fonctionnement. C'est la tâche de notre RFC 6265, d'être, normalement, la norme technique complète et faisant autorité sur les cookies, en capturant l'ensemble des points techniques sur les gâteaux en une seule norme. Les textes précédents étaient la description originale de Netscape (on notera avec ironie que cette spécification privée n'est plus accessible que via WebArchive), puis le RFC 2109, puis le RFC 2965, que notre RFC remplace et annule. Les documents précédents étaient loin de spécifier tous les aspects des petits gâteaux.
Le point de départ est que le protocole
HTTP, le plus utilisé du
Web est sans état. Lors
d'une visite à un site Web, l'utilisateur clique successivement sur
plusieurs liens, visite plusieurs pages, et chaque téléchargement
d'une page est une requête HTTP séparée des autres, sans rien qui
permette de les corréler (par exemple pour se souvenir des préférences
exprimées par
un utilisateur lors de l'arrivée sur la première page). Les gâteaux
visent à combler ce manque. La norme définit deux en-têtes HTTP,
Set-Cookie qui permet au
serveur HTTP de déposer un gâteau sur
l'ordinateur de l'utilisateur et Cookie qui
permet au client HTTP (typiquement le
navigateur) de renvoyer un gâteau préalablement
déposé. Lorsque le serveur reçoit le gâteau, il le compare à ceux
qu'il a envoyés et reconnait ainsi un utilisateur déjà vu. HTTP
devient alors un protocole avec état.
Ce n'est pas que les gâteaux soient une solution géniale : imposés par un acteur du Web particulier, Netscape, ils n'avaient pas fait l'objet d'un examen sérieux par une SDO et ont des tas d'inconvénients techniques et politiques. Néanmoins, comme ils sont largement utilisés dans le Web, il était préférable qu'une documentation sérieuse de leur syntaxe et de leur comportement existe, et c'est le rôle de ce RFC 6265.
La section 1 de ce RFC résume le principe des gâteaux. Un gâteau
inclus un certain nombre de métadonnées qui
permettent au client HTTP de savoir si et quand il doit retransmettre
le cookie. Par exemple, on peut spécifier la
période pendant laquelle le gâteau reste valable, les serveurs à qui
on doit le renvoyer, etc. Du fait de leur spécification hâtive et non
collective, les gâteaux ont bien des faiblesses techniques. Par
exemple, l'attribut secure dans les métadonnées
ne fournit aucune garantie d'intégrité en dépit
de ce que son nom pourrait faire croire. D'autre part, les gâteaux ne
sont pas spécifiques à un port donné donc, si
plusieurs serveurs tournent sur des ports différents de la même
machine, ils peuvent se voler leurs gâteaux mutuellement. Mais, d'une
manière générale, ce RFC n'essaie pas de réparer la situation, mais de
documenter les gâteaux tels qu'ils sont réellement produits et
consommés sur le Web.
Bien, assez râlé, qui doit lire ce RFC ? Il y a deux audiences, les développeurs d'applications côté serveurs (ou, plus exactement, des bibliothèques qui sont utilisées par ces applications) qui produisent et consomment des gâteaux, et les développeurs des logiciels clients, notamment les navigateurs Web. Pour maximiser les chances d'interopérabilité, les serveurs devraient se montrer très prudents et ne produire que des gâteaux parfaitement conformes à la norme (section 4 du RFC, qui décrit le profil restreint), alors que les clients doivent être plus tolérants et accepter la grande variété des gâteaux actuellement fabriqués (section 5, sur le profil libéral), car tous les serveurs ne suivent pas le profil restreint.
Avant de lire le gros du RFC, un petit détour par la norme HTTP, le RFC 7230, peut être utile, puisque notre RFC en reprend le vocabulaire.
La section 3 décrit les généralités sur les gâteaux. Ceux-si sont
envoyés par un en-tête Set-Cookie dans la
réponse HTTP, puis retournés dans un en-tête
Cookie dans la requête
suivante. L'état est donc stocké chez le client mais, en pratique, la
taille des gâteaux étant limité, le serveur stocke l'essentiel de
l'état et le gâteau ne sert que d'index pour retrouver une session
particulière. Un serveur peut utiliser Set-Cookie
dans n'importe quelle réponse (y compris les erreurs comme 404) et le client doit le gérer (sauf pour
les réponses de type 1xx, qui sont seulement « pour
information »). Plusieurs gâteaux peuvent être envoyés, chacun dans un
en-tête Set-Cookie différent (le client, lui,
peut utiliser un seul en-tête Cookie pour envoyer
plusieurs gâteaux). Un exemple
classique est l'envoi d'un identificateur de session (ici, SID, pour
Session ID). Le serveur envoie :
Set-Cookie: SID=31d4d96e407aad42
et à la requête suivante, le client renverra :
Cookie: SID=31d4d96e407aad42
Le serveur peut réduire la portée du gâteau avec les attributs
Path et Domain. Ici, par
exemple, le gâteau doit être renvoyé pour tous les
URL dans example.com :
Set-Cookie: SID=31d4d96e407aad42; Path=/; Domain=example.com
Ici, un serveur prudent utilise en plus les attributs
Secure et HttpOnly. En
outre, il envoie deux gâteaux, SID et lang (chacun étant un doublet nom-valeur) :
Set-Cookie: SID=31d4d96e407aad42; Path=/; Secure; HttpOnly Set-Cookie: lang=en-US; Path=/; Domain=example.com
Le client peut les renvoyer en un seul en-tête :
Cookie: SID=31d4d96e407aad42; lang=en-US
Ici, le serveur fixe une date d'expiration au gâteau :
Set-Cookie: lang=en-US; Expires=Wed, 09 Jun 2021 10:18:14 GMT
Après ces exemples tirés du RFC, voici maintenant un exemple réel entre un site Web écrit en PHP et un navigateur. Le trafic a été capturé et formaté avec tshark :
# Le serveur envoie :
Set-Cookie: PHPSESSID=euk3daoldp4s3j90uocetas3a0; path=/\r\n
# Le client répond (d'autres gâteaux avaient été transmis) :
Cookie: __utma=85646793.1868252067.1190397623.1190397623.1190397623.1; \
PHPSESSID=euk3daoldp4s3j90uocetas3a0; \
culture=fr\r\n
Autre façon de voir les gâteaux, se servir du client en ligne de commande curl :
% curl -v http://twitter.com/ > /dev/null ... < Set-Cookie: guest_id=130393513906128799; path=/; expires=Fri, 27 May 2011 20:12:19 GMT < Set-Cookie: _twitter_sess=BAh7CDoPY3JlYXRlZF9hdGwrCPc8l5gvAToHaWQiJWY3NTg3YTU1YTgwOWE2%250AODcxMTA5M2NiNzNiOWMxODRmIgpmbGFzaElDOidBY3Rpb25Db250cm9sbGVy%250AOjpGbGFzaDo6Rmxhc2hIYXNoewAGOgpAdXNlZHsA--dd45d4b08ccac6e6f832ccb70af983e16a12df43; domain=.twitter.com; path=/; HttpOnly
curl permet même de renvoyer ces gâteaux au serveur :
% curl --cookie _twitter_sess=BAh7CDoPY3JlYXRlZF9hdGwrCPc8l5gvAToHaWQiJWY3NTg3YTU1YTgwOWE2%250AODcxMTA5M2NiNzNiOWMxODRmIgpmbGFzaElDOidBY3Rpb25Db250cm9sbGVy%250AOjpGbGFzaDo6Rmxhc2hIYXNoewAGOgpAdXNlZHsA--dd45d4b08ccac6e6f832ccb70af983e16a12df43\;guest_id=130393513906128799 -v http://twitter.com/ > /dev/null ... > Cookie: _twitter_sess=BAh7CDoPY3JlYXRlZF9hdGwrCPc8l5gvAToHaWQiJWY3NTg3YTU1YTgwOWE2%250AODcxMTA5M2NiNzNiOWMxODRmIgpmbGFzaElDOidBY3Rpb25Db250cm9sbGVy%250AOjpGbGFzaDo6Rmxhc2hIYXNoewAGOgpAdXNlZHsA--dd45d4b08ccac6e6f832ccb70af983e16a12df43;guest_id=130393513906128799 ...
La section 4 définit rigoureusement les obligations d'un serveur sérieux, qui ne cherche pas à exploiter les possibilités de la norme à fond et qui veut être sûr que tous les clients pourront traiter correctement ses gâteaux. Sa section 4.1.1 définit la syntaxe formelle à suivre, en ABNF. Les valeurs qui ne sont pas réduites à un strict sous-ensemble de caractères sûrs, pour maximiser les chances d'être transmises sans accident, sont encodées en Base64. Les dates s'expriment avec le format du RFC 1123 (mais certains serveurs non compatibles avec ce profil envoient des dates sur deux chiffres...). Certains clients stockent les dates dans un entier de seulement 32 bits donc il est possible que les choses se passent mal à partir de 2038.
Le serveur peut ajouter des attributs aux gâteaux. Ainsi,
l'attribut Expires (section 4.1.2.1) permet de
spécifier la date limite de consommation du gâteau (« À consommer avant le 29 avril
2011 ») et l'attribut Max-Age indique la durée de
vie maximale (le RFC prévient que Max-Age est
moins souvent mis en œuvre que Expires par
les clients HTTP). Le gâteau peut durer moins longtemps que cela, par exemple
parce que le navigateur Web a décidé de faire de la place, ou bien
parce que l'utilisateur l'a détruit explicitement (chose que
permettent tous les bons navigateurs, vues les conséquences négatives des
gâteaux pour la vie privée).
Important pour la sécurité, l'attribut Domain
permet d'indiquer le domaine des serveurs à qui
le client doit renvoyer le gâteau. Attention, les sous-domaines de ce
domaine sont également acceptés. Si le serveur envoie
Domain=example.org lors du
Set-Cookie, le client renverra le gâteau à, par exemple,
www.example.org et
mail.example.org. (Et si un serveur distrait met
un gâteau avec Domain=com ? Il sera renvoyé à
tous les domains en .com ?
Cela dépend du navigateur ; beaucoup ignorent cet attribut
Domain s'il correspond à un domaine
d'enregistrement comme .fr
ou .co.uk mais il n'existe
pas de moyen officiel d'en connaître la liste donc ces navigateurs
dépendent de listes incomplètes comme http://publicsuffix.org. Voir la section 5.3 pour une
discussion complète. À noter que Konqueror
utilise une méthode encore pire qui n'a jamais été corrigée.)
Le serveur peut restreindre encore plus l'utilisation du gâteau
qu'il envoie avec l'attribut Path (section
4.1.2.4). Celui-ci indique quelle section du site Web a besoin du
gâteau. Si on met Path=/accounting et que le
domaine est www.example.com, seuls les URL
commençant par http://www.example.com/accounting
recevront le gâteau.
Enfin, deux autres attributs permettent d'améliorer la (faible)
sécurité des gâteaux, Secure, qui impose au
client de ne renvoyer le gâteau qu'au dessus d'une connexion « sûre »
(typiquement HTTPS, pour éviter les attaques
par FireSheep) et HttpOnly
qui restreint le gâteau à ce protocole.
Une fois que le serveur a créé le gâteau et l'a envoyé avec les
attributs qu'il juge utile, il doit être prêt à recevoir des gâteaux
retransmis par le client. La section 4.2 décrit l'en-tête
Cookie des requêtes HTTP, qui sert à cela. (Voir
les exemples plus haut.)
La section 4 décrivait un profil réduit des gâteaux. Un client HTTP sérieux qui veut pouvoir comprendre tous les serveurs existants dans la nature, y compris ceux qui ne s'en tiennent pas à ce profil réduit, doit, lui, lire la section 5, qui décrit l'intégralité du très compliqué comportement des gâteaux. Cette section reprend le plan de la 4, en détaillant toutes les horreurs qu'on peut rencontrer dans le monde réel.
Par exemple, le format des dates (section 5.1.1), utilisées dans
des attributs comme Expires, permet à peu près
toutes les variations possibles. Écrire un
analyseur complet n'est pas trivial, d'autant
plus que le RFC ne décrit pas une grammaire
indépendante du contexte mais un algorithme à état. (Si un pro de
l'analyse syntaxique peut fournir une grammaire plus déclarative de
cette syntaxe, je serais intéressé...)
De même, l'analyse du Set-Cookie en section 5
est plus complexe car le client doit accepter des
Set-Cookie plus variés, par exemple avec des
espaces en plus.
La section 5.3, qui n'a pas d'équivalent dans la section 4, décrit la façon dont les clients, les navigateurs Web, doivent stocker les gâteaux et les renvoyer. Elle rappelle la liste des attributs à stocker avec chaque gâteau (par exemple, s'il doit être renvoyé uniquement sur une connexion sécurisée ou bien si ce n'est pas nécessaire). Elle est très longue et le pauvre auteur de navigateur Web a donc bien du travail.
En parlant du programmeur, justement, la section 6 décrit les questions que pose l'implémentation de cette spécification. Parmi elles, la question de la taille du magasin où sont stockés les gâteaux. Le client Web n'est nullement obligé de fournir un magasin de taille infinie. Néanmoins, le RFC demande que le client accepte au moins quatre kilo-octets par gâteau, cinquante gâteaux par domaine et trois mille gâteaux en tout (ce qui permet déjà une belle indigestion). Conséquence de cette limite : un serveur doit s'attendre à ce qu'un client ne renvoie pas tous les gâteaux prévus. Certains ont pu être abandonnés par manque de place.
On l'a vu, la section 5, qui normalise le comportement du client,
est très complexe. La section 4 l'est moins mais l'expérience a
largement prouvé que les serveurs émettant des gâteaux avaient du mal
à se tenir à un profil strict, et produisaient trop de variations. Une
des raisons identifiées par la section 6.2 est le manque
d'API. La plupart du temps, les applications
font directement un printf "Set-Cookie: foobar=1234567;
Expires=Wed, 06 Jun 2012 10:18:14 GMT\n" (ou équivalent) au
lieu d'appeler une API plus abstraite dont l'implémentation se
chargera de sérialiser proprement les objets complexes comme la
date. Avec tant de liberté laissée au programmeur, il n'est pas
étonnant qu'il y ait des variations non-standard.
Si le RFC ne propose pas de solution, il insiste sur l'importance
pour les programmeurs d'utiliser des bibliothèques bien déboguées et
de ne pas se croire capable d'écrire un
Set-Cookie correct après cinq minutes de lecture
de la norme. Un exemple d'une telle bibliothèque est, en
Python, http.cookies. D'encore
plus haut niveau, dans le même
langage, urllib2 gère les gâteaux toute seule.
Comme le respect de la vie privée est le principal problème des gâteaux, il est normal que cette question ait une section entière, la 7, qui détaille ce point. C'est inhabituel à l'IETF, où la vie privée ne génère en général que peu d'intérêt. Peu de RFC ont une section Privacy considerations. Que dit-elle ? Que les gâteaux sont effectivement une technologie sensible (bien qu'il existe d'autres moyens de suivre un utilisateur mais moins pratiques donc moins dangereux) et que les plus problématiques sont les gâteaux envoyés à un tiers (c'est-à-dire à une autre organisation que celle qui gère visiblement la page, par le biais d'une discrète image insérée, par exemple). Par exemple, un service de statistiques utilisé sur de nombreux sites Web, ou bien un service de placement de publicités, peuvent permettre à leur gérant de croiser les visites faites sur plusieurs sites différents et ceci sans que l'utilisateur n'ait fait de visite explicite aux services de cette indiscrète organisation. Certains navigateurs sont, à juste titre, davantage paranoïaques lorsque le gâteau est envoyé par un tiers, par exemple en les refusant par défaut. D'autres ne traitent pas ces gâteaux différemment des autres. La question étant essentiellement politique, notre RFC 6265 ne définit pas de comportement normalisé, se contentant d'attirer l'attention sur ce point.
Peut-on demander son avis à l'utilisateur ? C'est ce qu'expose la section 7.2, consacrée au contrôle par l'utilisateur. Le RFC recommande que les clients Web fournissent des mécanismes de contrôle des gâteaux permettant de :
- Gérer les gâteaux stockés dans la magasin local, par exemple examiner les gâteaux en place, détruire tous ceux d'un certain domaine (voici comment faire dans Firefox), etc,
- Refuser systématiquement les gâteaux,
- Proposer à l'utilisateur de refuser ou d'accepter chaque gâteau
reçu, même si cela nécessite un
peu plus de travail lors de la navigation (mais cela a l'avantage de
faire prendre conscience de la quantité de gâteaux mis par des tiers,
sur des pages Web qui semblaient pourtant innocentes ; cette option
existait dans Firefox mais semble avoir disparu du panneau de contrôle des dernières versions de Firefox 3 ; on peut toujurs la régler « à la main » dans
about:config network.cookie.lifetimePolicy=1), - Traiter les gâteaux comme temporaires (et donc les détruire lorsqu'on quitte le programme), une option parfois nommée safe browsing (cf. « An Analysis of Private Browsing Modes in Modern Browsers ») ; dans Firefox, elle peut se configurer dans Privacy ; History ; Use custom setting for history.
Voici la liste des gâteaux stockés, telle que Firefox permet de
l'examiner et de la modifier :  Et la question que pose le même Firefox lorsqu'on l'a configuré avec
Et la question que pose le même Firefox lorsqu'on l'a configuré avec about:config network.cookie.lifetimePolicy=1 :
 Et le dialogue de configuration dans Firefox 4, montrant l'option qui permet de demander à chaque gâteau si on l'accepte :
Et le dialogue de configuration dans Firefox 4, montrant l'option qui permet de demander à chaque gâteau si on l'accepte :
 À noter qu'il existe bien d'autres moyens de configurer la politique
des gâteaux, si le navigateur ne fait pas ce qu'on veut, par exemple
des extensions comme Cookie
Monster, WebDeveloper (qui permet de voir tous les gâteaux de la page en cours, avec pour chacun « Éditer » ou « Supprimer ») ou Ghostery
pour Firefox. Le navigateur Dillo, quant à lui,
à un mécanisme très
détaillé.
À noter qu'il existe bien d'autres moyens de configurer la politique
des gâteaux, si le navigateur ne fait pas ce qu'on veut, par exemple
des extensions comme Cookie
Monster, WebDeveloper (qui permet de voir tous les gâteaux de la page en cours, avec pour chacun « Éditer » ou « Supprimer ») ou Ghostery
pour Firefox. Le navigateur Dillo, quant à lui,
à un mécanisme très
détaillé.
Même en dehors du cas de la vie privée, les gâteaux posent un certain nombre de problèmes de sécurité (section 8). L'utilisation de HTTPS, quoique évidemment souhaitable, ne protège pas complètement contre ces vulnérabilités.
Premier problème, l'autorité diffuse (ambient authority, section 8.2). Le gâteau utilisé pour l'authentification sépare la désignation (l'URL) de l'autorisation. Le client risque donc d'envoyer le gâteau pour une ressource Web qui était contrôlée par un attaquant, une technique connue sous le nom de CSRF (il existe plusieurs moyens de convaincre un navigateur de se prêter à cette attaque, une étude bien plus détaillée des CSRF, qui a parmi ses auteurs l'auteur de ce RFC, est « Robust Defenses for Cross-Site Request Forgery »). Une solution à ce problème serait de traiter les URL comme une capacité, donnant accès à une ressource. L'URL serait alors le secret à transmettre pour avoir accès (le RFC ne note malheureusement pas que les URL ne restent pas secrets longtemps, par exemple certains navigateurs ou extensions des navigateurs - la Google Toolbar - transmettent les URL consultés à leur maître).
Autre problème des gâteaux, leur envoi en texte clair (section
8.3). Si on n'utilise pas HTTPS, Set-Cookie et
Cookie sont transmis en clair avec leur contenu,
permettant à un espion de les copier et de les utiliser (c'est cette
vulnérabilité qu'exploite un programme comme
FireSheep). En outre, un attaquant actif peut
modifier ces en-têtes. La solution recommandée est évidemment de
chiffrer toute la session, et de mettre l'attribut
Secure aux gâteaux envoyés, pour éviter qu'ils ne
soient plus tard transmis sur une session non chiffrée. Beaucoup de
gros services très populaires ne sont pas accessibles en HTTPS ou bien
ne le mettent pas en œuvre par défaut (souvent pour des raisons
de performance, facteur crucial pour ces services qui reçoivent
beaucoup de visites). Dans le cas de Gmail,
c'est l'option « Général : Connexion du navigateur ; Toujours utiliser
le protocole https ». Dans celui de Twitter,
c'est « Toujours utiliser le HTTPS ». L'EFF
mène une campagne pour systématiser
cette protection. À noter qu'on peut limiter (mais pas
supprimer) la réutilisation du gâteau en liant celui-ci à
l'adresse IP du client ; si le gâteau vient
d'une autre adresse, il sera refusé. Cette méthode n'est pas si
efficace qu'elle en a l'air en raison de la fréquence du partage
d'adresses IP (via le NAT). Ainsi, dans un café
avec WiFi, un attaquant qui utilise FireSheep n'aura pas de problèmes
malgré cette protection car tous les clients sont probablement
derrière la même adresse IPv4 (c'est sans doute
pour cela que le RFC ne propose pas cette solution).
C'est encore pire si le gâteau contient directement de
l'information utile. Par exemple, si le gâteau est
lang=en-AU, l'espion qui écoute peut trouver la
langue et le pays de l'utilisateur. En général, cette information est
plutôt stockée sur le serveur et le gâteau ne contient qu'un
identificateur de session, inutile si on n'a pas accès au
serveur. Mais cette technique présente d'autres risques (section 8.4),
par exemple celui du « choix de session » où l'attaquant se connecte
au serveur, puis convainct la victime (par exemple par le biais d'un
lien) d'utiliser l'identificateur de session et d'interagir avec le
serveur (par exemple en y déposant des informations
confidentielles). L'attaquant, qui a conservé l'identificateur de
session, pourra alors continuer la session et récupérer ces
informations. (Voir un
exemple et un article
complet.)
Autre problème de sécurité des gâteaux, la confidentialité (section
8.5) : comme les gâteaux ne sont pas spécifiques d'un
port ou d'un plan (http, gopher, ftp, etc), un
client risque toujours de transmettre les gâteaux d'un serveur à un
autre. L'intégrité n'est pas non plus garantie (section 8.6). Si
bar.example.com a mis un gâteau de domain de
example.com, un autre serveur,
foo.example.com peut parfaitement le
remplacer. Path n'est pas une protection : il
n'empêche pas le remplacement.
Enfin, les gâteaux dépendent du DNS et en héritent les vulnérabilités (section 8.7).
Une très bonne synthèse des failles de sécurité des gâteaux figure dans l'excellent article « HTTP cookies, or how not to design protocols ».
Voilà, c'est tout, il reste à enregistrer les deux en-têtes dans le registre des en-têtes, ce que fait la section 9.
Contrairement aux autres RFC qui remplacent un autre RFC, ce RFC 6265 ne contient pas de description des changements par rapport aux précédents documents. Les clarifications et précisions sont sans doute trop nombreuses pour former une liste intéressante.
Merci à Jean-Baptiste Favre, bohwaz et Ollivier Robert pour leurs remarques et suggestions.
L'article seul
RFC 6147: DNS64: DNS extensions for Network Address Translation from IPv6 Clients to IPv4 Servers
Date de publication du RFC : Avril 2011
Auteur(s) du RFC : M. Bagnulo (UC3M), A. Sullivan
(Shinkuro), P. Matthews
(Alcatel-Lucent), I. van Beijnum (IMDEA Networks)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF behave
Première rédaction de cet article le 28 avril 2011
Ce nouveau RFC est un composant indispensable de la nouvelle technique de traduction entre des machines IPv4 et IPv6 (dont une description générale se trouve dans le RFC 6144). Les machines purement IPv6 ne pouvant pas initier une communication avec des machines n'ayant qu'une adresse IPv4, il est nécessaire de les « tromper » en fabriquant dynamiquement des adresses IPv6. Les machines IPv6 tenteront alors de s'y connecter, leurs requêtes seront reçues par le traducteur d'adresses, qui pourra alors les convertir en IPv4 (cf. RFC 7915 et RFC 6146).
DNS64 n'est donc pas utilisable seul. Il doit se combiner à une machine, typiquement un routeur, qui fait la traduction d'adresses, dite NAT64. La configuration typique des utilisateurs de DNS64 sera un réseau local purement IPv6 (puisque le stock d'adresses IPv4 est épuisé), dont le routeur fait de la traduction NAT64, et qui est muni d'un résolveur DNS capable de fabriquer des adresses IPv6 à partir des adresses v4 des machines externes. En effet, le but du système NAT64 est de ne pas avoir à modifier les machines, seulement les équipements d'infrastructure (routeur et résolveur DNS). Les machines purement v6, ignorantes de la traduction qui se fait entre leur réseau et le monde extérieur, ne pourraient pas se connecter si elle ne connaissaient de leur pair qu'une adresse IPv4. NAT64 et son indispensable compagnon DNS64 rejoignent donc la boîte à outils des techniques permettant de faire coexister IPv4 et IPv6 (cf. RFC 6144).
Comment est-ce que le serveur DNS64 synthétise cette adresse IPv6 ?
Supposons qu'une machine IPv6 du réseau local veuille se connecter à
www.example.com et que celui-ci n'ait qu'une
adresse v4, mettons 203.0.113.18. Le navigateur
Web tournant sur le client va faire une requête DNS de type AAAA
(adresse IPv6 ; puisqu'il n'a pas d'IPv4, les requêtes de type A
n'auraient aucun intérêt). Le serveur DNS la reçoit, la relaie et
récupère une réponse vide (le nom existe mais n'a pas d'enregistrement
AAAA). Il tente alors une requête A, reçoit
203.0.113.18 en réponse et génère l'adresse v6 de
manière purement algorithmique, sans état, en utilisant l'adresse v4
et les paramètres avec lesquels le serveur a été configuré
(typiquement, un préfixe v6). Rappelez-vous donc bien que le serveur
DNS64 et le traducteur doivent être configurés de manière cohérente
(dans la plupart des cas, ils seront sans doute dans la même boîte
mais, conceptuellement, ce sont deux services séparés.)
Pour le lecteur pressé qui veut juste une introduction à la norme, la section 2 est la meilleure lecture. Voici un exemple où une machine purement IPv6 tente de contacter Twitter, service purement IPv4 :
% telnet twitter.com 80 Trying 64:ff9b::80f2:f0f4... Connected to twitter.com. Escape character is '^]'.
C'est le serveur DNS64 qui a généré l'adresse
64:ff9b::80f2:f0f4 et c'est le traducteur qui
changera les paquets IPv6 en IPv4 à l'aller et en sens inverse au
retour. Twitter et le client purement IPv6 n'y verront que du
feu. Pour le préfixe à utiliser, le serveur DNS64 et le traducteur ont
le choix (cf. RFC 6052) entre un préfixe bien
connu, réservé à la traduction d'adresse (celui utilisé dans
l'exemple, qui avait été testé lors d'une réunion
IETF à Pékin) ou bien un
préfixe appartenant à l'opérateur réseau (NSP, pour
Network-Specific Prefix). La seule contrainte est
qu'il doit être configuré de manière identique dans le serveur DNS64
et dans le traducteur.
La norme elle-même fait l'objet de la section 5. Elle décrit avec précision le fonctionnement que j'ai résumé plus haut. Quelques petits points intéressants :
- On ne synthétise d'enregistrements que s'il n'y avait pas déjà un AAAA (section 5.1.1).
- Les erreurs (autres que NXDOMAIN - No Such Domain) doivent être traitées comme si le AAAA étai absent (section 5.1.2). Donc, par exemple, SERVFAIL (Server Failure) doit être traité comme un NOERROR,ANSWER=0, pour tenir compte des serveurs assez pourris pour ne pas répondre correctement aux requêtes AAAA (cf. RFC 4074). C'est une violation des normes du DNS, rendue nécessaire par le nombre de serveurs DNS (ou de middlewares placés devant eux) programmés avec les pieds.
- La règle précédente, interdisant la synthèse d'enregistrements
AAAA s'il en existe déjà, a quelques exceptions (section
5.1.4). Ainsi, les adresses IPv6 non utilisables globalement comme celles en
::ffff:0:0/96doivent être ignorés et le AAAA de synthèse produit. - Si le AAAA n'existe pas ou est inutilisable (section 5.1.6), le serveur DNS64 demande un enregistrement A (adresse IPv4). S'il n'en trouve pas, il répond au client « Désolé, aucune réponse ». S'il en trouve un, il fabrique l'enregistrement AAAA correspondant (typiquement en concaténant le préfixe IPv6 avec l'adresse IPv4) et le renvoie (la réponse de type A, elle, n'est pas transmise). La section 5.1.7 donne les détails de cette synthèse.
- Les deux requêtes, pour un enregistrement de type AAAA et pour un enregistrement de type A, peuvent être faites en parallèle (section 5.1.8). Certes, ce sera un gaspillage si l'enregistrement AAAA existe (puisque le A sera alors inutile) mais cela permettra de diminuer le temps total d'attente si le AAAA n'existe pas.
J'ai dit plus haut que l'adresse IPv6 de synthèse était fabriquée par concaténation du préfixe IPv6 (configuré à la main dans le serveur DNS64) et de l'adresse IPv4. Mais, en fait, le RFC n'impose pas l'utilisation d'un tel algorithme. La méthode utilisée n'a pas besoin d'être normalisée (elle n'est pas vue à l'extérieur) et doit seulement être la même sur le serveur DNS64 et sur le traducteur. La section 5.2 précise plus rigoureusement les exigences auxsquelles doit obéir cet algorithme. Le point le plus important est qu'il doit être réversible : en échange de l'adresse IPv6 de synthèse, le traducteur doit pouvoir retrouver l'adresse IPv4 originelle. Pour faciliter la vie des administrateurs réseau, un algorithme doit être obligatoirement présent dans les programmes (mais ce n'est pas forcément celui que l'administrateur choisira), celui décrit en section 2 du RFC 6052.
Et que doit faire le serveur DNS64 s'il reçoit des requêtes d'un
autre type que A ou AAAA ? La section 5.3 couvre ce cas. En gros, il
doit les traiter normalement sauf les requêtes de
type PTR (résolution d'une adresse en nom). Dans ce cas, le serveur
doit extraire l'adresse du nom en ip6.arpa
(section 2.5 du RFC 3596), regarder si cette
adresse correspond à un des préfixes qu'il gère et, si oui, le serveur
DNS64 a deux possibilités :
- Répondre immédiatement, avec autorité, en utilisant un nom adapté (qui peut
être le même pour toutes les adresses, mettons
locally-generated-ipv6-address-with-dns64.example.net). L'avantage est que les clients DNS verront bien que l'adresse avait été synthétisée, l'inconvénient est qu'on n'utilisera pas les informations qui pouvaient se trouver dans le DNS, - Synthétiser les enregistrements PTR à partir de données trouvées
dans le DNS, comme il synthétise des enregistrements AAAA à partir des
A récupérés dans le DNS. Dans ce cas, le serveur DNS64 traduit
l'adresse IPv6 en IPv4, crée un nom dans
in-addr.arpa, fait une requête PTR et renvoie le résultat au client.
La section 6, sur le déploiement, est consacrée aux problèmes pratiques qui pourront survenir lorsqu'on utilisera réellement DNS64. Par exemple, si une machine est multi-homée, il est possible que seulement certaines de ses connexions à l'Internet passent par un traducteur v4-v6. Il faudrait donc idéalement interroger des résolveurs DNS différents selon l'interface de sortie, et considérer les résultats comme locaux à l'interface.
Autre problème pratique, le cas d'une machine à double-pile qui utiliserait DNS64, passant ainsi par le traducteur même lorsque ce n'est pas nécessaire (section 6.3.2 et 6.3.3). Comme la configuration par défaut des systèmes d'exploitation est de préférer IPv6 à IPv4, le cas risque de se produire souvent. Il n'existe pas de moyen simple de le détecter puisque, pour le client, un serveur DNS64 semble un serveur comme un autre. Une machine double-pile (IPv4 et IPv6) ne devrait donc pas utiliser de résolveur DNS64. Mais il peut y avoir des cas où c'est nécessaire, par exemple si la machine double-pile n'a une connectivité IPv4 que partielle. Dans ces conditions, le serveur DNS64 doit exclure les préfixes IPv4 locaux de la synthèse. On peut donc prévoir quelques problèmes de débogage amusants...
La section 7 décrit des exemples de déploiement, en utilisant les
scénarios du RFC 6144. Par exemple, la section 7.1 cite le cas qui sera sans doute
le plus fréquent au début, une machine H1 réseau purement IPv6 (parce que arrivé
après l'épuisement des adresses
IPv4) qui essaie de se connecter à un serveur H2 situé dans
l'Internet v4 traditionnel. Le traducteur T et le serveur DNS sont
configurés avec le préfixe bien connu
64:ff9b::/96. H1 va commencer par faire une
requête AAAA pour h2.example.com. Le résolveur
DNS ne trouve pas de AAAA pour ce nom, mais il récupère un
enregistrement de type A, 192.0.2.1. Il fabrique
alors le AAAA 64:ff9b::c000:201 (qui peut aussi légitimement
s'écrire 64:ff9b::192.0.2.1). H1 va alors envoyer
un paquet TCP SYN à
64:ff9b::c000:201. Le routeur/traducteur le voit
passer, note le préfixe NAT64 avec lequel il a été configuré et le
traduit en un paquet TCP/IPv4.
Autre exemple, en section 7.3. C'est à peu près l'inverse : une machine dans un Internet passé presque entièrement en IPv6 essaie de se connecter à un des derniers serveurs v4 existants. À noter que DNS64 n'est pas indispensable dans ce cas : on peut simplement affecter algorithmiquement une adresse IPv6 à toutes les adresses IPv4, les publier sur des serveurs DNS normaux, et donc n'utiliser que le traducteur. Toutefois, cette section cite quelques cas où DNS64 peut être utile, par exemple si les adresses IPv4 sont affectées dynamiquement.
Fondamentalement, un serveur DNS64 est un menteur : il fabrique des réponses qui n'existent pas (Twitter, utilisé dans l'exemple plus haut, n'a pas d'adresse IPv6 à ce jour...). Il a donc des problèmes avec DNSSEC, qui a justement été conçu pour détecter les mensonges. Toute la section 3 est consacrée à discuter ce problème. Bien sûr, le résolveur DNS64 ment pour la bonne cause. Mais DNSSEC est au delà du bien et du mal, il se moque des motivations, il ne regarde que le résultat. Plusieurs cas peuvent se poser (le RFC en identifie sept !) selon les options indiquées dans la requête DNS et selon la configuration DNSSEC utilisée. Rappelons que les deux options importantes pour DNSSEC dans une requête DNS sont le bit DO (DNSSEC OK, RFC 4035, section 3.2.1) qui indique si le client DNS comprend les enregistrements DNSSEC et le bit CD (Checking Disabled, RFC 4035, section 3.2.2) qui indique au résolveur que le client fera la validation lui-même et qu'il faut lui envoyer toute l'information, même si elle s'avère fausse.
Les différents cas sont donc (je ne les ai pas tous mentionnés, voir le RFC pour les détails) :
- Un serveur DNS64 reçoit une requête où DO est à zéro (ce que font aujourd'hui la plupart des bibliothèques de résolution de noms, les stub resolvers). Aucun problème dans ce cas, le client ne comprend pas DNSSEC, le serveur DNS64 peut inventer tous les mensonges qu'il veut.
- Un serveur DNS64 avec gestion de DNSSEC reçoit une requête avec DO et CD mis à zéro (c'est typiquement le cas - rare - d'un client qui veut valider lui-même). Dans ce cas, il doit passer au client toute l'information obtenue. DNS64 ne marchera pas ici, le client n'acceptera pas le AAAA synthétisé comme étant valide. La seule solution est que le client mette en œuvre DNS64 lui-même.
- Un serveur DNS64 qui valide avec DNSSEC reçoit une requête avec DO à un et CD à zéro (ce sera sans doute le cas le plus courant dans le futur). Aucun problème, le serveur DNS64 valide les données récupérées et répond SERVFAIL (Server Failure) si cette validation échoue. Le AAAA synthétisé n'est pas validé avec DNSSEC mais le client ne le saura pas. Si le bit DO était mis à un, le serveur DNS64 a juste à mettre le bit AD (Authentic Data) à un dans sa réponse (un mensonge pour la bonne cause ; après tout, si le client DNS n'a pas mis CD à un, c'est qu'il fait complètement confiance au résolveur).
La section 5.5 donne les détails sur le fonctionnement de DNSSEC dans DNS64. La section 6.2 rappelle les problèmes pratiques de déploiement de DNS64 si on utilise déjà DNSSEC.
DNS64 pose t-il des problèmes de sécurité ? Pas beaucoup, dit la section 8. Comme indiqué (paragraphes précédents), il peut interférer avec DNSSEC. Et, surtout, il impose une coordination entre le serveur DNS64 et le traducteur. Si un attaquant peut modifier la valeur du préfixe du serveur DNS64, il peut envoyer les paquets où il veut. Donc, attention, la sécurité du serveur DNS64 est exactement aussi importante que celle du traducteur.
Enfin, l'annexe A explique des motivations pour générer un AAAA alors qu'il existe déjà. Il se peut que la meilleure route passe plutôt par le traducteur et donc, dans certains cas, un serveur DNS64 peut offrir à son administrateur la possibilité de permettre la synthèse d'enregistrements AAAA même quand un vrai existe.
BIND met en œuvre DNS64 depuis les versions 9.7.3 et 9.8.0. Voici un exemple de configuration de DNS64 avec une 9.8.0 :
acl me {
::1/128; 127.0.0.0/8;
};
acl rfc1918 {
10/8; 192.168/16; 172.16/12;
};
options {
...
dns64 64:ff9b::/96 { // The well-known prefix
clients { me; };
mapped { !rfc1918; any; }; // Never synthetize AAAA records
// for private addresses
exclude { 64:ff9b::/96; ::ffff:0000:0000/96; }; // If the retrieved
// AAAA record is in that range, do not send it back to the user,
// synthetize a AAAA.
//
// suffix ::42; // Trailing bits. Require some free space (here,
// 96 + 32 bits leave no room for trailing bits).
};
Le premier préfixe est celui des AAAA synthétisés (ici, le préfixe
bien connu). La directive clients réduit le
service DNS64 à certaines machines seulement (celles qui sont
connectées via un traducteur NAT64, relisez les sections 6.3.2 et
6.3.3 du RFC). La directive mapped met en
œuvre la règle d'exclusion des préfixes IPv4 locaux (ici, ceux
du RFC 1918). La directive
exclude implémente la règle d'exclusion des
préfixes IPv6 qui ne devraient même pas être mis dans le DNS
global. S'il existe un AAAA, mais qu'il pointe vers un des ces
préfixes, il sera remplacé par un AAAA synthétique. Enfin, la
directive suffix permet d'ajouter quelques bits à
la fin du AAAA de synthèse (mais, ici, avec 96 bits pour le préfixe
IPv6 et 32 pour l'adresse IPv4, il n'y a plus de place).
Voici l'effet du serveur ayant la configuration ci-dessus (il écoute sur le port 9053) :
[Adresse IPv6 déjà dans le DNS global.]
% dig +short -p 9053 @::1 AAAA www.ietf.org
2001:1890:1112:1::20
[Pas d'adresse IPv6 dans le DNS global mais trois adresses IPv4.]
% dig +short -p 9053 @::1 AAAA facebook.com
64:ff9b::453f:bd0b
64:ff9b::453f:bd10
64:ff9b::453f:b50c
[Les requêtes PTR marchent bien, BIND synthétise un CNAME, une des
deux techniques permises par le RFC.]
% dig -p 9053 @::1 -x 64:ff9b::453f:bd10
...
;; QUESTION SECTION:
;0.1.d.b.f.3.5.4.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.b.9.f.f.4.6.0.0.ip6.arpa. IN PTR
;; ANSWER SECTION:
0.1.d.b.f.3.5.4.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.b.9.f.f.4.6.0.0.ip6.arpa. 600 IN CNAME 16.189.63.69.in-addr.arpa.
16.189.63.69.in-addr.arpa. 7172 IN PTR www-11-01-ash2.facebook.com.
...
[Ici, le nom a une adresse IPv4 mais privée. L'ACL 'rfc1918' va donc
la bloquer.]
% dig +short -p 9053 @::1 A ciel.administratif.prive.nic.fr
10.1.84.200
% dig -p 9053 @::1 AAAA ciel.administratif.prive.nic.fr
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 0
^^^^^^^^^
Pour comparer, voici une configuration BIND avec un préfixe du FAI (NSP pour Network-Specific Prefix). Plus court que le précédent, il dégage de la place pour le suffixe :
dns64 2001:db8:666::/48 { // A Network-Specific Prefix (NSP).
clients { me; };
suffix ::42; // Trailing bits.
};
Et voici les résultats :
% dig +short -p 9053 @::1 AAAA facebook.com 2001:db8:666:453f:bd:1000:0:42 2001:db8:666:453f:b5:c00:0:42 2001:db8:666:453f:bd:b00:0:42
Si vous voulez manipuler les adresses vous-même, voici un joli script awk dû à gbfo, pour traduire les adresses IPv6 en la v4 correspondant :
% echo 64:ff9b::453f:bd0b | \
awk -F: '{h=strtonum("0x" $(NF-1));l=strtonum("0x" $NF);printf("%d.%d.%d.%d\n",h/256,h%256,l/256,l%256);}'
69.63.189.11
Question mises en œuvre de DNS64, outre le cas de BIND, déjà présenté, il existait une rustine pour Unbound, chez Viagénie (avec un très ennuyeux système de formulaire à remplir pour l'obtenir). Cette rustine porte sur une version ancienne du protocole, mais Unbound a désormais DNS64 en série. Il y a aussi au même endroit un serveur DNS64 autonome, écrit en Perl. Ce dernier est très court et peut donc être un bon moyen de comprendre le protocole, pour ceux qui aiment lire le code source. Enfin, Cisco a désormais DNS64 sur ses produits.
Voici un exemple de configuration Unbound pour un serveur DNS64 :
server: module-config: "dns64 validator iterator" dns64-prefix: 64:ff9b::0/96
Et mon opinion personnelle sur DNS64 ? Je dirais que, certes, c'est un hack, mais qu'on a vu pire et que ça traite un vrai problème. DNS64 semble bien pensé, rien n'est oublié et le RFC parle bien de tous les problèmes, notamment avec DNSSEC.
Pour un récit très détaillé, avec plein de technique, d'un test de NAT64 avec DNS64, voir l'article de Jérôme Durand « J'ai testé pour vous : Stateful NAT64 avec DNS64 ».
Notez qu'il existe des résolveurs DNS publics ayant DNS64
(évidemment uniquement avec le préfixe bien connu), comme celui de
Hurricane Electric, nat64.he.net /
2001:470:64::1 ou celui de Google,
google-public-dns64-b.google.com /
2001:4860:4860::6464.
L'article seul
RFC 6156: Traversal Using Relays around NAT (TURN) Extension fo IPv6
Date de publication du RFC : Avril 2010
Auteur(s) du RFC : G. Camarillo, O. Novo (Ericsson), S. Perreault (Viagenie)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF behave
Première rédaction de cet article le 28 avril 2011
Le protocole TURN, qui permet à deux machines coincées derrière des routeurs NAT de communiquer en utilisant un relais tiers, a été normalisé dans le RFC 5766, dans une version minimale, uniquement pour IPv4 et seulement pour UDP, les services « incontestables », qui étaient pressés d'avoir une solution. Depuis, des extensions à TURN sont développées pour d'autres services. C'est ainsi que ce RFC 6156 permet d'utiliser TURN pour établir des liaisons en IPv6. Cette extension à TURN a depuis été intégrée dans la norme de base, le RFC 8656, remplaçant ce RFC.
Cette extension permet de communiquer avec une machine IPv4 depuis une machine IPv6, avec une machine IPv6 depuis une autre machine IPv6 et enfin avec une machine IPv6 depuis une machine IPv4 (section 1 du RFC). C'est donc une véritable solution de communication entre les deux protocoles, travaillant dans la couche 7 (contrairement aux techniques comme le NAT qui travaillent dans la couche 3). Le serveur TURN relais la totalité des données entre les deux clients TURN.
On peut se demander si un tel service est bien nécessaire. Après tout, TURN avait été inventé pour le cas du NAT, qui lui-même était motivé par le faible nombre d'adresses IPv4 disponibles. En IPv6, le problème de la pénurie ne se pose pas et TURN semble inutile. Toutefois, comme le note le RFC 5902, il risque d'y avoir quand même des réseaux IPv6 NATés, peut-être avec des adresses ULA à l'intérieur, et TURN peut donc trouver sa place ici. Autre utilité : TURN peut aider les machines purement v4 (la majorité d'aujourd'hui) et les machines purement v6 (qui se répandront sans doute) à communiquer entre elles. Enfin, TURN peut aussi être utile pour un administrateur de pare-feu à état pour permettre aux utilisateurs d'ouvrir des ports afin de recevoir des connexions entrantes. TURN a été conçu pour qu'il soit très restreint dans ce qu'il accepte, de façon à ce que les administrateurs de pare-feux puissent lui faire confiance.
La nouvelle extension fonctionne avec un nouvel attribut TURN,
REQUESTED-ADDRESS-FAMILY, valeur 0x0017 (section 3). L'attribut
XOR-RELAYED-ADDRESS (RFC 5766, section 14.5, et section 4.2 de notre RFC) de la réponse contiendra une
adresse de la famille demandée (v4 ou v6). La famille d'adresse du
client est déterminée, elle, en regardant l'adresse utilisée pour
contacter le serveur. À noter que chaque demande
d'allocation TURN ne peut gérer qu'une seule adresse IP. Le client qui
voudrait communiquer avec une adresse IPv4 et une v6 devra faire deux
demandes d'allocation. Si le serveur ne veut ou ne peut pas gérer une
famille donnée, il répondra 440 (Address Family not
Supported).
La section 4 contient ensuite les détails concrets comme le format du nouvel attribut (section 4.1.1). Celui-ci a le numéro 0x0017, ce qui le met dans les plages des attributs dont la compréhension par le serveur est impérative. Un vieux serveur qui ne met pas en œuvre notre RFC ne peut donc pas ignorer cet attribut.
Un problème qui a toujours été très chaud dans le groupe Behave est celui de la traduction des paquets. Comme on dit en italien, « Traduttore, Traditore » (traducteur = traître). Lorsqu'un serveur TURN relaie des paquets, doit-il respecter toutes les options de l'en-tête IP ? La question est évidemment encore plus difficile pour une traduction entre IPv4 et IPv6. La section 8 fournit les règles. Par exemple, lors de la traduction de IPv4 vers IPv6 (section 8.1), que doit valoir le champ Traffic Class (RFC 2460, section 7) d'un paquet IPv6 sortant ? Le comportement souhaité est celui spécifié dans la section 3 du RFC 7915 (RFC qui décrit le mécanisme de traduction de IPv4 vers IPv6, notamment pour l'utilisation dans NAT64). Le comportement possible est d'utiliser la valeur par défaut de ce champ. Le Flow label (RFC 2460, section 6), lui, devrait être mis à zéro (il n'a pas d'équivalent IPv4). Et pour les en-têtes d'extensions IPv6 (RFC 2460, section 4) ? Aucun ne doit être utilisé, dans tous les cas (sauf la fragmentation).
Et si on relaie entre deux machines IPv6 ? Ce sont quasiment les mêmes règles, comme indiqué par la section 8.2. Par exemple, bien qu'il existe un Flow label des deux côtés, on considère que TURN, relais de la couche 7, ne devrait pas essayer de le copier : il y a deux flots différents de part et d'autre du serveur TURN.
Cette extension de TURN pose t-elle des problèmes de sécurité ? Potentiellement oui, répond la section 9. En effet, elle donne aux machines des capacités nouvelles. Ainsi, une machine purement IPv6 obtient, si elle a le droit d'accéder à un serveur TURN mettant en œuvre ce RFC 6156, la possibilité de parler aux machines purement IPv4, possibilité qu'elle n'avait pas avant. Comme il est recommandé de ne faire fonctionner TURN qu'avec une authentification préalable des clients, ce n'est sans doute pas une question sérieuse en pratique.
La section 10 décrit l'enregistrement à
l'IANA des nouveaux paramètres (attribut
REQUESTED-ADDRESS-FAMILY et codes d'erreur 440 et
443) dans le registre
des paramètres STUN (rappelez-vous que TURN est défini comme
une extension de STUN).
Question mise en œuvre, il en existe une côté serveur, non
distribuée mais accessible vie le réseau (voir http://numb.viagenie.ca/), une libre qui a IPv6 depuis la version 0.5, mais apparemment rien encore côté
client.
Merci à Simon Perreault pour sa relecture et ses remarques.
L'article seul
RFC 6204: Basic Requirements for IPv6 Customer Edge Routers
Date de publication du RFC : Avril 2011
Auteur(s) du RFC : H. Singh, W. Beebee (Cisco), C. Donley (CableLabs), B. Stark (AT&T), O. Troan (Cisco)
Pour information
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 28 avril 2011
Ce RFC du groupe de travail v6ops, qui se consacre aux problèmes pratiques du fonctionnement d'IPv6 (sans modification des protocoles, donc), porte sur les CPE (Customer Premises Equipment), alias CER (Customer Edge Routers), alias home gateway, qui sont les boîtiers installés chez l'utilisateur domestique ou petite entreprise. Par exemple, en France, la Freebox ou la DartyBox sont des CPE. Certains d'entre eux gèrent le protocole IPv6 et ce RFC résume tout ce que doivent savoir les concepteurs de ces « boxes » pour faire de l'IPv6 proprement. Il a depuis été remplacé par le RFC 7084.
Le gros débat qui avait eu lieu à l'IETF lors de la conception de ce RFC portait sur une règle exprimée dans les premières versions de l'Internet-Draft qui avait précédé le RFC : cette règle disait qu'un CPE IPv6 devait, par défaut, bloquer les connexions entrantes. L'argument principal était que les CPE IPv4 font tous cela. Mais ils le font parce qu'en IPv4, la pénurie d'adresses oblige à des bricolages comme le NAT, et empêchent de toute façon les connexions entrantes. IPv6 permettant enfin de récupérer une adresse IP unique mondialement, et donc d'avoir à nouveau une connectivité de bout en bout, cette règle évoquait plus un « Minitel 2.0 » que l'Internet du futur.
Elle a donc été retirée de ce RFC, qui laisse ouverte la question de la sécurité, la déléguant à un autre document, le RFC 6092. En coupant les connexions entrantes, on bloque certaines attaques (par forcément les plus fréquentes : aujourd'hui, la plupart des attaques se font par le contenu des données transférées - importation de malware - et pas directement sur IP) mais on empêche les utilisateurs de profiter des services comme la téléphonie sur IP ou le pair-à-pair, qui dépendent souvent de cette possibilité de connexions entrantes.
Donc, en dehors de ce point, que contient ce RFC ? La section 1 résume les points importants : le RFC se focalise sur le cas où IPv6 est natif (pas de traduction d'adresses entre v4 et v6), et sur le cas simple où il n'y a qu'un seul CPE, qui récupère sa configuration sur le WAN, puis la distribue aux machines IPv6 locales, puis route leurs paquets. Le déploiement de l'IPv6 dans le réseau de l'opérateur n'est pas discuté (cf. RFC 4779). Ce RFC concerne uniquement le « foyer, doux foyer ».
D'abord, un rappel du fonctionnement d'un CPE IPv4 aujourd'hui. Ce fonctionnement n'est spécifié nulle part, il résulte d'une accumulation de choix par les auteurs anonymes des CPE existants. Ces choix sont souvent erronés. En l'absence de norme formelle, la section 3.1 décrit le CPE « typique » de 2010. Ce CPE typique a une (et une seule) connexion avec l'Internet, une seule adresse IP publique (et encore, parfois, il y a même du NAT dans le réseau de l'opérateur) et il sert de routeur NAT aux machines IPv4 situées sur le réseau local. Par défaut, en raison du NAT, il bloque toutes les connexions entrantes (c'est la seule allusion à cette question qui soit restée dans la version finale du RFC). Ouvrir des ports entrants (port forwarding) se fait par une configuration manuelle du CPE, via une interface Web (cas de la Freebox) ou bien par UPnP. C'est donc un vrai Minitel 2.0. Un avantage de ces adresses privées est toutefois d'assurer la stabilité des adresses internes : elles ne changent pas si on quitte son FAI.
L'architecture ci-dessus est largement déployée et correspond au cas de la plupart des abonnés à l'Internet à la maison. À quoi ressemblera t-elle en IPv6 ? On ne peut évidemment pas encore être sûr. mais la section 3.2, qui la décrit en termes très généraux, suppose qu'elle ne sera pas très différente, à part que la présence de plusieurs réseaux (et donc plusieurs préfixes IP) sera peut-être un cas plus fréquent qu'aujourd'hui. Quelles adresses IP seront utilisées à l'intérieur ? On pense immédiatement au RFC 5902, qui n'est toutefois pas cité. Le RFC 6204 présente la possibilité que des adresse locales, les ULA (RFC 4193) soient utilisées pour le réseau local. Le CPE devra bien alors fournir un mécanisme de traduction.
Alors, maintenant, quelles sont les exigences auxquelles devront se plier les futurs CPE IPv6 ? La section 4 est la liste de ces demandes. Elles sont nombreuses. Citons, parmi elles, l'obligation de d'abord se comporter en bon routeur, ce qui implique par exemple de mettre en œuvre ICMP (RFC 4443) correctement. Du côté du WAN, le CPE devra lui-même utiliser les protocoles standard de découverte d'un routeur (RFC 4861) pour trouver où envoyer les paquets, devra demander son préfixe avec DHCP (RFC 8415), devra bien sûr encapsuler IPv6 correctement (RFC 2464 pour Ethernet), etc. Du côté du LAN, il devra fournir des adresses globales ou des ULA (les adresses locales au lien ne suffisent pas et, de toute façon, pas besoin d'un routeur pour en acquérir). La gestion des ULA est désormais obligatoire, et le CPE doit pouvoir mémoriser le préfixe ULA, même en cas de redémarrage, de façon à fournir un préfixe stable (et, idéalement, configurable) au réseau dont il a la charge. Il doit évidemment pouvoir distribuer ce préfixe sur le réseau local avec SLAAC (Stateless Address Autoconfiguration, RFC 4862) ou avec DHCP (RFC 3315, ce protocole devient donc désormais obligatoire). Il doit fournir des options comme l'annonce des serveurs DNS (RFC 3646).
La sécurité, on l'a vu, est l'aspect délicat de ces machines, puisque le M. Michu qui les utilise pour connecter sa maison, ne connait pas le problème et n'a pas envie d'apprendre. Sur ce point controversé, la section 4.4 se contente de renvoyer à un autre RFC, le RFC 6092 en disant que ce serait bien de mettre en œuvre ses recommandations. Délibérement, la question de la configuration par défaut souhaitable (permettre les connexions entrantes ou pas) est laissée de côté.
Les CPE d'aujourd'hui mettent-ils en œuvre ces recommandations ? Difficile à dire, je ne connais pas d'étude systématique ayant été faite sur les capacités de ces engins (un projet est en cours), mais ce serait certainement très instructif. Des tests chez Free sur une Freebox v5 semblent indiquer que tout est correct (pas de filtrage bizarre, et merci à Ludovic Martin pour ses essais.)
L'article seul
RFC 6144: Framework for IPv4/IPv6 Translation
Date de publication du RFC : Avril 2011
Auteur(s) du RFC : F. Baker (Cisco), X. Li, C. Bao (CERNET Center/Tsinghua University), K. Yin (Cisco)
Pour information
Réalisé dans le cadre du groupe de travail IETF behave
Première rédaction de cet article le 28 avril 2011
Le groupe de travail Behave de l'IETF a travaillé pendant longtemps sur les mécanismes permettant de communiquer malgré la présence d'un routeur NAT sur le trajet. Ayant terminé ce travail avec succès, il a été muni d'une nouvelle charte pour travailler sur la transition IPv4 -> IPv6, notamment sur un mécanisme de traduction pour permettre à des machines purement v4 de parler à des machines purement v6 et réciproquement. Le groupe « Behave 2 », en ayant fini avec NAT44 s'est donc attaqué à cette tâche et ce RFC est le deuxième de cette nouvelle série (le premier avait été le RFC 6052), qui décrit NAT64.
Il ne décrit pas une technique ou un protocole mais fournit seulement le cadre général dans lequel vont s'inscrire les autres RFC du nouveau groupe Behave comme le RFC 6145 sur le protocole de traduction ou le RFC 6147 sur l'aide que lui apporte le DNS. La liste de ces documents est en section 3.3.
En effet, l'IETF avait déjà normalisé une technique de traduction d'adresses entre IPv4 et IPv6, le NAT-PT (RFC 2766), technique qui avait été abandonnée officiellement par le RFC 4966. La traduction d'adresses entre v4 et v6 n'était pas forcément considérée mauvaise en soi mais NAT-PT était vu comme une mauvaise solution, pour les raisons expliquées dans le RFC 4966.
Mais il est vrai que la traduction d'adresses a toujours été mal vue à l'IETF et que NAT-PT a du faire face à une forte opposition. Le modèle de transition d'IPv4 vers IPv6 promu par l'IETF (RFC 4213) a toujours été d'activer IPv6 au fur et à mesure, de laisser coexister IPv4 et IPv6 sur le réseau et les machines pendant un moment (stratégie de la « double pile ») puis, une fois qu'IPv6 était généralisé, de supprimer IPv4 petit à petit. Cette méthode était encore raisonnable en 2005, lorsque le RFC 4213 a été publié, mais, aujourd'hui, après des années de ratiocination, alors que l'épuisement des adresses IPv4 est effectif, elle n'est plus réaliste : nous n'avons tout simplement plus le temps de procéder à une telle migration ordonnée (cf. section 1.4). Des machines purement v6 vont apparaître, tout simplement parce qu'il n'y aura plus d'adresses v4, alors que les machines purement v4 existant aujourd'hui n'auront pas encore commencé à migrer. Les mécanismes de traduction d'adresses d'une famille à l'autre prennent donc tout leur intérêt (section 1 du RFC). Le RFC 5211 propose donc un autre plan de transition, faisant sa place à ces mécanismes.
La section 1.1 explique pourquoi considérer les mécanismes de traduction d'adresses, à côté des deux techniques du RFC 4213 (la double-pile mais aussi les tunnels). Si la traduction d'adresses est souvent utilisé pour de mauvaises raisons (par exemple parce qu'elle assurerait la sécurité des machines), elle présente aussi des avantages, notamment le fait qu'elle soit, avec les ALG (cf. section 3.1.5), la seule à permettre la communication entre des machines purement v4 et des machines purement v6. Elle a donc sa place dans les stratégies de transition à moyen terme.
La section 1.3 fixe les objectifs de la traduction d'adresses. Il ne s'agit pas de résoudre tous les problèmes (NAT-PT avait souffert d'objectifs irréalistes) mais d'attraper les fruits les plus bas. Il y a (en simplifiant beaucoup), deux types d'application : les client/serveur comme SSH, où le serveur attend les connexions d'un client, et les pair-à-pair comme SIP, où tout le monde initie et accepte des nouvelles connexions. Celles-ci de subdivisent à leur tour en pair-à-pair « d'infrastructure » (SIP, SMTP, ...) où les connexions sont typiquement d'assez courte durée et pair-à-pair « d'échange » comme avec BitTorrent, où on choisit ses pairs (le plus fiable, le plus rapide) et où on maintient de longues sessions avec eux. Quelles sont les conséquences pratiques de cette typologie ? Les applications client/serveur nécessitent des connexions d'un client v4 vers un serveur v6 (ou réciproquement), idéalement sans que les équipements de traduction d'adresses aient à garder un état. Les applications pair-à-pair nécessitent aussi de telles connexions, et dans les deux sens cette fois, mais elles seront sans doute moins nombreuses que celles d'un client vers un serveur, et les solutions avec état seront donc moins problématiques. Enfin, dans le cas de machines purement clientes (des Minitel), il n'est pas nécessaire d'ouvrir des connexions vers elles. Dans tous les cas, s'il faut garder un état pour la traduction, il est très nettement préférable qu'il soit entièrement dans les équipements réseaux (typiquement le routeur) et que la traduction ne nécessite aucune aide de la part de la machine aux extrémités. NAT-PT exigeait de l'état dans deux endroits (le traducteur lui-même et le serveur DNS) et que ces états soient coordonnés. Un routeur NAT IPv4 actuel a un état mais qui est entièrement dans le routeur et qui ne nécessite aucune participation d'une autre machine.
Enfin, un problème de vocabulaire quasiment philosophique. Faut-il parler de « transition » vers IPv6 sachant que ce mot connote une idée d'achèvement (un jour, il n'y aura plus d'IPv4) alors que rien n'est moins sûr et que, de toute façon, cela prendra de nombreuses années ? Certains préfèrent dire que des mécanismes comme la traduction d'adresses sont des mécanismes de « coexistence » plutôt que de « transition » (section 1.4).
La section 2 du RFC s'attache ensuite à décrire les scénarios où
les mécanismes de transition pourront être utiles. Par exemple, en
2.1, le scénario est celui d'un FAI récemment apparu dans un endroit
où il est très difficile d'obtenir des adresses IPv4 (par exemple en
Asie ou en Afrique) et qui est donc entièrement en IPv6. Ses clients
veulent quand même se connecter à des services IPv4. Des techniques
comme celles du RFC 7915 peuvent alors être utilisées
(rappelez-vous que notre RFC 6144 ne décrit qu'un cadre,
pas des techniques spécifiques). Le scénario de la section 2.4
représente le problème inverse : un réseau ancien et jamais mis à
jour, entièrement en IPv4, et qui veut accéder aux services uniquement
v6.
Bien plus difficile à résoudre (le petit nombre d'adresse IPv4 ne
permet pas de faire une traduction d'adresses efficace, on doit
consommer également les ports et ils ne sont que 65536
par adresse IP), ce problème est considéré comme « hors-sujet ». On ne
peut pas résoudre tous les malheurs du monde et ce réseau devra
utiliser d'autres techniques (probablement des
ALG, même si le RFC ne les cite pas ici).
Le cadre complet de ces solutions à base de traduction d'adresses est en section 3. La section 3.1 liste les composants du cadre :
- La traduction d'adresses (section 3.1.1), comment une adresse v6 est traduite en v4 et réciproquement, ce qui implique un préfixe v6 et une méthode de dérivation des adresses v4 à partir de v6 et réciproquement. Le RFC 6052 donne les détails. Pour les traductions sans état, le même algorithme sert dans les deux sens (v4 vers v6 et l'inverse). Pour celles avec état, l'algorithme ne sert que dans un sens et la table des états est utilisée en sens inverse.
- La modification des paquets IP rendue nécessaire par la traduction d'adresses (par exemple dans ICMP puisqu'un paquet ICMP d'erreur contient une partie du paquet original, avec des adresses IP). La section 3.1.2 renvoie au RFC 6145 qui couvre le cas sans état.
- Le maintien d'un état pour les traductions avec état (section 3.1.3), traitée dans le RFC 6146.
- L'aide que doit apporter le DNS à ces opérations (section 3.1.4), normalisée dans le RFC 6147, qui prévoit la génération automatique d'enregistrements AAAA lorsque seul un enregistrement A existe.
- Les ALG (Application Layer Gateways, section 3.1.5) qui sont nécessaires pour certaines applications comme FTP (le RFC sur FTP64 n'est pas encore paru) qui inclus les adresses IP dans ses données.
Une fois les composants de la solution listés (on voit qu'il faut beaucoup de choses pour faire fonctionner l'Internet malgré le retard pris à migrer vers IPv6), la section 3.2 expose leurs modes de fonctionnement. La traduction sans état (section 3.2.1) passe mieux à l'échelle et maintient la transparence du réseau de bout en bout. Mais elle ne peut pas être utilisée pour tous les scénarios. La traduction avec état (section 3.2.2) peut alors prendre le relais.
Il n'existe pas de solution magique à tous les problèmes. Le déploiement bien trop lent d'IPv6 a laissé une situation peu satisfaisante, et qui ne pourra pas être complètement résolu par de nouveaux protocoles. La section 5 rappelle donc que certaines questions n'ont pas de solution présente. Mais le groupe Behave a dû travailler dans l'urgence, pour fournir des solutions avant l'épuisement d'IPv4 et s'est donc focalisé sur les problèmes les plus « faciles ». Peut-être dans de futurs RFC ?
À noter qu'un FAI britannique a déjà un tel service déployé sur son réseau.
L'article seul
RFC 6146: Stateful NAT64: Network Address and Protocol Translation from IPv6 Clients to IPv4 Servers
Date de publication du RFC : Avril 2011
Auteur(s) du RFC : M. Bagnulo (UC3M), P. Matthews (Alcatel-Lucent), I. van Beijnum (IMDEA Networks)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF behave
Première rédaction de cet article le 28 avril 2011
Dans la grande série des techniques de coexistence entre IPv4 et IPv6, voici une normalisation de NAT64, une technique de traduction entre IPv6 et IPv4, permettant à une machine purement IPv6 de se connecter à une machine purement IPv4. Ce RFC fait partie de la série introduite par le document d'architecture générale RFC 6144.
Aujourd'hui, l'état de l'Internet est que la majorité des serveurs sont accessibles uniquement en IPv4. Or, les dernières adresses IPv4 disponibles à l'IANA ont été distribuées le 3 février 2011. Demain, les nouvelles machines recevront donc de plus en plus uniquement des adresses IPv6. Comment se connecteront-elles à ces serveurs purement v4 ? Une des solutions est de traduire automatiquement les paquets IPv6 du client en IPv4 pour les envoyer au serveur, et de faire la traduction inverse au retour. Cela se nomme NAT64 et notre RFC normalise la version « à état » de cette méthode. « À état » car le traducteur garde un souvenir des flux de données en cours et peut donc, pour la traduction, tenir compte d'un état, des paquets précédents (la version sans état est dans le RFC 7915).
Notez le titre de ce RFC : ses ambitions sont limitées, il ne s'agit pas, comme l'essayait le défunt NAT-PT (RFC 2766) de fournir une solution générale à tous les problèmes de communication v4-v6 mais seulement de permettre à des clients IPv6 de se connecter à des serveurs IPv4.
NAT64 ressemble beaucoup à l'actuel NAT44 (celui que tout le monde est obligé d'utiliser à l'hôtel, chez lui s'il a plusieurs machines, cf. RFC 3022) dans la mesure où il permet :
- Aucune modification au client ou au serveur, tout est fait dans le routeur du réseau IPv6-pur,
- Les communications client-serveur, comme le titre de notre RFC le précise,
- Certaines communications pair-à-pair, en utilisant des techniques comme ICE (RFC 5245),
- Des communications lancées depuis l'extérieur, si on a configuré statiquement le traducteur pour reconnaître certaines adresses.
Il s'en distingue par le fait qu'on ne se contente pas de traduire les adresses, il faut traduire tout l'en-tête du paquet, et par le fait que, pour que les applications tournant sur la machine purement IPv6 trouvent une adresse IPv6, un serveur DNS spécial, DNS64 (RFC 6147) est nécessaire. Vu la nécessité de faire plus de travail qu'en NAT44, la spécification ne fonctionne que pour certains protocoles des couches supérieures, pour l'instant uniquement ICMP, UDP et TCP. Ne comptez donc pas faire, par exemple, du SCTP.
Notre RFC s'appuie sur plusieurs autres documents, celui d'architecture (RFC 6144), celui sur la traduction des adresses (RFC 6052), et celui sur l'algorithme de traduction (RFC 7915).
Les équipements qui font faire le travail sont donc :
- Le traducteur, qui sera typiquement embarqué dans le routeur (CPE, box, ou bien plus loin dans le réseau de l'opérateur),
- Le résolveur DNS64, qui pourra être inclus dans le même routeur ou bien fourni séparement.
Normalement, les traducteurs qui suivront ce RFC seront conformes aux recommandations qu'avait édicté le groupe de travail Behave, dans sa première version, à savoir les RFC 4787, RFC 5382, RFC 5508... et ils permettront les techniques de passage au travers des NAT comme ICE (RFC 5245).
La norme elle-même commence en section 3 mais une gentille introduction, utilisable si vous ne connaissez pas grand'chose aux NAT, figure en section 1.2. Essayons de la résumer sommairement en prenant pas mal de raccourcis : le traducteur a donc deux interfaces, une vers le réseau IPv6-pur et une vers un réseau IPv4 (et peut-être aussi IPv6 mais, dans ce cas, pas besoin de traduction). Le traducteur doit donc avoir une adresse IPv4 publique. Lorsqu'il reçoit un paquet IPv6 dont l'adresse de destination indique qu'il doit être traduit, il le transforme en IPv4 (l'adresse IPv4 est encapsulée dans l'adresse IPv6), et l'envoie par l'interface IPv4. Au retour, c'est un peu plus dur car l'adresse IPv4 de destination est celle du traducteur et, pour retrouver l'adresse IPv6 du vrai destinataire, il doit consulter une table où il a stocké les clients IPv6 qui parlaient à l'extérieur. Comme en NAT44, le numéro de port est utilisé pour reconnaitre les clients locaux. La combinaison d'une adresse IP et d'un port est appelée « adresse de transport ». On le voit, cela ne marche bien que si c'est le réseau IPv6 qui initie la communication (mais diverses astuces permettent des communications un peu plus pair-à-pair).
Le NAT64 devrait donc être appelé NAPT (Network Address AND PORT Translation) car, dans l'écrasante majorité des cas, le traducteur n'aura pas assez d'adresses IPv4 pour tous les clients IPv6 qu'il sert (si on avait assez d'adresses v4, il n'y aurait guère de raison de migrer vers v6).
Comment le client IPv6 a-t-il trouvé l'adresse IPv6 de destination, puisque le serveur n'a qu'une adresse IPv4 ? C'est le rôle du serveur DNS64 qui ment (pour la bonne cause) en fabriquant un enregistrement DNS de type AAAA (adresse IPv6) à partir de l'enregistrement réel A (adresse IPv4). Les étapes complètes effectuées par le client sont décrites en section 1.2.2.
On a vu que cette opération nécessitait de réserver une partie de
l'espace d'adressage IPv6 pour représenter les adresses IPv4. Cette
partie peut être localement définie (après tout, seuls le traducteur
et le résolveur DNS64 auront besoin de la connaître) ou bien on peut
utiliser le préfixe standard 64:FF9B::/96.
Ici, on voit un serveur DNS64 et un traducteur coopérer pour permettre
à une machine purement IPv6 de communiquer avec
www.example.com, qui n'a qu'une adresse IPv4 : .
Du fait que le traducteur a un état, tous les paquets IPv4 venus de l'extérieur ne sont pas acceptés. Seuls peuvent être transmis ceux qui correspondent à une correspondance existante, en suivant les règles des RFC 4787 et RFC 5382 (Endpoint-Independent Filtering et Address-Dependent Filtering ; suivre ces règles est important pour que les applications pair-à-pair fonctionnent).
Voilà pour l'introduction. Maintenant, pour lire la spécification elle-même, il faut d'abord bien apprendre la terminologie, en section 2. Quelques termes qui ne sont sans doute pas familiers à tous :
- Un quintuplet est l'identificateur d'une session TCP ou UDP. Il est composé de {adresse IP source, port source, adresse IP destination, port destination, protocole de couche 4}.
- La BIB (Binding Information Base) est la liste des communications actuellement en cours, pour un protocole de transport donné. Une liaison (binding) est faite entre une adresse de transport IPv4 et une IPv6, afin de déterminer à qui « appartient » un paquet entrant dans le traducteur. Les liaisons peuvent être établies automatiquement, lorsque le premier paquet passe, ou bien manuellement. Voir la section 3.1.
- Un virage en épingle à cheveux désigne le cas où deux machines situées du même côté du traducteur communiquent via le traducteur, qui doit alors renvoyer le paquet par là d'où il est venu (cf. section 3.8).
- Une adresse de transport est le doublet formé d'une adresse IP et d'un port. Comme le traducteur aura moins d'adresses IPv4 que de clients, l'ajout du port est nécessaire pour différencier les sessions, lorsqu'un paquet IPv4 arrive.
Vous avez bien retenu tout le vocabulaire ? Alors, vous pouvez lire la norme elle-même, à partir de la section 3. Quelques points importants à retenir :
- NAT64 doit garder une table des sessions TCP et UDP en cours, pour pouvoir déterminer leur fin (et donc la suppression des liaisons associées).
- Chaque entrée de la BIB peut être associée à plusieurs sessions et il ne faut donc la supprimer que lorsque la dernière session est finie.
- La fragmentation pose des défis particuliers. Un traducteur NAT64 conforme à la norme doit gérer les fragments, même s'ils arrivent dans le désordre. Il doit donc faire du réassemblage (en limitant toutefois les ressources allouées à cette tâche, pour se protéger contre les attaques DoS ; voir les RFC 1858, RFC 3128 et RFC 4963). Le traducteur a aussi le droit d'ajouter quelques contraintes comme le fait que tout l'en-tête TCP doit être dans le premier fragment.
- Comme le NAT64 avec état n'est défini que pour TCP, UDP et ICMP, le traducteur doit jeter les paquets des autres protocoles (en prévenant la source, via un paquet ICMP).
- Le traducteur ayant une connaissance des sessions actives, il peut jouer un rôle de filtre en bloquant les paquets ne correspondant pas à une telle session.
- Déterminer qu'une session est finie n'est pas forcément
évident. Ainsi, si la fin d'une session TCP est facile à observer
(échange des paquets
FINpar les deux parties), que faire pour une « session » UDP puisqu'il n'y a pas de connexion et donc pas de fin explicite ? La solution est d'utiliser une minuterie, remise à zéro par chaque paquet, et qui se déclenche après un certain temps d'inactivité, coupant la session UDP. - Pour TCP, la section 3.5.2 décrit en détail les événements de la machine à états de TCP que le traducteur doit observer pour découvrir début et fin de la session. Elle est très longue et détaillée, j'espère que les programmeurs des routeurs bas de gamme à 60 dollars prendront le temps de la lire !
- Les règles de conversion des adresses IPv4 en IPv6 et réciproquement sont celles du RFC 6052.
Vous avez noté qu'à plusieurs reprises, j'ai utilisé des termes vagues comme « un certain temps ». Les valeurs numériques recommandées pour les diverses constantes sont en section 4. Ainsi, avant de fermer une session UDP, le traducteur doit attendre (par défaut) au moins cinq minutes (cf. RFC 4787), le traducteur doit attendre les fragments manquants au moins deux secondes, etc.
Cette technique du NAT64 améliore-t-elle ou aggrave-t-elle les problèmes de sécurité ? D'abord, cette section note que toute solution de sécurité de bout en bout qui protège l'en-tête IP contre les modifications (par exemple l'AH d'IPsec) va être cassée par NAT64, qui modifie précisément l'en-tête. Si le NAT64 est obligatoire, IPsec peut, par exemple, utiliser l'encapsulation UDP (RFC 3948). La section 5 insiste d'autre part sur le fait qu'un traducteur n'est pas un pare-feu et que le filtrage réalisé par effet de bord de la gestion d'état n'est pas forcément adapté à la sécurité.
D'autre part, NAT64 a ses propres vulnérabilités. Les principales sont le risque d'attaques par déni de service. Par exemple, un attaquant situé à l'intérieur (côté IPv6) peut utiliser toutes les adresses (en général une seule) et ports disponibles et empêcher ainsi l'accès des autres utilisateurs. Une autre attaque possible est d'envoyer régulièrement des paquets de façon à maintenir une liaison active et d'empêcher le traducteur de relâcher des ressources. Une protection possible serait de ne remettre à zéro la minuterie que si le paquet qui passe vient de l'intérieur (supposé plus fiable).
Quelles implémentations existent aujourd'hui ? Viagénie
en à une en logiciel libre, voir http://ecdysis.viagenie.ca/.
Le terme de ecdysis désigne la
mue des arthropodes puisque NAT64 permet à IP
de muer vers un nouveau protocole...
Voici un exemple d'installation et d'usage :
c'est un module noyau, donc il
faut installer les paquetages qui permettent la compilation de modules
noyau. Sur une Debian version « squeeze » avec
le noyau Linux 2.6.32-5 :
% sudo aptitude install linux-headers-2.6.32-5-686 linux-kbuild-2.6.32 ... % make /bin/sh: [[: not found make -C /lib/modules/2.6.32-5-686/build M=/home/stephane/tmp/ecdysis-nf-nat64-20101117 modules make[1]: Entering directory `/usr/src/linux-headers-2.6.32-5-686' CC [M] /home/stephane/tmp/ecdysis-nf-nat64-20101117/nf_nat64_main.o CC [M] /home/stephane/tmp/ecdysis-nf-nat64-20101117/nf_nat64_session.o CC [M] /home/stephane/tmp/ecdysis-nf-nat64-20101117/nf_nat64_config.o LD [M] /home/stephane/tmp/ecdysis-nf-nat64-20101117/nf_nat64.o Building modules, stage 2. MODPOST 1 modules CC /home/stephane/tmp/ecdysis-nf-nat64-20101117/nf_nat64.mod.o LD [M] /home/stephane/tmp/ecdysis-nf-nat64-20101117/nf_nat64.ko make[1]: Leaving directory `/usr/src/linux-headers-2.6.32-5-686' % sudo make install ... # On peut éditer le script avant pour changer les paramètres... % sudo ./nat64-config.sh
Ensuite, on peut vérifier que tout s'est bien passé en regardant la table de routage :
% netstat -r -n -Ainet6 Kernel IPv6 routing table Destination Next Hop Flag Met Ref Use If 64:ff9b::/96 :: U 1024 0 0 nat64 ...
Parfait, les paquets pour le préfixe NAT64 sont bien routés à part. Tentons notre chance :
% telnet 64:ff9b::453f:bd0b Trying 64:ff9b::453f:bd0b...
Et on voit bien les paquets IPv6 sur l'interface nat64 :
21:18:58.910669 IP6 2a01:e35:8bd9:8bb0:304b:5a4b:3b8c:7b1c.37033 > \
64:ff9b::453f:bd0b.23: Flags [S], seq 3580860303, win 5760, \
options [mss 1440,sackOK,TS val 23731660 ecr 0,nop,wscale 6], length 0
Et les IPv4 sur l'interface normale :
21:19:09.263613 IP 192.168.2.1.37038 > \
69.63.189.11.23: Flags [S], seq 4043093045, win 5760, \
options [mss 1440,sackOK,TS val 23734248 ecr 0,nop,wscale 6], length 0
Un déploiement expérimental de NAT64 est celui du réseau de la recherche lituanien. Voir leur site Web.
Pour un récit très détaillé, avec plein de technique, d'un test de NAT64 avec DNS64, voir l'article de Jérôme Durand « J'ai testé pour vous : Stateful NAT64 avec DNS64 ».
L'article seul
RFC 6145: IP/ICMP Translation Algorithm
Date de publication du RFC : Avril 2011
Auteur(s) du RFC : X. Li, C. Bao (CERNET Center/Tsinghua University), F. Baker (Cisco Systems)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF behave
Première rédaction de cet article le 28 avril 2011
Parmi les nombreuses techniques de coexistence d'IPv4 et IPv6, le groupe de travail Behave, dans sa version 2 (la 1 avait été consacrée aux techniques permettant de supporter le NAT) développe un mécanisme de traduction permettant à une machine IPv6 de communiquer avec une machine v4 et réciproquement. Une des pièces de ce mécanisme est l'algorithme de traduction, présenté dans ce RFC 6145.
Ce nouveau mécanisme de traduction entre IPv4 et IPv6 s'inscrit dans le cadre décrit dans le RFC 6144. Il vise à remplacer « NAT-PT » (RFC 2765 et RFC 2766), officiellement retiré, après n'avoir eu aucun succès. Ce RFC a lui-même été remplacé par la suite par le RFC 7915.
Plus spécifiquement, notre RFC 6145 est la version sans état du traducteur, c'est-à-dire que le traducteur peut traiter chaque paquet indépendemment des autres. Le traducteur n'a pas de table des flots en cours. S'il redémarre et perd toute mémoire, pas de problème, il peut immédiatement reprendre son travail. Cette technique permet notamment le passage à l'échelle : un traducteur d'adresses peut gérer un très grand nombre de clients sans épuiser sa mémoire. Mais elle a quelques inconvénients comme le fait que les fragments ICMP ne seront pas traduits. Il existe donc également une version avec état du nouveau mécanisme, normalisée dans le RFC 6146. La section 1.3 discute plus en détail ces deux possibilités, avec ou sans état.
Donc, le NAT64 (son nom non officiel) vise à traduire des adresses IP entre deux réseaux, l'un v4 et l'autre v6. Comme notre RFC 6145 ne traite que le cas sans état, les adresses doivent être converties de manière purement algorithmique, sans référence à leur histoire (cf. RFC 6052 pour ces algorithmes).
Dit comme ça, cela a l'air simple mais la traduction entre deux protocoles différents porte pas mal de pièges. Ainsi, les en-têtes de paquet n'ont pas la même taille en v4 (20 octets ou plus) et en v6 (40 octets, fixe), ce qui fait que des problèmes de MTU peuvent se poser (section 1.4). Le traducteur doit se comporter comme un routeur, donc fragmenter les paquets trop gros (en IPv4) ou retourner un message ICMP « Packet too big ».
La section 4 du RFC décrit en détail les opérations que doit faire le traducteur depuis IPv4 vers IPv6 (rappelez-vous que la traduction des adresses v4 en v6 est essentiellement dans le RFC 6052, section 2). Il y a des détails que ne connaissent pas les routeurs NAT44, qui se contentent de changer adresses et ports. En effet, ici, il faut traduire tout l'en-tête. Je ne vais pas résumer complètement cette section, juste pointer quelques pièges possibles. Ainsi, les en-têtes n'étant pas les mêmes en v4 et en v6, notre RFC doit spécifier quoi en faire. Certains cas sont évidents (comme le champ Longueur), d'autres moins. Ainsi, le champ TOS de IPv4 doit être copié verbatim dans le champ Traffic Class de IPv6. Mais le traducteur doit aussi offrir une option pour ignorer le TOS et mettre systématiquement zéro comme Traffic Class. Le champ TTL de IPv4 doit être copié dans Hop limit mais après avoir été décrémenté (rappelez-vous que le traducteur est un routeur).
La vraie difficulté n'est pas tellement dans la traduction d'IP que dans celle d'ICMP. En effet, le paquet ICMP contient le début du paquet IP qui a motivé son envoi, et ce début de paquet doit être traduit, également, sans quoi le destinataire du paquet ICMP n'y comprendra rien (par exemple, sans traduction ICMP, il recevrait en IPv6 un paquet ICMP dont le contenu est un paquet IPv4...). Notre RFC détaille donc les traductions à faire pour tous les modèles de paquets ICMP.
Le traducteur doit aussi veiller au champ Type d'ICMP, dont les valeurs sont différentes entre IPv4 et IPv6 (par exemple, Echo Reply est 0 en v4 et 129 en v6). Certains types n'ont pas d'équivalent (comme les types Timestamp ou Address Mask d'ICMPv4, absents d'ICMPv6) et le paquet ICMP doit donc être abandonné.
Enfin, le traducteur doit aussi prendre en charge les en-têtes de la couche 4 car la traduction des adresses peut ne pas être neutre pour la somme de contrôle (section 4.5) et il peut donc être nécessaire de recalculer cette dernière.
Et en sens inverse ? La section 5 décrit la traduction d'IPv6 vers IPv4. On retrouve TOS et Traffic Class, les problèmes de MTU et de fragmentation, et la traduction des messages ICMP.
Les problèmes de MTU et de fragmentation sont des cauchemars habituels sur l'Internet, notamment en raison d'équipements intermédiaires (typiquement des pare-feux) programmés avec les pieds par des anonymes, ou bien configurés n'importe comment, et qui bloquent les paquets ICMP, voire les modifient, en ignorant complètement le RFC 4890. Les traducteurs v4<->v6 auront donc ce problème, comme tant d'autres techniques utiles. La section 6 doit donc se pencher sur le traitement des paquets ICMP Packet too big qui signalent normalement que la MTU est plus réduite que ne le croit l'émetteur et qu'il faut fragmenter. Comme ces paquets sont parfois interceptés, voire modifiés, par des machines gérées par des incompétents, le traducteur doit donc parfois faire des efforts spécifiques (par exemple en modifiant la valeur de la MTU dans certains messages Packet too big).
Rien n'étant parfait en ce bas monde, les traducteurs NAT64 vont aussi introduire de nouvelles questions de sécurité. La section 8 tente de prévoir lesquelles mais reste optimiste en considérant que la plupart des problèmes existent déjà dans IPv4 ou dans IPv6. Ainsi, comme avec le NAT traditionnel, l'authentification des paquets par IPsec (RFC 4302) ne marchera pas.
Pour les gens qui aiment bien les exposés concrets, avec des 0 et
des 1, l'annexe A explique en grand détail le
processus de traduction avec un réseau simple d'exemple, connectant le
réseau traditionnel 198.51.100.0/24 et le réseau
nouveau 2001:db8::/32, via un
traducteur. Deux machines, H4 et H6, Alice et Bob du NAT64, vont tenter de communiquer. Le traducteur
utilise le préfixe 2001:db8:100::/40 pour
représenter les adresses IPv4 et 192.0.2.0/24
pour représenter les adresses IPv6. Ainsi,
H6, qui a l'adresse 2001:db8:1c0:2:21:: est
représenté en v4 par 192.0.2.33. H4 a l'adresse
198.51.100.2. Une fois le routage
correctement configuré pour passer par le traducteur, suivez le RFC
pour voir le trajet des paquets et les opérations qu'ils subissent,
dans le cas où c'est H6 qui initie la connexion, et dans le cas inverse.
Au moins deux mises en œuvre existent déjà, faite par Ecdysis/Viagénie (avec état) et Tayga (sans état, mais nettement plus simple, d'après ses utilisateurs). Pour compenser l'absence de traduction avec état chez Tayga, on peut, sur Linux, le coupler avec SNAT/MASQUERADE (merci à Guillaume Leclanché pour sa suggestion).
Quels sont les changements entre ce mécanisme et celui du RFC 2765 ? Ils sont résumés en section 2. Outre une complète réorganisation des documents, il s'agit surtout de détailler bien davantage les opérations à effectuer. Depuis, notre RFC 6145 a été mis à jour dans le RFC 7915.
Pour réfléchir à la grande question « avec état ou sans état », un article « pro-état » : « Stateless NAT64 is useless ».
L'article seul
RFC 6164: Using 127-Bit IPv6 Prefixes on Inter-Router Links
Date de publication du RFC : Avril 2011
Auteur(s) du RFC : M. Kohno (Juniper Networks, Keio University), B. Nitzan (Juniper Networks), R. Bush, Y. Matsuzaki (Internet Initiative Japan), L. Colitti (Google), T. Narten (IBM Corporation)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 23 avril 2011
Quelles adresses IP utiliser sur un lien point-à-point, lorsque les deux machines qui se parlent sont seules sur le lien ? Ce nouveau RFC recommande l'utilisation d'un préfixe de longueur /127 pour IPv6, ne permettant que deux adresses IP.
Cette recommandation existait déjà pour IPv4, dans le RFC 3021, qui recommande un /31. Pour IPv6, la norme, en l'occurrence le RFC 4291 préconisait au contraire un préfixe /64 pour tous les liens. Les adresses sous ce préfixe pouvaient alors être construites selon le format dérivé du EUI-64. Certains opérateurs avaient déjà ignoré cette norme et utilisaient des préfixes de longueur /127 (ne laissant qu'un seul bit pour identifier la machine), malgré l'avis du RFC 3627, qui mettait en avant le risque de confusion avec l'adresse anycast des routeurs. Notre RFC 6164 leur donne raison et officialise les préfixes /127.
Lorsqu'il n'y a que deux machines sur un lien (par exemple une
liaison point-à-point, que ce soit parce
qu'elle utilise un technologie purement point-à-point ou bien
simplement parce qu'elle a été configurée ainsi), on peut aussi utiliser
les adresses locales au lien (fe80::/10). Mais,
comme le rappelle la section 2 de notre RFC, celles-ci ne sont pas
toujours suffisantes : surveillance du réseau à distance,
traceroute et BGP sont
des exemples de bonnes raisons pour utiliser des adresses
globales.
Quelles étaient les raisons pour se méfier des préfixes de longueur 127 ? La section 4 résume la principale : confusion possible avec l'adresse des routeurs du lien, définie en section 2.6.1 du RFC 4291. Or, non seulement l'expérience des opérateurs qui ont violé le RFC 3627 a été positive (pas de problèmes notés) mais on peut trouver des très bonnes raisons pour utiliser des préfixes plus spécifiques qu'un /64. La section 5 cite :
- Risque de boucle de routage sur un préfixe plus général qu'un /127, si le lien n'utilise pas le NDP (c'est le cas de SONET).
- Risque d'attaque par déni de service en épuisant le cache des voisins. Imaginons nos deux routeurs sur un Ethernet et étant configurés dans un préfixe /64. Tout paquet IP à destination d'une adresse de ce préfixe va faire l'objet d'une tentative de résolution par NDP (RFC 4861), et, pendant ce temps, le routeur devra garder une entrée dans sa table des voisins, avant de renoncer. Évidemment, aucune machine n'a une table des voisins de 2^64 entrées. Un méchant qui générerait des paquets à destination de toutes les adresses du préfixe /64 pourrait remplir cette table plus vite que l'expiration du délai de garde ne la vide. Notez que cette attaque n'est pas spécifique aux liens point-à-point mais ceux-ci sont souvent des liens vitaux, entre routeurs « importants ». Cette attaque peut être traitée en limitant le nombre de résolutions NDP en cours mais cela ne la résout pas complètement, alors que l'usage d'un /127 la supprime.
- Sensation de gaspillage des adresses si on bloque un /64 pour seulement deux machines. Vue la taille de l'espace d'adressage d'IPv6, c'est le moins convaincant des arguments.
Synthétisant tout cela, la section 6 de notre RFC conclut qu'il faut utiliser les /127. Le logiciel des routeurs doit accepter de tels préfixes. Les opérateurs doivent faire attention à ne pas utiliser certaines adresses, celles-ci ayant une signification particulière : adresses où les 64 bits les plus à droite sont nuls, ou bien adresses dont ces mêmes bits ont une des 128 plus grandes valeurs (réservées par le RFC 2526).
Pour un exemple des discussions récurrentes /64 vs. /127, voir « Point-to-point Links and /64s ». Le RFC 3627 a été officiellement déclaré « d'intérêt historique seulement » par le RFC 6547. À noter que ce RFC 6164 ne met pas à jour formellement le RFC 5375, qui continuait avec les anciennes recommandations.
L'article seul
RFC 6248: RFC 4148 and the IPPM Registry of Metrics are Obsolete
Date de publication du RFC : Avril 2011
Auteur(s) du RFC : A. Morton (AT&T Labs)
Pour information
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 15 avril 2011
Le progrès, c'est aussi de savoir reconnaître quand une idée était mauvaise et qu'il vaut mieux l'abandonner. Ce court RFC prend ainsi acte de l'échec du registre des métriques lancé par le RFC 4148 et décide d'y renoncer.
Le groupe de travail IPPM est chargé notamment de développer des métriques (définitions rigoureuses d'une grandeur qu'on peut mesurer) comme le taux de perte des paquets (RFC 7680). Dans le cadre de ce travail, il avait semblé intéressant, avec le RFC 4148 de créer un registre IANA des métriques existantes. En fait, aucun logiciel n'a été développé pour l'utiliser, aucun utilisateur de ce registre n'a pu être identifié après des mois de recherche (fin 2010), et le registre était donc déjà de facto abandonné avant que notre RFC 6248 le reconnaisse et ne le decrète dépassé. Un exemple montrant l'inutilisation du registre ? Le fait qu'il contenait une faute de syntaxe qui a mis huit mois (depuis la parution du RFC 5644) avant d'être signalée ! Cette décision d'abandon explicite est nécessaire pour éviter d'accumuler dans les registres IANA un grand nombre d'informations qui ne sont plus maintenues.
Notre RFC rappelle d'abord quelles étaient les motivations qui avaient mené à la création du registre : la grande variabilité des définitions de métriques, d'autant plus que certaines étaient modifiées et/ou enrichies par des RFC ultérieurs comme le RFC 3432. Stocker ces variations dans un registre semblait une bonne idée sauf que, en pratique, la structure du registre n'avait pas permis de stocker toute l'information.
Le registre ne sera donc plus mis à jour (le dernier RFC à l'avoir fait avait été le RFC 6049) même s'il continue à être distribué par l'IANA mais avec un texte montrant sans ambiguité son statut.
L'article seul
RFC 6220: Defining the Role and Function of IETF Protocol Parameter Registry Operators
Date de publication du RFC : Avril 2011
Auteur(s) du RFC : Danny McPherson (IAB), Olaf M. Kolkman (IAB), John Klensin (IAB), Geoff Huston (IAB)
Pour information
Première rédaction de cet article le 15 avril 2011
Dernière mise à jour le 6 mai 2011
Voici un RFC officiel de l'IAB pour mettre solennellement par écrit le rôle de l'opérateur des registres des protocoles utilisé par l'IETF. Des tas de protocoles normalisés par cet organisme ont besoin de garder une trace des noms ou numéros réservés (par exemple les numéros de port de TCP ou UDP, les numéros d'options DHCP, etc) et le rôle de l'opérateur du registre qui garde ces réservations (aujourd'hui, essentiellement l'IANA) n'avait apparemment jamais été formalisé. À noter que, depuis, ce RFC a été remplacé par le RFC 8722.
L'IETF n'assure en effet pas ce rôle d'opérateur du registre elle-même. Elle se focalise sur la production de normes (les RFC) et délègue la gestion du registre. Pourquoi les valeurs en question ne sont-elles pas directement mises dans les RFC ? Parce qu'elles évoluent plus vite que la norme elle-même. Ainsi, l'enregistrement d'un nouveau type d'enregistrement DNS est un processus bien plus souple que de modifier un RFC et la liste de tels types ne peut donc pas être figée dans un RFC (ceux-ci ne sont jamais modifiés, seulement remplacés, et cela n'arrive pas souvent).
Mais on ne peut pas non plus laisser chacun définir ses propres paramètres, car cela empêcherait toute interprétation commune. D'où cette idée d'un registre des paramètres. Les règles d'enregistrement dans ce registre, la politique suivie, sont décrites pour chaque norme dans la section IANA considerations du RFC, en utilisant le vocabulaire et les concepts du RFC 5226 (pour les types d'enregistrements DNS, cités plus haut, c'est dans le RFC 6895).
Plusieurs autres SDO suivent ce même principe de séparation entre la normalisation et l'enregistrement (en revanche, les groupes fermés d'industriels qui tentent d'imposer leur standard ne séparent pas en général ces deux fonctions). Par exemple, l'ISO définit, pour la plupart de ses normes, une Registration Authority ou bien une Maintenance Agency qui va tenir le registre. (Exemples : l'opérateur du registre de ISO 15924 est le consortium Unicode et celui du registre de ISO 639 est SIL. Contre-exemple : l'opérateur du registre de ISO 3166 est l'ISO elle-même.) Pourquoi cette séparation ? Les raisons sont multiples mais l'une des principales est la volonté de séparer la politique de base (définie dans la norme) et l'enregistrement effectif, pour gérer tout conflit d'intérêts éventuel. Un opérateur de registre séparé peut être plus indépendant, afin de ne pas retarder ou bloquer l'enregistrement d'un paramètre pour des raisons commerciales ou politiques. Notons aussi que bien d'autres fonctions liées à l'IETF sont également assurées à l'extérieur, comme la publication des RFC (cf. RFC 6335).
Contre-exemple, celui du W3C, qui utilise
très peu de registres et pas d'opérateur de registre officiel séparé. En
pratique, c'est l'IANA qui gère plusieurs registres Web, comme celui
des URI bien connus (RFC 8615), celui des types de
fichiers (comme application/pdf ou
image/png), celui des en-têtes
(utilisés notamment par HTTP), etc. En dehors
de l'IANA, le W3C a quelques registres gérés en interne comme celui de
Xpointer. Pour le reste, la politique
du W3C est plutôt qu'un registre est un point de passage obligé et que
de tels points ne sont pas souhaitables.
Dans le cas de l'IETF, les documents existants sont le RFC 2026, qui décrit le processus de normalisation
mais pas celui d'enregistrement. Ce dernier est traditionnellement
connu sous le nom de « fonction IANA » (d'où la section IANA
considerations des RFC) même si, en pratique, ce n'est pas
toujours l'IANA qui l'effectue. (Les registres
de l'IANA sont en https://www.iana.org/protocols/.)
La section 2 du RFC expose donc le rôle et les responsabilités
du(des) opérateur(s) de registres de paramètres. Celui(ceux)-ci, désormais nommés
avec majuscules IETF Protocol Parameter Registry Operator, seront formellement
choisis désormais par l'IAOC (RFC 4071). J'ai mis le pluriel car l'IANA
n'assure pas actuellement la totalité du rôle : il existe d'autres
opérateurs de registres, en général sur des tâches très secondaires comme par
exemple le RIPE-NCC pour l'enregistrement en
e164.arpa
(ENUM, cf. RFC 6116 et
lettre
de l'IAB). Dans le futur, on pourrait imaginer un
rôle moins exclusif pour l'IANA.
La section 2.1 est la (longue) liste des devoirs qu'implique le rôle d'opérateur de registre. Il y a bien sûr le tenue du registre à proprement parler mais ce n'est pas tout. En voici une partie :
- Donner des avis sur les futurs RFC (concrètement, relire les sections IANA considerations à l'avance, pour voir si elles ne poseraient pas de problèmes insurmontables au registre).
- Suivre les RFC : l'opérateur du registre n'est pas censé déterminer la politique mais l'appliquer. Si un RFC dit que l'enregistrement dans tel registre se fait sans contrainte, l'opérateur du registre ne peut pas refuser un enregistrement, par exemple. Chaque registre a une politique d'enregistrement, expliquée dans le RFC correspondant (les règles générales figurent dans le RFC 5226).
- Bien indiquer dans chaque registre les références notamment le numéro du RFC qui normalise ce registre et pour chaque paramètre enregistré dans le registre, indiquer la source de ce paramètre et la date d'enregistrement.
- En cas de désaccord ou de problème, se tourner vers l'IESG, seule habilitée à trancher.
- Diffuser gratuitement les registres qui sont tous publics par défaut
(contrairement à ce qui se passe chez l'ultra-dinosaure
ISO). Un exemple est le registre de
DHCP, en
https://www.iana.org/assignments/bootp-dhcp-parameters/. - Maintenir les listes de diffusion spécifiées pour certains registres, par exemple lorsque l'enregistrement nécessite un examen par un expert, sous l'œil du public.
- Produire des rapports réguliers à destination de l'IAB, suivant le RFC 2860 mais aussi suivant l'accord supplémentaire qui l'a complété, et à destination de toute l'IETF. Aujourd'hui, cela se fait sous la forme de l'exposé IANA qu'il y a à chaque plénière de l'IETF. Ces rapports incluent des points comme les performances de l'opérateur du registre (délai de traitement, par exemple).
- Ne pas oublier que les droits de propriété intellectuelle sur ces registres sont gérés par l'IETF Trust (RFC 4748).
Après cette description des devoirs de l'opérateur du registre, la section 2 continue avec les devoirs des autres acteurs. En section 2.2, ceux de l'IAB, qui supervise l'opérateur du registre : l'IAB procède à la délégation formelle du registre, après que l'IAOC ait identifié les candidats. L'IAB décide, l'IAOC gère la relation avec l'opérateur.
En section 2.3, le rôle de l'IESG : celui-ci s'occupe de la partie technique, vérifier que les RFC comportent une bonne section IANA considerations, identifier les experts techniques si le RFC précise que l'enregistrement est précédé d'une évaluation technique (exemple : le RFC 5646, où l'enregistrement d'une langue dans le registre des langues est précédé d'une telle évaluation par un linguiste), répondre aux questions de l'opérateur du registre si celui-ci a un problème pratique.
En section 2.4, le rôle de l'IETF Trust (RFC 4748). Il gère la propriété intellectuelle de l'IETF donc est « propriétaire » du contenu des registres. Enfin, en section 2.5, le rôle de l'IAOC, bras administratif de l'IETF, qui est de gérer au quotidien les relations avec l'opérateur du registre.
Voilà, l'essentiel était là mais la section 3 rajoute quelques détails.
L'article seul
RFC 6120: Extensible Messaging and Presence Protocol (XMPP): Core
Date de publication du RFC : Mars 2011
Auteur(s) du RFC : Peter Saint-Andre (Cisco)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF xmpp
Première rédaction de cet article le 13 avril 2011
Jabber est le nom original, et XMPP le nom IETF d'un protocole d'échange d'informations encodées en XML, protocole surtout connu pour son utilisation dans la messagerie instantanée. Ce RFC 6120 met à jour la définition originale de XMPP, qui était dans le RFC 3920.
La messagerie instantanée est une application très populaire surtout chez les moins de dix ans. Elle permet d'échanger des messages sans prendre le temps de réfléchir et en général sans craindre qu'ils soient archivés (contrairement au courrier électronique où il faut réfléchir car ce que l'on écrit restera). Elle sert à de nombreux usages, discussions entre geeks, systèmes de surveillance avec notification des problèmes, etc. À l'exception du vénérable protocole IRC (décrit - insuffisamment - dans le RFC 2810 et suivants), les systèmes existants de messagerie instantanée sont tous basés sur des protocoles privés et fermés comme MSN. La normalisation qui fait le succès du courrier électronique n'a pas réussi ici.
D'où le vieux projet (RFC 2779) de développer un protocole moderne et ouvert, adapté à cette application. C'est ce qu'on fait les développeurs du protocole Jabber en 1999, projet adopté ultérieurement par l'IETF, rebaptisé XMPP en 2002 et normalisé désormais dans ce RFC. Notre RFC décrit un protocole généraliste, un RFC compagnon, le RFC 6121, normalise les aspects spécifiques à la messagerie instantanée. Il est donc objectivement incorrect de dire que XMPP est un protocole de messagerie instantanée (c'est en fait un protocole d'échange de données XML en temps réel) mais je suis sûr que mes lecteurs me pardonneront mes abus de langage. Ce RFC 6120 est très long (notons pour la petite histoire que dix RFC sont quand même encore plus longs, le détenteur du record étant le RFC 5661), avec plus de deux cents pages, mais il est surtout composé de longues listes de détails, les principes sont relativement simples. En dépit de la longueur de ce RFC, il ne spécifie pas tout XMPP de nombreuses extensions existent, certaines très populaires (comme la possibilité pour un client de créer un compte sur un serveur directement via XMPP) et elles sont en général décrites, non pas dans un RFC, mais dans les XEP (XMPP Extension Protocols) de la XMPP Standards Foundation.
Quels sont les principes de XMPP (section 1.3) ? Les données sont encodées en
XML (avec
quelques bémols notés en section 11 comme l'interdiction des
commentaires XML, ou des encodages autres qu'UTF-8), dans des
strophes (stanzas) qui sont des petits paquets
d'information. Citons Wikipédia : « Les stances
sont, dans les sujets graves et spirituels, ce que le couplet est dans
les chansons et la strophe dans les odes ». Ces strophes sont transmises sur une connexion TCP
(section 3) entre
client et serveur, ou bien entre serveur et serveur (la section 2.5
contient une très intéressante présentation des concepts « réseau » de
XMPP, notamment pour répondre à la question philosophique « XMPP
est-il pair-à-pair ? »). Les entités qui
communiquent (ce ne sont pas forcément des humains, Jabber ayant été
conçu pour permettre également la communication entre programmes) sont
identifiées par une adresse, qui a une forme syntaxique proche de
celle du courrier électronique. Par exemple, mon adresse XMPP est bortzmeyer@gmail.com.
XMPP, comme le courrier électronique, fonctionne par le connexion
de serveurs, chacun chargé d'un ou plusieurs domaines. Les clients se
connectent à un serveur (par exemple talk.l.google.com. pour
Google Talk, par exemple) et s'y authentifient, puis ils
transmettent les messages aux serveurs, qui se chargent de les
acheminer au serveur suivant (section 2.1 du RFC). Les serveurs sont
trouvés en utilisant les enregistrements SRV
(RFC 2782) du
DNS (section 3.2) par exemple, pour un client
de l'OARC :
% dig SRV _xmpp-client._tcp.dns-oarc.net ... ;; ANSWER SECTION: _xmpp-client._tcp.dns-oarc.net. 3223 IN SRV 0 0 5222 jabber.dns-oarc.net. ...
L'usage de SRV fait que le numéro de port utilisé n'est pas toujours le même mais 5222 (pour les communications de client à serveur) et 5269 (pour celles de serveur à serveur) sont les valeurs les plus courantes (section 14.7).
Les adresses (JID pour Jabber Identifier) sont décrites dans un autre document, le RFC 7622. Outre le classique
nom@domaine, elles peuvent comporter une
ressource, indiquée après la barre oblique (par
exemple bortzmeyer@gmail.com/AFNIC).
La représentation des données en XML est décrite dans la section
4. Un flux de données, un stream, est un
élément XML <stream>,
qui comporte une ou plusieurs strophes,
<stanza>. Il existe de nombreux types de
strophes (section 8) sans compter les messages d'erreur, décrits en 4.9. Voici un
exemple classique d'un échange (C étant le client et S le serveur), avec des strophes de type
message :
C: <message from='juliet@example.com'
to='romeo@example.net'
xml:lang='en'>
C: <body>Art thou not Romeo, and a Montague?</body>
C: </message>
S: <message from='romeo@example.net'
to='juliet@example.com'
xml:lang='en'>
S: <body>Neither, fair saint, if either thee dislike.</body>
S: </message>
Des exemples plus détaillés figurent en section 9.
Contrairement à beaucoup d'autres protocoles de messagerie instantanée, conçus uniquement pour jouer, XMPP, étant prévu aussi pour le travail, dispose de fonctions de sécurité très riches. La section 5 précise l'utilisation de TLS et la 6 celle de SASL. La section 13 détaille en profondeur tous les problèmes de sécurité de XMPP.
La section 8 détaille les types de strophes disponibles. Trois
types sont définis dans ce RFC, <message>,
<presence> et
<iq>. <message>,
dont la sémantique est décrite en section 8.2.1, transporte
un... message, tandis que <iq> (section
8.2.3) est une interrogation (Info / Query). Ces éléments XML ont un certain
nombre d'attributs par exemple l'attribut
to, sections 4.7.2 et 8.1.1, qui spécifie l'adresse du destinataire
(romeo@example.net dans la pemière strophe de
l'exemple ci-dessus). La syntaxe complète, exprimée en W3C
Schema, figure dans l'annexe A.
Du fait de l'utilisation de XML, des attributs standard comme
xml:lang sont possibles (section 8.1.5) et on
peut ainsi marquer un message en tchèque :
<presence from='romeo@example.net/orchard' xml:lang='en'>
<show>dnd</show>
<status>Wooing Juliet</status>
<status xml:lang='cs'>Dvořím se Julii</status>
</presence
L'annexe D résume les changements depuis le RFC 3920, qui avait été fait en 2004. Le format des adresses a été sorti pour être dans un document à part, le RFC 7622, le vieux protocole de rappel (dialback) a été retiré des RFC, TLS est devenu obligatoire (section 13.8, il reste à voir si ce sera mis en œuvre : au moment de la sortie de notre RFC, très peu de clients XMPP Android avaient TLS), et le reste est un certain nombre de clarifications et de corrections : il ne s'agit donc pas d'une nouvelle version du protocole, juste d'une évolution inspirée par l'expérience.
XMPP est aujourd'hui mis en œuvre dans de nombreux logiciels. C'est ainsi que le service de messagerie instantanée Google Talk utilise XMPP. Le client XMPP (qui est aussi un client de nombreux autres protocoles) le plus populaire sur Unix est sans doute Pidgin (ex-Gaim). Côté serveurs, le plus pittoresque (et pas le moins utilisé) est sans doute ejabberd, écrit en Erlang. Mais il y en a d'autres comme Movim.
Les développeurs liront avec intérêt le livre Programming Jabber qui explique comment utiliser Jabber/XMPP dans ses propres programmes.
L'article seul
Curiosité BGP du mois : annonces ultra-larges
Première rédaction de cet article le 10 avril 2011
L'Internet, on le sait, est une jungle pas
civilisée, pleine de dangers et où les chinois, les pédonazis, les
musulmans qui sont trop nombreux et les téléchargeurs de
céline-dion.mp3 commettent d'innombrables crimes
tous les jours. Notamment, il est bien connu que
BGP est souvent l'innocente victime de leurs
amusements. Ce protocole de routage est à la
fois la base technique de l'Internet et l'un de ses points les plus
fragiles. Curieusement, la plupart du temps, cette vulnérabilité n'a
pas de conséquence : l'Internet est très robuste et la réparation est
rapide. C'est seulement si on regarde bien qu'on s'aperçoit qu'il y a
effectivement plein de choses bizarres dans BGP, masquées par cette
robustesse. J'ai découvert très récemment le problème des annonces BGP
trop larges, lorsqu'un opérateur annonce un préfixe bien plus général
que ce qu'il devrait.
Le point de départ était le débogage d'un problème de
routage. Utilisant des services qui affichent les annonces
BGP reçues par divers routeurs, on s'aperçoit
qu'il y a une annonce pour 64.0.0.0/3... Elle est
faite par Global Crossing, avec le numéro
d'AS 3549. Pourquoi est-ce un problème ? Parce
qu'un /3, c'est un huitième de l'Internet ! Il n'est pas possible que
Global Crossing ait autant de clients (l'examen des bases du
RIR ARIN ne montre
d'ailleurs aucune allocation correspondante : et ce /3 couvre des RIR
différents). Cette annonce est donc clairement anormale.
Regardons-la plus en détail en utilisant l'excellent service RIS (Routing Information
Service) du RIPE-NCC : http://www.ris.ripe.net/dashboard/64.0.0.0/3. Que voit-on ?
- Que le problème a apparemment commencé vers le 23 mars (observé à l'époque mais RIS ne garde que les deux dernières semaines) et, qu'au jour de cet article, il continue.
- Que la visibilité de cette annonce est très faible : 1 %, dit le
RIS, qui l'affiche en rouge. C'est très certainement parce que la
plupart des pairs BGP sérieux jettent les annonces
X.Y.Z.T/Noù N < 8 (il n'y a jamais eu d'allocation IPv4 plus générales qu'un /8). En regardant sur les routeurs BGP de mon employeur (situé assez loin du cœur de l'Internet, donc ne voyant que des annonces déjà très filtrées), on ne voit pas64.0.0.0/3. - Mais cette annonce est quand même propagée. Le service de surveillance Cyclops l'a vue, relayée sur le chemin 3130 2914 3549 donc il y a quand même des gens qui transmettent un /3 sans hésiter.
- Comment se fait-il que Global Crossing n'ait pas réagi ? Ils ont été notifiés presque tout de suite mais on sait bien que ce genre de grosses sociétés ne lit pas son courrier.
Est-ce que ce genre de « détournement » (Global Crossing n'est pas
gestionnaire de ce /3 et n'a aucun droit de l'annoncer) a des
conséquences pratiques ? Probablement pas, et c'est sans doute ce qui
explique que Global Crossing n'ait pas réagi, et que le problème
continue. D'une part, cette annonce est largement filtrée et peu de
routeurs BGP la verront. D'autre part, même si elle atteint un
routeur, celui-ci aura presque à coup sûr une route plus spécifique
vers les destinations incluses dans ce /3. Le routage
IP privilégiant les routes plus spécifiques
(règle dite du longest match), ce seront elles qui
seront utilisées (à noter qu'on lit parfois que c'est BGP qui
privilégie les routes plus spécifiques mais c'est tout à fait faux :
BGP ne fait de sélection qu'entre deux préfixes de même longueur, sinon
il transmet les deux préfixes). Les seules destinations atteignables
via cette annonce sont celles qui correspondent à des trous dans
64.0.0.0/3. Elles sont sans doute rares.
Mais, si cette annonce ne sert pas à grand'chose (filtrée, ou bien ignorée suite à une route plus spécifique), pourquoi Global Crossing le fait ? Si on est d'esprit paranoïaque, on peut imaginer plein de choses désagréables (et, si Global Crossing était une entreprise chinoise, il n'y a pas de doute que Fox News ferait un article sur ces choses) mais le plus probable est qu'il s'agit simpement d'une erreur. Certes, sans ce filtrage des annonces < 8 et sans la règle IP de la route la plus spécifique, ces annonces trop larges poseraient un problème de sécurité : un méchant qui annoncerait un /1 pourrait capter la moitié du trafic de l'Internet. Mais, en pratique, il ne semble pas qu'il faille s'en inquiéter, le /3 de Global Crossing n'est pas allé très loin.
À noter qu'il peut s'agir d'une « demi-erreur ». Il est fréquent
qu'un opérateur annonce à ses clients directs (et uniquement à
ceux-ci) des routes très larges, notamment une route par défaut
(0.0.0.0/0). Comme il s'agit d'un lien privé, ce
n'est pas en soi un problème. Parfois, l'opérateur fait la même
annonce aux moniteurs des services comme le RIS (parce que c'est plus
simple de ne pas avoir de cas spécial) et l'information se
retrouve alors publique.
Est-ce que ce genre d'erreurs (des annonces d'un /3, /4, /5...)
arrive souvent ? Je n'ai pas trouvé de traces de discussion à ce
sujet. Comme pour beaucoup de trucs bizarres de l'Internet, tant qu'on
ne regarde pas de trop près, on ne voit pas le problème. Dès qu'on
cherche, on voit des annonces rigolotes comme celle de
Swisscom annonçant 80.0.0.0/5,
préfixe qui n'est pas enregistré tel quel dans la base du
RIPE-NCC et qui est certainement une autre erreur. Le
phénomène est donc sans doute fréquent mais ignoré.
Profitons au moins de ce problème pour résumer quelques méthodes
pour explorer les annonces BGP récentes. Même si on peut se connecter
sur les routeurs BGP de son entreprise et taper des show
route, on ne verra (sauf à travailler chez un
Tier-1 et se connecter sur
beaucoup de routeurs) qu'une partie de l'Internet. Il est donc
préférable de compter sur des services extérieurs, en général
accessibles via le Web.
Pour connaître ce qui existe en ce moment même, la meilleure source,
ce sont les « looking
glasses ». Une bonne liste figure en http://www.traceroute.org/#Looking%20Glass. (Attention, cette
liste change tout le temps et un certain nombre de liens sont cassés.)
L'un des « looking glasses » les plus connus et les
plus stables est celui de Hurricane Electric,
en http://bgp.he.net. On peut féliciter HE pour son
ouverture. Malheureusement, il fournit peu de détails sur l'annonce
BGP vue.
Pour connaître ce qui a existé dans le passé, les meilleures sources sont le RIS du RIPE-NCC et Cyclops.
Il y a aussi des services qui stockent tout et produisent de très intéressantes analyses mais ils ne vous laissent pas interroger votre préfixe de votre choix. BGPmon et Renesys sont deux bons exemples.
Comme l'Internet lui-même, cet article a nécessité la mobilisation de compétences différences donc merci à Olivier Perret pour avoir détecté et signalé le problème, à Sylvain Busson pour l'analyse des routeurs BGP, à Michel Py et Stéphane Chevalier pour leurs bonnes remarques.
L'article seul
Allez, encore une attaque par déni de service contre la racine du DNS ?
Première rédaction de cet article le 9 avril 2011
Un mystérieux problème a gêné un bon nombre de serveurs racine du DNS le mercredi 6 avril. Plusieurs serveurs ont complètement arrêté de répondre. Cela fait clairement penser à une attaque par déni de service coordonnée, comme cela arrive de temps en temps.
L'article complet
Le domaine de tête ivoirien, .CI, marche encore
Première rédaction de cet article le 9 avril 2011
Malgré la guerre civile en Côte d'Ivoire, le
domaine de tête national,
.CI, marche
toujours, grâce aux efforts des responsables du
.CI.
Je ne mentionne pas de nom dans cet article car la situation sur
place est toujours dangereuse. Mais j'ai eu une réunion téléphonique
avec un responsable du .CI
jeudi 7 avril et le DNS tient toujours. Un des
serveurs de noms situés à Abidjan, ns1.nic.ci, ne répond
plus :
% check_soa ci There was no response from ns1.nic.ci ns-ci.ripe.net has serial number 2010290693 There was no response from censvrns0001.ird.fr ns1.ird.fr has serial number 2010290693 phloem.uoregon.edu has serial number 2010290693 ns.nic.ci has serial number 2010290693 ci.hosting.nic.fr has serial number 2010290693
mais l'autre marche toujours et c'est sur lui que s'alimentent les serveurs secondaires (situés à l'IRD, à l'Université d'Oregon et à l'AFNIC). Même si ce serveur primaire s'arrêtait à son tour, le délai d'expiration (indiqué dans l'enregistrement SOA) est de 41 jours donc il n'y aurait pas d'urgence : les serveurs secondaires situés à l'étranger suffiraient à la tâche pendant cette période.
Le serveur en panne est (sans doute était) dans un local proche de l'immeuble de la RTI, qui était un objectif prioritaire des combattants, il a donc sans doute pris un obus sur la figure.
On ne peut pas vérifier : depuis sept jours, les personnes qui
s'occupent du .CI ne peuvent plus
sortir de chez eux. La réunion téléphonique était perturbée par les
cris des enfants en arrière-plan. Ils deviennent intenables, à être ainsi
bouclés. Certains services fonctionnent, plus ou moins
irrégulièrement, comme l'eau (non potable), l'électricité (pas tout le
temps) et l'Internet (presque tout le temps).
Le fait qu'il n'y ait pas d'urgence immédiate, et que le contact
soit maintenu avec les gérants du TLD font
toute la différence avec ce qui s'est passé en
Haïti. Dans ce pays, le délai avant l'expiration du domaine
allait être atteint, et les responsables du
.HT n'étaient pas
joignables. Ici, ce sont les ivoiriens qui nous demandent
explicitement de ne toucher à rien.
Pour comprendre ce que signifie être enfermé chez soi dans un pays en guerre, voir par exemple le témoignage de Fatou Keïta (on peut ignorer son point de vue pro-Ouattara : les partisans de Gbagbo et les neutres vivent la même chose).
L'article seul
RFC 6121: Extensible Messaging and Presence Protocol (XMPP): Instant Messaging and Presence
Date de publication du RFC : Mars 2011
Auteur(s) du RFC : P. Saint-Andre (Cisco
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF xmpp
Première rédaction de cet article le 7 avril 2011
Le protocole XMPP, normalisé dans le RFC 6120, est souvent cité comme protocole de messagerie instantanée. Mais c'est en fait plus compliqué que cela : XMPP lui-même ne fournit qu'un service minimum de routage d'éléments XML, les vrais services devant être développés au dessus de XMPP. C'est ainsi que les services de messagerie instantanée et de présence sont normalisé dans ce RFC, le 6121. Il succède au premier RFC sur ces services, le RFC 3921.
Le protocole de base, décrit dans le RFC 6120, transmet des éléments XML, les strophes (stanzas, j'ai choisi cette traduction parce qu'elle maintenait la métaphore musicale), en temps réel ou presque. Sur ce protocole de base, des tas de services sont possibles. La messagerie instantanée est le plus connu. Décrite dans le RFC 2779, elle a aujourd'hui éclipsé la plupart des autres usages de XMPP.
XMPP a été développé vers 1999 sous le nom de Jabber. Le nom de XMPP lui est venu lors de son adoption par l'IETF en 2002, les premiers RFC sont sortis en 2004 et ils viennent d'être mis à jour par la sortie des RFC 6120 (le protocole de base), RFC 6121 (la messagerie instantanée, qui remplace le RFC 3921) et RFC 7622 (le format des adresses). De son histoire, qui s'est déroulée partiellement en dehors de l'IETF, XMPP a gardé plusieurs extensions qui ne sont pas spécifiées dans un RFC, mais dans des documents connus sous le nom de XEP (XMPP Extension Protocols) comme par exemple XEP-0160 pour le stockage des strophes si elles ne peuvent pas être délivrées immédiatement.
Qu'est-ce que la messagerie instantanée ? Vu de XMPP, ce sont une liste de connaissances (le carnet ou roster) et la possibilité d'envoyer entre ces connaissances des messages relativement courts, de manière quasi-instantanée. Contrairement au courrier électronique, dont la caractéristique principale est d'être asynchrone (on peut envoyer un message à quelqu'un qui est en vacances et qui le lira au retour), la messagerie instantanée (ou IM pour Instant Messaging ou chat ou clavardage si on veut parler comme l'Académie française) est synchrone : un message perd beaucoup de son intérêt s'il n'est pas lu tout de suite. Cela implique donc de gérer la présence : les correspondants ont besoin de savoir si le type en face est là ou pas. Comme cette information peut être considérée comme confidentielle, la présence n'est communiquée qu'à ceux qu'on a accepté comme correspondants (buddies, ce qu'un utilisateur de Facebook traduirait sans doute par ami).
Donc, les quatre fonctions :
- Gérer le carnet,
- Échanger des messages avec ses correspondants,
- Informer de sa présence,
- Gérer la liste des gens qu'on informe de sa présence.
résument très bien le RFC 2779, qui fut le cahier des charges de XMPP.
La section 1.4 de notre RFC détaille les dites fonctions. Le transport des données, la connexion au serveur, l'authentification, etc, sont des choses très importantes mais elles sont absentes de ce RFC, puisqu'elles sont déjà couvertes dans le RFC 6120. Pour résumer ce dernier : un client XMPP se connecte à un serveur XMPP et s'authentifie. La session XMPP ainsi ouverte (et qui dure typiquement des heures, voire des jours) permet de transmettre des strophes (l'élément de base d'une conversation XMPP), ces strophes pouvant être des messages lisibles par un humain (« Ça va ? Tu viens bouffer ? ») comme des messages de service comme ceux informant de la présence d'un correspondant. (Il y a aussi des messages entre serveurs, pour qu'un utilisateur puisse parler à un client d'un autre service. Contrairement à Facebook ou MSN, XMPP est un protocole Internet, donc ouvert) Une session typique est :
- Récupération de son carnet, stocké sur le serveur,
- Envoi de l'information de présence (« Je suis là »),
- Échange de messages, mises à jour du carnet, réception des informations de présence des potes, etc, tout au long de la session.
- Fin de la session quand on va se coucher le soir.
Notons que les utilisateurs ne sont pas forcément des humains, ils peuvent être des bots.
Terminées, les généralités, place au protocole. Ce RFC est très long (cent seize pages), mais la longueur vient surtout du nombre de types de messages possible, pas tellement de la complexité du protocole. Je ne vais pas détailler chaque fonction, seulement mettre en évidence quelques points.
La plus importante fonction est évidemment l'échange de messages,
donc commençons par elle (alors que le RFC fait passer la gestion du
carnet et celle de la présence d'abord). Elle figure en section 5. Le
principe est que le client XMPP transmet au serveur des éléments
<message>. Ceux-ci sont délivrés à un autre
client connecté au même serveur, ou bien routés vers un autre
serveur. XMPP fonctionne donc par push, pas par
pull : l'information doit être délivrée tout de
suite (la section 8.5.2.1.1 précise ce que doit faire un serveur si un
serveur distant n'est pas disponible de suite).
L'usage le plus courant est sous la forme d'une session de
discussion où plusieurs messages vont se suivre. Dans ces cas,
l'élément <message> reçoit un attribut
type dont la valeur est
chat (section 5.2.2). Voici un exemple de message (vous
noterez vite que tous les examples XMPP sont tirés de
Roméo et Juliette ; je n'ai pas
traduit le texte, que j'ai laissé dans la langue originale, celle de
Shakespeare, pas celle des amants de
Vérone, qui s'échangeaient plutôt des mots doux
en italien).
<message
from='juliet@example.com/balcony'
id='ktx72v49'
to='romeo@example.net'
type='chat'
xml:lang='en'>
<body>Art thou not Romeo, and a Montague?</body>
</message>
Tiens, justement, question langues, XMPP permet d'avoir plusieurs versions du même message, en des langues différentes (section 5.2.3). Voici un exemple en anglais et en tchèque :
<message
from='juliet@example.com/balcony'
id='z94nb37h'
to='romeo@example.net'
type='chat'
xml:lang='en'>
<body>Wherefore art thou, Romeo?</body>
<body xml:lang='cs'>
PročeŽ jsi ty, Romeo?
</body>
</message>
La section 3 explique le mécanisme de gestion de la présence. Celle-ci n'est transmise qu'aux abonnés, pas au public. Pour s'abonner, on envoie une demande (ici de Roméo vers Juliette) :
<presence id='xk3h1v69'
to='juliet@example.com'
type='subscribe'/>
Cette demande est en général présentée à l'utilisateur pour qu'il l'approuve (section 3.1.3). Le serveur peut alors répondre :
<presence from='juliet@example.com'
id='xk3h1v69'
to='romeo@example.net'
type='subscribed'/>
Une fois qu'on est approuvé, un peut recevoir des informations de présence (section 4). Celles-ci indiquent si l'entité (la personne ou le programme mais, en général, les programmes ne s'absentent pas) est disponible ou pas. Les clients XMPP l'affichent alors par exemple en vert si le contact est disponible et en rouge autrement, ou bien avec du texte comme online et offline. Donc, lorsque je lance mon client XMPP, ou bien lorsque je change manuellement l'état (le menu en bas de la fenêtre des contacts, avec Pidgin), le client XMPP envoie au serveur :
<presence/>
et celui-ci le retransmet aux abonnés (section 4.2.2). Le client peut aussi marquer explicitement qu'il ne veut pas être dérangé :
<presence type='unavailable'/>
information à laquelle on peut ajouter une explication :
<presence type='unavailable' xml:lang='fr'>
<status>Je suis en vacances.</status>
</presence>
La section 2 concerne la gestion du carnet (roster). Le serveur le stocke et le transmet à l'utilisateur, ce qui permet à celui-ci de disposer de son carnet depuis n'importe quelle machine (rappelons que XMPP est un protocole ouvert et que n'importe qui peut installer un serveur : celui-ci n'est donc pas forcément une grosse entreprise anonyme dans le nuage, il peut être géré par votre entreprise, votre association, par un copain ou par vous-même). Cela ne se fait évidemment qu'après authentification (la liste de mes copains ne regarde que moi...). À noter qu'un des changements depuis le RFC 3921 est que le carnet peut désormais être stocké sur un autre serveur que celui où on se connecte.
En gros, pour avoir le carnet, le client envoie la strophe :
<iq from='juliet@example.com/balcony'
id='bv1bs71f'
type='get'>
<query xmlns='jabber:iq:roster'/>
</iq>
et le serveur lui transmet (ici, seulement trois correspondants, pour ne pas rendre cet article trop long) :
<iq id='bv1bs71f'
to='juliet@example.com/balcony'
type='result'>
<query xmlns='jabber:iq:roster' ver='ver11'>
<item jid='romeo@example.net'
name='Romeo'
subscription='both'>
<group>Friends</group>
</item>
<item jid='mercutio@example.com'
name='Mercutio'
subscription='from'/>
<item jid='benvolio@example.net'
name='Benvolio'
subscription='both'/>
</query>
</iq>
Dans la liste d'élements <item> renvoyés,
l'attribut jid contient l'adresse XMPP formelle (JID =
Jabber ID, voir le RFC 7622)
et name un identificateur plus
convivial. L'élément <subscription> indique
si le correspondant est abonné à notre présence, nous à la sienne, ou
bien les deux. Le schéma XML complet figure en
annexe D, en utilisant le langage XSD.
La section 2 couvre également le cas des mises à jour du carnet (le
client ajoute ces mises à jour dans son
<query>). Notez que XMPP peut aussi utiiser
des enregistrements au format vCard (RFC 6350) pour remplir le carnet (annexe C et XEP-0054). Un serveur comme ejabberd gère cette possibilité.
La section 7 fournit un exemple plus détaillé d'une session complète, avec quatre utilisateurs. Lecture nécessaire si vous voulez comprendre tous les détails de XMPP.
Comme nous vivons dans un monde cruel (regardez ce qui est arrivé de tragique à Roméo et Juliette), XMPP a besoin d'une section sur la sécurité, la numéro 11. Elle traite des points comme l'importance de ne pas répondre aux demandes de présence si le demandeur n'est pas autorisé (soit explicitement, soit via une politique générale, par exemple l'autorisation de tous pour tous dans une même entreprise).
Qu'est-ce qui a changé depuis le RFC 3921 ? L'annexe E résume les principales différences. La plupart sont très pointues et ne se rencontrent pas tous les jours.
XMPP étant un protocole ancien et éprouvé, il est très largement déployé et on trouve de nombreuses implémentations :
- Des serveurs comme ejabberd ou jabberd, si on veut créer son propre service,
- Des clients comme Pidgin ou Empathy sur Unix (j'ai écrit un article spécifique pour les clients sur Android),
- Des serveurs gratuits comme jabber.org ou comme Google Talk (oui, c'est tout simplement du XMPP et un abonné de Google Talk peut interagir avec n'importe quel autre abonné d'un autre service XMPP).
Et enfin, si vous voulez m'écrire, mes adresses XMPP sont
bortzmeyer@dns-oarc.net pour le travail et
bortzmeyer@gmail.com (du Google Talk) pour le reste.
L'article seul
Exposé sur la transition IPv6 à Grenoble le 12 avril
Première rédaction de cet article le 6 avril 2011
Dernière mise à jour le 11 mai 2011
Le 12 avril, à Grenoble, l'association GUILDE organisait une rencontre sur le thème d'IPv6 et notamment des mécanismes de transition vers IPv6 et de coexistence avec IPv4.
J'ai présenté le sujet, au programme 6rd, NAT64 (dont on attend les RFC d'un moment à l'autre), DS-Lite, etc, en essayant d'être concret et pratique. À noter que, depuis cet exposé, un RFC a été publié qui est entièrement consacré à ce sujet, l'examen des mécanismes de transition : RFC 6180.
Voici mes transparents :
- Version adaptée à l'écran,
- Version adaptée à l'impression,
- Source en LaTeX/Beamer.
Tous les détails (par exemple l'enregistrement audio) sont sur le site de GUILDE. Le même enregistrement audio est disponible sur Wikimedia Commons. L'enregistrement vidéo est chez Framasoft.
L'article seul
RFC 6126: The Babel Routing Protocol
Date de publication du RFC : Avril 2011
Auteur(s) du RFC : J. Chroboczek (PPS, University of Paris 7)
Expérimental
Première rédaction de cet article le 6 avril 2011
La recherche sur les protocoles de routage ne désarme pas, motivée à la fois par les avancées de la science et par les nouvelles demandes (par exemple pour les réseaux ad hoc). Ainsi Babel est un nouveau protocole de routage, de la famille des protocoles à vecteurs de distance, qui vise notammment à réduire drastiquement les probabilités de boucle. (Depuis, Babel a été normalisé dans le RFC 8966.)
Il y a en effet deux familles de protocole de routage, ceux à vecteurs de distance comme l'ancêtre RIP et ceux à états des liens comme OSPF (RFC 2328). Ce dernier est aujourd'hui bien plus utilisé que RIP, et à juste titre. Mais les problèmes de RIP n'ont pas forcément la même ampleur chez tous les membres de sa famille, et les protocoles à vecteurs de distance n'ont pas dit leur dernier mot.
Babel s'inspire de protocoles de routage plus récents comme DSDV. Il vise à être utilisable, à la fois sur les réseaux classiques, où le routage se fait sur la base du préfixe IP et sur les réseaux ad hoc, où il n'y a typiquement pas de regroupement par préfixe, où le routage se fait sur des adresses IP « à plat » (on peut dire que, dans un réseau ad hoc, chaque nœud est un routeur).
L'un des principaux inconvénients du bon vieux protocole RIP est sa capacité à former des boucles lorsque le réseau change de topologie. Ainsi, si un lien entre les routeurs A et B casse, A va envoyer les paquets à un autre routeur C, qui va probablement les renvoyer à A et ainsi de suite (le champ « TTL » pour IPv4 et « Hop limit » dans IPv6 a précisement pour but d'éviter qu'un paquet ne tourne sans fin). Babel, lui, évitera les boucles la plupart du temps mais, en revanche, il ne trouvera pas immédiatement la route optimale entre deux points. La section 1.1 du RFC spécifie plus rigoureusement les propriétés de Babel.
Autre particularité de Babel, les associations entre deux machines pourront se faire même si elles utilisent des paramètres différents (par exemple pour la valeur de l'intervalle de temps entre deux « Hello » ; cf. l'annexe B pour une discussion du choix de ces paramètres). Le RFC annonce ainsi que Babel est particulièrement adapté aux environnements « sans-fil » où certaines machines, devant économiser leur batterie, devront choisir des intervalles plus grands.
Je l'ai dit, rien n'est parfait en ce bas monde, et Babel a des limites, décrites en section 1.2. D'abord, Babel envoie périodiquement toutes les informations dont il dispose, ce qui, dans un réseau stable, mène à un trafic total plus important que, par exemple, OSPF (qui n'envoie que les changements). Ensuite, Babel a des mécanismes d'attente lorsqu'un préfixe disparait, qui s'appliquent aux préfixes plus généraux. Ainsi, lorsque deux préfixes deviennent agrégés, l'agrégat n'est pas joignable immédiatement. Notre RFC a le statut « Expérimental » et l'usage découvrira peut-être d'autres faiblesses.
Comment Babel atteint-il ses merveilleux objectifs ? La section 2 détaille les principes de base du protocole, la 3 l'échange de paquets et la 4 l'encodage d'iceux. Commençons par les principes. Babel est fondé sur le bon vieil algorithme de Bellman-Ford, tout comme RIP. Tout lien entre deux points A et B a un coût (qui n'est pas forcément un coût monétaire, c'est un nombre qui a la signification qu'on veut, cf. section 3.5.2). Le coût est additif (la somme des coûts d'un chemin complet faisant la métrique du chemin, section 2.1 et annexe A), ce qui veut dire que Métrique(A -> C) - pour une route passant par B - = Coût(A -> B) + Coût(B -> C). L'algorithme va essayer de calculer la route ayant la métrique le plus faible.
Un nœud Babel garde trace de ses voisins nœuds en envoyant
périodiquement des messages Hello et en les
prévenant qu'ils ont été entendus par des messages
IHU (I Heard You). Le contenu
des messages Hello et IHU
permet de déterminer le coût.
Pour chaque source (d'un préfixe, pas d'un paquet), le nœud garde trace de la métrique vers cette source (lorsqu'un paquet tentera d'atteindre le préfixe annoncé) et du routeur suivant (next hop). Au début, évidemment la métrique est infinie et le routeur suivant indéterminé. Le nœud envoie à ses voisins les routes qu'il connait. Si celle-ci est meilleure que celle que connait le voisin, ce dernier l'adopte (si la distance était infinie - route inconnue, toute route sera meilleure).
L'algorithme « naïf » ci-dessus est ensuite amélioré de plusieurs façons : envoi immédiat de nouvelles routes (sans attendre l'émission périodique), mémorisation, non seulement de la meilleure route mais aussi de routes alternatives, pour pouvoir réagir plus vite en cas de coupure, etc.
La section 2.3 rappelle un problème archi-connu de l'algorithme de
Bellman-Ford : la facilité avec laquelle des boucles se forment. Dans
le cas d'un réseau simple comme celui-ci A annonce une route de métrique 1
vers S, B utilise donc A comme routeur suivant, avec une métrique de 2. Si le lien entre S (S = source de
l'annonce) et A
casse
comme B continue
à publier une route de métrique 2 vers S, A se met à envoyer les paquets à
B. Mais B les renvoie à A, créant ainsi une boucle. Les annonces
ultérieures ne résolvent pas le problème : A annonce une route de métrique
3, passant par B, B l'enregistre et annonce une route de métrique 4
passant par A, etc. RIP résout le
problème en ayant une limite arbitraire à la métrique, limite qui finit par
être atteinte et stoppe la boucle (méthode dite du « comptage à l'infini »).
Cette méthode oblige à avoir une limite très basse pour la métrique. Babel a une autre approche : les mises à jour ne sont pas forcément acceptées, Babel teste pour voir si elles créent une boucle (section 2.4). Toute annonce est donc examinée au regard d'une condition, dite « de faisabilité ». Plusieurs conditions sont possibles. Par exemple, BGP utilise la condition « Mon propre numéro d'AS n'apparaît pas dans l'annonce. ». (Cela n'empêche pas les micro-boucles, boucles de courte durée en cas de coupure, cf. RFC 5715.) Une autre condition, utilisée par DSDV et AODV, repose sur l'observation qu'une boucle ne se forme que lorsqu'une annonce a une métrique supérieure à la métrique de la route qui a été retirée. En n'acceptant que les annonces qui diminuent la métrique, on peut donc éviter les boucles. Babel utilise une règle un peu plus complexe, empruntée à EIGRP, qui tient compte de l'histoire des annonces faites par le routeur.
Comme il n'y a pas de miracles en routage, cette idée de ne pas accepter n'importe quelle annonce de route a une contrepartie : la famine. Celle-ci peut se produire lorsqu'il existe une route mais qu'aucun routeur ne l'accepte (section 2.5). EIGRP résout le problème en « rédémarrant » tout le réseau (resynchronisation globale des routeurs). Babel, lui, emprunte à DSDV une solution moins radicale, en numérotant les annonces, de manière strictement croissante, lorsqu'un routeur détecte un changement dans ses liens. Une route pourra alors acceptée si elle est plus récente (si elle a un numéro de séquence plus élevé).
À noter que tout se complique s'il existe plusieurs routeurs qui annoncent originellement la même route (section 2.7 ; un exemple typique est la route par défaut, annoncée par tous les routeurs ayant une connexion extérieure). Babel gère ce problème en associant à chaque préfixe l'identité du routeur qui s'est annoncé comme origine et considère par la suite ces annonces comme distinctes, même si le préfixe est le même. Conséquence : Babel ne peut plus garantir qu'il n'y aura pas de boucle (Babel essaie de construire un graphe acyclique mais l'union de plusieurs graphes acycliques n'est pas forcément acyclique). Par contre, il pourra détecter ces boucles a posteriori et les éliminer plus rapidement qu'avec du comptage vers l'infini.
Voilà pour les principes. Et le protocole ? La section 3 le décrit. Chaque routeur a une identité sur huit octets (le plus simple est de prendre l'adresse MAC d'une des interfaces). Les messages sont envoyés dans des paquets UDP et encodés en TLV. Le paquet peut être adressé à une destination unicast ou bien multicast.
Un routeur Babel doit se souvenir d'un certain nombre de choses (section 3.2) :
- Le numéro de séquence, qui croît strictement,
- La liste des interfaces réseau où parler le protocole,
- La liste des voisins qu'on a entendus,
- La liste des sources (routeurs qui ont été à l'origine de l'annonce d'un préfixe). Elle sert pour calculer les critères d'acceptation (ou de rejet) d'une route. Babel consomme donc plus de mémoire que RIP, qui ne connait que son environnement immédiat, alors qu'un routeur Babel connaît tous les routeurs du réseau.
- Et bien sûr la table des routes, celle qui, au bout du compte, sera utilisée pour la transmission des paquets.
Les messages Babel ne bénéficient pas d'une garantie de délivrance (c'est de l'UDP, après tout), mais un routeur Babel peut demander à ses voisins d'accuser réception (section 3.3). La décision de le demander ou pas découle de la politique locale de chaque routeur. Si un routeur ne demande pas d'accusé de réception, l'envoi périodique des routes permettra de s'assurer que, au bout d'un certain temps, tous les routeurs auront toute l'information. Les accusés de réception peuvent toutefois être utiles en cas de mises à jour urgentes dont on veut être sûr qu'elles ont été reçues. (L'implémentation actuelle de Babel ne les utilise pas.)
Comment un nœud Babel trouve t-il ses voisins ? La section 3.4 décrit ce mécanisme. Les voisins sont détectés par les messages Hello qu'ils émettent. Les messages IHU (I Heard You) envoyés en sens inverse permettent notamment de s'assurer que le lien est bien bidirectionnel.
Les détails de la maintenance de la table de routage figurent en section 3.5. Chaque mise à jour envoyée par un nœud Babel est un quintuplet {préfixe IP, longueur du préfixe, ID du routeur, numéro de séquence, métrique}. Chacune de ces mises à jour est évaluée en regard des conditions de faisabilité : une distance de faisabilité est un doublet {numéro de séquence, métrique} et ces distances sont ordonnées en comparant d'abord le numéro de séquence (numéro plus élevée => distance de faisabilité meilleure) et ensuite la métrique (où le critère est inverse). Une mise à jour n'est acceptée que si sa distance de faisabilité est meilleure.
Si la table des routes contient plusieurs routes vers un préfixe donné, laquelle choisir et donc réannoncer aux voisins (section 3.6) ? La politique de sélection n'est pas partie intégrante de Babel. Plusieurs mises en œuvre de ce protocole pourraient faire des choix différents. Les seules contraintes à cette politique sont qu'il ne faut jamais réannoncer les routes avec une métrique infinie (ce sont les retraits, lorsqu'une route n'est plus accessible), ou les routes infaisables (selon le critère de faisabilité cité plus haut). Si les différents routeurs ont des politiques différentes, cela peut mener à des oscillations (routes changeant en permanence) mais il n'existe pas à l'heure actuelle de critères scientifiques pour choisir une bonne politique. On pourrait imaginer que le routeur ne garde que la route avec la métrique le plus faible, ou bien qu'il privilégie la stabilité en gardant la première route sélectionnée, ou encore qu'il prenne en compte des critères comme la stabilité du routeur voisin dans le temps. En attendant les recherches sur ce point, la stratégie conseillée est de privilégier la route de plus faible métrique, en ajoutant un petit délai pour éviter de changer trop souvent.
Une fois le routeur décidé, il doit envoyer les mises à jour à ses voisins (section 3.7). Ces mises à jour sont transportées dans des paquets multicast (mais peuvent l'être en unicast). Les changements récents sont transmis immédiatement, mais un nœud Babel transmet de toute façon la totalité de ses routes à intervalles réguliers. Petite optimisation : les mises à jour ne sont pas transmises sur l'interface réseau d'où la route venait, mais uniquement si on est sûr que ladite interface mène à un réseau symétrique (un Ethernet filaire est symétrique mais un lien WiFi ad hoc ne l'est pas forcément).
Un routeur Babel peut toujours demander explicitement des annonces de routes à un voisin (section 3.8). Il peut aussi demander une incrémentation du numéro de séquence, au cas où il n'existe plus aucune route pour un préfixe donné (problème de la famine, section 3.8.2.1).
La section 4 spécifie l'encodage des messages Babel sur le
réseau. C'est un paquet UDP, envoyé à une
adresse multicast (FF02:0:0:0:0:0:1:6 ou 224.0.0.111) ou bien unicast,
avec un TTL de 1 (puisque les messages Babel
n'ont jamais besoin d'être routés), et un port
source et destination de 6696. En IPv6, les
adresses IP de source et de destination unicast sont
link-local et en IPv4 des
adresses du réseau local.
Les données envoyées dans le message sont typées et la section 4.1
liste les types possibles, par exemple interval, un
entier de 16 bits qui sert à représenter des durées en centisecondes
(rappelez-vous que, dans Babel, un routeur informe ses voisins de ses
paramètres temporels, par exemple de la fréquence à laquelle il envoie
des Hello). Plus complexe est le type
address, puisque Babel permet d'encoder les
adresses par différents moyens (par exemple, pour une adresse IPv6
link-local, le préfixe
fe80::/64 peut être omis).
Ensuite, ces données sont mises dans des
TLV, eux-même placés derrière l'en-tête Babel,
qui indique un nombre magique (42...) pour identifier un paquet Babel,
un numéro de version (aujourd'hui 2) et la longueur du message. (La
fonction babel_print_v1 dans le
patch de tcpdump est un bon
moyen de découvrir les différents types et leur rôle.) Chaque TLV, comme son nom l'indique, comprend un
type (entier sur huit bits), une longueur et une valeur, le
corps, qui peut comprendre plusieurs champs
(dépendant du type). Parmi
les types existants :
- 0 et 1, qui doivent être ignorés (ils servent si on a besoin d'aligner les TLV),
- 2, qui indique une demande d'accusé de réception, comme le Echo Request d'ICMP (celui qui est utilisé par la commande ping). Le récepteur doit répondre par un message contenant un TLV de type 3.
- 4, qui désigne un message
Hello. Le corps contient notamment le numéro de séquence actuel du routeur. Le type 5 désigne une réponse auHello, le IHU, et ajoute des informations comme le coût de la liaison entre les deux routeurs ou comme la liste des voisins entendus (les amateurs d'OSPF noteront que, dans ce protocole, la liste des voisins détectés apparaît dans leHello, ce qui augmente sa taille). - 6 sert pour transmettre l'ID du routeur.
- 7 et 8 servent pour les routes elles-mêmes. 7 désigne le routeur
suivant qui sera utilisé (next hop) pour les routes
portées dans les TLV de type 8. Chaque TLV
Update(type 8) contient notamment un préfixe (avec sa longueur), un numéro de séquence, et une métrique. - 9 est une demande explicite de route (lorsqu'un routeur n'a plus de route vers un préfixe donné ou simplement lorsqu'il est pressé et ne veut pas attendre le prochain message). 10 est la demande d'un nouveau numéro de séquence.
Quelle est la sécurité de Babel ? La section 6 dit franchement
qu'elle est à peu près inexistante. Un méchant peut annoncer les
préfixes qu'il veut, avec une faible métrique pour être sûr d'être
sélectionné, afin d'attirer tout le trafic. Des extensions futures à
Babel (par exemple telles que spécifiées dans le projet
draft-ietf-ospf-auth-trailer-ospfv3) permettront peut-être de signer les messages mais ce n'est pas
encore fait. (Notons que, en matière de routage, la signature ne
résout pas tout : c'est une chose d'authentifier un voisin, une autre
de vérifier qu'il est autorisé à annoncer ce préfixe.)
En IPv6, une protection modérée est fournie par le fait que les adresses source et destination sont locales au lien. Comme les routeurs IPv6 ne sont pas censés faire suivre les paquets ayant ces adresses, cela garantit que le paquet vient bien du réseau local.
Vous pourrez trouver plus d'informations sur Babel en lisant le RFC, ou bien sur la page Web officielle.
Qu'en est-il des mises enœuvre de ce protocole ? Il existe une
implémentation d'exemple, assez éprouvée pour être disponible en
paquetage dans plusieurs systèmes, comme babeld dans
Debian ou dans OpenWrt, plateforme très
souvent utilisée pour des routeurs libres (cf. https://dev.openwrt.org/browser/packages/net/babel). Si vous
voulez écrire votre implémentation, l'annexe C contient plusieurs conseils utiles,
accompagnés de calculs, par exemple sur la consommation mémoire et
réseau. Le RFC proclame que Babel est un protocole relativement simple
et, par exemple, l'implémentation de référence
contient environ 7300 lignes de C.
Néanmoins, cela peut être trop, une fois compilé, pour des objets (le RFC cite les fours à micro-ondes...) et l'annexe C décrit donc des sous-ensembles raisonnables de Babel. Par exemple, une mise en œuvre passive pourrait apprendre des routes, sans rien annoncer. Plus utile, une mise en œuvre « parasite » n'annonce que la route vers elle-même et ne retransmet pas les routes apprises. Ne routant les paquets, elle ne risquerait pas de créer des boucles et pourrait donc omettre certaines données, comme la liste des sources. (Le RFC liste par contre ce que la mise en œuvre parasite doit faire.)
Toujours côté programmes, il existe un patch à tcpdump pour afficher les paquets Babel et un en cours pour Wireshark. On commence à voir des traces Babel sur pcapr.net.
Si vous voulez approfondir la question des protocoles de routage, une excellente comparaison a été faite par David Murray, Michael Dixon et Terry Koziniec dans « An Experimental Comparison of Routing Protocols in Multi Hop Ad Hoc Networks » où ils comparent Babel (qui l'emporte largement), OLSR (RFC 7181) et Batman (ce dernier est dans le noyau Linux officiel). Notez aussi que l'IETF a un protocole standard pour ce problème, RPL, décrit dans le RFC 6550.
Merci beaucoup à Juliusz Chroboczek pour sa relecture et ses nombreux avis.
L'article seul
Faut-il remplacer régulièrement les clés DNSSEC ?
Première rédaction de cet article le 5 avril 2011
Je ne l'ai pas fait exprès mais une bonne partie des discussions qui ont suivi mon exposé à la conférence SATIN le 4 avril, ont porté sur la question qui figure en titre, le remplacement des clés (key rollover).
En effet, DNSSEC repose sur des clés cryptographiques qui vont par paire, une privée et une publique. Le conseil souvent donné dans les cours et formations DNSSEC est de changer ces clés régulièrement. Pourquoi ? Et est-ce vraiment une bonne idée ?
Il y a plusieurs raisons possibles pour changer les clés assez souvent (du genre, tous les deux mois pour une clé de 1024 bits) :
- Pour des raisons cryptographiques : le plus longtemps la clé reste en service, le plus de temps les cryptanalystes auront à leur disposition pour la casser (d'où le lien entre la taille de la clé et l'intervalle de remplacement).
- Pour des raisons opérationnelles : on aura toujours besoin de changer des clés dans certains cas (par exemple parce qu'on découvre soudainement qu'une clé privée a été copiée par un méchant ou simplement par précaution parce qu'un membre important de l'équipe est parti, et qu'on préfère changer le matériel cryptographique auquel il avait accès ; n'oubliez pas que les clés DNSSEC n'expirent pas toutes seules). L'idée est que, si on ne fait des remplacements que contraints et forcés, les procédures ne seront pas réellement testées, et les employés ne sauront pas vraiment quoi faire. Au contraire, si le remplacement est de la routine, les remplacements forcés passeront comme une lettre à la Poste.
Il y a aussi des raisons de ne pas changer les clés systématiquement et souvent :
- Chaque changement est une modification d'une donnée importante, et peut déclencher des bogues dans les logiciels. Ce n'est pas juste de la paranoïa, c'est ce qui est arrivé à .FR (voir aussi la discussion sur la liste dns-operations).
- Faire des remplacements de clés complique l'ensemble du système et peut décourager les administrateurs réseau de mettre en place DNSSEC.
Alors, quel est le consensus sur ce point ? Eh bien justement, il n'y a pas eu de consensus, si la majorité des participants à la conférence SATIN semblait pencher pour le remplacement fréquent et « gratuit », une minorité n'était pas d'accord. Le premier point de discussion portait sur la validité de l'argument cryptographique : compte-tenu de l'état de la sécurité du DNS aujourd'hui (très bas), se préoccuper d'un éventuel cassage d'une clé RSA de 1024 bits est-il vraiment pertinent ? De fait, l'argument cryptographique n'a été défendu par personne.
L'autre argument, l'opérationnel, est plus sérieux : il est clair qu'une procédure qui n'existe que sur papier, qui n'a jamais été testée, ne vaut rien. La crainte des « remplaceurs » (qui plaident pour des remplacements fréquents, afin que l'équipe d'exploitation ne perde pas la main) est que, en l'absence de ces remplacements fréquents, le jour où il y aura un problème nécessitant un remplacement d'urgence, personne ne sache réellement faire.
L'argument était contesté sur deux bases :
- Les remplacements d'urgence (face à une compromission d'une clé privée, par exemple, ou suite à une panne physique d'un HSM) ne sont pas comparables aux changements réguliers, qui peuvent être automatisés. Ces changements réguliers ne garantissent donc pas que tout se passera bien lors d'un remplacement d'urgence.
- Le DNS est un système vital, avec lequel on ne peut pas jouer juste pour s'entraîner. Pour habituer le pilote de ligne à voler avec un moteur en panne, on ne coupe pas un réacteur de l'avion à chaque vol !
Dans le cas de l'avion, la solution est la multiplication d'exercices sur simulateur. Transposé à l'informatique, cela veut dire des exercices réguliers sur un banc de test. Ce banc de test se comportera-t-il toujours comme la réalité ? C'est le reproche que font les remplaceurs.
Bref, pas d'accord encore. Au minimum, si on remplace souvent les clés, il faut le faire avec un logiciel qui marche (je suggère OpenDNSSEC). Mon étude présentée à SATIN montrait que les problèmes liés aux remplacements de clés sont toujours fréquents en pratique.
L'article seul
Où doit se faire la validation DNSSEC ?
Première rédaction de cet article le 5 avril 2011
Une question fréquemment posée par les débutants en DNSSEC est : qui doit faire la validation, c'est-à-dire vérifier les signatures cryptographiques ? Le résolveur habituel (typiquement celui du FAI) ? Ou bien un logiciel (par exemple le navigateur Web) situé sur le poste de travail de l'utilisateur ? La question est revenue sur le tapis lors de la conférence SATIN hier.
Le problème avait été soulevé par Wesley Hardaker lors d'un bref, mais excellent, exposé sur les tests des résolveurs DNS, pour déterminer s'ils pouvaient servir de relais pour DNSSEC. Mais un peu de contexte d'abord : DNSSEC permet au titulaire d'une zone DNS de signer celle-ci cryptographiquement. Pour que cela serve à quelque chose, une entité, le validateur, doit vérifier ces signatures (et leur lien avec une clé connue). Plusieurs logiciels savent faire cela (en logiciel libre, les résolveurs BIND, Unbound, les bibliothèques libval ou ldns, etc).
Quel est le meilleur endroit pour faire la validation. A priori, plusieurs endroits sont possibles :
- Dans le résolveur DNS existant, géré par le
FAI ou par le service informatique du réseau
local. Avantages : ce logiciel existe déjà, il est sans doute déjà
capable de valider DNSSEC, il suffit d'activer cette fonction (dans
BIND :
dnssec-validation yes;), il n'y a ainsi rien à faire sur les machines de l'utilisateur. Inconvénients : si l'attaque se produit entre le résolveur et la machine de l'utilisateur, DNSSEC n'aura servi à rien. Or, ce « dernier kilomètre » est loin d'être fiable. D'autre part, le FAI est souvent le premier ennemi (résolveurs DNS menteurs, censure genre LOPPSI). - Dans un résolveur installé sur la machine de l'utilisateur ?
Avantage : cela se produit sur une machine que l'utilisateur contrôle
complètement, nul ne peut plus lui mentir. Inconvénient : aujourd'hui,
il reste encore un peu de code à écrire pour que cela soit
complètement automatique. Si installer Unbound,
par exemple sur une Ubuntu, est trivial, encore
faut-il configurer la machine pour utiliser ce résolveur local
(fichier
/etc/resolv.confsur Unix). Un autre inconvénient potentiel, la charge sur les serveurs DNS, est traité plus loin. - Dans une application, comme Firefox ou
OpenSSH ? Avantages : l'application sait ainsi
tout ce qui se passe et peut présenter à l'utilisateur un message
approprié, voire lui permettre de passer outre une erreur
DNSSEC. (Avec les deux premières solutions, la seule possibilité du
résolveur, en cas d'échec de la validation, était de renvoyer un code
d'erreur très général, genre
SERVFAIL, Server Failure.) L'application peut aussi adapter son niveau de sécurité (on peut penser que la récupération d'un enregistrementSSHFP(RFC 4255) doit être davantage sécurisée que celle d'un enregistrementMX). Inconvénient : il faut modifier toutes les applications. S'il existe des bibliothèques de validation (citées plus haut), ce n'est quand même pas une tâche triviale, d'autant plus qu'il n'existe pas d'API standard (chaque bibliothèque a son interface).
Wesley Hardaker avait fait également un exposé plus long (« Enabling DNSSEC in Applications ») sur la troisième solution, avec une jolie démonstration où, pour montrer que la validation DNSSEC était peu coûteuse en ressources, il utilisait un Firefox et un OpenSSH « DNSSEC » sur son téléphone portable (utilisant Maemo). Mais son exposé rapide portait sur la deuxième solution, un résolveur sur la machine de l'utilisateur. Demain, tout smartphone aura-t-il un Unbound qui tourne ?
Appliquée telle quelle, cette solution coûterait cher en trafic DNS supplémentaire puisque ce résolveur local n'aurait plus accès au cache partagé du résolveur commun. Les serveurs faisant autorité (par exemple ceux des TLD) risqueraient de souffrir. Une solution est possible : utiliser le résolveur commun, celui du FAI (ou du réseau local de l'organisation) comme forwarder, par exemple, pour Unbound :
forward-zone:
name: "." # La racine, donc on fait tout suivre
forward-addr: 198.51.100.53
forward-addr: 203.0.113.129
Ainsi, Unbound fera la validation, mais les requêtes passeront par les
deux serveurs 198.51.100.53 et
203.0.113.129, qui pourront garder les résultats
dans leur cache, économisant les ressources du réseau. Comme DNSSEC
est une solution de bout en bout, qui sécurise le message et pas le
canal par lequel le message est passé, cela fonctionnera et cela sera sûr.
Cela pose deux problèmes, un petit et un gros. Le petit est, on l'a
vu, que sur une machine qui se déplace (un portable qui va au café ou à l'hôtel), il faut
réécrire le fichier unbound.conf (ou
named.conf pour BIND) à chaque fois qu'un serveur
DHCP transmet de nouvelles adresses d'un serveur
de noms résolveur. Pas un travail énorme mais il n'est pas fait
aujourd'hui donc cette solution n'est pas encore accessible à
l'utilisateur de base.
Le gros problème, et le cœur de l'exposé d'Hardaker, est que beaucoup de résolveurs (surtout dans les hôtels, trains et cafés, où personne ne sait exactement ce qui a été installé, mais également chez des FAI) ne sont pas des résolveurs corrects et massacrent plus ou moins les paquets DNS (à moins que ce massacre ne soit commis par la box insérée sur le chemin). Parmi les erreurs relevées par Hardaker :
- Résolveurs qui ne respectent pas le bit DO (DNSSEC OK, cf. RFC 3225) et transmettent la demande sans ledit bit, ce qui produit des résponses sans signature,
- Résolveurs qui ne peuvent pas recevoir les réponses de grande taille (DNSSEC est bavard), problème en général lié à la fragmentation,
- Résolveurs qui filtrent les réponses NSEC3 (cf. RFC 5155), peut-être parce que le nom en partie gauche n'est pas le nom demandé mais un condensat cryptographique,
- Et bien d'autres encore.
Résultat, on ne peut souvent pas utiliser le résolveur officiel. Il faut alors que le résolveur de la machine se résigne à parler directement à la racine et aux serveurs faisant autorité (sauf si le port 53 est filtré). C'est ce que teste un outil développé par l'auteur, qui fait tous ces tests et détermine si le résolveur officiel peut être utilisé comme forwarder.
Un bémol toutefois : cette idée très « développement durable » (on utilise le résolveur officiel si on peut, pour économiser des ressources), n'est pas forcément dans l'intérêt de l'utilisateur. Un autre exposé à cette même conférence SATIN, par Nicholas Weaver, « Implications of Netalyzr's DNS Measurements » montrait que, dans beaucoup de cas, le résolveur officiel est plus lent, pour une requête déjà en cache, que de demander au serveur faisant autorité ! Cela s'explique par le peu d'attention que beaucoup de gérants de réseau portent à leur résolveur.
À noter qu'un tel outil est également en cours de développement
pour Unbound, pour permettre de configurer simplement son Unbound en
résolveur local validant. Il pourra être utilisé par exemple via le
très récent outil de contrôle d'Unbound pour faire un
unbound-control forward $(ldns-test-edns
$IP_ADDRS) qui activera le forwarding si
et seulement si ldsn-test-edns ne répond pas
off. D'autre part, ce sujet avait déjà fait
l'objet d'une très bonne discussion sur la liste dns-operations, « DNSSEC validating clients that use upstream caching resolvers? ».
L'article seul
RFC 6125: Representation and Verification of Domain-Based Application Service Identity within Internet Public Key Infrastructure Using X.509 (PKIX) Certificates in the Context of Transport Layer Security (TLS)
Date de publication du RFC : Mars 2011
Auteur(s) du RFC : P. Saint-Andre (Cisco), J. Hodges (PayPal)
Chemin des normes
Première rédaction de cet article le 1 avril 2011
Un RFC long et complexe pour un problème
difficile. En résumant violemment, il s'agit de savoir quelle
identité utiliser lorsqu'un client
TLS s'assure de l'authenticité du serveur
auquel il se connecte. Par exemple, si un MTA
veut transmettre du courrier à bill@example.com,
que doit contenir le certificat
X.509 du MX d'example.com
pour que l'authentification réussisse ?
example.com ? D'autres noms, plus spécifiques à
ce service, sont-ils possibles ? Ce cas particulier est mentionné
dans la section 4.1 du RFC 3207 mais très peu détaillé, et renvoyé à des
décisions locales. Comme de nombreux autres protocoles ont des
problèmes de ce genre, l'idée avait germé de faire un RFC générique,
définissant un cadre et des principes,
RFC que les protocoles n'auraient plus qu'à citer. C'est notre RFC 6125 (depuis remplacé par le RFC 9525).
Traditionnellement, l'identité du pair avec lequel on se connecte était indiqué dans le champ Subject du certificat X.509. openssl permet de l'afficher :
% openssl s_client -starttls smtp -connect mail.bortzmeyer.org:25 ... Certificate chain 0 s:/C=FR/ST=Ile-de-France/L=Paris/O=Moi/OU=Maison/CN=mail.bortzmeyer.org/emailAddress=postmaster@b ortzmeyer.org ...
Le champ Sujet est formé de doublets attribut-valeur (par exemple,
l'attribut C veut dire Country, ici la France)
notamment CN (Common Name), le plus utilisé. Mais l'identité pouvait aussi figurer dans une
extension X.509, Subject Alternative Name (section
4.2.1.6 du RFC 5280). Cette extension est rare en pratique,
bien que normalisée depuis de nombreuses années. Je ne sais pas
comment l'afficher avec openssl. La seule solution que je
connaissais était de copier/coller le certificat affiché par
openssl s_client -connect www.example.com:443
puis de faire un openssl x509 -text -noout -in
/le/certificat.pem, ici avec le serveur HTTPS www.digicert.com :
Certificate:
...
Subject: businessCategory=V1.0, Clause 5.(b)/1.3.6.1.4.1.311.60.2.1.3=US/1.3.6.1.4.1.311.60.2.1.2=Utah/serialNumber=5299537-0142,
C=US, ST=Utah, L=Lindon, O=DigiCert, Inc.,
CN=www.digicert.com
...
X509v3 extensions:
...
X509v3 Subject Alternative Name:
DNS:www.digicert.com, DNS:www.origin.digicert.com,
DNS:content.digicert.com, DNS:digicert.com
...
On peut aussi combiner les deux commandes (openssl s_client
-connect www.digicert.com:443 | openssl x509 -text) voire
n'afficher que la partie qui nous intéresse (openssl s_client -connect www.digicert.com:443 | openssl x509 -text | perl -n0777e 'print $1 if /(.*Subject Alternative Name:.*\n.*\n)/', merci à minimalist pour son aide).
Mais les
navigateurs Web permettent en général de
montrer tout le certificat, y compris cette extension. Regardez par
exemple sur https://www.cisco.com/ ou bien https://www.digicert.com/. Un Subject Alternative
Name peut contenir un dNSName (un
nom de domaine), mais aussi un
uniformResourceIdentifier (un
URI) et, par des extensions de l'extension
(RFC 4985), un
SRVName (un nom de service, tel que présent en
partie gauche d'un enregistrement SRV).
Quel nom utiliser lorsque plusieurs sont présents ? C'est tout le but de ce RFC : lorsqu'un client TLS se connecte à un serveur TLS, et qu'une authentification X.509 prend place, le client a une idée sur l'identité du serveur (reference identity, identité de référence, dit le RFC) et le serveur présente un certificat contenant un certain nombre d'identités (presented identity, identité affichée). Comment comparer ? Aujourd'hui, la situation est plutôt confuse et deux approches sont largement utilisées :
- Utiliser uniquement le CN (Common Name) du champ Sujet (subject field), puisque tout le monde doit le connaître, c'est le champ traditionnel,
- Répéter l'identité du serveur à plusieurs endroits dans le certificat en se disant que le vérificateur en trouvera au moins un.
Une partie de la difficulté est que le déploiement d'une méthode propre et standard nécessite la copération de plusieurs acteurs. Ce nouveau RFC 6125 est surtout destiné à l'usage interne de l'IETF, aux concepteurs de protocoles (section 1.2). Mais les autres acteurs impliqués, par exemple ceux qui écrivent les logiciels ou bien qui gèrent une CA ont tout intérêt à le lire également. Ils ne s'amuseront pas forcément (ce RFC est long, complexe et très abstrait, la section 1.3 donne quelques pistes pour le lire sans trop souffrir) mais ils apprendront des choses utiles. Avant de se mettre à la lecture, il fraut s'assurer d'avoir lu et bien compris le RFC 5280, dont les règles demeurent actives. Il faut également garder en mémoire les RFC spécifiques d'un protocole applicatif particulier comme le RFC 2595 pour IMAP, RFC 2818 pour HTTP, RFC 2830 pour LDAP, RFC 3207 pour SMTP, RFC 6120 pour XMPP, et plusieurs autres encore (liste en section 1.6)...
Pour le lecteur pressé, la section 1.5 résume les recommandations essentielles de ce RFC 6125 :
- Abandonner progressivement l'utilisation de noms de domaine dans le champ CN (Common Name) du sujet du certificat. Aujourd'hui, c'est un vœu pieux, à en juger par les certificats HTTPS existants. Ceux-ci, soucieux de compatibilité, mettent presque tous le nom de la machine dans ce champ CN.
- Privilégier l'utilisation des champs de l'extension Subject Alternative Name du RFC 5280.
- Encore mieux, utiliser de préférence, dans cette extension, les champs typés comme celui qui permet d'indiquer l'URI du service ou celle qui permet d'indiquer le nom SRV (RFC 4985) car ils sont plus spécifiques et évitent de faire des certificats « attrape-tout ». (Personnellement, je n'ai jamais vu dans la nature des certificats d'un serveur HTTPS ou IMAP utilisant ces champs.)
- Pour le même souci de spécificité, abandonner petit à petit les
certificats incluant un joker (
*.example.com), un conseil qui plaira aux CA, car il augmentera leur chiffre d'affaires.
Plusieurs points sont exclus de ce RFC (section 1.7) :
- Les
identités des clients finaux (comme l'adresse de courrier électronique représentée par l'identificateur
rfc822Name), qui peuvent servir en cas de présentation d'un certificat client. Notre RFC ne considère que l'authentification du serveur. - Les identificateurs qui ne sont pas des noms de domaines (par exemple les adresses IP, théoriquement possibles mais, en pratique, très peu utilisées).
- Les protocoles non-TLS, même si certains d'entre eux, comme IPsec, peuvent eux aussi utiliser X.509.
- Les certificats non-X.509 comme ceux d'OpenPGP (RFC 4880 et RFC 6091).
Une fois éliminé ces « non-sujets », le lecteur doit ensuite passer un peu de temps sur la section de terminologie en 1.8, car X.509 utilise beaucoup de vocabulaire. Il faut également connaître le vocabulaire standard de la sécurité, exposé dans le RFC 4949. Parmi les sigles dont on aura le plus besoin ici :
- CN-ID: un RDN (Relative Distinguished Name
dans le champ sujet du certificat, qui contient une paire clé-valeur
de type CN (Common Name) et qui ait la forme d'un
nom de domaine. Par exemple, dans le certificat actuel de
www.gmail.com(après redirection versmail.google.com), le champ sujet estCN = mail.google.com, O = Google Inc, L = Mountain View, ST = California, C = USet le CN-ID estmail.google.com. C'est de très loin le type le plus fréquent aujourd'hui. - DNS-ID: un identificateur de type
dNSNamemis dans l'entréesubjectAltNamedu RFC 5280. Par exemple, dans le certificat actuel dewww.digicert.com, le DNS-ID estwww.digicert.com(le même que le CN-ID, ce qui est le cas de la quasi-totalité des certificats qu'on trouve sur l'Internet public). - SRV-ID et URI-ID: des identificateurs trouvés également dans
l'entrée
subjectAltNamedu RFC 5280 (plus le RFC 4985 pour le SRV-ID), de types respectifsSRVNameetuniformResourceIdentifier. On ne les trouve quasiment jamais dans les certificats disponibles sur l'Internet public.
Puisqu'on parle de ce qu'on trouve en pratique ou pas, je précise que mes avis là-dessus sont surtout tirés de quelques explorations faites sans méthode. Ce qui serait cool, ce serait d'avoir un Google des certificats X.509. Un robot récolterait les certificats, les analyserait et un moteur de recherches permettrait de trouver « Des certificats avec Subject Alternative Name » ou bien « Des certificats avec un condensat MD5 » ou aussi « Des certificats expirant après 2014 » ou encore « Des certificats Comodo émis par la Iranian Cyber Army :-) » Il existe deux projets allant dans cette direction : SSLiverse, qui a la récolte mais pas le moteur de recherche. L'archive fait 12 Go et est disponible en torrent. Il ne reste plus qu'à fouiller dedans (ce qui peut s'avérer assez long), la liste de diffusion du projet devient utile dans ce cas (merci à Étienne Maynier pour ses conseils et informations). L'autre projet est Shodan qui, lui, dispose non seulement d'une telle base, mais d'une partie des fonctions de recherche souhaitées (mais pas celle qui me fallait, pour trouver les certificats avec Subject Alternative Name).
Maintenant, passons aux noms. Un certificat contient les noms de
services comme www.example.org. Certains noms
sont directs : ils ont été tapés par un être
humain ou sélectionnés à partir d'une page Web. D'autres, indirects,
ont été obtenus, par exemple via une résolution
DNS. Ainsi, pour envoyer du courrier à
sandra@example.com, une résolution DNS de type
MX permettra de trouver le relais de courrier
de example.com, mettons
smtp.example.net. (On peut noter que, en
l'absence de résolution sécurisée, par exemple par
DNSSEC, c'est le premier nom qu'il faut
chercher dans le certificat,
le second peut être le résultat d'un empoisonnement DNS.)
Les noms peuvent également être restreints ou pas. Un nom restreint ne peut être utilisé que pour un seul service. Par exemple, une CA peut émettre un certificat qui ne sera utilisable que pour de l'IMAP.
On voit donc qu'un CN-ID ou un DNS-ID sont directs et non restreints, qu'un SRV-ID peut être direct ou indirect (mais il est indirect la plupart du temps) mais est restreint (le nom de l'enregistrement SRV indique un certain type de service), qu'un URI-ID est direct et restreint.
Et le nom de domaine lui-même, a-t-il plusieurs catégories possibles ? Oui, dit la section 2.2 qui sépare les noms en :
Au tout début de X.509, les noms étaient censés être tirés d'un
grand Annuaire officiel X.500 mais ce projet
s'est cassé la figure, comme la plupart des autres éléphants blancs de
l'UIT et il ne reste que des certificats
isolés (section 2.3). Pour assurer l'unicité des noms, la méthode la
plus courante sur l'Internet a donc rapidement été de mettre un nom de
domaine dans le CN (Common Name) du sujet du
certificat, par exemple C=CA,O=Example
Internetworking,CN=mail.example.net. Mais ce n'est qu'une
convention : le CN n'est pas typé, il peut contenir n'importe quoi,
par exemple un nom lisible par un humain comme CN=A Free
Chat Service,O=Example Org,C=GB et, dans ce cas, la
vérification automatique de ce nom par rapport à ce qu'attendait
l'utilisateur n'est pas évidente. Voici pourquoi notre RFC 6125 recommande l'utilisation des champs typés de
subjectAltName au lieu du CN (recommandation très
peu suivie dans l'Internet d'aujourd'hui).
Ces (longs) préliminaires étant achevés, la section 3 commence enfin la partie pratique du RFC, destinée aux auteurs de protocoles. Ceux-ci doivent d'abord faire une petite liste des caractéristiques pertinentes de leur protocole : utilise-t-il les enregistrements SRV ? Utilise-t-il des URI ? A-t-il besoin de jokers dans les noms de domaine ? Armé de cette connaissance, le concepteur de protocoles peut passer à la section 4 qui définit les règles de production d'identité (les règles pour les autorités de certification, donc).
Il est donc recommandé de mettre dans les certificats un
subjectAltName DNS-ID. Si le protocole utilise
les SRV, il est recommandé de mettre un SRV-ID (même conseil évident
pour les URI). J'aimerais bien savoir
combien de CA permettent de mettre un tel identificateur. Je parierais
bien qu'il n'y en a aucune. Le RFC conseille également de ne
pas inclure de nom de domaine dans le CN, pour
encourager la migration (notons que le premier exemple donné, en
section suivante, ne suit pas ce conseil...).
Voyons quelques exemples concrets :
- Pour un serveur HTTP, protocole qui
n'utilise pas les SRV et n'a pas prévu de mettre des URI dans les
certificats (cf. RFC 2818), le certificat pour
www.example.comdoit inclure un DNS-IDwww.example.comet peut inclure un CN-IDwww.example.compour la compatibilité avec les vieilles implémentations. - Pour un serveur IMAP, qui sert
user@example.netet se nommemail.example.net, comme le protocole peut utiliser les SRV (cf. RFC 6186), il faudra mettre le SRV-ID_imap.example.net, ainsi que les DNS-IDexample.netetmail.example.net(là encore, on pourra ajouter un nom de domaine dans le CN, si on tient à gérer les vieux clients IMAP). - C'est presque pareil pour XMPP, avec en
prime l'extension X.509 spécifique à ce protocole,
XmppAddr(section 13.7.1.4 du RFC 6120). - Pour un service SIP qui gère
user@voice.example.edu, comme SIP peut utiliser des URI (cf. RFC 5922), il faudra au moins un URI-IDsip:voice.example.eduet un DNS-IDvoice.example.edu.
Ces spécifications de la section 4 étaient pour les autorités de certification. Et les gérants des services sécurisés, que doivent-ils mettre dans leurs demandes de certificats (CSR, Certificate Signing Requests) ? La section 5 précise qu'ils doivent demander tous les identificateurs nécessaires (ce qui ne veut pas dire que la CA leur donnera...), donc, par exemple, le SRV-ID et le DNS-ID dans le cas de IMAP. Si le certificat sera utilisé pour des services différents, il vaut mieux ne demander que le DNS-ID (les autres étant restreints, rappelez-vous la section 2.1).
Les gérants des services ont demandé les certificats (section 6), les CA ont émis des certificats (section 5), reste à les vérifier dans le logiciel client (section 6, qui concerne donc surtout les programmeurs). Le principe est le suivant :
- L'application construit une liste des identités de
référence. Typiquement, c'est ce que l'utilisateur a tapé
au clavier ou bien sélectionné explicitement. S'il a configuré son
compte de messagerie comme étant
thierry.breton@iloveemail.example, le nomiloveemail.examplesera une identité de référence (rappelez-vous que notre RFC ne se préoccupe que d'authentifier des serveurs, pas des personnes, donc le nom de l'individu n'est pas pris en compte). Si l'utilisateur a sélectionnéhttps://www.dns-oarc.net/sur une page Web,www.dns-oarc.netest une identité de référence. - Le serveur TLS envoie un certificat, qui contient des identités affichées.
- Le client TLS compare les identités de référence aux identités affichées, râlant s'il n'y a pas correspondance.
Le reste de la section 6 formalise cette méthode. Quelques points particuliers, par exemple :
- Le client doit faire attention à ne pas dériver des identités à partir d'autres identités, sauf si cela peut être fait de façon sûre. Ainsi, analyser un URI, pour en extraire le nom de domaine, si c'est fait proprement, est une opération sûre. Résoudre un nom en un autre (par exemple le serveur de messagerie à partir du MX du domaine) via le DNS est non sûr. Si on utilise DNSSEC, cela redevient sûr.
- Mais, d'une manière générale, le RFC décourage la dérivation :
seuls les noms entrés directement par l'utilisateur sont vraiment
fiables comme identité de référence puisque, par définition, ils
expriment la volonté directe de l'utilisateur (« je veux communiquer
avec
gmail.com»). La règle n'est toutefois pas absolue car, par exemple, l'utilisateur a pu « épingler » un autre nom précédemment (« je sais que le serveur XMPP deexample.orgestjabber.toto.example, authentifie ce dernier nom », cf. section 7.1). - La liste des identités de référence doit comprendre un DNS-ID. S'il y a eu une résolution SRV, elle devrait comprendre un SRV-ID (même raisonnement pour les URI-ID).
- On peut y ajouter un CN-ID, pour réussir l'authentification avec les vieux certificats (le RFC note bien que, en l'état actuel des choses, cette possibilité est de facto une obligation, les certifiats avec CN-ID étant largement dominants).
Le RFC donne quelques exemples : une requête
Web pour
https://www.dns-oarc.net/ produira une liste
d'identités de référence comportant un DNS-ID,
www.dns-oarc.net et un CN-ID optionnel
identique. Une tentative de connexion IMAP pour le domaine
example.net, dont l'enregistrement SRV indiquera
que le serveur est mail.example.net, donnera une
liste comportant les SRV-ID _imap.example.net et
_imaps.example.net ainsi que les DNS-ID
example.net et
mail.example.net (sans compter le CN-ID)
optionnel. Le RFC ne rappelle apparemment pas que l'étape de
résolution DNS de example.net en
mail.example.net n'est pas forcément sûre... Le
fait qu'ils soient sous le même domaine
example.net n'est pas une protection parfaite
(car on ne connait pas les frontières des zones DNS) et, de toute
façon, le serveur n'est pas forcément dans le même domaine que celui
qu'il sert. Et le RFC semble avoir oublié ici son conseil précédent de se méfier des noms dérivés...
Ensuite, il reste à comparer les deux listes (section 6.3). Le principe est celui de la première correspondance. Dès qu'une identité présentée correspond à une des identités de référence, on s'arrête, on a authentifié le serveur (section 6.6.1) et cette identité authentifiée est celle qui doit pêtre montrée à l'utilisateur. (Le cas où on voudrait que toutes les identités correspondent est laissé à une future norme.) Attention, le CN-ID dans les identités de référence est traité un peu à part : il ne doit pas être utilisé si le certificat inclus d'autres identités (comme un DNS-ID).
Cette correspondance nécessite quelques précisions (section 6.4). Ainsi, le RFC rappelle que les noms de domaine traditionnels doivent être comparés de manière insensible à la casse (RFC 4343), que les noms de domaine internationalisés doivent être transformés en A-labels (cf. RFC 5890) avant comparaison, que les jokers (indiqués par le signe *) nécessitent de l'attention particulière (par exemple, ils ne sont considérés comme spéciaux que s'ils apparaissent seuls, dans le composant le plus à gauche du nom). Globalement, faire correctement cette comparaison n'est pas trivial pour le programmeur.
Pour les CN, il est rappelé qu'un CN dans la liste des identités de référence n'est là que pour pouvoir authentifier avec les « vieux » certificats et ne doit pas être utilisé avec un certificat moderne, incluant des DNS-ID, SRV-ID ou URI-ID. S'il n'y a pas le choix (pas de Subject Alternative Name dans le certificat), l'application peut comparer ses identités de référence au CN, en suivant les règles de comparaison des noms de domaine.
Bon, si l'authentification du serveur a réussi, on continue et on affiche à l'utilisateur, sur un joli fond vert, l'identité authentifiée. Et si ça a raté, que doit-on faire ? La section 6.6.4 propose des stratégies de repli : si le logiciel est interactif, avec un humain pas loin, la méthode recommandée est de mettre fin à la connexion, avec un message d'erreur (conseil que je trouve déplorable : vu le nombre de certificats invalides, cela diminuerait nettement l'utilisabilité du Web et cela encouragerait les sites à ne pas proposer HTTPS). La possibilité de permettre à l'utilisateur de passer outre le problème et de contnuer (ce que font tous les navigateurs Web, autrement ils perdraient tous leurs clients) est mentionnée mais très découragée.
Si l'application n'est pas interactive, la démarche recommandée est
d'afficher un message d'erreur et de s'arrêter. Une option pour
ignorer le certificat est possible mais ne doit pas être activée par
défaut. C'est ainsi que wget, fidèle à cette
règle, a son option --no-check-certificate, alors
que
fetchmail, qui ne suit pas le RFC, a son
--sslcertck pour activer la
vérification.
D'ailleurs, une section entière, la 7, est consacrée à la discussion détaillée de certains problèmes de sécurité. Ainsi, les jokers font l'objet de la section 7.2. Ils sont déconseillés (pour les raisons expliquées en « New Tricks for Defeating SSL in Practice » et « HTTPS Can Byte Me ») mais, s'ils sont présents dans un certificat, le client devrait se préparer à les gérer, avec prudence.
Autre cas complexe, celui où un même serveur est accédé par plusieurs noms (virtual hosting) par exemple un serveur IMAP qui hébergerait plusieurs domaines de messagerie, ce qui est courant. Il existe plusieurs méthodes pour gérer ce cas, comme de mettre tous les noms possibles dans le certificat (pas pratique...), ou bien d'utiliser SNI (Server Name Indication, section 3 du RFC 6066). Si on met plusieurs noms dans le certificat, le RFC recommande que ce soit plusieurs DNS-ID (ou SRV-ID ou URI-UID) pas plusieurs CN.
Voilà, arrivé ici, le concepteur d'un protocole utilisant l'authentification avec X.509 sait normalement tout ce qu'il faut savoir. Il ne lui reste plus qu'à inclure dans sa spécification le texte exact et, pour lui faciliter la vie, l'annexe A contient un tel texte (pris dans le RFC 6120, section 13.7.1.2), qui peut être copié/collé avant d'être adapté à ce protocole particulier. De nombreux RFC avaient des règles spécifiques, avant la publication de notre RFC 6125 et la variété de ces règles était justement une motivation pour le développement du nouveau RFC. L'annexe B rappelle et cite les principaux RFC qui avaient traité le sujet comme le RFC 2818 pour HTTPS ou le RFC 2830 pour LDAP.
Ce RFC 6125 avait été chaudement discuté à l'IETF, ce qui explique qu'il ait mis si longtemps à être publié. Le lecteur courageux doit relire toutes les archives de la liste certid pour suivre toutes ces discussions (je recommande celles de septembre 2010 et décembre 2010).
Quelques petits trucs techniques pour ajouter des extensions comme
subject alternative name avec les logiciels
existants (merci à Dany Mello et Christian Pélissier ; on peut aussi
consulter mon article « Plusieurs noms dans un certificat X.509 »). Avec OpenSSL,
on peut aussi utiliser un fichier texte où on place l'extension. Pour une
extension de type IP, le fichier ext.txt contient :
subjectAltName="IP:1.1.1.1"
puis on ajoute l'argument -extfile dans la ligne de commande d'openssl :
% openssl x509 -req -days 7300 -in moncsr.csr -CA ca.crt -CAkey ca.key \
-set_serial 01 -out moncrt.crt -extfile ext.txt
Avec l'utilitaire certpatch (qui ne semble pas très documenté) disponible dans le paquetage isakmpd, c'est :
% certpatch -t fqdn -i www.example.org -k /etc/ssl/private/ca.key \
oldcert.crt nwcert.crt
Avec l'utilitaire certutil (des outils de sécurité NSS), c'est :
% certutil -R -s "cn=dapou.exemple.fr,ou=DI,o=Exemple,...,c=FR" \
-a -o $CADIR/$host.$domain.pem.csr -d $CADIR \
-8 "cn=ldap1.exemple.fr" \
-z random -f password-file
où ldap1.exemple.fr sera le nom alternatif.
L'article seul
RFC 6122: Extensible Messaging and Presence Protocol (XMPP): Address Format
Date de publication du RFC : Mars 2011
Auteur(s) du RFC : P. Saint-Andre (Cisco)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF xmpp
Première rédaction de cet article le 31 mars 2011
Ce RFC normalisait le format des adresses du protocole de messagerie instantanée XMPP, également connu sous son ancien nom de Jabber. Il s'agissait d'un document transitoire, qui remplaçait une partie de l'ancien RFC 3920, et qui a lui même été remplacé par le RFC 7622.
Le protocole XMPP est le standard actuel de
messagerie instantanée de
l'IETF. Les utilisateurs sont identifiés par
une adresse également connue, pour des raisons
historiques, sous le nom de JID (Jabber
IDentifier). Ces adresses ont une forme qui ressemble aux
adresses de courrier électronique mais elles
sont en fait complètement différentes. Ainsi, j'ai personnellement
deux adresses XMPP, bortzmeyer@gmail.com (le
service de messagerie Google Talk utilise en
effet la norme XMPP), qui me sert surtout pour la distraction, et
bortzmeyer@dns-oarc.net qui me sert pour le
travail. Mais rien ne dit qu'un courrier envoyé à ces adresses
fonctionnera : adresses XMPP et de courrier vivent dans des mondes différents.
Le format des adresses XMPP était spécifié à l'origine dans le document XEP-0029. Puis il a été normalisé dans la section 3 du RFC 3920. La norme XMPP ayant subi une refonte complète, qui a mené entre autre à un nouveau RFC, le RFC 6120, se posait la question du format d'adresses, dont l'internationalisation, compte-tenu de la nouvelle norme IDN, suscitait des débats. Ces débats n'étant pas terminés, la décision a été prise de sortir le format d'adresses du RFC principal, et d'en faire ce RFC 6122, jusqu'à ce qu'un consensus apparaisse sur le format « définitif ».
Donc, quels sont les points essentiels des adresses XMPP (section
2) ? Une adresse (ou JID) identifie une entité (un humain mais peut-être aussi
un programme automatique). Elle comprend trois parties (donc une seule
est obligatoire), la partie locale, le
domaine et une
ressource. Ainsi, dans
bortzmeyer@gmail.com/Home,
bortzmeyer est la partie locale,
gmail.com le domaine et Home
la ressource. Le @ et le
/ servent de séparateurs. Chacune des trois
parties peut-être composée de caractères
Unicode (cf. section 3), qui doivent être encodés en
UTF-8. La partie locale doit être canonicalisée
avec Nodeprep, le domaine avec le
Nameprep du RFC 3491. Seul le domaine est obligatoire et
bot.example.org est donc un JID valide.
Les adresses XMPP (ou JID) sont souvent représentées sous forme
d'un IRI, selon le RFC 5122. En gros, un IRI XMPP est un JID préfixé par
xmpp:. Mais ces IRI ne sont pas utilisés par le
protocole XMPP. Dans les champs to et
from des strophes (stanzas) XMPP, on
ne trouve que des JID (sans le xmpp: devant). Les
IRI ne servent que dans les liens dans les pages Web, comme xmpp:bortzmeyer@gmail.com (attention, ce lien ne marchera pas
avec tous les navigateurs).
Le RFC détaille ensuite chaque partie. Le domaine, seule partie
obligatoire, est dans la section 2.2. On peut le voir comme une
identification du service auquel on se connecte
(gmail.com = Google Talk), et la création de
comptes et l'authentification se font typiquement en fonction de ce
service. En théorie, une adresse IP est
acceptable pour cette partie mais, en pratique, c'est toujours un
FQDN. Ce nom de domaine peut être un
IDN donc
instantanée.nœud.example est un nom
acceptable pour former un JID. Auquel cas, ce doit être un IDN légal
(ce qui veut dire que toute chaîne de caractères Unicode n'est pas
forcément un nom légal pour la partie domaine d'un JID). À noter que
XMPP n'utilise pas l'encodage en
ASCII des IDN (le Punycode).
Et la partie locale, celle avant le @ ? La
section 2.3 la couvre. Elle est optionnelle et identifie en général
une personne (mais peut aussi indiquer un programme ou bien un salon de
conversation à plusieurs). Si elle est en Unicode, elle doit être
canonicalisable avec le
profil Nodeprep (Nodeprep est normalisé en
annexe A de notre RFC).
Quant à la ressource, troisième partie du JID (après le
/), également optionnelle, elle sert à
distinguer plusieurs sessions par le même utilisateur (par exemple
/Home et /Office). La
section 2.4 la décrit en détail. Également en Unicode, elle est
canonicalisée par le profil Resourceprep. Elle n'a pas de structure
officielle. Un / dans une ressource (par exemple
example.com/foo/bar) n'implique donc pas une hiérarchie.
De même, si on y trouve quelque chose ressemblant à une adresse (par
exemple joe@example.net/nic@host), cette ressource
nic@host doit être traitée comme un identificateur
opaque (et pas être analysée en « nom (at) machine »).
Quelles sont les conséquences de sécurité de ces adresses ? Il n'y
en a guère mais, bon, il y a toujours des inquiets donc la section 4
examine en détail tous les risques, même très théoriques. Bien sûr,
les adresses XMPP héritent des questions de sécurité de
Stringprep (section 9 du RFC 3454) mais le RFC mentionne surtout les risques de triche
sur les
adresses. Il y en a de deux sortes, les usurpations et les
imitations. Les usurpations (section 4.3.1) sont les cas où un méchant
arrive à envoyer un message XMPP en trichant sur
l'origine, par exemple si jean@example.net, une
fois authentifié auprès de son propre serveur, arrive
à transmettre un message prétendant venir de
jeanne@jabber.example. Normalement, le protocole
XMPP empêche cela, par l'authentification mutuelle des serveurs (sauf
attaques un peu sophistiquées, par exemple sur le DNS). Cela
dit, cette authentification n'empêche pas un serveur d'annoncer une
autre partie locale (jeanne@example.net au lieu
jean@example.net).
L'autre risque est celui d'imitation (section 4.3.2). Cette fois,
il s'agit d'utiliser des JID légitimes et authentiques mais qui ressemblent à celui de la victime,
par exemple fric@paypa1.com au lieu de
fric@paypal.com (si vous ne voyez pas la
différence, regardez mieux). Cette technique est souvent connue sous
le nom de typejacking. Dans un accès de beaufitude,
le RFC mentionne aussi le cas d'écritures « moins familières » que
l'alphabet latin (moins familières pour qui ?)
mais, comme le montre l'exemple du RFC ou bien celui cité plus haut,
le problème arrive même en se limitant à ASCII. Si vous voulez un joli
exemple avec Unicode (mais le résultat dépend de l'environnement avec
lequel vous lisez cet article), le RFC cite ᏚᎢᎵᎬᎢᎬᏒ qui ressemble à
STPETER mais est écrit en
Cherokee. Comme un JID peut contenir à peu près
n'importe quel caractère Unicode, il n'y a pas vraiment de prévention technique
possible contre ce problème. Toutefois, contrairement à ce que prétend
le RFC (qui évoque le spectre du hameçonnage),
il est peu probable que cela ait des conséquences en pratique. Le RFC, qui
exagère le risque, suggère que les serveurs XMPP qui servent une
communauté homogène, linguistiquement parlant, peuvent réduire le jeu
de caractères Unicode acceptés comme partie locale d'un JID (par
exemple, à l'alphabet cyrillique pour un
serveur russe). Une telle
politique serait, je trouve, un gros recul dans l'internationalisation
de l'Internet et, de toute façon, elle n'aiderait pas les serveurs
internationaux comme jabber.org ou
Google Talk. Une approche moins restrictive est
aussi proposée par le RFC : le logiciel client XMPP pourrait prévenir
visuellement l'utilisateur lorsqu'un JID utilise une écriture
distincte de celle utilisée habituellement par l'utilisateur (et qui
est déduisible de ses préférences).
Le RFC se termine par les annexes normalisant
les profils Nodeprep et
Resourceprep. Rappelons que
Stringprep (RFC 3454)
décrit un cadre général pour la canonicalisation de chaînes de
caractères Unicode, afin de faciliter les comparaisons
ultérieures. Stringprep laisse un grand nombre de
choix ouverts et doit donc, avant utilisation, être réduit à un
profil. Les profils normalisés sont enregistrés
à l'IANA. Par exemple, Nodeprep précise
que la normalisation Unicode utilisée doit être la
NFKC et donne la liste des caractères interdits
dans une partie locale
(par exemple @, <, >, /,
etc). Resourceprep, lui, est dans l'annexe B et
n'est pas équivalent (par exemple, les caractères cités plus haut ne
sont pas interdits dans la ressource d'un
JID). Stringprep ayant depuis été abandonné (remplacé par le cadre du RFC 7564), une nouvelle version de XMPP est en cours de rédaction pour la partie « Unicode ».
La liste complète des changements par rapport au RFC 3920 figure en annexe C. Rappelons que le RFC 3920 s'appuyait, pour les parties en
Unicode, sur des profils
Stringprep (RFC 3454) comme Nameprep. Ce Nameprep, décrit dans le RFC 3491, ayant été supprimé à l'occasion de la
réforme IDNA bis, la question se posait
de l'avenir des profils Stringprep. Un groupe de
travail IETF, PRECIS, a été monté pour
discuter de l'avenir des normes utilisant
Stringprep. Son travail n'étant pas terminé, et le
groupe de travail sur XMPP ne souhaitant pas retarder la sortie de la
nouvelle norme (RFC 6120), la question du
successeur de Nameprep a été remise à plus tard et
notre RFC 6122 normalise donc le format d'adresses XMPP
tel qu'il était avant IDNA bis. Le RFC note que les implémenteurs sont
encouragés à utiliser dès maintenant IDNA bis, même avant la sortie du
RFC sur le format d'adresses (à part la question de la
canonicalisation avec Nameprep, les différences
entre l'IDN original et IDNA bis sont de peu d'importance
pratique). Ce RFC a finalement été le RFC 7622,
qui est désormais la norme des adresses XMPP.
Les autres changements sont limités : clarification sur
l'utilisation d'adresses IPv6 littérales dans
les JID (j'offre une bière au premier qui annonce un JID
quelqun@[2001:db8::bad:dcaf:1] qui
marche), correction de bogues dans la
grammaire pour le cas de termes de longueur
nulle, changements de terminologie (la partie locale se nommait
node identifier, d'où le terme de
Nodeprep, survivance de l'ancien vocabulaire), etc.
L'article seul
RFC 6186: Use of SRV Records for Locating Email Submission/Access services
Date de publication du RFC : Mars 2011
Auteur(s) du RFC : C. Daboo (Apple)
Chemin des normes
Première rédaction de cet article le 31 mars 2011
Les enregistrements DNS de type
SRV ont été normalisés dans le RFC 2782 il y a dix ans, pour permettre de trouver la
ou les machines rendant un service (par exemple de
messagerie instantanée avec
XMPP), en ne connaissant que le nom de
domaine délégué, par exemple
example.org ou apple.example. Ils ont été adoptés par la plupart des protocoles
Internet, avec deux exceptions importantes : le
Web ne les utilise toujours pas, ce qui mène à
des bricolages contestables comme de mettre une adresse IP sur un nom de domaine délégué. Et le
courrier électronique n'utilise pas non plus
SRV car, pour trouver le serveur d'un domaine, il compte sur une
technique plus ancienne, proche du SRV mais spécifique au courrier, le
MX (les MX ne présentent aucun avantage
spécifique et, si tout était à refaire de zéro, on utiliserait
certainement les SRV aussi pour cela). Les enregistrements MX ne concernent
toutefois que la transmission de courrier de
MTA à MTA. Pour les autres logiciels de
courrier, comment font-ils ?
Depuis ce RFC 6186, ils utilisent
SRV à leur tour. Ainsi, un
MUA qui cherche à quel serveur transmettre le
courrier n'aura plus besoin d'être configuré explicitement (options
Mail submission server, Mail retrieval server, ou quelque chose de ce
genre). Il suffira d'indiquer l'adresse électronique de l'utilisateur
(mettons jeanne@example.org) et le MUA pourra
extraire le domaine (example.org) et chercher des
enregistrements SRV qui lui indiqueront où trouver ces serveurs. (Une
autre méthode ancienne était d'utiliser des
conventions comme de mettre le serveur
IMAP en imap.example.org
mais elle est moins souple, les SRV permettent en effet d'indiquer
plusieurs serveurs, de préciser leurs priorités, etc.)
Bien, commençons par l'introduction. Une liste (sans doute non limitative) des services de courrier est donnée par la section 1 :
- Service SMTP (RFC 5321) et son profil spécifique à la soumission initiale de messages (RFC 6409),
- Services de récupération du courrier, IMAP (RFC 9051) et POP (RFC 1939).
Le premier cité de ces RFC, le RFC 5321 (section 5)
normalise l'utilisation des enregistrements MX
pour trouver le serveur de courrier suivant. Mais il ne dit rien des
autres services. Par exemple, un MUA ne peut pas trouver dans les MX
le serveur de soumission. Résultat, les MUA dépendent d'une
configuration manuelle des serveurs à utiliser, parfois augmentée
d'une série d'heuristiques (du genre, essayer l'IMAP sur le serveur de
soumission, au cas où ce serait le même...). Ce système est complexe
pour les utilisateurs (« Indiquez le numéro de port de votre serveur
IMAP ; si vous ne le connaissez pas, écrivez à jenerepondsjamaisintelligemment@support.votre-fai.net »...)
Les différents noms SRV utilisés sont normalisés en section 3 :
submission(section 3.1) sert pour la soumission initiale de message, telle que décrite dans le RFC 6409. Ainsi, pour le domaineexample.org, on pourrait voir un enregistrement_submission._tcp.example.org. SRV 0 1 9587 mail.example.NET.indiquant que les messages doivent être soumis àmail.example.NET, sur le port non-standard 9587. À noter que cet enregistrement couvre les connexions avec ou sans TLS, ce qui est une autre source de confusion lors de la configuration. (Depuis, la sortie du RFC 8314, avec son_submissions._tcp, a clarifié les choses.)imap(section 3.2) etimapsservent pour trouver le serveur IMAP. Donc, par exemple, avec cette fois le port standard,_imap._tcp.example.org. SRV 0 1 143 imap.example.NET..pop3etpop3sservent à localiser le serveur POP3. Leur absence peut donc indiquer que ce vieux protocole n'est pas disponible pour un domaine.
Les enregistrements SRV indiqués ici utilisent évidemment la sémantique standard du RFC 2782. Ainsi, l'ensemble suivant :
$ORIGIN example.org.
_imap._tcp SRV 0 1 143 imap.example.net.
SRV 10 1 143 imap.plan-B.example.
signifie, en raison du champ Priorité (mis à zéro pour le premier
enregistrement et à 10 pour le second), que le client IMAP
doit tenter d'abord de se connecter à
imap.example.net et ne doit essayer
imap.plan-B.example que si le premier est
injoignable. Tout cela est ancien et bien connu. Mais le courrier
présente un défi spécifique, l'existence de deux protocoles de
récupération, IMAP et POP. Que doit faire le MUA si les deux sont
annoncés dans le DNS ? La section 3.4 tranche : le MUA qui gère les
deux protocoles devrait
récupérer les enregistrements pour POP et IMAP et utiliser ensuite le
champ Priorité, non seulement à l'intérieur d'un ensemble (POP ou
IMAP) mais même pour choisir entre les deux protocoles. Ainsi, ces
données :
$ORIGIN example.org. _imap._tcp SRV 10 1 143 imap.example.net. _pop3._tcp SRV 50 1 143 pop.example.net.
indiquent sans ambiguité que l'administrateur système voudrait qu'on utilise de préférence IMAP (champ Priorité plus petit, donc plus prioritaire).
Bien, maintenant, dans le futur (car, aujourd'hui, il n'y a à ma
connaissance aucune mise en œuvre de ce RFC dans un logiciel), comment se comportera un
MUA lorsque ce RFC sera déployé ? La section 4
expose le mode d'emploi. Il leur suffira d'interroger l'utilisateur
sur son adresse électronique et tout le reste pourra être trouvé dans
le DNS, en prenant la partie à droite du @ et
en cherchant les SRV pour les différents services. Regardez par
exemple le domaine bortzmeyer.fr comment
c'est fait (enregistrements _submission._tcp,
_imap._tcp et
_imaps._tcp). Si la recherche des SRV ne donne
rien, le MUA pourra alors, comme aujourd'hui, demander à l'utilisateur
ces informations.
Notez toutefois que beaucoup d'hébergeurs DNS ne permettent pas, via le panneau de contrôle qu'ils proposent à leurs clients, d'ajouter un enregistrement SRV. Même lorsque cette possibilité existe, elle est souvent boguée comme chez Gandi où le formulaire ne permet pas d'indiquer proprement poids, priorité ou port (astuce : il faut les taper dans le champ Valeur, dans le bon ordre).
La partie de cette section concernant TLS
est plus faible (mais a été changée dans le RFC 8314, bien plus détaillé). Si on trouve un serveur IMAP, par exemple,
le RFC demande de tenter la commande STARTTLS
pour voir si elle marche. Les enregistrements SRV de notre RFC ne permettent pas
d'indiquer que la gestion de TLS est obligatoire (chose que l'on peut
configurer dans beaucoup de MUA) et, si TLS échoue, le MUA doit donc
compter sur une configuration manuelle par l'utilisateur (du genre
« Toujours utiliser TLS »). La section 6 détaille ce choix.
Notons aussi que
l'utilisation des SRV peut compliquer la vérification de l'identité du
serveur distant (si le domaine est
mapetiteentreprise.example et que l'enregistrement SRV indique
que le serveur IMAP est
mail.grosfournisseur.example, l'identité du
serveur dans le certificat ne sera pas
mapetiteentreprise.example). La procédure du RFC 6125 doit impérativement
être utilisée.
Lors de la connexion au serveur IMAP ou au serveur SMTP de soumission, il faut en général s'authentifier, ce qui implique qu'on puisse indiquer un nom d'utilisateur. Notre section 4 impose au MUA d'utiliser d'abord l'adresse électronique entière, puis la partie à gauche du @. Si ces deux tentatives échouent, il reste à demander à l'utilisateur (le nom pour la procédure d'authentification n'est en effet pas forcément dans l'adresse de courrier).
Les informations sur les serveurs peuvent être conservées pour éviter de demander au DNS à chaque fois. Mais, si la connexion a marché à un moment mais échoue par la suite, le MUA doit ré-interroger le DNS pour voir si les serveurs n'ont pas changé.
La section 4 conseillait les auteurs de MUA. La section 5 aide les fournisseurs de courrier. Le principal conseil est de permettre comme nom de connexion l'adresse électronique complète, vu que c'est la première chose que tenteront les MUA.
La section 6 est celle de la sécurité. En l'absence de signatures DNSSEC, la récupération des enregistrements SRV n'est pas sûre. Si un attaquant a réussi à empoisonner le cache du résolveur DNS, il peut rediriger le courrier vers n'importe quel serveur de son choix. Notez bien que c'est un des cas où l'argument des sceptiques sur DNSSEC « Il suffit d'utiliser TLS » ne tient pas. Sans DNSSEC pour sécuriser le SRV (le lien entre un nom de domaine et les noms des serveurs), TLS ne protégerait rien puisque les serveurs d'un attaquant peuvent parfaitement avoir un certificat valide et correspondant à leur nom.
La section 6 conseille, au cas où DNSSEC ne soit pas utilisé (ce
qui est aujourd'hui le cas le plus fréquent), de vérifier que les
serveurs sont dans le même domaine que le domaine de l'adresse de
courrier et, sinon, de demander confirmation à l'utilisateur,
procédure lourde qui annulerait une partie de l'intérêt de ce RFC (et qui n'est pas suivie dans l'exemple de bortzmeyer.fr donné plus haut).
L'article seul
RFC 6206: The Trickle Algorithm
Date de publication du RFC : Mars 2011
Auteur(s) du RFC : P. Levis (Stanford University), T. Clausen (LIX, Ecole Polytechnique), J. Hui (Arch Rock Corporation), O. Gnawali (Stanford University), J. Ko (Johns Hopkins University)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF roll
Première rédaction de cet article le 29 mars 2011
Dernière mise à jour le 30 mars 2011
Dans le cadre des travaux sur l'Internet des objets, le groupe de travail ROLL de l'IETF s'occupe de définir des mécanismes de routage pour des réseaux d'engins aux capacités limitées, et connectés par des liens radio à faible portée et souvent brouillés. (Par exemple, cela peut décrire la situation de capteurs dans une usine.) Une brique de base pour beaucoup de protocoles utilisés dans ce contexte est un algorithme pour coordonner un état entre toutes les machines (cet état pouvant être par exemple la table de routage, mais aussi une configuration commune). Trickle (terme désignant un mince filet d'eau, par exemple celui coulant du robinet en cas de fuite) est l'algorithme utilisé et ce RFC est sa première normalisation. Il est notamment utilisé dans le protocole RPL du RFC 6550.
Vu le contexte très spécial, les protocoles classiques de distribution d'information ne convenaient pas forcément à ce type de réseau, où il est crucial d'économiser l'énergie, et de fonctionner malgré des liaisons physiques sommaires. Trickle atteint ces objectifs en ne diffusant l'information que lorsque elle a changé. L'idée de base est de permettre à deux nœuds de déterminer très rapidement s'ils ont la même version de l'information distribuée et, sinon, de se synchroniser. S'ils sont synchronisés, il n'y a plus beaucoup de communication. Lorsque de la nouvelle information apparait, le trafic reprend. Trickle repose entièrement sur les mécanismes de diffusion du réseau local et n'est donc pas routé. Le tout est simple et tient dans 50 à 200 lignes de code C (je n'ai pas trouvé de distribution officielle de référence de ce code miracle mais l'implémentation dans Contiki fait effectivement cette taille).
Trickle est un algorithme générique : conçu à l'origine pour distribuer du code (pour mettre à jour le programme sur les autres machines), il a pu être adapté pour distribuer n'importe quel type d'information, par exemple une table de routage. Pour un nouveau type d'information, il suffit de définir ce que veut dire « être synchrone » ou pas et la partie générique de Trickle fait le reste.
Assez de publicité, place à l'algorithme (sections 3 e 4 du RFC). Le travail de chaque nœud est de transmettre les données qu'il connait jusqu'à ce que, en entendant les autres nœuds, il se rende compte que ses transmissions sont inutiles (cela veut dire qu'un nœud Trickle isolé continuera à parler tout seul). Pour prendre l'exemple du protocole CTP (Collection Tree Protocol), quelques paquets par heure suffisent.
La transmission se fait à une adresse
multicast locale. Par
exemple, au dessus d'IPv6, Trickle va écrire à
une adresse multicast locale au lien alors qu'en
IPv4, il utiliser
255.255.255.255.
Lorsqu'un nœud reçoit les messages d'un autre, il y a deux cas :
- Le message montre que celui dont on vient de recevoir des nouvelles a la même version de l'information,
- Le message montre qu'un des deux nœuds, le récepteur ou l'émetteur, est en retard. Notons que Trickle ne fait pas trop de différence entre ces deux sous-cas : ils entraineront tous les deux une transmission de données.
L'un des principaux paramètres d'un algorithme spécifique utilisant Trickle est un moyen de déterminer cette notion de « être à jour ». Par exemple, supposons que l'information ait un numéro (comme le numéro de série des zones DNS). Alors, « être à jour » signifie avoir le même numéro que l'autre et « être en retard » avoir un numéro inférieur.
Pour décider ensuite de l'action exacte à entreprendre, les nœuds Trickle ont besoin de quelques paramètres :
- la taille minimum de l'intervalle, Imin,
- la taille maximum de l'intervalle, Imax,
- la constante de redondance k.
et de quelques variables :
- la taille actuelle de l'intervalle, I,
- le moment de la transmission, t,
- le compteur c.
Le nœud suit les règles suivantes :
- Choisir I entre Imin et Imax. Commencer le premier intervalle.
- Au début de l'intervalle, mettre c à zéro et t à une valeur située dans la deuxième moitié de l'intervalle.
- À chaque message reçu pour lequel on est à jour, incrémenter c.
- Au temps t, si c est inférieur à k, on transmet les données. (C'est la seule étape de l'algorithme où on transmet quelque chose.) c < k peut se traduire par « j'ai trop de voisins qui ne sont pas à jour par rapport à l'ensemble de mes voisins ». C'est par cette comparaison de c (nombre de voisins à jour) à k que Trickle s'adapte automatiquement à la densité du réseau (s'il y a plein de voisins à jour, pas la peine de se fatiguer à transmettre, un autre le fera).
- À la fin de l'intervalle, doubler la taille de l'intervalle (en s'arrêtant à Imax).
- Si on entend un message qui montre que quelqu'un (le nœud qui exécute cet algorithme ou bien son voisin) n'est pas à jour, on réduit l'intervalle à Imin. L'idée est de rendre l'algorithme plus dynamique lorsqu'il y a des nœuds qui sont en retard.
On note que Trickle ne réagit pas immédiatement en détectant un retard : il se contente de démarrer un nouvel intervalle. C'est fait exprès pour éviter une tempête de mises à jour, par exemple lorsqu'un nouveau nœud rejoint le réseau après une absence. Trickle privilégie donc l'économie de ressources, et ne cherche pas à être temps-réel.
Ça, c'était l'algorithme. Simple, non ? Maintenant, si vous êtes concepteur de protocoles et que vous voulez utiliser Trickle, que vous reste-t-il à faire ? La section 5 liste vos tâches :
- Préciser des valeurs par défaut pour les paramètres Imin, Imax, k, etc. Notamment, Imin dépend de la latence du réseau utilisé.
- Définir ce que signifie « être à jour » et « être en retard ».
- Et quelques détails. Regardez le RFC 6550 pour un exemple de protocole de routage utilisant Trickle.
Il ne faut quand même pas oublier quelques considérations pratiques (section 6). D'abord, le bon fonctionnement de Trickle dépend d'un accord de tous les nœuds sur les paramètres à utiliser. En cas de différence, le résultat peut être sous-optimal voire faux dans certains cas. Par exemple, un nœud qui aurait une constante de redondance k supérieure aux autres pourrait se retrouver à émettre à chaque intervalle, vidant sa batterie. De même, un désaccord sur Imax pourrait mener certains nœuds à ne jamais transmettre, laissant les autres faire tout le travail. En outre, toutes les valeurs ne sont pas forcément raisonnables. Par exemple, la constante de redondance k mise à l'infini est théoriquement possible (Trickle travaillerait alors en mode bavard, n'économisant pas les transmissions) mais très déconseillée. Il faut donc trouver un moyen de distribuer la bonne configuration à toutes les machines.
Le pire problème serait évidemment une fonction de définition de la cohérence différente selon les nœuds, cela pourrait mener à une impossibilité de converger vers un état commun. C'est pour cela que le RFC demande qu'elle soit strictement définie pour un protocole donné, et non configurable.
L'auteur de protocole, ou le programmeur, pourraient vouloir « améliorer » Trickle en ajustant l'algorithme. Attention, avertit le RFC, cet algorithme a été soigneusement étudié et testé et la probabilité d'arriver à l'améliorer est faible. Il est conseillé de ne pas le toucher gratuitement. Trickle est extrêmement simple et la plupart des améliorations mèneraient à un code plus compliqué. Or, pour le genre de machines pour lesquelles Trickle est prévu, économiser en transmissions de paquets pour finir par faire davantage de calculs ne serait pas forcément optimal.
Enfin, question sécurité, c'est simple, Trickle n'en a pas (section 9). Un méchant peut facilement pousser tous les nœuds à transmettre, épuisant leurs ressources. Et il peut assez facilement empêcher le groupe de converger vers un état stable. Les protocoles qui utilisent Trickle doivent donc définir leurs propres mécanismes de sécurité.
Pour approfondir Trickle, notamment sur ses performances ou son implémentation, les articles recommandés sont « Trickle: a self-regulating algorithm for code propagation and maintenance in wireless sensor networks » et « The emergence of a networking primitive in wireless sensor networks ».
Plusieurs utilisations de Trickle sont mentionnées en section 6.8,
avec références. Trickle est par exemple utilisé dans Contiki : http://www.sics.se/~adam/contiki/contiki-2.0-doc/a00543.html. Damien Wyart s'est attelé à la tâche de trouver d'autres mises en œuvre et voici ses
résultats (je le cite).
« Dans les travaux qui parlent de Trickle, on voit souvent cité Maté, une sorte d'environnement qui permet de mettre en réseau des mini-machines virtuelles (si j'ai bien compris), et certains documents indiquent que Maté contient une implantation de Trickle. Maté est distribué principalement sous forme de RPM, ce qui n'aide pas sur Debian... Il ne semble plus évoluer depuis 2005 (mais l'auteur principal continue à travailler sur TinyOS et peut sans doute être contacté pour obtenir plus de détails sur les implantations de Trickle. De plus, Maté est intimement lié à TinyOS qui a depuis, semble-t-il, beaucoup évolué. »
« Par recoupements (c'est assez rare d'avoir à autant jouer les détectives
entre fichiers RPM, confusion sur les versions et vieux dépôts
CVS ---
TinyOS a maintenant un SVN chez Google Code), je suis arrivé
principalement au fichier http://tinyos.cvs.sourceforge.net/viewvc/tinyos/tinyos-1.x/tos/lib/VM/components/MVirus.nc?view=log. Sur
une copie locale des deux sous-arborescences
tinyos-1.x/tools/java/net/tinyos/script et
tinyos-1.x/tos/lib/VM
(citées dans http://www.eecs.berkeley.edu/~pal/mate-web/downloads.html),
j'arrive à ceci (avec le bien pratique concurrent de grep, ack) :
dw@brouette:/storage/sandbox/tinyos-1.x$ ack -ai trickle
tos/lib/VM/components/MVirus.nc
118: MateTrickleTimer versionTimer;
119: MateTrickleTimer capsuleTimer;
153: void newCounter(MateTrickleTimer* timer) {
tos/lib/VM/doc/tex/mate-manual.tex
615:that has newer code will broadcast it to local neighbors. The Trickle
635:Trickle's suppression operates on each type of packet (version,
645:\subsubsection{Trickle: The Code Propagation Algorithm}
647:The Trickle algoithm uses broadcast-based suppressions to quickly
651:completes, Trickle doubles the size of an interval, up to
662:Trickle maintains a redundancy constant $k$ and a counter
tos/lib/VM/types/Mate.h
168:typedef struct MateTrickleTimer {
173:} MateTrickleTimer;
tools/java/net/tinyos/script/VMFileGenerator.java
524: writer.println(" * MVirus uses the Trickle algorithm for code propagation and maintenance.");
528: writer.println(" * \"Trickle: A Self-Regulating Algorithm for Code Propagation and Maintenance");
549: writer.println(" the timer interval for Trickle suppression, and the redundancy constant");
Cela donne donc des pistes, la partie principale semblant bien être le fichier
MVirus.nc. »
L'article seul
RFC 6195: Domain Name System (DNS) IANA Considerations
Date de publication du RFC : Mars 2011
Auteur(s) du RFC : Donald E. Eastlake 3rd (Motorola)
Première rédaction de cet article le 29 mars 2011
Un RFC un peu bureaucratique, pour détailler les mécanismes utilisés pour l'enregistrement dans les registres de l'IANA des paramètres liés au DNS. Il met très légèrement à jour son prédécesseur, le RFC 5395, qui avait libéralisé l'enregistrement de nouveaux paramètres. Et il a lui-même été remplacé par la suite par le RFC 6895.
Un certain nombre de paramètres, dans le DNS, sont enregistrés à l'IANA, afin de s'assurer d'une interprétation identique partout. C'est ainsi que l'IANA gère un registre des paramètres DNS où on trouve, entre autres, les types d'enregistrement (A, codé 1, pour une adresse IPv4, AAAA, codé 28, pour une adresse IPv6, LOC, codé 29, pour les positions géographiques du RFC 1876, etc). Cet espace n'étant pas de taille infinie, il faut y enregistrer de nouveaux paramètres avec prudence, selon les règles qui étaient expliquées dans le RFC 2929, qui a été sérieusement réformé par le RFC 5395 avant de l'être, beaucoup plus légèrement, par notre RFC 6195.
En effet, les règles du RFC 2929 étaient bien trop strictes à l'usage. Notamment, le processus d'enregistrement d'un nouveau type d'enregistrement était tellement pénible que beaucoup de protocoles (comme SPF à ses débuts) préféraient utiliser le fourre-tout TXT pour y mettre leurs enregistrements. Ce goulet d'étranglement était souvent cité comme un exemple typique des blocages liés à l'IETF.
Le RFC 5395 avait donc assoupli les règles d'enregistrement des types de ressources DNS (les autres règles sont peu changées). Avant, il y avait deux solutions (voir le RFC 5226 pour plus d'explications), IETF Review (ex-IETF Consensus), un processus long et incertain imposant un RFC sur le chemin des normes, approuvé par l'IESG, ou Specification required, qui impose l'écriture d'une norme (pas forcément un RFC) « stable et permanente ».
Le nouveau système est plus léger (section 3.1.1) : il suffit désormais de remplir un formulaire décrivant le nouveau type d'enregistrement (un gabarit figure en annexe A), de le soumettre sur la liste dnsext@ietf.org et d'attendre le jugement d'un expert, désigné parmi les noms fournis par l'IESG, qui décidera, sur la base du formulaire soumis, d'allouer ou pas la requête. Un tel processus est utilisé pour d'autres enregistrements à l'IANA, par exemple pour les nouvelles étiquettes de langue.
Le nouveau processus a été testé pour la première fois pour le
type
d'enregistrement ZS (Zone Status) qui a
été accepté, sous un autre nom, NINFO, et figure désormais sous
le numéro 56 dans le registre
IANA. Autre exemple, plus récent, le type
URI, permettant de stocker des
URI dans le DNS, enregistré en
février 2011, sous le numéro 256. Mais tous les types ne
réussissent pas forcément leur entrée dans le
registre. CAA, qui sert à indiquer
l'autorité de certification du domaine, est
toujours
en discussion.
Quels sont les changements entre le RFC 5395, qui avait marqué l'entrée dans la nouvelle ère, et notre RFC 6195 ? Ils sont minimes (voir annexe B). Le principal est le changement de nom de la liste de diffusion où se discutent les demandes. Autrement, ce sont surtout des petites corrections éditoriales. À son tour, le successeur de notre RFC, le RFC 6895 n'a apporté que de petits changements.
Outre l'enregistrement de nouveaux types de ressources DNS, notre RFC mentionne également d'autres champs des messages DNS. Un changement ou une extension de leur sémantique continue à nécessiter une action plus lourde à l'IETF. Ainsi, le bit RD (Recursion Desired) n'a de signification que dans une question DNS. Dans une réponse, il est indéfini et son éventuelle utilisation future nécessitera un RFC sur le chemin des normes. Même chose pour le dernier bit qui reste libre dans les options, le bit Z. Quant aux opcodes qui indiquent le type du message (requête / notification / mise à jour dynamique / etc), un ajout à leur liste nécessitera le même chemin.
Les codes de réponse (rcodes), comme
NXDOMAIN (nom inexistant) ou
BADTIME (signature trop ancienne ou trop récente,
cf. RFC 8945) sont tirés d'un
espace plus vaste et la procédure est donc un peu plus libérale (section 2.3).
L'article seul
RFC 6203: IMAP4 Extension for Fuzzy Search
Date de publication du RFC : Mars 2011
Auteur(s) du RFC : T. Sirainen
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF morg
Première rédaction de cet article le 27 mars 2011
Où s'arrêtera la liste des extensions au protocole IMAP d'accès aux boîtes aux lettres ? En tout cas, elle ne cesse de grossir. Ce RFC propose une extension aux fonctions de recherche d'IMAP pour permettre des recherches floues, par exemple pour que « hipothèse » puisse trouver « hypothèse ».
Beaucoup de systèmes de recherche disposent de mécanisme analogue,
par exemple le moteur de recherche Google,
lorsqu'on lui soumet la requête erronée citée plus haut propose
« Essayez avec cette orthographe : hypothèse 2 premiers résultats affichés ». Mais IMAP n'avait qu'un service de recherche exact, via la
commande SEARCH (RFC 3501,
section 6.4.4). Notre RFC 6203 l'étend en permettant, via
l'ajout du mot-clé FUZZY, des recherches
floues. Il est important de noter que ce RFC ne spécifie qu'une
syntaxe : la sémantique exacte d'une recherche est laissée à
chaque mise en œuvre, et on peut penser qu'elle évoluera avec
les progrès de la recherche floue. Ainsi, pour prendre un exemple,
est-ce que « Penelope » trouvera les textes sur Pénélope ? Le RFC ne
le spécifie pas, laissant chaque serveur IMAP ajouter les algorithmes de
recherche floue qu'il préfère.
La syntaxe exacte figure en section 3. Un mot-clé,
FUZZY, enregistré dans le registre
IANA d'IMAP, préfixe le critère de recherche, comme
dans, par exemple :
C: MYTAG1 SEARCH FUZZY (SUBJECT "balade dames jadisse") S: * SEARCH 1 5 10 S: MYTAG1 OK Search completed.
Et on trouvera peut-être (selon l'implémentation) un message dont le sujet était « La ballade des dames du temps jadis » (et merci à ma fille pour une intéressante discussion sur balade / ballade). Je répète que c'est le serveur qui décidera du niveau de flou acceptable, le RFC ne fournit pas de guide à ce sujet.
Le mot-clé FUZZY s'applique au critère qu'il
préfixe, pas à
toute la recherche. Donc :
C: MYTAG2 SEARCH FUZZY (SUBJECT "balade dames jadisse") FROM francois@villon.fr S: * SEARCH 1 4 S: MYTAG2 OK Search completed.
fera une recherche floue sur le sujet mais une recherche exacte sur l'auteur.
Les recherches floues vont évidemment renvoyer davantage de
résultats que les recherches exactes et le tri de ces résultats, par
pertinence, est donc essentiel. La section 4 décrit donc le mécanisme
de pertinence. Le RFC recommande très fortement aux serveurs IMAP qui
mettent en œuvre FUZZY d'affecter une
grandeur entre 0 et 100 à chaque résultat, indiquant la pertinence. Si
le serveur accepte également l'extension ESEARCH
(RFC 4731), celle-ci peut servir à récupérer
les valeurs de pertinence, avec la nouvelle option de
RETURN, RELEVANCY :
C: MYTAG3 SEARCH RETURN (RELEVANCY ALL) FUZZY TEXT "Bnjour" S: * ESEARCH (TAG "MYTAG3") ALL 1,5,10 RELEVANCY (4 99 42) S: MYTAG3 OK Search completed.
Les exemples ci-dessus utilisaient la recherche floue avec des chaînes de caractère. Mais la norme ne se limite pas à ces chaînes, comme le précise la section 5. Un serveur peut donc décider de permettre des recherches floues pour d'autres types de données et le RFC donne des indications sur les types pour lesquels c'est utile :
- Les dates, pour permettre des recherches comme « il y a une semaine, à peu près », la pertinence décroissant lorsqu'on s'éloigne de la date indiquée,
- Les tailles, pour chercher des messages d'« environ un Mo »,
- Alors qu'en revanche les recherches par UID (RFC 3501, section 2.3.1.1) n'ont sans doute aucune raison d'être floues.
Le concept de pertinence s'applique aussi à la commande
SORT (section 6). On peut donc trier les messages
selon la pertinence :
C: MYTAG4 SORT (RELEVANCY) UTF-8 FUZZY SUBJECT "Bjour" S: * SORT 5 10 1 S: MYTAG4 OK Sort completed.
Si vous être programmeur et que vous ajoutez cette capacité de flou à un serveur IMAP existant, lisez bien la section 8 sur la sécurité. En effet, les recherches floues peuvent consommer bien plus de ressources du serveur et faciliter ainsi des attaques par déni de service.
D'autre part (comme, là encore, avec les moteurs de recherche du Web), les recherches floues peuvent être plus susceptibles d'empoisonnement par des méchants qui glisseraient dans les messages de quoi apparaître en tête du classement.
Et quelles sont les implémentations existantes de cette extension ? Il y en a apparemment au moins deux mais j'ai été trop paresseux pour chercher lesquelles, comptant sur les lecteurs pour me les signaler.
L'article seul
RFC 6177: IPv6 Address Assignment to End Sites
Date de publication du RFC : Mars 2011
Auteur(s) du RFC : Thomas Narten (IBM), Geoff Huston (APNIC), Lea Roberts (Stanford University)
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 27 mars 2011
Ce RFC vient remplacer le RFC 3177 et modifier assez sérieusement les recommandations en matière d'allocation d'adresses IPv6 aux sites situés aux extrémités du réseau (entreprises, universités, particuliers, à l'exclusion des FAI et des opérateurs). Le RFC 3177 recommandait, en gros, de donner un préfixe de même longueur, un /48, à tout le monde. Ce nouveau RFC 6177 met un sérieux bémol à cette recommandation.
Le RFC 3177 avait été publié en
2001 et mis en œuvre par les
RIR dans leurs politiques d'allocation
d'adresses (celle du RIPE-NCC est en http://www.ripe.net/ripe/docs/ipv6policy.html). À partir de 2005, plusieurs
critiques se sont fait jour (voir par exemple la
proposition 2005-08), menant à une révision de ces politiques
et à ce nouveau RFC 6177. Les critiques portaient aussi
bien sur la technique (un /48 n'est-il pas excessif ?) que sur la
politique (est-ce vraiment le rôle de l'IAB et
de l'IETF de recommander des politiques
d'allocation ?). Résultat, le « /48 pour tous » n'est plus la
politique officielle.
La section 1 de notre nouveau RFC rappele les principaux changements par rapport au RFC 3177 :
- La possibilité de distribuer des /128 (une seule adresse IPv6) est retirée, un site comprend forcément plusieurs machines,
- Les valeurs numériques explicitement indiquées par le RFC 3177, /48, /64 et /128, ne sont plus mentionnées, de crainte qu'elles ne deviennent « sacrées » et soient, par exemple, codées en dur dans certaines mises en œuvre d'IPv6, ce qui n'avait pas été prévu,
- Et, la plus spectaculaire, le retrait de la recommandation d'un /48 pour tous les sites. Il n'y a désormais plus de recommandation officielle de l'IETF, la taille des allocations devant être décidée par les RIR. (On notera que c'est un changement de gouvernance : les RIR, émanation des opérateurs réseau, sont moins favorables que l'IETF aux demandes des utilisateurs.) À titre d'exemple, voici la politique d'APNIC.
Mais alors, que reste-t-il du RFC 3177 ? Le principe comme quoi un site ne devrait pas avoir à geindre et à supplier pour avoir suffisamment d'adresses. En IPv4, la rareté des adresses justifiait les obstacles mis devant les utilisateurs mais, en IPv6, cet argument ne joue plus. Les sites devraient donc toujours avoir les adresses dont ils ont besoin, et ne jamais être contraints à utiliser des techniques comme le NAT pour économiser des adresses, ces économies étant tout à fait inutiles avec IPv6.
La question de l'allocation d'un /48 aux sites d'extrémité est discutée dans la section 2. La recommandation du RFC 3177 était fondée sur trois motivations :
- Garantir que ces sites auraient suffisamment d'adresses et donc décourager fortement les pratiques malthusiennes de certains FAI comme par exemple, celle de ne donner qu'une seule adresse IPv4, ce qui est compréhensible vue la pénurie mais gêne les sites qui ont plusieurs machines, ce qui est pourtant banal aujourd'hui, même chez le particulier. La plupart du temps, obtenir autant d'adresses IPv4 qu'on a de machines nécessite de passer à un abonnement beaucoup plus cher, sans que cela soit justifié par le coût de ces adresses.
- La seconde motivation, et qui était souvent oublié par les
adversaires du « /48 pour tous », était de faciliter le changement de
FAI. Si certains FAI fournissent un /56 à un site et d'autres un /60,
le passage du premier au second nécessitera de refaire les plans
d'adressage (puisqu'il y a moins de sous-réseaux disponibles) alors que, si tout le monde propose un /48, le changement
de fournisseur ne nécessite qu'un changement de préfixe (ce qui est en
général très simple avec IPv6). Même chose pour l'administration du
DNS, les zones dans
ip6.arpaseront plus simples à gérer si on change juste de préfixe, sans avoir à réorganiser ses sous-réseaux. L'idée d'une même taille d'allocation pour tous (de la grande université au particulier) est donc une mesure de protection du client, de garantie qu'il n'y aura pas d'obstacle artificiel à un changement de fournisseur. - La troisième motivation de la recommandation du RFC 3177 était de faciliter la croissance des réseaux. Ceux-ci peuvent souvent dépasser les prévisions (une école connecte le bureau du directeur, puis une salle de classe, puis finalement on connecte tout) et les plans d'adressage prudents d'IPv4, conçus pour ne demander que le nombre d'adresses strictement nécessaire, ont souvent gêné la croissance d'un réseau.
Mais, alors, quels sont les problèmes perçus avec cette recommandation du « /48 pour tous » ? D'abord, certains trouvent qu'elle mène au gaspillage. (Je pense personnellement que c'est un argument subjectif, sans base scientifique : il existe 280 billions de /48 disponibles, ce qui fait qu'on n'épuisera pas IPv6 en en donnant un à chacun.) Les partisans de cet argument disent souvent qu'on pourrait ne donner qu'un /64 aux particuliers (ce que fait aujourd'hui un FAI comme Free), oubliant qu'une maison bien dotée en appareils numériques peut avoir besoin de plusieurs réseaux, pas seulement d'adresses, et que, avec l'auto-configuration des adresses IPv6, il faut un /64 par réseau. Notre RFC 6177 demande donc qu'on donne à tous davantage qu'un /64 (un /56 est cité comme possibilité).
Notons que notre RFC 6177 ne traite pas explicitement le cas des hébergeurs de serveurs dédiés comme Gandi ou OVH. Par exemple, Gandi ne permet apparemment qu'une seule adresse IPv6 par machine, rendant ainsi difficile d'y faire tourner plusieurs serveurs. (Pour OVH, l'information est en ligne, avec l'orthographe habituelle de ce fournisseur.)
Le RFC 3177 contenait d'autres points (section 3). Par exemple, il rappelait explicitement que la règle d'un /48 pour tous limitait le pouvoir des intermédiaires : sans avoir à demander, sans remplir de paperasserie, l'utilisateur avait droit à une quantité d'adresses suffisante. C'est hélas quelque chose qui sera différent désormais, l'utilisateur devra à nouveau affronter un bureau insensible pour avoir la quantité d'adresses nécessaire.
L'article seul
Michel Riguidel est un imposteur
Première rédaction de cet article le 25 mars 2011
Dernière mise à jour le 26 mars 2011
Je m'étais dit que je n'allais pas me livrer aux attaques personnelles contre Michel Riguidel, malgré les innombrables inepties dont il inonde régulièrement les médias à propos de l'Internet. Néanmoins, comme il continue, et semble disposer de bons relais médiatiques (il vient d'obtenir un article dans le Monde et, apparemment, un certain nombre de personnes croient qu'il est expert en réseaux informatiques), j'ai décidé qu'il était temps de dire clairement que Riguidel est à l'Internet ce que les frères Bogdanoff sont à l'astrophysique.
Il y a longtemps que Michel Riguidel est... disons, « dans une autre sphère ». Rappelons-nous son immortel appel à la lutte contre les « photons malveillants » dans le journal du CNRS, sa mobilisation contre les « calculs illicites » et son show au forum Atena. Comme, sur les questions scientifico-techniques, les médias de référence ne remettent jamais en cause leur carnet d'adresses, il suffit d'avoir travaillé sur un domaine il y a de nombreuses années, et on est un expert à vie, même dans les domaines assez éloignés (cf. Claude Allègre parlant du réchauffement climatique). Le tout peut être aidé par des titres ronflants comme « professeur émérite » (titre purement honorifique qui ne signifie rien et semble s'obtenir assez facilement) Riguidel a donc obtenu pas mal de place dans le Monde, pour nous expliquer que les Mayas avaient mal déterminé la fin du monde, celle-ci surviendra, non pas en 2012 mais en 2015, suite à une « imprégnation de la réalité physique et humaine par l'informatique » (la fusion des robots et des humains, si j'ai bien compris son gloubi-boulga pseudo-philosophique).
Certaines personnes de bonne foi m'ont demandé si je pouvais répondre techniquement et concrètement à ses articles. Mais non, je ne peux pas ! On peut argumenter contre un point de vue opposé, on ne peut pas répondre à des textes qui ne sont « même pas faux », dont il n'est tout simplement pas possible de voir quels sont les éléments concrets, suspectibles d'analyse scientifique.
Prenons l'exemple de son long texte contre la neutralité du réseau. (Malheureusement, il ne semble plus en ligne. Florian Lherbette a fouillé et a trouvé une copie dans le cache de Yahoo que je mets en ligne sans autorisation et sans authentification. Je demande donc à mes lecteurs de me faire confiance pour les citations ci-dessous. Remarquez, en les lisant, on comprend que Riguidel n'ait pas republié ce texte ailleurs.) On ne peut pas le corriger techniquement, il ne contient que des envolées et du charabia (qui peut passer pour de la technique auprès d'un journaliste de Sciences et Vie). Tout son article mérite un prix global, ainsi que des prix spécialisés.
Prix des faits massacrés : « Internet a été inventé par quelques fondateurs, et rien n'a réellement changé techniquement depuis 1973. » En 1973, IPv4, TCP, le DNS et BGP n'existaient pas... (Et ils n'avaient aucun équivalent, la couche 3 et 4 n'étaient pas encore séparées, par exemple.)
Prix de la frime : « En effet, sur un clavier, il est impossible d'obtenir des octaves, des tierces, des quintes pures dans chacune des tonalités et le demi-ton dièse et bémol ne produit qu'un son unique, contrairement aux instruments comme le violon où il est possible de diviser un ton en 9 commas et de distinguer un sol dièse d'un la bémol. »
Prix de la langue française : Akamai, que Riguidel écrit Akamaï.
Prix d'Économie, option Capitalisme : « mieux vaut faire du MPLS de transaction financière entre Boston et Los Angeles que de faire de la Voix sur IP entre Paris et Dakar ! »
Prix du gloubi-boulga technologique : « Les success stories (comme Skype) récentes sont souvent des applications qui utilisent une liaison étroite entre l'application et le réseau, avec des protocoles (STUN : RFC 3489 de l'IETF [...]), ouverts mais agressifs dans le but de transpercer les architectures sécurisées. » alors que Skype, service ultra-fermé, n'utilise pas le protocole standard STUN (qui est d'ailleurs dans le RFC 5389).
Prix Robert Langdon : « Pour injecter de la sémantique dans les « tuyaux » et sur les flux d'information des réseaux filaires (IP, MPLS) et des réseaux sans fil de diverses technologies (environnement radio 3G, Wi-Fi, WiMAX), on exhibe le volet cognitif par une infrastructure de phares et de balises. On colle un système d'étiquettes sur les appareils de communication (point d'accès Wi-Fi, antennes WiMAX, boîtier ADSL , routeurs IP) et sur les trames Ethernet des flux d'information. Ces étiquettes constituent, par combinaison de symboles, un langage. »
Prix de l'envolée : « C'est cette « épaisseur des signes » de la boîte grise de la communication qui permettrait d'éclairer une nouvelle perspective de la neutralité informatique, en accord avec la science, la technologie et l'économie. »
J'arrête là. L'article récent du Monde est de la même eau. Mais Riguidel n'est pas qu'un pittoresque illuminé. C'est aussi quelqu'un qui est cité comme expert dans des débats politiques, comme la neutralité du réseau, citée plus haut ou comme l'HADOPI dont il est le collaborateur technique (tout en détenant des brevets sur les techniques que promeut l'HADOPI. Celle-ci, dont l'éthique est limitée n'y voit pas de conflit d'intérêts). Si Michel Riguidel n'était qu'un amuseur public, plutôt inoffensif, je ne ferais pas un article sur lui. Mais c'est aussi un promoteur de la répression (« Il est urgent d'inventer des instruments de sécurité, opérés par des instances légales. » dans l'article du Monde, glaçant rappel de la LOPPSI ou bien « Ceux qui n'ont rien à se reprocher n'ont rien à craindre. » dans l'article du journal du CNRS), un adversaire de la neutralité du réseau et un zélateur de l'organisation de défense de l'industrie du divertissement.
Pourquoi est-ce que des organisations, certes répressives et vouées à défendre les revenus de Johnny Halliday et Justin Bieber, mais pas complètement idiotes, comme l'HADOPI, louent-elles les services de Riguidel ? Parce qu'elles sont bêtes et n'ont pas compris qu'il était un imposteur ? Certains geeks voudraient croire cela et pensent que l'HADOPI est tellement crétine qu'elle n'est pas réellement dangereuse. Mais ce serait une illusion. L'HADOPI sait parfaitement que Riguidel n'est pas sérieux. Mais son usage par cette organisation est un message fort : HADOPI a choisi Riguidel pour bien affirmer qu'elle se fiche de la technique, il s'agit juste de prouver qui est le plus fort, au point de n'avoir même pas besoin de faire semblant de s'y connaître. Avoir un imposteur comme consultant technique est une façon de dire clairement aux geeks : « on se fiche pas mal de vos critiques techniques, nous, on a le Pouvoir ».
Et pourquoi des journaux « sérieux » comme le Monde lui laissent-ils tant d'espace ? En partie parce que personne n'ose dire franchement que Riguidel n'est pas un expert mais un souffleur de vent. Et en partie parce qu'il faut bien remplir le journal, que le contenu de qualité est rare, et qu'un histrion toujours volontaire pour pondre de la copie est la providence des journalistes paresseux. (Heureusement, les commentaires des lecteurs, après l'article, sont presque tous de qualité et, eux, ils correspondent à la réputation traditionnelle du journal.)
Sur le thème de l'article du Monde (la catastrophe planétaire par extinction d'Internet), on peut lire des articles plus informés comme le mien ou comme le dossier de l'AFNIC sur la résilience. Sur l'article du Monde, voir aussi un très bon point de vue dans un blog du Monde, l'analyse de PCinpact et celle de Numérama. Si vous trouvez les commentaires trop favorables à ma thèse, lisez l'article de ZDnet où les commentaires mettent en doute mes compétences, mon savoir-vivre, ou la « technoscience » en général.
L'article seul
RFC 6182: Architectural Guidelines for Multipath TCP Development
Date de publication du RFC : Mars 2011
Auteur(s) du RFC : A. Ford (Roke Manor Research), C. Raiciu, M. Handley (University College London), S. Barre (Université catholique de Louvain), J. Iyengar (Franklin and Marshall College)
Pour information
Réalisé dans le cadre du groupe de travail IETF mptcp
Première rédaction de cet article le 23 mars 2011
Plusieurs efforts ont déjà été déployés pour avoir un protocole de transport qui puisse utiliser plusieurs chemins simultanés, pour le cas où deux machines disposent de plusieurs moyens de se joindre. Le projet « Multipath TCP » dont voici le premier RFC se distingue par le fait que son trafic apparaîtra comme du TCP habituel, aussi bien aux applications qu'aux équipements intermédiaires situés sur le réseau.
L'idée de base de tous ces efforts est : il arrive qu'entre deux machines A et B, il existe plusieurs chemins possibles, par exemple si A et B sont tous les deux connectés à au moins deux FAI (cf. section 1.3). Utiliser simultanément ces deux chemins permettrait d'augmenter la capacité disponible (et donc le débit effectif) et d'augmenter la résilience (en cas de panne d'un chemin pendant la connexion, on utiliserait automatiquement l'autre). TCP ne permet pas cela, puisqu'il est lié à des adresses IP source et destination qui ne changent pas. Des protocoles de couche 4 comme SCTP (RFC 4960) ont déjà exploré cette voie. Mais ils souffrent d'un double problème : il faut parfois adapter les applications, qui s'attendent à la sémantique de TCP, et il faut être sûr que le chemin complet soit de l'IP propre. Or, cela est rare dans l'Internet aujourd'hui, que des incompétents ont truffé de boîtiers intermédiaires non transparents et qui rendent le déploiement de tout nouveau protocole très difficile.
Pourtant, pouvoir mettre en commun la capacité de plusieurs chemins est tellement tentant que d'autres projets ont vu le jour. C'est ainsi que le groupe de travail mptcp de l'IETF a été créé pour mettre au point une architecture, Multipath TCP et un protocole mettant en œuvre cette architecture, MPTCP (le RFC normalisant ce protocole étant encore en cours d'élaboration).
Comme son nom l'indique, l'idée de base est de ne pas trop s'éloigner du TCP actuel, afin d'assurer une compatibilité à la fois avec les applications actuelles et avec le réseau actuel, les deux points sur lesquels SCTP a largement achoppé. SCTP est donc plus propre, plus conforme à l'architecture originale de l'Internet mais Multipath TCP est peut-être plus réaliste. (Notre RFC 6182 ne cite pas SHIM6 - RFC 5533 - mais celui-ci possède pas mal de points communs avec SCTP, notamment un très faible déploiement dans l'Internet actuel.)
La section 2 précise les buts de l'architecture Multipath TCP. Du point de vue des fonctions, on voudrait :
- Augmenter le débit, par l'utilisation simultanée de davantage de ressources réseaux. Plus formellement, l'utilisation de Multipath TCP doit mener à un débit au moins égal à celui du meilleur des chemins.
- Augmenter la résistance aux pannes. La résistance totale de Multipath TCP doit être au moins aussi bonne que celle du chemin le plus fiable.
Notons que SCTP n'avait que le second but (SCTP ne permet pas actuellement d'envoyer des paquets sur différents chemins, cf. section 2.4). Naturellement, il faut en outre que le tout se fasse automatiquement : une machine MPTCP doit pouvoir trouver seule si son partenaire est également MPTCP et basculer automatiquement vers le nouveau protocole.
Mais, tout aussi importants que les fonctions sont les critères de compatibilité avec l'Internet d'aujourd'hui :
- Compatibilité avec les applications : l'API doit rester la même et les services rendus à l'application doivent être les mêmes (délivrance des octets dans l'ordre, et sans perte). Ainsi, on doit pouvoir passer à Multipath TCP uniquement en mettant à jour le système d'exploitation, sans réécrire les applications. Il est souhaitable que l'API soit étendue pour permettre une utilisation (optionnelle) des fonctions spécifiques de Multipath TCP. Enfin, petite exception à cette compatibilité, une application qui s'attendrait à un débit très régulier peut être surprise par Multipath TCP, qui aura probablement des débits et des latences moins constants. La section 6 donne des détails sur les relations entre Multipath TCP et les applications.
- Compatibilité avec le réseau : Multipath TCP devra fonctionner avec l'Internet tel qu'il est aujourd'hui. Or, comme l'illustrent très bien les figures 2 et 3 du RFC, l'architecture de l'Internet a changé, de fait. Elle était censée offrir un lien IP transparent, de façon à ce que la première couche « de bout en bout » soit la couche 4. En fait, l'Internet d'aujourd'hui est truffé de middleboxes qui ont souvent un rôle actif dans la couche 4 (terminaison de connexions, par exemple, ou bien filtrage des protocoles de couche 4 inconnus) et donc, de fait, la première couche de bout en bout aujourd'hui est la couche 7. La section 7 revient en détail sur cette interaction entre Multipath TCP et les middleboxes.
- Compatibilité avec les utilisateurs existants : Multipath TCP ne doit pas « voler » de la capacité réseau aux utilisateurs du TCP normal (mais pas non plus être trop poli et les laisser tout prendre).
La deuxième exigence de compatibilité, celle avec le réseau, va donc être difficile à assurer. Mais elle est nécessaire pour le succès de Multipath TCP, les innombrables middleboxes programmées avec les pieds et configurées n'importe comment étant un puissant frein au déploiement de tout protocole de transport qui ne serait pas TCP ou UDP.
Multipath TCP a également des contraintes en terme de sécurité : la section 2.3 impose qu'il n'aggrave pas la situation par rapport à TCP.
Une fois les buts exposés, comment les atteindre ? la section 3 décrit l'architecture de Multipath TCP. En gros, Multipath TCP part des idées exposées dans « Breaking Up the Transport Logjam » de Ford & Iyengar : séparation de la couche transport en deux, une demi-couche haute « sémantique » (service aux applications, fonctionnant de bout en bout) et une demi-couche basse « flot et terminaison » (pas forcément de bout en bout, si des middleboxes sont présentes).
La section 4 de notre RFC descend ensuite dans le concret. On passe de l'architecture, Multipath TCP, au protocole, MPTCP. Le principe de base de MPTCP est de répartir chaque connexion TCP en plusieurs « sous-connexions », chacune d'entre elles apparaissant à un observateur extérieur comme une connexion TCP complète et normale (et aura donc de bonnes chances de passer à travers les NAT et autres horreurs). Les méta-informations spécifiques à MPTCP seront transportées à part. MPTCP aura les tâches suivantes :
- Gérer les chemins : cela veut surtout dire les découvrir, essentiellement via la présence de plusieurs adresses IP sur une même machine. On pourra aussi utiliser ECMP (RFC 2992).
- Gérer les paquets : les octets transmis par l'application doivent être répartis entre les différents chemins. Cela implique la remise dans l'ordre à la destination, puisque des paquets ont pu voyager par des chemins différents.
- Gérer chaque sous-connexion : c'est relativement facile, chacune est une connexion TCP habituelle.
- Contrôler qu'il n'y a pas de congestion.
La section 5 rappelle les choix techniques importants de MPTCP et leurs raisons. Ainsi de la façon de numéroter les octets. La section 5.1 explique qu'il y avait deux façons :
- Un seul espace de numérotation, pour toute la connexion MPTCP. Cela aurait facilité le réassemblage des octets issus de chaque sous-connexion mais cela aurait rendu les sous-connexions bizarres, puisque les séquences auraient été incomplètes. Des engins comme les IDS auraient alors pu décider de couper ces connexions bizarres.
- La solution choisie a donc été d'avoir un espace de numérotation par sous-connexion, de façon à ce que chacune de celles-ci ressemble vraiment parfaitement à une connexion TCP traditionnelle. Cela implique par contre de conserver (et de transmettre au pair) la correspondance entre les numéros de séquence de la sous-connexion et ceux de la connexion complète.
Autre choix délicat, les retransmissions en cas de perte. Chaque sous-connexion étant du TCP normal, elle a un système d'accusé de réception. Mais si des données sont perdues, par exemple lors du réassemblage des sous-connexions, on ne peut pas utiliser les mécanismes TCP normaux pour demander une réémission puisque ces données ont déjà fait l'objet d'un accusé de réception. Il y a donc également un système d'accusés de réception et de réémission au niveau de la connexion MPTCP globale.
Plusieurs des fonctions de MPTCP nécessitent donc un mécanisme de signalisation entre les deux pairs, par exemple au démarrage lorsqu'il faut signaler au pair TCP qu'on sait faire du MPTCP. La section 5.4 explore l'espace des choix : les options TCP (RFC 793, section 3.1) ont été retenues pour cette signalisation, de préférence à un encodage TLV dans les données. Les options sont la solution standard de TCP et la seule propre. Elle présentent toutefois une limitation, leur faible taille, et un risque : certaines middleboxes massacrent les options (section 7 et voir aussi par exemple l'excellente étude de Google Probing the viability of TCP extensions).
Et comment va t-on identifier une connexion MPTCP ? Traditionnellement, l'identificateur d'une connexion TCP était un quadruplet {adresse IP source, adresse IP destination, port source, port destination}. La connexion MPTCP, reposant sur plusieurs connexions TCP, ne peut pas utiliser un de ces identificateurs (puisqu'il risque de ne plus rien signifier si la connexion TCP associée casse). MPTCP devra donc développer un nouvel identificateur (section 5.6). Cela limitera d'ailleurs la compatibilité de MPTCP avec les anciennes applications, qui n'utiliseront comme identificateur celui de la première connexion TCP. Si celle-ci défaille ultérieurement, la connexion MPTCP entière pourra avoir un problème.
L'Internet étant ce qu'il est, tout nouveau protocole apporte un lot de nouveaux problèmes de sécurité (section 5.8). Le cas de la sécurité de Multipath TCP est traité plus en détail dans un futur RFC « Threat Analysis for TCP Extensions for Multi-path Operation with Multiple Addresses ». En attendant, les propriétés de sécurité essentielles attendues sont :
- Permettre de vérifier que les pairs qui négocient une sous-connexion TCP sont bien les mêmes que ceux qui avaient négocié la première sous-connexion de la connexion MPTCP.
- Avant d'ajouter une adresse à la liste, permettre de vérifier que le pair peut recevoir du trafic à cette adresse, pour éviter qu'un pair MPTCP ne vous fasse attaquer un tiers innocent.
- Protéger contre le rejeu.
Atteindre ces objectifs ne va pas être facile pour MPTCP : le choix d'utiliser les options TCP limite sévèrement la quantité d'information qu'on peut transmettre et le choix de permettre qu'une middlebox s'interpose oblige à compter avec le fait que certains paquets seront modifiés en transit.
Revenons aux applications (section 6). Il y aura un certain nombre de points de détail qu'elles vont devoir gérer. Par exemple, si l'application se lie explicitement à une adresse particulière de la machine, MPTCP ne doit pas être utilisé (puisque l'application a marqué une préférence pour une adresse donnée).
L'interaction avec les équipements intermédiaires fait l'objet d'une étude plus approfondie en section 7. MPTCP ne sera pas déployé dans un réseau idéal, un réseau qui ne fournirait que de la délivrance de datagrammes IP. Au contraire, il opérera au milieu d'une jungle de middleboxes toutes plus mal programmées les unes que les autres : routeurs NAT, pare-feux, IDS, PEP, etc. Toutes ont en commun d'optimiser les applications d'aujourd'hui au détriment de celles de demain. En effet, violant la transparence du réseau, elles rendent très difficiles de déployer de nouvelles techniques qui font des choses inattendues. La section 7 donne une liste détaillées des différentes catégories de middleboxes et de leur influence possible. Ansi, certains pare-feux mélangent les numéros de séquence TCP (pour protéger les systèmes bogués qui ne choisissent pas le numéro initial au hasard). Si un tel équipement se trouve sur le trajet, l'émetteur TCP ne sait même pas quel numéro de séquence sera vu par le récepteur ! Quant aux IDS, ne connaissant pas MPTCP, ils trouveront peut-être suspect cet établissement de multiples connexions. À moins qu'ils ne comprennent pas que ces connexions sont reliées, ratant ainsi certaines informations transportées. (Imaginons une attaque transmise par MPTCP, où les différentes parties de l'attaque arrivent par des chemins séparés...).
Comme indiqué, MPTCP n'est pas encore complètement spécifié. Seule
l'architecture générale est choisie. Il n'est donc pas étonnant qu'on
n'en trouve pas encore d'implémentations officielle, que ce soit dans
Linux ou dans
FreeBSD. Néanmoins, le travail est déjà en
cours sur Linux à l'Université de
Louvain qu'on peut tester selon les instructions en http://mptcp.info.ucl.ac.be/.
L'article seul
RFC 6179: The Internet Routing Overlay Network (IRON)
Date de publication du RFC : Mars 2011
Auteur(s) du RFC : F. Templin (Boeing Research & Technology
Expérimental
Réalisé dans le cadre du groupe de recherche IRTF RRG
Première rédaction de cet article le 21 mars 2011
Sous la houlette du groupe de travail RRG (Routing Research Group) de l'IRTF, un gros effort est en cours pour définir une nouvelle architecture de routage pour l'Internet. Cette future architecture doit permettre de poursuivre la croissance de l'Internet sans se heurter aux limites quantitatives des routeurs, et en autorisant des configurations qui sont actuellement peu pratiques comme le multi-homing. Cet effort a été synthétisé dans les recommandations du RFC 6115. La plupart des propositions d'architecture résumées dans le RFC 6115 seront sans doute publiées, chacune dans son RFC. Notre RFC 6179 ouvre la voie en décrivant le système IRON (Internet Routing Overlay Network).
IRON fait partie de la famille des architectures Map-and-Encap où les réseaux ont un identificateur indépendant de leur position dans le réseau et où les routeurs doivent utiliser un mécanisme de mapping, de correspondance entre l'identificateur connu et le localisateur cherché, avant d'encapsuler les paquets, pour qu'ils puissent atteindre leur destination via un tunnel. L'originalité d'IRON est de combiner mapping et routage pour distribuer l'information nécessaire aux routeurs. Comme les autres architectures Map-and-Encap (par exemple LISP), IRON ne nécessite pas de changement dans les machines terminales, ni dans la plupart des routeurs, mais seulement dans les routeurs d'entrée et de sortie des tunnels.
Comme IRON utilise une terminologie très spéciale, qu'on ne trouve pas dans les autres protocoles, cela vaut la peine, si on veut lire ce RFC, de bien apprendre la section 2, qui décrit le vocabulaire. IRON est donc un système d'overlay, c'est-à-dire de réseau virtuel fonctionnant au dessus d'un réseau « physique », l'Internet. Il part de RANGER RFC 5720 en le généralisant à tout l'Internet. En partant du bas (la description du RFC, c'est peut-être symptomatique, part du haut), chaque organisation connectée à IRON (un EUN pour End User Network) aurait un préfixe à elle, un identificateur, nommé le EP (EUN Prefix). Ces préfixes viennent de préfixes plus larges, les VP (Virtual Prefix), qui sont alloués par de nouvelles organisations, les VPC (Virtual Prefix Companies). Ces organisations n'ont pas d'équivalent dans l'Internet actuel : les VPC pourraient être des FAI mais ce n'est pas obligatoire. Le RFC ne donne aucun détail sur les points non-techniques de cette architecture (par exemple, comment une VPC gagnera sa vie ? Si on change de VPC, pourra t-on garder son préfixe ?) considérant que ces questions sont hors-sujet pour une spécification technique.
Les routeurs IRON se connectent entre eux par des liens NBMA qui sont simplement des tunnels au dessus de l'Internet existant.
Toujours dans le vocabulaire original (IRON n'utilise pas les termes d'ITR - Ingress Tunnel Router - et ETR - Egress Tunnel Router - probablement parce que son architecture ne colle pas bien à ce modèle), IRON repose sur trois types de routeurs (appelés collectivement agents) :
- Le client est le routeur chez l'EUN, l'organisation terminale (entreprise, association, université, etc). Il connait les EP de l'organisation et se connecte au « réseau » IRON (éventuellement via du NAT). La section 3.1 détaille ces clients.
- Le serveur appartient à la VPC et il reçoit les « connexions » des EUN qui hébergent les clients. La section 3.2 le décrit complètement.
- Le relais appartient également à la VPC et assure l'interconnexion avec l'Internet actuel, pour les correspondants qui ne sont pas dans IRON. Il va donc parler BGP avec les routeurs actuels et utiliser les protocoles IRON avec les autres relais. Il est présenté complètement en section 3.3.
Les détails de l'architecture sont ensuite détaillés en sections 3 à 6. Les agents IRON (les trois sortes de routeurs présentées plus haut) forment des tunnels entre eux, en utilisant la technique VET (Virtual Enterprise Traversal, RFC 5558) et encapsulent selon le format SEAL (Subnetwork Encapsulation and Adaptation Layer, RFC 5320). Curieusement, l'auteur prend soin de préciser que SEAL permet de tunneler d'autres protocoles qu'IP et il cite CLNP, ce qui donne une idée de l'âge des idées qui sont derrière SEAL...
SEAL dispose d'un protocole d'échange d'informations sur les routes, les MTU, etc, SCMP (SEAL Control Message Protocol) et c'est lui qui permet à l'overlay IRON de fonctionner.
Chaque VPC représente donc un morceau d'un patchwork global. Les morceaux sont connectés entre eux via l'Internet public. Le client final, lui, doit se connecter à l'Internet puis acquérir une connectivité IRON auprès d'une VPC, et s'équiper d'un routeur client qui va relier son EUN (son réseau local) à la VPC.
Pour amorcer la pompe (section 5), chaque relais est configuré avec la liste des VP qu'il va servir, la liste des serveurs (les routeurs des VPC), et avec celle de ses voisins BGP. Avec ces derniers, il établit des liens comme aujourd'hui et annonce sur ces liens les VP. Avec les serveurs, le relais découvre la correspondance entre les EP, les identificateurs des réseaux IRON et les serveurs. (Rappelons que les identificateurs, EP et VP, ont la même forme que des adresses IP et peuvent donc être annoncés comme tels aux routeurs BGP actuels.)
Les serveurs, eux, sont nourris avec la liste des relais, auxquels ils vont transmettre les VP qu'il servent. Ils attendent ensuite les connexions des clients, apprenant ainsi petit à petit les EP connectés, que les serveurs transmettront aux relais.
Les clients, eux, auront besoin de connaître les serveurs de leur VPC, ainsi que leurs EP, et un moyen de s'authentifier.
Une fois tout ceci fait, les routeurs n'ont plus qu'à router les paquets comme aujourd'hui (section 6, qui décrit les différents cas, notamment selon que le destinataire du paquet est dans IRON ou pas ; par exemple, le cas du multi-homing est en section 6.5.2, qui précise qu'un client peut avoir plusieurs localisateurs pour un même EP).
Et d'une manière plus générale, comment cela va se passer en pratique ? La section 7 se lance dans certains détails concrets. Par exemple, comme le routage à l'intérieur d'IRON est souvent sous-optimal, mais qu'un mécanisme d'optimisation des routes permet de les raccourcir par la suite, le premier paquet de chaque flot aura sans doute un temps de trajet bien supérieur à celui de ses copains.
Et, comme toute solution utilisant des tunnels, IRON aura sans doute à faire face à des problèmes de MTU, que cette section mentionne, mais jette un peu rapidement à la poubelle.
Toujours pour ceux qui s'intéressent aux problèmes concrets, l'annexe B est une très bonne étude des propriétés de passage à l'échelle d'IRON.
IRON ne semble pas avoir été testé, même en laboratoire, même tout simplement dans un simulateur. Et mon avis personnel ? Je dois avouer n'avoir pas tout compris et avoir la sensation inquiétante que ce n'est pas uniquement une limite de mon cerveau, mais que l'architecture d'IRON reste encore insuffisamment spécifiée.
L'article seul
IRIS ou bien un whois REST ?
Première rédaction de cet article le 18 mars 2011
À la réunion ICANN de San Francisco, le 16 mars, un intéressant débat a eu lieu autour de la question de l'évolution technique de whois : son successeur théorique, IRIS, a t-il une chance, face à la mode actuelle du whois REST ?
Le débat était introduit par Andy Newton, d'ARIN, lui-même un des concepteurs d'IRIS mais qui a fait une présentation très unilatérale des avantages de REST. Un peu d'histoire : le protocole whois est aujourd'hui normalisé dans le RFC 3912. Mais il est bien plus ancien que cela, sa première description ayant apparemment été faite en 1982 dans le RFC 812. Il a des tas d'inconvénients (bien décrits dans le RFC 3912 lui-même, ou dans le cahier des charges RFC 3707 qui réclamait un remplacement) : pas d'internationalisation, pas d'authentification, pas de fonctions de recherche élaborées et pas de structuration des résultats. Il aurait logiquement dû être remplacé depuis longtemps et les candidats n'ont pas manqué : LDAP a été proposé, ainsi que des protocoles spécifiques comme whois++ (RFC 1834) ou rwhois (RFC 2167). Aucun n'avait connu le moindre succès et whois reste le protocole d'accès aux données des registres (qu'ils soient de noms de domaines ou d'adresses IP).
Le candidat officiel à la succession de whois est désormais IRIS (RFC 3981), normalisé en 2005. Compliqué à programmer, IRIS n'a connu que très peu de déploiements. Les principaux se limitent à la fonction de disponibilité d'un domaine (RFC 5144). Selon son auteur, IRIS a été « requirment by lawyers, design by committee », ce qui n'est pas un compliment.
Y a-t-il une alternative ? Oui, selon Newton, REST fait tout cela et mieux (son exposé était très unilatéral en faveur de REST). L'idée est de définir un service analogue à whois (mais sur un protocole complètement différent : le terme de RESTful whois est donc maladroit car ce n'est pas du whois) en suivant les principes REST :
- Utilise HTTP, et à fond, avec ses codes de retour (404 : objet inexistant, etc), sa négociation de contenu et tout,
- Un URL qui identifie l'objet,
- Les verbes HTTP qui expriment les actions sur l'objet (principe CRUD), le service d'ARIN permettant désormais la modification d'objets, pas uniquement leur récupération,
- Résultat sous une forme structurée.
Ainsi, ARIN a un tel service en production aujourd'hui. Si je tape (POC = Point Of Contact) :
% curl http://whois.arin.net/rest/poc/KOSTE-ARIN <?xml version='1.0'?> <?xml-stylesheet type='text/xsl' href='http://whois.arin.net/xsl/website.xsl' ?> <poc> <registrationDate>2009-10-02T00:00:00-04:00</registrationDate> <city>Chantilly</city><companyName>ARIN</companyName> <iso3166-1><code2>US</code2><code3>USA</code3><name>UNITED STATES</name><e164>1</e164></iso3166-1> <firstName>Mark</firstName><handle>KOSTE-ARIN</handle><lastName>Kosters</lastName> ...
je récupère sous une forme structurée (ici en
XML), les informations disponible sur le
contact KOSTE-ARIN.
Quels sont les avantages de REST, tels que décrits par Newton ?
Essentiellement la simplicité de développement. Il existe des
bibliothèques HTTP pour tous les langages de programmation, des
clients en ligne de commande existants (comme
curl que j'utilise plus haut), et, grâce à
l'instruction <?xml-stylesheet qu'on
voit plus haut, la requête peut même être faite dans un navigateur Web
ordinaire. On constate que très peu de clients IRIS ont été
développés alors que tout le monde, même sans le savoir, a un client REST.
Tiens, une remarque sur le format de sortie : un sujet de polémique classique dans le monde REST concerne celui-ci. JSON ou XML ? Heurement, le service de l'ARIN permet les deux, en utilisant la négociation de contenu HTTP :
% curl -H "Accept: application/json" http://whois.arin.net/rest/ip/209.118.190.4
{"net":
...
"registrationDate":{"$":"2001-01-02T00:00:00-05:00"},
...
"handle":{"$":"NET-209-116-0-0-1"},"name":{"$":"ALGX-ABI-BLK14"},
...
"netBlocks":{"netBlock":{"cidrLength":{"$":"14"},
...
"description":{"$":"Direct Allocation"},"type":{"$":"DA"},"startAddress":{"$":"209.116.0.0"}}},
"orgRef":{"@name":"XO Communications",
...
Le RIPE-NCC dispose également d'un tel service, apparemment en mode expérimental. À noter qu'il n'existe pour le moment pas de schéma standard pour l'URL de la requête, ni pour les résultats. Un tel schéma apparaîtra-t-il ? IRIS s'imposera-t-il avant REST ? Nous le saurons plus tard... Mais il est symptômatique que personne dans la salle ne se soit levé pour défendre IRIS.
(Depuis, IRIS n'a eu en effet aucun succès et, en mars 2015, un autre candidat à la succession de whois est apparu, fondé sur REST, le protocole RDAP.)
L'article seul
RPZ, un moyen simple de configurer un résolveur DNS BIND pour qu'il mente
Première rédaction de cet article le 18 mars 2011
L'exposé le plus controversé lors de la réunion OARC de San Francisco était, le 14 mars, celui intitulé simplement « DNS RPZ, Rev 2 », par Paul Vixie (voir ses transparents). En effet, traditionnellement, le résolveur DNS BIND servait exactement ce que lui avait envoyé les serveurs faisant autorité. BIND ne mentait pas. Les gens qui voulaient des mensonges (par exemple renvoyer l'adresse IP d'un serveur à eux au cas où le domaine n'existe pas) devaient modifier BIND (ce qui était toujours possible, puisque BIND est un logiciel libre mais pas forcément très pratique). Désormais, avec le système RPZ (Response Policy Zone), BIND peut mentir.
Cette fonction a été ajoutée à partir de la version 9.8.0, sortie le 1er mars. RPZ est un mécanisme de configuration du mensonge dans le résolveur. Il peut être utilisé pour le cas ci-dessus (fausse adresse en cas de domaine non existant) ou, comme le signalent sans pudeur les « release notes », pour la censure de l'entreprise ou de l'État (comme en Chine ou en Loppsiland).
Comment fonctionne RPZ ?
Une zone RPZ est une zone DNS normale (on peut donc la distribuer par
les mécanismes habituels du DNS, comme par exemple le transfert de
zones du RFC 5936) contenant des règles sur les réponses
à donner. Les règles peuvent porter sur la requête (noirlister tous
les domaines en send-me-spam.biz ou illegal-gambling.cn) ou sur la
réponse.
Du fait du mécanisme de distribution, on verra donc sans doute des
fournisseurs de zones RPZ, comme il existe des fournisseurs de
listes
noires DNS pour la lutte
anti-spam. Ainsi, la place Beauvau créerait une zone
des domaines qui déplaisent au gouvernement, dont les résolveurs des
FAI français seraient esclaves. Il ne sera plus possible de retarder
de telles demandes en disant « Le logiciel ne sait pas faire ». Notons
au passage que ce n'est pas un cas théorique : la
LOPPSI est normalement réservée aux cas de
pédopornographie mais, si son article 4
prévoit que la décision de mettre un site sur la liste noire est prise
par le gouvernement et non pas par un juge indépendant, cela ne peut
être que pour une seule raison : étendre discrètement la liste des cas
pour laquelle on est mis sur la liste noire. Toujours pour le cas
français, notons aussi que
l'ARJEL a déjà plusieurs fois envoyé des
injonctions aux FAI de barrer l'accès à tel ou tel site de jeux
illégal, et que donc la censure ne concerne déjà plus exclusivement la
pédopornographie (les intérêts de l'industrie du jeu sont
puissants). Des TLD entiers, s'ils sont contestés par
certains (comme .xxx ou
.ru) pourraient être
victimes de filtrage volontaire.
RPZ peut évidemment être utilisé pour le bien ou pour le mal et
Vixie
n'a pas manqué de prévenir les critiques en exposant lui-même tous les
défauts et les risques de
RPZ. Les avantages sont la capacité à bloquer, par exemple, des
domaines de hameçonnage (ou des domaines commerciaux inutiles et
dangereux comme google-analytics.com dans l'exemple plus bas). Les inconvénients
sont l'utilisation par la censure mais aussi (point signalé, et à
juste titre, par Vixie)
la moins grande résilience du DNS du fait de l'introduction d'un
nouveau composant. On peut imaginer d'avance la prochaine grande bogue : un fournisseur RPZ bloque tout
*.fr par erreur et tous les FAI automatiquement appliquent cette
règle...
Passons maintenant à l'utilisation pratique. Comme indiqué, il faut au moins BIND 9.8.0. Quelqu'un doit créer une zone RPZ. Dans tous les exemples ci-dessous, cette zone se trouve sur le même serveur, qui est maître. Dans la réalité, le résolveur sera souvent un esclave, soit d'un maître placé dans la même organisation (centralisation de la censure au niveau d'une entreprise), soit situé à l'extérieur. Dans ce dernier cas, le serveur maître pourra être au gouvernement, dans le cas de la Chine ou de la France, ou bien chez un fournisseur privé de RPZ, comme il existe des fournisseurs privés de DNSBL. (Un point en passant : je sais bien qu'une censure via le DNS est peu efficace, car relativement facile à contourner. Mais la censure ne vise pas à marcher à 100 % : elle vise simplement à rendre les choses pénibles pour la majorité des utilisateurs, qui ne connaissent pas forcément les techniques de contournement).
Cette fourniture des zones RPZ par des organisations extérieures posera probablement les mêmes problèmes qu'avec les listes noires anti-spam d'aujourd'hui : listes gérées par des cow-boys qui vous mettent sur la liste noire pour un oui ou pour un non, listes où on est facilement enregistrés mais jamais retirés, etc.
Revenons à BIND. Pour indiquer que je veux utiliser la RPZ, je dois
donner le nom de la zone qui contient les règles de filtrage (ici,
loppsi.gouv.fr) :
options {
...
response-policy { zone "loppsi.gouv.fr"; };
};
Et on doit ensuite indiquer où trouver la zone en question. Ici, pour faciliter les tests, le serveur DNS est également maître pour la zone :
zone "loppsi.gouv.fr" {
type master;
file "loppsi.gouv.fr";
allow-query {none;};
};
La dernière directive, interdisant l'accès direct à la zone, est là pour respecter la LOPPSI, où la liste des sites filtrés n'est pas publique (pour éviter que les citoyens ne puissent la contrôler).
Le contenu de la zone lui-même suit la syntaxe décrite dans la
documentation de BIND, dans la section « Response Policy Zone
(RPZ) Rewriting ». Par exemple, pour qu'un nom soit présenté
comme non-existant, on met un enregistrement de type
CNAME et de valeur .
(juste un point). Je n'ai pas trouvé de mécanisme simple pour
appliquer le traitement à tout l'arbre sous le
nom et la documentation ne semble pas en parler. Apparemment, il faut
indiquer séparement l'apex et les sous-domaines
(avec le caractère *, le joker). Imaginons donc
qu'on veuille bloquer Google Analytics, système
qui non seulement ralentit les accès au site mais en outre est
dangereux pour la vie privée : en visitant un
site qui n'a rien à voir avec Google, vous
donnez des informations à cette entreprise. Bloquons donc ce domaine :
; Beginning of the zone, some mandatory values
$TTL 1H
@ SOA gueant.interieur.gouv.fr. root.elysee.fr (2011031800 2h 30m 30d 1h)
NS gueant.interieur.gouv.fr.
; Filtering rules
; NXDOMAIN will be sent back
google-analytics.com CNAME .
*.google-analytics.com CNAME .
Testons le serveur ainsi configuré, faisons d'abord une vérification avec un résolveur non-menteur :
% dig A google-analytics.com ... ;; ANSWER SECTION: google-analytics.com. 300 IN A 74.125.224.52 google-analytics.com. 300 IN A 74.125.224.48 ...
Puis essayons avec le résolveur menteur, qui écoute sur le port 9053
de la machine localhost :
% dig @localhost -p 9053 A google-analytics.com ... ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 20660 ... ;; AUTHORITY SECTION: loppsi.gouv.fr. 3600 IN SOA gueant.interieur.gouv.fr. root.elysee.fr.loppsi.gouv.fr. 10 3600 900 2592000 7200
C'est parfait. BIND a répondu que le domaine n'existe pas
(NXDOMAIN) et a même donné les coordonnées du
responsable (le filtrage n'est donc pas caché).
On peut mettre dans la zone RPZ d'autres choses. Par exemple, on
peut vouloir une réponse NOERROR,ANSWER=0 au lieu
du NXDOMAIN :
; NOERROR, ANSWER=0 will be sent back enlarge-your-penis.biz CNAME *. *.enlarge-your-penis.biz CNAME *.
Et on a bien le résultat attendu :
% dig @localhost -p 9053 A buy.enlarge-your-penis.biz ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 49450 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1
Et si on veut un mensonge encore plus gros, renvoyer l'adresse IP d'un de ses serveurs à la place de la vraie ? On peut :
; Replace the address by ours ; Since we provide only a AAAA, A queries will get NOERROR,ANSWER=0 ads.example.net AAAA 2001:db8::1
Ce qui fonctionne :
% dig @localhost -p 9053 AAAA ads.example.net ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 63798 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 1, ADDITIONAL: 1 ... ;; ANSWER SECTION: ads.example.net. 3600 IN AAAA 2001:db8::1
Il peut être intéressant de mettre une règle générale et
d'autoriser ensuite des exceptions. Supposons qu'on veuille défendre
la langue française en ne permettant que la consultation du
Wikipédia francophone. On met alors une règle
générale pour wikipedia.org puis une exception
pour fr.wikipedia.org, ce qui se fait en mettant
un CNAME vers le domaine lui-même :
; Language-enforcement policy: no access to Wikipedia except the ; French-speaking one wikipedia.org CNAME . *.wikipedia.org CNAME . ; and the exception: fr.wikipedia.org CNAME fr.wikipedia.org.
Dans tous les exemples précédents, on procédait à la réécriture en
fonction de la question posée. Mais BIND permet
aussi de réécriture selon la réponse. Cela se
fait en encodant l'adresse IP (et la longueur du préfixe) dans le nom et en la mettant dans le
sous-domaine rpz-ip. Imaginons qu'on veuille bloquer
toutes les réponses lorsque l'adresse IP est dans 192.0.2.0/24 :
; Forbidding answers that are the documentation prefix, 192.0.2.0/24 24.0.2.0.192.rpz-ip CNAME .
Voilà, vous savez l'essentiel désormais. N'oubliez pas, comme aime à le dire Spider-Man, qu'un grand pouvoir implique de grandes responsabilités...
Un bon article en anglais sur le même sujet est « How to configure your BIND resolvers to lie using Response Policy Zones (RPZ) ». L'ISC maintient aussi une liste de liens utiles.
L'article seul
La faille TLS de (non-)vidage des tampons
Première rédaction de cet article le 11 mars 2011
Les failles de sécurité sont nombreuses sur l'Internet et CVE 2011-0411 n'est pas la plus grave. Mais elle est rigolote car elle ne résulte pas d'une faille du protocole (comme c'était le cas pour la renégociation TLS) ni d'une bourde isolée présente uniquement dans un logiciel (comme la faille d'IOS dite « attribut 99 »). La faille d'« injection de texte » de TLS ne met pas en cause ce protocole mais elle touche plusieurs mises en œuvre, car elle découle de suppositions qu'avaient faites plusieurs programmeurs indépendants.
D'abord, un avertissement, cet article est largement pompé de
l'excellente synthèse de Wietse Venema,
« Plaintext command injection in multiple implementations of STARTTLS ». Si vous lisez
l'anglais, vous pouvez laisser tomber mon article et voir celui de
Venema. Sinon, continuons. La faille est liée à la façon dont plusieurs protocoles utilisent
TLS. Ce protocole de
cryptographie, normalisé dans le RFC 5246, permet de protéger une communication, et
assure la confidentialité et l'intégrité de celle-ci (et, en prime, si
on croit en X.509, une certaine
authentification). Tout va bien si on utilise
TLS depuis le début, ce que fait la plupart du temps
HTTP (si on a un URL de
plan https:, la session sera protégée par TLS
depuis le début, cf. RFC 2818). Mais beaucoup
de protocoles utilisent une autre méthode, celle qui consiste à
démarrer la session d'abord, puis à la monter en TLS, en général avec
une commande nommée STARTTLS. C'est ainsi que
fonctionnent SMTP (RFC 3207), IMAP (RFC 3501), ManageSieve (RFC 5804), etc. Ici, je me connecte à un serveur SMTP,
je vérifie (réponse à la commande EHLO) qu'il
gère TLS
et je passe en TLS :
% telnet localhost smtp Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. 220 horcrux ESMTP Postfix (Ubuntu) EHLO test.example 250-horcrux 250-PIPELINING 250-SIZE 20000000 250-VRFY 250-ETRN 250-STARTTLS 250-ENHANCEDSTATUSCODES 250-8BITMIME 250 DSN STARTTLS 220 2.0.0 Ready to start TLS
Et, ensuite, je ne peux plus lui envoyer de commandes car je ne sais
évidemment pas faire du TLS à la main. Pour déboguer des sessions TLS,
on utilise en général openssl, inclus dans le
paquetage du même nom :
% openssl s_client -quiet -starttls smtp -connect localhost:smtp ... 250 DSN
Et, à la fin, je peux taper des commandes dans une session protégée par TLS.
C'est là, dans cette promotion d'une session « normale » en session
TLS qu'il y a un piège. Dès que le serveur reçoit
STARTTLS, il commence la négociation TLS. Puis il
continue à lire les données du client, et les traite désormais comme
« protégées », comme « plus sûres ». Mais, pour cela, il faut être sûr
qu'elles ont été envoyées après que la
négociation TLS soit terminée avec succès. Or, plusieurs programmeurs
(comme ceux du MTA
Postfix, qui ont découvert la faille en
auditant leur code)
ont oublié ce détail, Leur code reprenait la lecture après la
négociation TLS, en lisant des données qui avaient été envoyées
avant et qui trainaient dans les
tampons d'entrée-sortie.
On ne peut pas reproduire cette bogue avec
telnet car la frappe est trop lente. Le temps
de tenter l'injection de texte en clair, la négociation TLS est
largement finie. Il faut donc modifier
openssl La modification est simple : là où
openssl envoie STARTTLS\r\n
(les deux caractères \r et \n sont le Retour Chariot et le Saut de
Ligne qui, ensemble, forment la fin d'une ligne dans la plupart des
protocoles TCP/IP), on va envoyer
STARTTLS\r\nXXXXX\r\n où XXXXX est une commande
qui sera exécutée alors que le serveur se croit protégé, alors qu'elle
avait été tapée avant. Ici, bien sûr, le client est le même, et n'a
donc aucune raison de tricher, mais, dans
le cas d'une vraie attaque, on peut imaginer un homme du
milieu qui introduirait les commandes après
STARTTLS mais avant que TLS soit réellement en
route et n'empêche cette injection.
Voyons un exemple concret avec IMAP. Le
protocole est un tout petit peu plus compliqué que SMTP car il faut
préfixer chaque commande d'une étiquette, permettant d'associer une
réponse à chaque question (RFC 3501, section 2.2.1). OpenSSL ne se fatigue pas, il utilise
simplement un point comme étiquette. Dans la fonction
main on trouve donc :
BIO_printf(sbio,". STARTTLS\r\n");
Comme commande à injecter, comme nous ne sommes pas de réels
attaquants, nous allons simplement utiliser NOOP
(RFC 3501, section 6.1.2) :
BIO_printf(sbio,". STARTTLS\r\n. NOOP\r\n");
Normalement, la commande NOOP ne doit
pas être exécutée, puisque injectée en clair,
après un STARTTLS. Testons avec notre OpenSSL
modifié, sur un serveur Dovecot :
% ./apps/openssl s_client -quiet -starttls imap -connect imap.example.net:imap ... . OK Capability completed.
Effectivement, rien n'indique que la commande ait été exécutée. C'est la même chose avec Zimbra. Mais, avec Courier :
% ./apps/openssl s_client -quiet -starttls imap -connect imap.example.net:imap ... . OK CAPABILITY completed . OK NOOP completed
Le NOOP a été exécuté. Le serveur Courier est
donc vulnérable. Est-ce exploitable ? Sans doute. Par exemple, si le serveur authentifie le
client sur la seule base d'un certificat fourni
lors de la négociation TLS, un . DELETE INBOX
ainsi injecté peut détruire la boîte INBOX de
l'utilisateur... (Notez que l'attaque résumée ici n'est pas complète,
je vous laisse trouver la faille.)
L'article de Venema, cité plus haut, explique très bien la cause de l'erreur dans le programme. Une leçon à en tirer pour les programmeurs ? Ne mélangez pas deux canaux d'entrée, un protégé et un qui ne l'est pas, ou, au moins, remettez à zéro le tampon d'entrée avec une promotion vers un protocole protégé.
L'article seul
RFC 6175: Requirements to Extend the Datatracker for IETF WG Chairs and Authors
Date de publication du RFC : Mars 2011
Auteur(s) du RFC : E. Juskevicius (TrekAhead)
Pour information
Première rédaction de cet article le 11 mars 2011
Comme toute organisation qui manipule de grandes quantités de documents, et des processus formalisés complexes, l'IETF a besoin de logiciels qui mettent en œuvre ces processus. Le principal outil est le Datatracker et ce RFC 6175 est le cahier des charges pour une nouvelle extension du Datatracker.
Le Datatracker sert entre autres à suivre l'état des Internet-Drafts. Il était traditionnellement très détaillé pour la phase d'évaluation à l'IESG de ces documents, et nettement moins précis pour les autres phases. Ce service était très réclamé depuis longtemps. Ce cahier des charges demande donc que le Datatracker soit mis à jour pour gérer les états décrits par le RFC 6174.
Quelques rappels, en section 2, pour les gens qui ne suivent pas
l'évolution du vocabulaire IETF. Tous les
Internet-Drafts ne sont pas forcément liés à un
groupe de travail de l'IETF. Ceux qui le sont, parce qu'un groupe a
décidé de les adopter, sont qualifiés de
WG draft. Leur nom est du type
draft-ietf-wgname-.... Ces
drafts, et ceux qui sont candidats à
l'adoption mais n'ont pas encore été adoptés, sont ensemble les associated
with a WG. Dans le cas où ils ne sont pas encore adoptés,
leur nom inclus l'acronyme du groupe de travail mais ne commence pas
par draft-ietf. Enfin, tous les autres
Internet-Drafts sont qualifiés
d' « individuels ».
Les exigences générales sur le « nouveau »
Datatracker figurent en section 3. Chacune est
numérotée. La première, R-001, est que le
Datatracker doit
permettre aux présidents des groupes de travail de l'IETF de saisir
directement l'état des I-D, en suivant les états
décrits dans le RFC 6174. Parmi les
autres exigences (consultez le RFC pour une liste complète), le fait
que tout changement doit être estampillé, lié à
une personne précise
(R-007) et que la date et l'heure de ce changement soient
affichées. Le Datatracker doit étendre la
machine à états existante (illustrée en https://datatracker.ietf.org/images/state_diagram.gif), pas la
remplacer (R-011). Et les présidents d'un groupe de travail doivent
pouvoir agir sur l'état d'un I-D, indépendemment de son statut à
l'IESG (R-012).
{kind=link}
La section 4 est consacrée aux questions d'autorisation. En lecture, le Datatracker est accessible à tous (R-013), l'IETF tirant une grande fierté de son ouverture au public (contrairement à la majorité des SDO, qui travaillent derrière des portes closes). Mais en écriture, les personnes qui peuvent modifier l'état d'un I-D doivent d'abord s'authentifier auprès du Datatracker (et inutile de dire que l'IETF n'utilise pas Facebook Connect). La section 11 note d'ailleurs les conséquences que cela peut avoir en matière de sécurité.
Les présidents des groupes de travail doivent avoir la possibilité (section 4.2) de modifier l'état de tous les Internet-Drafts de leur groupe, en restant dans la liste d'états pré-définie (cf. RFC 6174 et voir aussi la section 5.1), peuvent désigner jusqu'à trois délégués pour les aider, etc. Une autre population intéressante est celle des pasteurs (sheperds, cf. RFC 4858). Ceux-ci (section 4.4) sont chargés de suivre un document particulier et doivent donc pouvoir déposer le write-up, le formulaire rempli qui indique à l'IESG les points importants du document (voir aussi la section 5.3). Au sommet de cette série de personnes privilégiées, se trouvent évidemment les directeurs de secteurs (Area Directors), qui couvrent chacun plusieurs groupes de travail et doivent également pouvoir mettre à jour l'état des documents (section 4.5).
Certains états des documents posent des problèmes particuliers et la section 6 les énumère. Ainsi, un document peut être garé (parked document, section 6.4) lorsqu'il a perdu son auteur. Le directeur de secteur a alors des pouvoirs supplémentaires, comme de le transférer à un autre groupe de travail. Plus triste, un document peut aussi mourir (dead document, section 6.5) lorsque tout travail le concernant a été abandonné. Là encore, le directeur peut le transférer.
Jusqu'ici, on a parlé des changements manuels, comme lorsque le
président d'un groupe de travail met à jour l'état d'un I-D
(Internet-Draft). Y a-t-il aussi des changements
automatiques ? Oui, et la section 7 liste les cas où le
Datatracker doit agir seul. Par exemple, si une
nouvelle version d'un document a un nom qui commence par
draft-ietf, le document devient automatiquement
document d'un groupe de travail (avant, c'était juste une convention :
désormais, cela fait partie des règles mises en œuvre
automatiquement).
Quelles sont les informations qui doivent être affichées par le Datatracker ? Les sections 8 et 9 les définissent. Par exemple, le Datatracker doit garder trace de l'historique complet du document puisqu'il doit pouvoir le montrer à quiconque a les droits d'écriture (la foule anonyme n'a droit qu'à l'affichage de l'état actuel).
L'article seul
RFC 6174: Definition of IETF Working Group Document States
Date de publication du RFC : Mars 2011
Auteur(s) du RFC : E. Juskevicius (TrekAhead)
Pour information
Première rédaction de cet article le 11 mars 2011
Le processus de production de normes au sein de l'IETF était historiquement informel et peu documenté. Petit à petit, il s'est formalisé (voire ossifié) et a même reçu l'aide de logiciels permettant de suivre l'avancement des travaux. Ce RFC de processus décrit des nouveaux états que peut avoir un document en cours de discussion à l'IETF.
Une des particularités de l'IETF est son ouverture. Tout le monde doit pouvoir suivre l'état d'avancement des travaux, via l'Internet. C'est ce que permet par exemple le Datatracker de l'IETF qui donne accès à l'état (en février 2011) du document sur la syntaxe des TLD (apparemment abandonné, et tant mieux), à celui de la documentation de l'AS 112 (adopté par un groupe, mais perdu dans les sables bureaucratiques depuis très longtemps), à celui sur l'enregistrement DNS CERT (pas adopté par un groupe de travail), ou à celui sur le protocole LISP (en plein développement par un groupe de travail).
Les informations affichées par le Datatracker n'étaient pas toutes documentées et certaines, non actuellement affichées, pourraient être nécessaires. Ce RFC 6174 documente donc les états possibles des documents.
Le Datatracker gère bien d'autres choses que les
documents, puisqu'il donne aussi accès aux revendications
d'appropriation intellectuelle, et à d'autres aspects de la vie
de l'IETF. Concernant le document, la version du
Datatracker en service fin 2010 ne permettait de
suivre que les documents présentés à l'IESG
pour évaluation. Avant cela, il ne savait pratiquement d'un document que le fait
qu'il soit Active (en cours de discussion) ou
Expired (les Internet-Drafts
ont une durée de validité de six mois). Or le processus (décrit dans
le RFC 8729 est bien plus riche.
Comme le rappelle la section 2 de notre RFC, un Internet-Draft peut être complètement individuel ou bien être un Working Group I-D si un groupe de travail IETF a décidé de l'adopter et de travailler sur ce document. Dans ce cas, sa vie au sein du groupe passe par plusieurs stades qui étaient ignorés du Datatracker.
La section 3 résume en effet l'état du
Datatracker fin 2010. Si ce dernier connaissait
tous les détails de l'évaluation à l'IESG, la vie du document avant
son passage devant cet aréopage était nettement moins détaillé, le
Datatracker ne prenant en compte que la
disponibilité du document. La
section 3.1 donne une liste complète. Celle-ci inclut, comme vu plus haut,
Active et Expired, mais
aussi des états comme Replaces et
Replaced-by qui indique le remplacement d'un
Internet-Draft par un autre, équivalent. Cela se
produit typiquement lors de l'adoption d'un draft
par un groupe de travail. Si le document était nommé
draft-authorname-topic-nn, il devient alors
draft-ietf-wgname-topic-00. À noter qu'il
n'existe pas de moyen automatique pour identifier ce remplacement (les
Internet-Drafts n'ont pas de métadonnées structurées), le
président du groupe de travail doit l'indiquer explicitement.
Une fois le document terminé par le groupe de travail, il passe à l'IESG pour évaluation. Cette phase est celle qui a suscité le plus de formalisation et celle-ci est décrite dans la section 3.2 (avec l'intégralité des états dans l'annexe A). Un Internet-Draft peut ainsi être, entre autres :
Publication requested, le premier stade, suivant les procédures de la section 7.5 du RFC 2418.AD evaluationqui indique qu'un AD (un Area Director, la personne coresponsable d'une zone de travail de l'IESG comme le routage, la sécurité, les applications) est en train d'évaluer le document.IESG evaluationqui indique que le document est désormais évalué par toute l'IESG, c'est-à-dire par tous les AD. Chacun peut émettre une objection bloquante, connue sous le nom (fort mal choisi) deDISCUSS.
Quels sont les nouveux états possibles pour un document, créé par ce RFC 6174 ? La section 4 les détaille et s'appuie pour cela sur une machine à états (figure 1). Ils sont déjà mis en œuvre dans le Datatracker et se trouvent simplement documentés ici, par exemple (ce n'est pas une liste complète) :
Call for adoptionquand un document est encore individuel mais que son auteur a demandé qu'un groupe de travail l'adopte comme document de travail officiel du groupe,Adopted, une fois que c'est fait ; le document prendra alors un nom du genredraft-ietf-workingroupname-topic-00,Working Group documentune fois que le travail du groupe a effectivement commencé,Working Group Last Call; le sigle WGLC apparît souvent dans les listes IETF car cet état est une partie importante (quoique optionnelle, cf. RFC 2418) du folklore de cette organisation. C'est le dernier moment où le groupe peut donner son avis avant que le document, transmis à l'IESG, ne lui échappe.Working Group consensus, waiting for write-up, qui indique que le document fait l'objet d'un large consensus dans le groupe, et qu'il a juste besoin d'un write-up, le formulaire qui accompagne tout envoi à l'IESG et qui explique à celle-ci les points importants (comme l'existence de mises en œuvre, l'état effectif du consensus, les menaces d'appel, etc, voir RFC 4858),Submitted to IESG, lorsque le travail du groupe est fini,
Outre ces états, qui sont mutuellement exclusifs, le document peut porter un certain nombre d'étiquettes indiquant des points importants du processus, parmi lesquelles :
Awaiting Expert Review/Resolution of Issues Raisedqui indique qu'un examen du document par un expert du domaine est en cours (de tels examens existent, par exemple, pour toutes les MIB, qui sont vérifiées par un spécialiste ès-MIB),Waiting for Referencing Document, le document dépend d'un autre document, pas encore prêt,Revised I-D Needed - Issue raised by WGLC, lorsque le dernier appel à commentaires dans le groupe de travail a suscité des problèmes suffisamment sérieux pour justifier un nouvel ID (Internet-Draft).
Enfin, un autre champ est spécifié, en section 5. Tout document doit avoir un « niveau de normalisation visé » qui indique si le groupe de travail veut voir le futur RFC sur le chemin des normes, ou simplement « Pour information » ou encore purement « Expérimental ». (Ces niveaux sont expliqués dans le RFC 2026.)
La mise en œuvre de ces nouveaux états dans le Datatracker se fera suivant le cahier des charges contenu dans le RFC 6175.
Une lecture intéressante sur le sujet de la vie des Internet-Drafts est « Guidelines to Authors of Internet-Drafts ».
L'article seul
RFC 6143: The Remote Framebuffer Protocol
Date de publication du RFC : Mars 2011
Auteur(s) du RFC : T. Richardson, J. Levine (RealVNC)
Pour information
Première rédaction de cet article le 8 mars 2011
Il est assez fréquent à l'IETF qu'un protocole ne soit documenté dans un RFC que longtemps après son déploiement. C'est le cas de RFB (Remote Framebuffer Protocol), le protocole utilisé dans le système VNC, système qui permet de transmettre via un réseau TCP/IP l'interface graphique d'une machine. VNC permet, par exemple, d'avoir sur son ordinateur le bureau d'une machine distante, se s'y loguer, etc, comme si on était physiquement devant. C'est donc un concurrent de X11 avec XDMCP ou bien de NX mais avec l'avantage sur ce dernier d'avoir désormais une spécification publique, et de nombreuses mises en œuvre. Je compte une quarantaine de clients, de serveurs et de bibliothèques VNC sur mon Ubuntu.
RFB se veut un protocole simple, bien plus simple que X11, basé sur l'idée d'un serveur, tournant sur la machine distante, qui écrit dans une mémoire graphique (le framebuffer) qui est en fait située sur la machine de bureau (le client ; notez que « client » et « serveur » ont des sens différents de celui de X11). Le système VNC, qui utilise ce protocole, est très largement utilisé pour l'accès distant à une machine, exactement dans les mêmes conditions que si on était présent devant cette machine (système de fenêtrage, accès à la souris, etc).
RFB travaille au niveau de la mémoire graphique et est donc compatible avec tous les systèmes de fenêtrage comme X11 ou comme celui de Windows. Le protocole se veut simple, surtout côté client, pour pouvoir être mis en œuvre sur de petites machines. Il existe même un widget VNC/RFB pour GTK, pour ceux qui veulent mettre un client VNC dans leurs programmes.
Le client est sans état et peut donc redémarrer à tout moment et reprendre la session là où il l'avait laissée. C'est le serveur qui maintient l'état de l'interface utilisateur. Cela permet par exemple de changer de client en cours de session.
RFB, je l'ai dit, a été implémenté avant d'être spécifié et a connu plusieurs versions. Ce RFC essaie donc de documenter l'état actuel du protocole.
Si les détails prennent parfois de la place, les principes sont simples et les premières sections du RFC sont donc courtes. La section 2 décrit les connexions entre le client et le serveur. Le mode normal de fonctionnement de VNC est que le serveur tourne pendant une longue période, gardant en mémoire l'état de la mémoire graphique, le ou les clients se connectant à loisir, pendant parfois seulement de courtes périodes. Cela ressemble donc, adapté au graphique, au principe de screen. Le client peut être n'importe où sur l'Internet et se connecte par défaut au port 5900.
Loin de la richesse du protocole de
X11, RFB ne fournit qu'une seule primitive :
« afficher un rectangle à la position X,Y
indiquée » (section 3). Cela peut sembler très inefficace mais divers
encodages subtils permettent de rendre ce protocole supportable. Les
mises à jour (nouveaux rectangles à afficher) ne sont jamais envoyées par
le serveur mais demandées par le client (message
FramebufferUpdateRequest, section 7.5.3). Le protocole est donc
adaptatif : un client lent ne demandera pas souvent des mises à jour
et aura donc moins de travail. Si une même région de la mémoire
graphique voit plusieurs modifications successives, le client lent
peut donc parfaitement sauter les étapes intermédiaires.
Afficher des rectangles, c'est très joli mais un environnement graphique digne de ce nom doit aussi permettre à l'utilisateur de dire quelque chose, par exemple de taper au clavier ou de cliquer avec la souris. La section 4 résume le protocole d'entrée de RFB : ce dernier ne connait que clavier et souris (multi-boutons). Tout autre périphérique d'entrée doit donc être modélisé comme clavier ou comme souris.
Et les pixels, comment sont-ils modélisés ? La section 5 décrit le modèle. Il repose sur une négociation entre client et serveur, à l'ouverture de la connexion, où le client est roi. C'est lui qui choisit la représentation des pixels sur le réseau, et il peut donc choisir ce qui lui fait le moins de travail, tout reposant alors sur le serveur. Les deux formats les plus classiques sont le « couleurs réelles » où chaque pixel est un nombre sur 24 bits, chaque groupe de 8 bits indiquant l'intensité de rouge, de vert ou de bleu, ou bien le « table des couleurs » où chaque pixel est un nombre sur 8 bits indiquant une entrée d'une table où sont stockées les 256 couleurs possibles.
Plusieurs encodages sont ensuite possibles dans RFB, six étant définis par notre RFC 6143, permettant plus ou moins de compression.
En parlant de négociation, comme RFB existe depuis un certain temps et a connu plusieurs versions, la section 6 décrit la notion de version du protocole. Notre RFC 6143 normalise la version 3.8. Les versions précédentes résumées dans l'annexe A. Si une version 4.x apparaîtra peut-être un jour, la version actuelle, la 3.8, est extensible sans avoir besoin de changer de version. On peut ainsi introduire :
- De nouveaux encodages en plus des six indiqués plus haut,
- Des nouvelles fonctions du protocole (appelées « pseudo-encodages » car, dans le processus de négociation initial, elles sont représentées comme des encodages),
- Des nouveaux mécanismes de sécurité.
Le protocole RFB lui-même figure dans la section 7. Elle est très longue, bien plus que les autres sections, mais pas forcément plus difficile, elle liste juste tous les messages possibles. RFB peut fonctionner sur n'importe quel protocole de transport fiable (comme TCP). La communication commence par une phase de négociation entre le client et le serveur, puis l'initialisation, puis l'envoi des messages de mise à jour de la mémoire graphique. La description des messages utilise quelques types de base comme U8 (entier de huits bits non signé), S16 (entier de seize bits signé, toujours en gros boutien), etc.
La section 7.1 décrit le protocole de négociation. Ainsi, le
serveur commence par envoyer un message où il indique la version
(message ProtocolVersion, ici, le serveur à l'autre bout est x11vnc) :
% nc ec2-xxx.eu-west-1.compute.amazonaws.com 5900 RFB 003.008
La sécurité se négocie ensuite (section 7.2). La phase
d'initialisation est décrite en section 7.3. Par exemple, le message
ServerInit contiendra la hauteur et la largeur de
la mémoire graphique en nombre de pixels (tous les deux en UA16),
ainsi que le format de représentation des pixels (décrit en section 7.4).
La représentation des caractères tapés au clavier du client
(message KeyEvent, section 7.5.4) est
complexe. La valeur utilisée est un keysym de X11
(même si ni le client, ni le serveur n'utilisent X11). Si vous avez
une machine Unix où X11 est installé, le
fichier /usr/include/X11/keysymdef.h vous donnera
une idée des valeurs possibles. Cela aurait été
plus simple si un point de code Unicode était
envoyé... Mais il n'y a que pour ASCII que le
keysym correspond au point de code. Le RFC va
même jusqu'à préciser qu'il vaut mieux utiliser le
keysymI traditionnel, même s'il y en a un pour le
caractère Unicode. l faut dire
que le protocole RFB ne transmet pas que des caractères mais aussi des
états des touches (comme le fait que la touche Majuscule est pressée)
et des touches non affectées à un caractère particulier (comme F1,
F2, etc). Les règles d'interprétation des keysyms
sont d'une grande complexité. Le lecteur curieux doit se munir
d'aspirine avant de lire lui-même cette section.
Plus facile, le cas du « pointeur » (la souris) en section 7.5.5. Les événements sont simplement « bouton pressé » et « bouton relaché », les attributs étant la position X,Y et le numéro du bouton (huit boutons sont prévus, afin de pouvoir modéliser des dispositifs d'entrée plus complexes comme les roulettes).
Jusqu'à présent, je n'ai parlé que des messages envoyés par le
client RFB au serveur. En sens inverse, le principal message est
FramebufferUpdate (section 7.6.1) qui indique un changement dans
la mémoire graphique. Il contient un certain nombre de rectangles et,
pour chacun d'eux, sa position X,Y, sa hauteur et sa largeur, et le
type d'encodage utilisé.
Les encodages sont définis en section 7.7. Les six standards à l'heure actuelle sont :
Raw: comme son nom l'indique, aucun effort, on envoie juste les pixels l'un après l'autre (largeur, puis hauteur).CopyRect: le serveur indique les coordonnées d'un rectangle existant dans la mémoire du client. Cela sert, par exemple, lorsqu'une fenêtre est déplacée sur l'écran.RRE encoding: officiellement abandonné.Hextile encoding: officiellement abandonné.TRLE encoding: Tiled Run-Length Encoding utilise un ensemble de techniques de compression dont le run-length encoding appliquée à des « tuiles » de 16x16 pixels.ZRLE encoding: Zlib Run-Length Encoding utilise la compression Zlib (RFC 1950 et RFC 1951).
La normalisation du Remote Framebuffer Protocol a nécessité quelques nouveaux registres IANA, décrits en section 8 : celui des types de sécurité, celui des messages RFB, et celui des encodages, qui permettra d'étendre la liste de six encodages présentée plus haut.
Quelle est la sécurité de RFB ? Par défaut, inexistante : comme le note justement la section 9, l'authentification est faible et la confidentialité et l'intégrité sont nulles. RFB est traditionnellement utilisé avec une protection fournie par, par exemple, un VPN chiffré, seule façon de l'utiliser de manière sûre.
L'annexe A du RFC résume les différences entre cette version du protocole (la 3.8) et les précédentes. Ces différences sont concentrées dans la phase de négociation.
À l'heure d'aujourd'hui, je n'ai pas trouvé de connaissance de ce
protocole dans tcpdump mais
Wireshark, par contre, le décode, sous son ancien
nom de VNC (qui est désormais uniquement le nom d'un logiciel). C'est
aussi le nom à utiliser sur pcapr : http://www.pcapr.net/browse?proto=vnc&order=date.
L'article seul
RFC 6151: Updated Security Considerations for the MD5 Message-Digest and the HMAC-MD5 Algorithms
Date de publication du RFC : Mars 2011
Auteur(s) du RFC : S. Turner (IECA), L. Chen (NIST)
Pour information
Première rédaction de cet article le 7 mars 2011
Ce RFC marque un peu l'enterrement officiel de MD5 dans les protocoles IETF. Cet algorithme de cryptographie, très répandu et très utilisé, décrit dans le RFC 1321, a connu de nombreuses attaques cryptanalytiques réussies et, pour plusieurs de ces usages, ne doit plus être considéré comme offrant une protection raisonnable. Une bonne partie de la sécurité de l'Internet reposait historiquement sur des protocoles utilisant MD5 et c'est donc un chapitre important qui se clot.
Peut-on dire aujourd'hui que MD5 est « cassé » et n'offre plus aucune protection ? La réponse doit en fait être plus nuancée et cela explique que ce très court RFC ait fait l'objet d'une aussi longue discussion à l'IETF, pour ne sortir que maintenant. En effet, si on voit souvent des affirmations hâtives de la part des ignorants, prétendant sans nuance que MD5 a été cassé, la réalité est plus complexe.
La section 1 rappelle en effet l'état de l'art. MD5 est utilisé pour deux choses :
- Pour calculer un condensat cryptographique d'un message. C'est ce que fait la commande Unix md5sum et cet usage est à la base de plusieurs solutions de signature.
- Pour authentifier un message en condensant le message avec une clé secrète (technique HMAC, RFC 2104).
Dans le premier cas, MD5 n'offre en effet plus une sécurité acceptable face à un attaquant (il reste utilisable lorsque le seul but est de détecter des erreurs produites par un processus aveugle, par exemple des parasites sur la ligne). Pour le second cas, c'est moins évident.
C'est qu'il existe plusieurs types d'attaques contre les fonctions de hachage cryptographiques comme MD5 (voir le RFC 4270). Par exemple, une attaque par collision consiste en la production de deux messages ayant le même condensat. Ce sont ces attaques auxquelles MD5 est le plus vulnérable. Si un document est signé via un condensat MD5, il est aujourd'hui simple de créer deux documents ayant le même condensat MD5, ce qui annule une bonne partie de l'intérêt des signatures.
Mais MD5 résiste bien mieux à d'autres attaques comme celles par pré-image, où un attaquant cherche à fabriquer un message ayant le même condensat qu'un message donné. C'est une tâche nettement plus complexe que la collision, où l'attaquant contrôle les deux messages. Donc, chaque protocole ou application qui utilise MD5 doit analyser si son usage de cette fonction est acceptable ou pas, compte-tenu de l'état de l'art en cryptographie.
Pour voir la différence entre ces deux problèmes, reprenons la
commande md5sum. Soit un fichier
toto.txt. md5sum calcule le condensat :
% md5sum /tmp/toto.txt 0365023af92c568e90ea49398ffec434 /tmp/toto.txt
Une attaque par pré-image consisterait en la création d'un nouveau fichier
ayant le même condensat
0365023af92c568e90ea49398ffec434 que
toto.txt. Cela reste une tâche non-triviale. Une
attaque par collision permet au contraire à l'attaquant de choisir le
condensat à produire. Avec l'aide du paradoxe de
l'anniversaire, c'est bien plus facile. Mais cela ne
marche que si l'attaquant a le choix des données, ce qui est
partiellement vrai pour les signatures mais pas pour HMAC. (Voir une
bonne explication des différentes possibilités d'attaque, assez trapue mais originale, en « Meaningful Collisions (for SHA-1) ».)
La section 2 liste les attaques publiées contre MD5. Attention, en cryptanalyse, toutes les attaques réussies ne sont pas publiées, certains préférant les garder pour eux. Il faut donc toujours prévoir une marge en se disant que, si une attaque publiée permet de casser un algorithme de cryptographie en un mois, les attaques non publiées peuvent sans doute le faire en quelques jours, voire quelques heures.
Donc, les attaques par collision réussies contre MD5 ont été publiées pour la première fois en 1993. Les progrès ont été importants en 2004 avec « Cryptanalysis of HMAC/NMAC-MD5 and MD5-MAC » de Wang, Feng, Lai et Yu. En 2006, une attaque publiée descend à une seule minute de temps d'exécution sur un portable normal. En 2007, ce genre d'attaques a pu casser des certificats X.509. Il est donc clair que MD5 ne doit plus être utilisé pour la signature numérique. (En cherchant, vous trouverez probablement un certain nombre de sites Web qui ont toujours un certificat utilisant MD5.)
Au contraire, comme le note la section 2.2, les meilleures « attaques » pré-image publiées n'ont pas encore abouti. Quelles sont les conséquences pour HMAC (section 2.3) ? S'il y a eu plusieurs tentatives de casser HMAC-MD5 (tel qu'il est utilisé, par exemple, dans TSIG, RFC 8945), aucune de celles publiées n'a réussi. Il n'y a donc pas d'urgence à supprimer MD5 lorsqu'il est utilisé ainsi, néanmoins des remplaçants sont prêts (cf. RFC 4231) et peuvent être intégrés dans les nouvelles versions des protocoles (RFC 6039). Notez que les faiblesses de MD5 ne sont évidemment pas spécifiques aux protocoles Internet, voir par exemple la documentation de GnuPG.
L'article seul
Conférence SATIN : sécurité des noms de domaines
Première rédaction de cet article le 4 mars 2011
Dernière mise à jour le 4 avril 2011
Il y a déjà eu beaucoup de discussions, de textes et de réunions sur la sécurité des noms de domaine. Mais je crois que c'est la première fois qu'une conférence à caractères scientifique est entièrement consacrée à ce sujet : SATIN (Securing and Trusting Internet Names).
Vous pouvez accéder aux articles via l'agenda de SATIN. On y trouve en majorité des sujets sur DNSSEC. Bien que l'appel à contributions fasse explicitement référence à divers technologies, les promoteurs de celles-ci ont apparemment décliné l'occasion d'explorer des alternatives.
Personnellement, j'ai parlé de l'importance de la
surveillance lorsqu'on a déployé DNSSEC,
notamment lors des remplacements de clés. Un outil a été développé
pour surveiller que ces remplacements se passent bien et il a détecté
de nombreuses erreurs. Il est disponible en https://framagit.org/bortzmeyer/key-checker. Lors de la conférence, la présentation des résultats de cet outil a déclenché
un débat animé sur l'utilité des remplacements de clés systématiques.
L'article que je distribue ici est une version légèrement corrigée par rapport à celle disponible sur le site de la conférence (je vous laisse trouver la bogue).
- L'article en version PDF, et son source en LaTeX,
- Les transparents en version adaptée à l'écran, adaptée à l'impression et leur source.
L'article seul
Jean-René Chauvin (1919-2011)
Première rédaction de cet article le 3 mars 2011
Militant trotskyste, résistant et déporté, Jean-René Chauvin est décédé le dimanche 27 février.
De son combat pendant la seconde guerre mondiale et de son séjour dans les camps, il avait tiré un livre de témoignage, « Un trotskyste dans l'enfer nazi ».
Il n'avait jamais cessé d'être un empêcheur de ronronner en rond, s'étant par exemple fait expulser d'un colloque en Russie, qui réunissait des anciens des camps nazis et staliniens, parce qu'il avait profité de la tribune, non pas pour tenir des discours historiques, mais pour appeler à la solidarité avec le peuple tchétchène.
Je me souviens de son intérêt lorsque je lui avais expliqué le concept d'Unicode. En bon internationaliste, il s'était enthousiasmé qu'on puisse travailler à permettre l'expression dans toutes les écritures du monde.
L'article seul
La cuisine des flibustiers (Mélani Le Bris)
Première rédaction de cet article le 3 mars 2011
Vous voulez changer de monde ? Revivre l'épopée de la flibuste dans votre assiette ? Tester des saveurs nouvelles ? Pratiquer la cuisine et l'histoire en même temps ? Vous avez du temps libre, des cochons sauvages qui passent de temps en temps dans votre jardin et des bananes plantain qui y poussent ? Alors, larguez les amarres, hissez les voiles et entamez la lecture du livre de Mélani Le Bris, « La cuisine des flibustiers » (éditions Libretto).
Érudite et cuisinière, Mélani Le Bris s'est lancée dans un livre de cuisine original, un livre de la cuisine des flibustiers et autres pirates. Compilées à partir de récits comme ceux de l'inénarrable Père Labat (un curé qui se préoccupait nettement plus de son ventre que de son âme), testées de nos jours, ses recettes sont loin d'être faciles à réaliser aujourd'hui, lorsqu'on habite une grande ville, par exemple lorsqu'il faut rôtir le cochon sur la plage pendant des heures !
Mais, même si vous manquez de courage pour les recettes de boucanier, les récits vous feront rêver. Les pirates ne passaient pas tout leur temps à piller et massacrer, ils se préoccupaient également de dépenser leur argent dans des bombances gigantesques. Et ils développèrent une tradition culinaire spécifique. Contrairement aux colons qui mettaient un point d'honneur à manger comme en Europe, avec des aliments importés à grand frais, les flibustiers ne pouvaient pas trop faire les difficiles et devaient se nourrir avec ce qu'offrait le pays. Leur cuisine fut très influencée par celle des indiens et des marrons, les éventuels préjugés racistes des pirates ayant vite cédé devant la nécessité de trouver des alliés, des observateurs, et des gens qui puissent les guider dans la richesse, mais aussi les dangers, des nourritures locales.
Pour donner une idée du style de l'auteure, voici une partie de sa présentation du piment : « Le feu même de la création, avant qu'elle se repose, la lave encore bouillante dans le cratère du monde naissant. Et tant de saveurs révélées, passé le choc de la première rencontre ! Qui a goûté au feu des pimentades bientôt ne s'en passera plus ».
Vous voulez un exemple de recette ? « Faire mariner le requin dans le jus de citron vert additionné de l'oignon émincé, du thym effeuillé, de la gousse d'ail et du morceau de piment haché. Laisser macérer 1 à 2 heures. [...] Faire chauffer l'huile à feu moyen et frire les beignets jusqu'à ce qu'ils prennent une belle couleur brune. [...] Sortir le requin de sa marinade, le rincer dans l'eau froide et le tremper dans l'assaisonnement, puis dans le mélange de farine, poivre, sel et origan. Plongez les steaks de requin dans l'huile [...] Disposer chaque steak de requin dans un beignet chaud, assaisonner à volonté de Shadow Bennie Sauce (voir p. 52) ou autres pimentades. ».
Les pirates et flibustiers ne mangeaient pas que des plats aussi hots. Ils adoraient aussi les desserts, facilités par l'abondance de sucre aux Caraïbes et le chapitre sur les desserts a de quoi faire saliver, même si l'auteure note que la mort précoce et violente de la plupart des pirates leur a sans doute épargné beaucoup de caries... Pour ce chapitre, l'auteure cite largement Caroline Sullivan, la Ginette Mathiot de la cuisine caribéenne.
Si le livre vous a plu, je recommande également très fortement celui du père de l'auteure, Michel Le Bris, « D'or, de rêves et de sang », une analyse très pertinente du phénomène de la flibuste, qui n'était pas uniquement motivée par l'argent, mais qui avait aussi une solide base religieuse (les premiers flibustiers étaient tous protestants) et politique.
L'article seul
Fiche de lecture : Programmer en Erlang
Auteur(s) du livre : Francesco Cesarini, Simon Thompson
Éditeur : Pearson
978-2-7440-2445-0
Publié en 2010
Première rédaction de cet article le 2 mars 2011
Ce livre est un des premiers sur Erlang en français (je n'ai pas lu celui de Mickaël Rémond). Le langage de programmation Erlang occupe une niche originale en étant à la fois un langage fonctionnel et un langage parallèle. Ses promoteurs le disent particulièrement adaptés aux grands systèmes temps-réel complexes, comme les autocommutateurs d'où il vient. Mais Erlang a aussi été utilisé pour des serveurs Internet qu'on peut installer sur ses machines Unix normales, comme la base de données NoSQL CouchDB ou comme le serveur XMPP ejabberd.
D'abord, un mot sur le livre, avant de revenir au langage. [Pour information : j'ai reçu un exemplaire gratuit de l'éditeur, en tant que blogueur supposé influent.] Il est écrit en anglais par deux spécialistes du langage. Ceux-ci ne manquent pas d'humour autocritique comme le montre l'exercice 17.4 « Des deux auteurs du livre, qui est celui qui a réussi à provoquer tout seul une panne d'un réseau mobile au niveau national en utilisant sans précaution l'outil de trace dbg ? ». Leur livre couvre tous les aspects, aussi bien sur le langage lui-même, que sur des questions de plus haut niveau, comme les patrons de conception pour la programmation parallèle, les bonnes pratiques pour la gestion des erreurs, et les détails pratiques (comme le débogueur, cité dans l'exercice ci-dessus) ou les logiciels auxiliaires comme le système de documentation EDoc. Le livre est très concret, plein d'exemples (qui marchent) et d'exercices. Cela va jusqu'à du code pour décoder les paquets TCP, qui vous donnera une bonne idée des capacités « bas niveau » d'Erlang. Avec Erlang, on fait du pattern matching même sur les bits entrants. Si vous avez passé une journée à faire de l'ISO 9001, ce livre est un excellent traitement à prendre dans la soirée. Compte-tenu à la fois de l'importance de ce domaine pour Erlang, et de sa relative difficulté, je préviens que la programmation parallèle occupe une grande part du livre.
La traduction est d'Éric Jacoboni, un vieux de la vieille, un expert qui a déjà produit de très nombreuses documentations et livres. (Pour les amateurs de souvenirs, voir sa documentation sur sendmail.) Il s'est bien tiré des défis habituels de la traduction de livres techniques en français. Les exemples ont ainsi reçu des noms de variables, de types et de fonctions en français, ce qui aide à les différencier facilement des mots-clés (Erlang n'a pas de règle pour différencier une fonction définie par l'utilisateur de celles du système). On a donc des « processus ouvriers » (je n'ai pas vérifié dans le texte original, je suppose que c'étaient des worker thread), des enregistrements et pas des records et on se lie au lieu de se binder. Certains termes ne sont pas traduits mais toujours pour de bonnes raisons. Ainsi, les fun (les lambda d'Erlang) gardent leur nom, puisque c'est aussi un mot-clé. Le pattern matching, concept essentiel en Erlang, garde prudemment son nom. Plus curieusement, les compétitions sont restées des races.
Le contenu du livre est globalement de très bonne qualité. La seule erreur que j'ai trouvée est l'amusante bogue en bas de la page 459, où une note du relecteur est restée dans la version imprimée. En revanche, la qualité physique du livre est plus contestable : plusieurs pages ne sont tout simplement pas fixées et partent spontanément. À l'heure où les livres papier sont tant menacés par le numérique, c'est un problème sérieux, s'ils ne sont même pas pratiques à utiliser.
Et le langage lui-même ? Erlang est très déroutant pour celui qui vient des langages impératifs traditionnels comme C. Ainsi, on ne peut lier une valeur qu'à une variable (qui commence par une majuscule) :
> A = 4. 4 > a = 4. ** exception error: no match of right hand side value 4
C'est logique, mais le message d'erreur est déroutant !
Autre sujet d'étonnement si on a lu trop vite l'excellente section sur le pattern matching :
> {Foo, Bar} = {1, 2}.
{1,2}
> {Foo, Bar} = {3, 4}.
** exception error: no match of right hand side value {3,4}
> {Foo, Bar} = {1, 2}.
{1,2}
Comme dans beaucoup de langages fonctionnels, on ne peut en effet affecter une valeur à une variable (on dit lier) qu'une fois. Mais Erlang est plus intelligent que ça, on peut affecter plusieurs fois, si c'est à la même valeur (car l'affectation n'est qu'un cas particulier du pattern matching). C'est donc pour cela que le troisième cas réussit.
Globalement, le langage est très intéressant (je n'écris pas « prometteur » : Erlang est un vieux langage même s'il est encore peu connu), utilisable dès aujourd'hui pour des projets réels et ce livre est un très bon moyen de s'y plonger. Je le recommande à tous les programmeurs, pour élargir leur perspective sur la programmation.
Sur ce créneau de langages de (relativement) bas niveau, avec parallélisme intégré, le principal concurrent d'Erlang est sans doute Go dont j'ai déjà parlé. Tout le monde n'aime pas forcément Erlang et la critique la plus argumentée que j'ai vue est « What Sucks About Erlang ». Un bon article de défense d'Erlang est « An Open Letter to the Erlang Beginner (or Onlooker) ».
L'article seul
Il faut arrêter de parler des « distributions Linux »
Première rédaction de cet article le 27 février 2011
Pendant longtemps, de nombreuses personnes ont utilisé le terme de « distribution Linux » pour désigner les systèmes d'exploitation comme Debian ou Fedora. Ce terme, bien que très répandu, a toujours été incorrect et, heureusement, il commence à être moins utilisé. Quels problèmes pose-t-il ?
Pendant longtemps, ce terme de « distribution Linux » était présent sur la page d'accueil de Debian et était repris dans l'article de Wikipédia. Il a aujourd'hui disparu du site Web officiel et est moins présent sur l'article de Wikipédia. Mais, en fait, il a toujours été incorrect, pour plusieurs raisons.
La raison immédiate de la disparition du terme chez Debian est la sortie, le 6 février 2011, de la version 6 de Debian, surnommée Squeeze, et qui était la première version de Debian où un noyau non-Linux, en l'occurrence FreeBSD, était officiellement intégré. Debian ne peut donc clairement pas être appelée une « distribution Linux ».
Mais ce point peut être considéré comme relativement anecdotique car, après tout, l'écrasante majorité des utilisateurs de Debian se serviront de Linux. Le problème est qu'il y a une autre raison pour laquelle le terme de « distribution Linux » est inadapté : c'est que ce terme donne une importance excessive à un composant du système d'exploitation, le noyau. Sur la machine Debian où je tape ce texte, de très nombreux logiciels sont présents et nécessaires. Si le noyau est un des plus complexes, il n'est pas le seul logiciel. Pourquoi appeler ce système une « distribution Linux » et pas une « distribution X11 » ? Ou une « distribution GNU » ? Après tout, le système de fenêtrage X11 est un composant tout aussi crucial pour l'utilisateur moderne. Même chose pour la quantité des logiciels GNU dont dépend mon travail (à commencer par l'éditeur emacs). Il n'y a pas de raison objective de privilégier le noyau. D'autres logiciels sont indispensables (la libc par exemple). D'autres sont aussi complexes (X11...). D'autres sont plus significatifs pour décrire l'expérience quotidienne de l'utilisateur (Gnome...) Parler de « distribution Linux » laisse entendre que tous ces logiciels sont juste installés pour accompagner le noyau Linux dans sa tâche...
Est-ce juste un détail de terminologie ? Non, pas seulement car ce nom de « distribution Linux » a des conséquences pratiques fâcheuses. Ainsi, un certain nombre de programmeurs disent que leur logiciel tourne sur Linux parce qu'il marche sur leur Fedora, mais dépend en fait de plusieurs composants qui ne sont pas liés à Linux. Ainsi, contrairement à ce que pensent pas mal de gens :
- Tous les systèmes utilisant Linux ne se servent pas forcément de la GNU libc (notamment les embarqués, où la µClibc est plus fréquente).
- Tous les systèmes utilisant Linux n'ont pas forcément les outils GNU (ils peuvent par exemple utiliser BusyBox).
Donc, quand vous voyez « compatible Linux » sur un logiciel, cela ne veut pas dire qu'il marche avec tout système utilisant ce noyau, mais simplement qu'il a été documenté par quelqu'un qui ne comprenait pas la différence entre noyau et système d'exploitation, et qui a supposé que tous les Linux étaient à peu près pareils.
En parlant de systèmes embarqués, un bon exemple d'un système d'exploitation très populaire, utilisant Linux (et se présentant comme « distribution Linux »), mais pas beaucoup de choses que certains considèrent comme consubstantiels à Linux est le système OpenWrt. Un autre exemple fameux est Android qui utilise également Linux et qui, lui, de manière purement arbitraire, n'est jamais qualifié de « distribution Linux ».
Car on voit bien que le fond de l'affaire est une affaire de définition. Lors d'une discussion sur Twitter suite à cet article, plusieurs personnes ont affirmé que « Fedora est une distribution Linux mais pas Android » sans vraiment donner les critères qui permettent de séparer une « vraie distribution Linux » d'un système qui n'en est pas une. Parmi les critères proposés dans cette discussion :
- La compatibilité Posix. Mais, dans ce cas, FreeBSD est aussi une « distribution Posix ».
- Le fait d'être un « vrai » Linux, sans explications.
Même problème de définition lorsqu'on s'attaque à la question de savoir où s'arrête le système d'exploitation et où commencent les applications. Sur Debian, est-ce qu'emacs, le shell, la libc, init, ifconfig, vi, la bibliothèque OpenSSL et apt font partie du système ou des applications ? Il n'existe pas de critère fiable pour décider.
La principale raison du succès de ce terme de « distribution Linux » est sans doute d'ordre marketing : « Linux » est une marque connue. Mais ce terme n'a pas de base technique. Debian, CentOS, Gentoo, etc sont donc des systèmes d'exploitation, pas des distributions Linux.
Si on veut étudier plus précisement la part quantitative des différentes sources de code dans un système comme Ubuntu, on peut lire « How much GNU is there in GNU/Linux?. Mais cet article ne prend en compte que le nombre de lignes de code, pas leur importance (une ligne de la libc compte certainement plus que dix lignes d'un gadget qui affiche un truc rigolo sur l'écran) ou leur part réellement utilisé (le code du noyau est surtout composé d'innombrables pilotes dont seule une petite partie sert réellement).
L'article seul
RFC 6108: Comcast's Web Notification System Design
Date de publication du RFC : Février 2011
Auteur(s) du RFC :
C. Chung (Comcast), A. Kasyanov (Comcast), J. Livingood (tComcast), N. Mody (Comcast), B. Van Lieu
Intérêt historique uniquement
Première rédaction de cet article le 24 février 2011
Soit un FAI avec beaucoup de clients résidentiels. La plupart utilisent une machine sous Windows. Beaucoup de ces machines sont infectées par un des innombrables virus ou vers qui existent pour cette plate-forme. Devenues des zombies, ces machines participent désormais à diverses opérations illégales comme les dDoS ou l'envoi de spam. Si le FAI détecte, par le comportement de ces machines, ou par des rapports qui lui sont envoyés, qu'un de ses clients a été zombifié, comment le prévenir ? Vues les marges financières existantes dans cette industrie, pas question d'envoyer un technicien compétent chez le client pour lui expliquer. Il n'est même pas possible de l'appeler et de passer une heure à répondre à ses questions idiotes, cela mangerait tout le profit retiré de l'abonnement de ce client. Ce RFC décrit le système qu'utilisait Comcast pour prévenir ses abonnés.
Il existe bien sûr d'autres méthodes, comme de couper purement et simplement la connexion Internet dudit client. Cette méthode est régulièrement réclamée par certains éradicateurs. Outre qu'elle n'est pas dans l'intérêt financier du FAI (le client arrêterait de payer s'il était coupé), elle n'est pas envisageable dans un État de droit (en France, le Conseil Constitutionnel avait cassé une version de la loi Hadopi car elle prévoyait une coupure de l'accès Internet sans jugement). Même dans un pays de cow-boys, cette mesure est largement jugée comme trop radicale (voir la description de la section 12, plus loin). En outre, l'utilisateur risque de ne pas la comprendre, de croire à une panne et d'embêter le support utilisateur. Comcast a donc choisi une autre approche, celle de la notification à l'utilisateur, dont on espère qu'il réagira et prendra des mesures pour éliminer le malware de sa machine.
Concevoir un tel système de notification n'est pas évident. Il n'existe (heureusement) pas de moyen technique standard permettant à un tiers, le FAI, de faire soudain apparaître des messages sur l'écran de l'utilisateur (un tel mécanisme serait vite détourné par des plaisantins). Envoyer un courrier est simple et automatisable mais rien ne garantit que l'utilisateur les lit (la plupart ne le liraient pas ou bien, peut-être à raison, considéreraient-ils qu'il s'agit de hameçonnage).
L'approche de Comcast est donc de profiter du fait que la plupart
des utilisateurs passent beaucoup de temps à regarder des pages
Web. Il « suffit » de détourner les pages HTML,
d'y insérer le message et bingo ! Le message apparaîtra à l'écran. Voici une copie d'écran de http://www.example.com/,
avec l'exemple de modification que donne le RFC en section 8. Cette
modification consiste simplement en l'ajout d'un peu de
JavaScript:
 (On note que la possibilité d'accuser réception, mentionnée plus loin
dans le RFC, est absente de cet exemple. Notez aussi le commentaire
dans le code CSS qui insiste sur l'importance
de ne pas hériter des styles qui seraient déjà présents dans la page.)
(On note que la possibilité d'accuser réception, mentionnée plus loin
dans le RFC, est absente de cet exemple. Notez aussi le commentaire
dans le code CSS qui insiste sur l'importance
de ne pas hériter des styles qui seraient déjà présents dans la page.)
Bref, ce mécanisme est une attaque de l'homme du milieu, réalisée pour la bonne cause. Les auteurs insistent beaucoup sur le fait que leur solution repose sur des normes ouvertes et n'utilise pas de DPI mais cela me semble tout à fait secondaire. Le point important est que le FAI joue un rôle plus actif dans la chasse aux zombies et, pour cela, s'insère dans les communications de son client. Ce n'est pas forcément une mauvaise idée mais c'est une modification sérieuse du modèle traditionnel (où le client était seul maître à bord, même si, la plupart du temps, il ne se rendait pas du tout compte de la responsabilité qu'il avait.) Pour l'instant, il n'existe pas de travail organisé à l'IETF sur ce problème des machines zombies et chacun en est donc conduit à expérimenter seul (cf. section 13 du RFC).
Les détails pratiques suivent. La solution décrite très en profondeur est spécifique à DOCSIS mais pourrait être adaptée assez facilement à d'autres types d'accès. Les techniques utilisées sont le protocole ICAP (RFC 3507) et HTTP, les logiciels étant Squid et Tomcat.
Voyons d'abord le cahier des charges exact. Il figure en section 3. Je ne vais pas répéter tous ses points ici, seulement les plus importants. D'abord, les principes généraux :
- N'est utilisé que pour les notifications de problèmes sérieux (comme le recrutement dans un botnet), pas pour des publicités.
- Tourne sur le port 80, celui de HTTP, car à peu près tous les utilisateurs s'en servent. Ne doit pas gêner les autres protocoles qui utiliseraient ce port. D'une manière générale, ne doit pas perturber ou casser des applications.
- N'utilise pas de ReSeTs TCP comme le faisait Comcast pour démolir les connexions BitTorrent de ses utilisateurs (sauf erreur, c'est la première fois que Comcast reconnait officiellement qu'il utilisait cette méthode (RFC 3360), après l'avoir nié pendant longtemps).
- Permet à l'utilisateur de dire « Oui, je sais » et de faire ainsi cesser les notifications.
- Respecte les pages Web existantes, n'en supprime pas du contenu et n'en insère pas (à vous de voir si l'exemple Javascript montré plus haut respecte ce principe). Le RFC note justement que toute modification des pages Web existantes susciterait une levée de boucliers.
Ensuite, ceux liés au relais HTTP :
- Logiciel libre, avec un client ICAP (Squid a été choisi, entre autres pour cette gestion d'ICAP).
- Possibilité d'ACL car les notifications ne doivent être envoyés qu'à certains utilisateurs, et que certaines pages Web ne doivent pas être affectées du tout.
Il y a aussi quelques exigences techniques pour le serveur ICAP (un protocole, normalisé dans le RFC 3507, permettant à un serveur ou relais de demander au serveur ICAP des changements à apporter au contenu qu'ils servent) et pour l'arrière-plan du système (la partie qui va noter les comportements bizarres des machines, ainsi que les actions de réparation des utilisateurs).
Armée de ces bons principes, les sections 4, 5, 6 et 7 présentent le système effectivement déployé. Le relais Squid... relaie les requêtes HTTP et, lorsqu'il reçoit une réponse, demande au serveur ICAP si et comment la modifier. Le serveur ICAP utilise GreasySpoon. Si la notification est nécessaire, il répond avec un bout de code Javascript à insérer dans les pages. Un serveur Tomcat garde les messages à envoyer aux utilisateurs (il peut y avoir plusieurs types de messages). Un équipement de load-balancing est utilisé pour séparer le trafic HTTP du reste (même s'il tourne sur le port 80) et pour n'aiguiller vers le relais Squid que les clients listés comme suspects. Le dessin n° 1 montre tous ces composants et leur interaction. Le dessin n° 2, plus concret, illustre les connexions réseau entre ces composants. À noter qu'il ne semble pas y avoir de protection contre un malware qui supprimerait la notification (après tout, il contrôle la machine de l'utilisateur).
Voici pour le fonctionnement technique. Maintenant, quelques considérations de sécurité, en section 10. D'abord, la rédaction du message de notification doit être très soignée, notamment pour éviter que l'utilisateur ne la considère comme du hameçonnage. Le message ne doit pas mener à une page où l'utilisateur est invité à taper son mot de passe. Il doit fournir un moyen d'obtenir plus de détails, par exemple un numéro de téléphone ou tout autre mécanisme de validation indépendante.
Un tel système de modification des pages Web vues, à des fins de notification, est-il Bon ou Méchant ? La section 11 discute cette question philosophique. Certains peuvent penser que le changement, par un intermédiaire technique, le FAI, est un franchissement de la ligne rouge. Selon ce point de vue, les intermédiaires ne devraient jamais tripoter le contenu des communications. Le RFC ne répond pas réellement à ces objections (à part en affirmant que Comcast a de « good motivations » et par l'argument traditionnel de chantage que, si on refuse ce mécanisme, on aura pire, par exemple à base de DPI) mais note que, au minimum, l'existence de ce système doit être annoncée aux clients (actuellement, la plupart des FAI gardent un silence complet, vis-à-vis de leurs propres clients, sur les éventuelles opérations de « gestion du réseau » qu'ils effectuent).
Et, compte-tenu des objections que peut soulever ce système, fallait-il publier ce RFC ? C'est un débat traditionnel à l'IETF : lorsqu'une idée ne fait pas l'objet d'un consensus, mais est largement déployée sur l'Internet, faut-il la documenter dans un RFC (évidemment sans que celui-ci ait le statut de norme, cf. RFC 1796 et RFC 2026), au risque que des gens croient que l'idée bénéficie d'un soutien de l'IETF, ou bien l'ignorer, au risque que les RFC ne reflètent plus la réalité de l'Internet ? La section 11 répond également à ce débat de fond en considérant qu'il vaut mieux publier, ne serait-ce que pour aider aux futurs débats.
Le problème de ces notifications est d'autant plus complexe que le FAI n'est pas tout seul face aux décisions à prendre : de nombreux organismes, au gouvernement ou ailleurs, font lourdement pression sur les FAI pour que ceux-ci fassent quelque chose contre les machines zombies. Est cité Howard Schmidt, conseiller d'Obama pour la cybersécurité, qui dit « As attacks on home-based and unsecured networks become as prevalent as those against large organizations, the need for ISPs to do everything they can to make security easier for their subscribers is critical for the preservation of our nation's information backbone. » Le RFC dit clairement qu'un des buts de cette technique de notification est de satisfaire de telles demandes.
Mais, pour atteindre ce but, y a-t-il d'autres méthodes ? La section 12 présente une alternative possible, le jardin fermé. Dans un tel système, les clients détectés comme zombifiés sont limités à l'accès à un petit nombre de sites Web, par exemple ceux de sites liés la sécurité, ou à la mise à jour de leur système d'exploitation. De facto, cela notifie l'utilisateur qu'il y a un problème. On peut aussi rediriger toutes les autres connexions HTTP vers un serveur présentant un message d'alerte. Mais c'est beaucoup plus violent, en coupant l'accès à des services que l'utilisateur peut considérer comme essentiels, comme une conversation téléphonique qui serait alors brutalement interrompue. La responsabilité du FAI serait alors clairement engagée. Le RFC rappelle à juste titre qu'il n'y a pas que le Web ! Et rejette donc l'idée du jardin fermé.
Ah, et mon opinion personnelle ? Je pense que cette méthode est un compromis acceptable. Sur le principe, c'est une attaque de l'intermédiaire et une violation de la neutralité du réseau mais l'ampleur du problème des machines Windows infectées, qui attaquent ensuite les autres, est tel qu'il peut être justifié de prendre des mesures un peu dures. Après, tout dépendra des détails concrets de réalisation (taux de fausses alertes, par exemple).
Un article avait été fait à l'occasion des premiers tests, « Comcast to send infected-PC alerts ».
L'article seul
RFC 6104: Rogue IPv6 Router Advertisement Problem Statement
Date de publication du RFC : Février 2011
Auteur(s) du RFC : T. Chown (University of Southampton), S. Venaas (Cisco)
Pour information
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 24 février 2011
Il y a une tension permanente en sécurité des réseaux, entre la sécurité et la facilité d'usage (quelqu'un a une meilleure traduction pour convenience ? « ergonomie » ?). Ainsi, le protocole IPv6 permet l'autoconfiguration sans état des machines, par le biais d'annonces, les RA (Router Advertisement) diffusées par les routeurs. C'est très pratique et IPv4 n'a rien de tel. Mais qui dit que la machine qui diffuse est un vrai routeur légitime ? Rien. Les « RAcailles » (mauvaise traduction de rogue RA), ces annonces envoyées à tort, sont très fréquents dans la réalité. Avant que des solutions soient proposées et discutées, ce court RFC spécifie précisément le problème.
Le mécanisme des RA (Router Advertisement) est décrit dans le RFC 4861. Le principe est que le ou les routeurs officiels du réseau local diffusent des informations telles que le préfixe à utiliser sur ce lien (ce qui permet l'autoconfiguration du RFC 4862) ou l'adresse IP du routeur à utiliser par défaut. Les « RAcailles » sont des annonces RA envoyées par un engin qui n'est pas routeur officiel. Cela peut être dû à une attaque délibérée, ou tout simplement à une erreur de configuration, par exemple une machine configurée pour monter un hotspot WiFi avec réseau ad hoc et qui diffuse donc des RA, se croyant le routeur officiel. Ce phénomène est fréquent sur les réseaux sans-fil partagés (on le voit à chaque réunion IETF, dont les participants sont pourtant censés être des experts, et il faut des annonces répétées au micro pour que les machines émettant des RAcailles se taisent ; un exemple à la réunion d'Hiroshima est décrit dans ce message). Mais on le voit aussi dans des réseaux filaires, par exemple les résidences d'étudiants.
Sur un réseau sans-fil partagé, il n'y a guère de moyen de repérer le coupable, dont on ne connait que l'adresse MAC. Encore aujourd'hui, la solution la plus courante (décrite en section 3.7) est de filtrer les RA, sur la base de l'adresse attendue (liste blanche), ou sur celle des adresses repérées comme erronées (liste noire). Mais cela diminue évidemment sérieusement l'intérêt de l'autoconfiguration (toujours cette tension entre sécurité et facilité d'usage). Sur Linux, cela serait quelque chose comme :
% ip6tables -A INPUT -m mac --mac-source 00:1b:77:bc:a4:e6 -j DROP
(Exercice pour le lecteur : cette commande bloque absolument
tout le trafic en provenance de
00:1b:77:bc:a4:e6. Comment ne bloquer que les
RA ? Benjamin Bachelart
suggère ip6tables -A INPUT -m mac --mac-source
00:1b:77:bc:a4:e6 -p icmpv6 --icmpv6-type router-advertisement -j
DROP qui semble correct mais je ne l'ai pas testé.)
Quel problème posent ces RAcailles ? La section 1 les résume : si les machines présentes les croient, et utilisent les informations qu'ils contiennent, elles peuvent se trouver partiellement ou totalement coupées du réseau. Par exemple, si elles changent l'adresse IP du routeur par défaut, pour celle indiquée dans le RAcaille, tous les paquets qui ne sont pas envoyés au réseau local sont transmis à un routeur voyou, qui peut les transmettre... ou pas.
Un point important de ce RFC est qu'il se focalise surtout sur les RAcailles accidentels, ceux provoqués par une erreur de configuration, qui sont de loin les plus fréquents aujourd'hui (les méchants sont plus habiles mais les maladroits sont beaucoup plus nombreux...). En outre, si les RAcailles sont émis par un attaquant conscient de ce qu'il fait, protéger contre eux serait très insuffisant : s'il peut émettre des faux RA, il peut aussi bien interférer avec le protocole ND.
Donc, première question (section 2), quel phénomène peut mener à l'envoi de RAcailles par une machine ? Il y en a trois :
- La traditionnelle erreur commise par l'administrateur réseaux (qui tape les mauvaises commandes sur le routeur, ou bien sélectionne la mauvaise option dans un cliquodrome),
- L'erreur commise par un utilisateur qui n'est pas l'administrateur réseaux (comme dans l'exemple du réseau ad hoc cité plus haut, par exemple suite à l'activation de ICS, qui transformera également la machine en un serveur DHCP IPv4, ou bien dans le cas d'un portable configuré pour un réseau isolé et connecté ensuite à un autre réseau),
- L'attaque délibérée par le méchant, prélude à une DoS ou bien à une attaque de l'intermédiaire. Notons bien que ce genre d'attaques est rarement signalé (alors que les récits de RAcailles accidentels abondent). Le RFC relègue donc ce problème pour de futures études et se concentre sur le problème le plus fréquent.
Et quelles sont les solutions possibles ? La plupart seront
détaillées dans d'autres RFC comme le RFC 6105 mais la section 3 du nôtre
donne quelques pistes. La plus évidente est de laisser tomber
l'autoconfiguration et de revenir aux solutions à configuration
manuelle. Sûr mais pas forcément enthousiasmant pour l'administrateur
du réseau. D'autant plus que cela n'éliminera pas les
erreurs... Pour être cohérente, une telle solution implique, outre la
configuration manuelle de l'adresse IP et du routeur, d'ignorer les
éventuels RA (avec Linux, il faut mettre la
variable sysctl net.ipv6.conf.all.accept_ra à 0).
Autre solution, profiter de ce que les RA soient diffusés à tous pour les observer et détecter ainsi rapidement les RAcailles. C'est ce que fait NDPMon, par exemple. Fait dans le commutateur, comme le propose le RFC 6105, cela pourrait permettre le blocage des RAcailles en temps réel. Le filtrage par les commutateurs peut aussi être configuré manuellement, par le biais d'ACL. Après tout, l'administrateur réseaux sait sur quel(s) port(s) du commutateur se trouvent les routeurs légitimes et il peut donc bloquer les RA sur les autres (quelqu'un a des exemples concrets avec des commutateurs réels ? Je n'ai jamais essayé.) Notez que cela marche seulement si toutes les communications passent par le commutateur, ce qui est typiquement le cas aujourd'hui des réseaux filaires. Avec un réseau sans-fil ad hoc, il faudra trouver autre chose.
De plus haute technologie, il y a aussi l'inévitable solution utilisant la cryptographie, SEND (RFC 3971), où les annonces des routeurs légitimes sont signées. SEND est très peu déployé en pratique, sans doute en raison de sa complexité, et du fait qu'il faille configurer chaque machine avec le certificat de la CA. Du point de vue sécurité, SEND est la solution idéale (cf. section 6), mais il est probablement peu adapté aux environnements assez ouverts, comme un campus ou bien un café avec WiFi, où chacun administre sa machine. Le principal avantage de SEND est qu'il fonctionne aussi en cas d'attaque délibérée et intelligente et il convient donc bien aux environnements qui exigent un haut niveau de sécurité.
D'autres solutions techniques ? Mais oui, l'imagination des experts étant inépuisable. Par exemple, puisque le RFC 4191 ajoute une option Préférence aux RA, pourquoi ne pas mettre cette option à la valeur maximale pour les routeurs légitimes, en espérant que les accidentels la laissent à une valeur plus faible ? Mais le RFC n'indique pas si cette option est souvent reconnue par les clients. Autre idée, se servir des protections de la couche 2 (par exemple 802.1X) pour limiter l'accès au réseau. Le problème est qu'authentification n'est pas autorisation. Une machine peut avoir légitimement un accès, sans être pour autant autorisée à envoyer des RA. Il reste le filtrage au niveau de la machine, déjà mentionné. Son principal inconvénient est qu'il faut manuellement maintenir à jour les ACL, ce qui supprime une bonne partie de l'intérêt de l'autoconfiguration.
Et la contre-attaque ? Si une machine envoie des RAcailles sans y
être autorisée, on n'a pas de raison d'avoir des scrupules à la faire
taire. Une autre solution aux RA non autorisés est donc de surveiller
le trafic (comme avec NDPMon) et de générer des faux RA, ayant la même adresse source que
les RAcailles, avec une durée de vie de zéro. Cet empoisonnement
devrait donc masquer le RAcaille par le RA à durée de vie nulle (et
qui ne sera donc pas utilisé par les machines). Cette technique est
mise en œuvre dans la suite logicielle
KAME et a déjà été déployée lors de réunions
IETF. On peut télécharger le source en http://ramond.sourceforge.net. À noter qu'un tel outil
pourrait aussi parfaitement être utilisé pour lancer une belle
attaque par déni de service (cf. section 7).
Enfin, dernière solution proposée par notre RFC, configurer les machines pour n'utiliser que DHCPv6 et renoncer à l'autoconfiguration sans état. DHCP peut allouer les adresses. Une nouvelle option, en cours de normpalisation, lui permettra d'indiquer également le routeur à utiliser. DHCP présente de nombreux avantages pour l'administrateur réseaux, notamment d'un meilleur contrôle de la configuration des machines. Mais on n'a fait que déplacer le problème. Comme le montre l'expérience d'IPv4, les serveurs DHCP non autorisés sont un problème, autant que les RA non autorisés... Le seul avantage serait que le problème est mieux connu avec DHCP (voir aussi la section 5.2).
Les différentes solutions, avec leur domaine d'application, sont résumées dans un tableau en section 4. La section 5 discute ensuite d'autres problèmes liés à celui des RAcailles. Par exemple, un RA n'est pas forcément envoyé par diffusion, il peut être transmis directement à une machine et, dans ce cas, a des chances de ne pas être détecté par d'éventuels outils de surveillance. Les RAcailles accidentels seront sans doute en multicast mais un attaquant, lui, choisira peut-être donc l'unicast.
La section 5.2 compare les menaces de RA par rapport à celles de DHCP. De même que les RA peuvent être protégés avec SEND, DHCP peut être protégé par des options d'authentification (RFC 3315, section 21). Mais ne nous voilons pas la face : personne n'utilise ces options de sécurité (elles ont même été larguées par le RFC 8415). Elles sont bien trop contraignantes, alors qu'on choisit justement RA ou DHCP pour se simplifier la vie.
L'importance d'une surveillance du réseau, avec un logiciel comme NDPMon, est rappelée dans la section 5.4. Si cette recommandation est appliquée, l'administrateur réseaux saura au moins ce qui se passe. Actuellement, il est probable que la plupart de ces administrateurs ne savent même pas si le problème existe dans leur réseau.
Toujours dans la série « guérir si on n'a pas pu prévenir », la section 5.5 est consacrée aux conséquences. Si les RAcailles existent et que certaines machines en ont tenu compte, que faire ? Le comportement de la machine touchée est très imprévisible (plusieurs adresses, plusieurs routes par défaut, et, avec SHIM6, la machine peut même croire qu'elle est réellement connectée à plusieurs réseaux). Aujourd'hui, il n'y a pas de moyen simple, une fois les RAcailles supprimés, de ramener ces machines à la normale, on risque d'attendre jusqu'à deux heures (RFC 4862, section 5.5.3) avant que la machine n'oublie le RAcaille.
Quelques documents à lire sur ce sujet et des logiciels à essayer :
- Le site web de NDPMon, excellent outil de détection des annonces v6, notamment des RA.
- Le dépôt de rafixd, un outil d'empoisonnement actif des RAcailles.
- Le site Web de Ramon, outil de détection utilisé par exemple à la réunion RIPE 63, avec succès.
- Une discussion des différentes solutions (en anglais).
- Très détaillé, très concret : « IPv6 security », chez Cisco press, couvre largement les RAcailles..
- En français, le problème est décrit en détail dans « La sécurité dans une transition vers IPv6 » de Gaël Beauquin.
L'article seul
RFC 6105: IPv6 Router Advertisement Guard
Date de publication du RFC : Février 2011
Auteur(s) du RFC : E. Levy-Abegnoli, G. Van de Velde, C. Popoviciu (Cisco Systems), J. Mohacsi (NIIF/Hungarnet)
Pour information
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 24 février 2011
Comme le décrit très bien le RFC 6104, la situation de la sécurité des RA (Router Advertisement, cf. RFC 4861) n'est pas satisfaisante. Les « faux RA », envoyés par un méchant ou par un maladroit, sont trop fréquents. Notre RFC 6105 propose donc une solution. Elle est bien plus légère que SEND et repose sur un filtrage au niveau deux.
Je vous renvoie à mon article sur le RFC 6104 pour davantage de détails sur le problème. Ici, je ne vais parler que de la solution. Elle fonctionne pour un réseau partagé où les participants doivent passer par un commutateur (on ne peut donc pas l'utiliser pour du WiFi ad hoc, cf. section 5) et elle nécessite que ledit commutateur mette en œuvre le système décrit dans ce RFC (cf. section 2 et sa figure 1).
Officiellement, SEND (RFC 3971), reste la solution de choix. Après l'obligatoire rappel que SEND résoudrait tous les problèmes, notre RFC rappelle qu'il n'est pas réaliste d'espérer un déploiement massif de SEND dans les années à venir. Pire, le RFC reconnait que certains équipements (on pense au célèbre grille-pain IPv6) n'auront jamais SEND. La solution proposé, RA Guard, est donc un système de filtrage des RA par le commutateur, suivant plusieurs méthodes possibles. Le commutateur sert donc de centre de contrôle, autorisant ou bloquant les RA selon plusieurs possibilités.
Quelles sont ces possibilités ? Les sections suivantes les décrivent. D'abord, le RA guard sans état (section 3). Dans ce mode, le commutateur examine les RA entrants et les bloque ou pas en ne tenant compte que du contenu du RA et de sa propre configuration. Il n'a donc pas de mémoire, pas d'état. Sur quelle base décider ? L'adresse MAC source du RA, le port sur lequel le RA a été reçu, l'adresse IP source, le ou les préfixes annoncés dans le RA… Le commutateur a pu être configuré pour autoriser ou interdire sur la base de ces informations. Une fois le RA considéré comme légitime, il est transmis sur toutes les interfaces, comme n'importe quel paquet. Le RFC présente par exemple une solution ultra-simple où l'administrateur du commutateur indique juste un port comme étant celui du routeur officiel, et les RA arrivant sur les autres ports seront donc simplement ignorés. Cette méthode a l'inconvénient de nécessiter une configuration manuelle.
Plus sophistiquée, le RA guard avec état (section 4). Le principe est d'apprendre automatiquement à quoi ressemblent les RA légitimes, avant de se mettre à bloquer les autres. Dans sa version la plus simple, le commutateur écoute pendant un moment (défini par l'administrateur), notant qui envoie les RA, puis considère que, après ce laps de temps, tout autre RA est illégitime. Cela protège donc contre les RA anormaux survenant après cette période d'apprentissage. Si un nouveau routeur légitime arrive, on recommence l'apprentissage de zéro.
La section 4.1 décrit les détails. Au début, le commutateur est dans l'état
LEARNING où il écoute les RA. Fait-il suivre tous
les RA pendant cette phase, ou bien les bloque-t-il tous ? C'est
configurable selon le degré de paranoïa de l'administrateur. Une fois
cette phase terminée, les interfaces passent dans l'état
BLOCKING ou FORWARDING selon
qu'elles recevaient des RA acceptables ou non. (Le
RFC ne mentionne donc que la possibilité d'apprendre les interfaces où
se trouve un routeur légitime, pas celles d'apprendre son adresse
MAC.) La section 7 suggère fortement que l'administrateur jette un
coup d'œil à la liste des interfaces à RA légitimes, pour
vérifier… Par contre, elle ne rappelle pas que le mécanisme est mis
en danger si un routeur illégitime est présent dès la phase
d'apprentissage. Normalement, ce cas est traité par le fait que cette
technique est combinée avec des filtres manuels comme ceux de la
section précédente.
Encore plus ambitieux, la possibilité pour le commutateur d'être un mandataire SEND (section 4.2). L'un des problèmes de SEND est que chaque machine du réseau, grille-pain et frigidaire inclus, doit faire de la cryptographie (parfois compliquée, par exemple s'il faut récupérer des certificats intermédiaires) et être configurée avec un certificat. Avec le mandataire SEND, seul le commutateur va valider les annonces signées par SEND. Il les fera suivre ou les bloquera en fonction du résultat de la validation.
Je ne connais pas de liste d'implémentations officielles de ce service. Apparemment, certains le déploieraient déjà, si on en croit des témoignages. Fin 2011, Juniper annonçait RA Guard pour les versions 12.x, Cisco a déjà cette fonction dans des engins comme le Cisco 3750g avec « advanced enterprise featureset » (voir un bon article sur le sujet et un plus détaillé, du même auteur). Brocade n'a rien communiqué. Une technique permettant de contourner le RA guard a déjà été décrite.
L'article seul
Le choix des clients XMPP sur Android
Première rédaction de cet article le 23 février 2011
Le choix d'une application pour téléphone Android est parfois très simple lorsque personne n'a développé d'application sérieuse pour une fonction, et parfois plus compliqué quand chacun a cru malin de développer une nouvelle application pour une fonction où il y en avait déjà plusieurs. C'est le cas de la fonction de client XMPP.
XMPP, normalisé dans le RFC 6120, est un protocole de messagerie instantanée, parfois cité sous son ancien nom de Jabber. Il sert à un peu tout, par exemple je l'utilise dans un cadre professionnel pour des échanges rapides et synchrones avec des pairs, en cas de problèmes, ou bien comme tableau pendant une téléconférence lorsque ce qu'on veut dire passe mieux à l'écrit qu'à l'oral (un problème fréquent lors des conférences internationales en anglais ; tous ceux qui m'ont entendu parler en anglais comprendront).
J'ai donc deux comptes XMPP. Attention, si les identifiants XMPP
(ou JID pour Jabber ID, cf. RFC 7622) ressemblent aux adresses de
courrier électronique, ils sont en fait
complètement différents. N'essayez pas de me joindre par courrier à
ces adresses ! Le premier compte est pour les applications sans trop
d'importance, bortzmeyer@gmail.com (le service de
Google, Google Talk, est
en effet entièrement en XMPP) et le second sert professionnellement,
bortzmeyer@dns-oarc.net. Il me faut donc une
application permettant d'avoir plusieurs comptes et de passer de l'un
à l'autre assez facilement.
XMPP est une norme riche avec plein d'extensions et j'utilise très souvent celle qui permet des conversations à plusieurs (MUC, pour Multi-User Chat ou « conférence » ou encore Jabber room). Il se trouve qu'à l'heure actuelle, c'est le critère le plus discriminant entre les clients XMPP pour Android : très peu permettent ces conférences.
OK, venons-en aux logiciels. J'ai commencé par tester Beem parce que c'est le seul
libre. Il marche bien
mais, hélas, il ne permet pas la participation à une
conférence. C'est d'autant plus paradoxal que le support pour
ce logiciel se fait dans une telle conférence,
beem@conference.elyzion.net. Bon, de toute façon,
il ne gère pas non plus les comptes multiples.
J'ai donc choisi pour l'instant Jabiru. Il marche bien, est multi-comptes (mais, hélas, un seul à la fois, il faut se déconnecter et reconnecter pour changer de compte). Le principal manque est que je ne vois pas comment conserver une liste de ses conférences favorites pour éviter d'avoir à taper leur nom à chaque fois qu'on veut s'y connecter.
Les autres logiciels que j'ai regardé :
- imov. Mono-compte et semble très bogué (écrans vides mystérieux).
- emess. Pas testé, le site Web est seulement en russe.
- Xabber. Bonne gestion du multi-comptes. Pas de conférences encore (cette fonction était, en février 2011, prévue à court terme).
- Mundu a la particularité de gérer d'autres protocoles que XMPP mais, hélas, pas celui qui m'intéresserait, IRC. D'autre part, les publicités y sont vraiment envahissantes. Pas de conférences.
- jTalk semble vraiment trop minimaliste.
- Jabbroid n'a jamais réellement marché pour moi, je n'ai même pas pu me connecter à Google Talk. Et le message d'erreur qu'il produit alors est collant, ne disparaissant qu'au redémarrage du téléphone.
- Yaxim, que j'ai découvert récemment et pas testé.
Globalement, je trouve la situation peu satisfaisante. Beaucoup de logiciels, la plupart très sommaires (cela fait projet d'étudiant qui a terminé son stage et arrêté le développement). Rien d'aussi riche que le client multi-protocoles Pidgin sur Unix. Et encore, je n'ai pas encore testé des choses indispensables pour une utilisation professionnelle comme la connexion avec TLS... (Xabber a une option permettant d'imposer TLS pour la connexion à un serveur mais je ne l'ai pas essayée.)
L'article seul
RFC 6115: Recommendation for a Routing Architecture
Date de publication du RFC : Février 2011
Auteur(s) du RFC : T. Li (Cisco)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF RoutingResearchGroup
Première rédaction de cet article le 22 février 2011
Le mécanisme de routage dans l'Internet est une invention géniale. Bien qu'ayant été décrié par tous les experts des télécoms, unanimes dans leur appréciation comme quoi cela ne pourrait jamais marcher, ce mécanisme a permis la croissance d'un réseau de quatre machines aux États-Unis à des débuts, vers des centaines de millions aujourd'hui, réparties partout dans le monde. Néanmoins, rien n'est éternel en technologie. Tous les systèmes sont un jour remplacés, ne serait-ce que parce que de nouveaux besoins émergent et que de nouveaux problèmes apparaissent. Le groupe RRG (Routing Research Group) de l'IRTF est donc chargé d'explorer, pour le moyen et long terme, les solutions qui pourraient remplacer le routage actuel, notamment pour améliorer son passage à l'échelle, le cas des réseaux multihomés et la possibilité de faire de l'ingénierie de trafic. Ambitieux défi puisqu'il faut, non seulement concevoir un système meilleur que le système qui a assuré un tel succès, mais aussi le déployer, dans un réseau qui se méfie des nouveautés.
On ne s'étonnera donc pas que le RRG a à moitié échoué. Aucune idée géniale, créant un consensus par sa beauté, n'a émergé. De nombreuses propositions, souvent astucieuses, ont été présentées et discutées mais aucune n'a fait l'objet d'un consensus. Les présidents du groupe ont fini par publier le RFC tel quel, avec les différentes contributions, les points sur lesquels un accord s'est fait, et leur recommandation personnelle, qui est de partir de la proposition ILNP. Celle-ci a été normalisée en novembre 2012 dans les RFC 6740 et suivants.
D'abord, un peu de contexte. Les documents sur lesquels se base le
travail du RRG (Routing Research Group) n'ont pas
tous été publiés en RFC encore. Parmi eux, le RFC 6227, cahier des charges du projet. Les autres sont seulement des Internet-Drafts. Le
principal est l'exposé du problème, draft-narten-radir-problem-statement. Ces
deux documents ont donné naissance à de nombreuses
propositions. Attention en les lisant : il n'y a pas de censure à
l'IRTF et toutes les propositions sont étudiées
et discutées. Beaucoup provenaient d'une personne isolée et, s'il
existe parfois des génies solitaires et incompris, les propositions
individuelles sont plus souvent l'œuvre de gens assez
déconnectés de la pratique. On trouvera donc de tout dans ce RFC,
hommage à l'ouverture de l'IRTF, plus qu'à sa capacité de
sélection...
Il y avait en effet pas mal de zozos au RRG, des fois même incapables de formater un message électronique correctement (erreurs dans les citations, par exemple). Plusieurs propositions n'ont ainsi pas encore (?) connu le moindre début de mise en œuvre.
À noter également que les bruyants partisans des solutions de type « table rase » comme John Day ou comme le projet Clean Slate n'ont pas participé du tout à cet effort. À leur décharge, il faut dire que la solution devait être déployable incrémentalement, ce qui contredisait leur postulat de départ, qui est d'ignorer l'existant. Mais cette non-participation reflète aussi leur difficulté à travailler sur des questions concrètes. Tant qu'on se contente d'interviews au New York Times, refaire l'Internet en partant de zéro est facile. S'il faut écrire de vraies normes, compréhensibles, et se confronter au jugement de ses pairs, il y a moins d'enthousiasme.
Je ne vais pas détailler chacune des nombreuses propositions, plutôt me servir de chacune pour exposer un défi particulier auquel est confronté l'architecte du futur réseau. Par manque de temps, j'ignorerai même complètement certaines des propositions.
Pour résumer ces documents de base, à quoi servait le groupe RRG (Routing Research Group) ? Il avait été établit pour trouver une nouvelle architecture de routage pour l'Internet, rien que ça. Il s'est réuni à chaque réunion IETF de 2007 à 2010, a beaucoup discuté via sa liste de diffusion, mais, comme indiqué, n'a pas atteint de consensus. Les présidents du groupe, Lixia Zhang et Tony Li, deux experts expérimentés et reconnus, ont donc fini par jeter l'éponge et décider de tout publier, en ajoutant leur recommandation personnelle en faveur d'ILNP. Chaque proposition d'architecture ou de protocole a bénéficié d'un résumé (en général par son auteur, et la plupart de ces résumés sont de lourdes publicités avec peu de détails pratiques), résumé qui inclus obligatoirement les avantages de la proposition, mais aussi de ses coûts (il n'y a pas de déjeûner gratuit...), d'une critique par un autre membre du groupe et, parfois, d'une réponse de l'auteur à cette critique. (En pratique, je trouve que certaines critiques pinaillent sur quelques détails de la proposition, et n'analysent pas assez ses grandes idées et principes.)
Mais tout n'a pas été un flop : s'il n'y a pas eu d'accord sur une proposition concrète, le groupe a quand même mis en évidence plusieurs points importants, qui n'étaient pas évidents au début, mais qui ont rencontré un large accord. Ces points étaient (section 1.2) parfois de simple terminologie, parfois portant sur des concepts plus profonds. Par exemple :
- [terminologie] Un nœud est soit un routeur, soit une machine terminale (host).
- [terminologie] Un nom est une suite de bits utilisée pour désigner quelque chose (c'est vague mais c'est bien pour indiquer que le terme « nom » est très générique, et qu'il existe des termes mieux définis). Il existe des noms à des tas d'endroits de la pile des couches. Dans cette définition, le nom n'est donc pas forcément lisible et mémorisable par un humain.
- Une adresse est un nom qui mêle identification et indication de l'emplacement dans le réseau (évidemment pas dans l'espace physique). Les actuelles adresses IP sont dans cette catégorie.
- Un localisateur est un nom qui ne sert pas à l'identification mais uniquement pour exprimer une position dans le réseau (sans être une route complète vers l'objet). Actuellement, il n'existe pas de vrais localisateurs dans l'architecture Internet.
- Un identificateur est un nom qui ne contient pas d'information topologique (c'est-à-dire qu'il est complètement indépendant de la position du nœud, si on débranche une machine au Burkina Faso et qu'on la rebranche au Canada, ou si on passe de la connexion filaire avec le réseau local, à une connexion 3G, l'identificateur ne doit pas changer). Aujourd'hui, certains FQDN peuvent être considérés comme des identificateurs, selon cette définition. Même chose pour les clés SSH ou HIP.
- L'intérêt de séparer les définitions des identificateurs et des localisateurs est qu'un des points consensuels du groupe RRG a été que la séparation de l'identificateur et du localisateur était à la fois faisable et souhaitable.
- Un autre consensus s'est fait sur l'importance du multihoming, et qu'il soit possible à un coût raisonnable (la solution actuelle, avec adresses PI et BGP, ne passe pas tellement à l'échelle).
À propos de terminologie, je recommande au lecteur du RFC qui n'aurait pas suivi tous les travaux du RRG de bien lire la section 1.3, qui liste les sigles les plus courants. Tout le reste du RFC en fait une forte consommation et certains ne sont pas forcément familiers à l'ingénieur réseaux (comme ITR, Ingress Tunnel Router, qui désigne le point d'entrée d'un tunnel, pour les solutions à base de tunnel ou EID, Endpoint IDentifier, qui désigne l'identificateur de la machine de destination).
Maintenant, assez de préliminaires, place aux propositions concrètes. La première exposée est LISP, qui n'a rien à voir avec le langage de programmation du même nom et qui occupe la section 2. À noter que les « LISPiens » ont peu participé au RRG, ayant un groupe de travail IETF à eux et leur proposition étant de loin la plus avancée, puisque implémentée et déployée. Par contre, aucun RFC LISP n'a encore été publié.
LISP fait partie des propositions dites CES pour Core-Edge Separation, où une coupure très nette est faite entre le cœur de l'Internet (en gros, le monde de ceux qui ont aujourd'hui un routeur dans la DFZ) et les bords. Si LISP est largement déployé, seul le cœur aura encore des adresses IP globalement uniques et les bords auront des identificateurs uniques, qui ne seront pas des localisateurs. Un mécanisme d'annuaire (mapping) permettra de trouver l'adresse d'un routeur capable d'acheminer les paquets pour un identificateur donné et ce routeur sera le point d'entrée d'un système de tunnels, qui permettra de router ce paquet. Le tunnel n'est pas forcément fourni par le FAI, et on pourrait imaginer un nouveau métier dans l'Internet, celui de fournisseur de tunnels. Comme avec toutes les autres propositions de séparation identificateur-localisateur, les localisateurs, plutôt dépendants du FAI, sont fortement agrégeables, les identificateurs sont stables (on ne les change pas en changeant de FAI, ce que les LISPiens appellent PI for all). LISP ne nécessite aucune modification des machines terminales (c'est une solution purement dans les routeurs et encore, pas dans tous, uniquement les routeurs d'entrée et de sortie de tunnel). Ce type de solution est aussi appelée Map-and-Encap car on cherche d'abord une correspondance entre identificateur et localisateur (Map) puis on encapsule le paquet (Encap) pour la traversée du tunnel.
Notez que cette CES, cette séparation entre cœur et bords changerait le modèle classique de l'Internet, fondé sur le même protocole IP partout, du réseau local de M. Michu à celui du plus gros Tier-1. Cela rappelerait les réseaux des PTT où X.25 ne servait qu'à l'accès, d'autres protocoles (comme X.75) étant utilisés à l'intérieur du réseau de l'opérateur.
Et, comme toutes les solutions fondées sur la séparation entre identificateur et localisateur, LISP nécessite un système de correspondance (mapping) entre les deux, permettant de trouver, lorsqu'on cherche à joindre la machine d'identificateur X, à quel routeur Y il faut envoyer le paquet. Pour des raisons en partie idéologiques, LISP n'a pas considéré le DNS pour cette tâche et a plusieurs systèmes de correspondance possibles, le plus avancé se nommant ALT (pour ALternative Topology). La tâche serait relativement simple si le réseau ne changeait pas mais la réalité étant qu'il y a des pannes, des reconfigurations, etc, une bonne partie de la complexité de LISP et de sa fonction de correspondance va être dans la détection et le traitement des pannes (pas question d'envoyer des paquets à un ITR en panne). Ce problème, là encore, est commun à toutes les propositions de séparation de localisateur et d'identificateur.
C'est donc logiquement sur ces fonctions (correspondance entre identificateur et localisateur, et détection puis contournement de pannes) que se focalisent les critiques. Alors que LISP ne change pas énormément le modèle d'IP, le déploiement d'un tout nouveau système de correspondance, non testé, et qui doit encaisser d'énormes quantités d'information changeant souvent, est vu comme le plus gros risque de LISP. Parmi les problèmes posés : que va t-il advenir du premier paquet, celui pour lequel le routeur ne connait pas encore de localisateur ? Le temps que le système de correspondance l'obtienne (et une requête dans ALT peut avoir un long chemin à parcourir), le paquet va devoir attendre. Les gros routeurs, ne souhaitant pas gérer de longues files d'attente, abandonneront probablement immédiatement de tels paquets, comme ils le font aujourd'hui lorsqu'il n'y a pas d'entrée ARP pour le destinataire. La source finira par réemettre et, cette fois, la table aura été remplie et le second paquet sera acheminé. Certains protocoles pourraient mal supporter cette « perte du premier paquet » (qui n'est pas non plus un problème spécifique à LISP). La réponse des LISPiens est que le problème n'est pas si grave que cela, les caches des routeurs se peupleront vite de l'essentiel des correspondances, ne serait-ce que grâce aux pirates scannant le réseau. Quant à ALT, il n'est qu'une des propositions, LISP offre le choix de plusieurs systèmes de correspondance identificateur -> localisateur comme TREE. Le modèle de LISP ne repose pas sur une fonction de correspondance unique.
Quant à la complexité de détection des pannes, nécessitant des échanges spécifiques entre les ITR et les ETR (les routeurs d'entrée et de sortie des tunnels), elle est vue comme inévitable, et, comme LISP fonctionne déjà sur le terrain, l'argument massue des LISPiens est que « ça marche ».
Le second système présenté, RANGI (Routing Architecture for the Next Generation Internet, présenté par X. Xu), en section 3, est, au contraire de LISP, une solution basée sur les machines terminales et non plus sur les routeurs. Comme HIP, RANGI introduit un identificateur propre à la machine et les connexions TCP sont liées à cet identificateur et plus aux adresses IP. Mais, alors que l'identificateur de HIP est « plat », sans structure, ce qui le rend difficilement résolvable en localisateur (et difficilement filtrable par les pare-feux), celui de RANGI est hiérarchique, pour pouvoir être résolu en localisateur par les méthodes arborescentes qui ont fait leur preuve, par exemple avec le DNS (alors que HIP doit utiliser des techniques moins éprouvées comme les DHT).
Comme HIP, RANGI ne connait que la distinction entre routeurs et machines terminales et n'a pas de distinction entre le cœur du réseau et ses bords. On parle donc de solution CEE (Core-Edge Elimination). Comme toute solution « côté machines terminales », RANGI nécessitera une mise à jour de tous les systèmes d'exploitation. La question de savoir s'il vaut mieux modifier toutes les machines terminales (plus nombreuses, pas forcément gérées, mais moins sensibles et plus souvent changées pour une neuve) ou tous les routeurs (moins nombreux, gérés par des professionnels mais souvent difficiles à remplacer ou à mettre à jour) a été souvent discutée dans le RRG mais sans résultat ferme.
Comme toute solution de séparation de l'identificateur et du localisateur, RANGI nécessitera le déploiement du nouveau système de correspondance entre identificateur et localisateur. Mais, contrairement à LISP, RANGI envisage de réutiliser le DNS.
À noter que le RRG insistait sur la déployabilité incrémentale des solution, nécessaire pour éviter d'arrêter tout l'Internet pendant les années de la transition. RANGI la permet mais les premiers adoptants ne gagnent rien à le faire, ce qui conduit à s'interroger sur la possibilité d'un déploiement effectif. Après tout, HIP, solution élégante et sûre, normalisée depuis longtemps, implémentée pour Linux et FreeBSD, n'a jamais décollé, en partie à cause de ce problème de la « récompense initiale ».
Proposition suivante, en section 4, IVIP (Internet Vastly Improved Plumbing, dû à R. Whittle). Système de séparation cœur-bords, comme LISP, proche de LISP par beaucoup d'aspects, il s'en distingue notamment par le fait que les correspondances entre identificateurs et localisateurs sont poussées, plutôt que tirées, et que donc tous les routeurs d'entrée de tunnel ont un accès rapide à tout moment à une copie complète de la base. Cette mise à jour en temps réel élimine la nécessité pour les ITR (routeurs d'entrée des tunnels) de tester que l'ETR correspondant attend toujours les paquets à la sortie. En contrepartie, elle exige beaucoup de mémoire chez l'ITR, de l'ordre de dizaines de Go (cela semble énorme mais, d'ici à l'adoption massive, le moindre ordinateur de bureau aura autant de RAM que cela).
Cette base des correspondances, disponible en temps réel, malgré le taux de changement qu'imposent, par exemple, les machines et les réseaux mobiles, est évidemment la principale faiblesse d'IVIP. Certes, elle permet d'éliminer complètement plusieurs problèmes sérieux, concernant la mobilité ou la détection des pannes d'un ETR, mais est-elle réaliste ? Il n'y a aucun précédent développé et déployé avec succès... Le DNS ne fonctionne qu'en renonçant à la propagation instantanée des informations. DRTM (Distributed Real Time Mapping, le système de correspondance d'IVIP) fera-t-il mieux ? En tout cas, il est intéressant de voir ce que permet cette approche.
Autre point à noter : les solutions de séparation du cœur et des bords, comme LISP et IVIP, sont parmi les seules à ne pas avoir besoin de noms uniques et donc à pouvoir fonctionner avec les petites adresses IPv4. La plupart des autres solutions dépendent d'IPv6.
Mais IVIP et LISP peuvent fonctionner avec IPv6. Au contraire, hIPv4 est spécifique à IPv4. Il a souvent été dit que la séparation entre identificateur et localisateur était déjà réalisée dans l'Internet, via le NAT, où l'adresse privée est un identificateur et l'adresse publique est un localisateur. C'est bien sûr largement une boutade (par exemple, l'adresse privée n'est pas unique, une machine qui se déplace peut changer d'adresse privée, etc), mais cela peut inspirer des idées qui ont des points communs avec le NAT comme hIPv4 (protocole créé par Patrick Frejborg). L'idée de base est que chaque machine a un identificateur sous forme d'une adresse IPv4 et un localisateur de même syntaxe. Les deux noms seront insérés dans chaque paquet (une petite couche entre la couche 3 et la couche 4), les routeurs de bord du domaine faisant l'échange des noms, pour que les autres routeurs n'aient pas à être modifiés. Du fait que la machine terminale doive insérer ces deux noms (l'identificateur et le localisateur), son système d'exploitation doit être modifié et hIPv4 est donc une des rares solutions qui nécessitent des changements à la fois dans les machines terminales et dans certains routeurs. Autre problème, l'épuisement des adresses IPv4 fait qu'on peut se demander d'où viendront ces adresses... Ce problème, celui de la déployabilité, et la question (qu'on retrouve dans le NAT) des protocoles qui s'échangent directement des adresses IP (comme SIP) fait que hIPv4 fait partie des propositions qui sont explicitement rejetées.
Continuons, puisque l'imagination des participants au RRG est sans limites. La section 6 présente NOL (Name OverLay). Actuellement, dans l'Internet, les noms de domaine, gérés dans le DNS, sont complètement extérieurs à la machine elle-même. C'est au point qu'une machine n'a pas de moyen simple de connaître son propre nom de domaine (si elle en a un !) sans parler de l'idée de l'influencer ou de le changer. L'idée de base de NOL est d'ajouter une couche de gestion des noms de domaine à toutes les machines, et d'utiliser ces noms comme identificateurs. (Voir les Name-Based Sockets, en section 15, une idée qui présente de nombreuses similarités.) Il est difficile de la décrire en détail car, apparemment, aucune spécification écrite n'a été produite. Il n'est pas nécessaire de modifier le système d'exploitation mais il faudra modifier les bibliothèques utilisées habituellement pour la résolution de noms (sur Unix, la libc). NOL n'implique pas de modifier l'application des deux côtés (contrairement à NBS, name-based sockets, présenté plus loin) car des relais spéciaux traduisent les noms et les adresses IP (une sorte de routeur NAT étendu). NOL n'a pas bénéficié de critiques ou de jugements précis, peut-être en raison de son caractère trop exotique.
C'est seulement avec la section 12 qu'apparait
ILNP
(Identifier-Locator Network Protocol, fait par
R. Atkinson & S. Bhatti, site officiel en http://ilnp.cs.st-andrews.ac.uk/, bons transparents
d'introduction en à
NANOG, RFC 6740 et suivants, l'architecture qui a finalement eu les
faveurs des présidents du groupe. Il repose sur une stricte séparation
de l'identificateur et du localisateur, avec le
DNS pour passer de l'un à l'autre. Pour gérer
les changements de connectivité, ILNP fait donc un usage intensif de
DNSSEC et des
mises à jour dynamiques du DNS (RFC 2136 et RFC 3007). L'auteur semble d'ailleurs prêter trop de
pouvoirs à DNSSEC, par exemple en disant que les requêtes
PTR peuvent également être authentifiées. C'est
vrai qu'on peut signer un enregistrement PTR mais, lorsque le PTR de
2001:db8::dead:beef pointe vers
www.amazon.com, il n'y a aucun moyen de s'assurer
qu'il en a le « droit », DNSSEC ou pas.
ILNP atteint plusieurs des
objectifs du RFC 5887 mais pas tous. Ainsi,
certains serveurs (ceux du DNS, par exemple)
doivent toujours être décrits par un localisateur. Dans son état
actuel, ILNP impose l'usage du DNS pour tout (plus de ping
2001:db8:1:3::cafe), ce qui ne convient pas forcément à
toutes les applications. Il faudra donc sans doute étendre ILNP sur ce
point.
Dernière architecture de routage envisagée dans notre RFC, IRON/RANGER (section 16) où IRON signifie Internet Routing Overlay Network (auteur : F. Templin, décrit dans le RFC 6179) et s'appuie sur l'architecture RANGER (Routing and Addressing in Networks with Global Enterprise Recursion, RFC 5720). RANGER est dérivé de ISATAP (RFC 5214) et fournit un système de tunnels automatiques pour transporter des paquets identifiés par un... identificateur à travers un cœur qui n'utilise que des localisateurs. À son tour, RANGER s'appuie sur le mécanisme SEAL (Subnetwork Encapsulation and Adaptation Layer, RFC 5320, qui gère notamment les questions de MTU, toujours cruciales avec les tunnels. La critique de ce mécanisme note que beaucoup de détails manquent, notamment la fonction de recherche de la correspondance entre un identificateur et un localisateur. Elle remarque aussi que SEAL empêcherait de déployer les jumbogrammes. Dans sa réponse à la critique, l'auteur note que IRON ne repose pas sur un système de mapping classique mais sur une combinaison du protocole de routage et d'un protocole spécifique de distribution des correspondances. Personnellement, cela me semble encore très flou.
Une autre architecture est présentée en section 14, Évolution. Conçue par Lixia Zhang, une vétéran de l'IETF, auteure de plus de trente RFC, Évolution propose une approche du passage à l'échelle du système de routage qui est assez originale. L'idée de base est de faire feu de tout bois, en agrégeant les routes partout où on peut, sans attendre le « Grand Soir » d'une nouvelle architecture. Évolution critique la tendance des autres propositions du RRG à considérer qu'on ne peut rien résoudre tant qu'on n'a pas changé tout le routage. Mais, comme le peu de déploiement de IPv6 l'a montré, les solutions qui aideront tout le monde, une fois que tout le monde les aura déployé, ont le plus grand mal à s'imposer sur l'Internet. Les solutions qui gagnent sont au contraire en général celles qui procurent un bénéfice immédiat et à court terme aux décideurs.
Évolution propose donc de commencer par le routeur seul : tout routeur pourrait déjà agréger massivement les routes qu'il connait, économisant ainsi sa mémoire. Cet effet est d'autant plus marqué que le routeur a peu de liens physiques possibles. Ensuite, au sein cette fois d'un système autonome, on pourrait désigner certains routeurs comme étant les seuls à avoir une connaissance complète des liens externes, la plupart des routeurs de l'AS pouvant alors se contenter de tunnels vers ces « super-routeurs », créant une sorte de schéma Map-and-Encap local. Une fois cette « agrégation virtuelle » réalisée à l'intérieur de plusieurs AS, ceux-ci pourraient annoncer ces super-routeurs via BGP, étendant leur bénéfice aux autres AS. Enfin, une séparation plus intense entre le contrôle des routes (fait par BGP, et qui limite l'agrégation puisqu'il faut pouvoir annoncer les routes aux autres) et la transmission effective des paquets (où le routeur peut se contenter d'une FIB bien plus petite que sa RIB) complèterait le dispositif. Le point important d'Évolution est que chaque étape apporte ses bénéfices, et qu'il n'est donc pas indispensable de faire miroiter des bénéfices lointains aux décideurs pour les convaincre. Chaque étape a sa récompense propre.
Mais Évolution a ses propres problèmes. Certaines des techniques d'agrégation perturbent les systèmes existants (par exemple, l'agrégation de N préfixes en un super-préfixe, qui couvre un espace plus grand que ne le faisaient les N sous-préfixes, crée des adresses routables qui n'existaient pas avant, ce qui peut entraîner de nouvelles boucles de routage, et peut gêner les systèmes de sécurité comme RPF - RFC 3704). D'autre part, l'agrégation virtuelle allonge le chemin pris par les paquets, et peut aussi gêner RPF. À noter qu'Évolution ne fournit pas de solution pour la mobilité, concept à la mode, mais dont il n'est pas évident qu'il doive être géré par le système de routage (plutôt que, par exemple, une combinaison de DHCP et de meilleures applications).
Une autre critique faite à Évolution est plus philosophique : en fournissant des bénéfices à court terme, n'encourage-t-on pas les rustines sur un système déjà pas mal rapiécé, au risque de détourner les gens d'une transition, certes coûteuse mais nécessaire ?
On l'a vu, un problème commun à toutes les propositions de séparation du localisateur et de l'identificateur est le système de correspondance (mapping) entre les deux. Cela a mené certains à concentrer leurs efforts sur ce problème et à travailler sur des systèmes de correspondance génériques, pouvant être utilisés pour plusieurs protocoles. C'est le cas de LMS (Layered Mapping System), en section 8. Comme le ALT de LISP, il repose sur une hiérarchie des noms (système de résolution bien plus éprouvé que les systèmes plats, qu'utilisent par exemple les DHT). Mais, contrairement à ALT, la correspondance entre noms est complètement déconnectée du routage : ce ne sont pas les FAI ou les opérateurs réseau qui font la résolution de noms.
Autre système de correspondance, le 2-phased mapping de la section 9. Ce système vise à trouver l'ETR (le routeur de sortie du tunnel, celui qui est le plus « proche » du réseau visé) correspondant à un préfixe donné, le préfixe contenant l'identificateur de la machine visée. Tout serait simple si cette correspondance préfixe -> ETR était relativement statique. Mais, évidemment, ce n'est pas le cas et 2-phased mapping considère qu'un système qui stockerait toutes les relations préfixe -> ETR de la planète ne tiendrait pas longtemps. Son idée centrale est d'intercaler un numéro de système autonome (AS) entre les deux, de façon à avoir une relation préfixe -> AS -> ETR. Les systèmes autonomes connaissent en effet certainement leurs clients et donc les ETR qui les desservent. Il ne reste donc qu'à créer un système pour que les AS puisse informer le système de résolution des préfixes qu'ils servent. On peut donc envisager de d'abord résoudre le préfixe en un numéro d'AS puis d'interroger ce dernier. Ce système en deux étapes (les résultats de chacune pouvant être mis en cache) passe certainement mieux à l'échelle. À noter que les deux étapes ne sont pas forcées d'utiliser les mêmes techniques (par exemple, la première pourrait être faite avec le DNS, ou bien avec un serveur centralisé, type whois, et la seconde avec une extension à BGP). L'idée n'a toutefois pas été assez développée pour être considérée sérieusement par le RRG.
On l'a vu, toutes les propositions soumises au RRG ne concernaient pas forcément une architecture de routage nouvelle, certaines présentaient une solution auxiliaire, qui allait aider les nouvelles architectures. C'est le cas des Name-based sockets de la section 15. L'idée de base est de ne manipuler, depuis les applications, que des noms et de laisser les couches basses gérer et stocker les adresses. Dans la proposition actuelle, ces name-based sockets permettraient aux applications d'initier et de recevoir des communications uniquement avec les noms. Il ne s'agit pas seulement de cacher les adresses IP dans une bibliothèque utilisée par l'application (comme le font, par exemple, les bibliothèques curl et neon pour les programmeurs C) mais de déplacer leur gestion bien plus bas, dans la pile IP elle-même, permettant ainsi des choses comme le changement d'adresse IP en cours de communication.
En quoi est-ce que cela aiderait le routage ? Eh bien, cela réduirait la nécessité de disposer d'adresses PI et transformerait l'adresse IP est un nom largement invisible, comme l'est l'adresse MAC aujourd'hui. La souplesse que cela apporterait permettrait, par exemple, d'agréger plus radicalement les préfixes. Les NBS (name-based sockets) ont bien d'autres propriétés intéressantes comme de rendre le NAT largement inoffensif (si l'application ne voit jamais d'adresses IP, leur changement par le routeur NAT n'aura pas de conséquence).
Les NBS sont donc une solution situéee dans la machine terminale, sans changement des routeurs. Leur déploiement suppose donc leur adoption par les systèmes d'exploitaion (rappelez-vous qu'il ne s'agit pas d'une simple couche pour aider le programmeur, les NBS doivent interagir fortement avec IP et donc être dans le noyau). NBS est plus longuement documenté dans l'article de Vogt, « Simplifying Internet Applications Development With A Name-Based Sockets Interface ».
Quelles sont les limites des NBS ? D'abord, certaines applications auront toujours besoin d'adresses IP, par exemple celles nécessaires au bootstrapping comme les serveurs DNS. Ensuite, un réseau ne pourra abandonner ses adresses PI que lorsque toutes ses machines auront migré vers NBS.
Où cela nous mène t-il ? Comme indiqué au début, aucune proposition n'a recueilli le consensus du groupe. La section 17 expose donc la seule recommandation des présidents du groupe. Ceux-ci exposent d'abord le contexte, celui d'un Internet faiblement coordonné, sans point de décision central, et où les changements ne peuvent être introduits que de manière incrémentale. Tout changement étant compliqué, il faut choisir avec soin les changements qu'on propose. L'Internet a tenu, et très bien, jusqu'à présent, grâce à un grand nombre de modifications partielles, faites au fur et à mesure que les problèmes se posaient. Mais l'accumumation de ces changements a fini par mener à un réseau excessivement complexe et difficiles à maintenir. Les présidents du RRG proposent donc à la fois des changements à court terme, pour traiter les cas les plus urgents et une « bonne » solution à long terme, dont ils reconnaissent qu'elle n'existe pas encore. La recommandation est donc de travailler sur trois techniques :
- À court terme, une agrégation plus vigoureuse des préfixes,
comme proposé dans le plan Évolution (section 14 et
Internet-Draft
draft-zhang-evolution). - À long terme, une nouvelle architecture fondée sur ILNP (Identifier-Locator Network Protocol, section 12).
- À court et moyen terme, travailler à rendre la renumérotation des réseaux plus facile, pour diminuer la pression en faveur des adresses PI. Décrit dans le RFC 5887, cette question est désormais du ressort du futur groupe de travail Renum.
Pourquoi ces choix ? L'agrégation de Évolution parce qu'on a besoin de solutions à court terme. ILNP parce que c'est une solution architecturalement propre, qui sépare nettement identificateur et localisateur, et qui ne dépend pas de tunnels. Et la rénumérotation facilitée parce que, quelle que soit la solution finale choisie, on ne pourra pas éviter des rénumérotations de temps en temps.
L'article seul
RFC 6055: IAB Thoughts on Encodings for Internationalized Domain Names
Date de publication du RFC : Février 2011
Auteur(s) du RFC : D. Thaler (Microsoft), J. Klensin, S. Cheshire (Apple)
Pour information
Première rédaction de cet article le 22 février 2011
Ce RFC de l'IAB fait
le point sur un petit problème lié aux IDN,
problème qui, semble t-il, n'avait jamais été traité en détail
avant. La norme actuelle (RFC 5890 et suivants)
est connue sous le nom d'IDNA pour IDN
in Applications car elle ne change rien au
protocole et que tout le travail doit être fait
dans l'application. Toutefois,
«application » est un terme un peu vague. Par exemple, un programme
écrit en C doit-il convertir le
U-label (forme Unicode du
nom) en A-label (forme
ASCII) avant l'appel à la fonction de
bibliothèque getaddrinfo() ? Ou bien
est-ce que getaddrinfo() doit le faire seul ?
(Pour les impatients, la réponse, qui arrive au terme d'un long RFC,
est que l'application ne doit pas convertir en
Punycode avant d'être certaine que la résolution
de noms se fera avec le DNS, dans l'espace public.)
Les deux méthodes mènent en effet à des résultats différents dès
qu'un autre protocole que le DNS est utilisé
pour la résolution de nom. En effet, contrairement à ce qu'on lit
parfois, l'appel de getaddrinfo() n'est pas un
appel au DNS mais aux mécanismes de résolution de nom locaux. Par
exemple, sur un système d'exploitation qui utilise la GNU
libc comme Debian, le mécanisme se
nomme NSS (pour Name Service
Switch) et le fichier
/etc/nsswitch.conf permet de le configurer. Si
ce fichier contient une ligne comme :
hosts: files ldap dns
alors, un appel à getaddrinfo() par une
application qui veut récupérer l'adresse IP
correspondant à un nom de domaine ne produira
pas forcément une requête DNS, le nom sera peut-être trouvé dans
/etc/hosts ou dans LDAP
d'abord. Dans ce cas, traduire le nom en ACE
(ASCII compatible encoding, c'est-à-dire traduire palais-congrès.fr en
xn--palais-congrs-7gb.fr, selon le RFC 3492) serait une erreur car LDAP, par exemple,
est nativement Unicode depuis le début et n'a nul besoin de l'ACE.
La section 1 du RFC rappelle la terminologie, les textes de
référence (comme le RFC 2130) et les concepts,
notamment la notion d'encodage. Elle rappelle aussi que des opérations
aussi simples que l'égalité sont plus complexes en Unicode
qu'en ASCII. Cette même section revient sur la question des
API, résumée plus haut. La lecture du RFC 3490 pourrait faire croire à l'implémenteur d'IDN
que la situation est simple (figure 1 du RFC) avec l'application
parlant au stub resolver DNS qui parle à
l'Internet. La réalité est en fait plus riche comme le montre la
figure 2, avec un niveau d'indirection supplémentaire entre le
sous-programme appelé par l'application (par exemple
getaddrinfo(), normalisé dans le RFC 3493) et les techniques de résolution
utilisées, le DNS mais aussi LLMNR (RFC 4795), Netbios (RFC 1001), /etc/hosts (RFC 952),
etc.
Tiens, justement, ces API, elles prennent
des noms de domaine sous quelle forme ? UTF-8 ?
Punycode ? Autre ? La section 1.1 se penche sur
ce problème. La description de
getaddrinfo() dit juste que le nom
(le paramètre nodename)
est un char *, une chaîne de caractères, sans
indiquer d'encodage. Les règles des chaînes de
caractères en C font que l'octet nul ne peut
pas en faire partie, ce qui élimine des encodages comme
UTF-16 et UTF-32. En
pratique, le nom passé peut être de l'ASCII
(c'est le cas s'il a été traité par Punycode),
de l'ISO 8859, du
ISO-2022-JP (très répandu au
Japon) ou de l'UTF-8. On
peut noter qu'il est possible de distinguer algorithmiquement certains de ces
différentes encodages avec des règles comme « Si le nom comporte un
ESC, U+001B, alors, c'est de l'ISO-2022-JP,
sinon si n'importe quel octet a un bit de poids fort à un, c'est de
l'UTF-8, sinon, si le nom commence par xn--,
c'est du Punycode, sinon enfin c'est de l'ASCII traditionnel. » Ces
règles ne sont pas parfaites (celle-ci ne tient pas compte des ISO 8859, d'autre part un nom ASCII traditionnel peut
théoriquement commencer
par xn-- sans être un A-label)
et on peut préférer des règles plus sophistiquées comme celle exposée
dans « The
Properties and Promizes of UTF-8 ». Quant à
ISO 8859, c'est le plus ennuyeux, car il n'y a
aucun moyen fiable de reconnaître un membre du jeu ISO 8859 d'un
autre. Dans un texte long, des heuristiques sont possibles mais les
noms de domaines sont trop courts pour fournir assez d'information
pour distinguer, par exemple, ISO 8859-1 de
ISO 8859-15.
Enfin, il n'y a
pas que le getaddrinfo() du RFC 3493, il y a d'autres sous-programmes comme, sur Windows,
GetAddrInfoW qui accepte de l'UTF-16.
Tout cela, c'était pour expliquer que des sous-programmes de
résolution de noms comme getaddrinfo() ne
reçoivent pas toujours assez d'information pour savoir ce qu'ils
doivent faire. L'autre moitié du problème est décrit dans la section
2 : il y a d'autres protocoles de résolution que le DNS. Par
exemple, la technologie privée d'Apple,
Bonjour, a des noms entièrement en
UTF-8 (ce qui est conforme aux recommandations
du RFC 2277). Une application qui traduirait les
noms Unicode en ACE empêcherait donc Bonjour de
trouver la machine portant ce nom. Même chose avec les autres
protocoles comme le fichier hosts (RFC 952. Ainsi, si je mets dans mon /etc/hosts sur Unix :
64.170.98.32 café-crème
je peux l'utiliser sans problème :
% ping -c 1 café-crème PING café-crème (64.170.98.32) 56(84) bytes of data. 64 bytes from café-crème (64.170.98.32): icmp_req=1 ttl=70 time=155 ms --- café-crème ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 155.568/155.568/155.568/0.000 ms
Traduire trop tôt est donc une méthode déconseillée : la traduction en ACE devrait se faire bien plus tard, lorsqu'on connait le protocole de résolution employé. Et cela ne peut pas se faire dans l'application à proprement parler, puisqu'elle ne connait jamais ce protocole.
D'ailleurs, puisque des protocoles comme LDAP utilisent Unicode de bout en bout, pourquoi le DNS n'en fait-il pas autant ? La section 3 décrit ce problème (voir aussi mon article « Pourquoi avoir développé IDNA au lieu d'utiliser directement l'Unicode dans le DNS ? »). Elle rappelle que, contrairement à ce que disent souvent les ignorants, le DNS est parfaitement capable, depuis le début, de faire passer autre chose que l'ASCII, a fortiori autre chose que le sous-ensemble LDH (Letters, Digits and Hyphen) de l'ASCII. Cette erreur est tellement répandue qu'il a fallu, en 1997, consacrer une part du RFC 2181 (section 11) à tordre le coup à cette idée. Le DNS peut donc gérer des octets où le huitième bit est à un et donc, par exemple, des noms en UTF-8 (il n'est donc pas en contradiction avec le RFC 2277 qui pose comme principe que UTF-8 est l'encodage Unicode de l'Internet). Il y a des raisons techniques pour ne pas utiliser UTF-16 ou UTF-32 (présence d'octets nuls qui pertuberaient les bibliothèques écrites en C pour lesquelles c'est une marque de fin de chaîne) mais UTF-8 ne pose pas de problème. En prime, UTF-8 est un sur-ensemble d'ASCII, toute chaîne ASCII est forcément une chaîne UTF-8, ce qui fait qu'une application peut tout traiter comme de l'UTF-8, même les noms existants.
Donc, le DNS ne pose pas de restrictions ASCII ou LDH. Par contre, les applications peuvent, elles, en imposer. Ainsi, pour le Web, l'ancienne norme des URI, le RFC 2396 (remplacé depuis par le RFC 3986), limitait (dans sa section 3.2.2) le nom de machine présent dans l'URL au jeu LDH (lettres, chiffres et tiret). C'est en raison de cette limitation (présente dans d'autres protocoles) que beaucoup de registres n'autorisent que ces noms à l'enregistrement.
Si le DNS n'est pas limité à l'ASCII, pourquoi ne pas faire des IDN uniquement en mettant carrément de l'UTF-8 dans les noms ? Certes, la représentation des chaînes de caractères dans le DNS ne permet pas d'indiquer l'encodage utilisé mais, après tout, le RFC 2277 dit clairement que, sur l'Internet, en l'absence de mention contraire, tout est en UTF-8. Cette méthode a effectivement été utilisée dans certaines zones, notamment privées (non visibles depuis l'Internet public). Elle marche : l'application passe de l'UTF-8 au résolveur qui la transmet aveuglément au DNS, qui sait répondre à ces requêtes. Le principal problème de cette méthode (et qui est à peine esquissé dans notre RFC 6055) est la canonicalisation. Le fait que les requêtes DNS soient insensibles à la casse ne marche pas pour l'Unicode, où les règles sont bien plus complexes (pensons au ß allemand dont la majuscule comprend deux lettres, SS, voir le RFC 5198 pour un point de vue plus large). C'est cette absence d'une canonicalisation satisfaisante (qui affecte également les autres protocoles comme LDAP), bien plus qu'une soi-disant incapacité du DNS à gérer l'Unicode, qui explique pourquoi l'actuelle norme IDN n'utilise pas UTF-8.
Parmi les autres surprises que nous réserve la résolution de noms,
la section 3 note aussi que le nom actuellement résolu n'est pas
forcément celui tapé par l'utilisateur. Il est en effet fréquent que
le nom tapé soit complété par des noms de domaines locaux. Par
exemple, sur Unix, le fichier /etc/resolv.conf
contient souvent une directive
search qui indique les noms « suffixes » à essayer (voir la
section 6 du
RFC 1536, le RFC 3397 et la section 4 du RFC 3646 pour
d'autres exemples). Si ce
fichier contient search foo.example bar.example
et qu'un utilisateur tape le nom de machine toto,
le résolveur essaiera successivement
toto.foo.example et
toto.bar.example. Si
foo.example et bar.example
utilisaient des règles différentes (par exemple que l'un de ces
domaines autorise de l'UTF-8 brut et pas l'autre), la pauvre
application qui reçoit le nom toto n'aurait pas
de moyen de prévoir ce qui va se passer. (Ici,
toto est en ASCII. Mais si on le remplace par
café ?)
La section 3.1 donne une longue liste d'exemples détaillés des
comportements actuels des applications. On y voit entre autres ce
qui peut se passer lorsque l'application est « trop maligne » et tente
de traduire trop tôt les noms. Par exemple, l'application reçoit le
nom crème, le traduit en Punycode
(xn--crme-6oa) mais
resolv.conf contient un nom en UTF-8, mettons
café.example et le résolveur (qui ne fait pas de
conversion en Unicode) va alors chercher la chaîne incohérente
xn--crme-6oa.café.example !
Après toutes ses considérations, très détaillées, est-il encore
possible de donner une recommandation ? Oui, et elle tient en un
paragraphe dans la section 4 : « Une application qui va
appeler un sous-programme de résolution de noms ne doit pas convertir
le nom en Punycode si elle n'est pas absolument certaine que la
résolution se fera uniquement avec le DNS public. ». En
d'autres termes, l'application plus haut qui appelerait aveuglément, par exemple,
le sous-programme idna_to_ascii_8z() (qui, avec
la GNU libidn, convertit du jeu de caractères
local vers Punycode) avant de faire un
getaddrinfo() a tort.
La section 4 de notre RFC laisse une possibilité à l'application
d'essayer plusieurs méthodes, comme de tenter
getaddrinfo() sur le nom brut, puis sur le nom
punycodé. Mais ce n'est pas obligatoire. Même recommandation pour les
traductions d'adresses IP en nom : une application « intelligente »
peut se préparer à recevoir de l'UTF-8 ou du Punycode et réagir
proprement dans les deux cas.
Dans tous les cas, une autre recommandation importante du RFC est
que les API de résolution de noms spécifient clairement l'encodage
qu'elles attendent. Sur Windows, GetAddrInfoW()
spécifie bien qu'il prend de l'UTF-16 alors que
la norme de getaddrinfo() (le RFC 3493) n'en parle pas, faisant que la mise en
œuvre de getaddrinfo sur Windows utilise la
page de code Windows alors que celle de
MacOS utilise UTF-8.
On peut noter que la norme IDN a été révisée récemment mais, pour les questions discutées dans ce RFC, cela n'a pas de conséquence.
Aujourd'hui, l'erreur qui consiste à traduire en ACE sans faire attention semble assez fréquente. C'est le cas par exemple d'echoping avec sa bogue #3125516.
Merci à Pascal Courtois pour sa découverte d'une bogue gênante dans ce texte (pas dans le RFC).
L'article seul
RFC 6137: The Network Trouble Ticket Data Model
Date de publication du RFC : Février 2011
Auteur(s) du RFC : Dimitris Zisiadis (CERTH), Spyros Kopsidas (CERTH), Matina Tsavli (CERTH), Leandros Tassiulas (CERTH), Chrysostomos Tziouvaras (GRNET), Guillaume Cessieux (CNRS), Xavier Jeannin (CNRS)
Expérimental
Première rédaction de cet article le 19 février 2011
Les centres qui gèrent les réseaux qui composent l'Internet, les NOC, ont régulièrement besoin d'échanger de l'information. Celle-ci, concernant les incidents, les nouveautés, les problèmes, circule souvent en quantités impressionnantes et est donc une bonne candidate pour l'automatisation. Ce RFC expérimental propose donc un format standard, basé sur XML, pour représenter l'information qui circule entre NOC, notamment ceux qui gèrent en commun une grande grille, ce qui est le cas d'EGEE, où travaillent les auteurs. Il est important pour de grosses infrastructures réseau comme les grilles de calculs, qui s'étendent sur plusieurs domaines administratifs, de pouvoir interpréter correctement les tickets avec un minimum de dépendance vis-à-vis de l'origine du ticket. L'effort de normalisation prend tout son sens dans ce contexte. Un ticket pourra donc être lu et compris sans avoir besoin de connaître les particularités et la terminologie du domaine d'origine.
Le but (section 1) n'est pas de remplacer les outils de gestion de tickets de chaque NOC mais d'avoir un format d'échange standard, suivant les souhaits du RFC 1297. Les tickets ainsi formatés pourront automatiquement être émis par un NOC, reçus par un autre, être analysés, etc. Ces outils de gestion de tickets seront ensuite utilisés pour analyser le problème, suivre son évolution et, d'une manière générale, assurer un bon fonctionnement du réseau.
On comprend mieux la taille du problème quant on voit que la grille de calcul EGEE qui utilise les NREN (vingt participants) pour sa connectivité, reçoit 800 tickets et 2500 messages par mois.
Notre RFC décrit un modèle de données en UML, puis un format concret de représentation en XML. Un problème classique que rencontrent toutes les tentatives de normalisation dans ce domaine est qu'il faut à la fois décrire de manière formelle l'incident, en énumérant de manière limitative les choix possibles, pour permettre son traitement automatique, tout en gardant des possibilités d'exprimer des problèmes nouveaux, ce qui impose de garder la possibilité de mettre du texte libre, non formaté.
Voyons d'abord les types de données utilisés (section 2). On y
trouve plusieurs énumérés comme
TT_TYPE qui indique si le ticket concerne un
problème opérationnel, administratif, ou bien n'est là que pour
information, TYPE qui indique si l'événement
était prévu ou accidentel, TT_STATUS qui donne
l'état du ticket (ouvert, résolu, annulé, fermé..., avec un diagramme
de transition apparemment obligatoire). On trouve aussi bien sûr des
chaînes de caractères (qui seront simplement le type W3C
XML Schema xs:string) et des heures
(au format du RFC 3339, alias
xs:dateTime).
Armée de ces définitions, la section 3 détaille la longue liste des
attributs d'un ticket. On y trouvera même un diagramme de classe
UML en art
ASCII... Parmi ces attributs, les grands classiques, comme
l'identificateur unique du ticket (formé par la concaténation de
l'identificateur du NOC et d'un identificateur local, ce qui permet d'allouer ces identificateurs uniques de
manières décentralisée), l'état du ticket, sa date de création, l'identificateur du NOC qui est
à l'origine du ticket (le RFC n'explique pas comment ses
identificateurs, qui doivent être uniques, sont attribués et
conservés), une description courte qui est sélectionnée à partir d'une
liste pré-définie (pour permettre le traitement automatique) et une
description longue qui est en texte libre (la
langue utilisée peut être représenté dans le
fichier XML par un attribut lang - pour des
raisons que j'ignore, l'attribut standard XML
xml:lang n'a pas été utilisé), les identificateurs de
tickets ayant un rapport avec celui-ci, etc. Pour chaque attribut est
indiqué s'il est obligatoire ou non.
La section 4 décrit l'approche utilisée pour l'internationalisation puisque les tickets seront échangés entre NOC de pays et de langues différents. Les champs formels (comme la description courte) n'ont pas besoin d'être adaptés (le logiciel de chaque NOC pourra les présenter comme il le voudra), les textes libres (comme la description longue de l'incident) peuvent être dans n'importe quelle langue (des systèmes de traduction automatique sont prévus pour EGEE dans le futur).
Si vous êtes impatients de voir à quoi ressemblent ces fameux tickets en XML, sautez directement à la section 5, qui présente les exemples. Voici un joli ticket indiquant une panne chez Forth en Grèce :
<?xml version="1.0" encoding="UTF-8"?>
<!-- This example describes a link failure that was detected -->
<NTTDM-Document version="1.00" lang="el"
xmlns="urn:ietf:params:xml:ns:nttdm-1.0">
<Ticket>
<Original_ID>5985</Original_ID>
<Partner_ID>01</Partner_ID>
<TT_ID>01_5985</TT_ID>
<TT_Title>Forth Link Failure</TT_Title>
<TT_Type>Operational</TT_Type>
<TT_Status>Closed</TT_Status>
<TT_Open_Datetime>2008-12-16T10:01:15+02:00</TT_Open_Datetime>
<TT_Short_Description>Core Line Fault</TT_Short_Description>
<TT_Long_Description>Forth Link Failure</TT_Long_Description>
<Type>Unscheduled</Type>
<TT_Impact_Assessment>No connectivity</TT_Impact_Assessment>
<Start_Datetime>2008-12-16T09:55:00+02:00</Start_Datetime>
<TT_Last_Update_Time>2008-12-16T15:00:34+02:00</TT_Last_Update_Time>
<Location>HERAKLION</Location>
<History>Optical transmitter was changed</History>
<TT_Close_Datetime>2008-12-16T15:05:00+02:00</TT_Close_Datetime>
<End_Datetime>2008-12-16T15:01:21+02:00</End_Datetime>
<Network_Node>
<Node>FORTH</Node>
</Network_Node>
<Network_Link_Circuit>
<Link_Circuit>FORTH-2</Link_Circuit>
</Network_Link_Circuit>
<Open_Engineer>Dimitris Zisiadis</Open_Engineer>
<Close_Engineer>Guillaume Cessieux</Close_Engineer>
<Contact_Engineers>
<Engineer>Spyros Kopsidas</Engineer>
<Engineer>Chrysostomos Tziouvaras</Engineer>
</Contact_Engineers>
<TT_Priority>High</TT_Priority>
</Ticket>
</NTTDM-Document>
On notera que l'exemple est imparfait :
l'étiquette de langue el indique du
grec mais le texte est entièrement en anglais.
Enfin, la section 6 contient le schéma complet, en langage W3C XML schema et la section 7 quelques avertissements de sécurité. Comme le contenu des tickets peut être sensible, il peut être utile de chiffrer et d'authentifier les tickets mais le RFC ne suggère pas de technique standard pour cela.
Merci à Xavier Jeannin pour sa relecture.
L'article seul
RFC 6129: The 'application/tei+xml' mediatype
Date de publication du RFC : Février 2011
Auteur(s) du RFC : L. Romary (TEI Consortium and INRIA), S. Lundberg (The Royal Library, Copenhagen)
Pour information
Première rédaction de cet article le 12 février 2011
Petit à petit, de nombreux formats XML
obtiennent un type MIME, comme indiqué dans le
RFC 7303 et RFC 6839. Ces types permettent d'identifier un contenu de
manière précise sur le réseau, et ont la forme
application/XXX+xml où XXX indique le format
précis. Ici, notre RFC concerne le type
application/tei+xml, pour le format
TEI, un format de documents très utilisé dans
le monde des bibliothèques et dans les sciences humaines en général (le secteur de l'étude des documents
anciens est un utilisateur très visible de TEI, mais ce n'est pas le seul).
En effet, TEI (Text Encoding and
Interchange) est un format utilisé depuis longtemps, par les
musées, les bibliothèques, et des chercheurs, par exemple pour encoder un manuscrit qu'on a réussi à déchiffrer. Nous sommes donc ici à
l'intersection du monde des geeks et de celui
d'Umberto Eco. Si vous voulez voir des exemples
de documents TEI, on en trouve un peu partout, par exemple une version
d'« Alice au pays des merveilles » issue du
Projet Gutenberg et TEIsée. L'original est en
http://www.gnutenberg.de/pgtei/0.5/examples/alice/alice.tei
mais j'en ai fait une version légèrement
modifiée pour en retirer ce qui était spécifique de Gutenberg.
Comme tout bon fichier XML, les documents
TEI ont un namespace XML, ici
http://www.tei-c.org/ns/1.0. Plusieurs éléments
XML peuvent être utilisés pour être la racine d'un document TEI, mais
les plus communs sont <TEI> et
<teiCorpus>. On les trouve souvent sur
l'Internet avec des extensions de fichier .tei et
.teiCorpus. (À noter qu'une recherche
Google des fichiers se terminant par
.tei ne donne pas le
résultat attendu en raison du nombre de chinois nommés
Tei...)
Notre RFC est très court. TEI lui-même est spécifié dans des documents du consortium TEI (le format est du Relax NG et disponible en format XML ou en format compact) et ce RFC ne fait que spécifier le type MIME et donner quelques conseils. Armé de ces schémas, on peut valider avec rnv :
% rnv tei_all.rnc alice.tei alice.tei
Par contre, la validation avec xmllint échoue en raison d'une boucle sans fin.
Enfin, le consortium TEI fournit divers outils permettant, par exemple, la traduction vers LaTeX ou HTML. À noter que le journal de ce consortium est sur revues.org.
À noter que la traditionnelle section sur la sécurité couvre des points
inhabituels dans un RFC. Par exemple, les documents encodés en TEI
peuvent être tellement anciens qu'ils sont montés dans le
domaine public mais parfois ils sont au
contraire encore plombés par des règles d'appropriation intellectuelle. Le format
TEI permet de spécifier ces règles, avec une grande granularité (élément availability). Ces spécifications
peuvent être utilisées pour mettre en œuvre un système de
menottes numériques ou, plus
simplement, pour permettre l'application du droit moral de l'auteur (citer
correctement les auteurs de chaque partie d'un document TEI).
D'autre part, TEI a déjà été utilisé pour encoder des documents ayant un rôle légal, et qui peuvent être encore applicables des siècles plus tard. Il peut donc être nécessaire de prendre des précautions pour vérifier l'authenticité et l'intégrité de ces documents (TEI lui-même ne le fait pas).
Enfin, les documents encodés peuvent être confidentiels et, là encore, cette confidentialité peut devoir être respectée sur de longues périodes (des dizaines d'années, si des personnes physiques sont mentionnées). Regardez donc bien les règles pour les archives de votre pays avant de distribuer des documents TEI.
Merci à Laurent Romary et Sebastian Rahtz pour leurs relectures et
pour m'avoir envoyé un autre exemple de document TEI, un encodage du
« Conte de Noël » de
Dickens. Le fichier
carol.zip contient le source TEI et on peut en tirer
automatiquement une version EPUB, qui est dans
le fichier 3256.epub.
L'article seul
SeenThis, un nouveau réseau social, orienté recommandations
Première rédaction de cet article le 11 février 2011
Dans la galaxie toujours croissante des « réseaux sociaux » (les services sur l'Internet qui vous permettent d'interagir de manière relativement structurée avec des gens partageant vos goûts ou vos idées), le petit nouveau est SeenThis. Son but principal est de faciliter l'envoi de recommandations (sites Web à voir, articles à lire, etc).
Pas facile à décrire. Cela ressemble apparemment à
Pearltrees (que je n'ai jamais pu tester sérieusement, car il dépend d'un logiciel privateur), cela tient du moteur de
blog, de l'outil de
microblogging, des
sites de partage de signets comme
del.icio.us mais cela a
aussi des rapports avec les sites de Q&A
comme le groupe StackExchange... Le mieux
est peut-être que je pointe vers les descriptions de SeenThis
lui-même : « C'est
quoi, SeenThis ? » et « Le
minimum à savoir » (la documentation pour les débutants). Mais,
si vous tenez à ce que je fasse un résumé moi-même, je dirais que
SeenThis permet d'écrire de manière très légère, très rapidement, des
courtes recommandations, du genre « J'ai vu ce site Web de cuisine. Il est très
bien pour ceux qui aiment les fraises. Son URL est
http://strawberry.example. » Ces recommandations
sont supposées être courtes mais elles ne sont pas limitées à 140
caractères et on peut donc développer ses idées si on le souhaite. Le
site semble donc utile pour les activités de veille. Ainsi, on peut voir des messages sur la situation à Gaza, le projet de DNS pair-à-pair,
les plans répressifs
d'Hadopi et la
vraie traduction de Firefox (qui n'est pas un renard).
On retrouve dans SeenThis des choses classiques comme le principe d'abonnement aux recommandations d'une personne donnée, ou comme le hashtag mais, ici, on a droit à tout Unicode (ce qui résout un des problèmes les plus agaçants de Twitter.) On peut donc suivre #Android ou #Chine ou #Sexe mais aussi #détection_des_langues.
Sur le papier, SeenThis dispose de fonctions linguistiques avancées (j'ai bien aimé l'ajout automatique de la langue d'un site vers lequel on pointe) mais ces possibilités ne sont pas encore très utilisées, l'essentiel des messages semblant en français.
SeenThis est actuellement encore en version béta et évolue souvent. Depuis hier, il est ouvert à tous. Parmi les limitation gênants, on notera qu'il n'existe pas encore d'API, ce qui interdit de développer des clients SeenThis adaptés (il faut passer par un navigateur Web).
Je vous laisse chercher quels sont les gens connus qui sont déjà sur SeenThis. Moi, je suis là.
L'article seul
Mélanger les lignes en shell Unix
Première rédaction de cet article le 8 février 2011
C'est toujours amusant de voir la quantité de logiciels qui existent pour le shell Unix. Hier, j'avais un problème simple, mélanger au hasard les lignes de texte produites par un programme et je craignais qu'il n'existe pas de solution. Au contraire, grâce à des twittériens sympas (et grâce à un moteur de recherche), j'en ai trouvé de nombreuses.
D'abord, le problème : un script shell qui
doit se connecter à un serveur de
noms parmi ceux faisant autorité pour une zone. La
commande dig renvoie une liste de candidats
(ici, pour .fr) :
% dig +short NS fr. f.ext.nic.fr. d.nic.fr. e.ext.nic.fr. d.ext.nic.fr. a.nic.fr. c.nic.fr. g.ext.nic.fr.
et il faut en prendre un au hasard. Minute, dirons certaines personnes qui ont déjà fait du DNS : cela se fait tout seul. BIND mélange automatiquement les réponses (on nomme cela le round-robin). Certes, mais c'est spécifique à BIND, aucune norme DNS n'exige cela et le résolveur dont je me sers, Unbound, ne le fait pas, et à juste titre : c'est le client DNS qui doit mélanger, s'il le souhaite.
Comment le faire en shell ? D'abord, voyons une solution
non-portable. La version GNU de
sort (utilisée par exemple par
Debian) a une option -R
(ou --random-sort)
qui fait exactement ce qu'on veut (idée de Pascal Bouchareine) :
% dig +short NS fr. | sort -R | head -n 1 f.ext.nic.fr. % dig +short NS fr. | sort -R | head -n 1 e.ext.nic.fr.
Autre solution, en Perl (due à Gaël Roualland) :
% dig +short NS fr. | perl -MList::Util -e 'print List::Util::shuffle <>' | head -n 1 a.nic.fr. % dig +short NS fr. | perl -MList::Util -e 'print List::Util::shuffle <>' | head -n 1 c.nic.fr.
Avec Ruby (code de Ollivier Robert et Farzad Farid) :
% dig +short NS fr. | ruby -e "puts STDIN.readlines.shuffle.first" g.ext.nic.fr.
Et en Python (code de Jérôme Petazzoni) :
% dig +short NS fr. | \ python -c "import random,sys ; print random.choice(sys.stdin.readlines())," d.nic.fr. % dig +short NS fr. | \ python -c "import random,sys ; print random.choice(sys.stdin.readlines())," d.nic.fr.
Et puis pourquoi s'arrêter là ? En Scala (code de Eric Jacoboni, non testé) :
scala -e 'util.Random.shuffle(io.Source.stdin.getLines) foreach println'
On peut souhaiter utiliser plutôt un programme tout fait. Étonnemment, il n'en existe pas moins de quatre juste pour cette tâche (en commentaires, j'indique le nom du paquetage Debian contenant ce programme) :
# unsort, suggestion de Hauke Lampe # Paquetage unsort % dig +short NS fr. | unsort -r | head -n 1 e.ext.nic.fr. % dig +short NS fr. | unsort -r | head -n 1 d.nic.fr. # bogosort, suggestion de Hauke Lampe # Plus de paquetage dans Debian # <http://www.lysator.liu.se/~qha/bogosort/> ne compile pas tout # seul, non testé # shuf, trouvé dans la FAQ Bash (merci à Pierre Chapuis pour l'aide) # Paquetage coreutils % dig +short NS fr. | shuf -n 1 g.ext.nic.fr. % dig +short NS fr. | shuf -n 1 c.nic.fr. # randomize-lines, suggestion de Thibaut Chèze # Paquetage randomize-lines % dig +short NS fr. | rl -c 1 a.nic.fr. % dig +short NS fr. | rl -c 1 c.nic.fr.
unsort dispose d'options intéressantes, je vous invite à regarder sa page de manuel. Toutes ces commandes nécessitent l'installation d'un programme qui n'est pas forcément présent par défaut. Y a-t-il une solution en shell « pur » ?
Les shells modernes disposent d'une pseudo-variable
RANDOM qui est plus ou moins aléatoire. On peut
donc s'en servir (et c'est la solution que j'ai adopté pour mes
scripts) pour tirer au hasard. En m'inspirant d'un excellent
cours sur ksh, j'ai fait :
% set $(dig +short NS fr.) % shift $(($RANDOM % $#)) % echo $1 e.ext.nic.fr. % set $(dig +short NS fr.) % shift $(($RANDOM % $#)) % echo $1 d.nic.fr.
Ce code affecte le résultat de dig à $*, puis
décale d'une quantité aléatoire (le % est
l'opérateur modulo). Il marche sur bash, zsh et
ksh. Mais la pseudo-variable RANDOM n'est pas
normalisée dans Posix
(dash, par exemple, ne l'a pas) et le script
n'est donc pas vraiment portable. Ollivier Robert me rappelle que
FreeBSD a une commande random
(dans la section games donc pas forcément installée)
qui peut être utilisée pour générer ce nombre aléatoire, à la place de
$RANDOM. Si on ne veut dépendre d'aucun programme
extérieur, je ne crois pas qu'il existe de solution
complètement portable, et qui marche avec n'importe quel shell (par
exemple, /dev/random n'est sans doute pas
normalisé non plus...).
Si on veut du code qui est à peu près sûr de marcher sur tout Unix, il faut se limiter aux outils de base, dont awk fait partie. gbfo me suggère (et ça marche) :
% dig +short NS fr. | awk '{t[NR]=$0}END{srand();print t[1+int(rand()*NR)]}'
f.ext.nic.fr.
% dig +short NS fr. | awk '{t[NR]=$0}END{srand();print t[1+int(rand()*NR)]}'
d.ext.nic.fr.
Plusieurs autres solutions intéressantes figurent dans l'excellente FAQ de bash (merci à Robin Berjon pour le pointeur). Une des plus amusantes ajoute un nombre aléatoire devant chaque valeur, puis trie, puis retire le nombre ajouté :
% randomize() {
while IFS='' read -r l ; do printf "$RANDOM\t%s\n" "$l"; done |
sort -n |
cut -f2-
}
% dig +short NS fr. | randomize | head -1
a.nic.fr.
% dig +short NS fr. | randomize | head -1
f.ext.nic.fr.
Attention, ce code ne marche pas avec zsh qui crée un « sous-shell »
dans while. Comme le dit
la documentation, « subshells that reference RANDOM will
result in identical pseudo-random values unless the value of
RANDOM is referenced or seeded in the parent shell in between
subshell invocations ».
Merci à Manuel Pégourié-Gonnard pour ses explications sur ce point. Il
propose un autre code, que je n'ai pas testé :
randomize() {
RANDOM=$RANDOM
while IFS='' read -r l; do
printf "$RANDOM\t%s\n" "$l"
done | sort -n | cut -f2-
}
L'article seul
RFC 6071: IP Security (IPsec) and Internet Key Exchange (IKE) Document Roadmap
Date de publication du RFC : Février 2010
Auteur(s) du RFC : S. Frankel (NIST), S. Krishnan (Ericsson)
Pour information
Réalisé dans le cadre du groupe de travail IETF ipsecme
Première rédaction de cet article le 8 février 2011
Le protocole de sécurité IPsec a connu plusieurs versions, et de nombreuses extensions. Le programmeur qui voudrait aujourd'hui le mettre en œuvre, l'administrateur réseaux qui voudrait le déployer, doivent souvent se gratter le crâne assez longtemps, uniquement pour identifier les normes pertinentes. Pour leur faciliter la tâche, l'IETF produit un RFC spécial, la « carte routière » qui est uniquement une liste commentée des RFC qui s'appliquent à leur cas. La précédente version de la carte d'IPsec était le RFC 2411, que notre RFC 6071 remplace. Si vous voulez comprendre IPsec et IKE et que vous ne savez pas par où commencer, ce RFC 6071 pourra vous servir de guide dans la jungle des normes sur IPsec.
La section 1 commence par fournir un résumé bien utile d'IPsec et de ses protocoles auxiliaires comme IKE. IPsec vise à fournir un service de sécurité à tout service Internet, sans modifier les applications (contrairement à TLS). Si l'échange de paquets entre deux machines est protégé par IPsec, toutes leurs communications pourront être authentifiées et/ou confidentielles. On peut utiliser IPsec de bien des façons, mais les plus courantes aujourd'hui sont de créer un tunnel sécurisé entre deux sites ou bien d'établir un VPN entre un site central et des machines en promenade.
IPsec utilise la cryptographie et, pour cela, a besoin de clés. On peut les gérer de plusieurs façons (aujourd'hui, c'est souvent fait manuellement), mais la méthode standard pour la gestion dynamique des clés est IKE.
La section 2 de notre RFC classe les normes IPsec en pas moins de sept groupes : l'architecture, le protocole ESP (qui fournit authentification et confidentialité), le protocole AH (qui ne fournit que l'authentification), les algorithmes cryptographiques, les algorithmes combinés (qui indiquent comment faire fonctionner ensemble les différentes pièces), les algorithmes de préservation de l'intégrité des paquets et enfin IKE.
Du fait de la longue histoire d'IPsec, plusieurs versions de ce protocole coexistent. La version actuelle est IPsec v3 mais IPsec v2 est encore fréquemment rencontré dans la nature. La section 2.1.1 résume leurs différences. Par exemple, le protocole AH (RFC 4302), dont l'utilité est douteuse, puisque ESP fournit les mêmes services (tels que perçus par l'application), n'est plus obligatoire. AH existait en raison des restrictions à l'exportation de logiciels cryptographiques en dehors des États-Unis et de restrictions d'usage moyenâgeuses dans certains pays comme la France. Aujourd'hui que ces restrictions sont assouplies, AH ne fait que générer de la complexité supplémentaire, comme l'exposait la fameuse critique de Niels Ferguson et Bruce Schneier, « A Cryptographic Evaluation of IPsec ».
IKE a aussi plusieurs versions qui coexistent (section 2.3). La version actuelle est la v2, mais la v1 est toujours en service. La v2 se signale (section 2.3.1) entre autres par l'intégration d'EAP, l'utilisation d'ESP pour protéger IKE lui-même (avant, c'était un protocole spécifique qui s'en chargeait), par de meilleures protections contre les DoS, notamment en permettant au répondeur de ne pas allouer trop de ressources avant d'avoir authentifié l'appelant.
Outre les RFC sur IPsec et IKE, présentés plus loin, en section 3, il existe plusieurs registres IANA sur ces protocoles (section 2.4), notamment :
La section 3 décrit les documents à lire si on veut programmer IPsec. Je ne mentionne ici que ceux de l'IPsec récent (IPsec v3) mais notre RFC 6071 décrit aussi (section 3.1.1) ceux de la précédente version d'IPsec, autour du RFC 2401.
Le cœur de IPsec v3 est décrit dans trois RFC (section 3.1.2), le RFC 4301 sur l'architecture générale, le RFC 4302 sur AH et le RFC 4303 sur ESP. Autour de ce cœur, on trouve plusieurs ajouts comme la possibilité d'encapsuler IPsec dans UDP (RFC 3948) ou bien la possibilité de chiffrer sans arrangement préalable entre les parties (RFC 4322), par exemple en récupérant les clés dans le DNS (avec protection par DNSSEC bien sûr).
Sans être des ajouts à IPsec, il existe plusieurs RFC qui discutent de questions générales (section 3.3) comme la traversée des équipements NAT par IPsec (RFC 3715) ou les suggestions pour évaluer si IPsec est une solution adaptée (RFC 5406, uniquement pour le vieil IPsec v2).
IKE est traité de la même façon en section 4 : les documents de base pour la vieille - mais encore utilisée - version et pour la version actuelle, la v2 (le principal document étant le RFC 4306, suivi du document de clarification RFC 4718) puis les ajouts.
La section 5 est entièrement consacrée au délicat problème des algorithmes de cryptographie. Comme la cryptanalyse progresse sans cesse, envoyant dans les poubelles de l'histoire des algorithmes peu sûrs, et poussant à l'introduction de petits nouveaux, il est important qu'un protocole de sécurité comme IPsec puisse suivre l'état de l'art sans avoir besoin d'une révision. En nombre de RFC, c'est de loin ce secteur qui contribue le plus à la taille des normes IPsec. Pour que, dans cette variété de protocoles, deux mises en œuvre d'IPsec aient une chance de communiquer (section 5.1), il faut qu'il y ait un ensemble d'algorithmes communs. Dans IPsec, les algorithmes sont marqués comme obligatoires (toute mise en œuvre d'IPsec doit les implémenter) ou facultatifs. Le RFC 7321 définit les exigences auxquelles doivent obéir les algorithmes utilisés par IPsec, le RFC 4307, celles pour IKE.
La section 5.2 décrit ensuite les algorithmes de chiffrement eux-mêmes, par exemple l'obligatoire NULL (qui ne chiffre rien et ne protège donc rien, RFC 2410), l'obligatoire AES-CBC (RFC 3602, le facultatif Camellia (RFC 4312), etc.
Si la section 5.2 listait les algorithmes de chiffrement, la 5.3 décrit ceux utilisés pour le contrôle d'intégrité. On y trouve HMAC-SHA1 (RFC 2404), dont la mise en œuvre est obligatoire, mais aussi la famille SHA-2 (optionnelle, cf. RFC 4868), et même MD5 (RFC 2403) pas conseillé mais pas interdit non plus, les multiples vulnérabilités de MD5 n'affectant apparemment pas (pour l'instant) son usage en HMAC (RFC 4835).
Certains algorithmes peuvent fournir à la fois le chiffrement et l'intégrité, et la section 5.4 décrit ces combinaisons. Ainsi, AES en mode CCM CBC-MAC permet d'assurer les deux tâches (RFC 4309).
Pas de cryptographie sans nombres aléatoires (section 5.5), par exemple pour générer les clés de sessions de IKE. C'est donc une nouvelle série d'algorithmes qui doit être spécifiée.
Le zoo des algorithmes de cryptographie utilisés devient donc d'une taille impressionnante et on peut se demander si deux pairs IPsec trouveront une combinaison d'algorithmes qu'ils peuvent utiliser tous les deux ! La section 5.6 expose donc les suites. Une suite est un ensemble cohérent d'algorithmes qui simplifie le travail du programmeur : si on implémente toute la suite, on a un groupe d'algorithmes qui interopérera avec les autres utilisateurs de la même suite. En outre, il est plus facile de se référer à une suite qu'à une longue liste d'algorithmes. C'est ainsi que le RFC 4308 décrivait deux suites, « VPN-A », qui inclut 3DES, HMAC-SHA-1, et un mode Diffie-Hellman et « VPN-B » qui inclut AES-CBC, AES-XCBC-MAC et un mode Diffie-Hellman plus long. On peut ainsi choisir tout un ensemble d'algorithmes avec un seul bouton dans la configuration (« Use VPN-B: Yes »). Le RFC 4869 a ajouté quatre autres suites, tirées de normes « Suite B » de la NSA. Elles incluent la famille SHA-2.
Tiens, puisque j'ai parlé de Diffie-Hellman, mécanisme pour permettre à deux pairs de trouver des clés secrètes communes pour pouvoir communiquer, la section 5.7 décrit les RFC qui mentionnent cette méthode dans le contexte d'IPsec. Ainsi, le RFC 5903 est la dernière norme pour l'utilisation de courbes elliptiques dans le cadre Diffie-Hellman, et le RFC 5114 définit de nouveaux groupes pour cet algorithme.
Dans le monde réel, IPsec a connu de nombreux usages qui dépassaient parfois le strict cadre de ce qui était normalisé. La section 7 décrit certains de ces usages, qui étendent et facilitent l'utilisation d'IPsec. Ainsi, les RFC 3586 et RFC 3585 se penchent sur la question de définitions formelles des politiques de sécurité IPsec, le RFC 4807 décrit une MIB pour la gestion IPsec (il semble très peu utilisé), etc.
Une extension intéressante a été BTNS (Better-Than-Nothing Security, section 7.5) qui a introduit le concept de « la plus mauvaise sécurité est celle qu'on ne déploie pas » dans le monde IPsec. Celui-ci était réputé pour sa rigidité et son strict respect des bons principes techniques de sécurité. Ainsi, les protocoles IPsec imposaient une authentification des deux pairs, sans laquelle une attaque de l'intermédiaire était possible. Très bonne idée sauf que, en pratique, cette authentification nécessitait une lourde infrastructure d'identité (par exemple à base d'IGC) et qu'elle a, en pratique, pas mal freiné le déploiement d'IPsec. D'où cette évolution récente (2008) d'accepter un mode sans authentification, BTNS, qui permet d'établir une session IPsec avec des gens qu'on ne connait pas (pensez à un serveur Web, qui ne connait évidemment pas chacun de ses clients à l'avance). Les RFC 5386 et RFC 5387 décrivent BTNS.
Le talon d'Achille de tout protocole de
cryptographie est souvent dans la gestion des clés. Où les stocker,
comment garantir que la clé privée est en sécurité, que la clé
publique est bien authentique ? Pour la seconde question, la garantie
que la clé publique est bien la bonne, la section 7.8 rappelle le
mécanisme IPSECKEY qui permet de stocker les clés
publiques dans le DNS (RFC 4025). Ce
mécanisme est resté largement théorique à ce jour (après tout, le DNS
n'offrait typiquement que peu de garanties de sécurité) mais la
signature de la racine avec DNSSEC le 15 juillet 2010 lui
a redonné de l'actualité. Il est désormais possible de valider une clé
trouvée dans le DNS.
Le programmeur qui implémente IPsec doit se rappeler que c'est un mécanisme général, situé en desous de la couche transport. Normalement, il est invisible aux applications. Toutefois, certains protocoles intermédiaires font un usage spécifique d'IPsec et la section 8 en donne une liste. Ainsi (section 8.2) OSPF, depuis la version 3 (RFC 4552 et RFC 5340), a remplacé son ancien mécanisme d'authentification spécifique par IPsec. OSPF fonctionnant souvent en diffusion restreinte, cela ne permet pas l'usage de clés manuelles. En pratique, ce mécanisme de sécurisation semble très peu déployé et le passage à IPsec, trop complexe par rapport à l'ancienne méthode, a donc réduit la sécurité de OSPF (en sécurité, comme souvent dans d'autres domaines de l'ingéniérie, le mieux est l'ennemi du bien...)
Autre protocole de routage qui aurait bien besoin de davantage de sécurité, BGP. La section 8.6 décrit ce que IPsec peut lui apporter. Le RFC 5566 décrit ainsi une méthode pour protéger les session BGP. En pratique, elle semble quasi-inutilisée, les opérateurs préférant le RFC 2385 (ou peut-être demain son successeur, le RFC 5925). À noter que le plus gros problème de BGP, en pratique, n'est pas l'authentification du pair, mais la confiance qu'on accorde à ce qu'il transmet. Et, là, IPsec ne peut rien.
Autre consommateur d'IPsec, HIP (section 8.3 et RFC 7401). HIP est un protocole de séparation de l'identificateur et du localisateur. Il introduit donc des failles potentielles liées à l'indirection supplémentaire, par exemple d'un méchant essayant de rediriger un trafic important vers une victime en faisant croire que l'adresse IP de la victime est la sienne. N'ayant pas de mécanisme de sécurité propre, HIP délègue la protection de son trafic à IPsec (RFC 5202 et RFC 5206).
IPsec garantissant l'intégrité du trafic IP, il peut rentrer en conflit avec des protocoles qui modifient les paquets, pour de bonnes raisons, par exemple la compression. D'où le nombre de RFC sur l'interaction entre IPsec et ROHC (section 8.5), par exemple le RFC 5856 qui permet de comprimer les paquets dans un tunnel IPsec ou le RFC 5858 qui décrit des extensions à IPsec lui permettant de mieux s'entendre avec ROHC.
Si certains protocoles, comme dans la section précédente, utilisent IPsec, d'autres réutilisent seulement IKE pour leurs besoins propres (section 9). C'est le cas par exemple d'EAP (RFC 5106).
Voilà, ce résumé d'un long RFC (et qui se termine par une longue bibliographie) aura réussi, je l'espère, à donner une idée de la richesse et de la complexité du monde d'IPsec.
Merci à Yves Rutschle pour avoir relu et trouvé une grosse bogue.
L'article seul
Atelier IDN de l'AFNIC le jeudi 10
Première rédaction de cet article le 7 février 2011
Dernière mise à jour le 10 février 2011
Le jeudi 10 février, au matin, l'AFNIC
organisait à Paris un atelier d'information et de
réflexion sur l'introduction des IDN dans
.fr. Je présentais
l'introduction à cet atelier.
Il serait en effet temps qu'on puisse enregistrer
stéphane.fr ou
maçonnerie-générale.fr (on voit d'ailleurs des
publicités où l'utilisateur, ignorant des règles d'enregistrement dans
.fr, a utilisé un IDN.fr...). Voici les transparents de mon exposé :
Le compte-rendu officiel de l'atelier est sur le site de l'AFNIC. Vous pouvez aussi chercher dans ce blog des articles sur les IDN ou lire un autre compte-rendu du même atelier, par exemple celui par Cédric Manara (avec une étude très fouillée des contentieux affectant les IDN), ou celui du SEO Camp (avec d'intéressants tests faits sur des logiciels courants) ou bien celui par Éric Freyssinet.
L'article seul
Import/export de données avec un calendrier Android
Première rédaction de cet article le 6 février 2011
Un des plus gros problèmes du système d'exploitation Android est certainement dans la dépendance de son outil d'agenda au service Google Calendar. Si on utilise Google Calendar, tout va vien, la synchronisation avec les données du téléphone se fait toute seule, les sauvegardes sont faites chez Google, tout le monde est heureux. Mais si on ne veut pas partager ses données avec Google, qui va lui même les partager avec plein de gens (à commencer par la police de son pays), si on veut pouvoir avoir des rendez-vous personnels ou professionnels sans que Google soit au courant, quelle solution pour faire des sauvegardes ? Et, plus généralement, pour importer et exporter des calendriers avec Android ?
La solution la plus évidente, changer de logiciel, ne marche pas : le seul logiciel concurrent, Jorte, est plutôt pauvre. Par exemple il n'a même pas le concept d'évenements récurrents. Très peu de gens l'utilisent. Et, s'il y a au moins une dizaine de clients Twitter sur Android, écrire un logiciel d'agenda est moins prestigieux et il n'y a donc guère de choix. (Je n'ai pas encore testé Pimlico qui, au 11 février 2011, n'a pas atteint le Market, ni Calengoo, dont Yannick vient de me parler mais, de toute façon, ce dernier ne gère pas non plus iCalendar. De même, le projet aCal, suggéré par Raphaël 'SurcouF' Bordet, n'est pas encore assez mûr (en mai 2011, il n'y a toujours pas grand'chose qui marche)
L'idéal serait que le client Agenda puisse enregistrer au format standard iCalendar (RFC 5545). Mais il ne le peut hélas pas, ce qui en dit long sur la volonté d'ouverture réelle de Google. Pour les sauvegardes, on doit donc copier les fichiers de l'agenda (je dois dire que je ne sais pas trop où ils sont sur le téléphone) ou bien synchroniser avec un serveur qui fera ensuite les sauvegardes.
À noter que le problème n'est pas spécifique à la distribution Android officielle. CyanogenMod a le même problème et la question ne semble pas susciter d'intérêt.
Pour cette synchronisation, il existe un protocole standard,
CalDAV (RFC 4791). Le client Agenda
d'Android ne le
parle pas (plus exactement, il le parle, et l'utilise avec
Google, mais ne permet pas de l'utiliser avec des serveurs tiers ;
difficile de ne pas penser que Google veut nous garder
prisonniers...) mais il existe plusieurs applications qui
peuvent assurer cette fonction. Côté serveur, j'ai testé Calendar Server d'Apple et un serveur Zimbra au bureau.
J'ai utilisé CalendarSync,
qui marche bien (avec Calendar Server, mais pas avec Zimbra, où je récupère un Method REPORT is not defined in RFC 2068 and is not supported by the Servlet API). (À noter que Calendar Sync ne semble pas être disponible pour CyanogenMod.) CalendarSync a depuis été remplacé par AnDal. Quant à
Funambol, il
essaie apparemment uniquement avec la méthode
POST sans tenir compte de ce que propose le
serveur CalDAV (section 5.1.1 du RFC 4791). Le serveur (ici
Calendar Server d'Apple) le jette donc (405 : méthode non disponible) et Funambol ne fournit rien de
plus détaillé qu'un mystérieux Network Error :
192.168.2.31 - - [02/Oct/2010:14:18:59 +0200] "POST / HTTP/1.1" 405 151 "-" "Funambol Android Sync Client 8.7.3" [1.2 ms]
Je n'ai pas eu plus de succès avec Funambol et Zimbra donc j'ai renoncé à ce logiciel. Question client CalDAV, il faut enfin signaler le récent (et loin d'être terminé) e7o.
Revenons au serveur CalDAV. Sur
Unix, j'ai testé Davical, très complexe et que je
n'ai jamais réussi
à faire fonctionner sur ma Gentoo
(Raphaël Bordet me signale que ça marche du premier coup sur
Debian et Florian Crouzat y arrive sur Gentoo). En revanche, le CalendarServer d'Apple,
disponible sous forme de paquetage pour la
plupart des Unix, est très
simple et marche du premier coup. Les données sont ainsi sauvegardées
en dehors du téléphone. Avec la configuration par défaut,
CalendarServer met un fichier .ics par événement,
dans un sous-répertoire de
/var/spool/caldavd/calendars. Il faut fouiller un
peu, notamment parce que les identités de l'utilisateur sont
remplacées par des nombres mais, mais, une fois que c'est fait, un simple cat dans le répertoire de l'utilisateur récupère le calendrier entier. (Sinon, je n'ai pas réussi à connecter
Evolution à CalendarServer, alors que
j'espérais que ce client CalDAV puisse ensuite exporter les
données. Erwan le Gall me signale que ça marche très bien avec Thunderbird.)
En parlant de sauvegarde, j'avais aussi le problème inverse : envoyer les données qui avaient été stockées sur mon Palm vers le nouveau smartphone. j-Pilot avait gentiment converti ces données en iCalendar, mais je n'ai pas trouvé de moyen de transmettre ces données à l'agenda d'Android : il ne lit pas le iCalendar et je ne sais pas comment l'injecter dans le serveur CalDAV CalendarServer.
Laurent Frigault suggère une autre méthode que je n'ai pas encore
complètement testée mais qui marche pour lui. Je le cite : « Pour l'importation, j'ai trouvé un moyen tout bête de contourner
ça : le courrier.
Il suffit de générer un fichier .vcs (iCalendar) et de se l'envoyer par
courrier (ou probablement de le déposer quelque part via le partage de disque
USB) et le tour est joué. Une fois le message arrivé dans K9-mail, on clique
sur la pièce jointe et on a alors le choix d'importer les évènements
dans le calendrier. » Pour ma part, j'ai noté que cela ne marchait que
si le fichier avait l'extension .vcs. S'il se
nomme .ics, ce qui est plus courant, K9-mail ne
propose pas de lancer l'Agenda.
« Pour les sauvegardes du calendrier, j'ai trouvé sur l'Android Market un programme qui fait de l'import/export au format iCalendar : iCal Import/Export. Ça ne fait pas de client/serveur juste import/export. » Cela marche très bien pour moi et j'obtiens bien du bel iCalendar comme :
BEGIN:VEVENT ORGANIZER:Outlook SUMMARY:Parinux Seeks DESCRIPTION:http://www.parinux.fr/ LOCATION: DTSTART:20101214T191500 DTEND:20101214T231500 DTSTAMP:20110206T205333Z UID:41+Outlook END:VEVENT
Raphaël Fournier me rappelle qu'il existe un format de synchronisation non normalisé, SyncML et que plusieurs logiciels pour Android gèrent ce format (comme Funambol, déjà cité), qui pourrait donc fournir une autre solution. Plusieurs logiciels serveurs libres le gèrent également, comme Horde, qu'utilise Raphaël avec succès.
Patrick van de Walle a documenté la méthode qu'il utilise (avec Davical).
L'article seul
Fiche de lecture : Through the language glass
Auteur(s) du livre : Guy Deutscher
Éditeur : Metropolitan Books
978-0-8050-8195-4
Publié en 2010
Première rédaction de cet article le 6 février 2011
Il y a depuis longtemps en linguistique un débat sur l'hypothèse de Sapir-Whorf. Celle-ci a plusieurs formes possibles (Sapir et Whorf n'utilisaient pas la même). Une version modérée de cette hypothèse est de dire que la langue qu'on parle influence le cours des pensées. Une version plus extrême est d'affirmer que la langue parlée rend difficile, voire empêche complètement d'exprimer certaines idées. Quel est aujourd'hui l'avis de l'auteur, le linguiste Guy Deutscher ?
La linguistique, comme toutes les sciences humaines, aime bien les longues polémiques détachées de tout fait précis. Car enfin, comment savoir si la vision du monde des Hopis, leur philosophie, est due au fait que le verbe et l'action sont souvent fusionnés dans leur langue (comme dans le français « il pleut » alors que l'hébreu dit « la pluie tombe ») ? Ne sachant pas réellement ce qui se passe dans le cerveau, on ne peut souvent faire que des hypothèses, souvent fortement teintées idéologiquement (ainsi, les langues des peuples premiers étaient vues autrefois comme inférieures et peu dignes d'intérêt, alors qu'on a souvent tendance depuis les années 60 à les voir au contraire comme le véhicule de sagesses ancestrales). Deutscher ne se prive donc pas des polémiques de bas niveau et des règlements de compte.
Mais ce n'est pas l'intérêt de son livre. Sa valeur vient du fait que, depuis dix ou vingt ans, des expériences astucieuses ont permis, sinon de répondre définitivement à l'hypothèse de Sapir-Whorf, du moins d'être affirmatif à juste titre, dans certains cas. Ainsi, on a maintenant une meilleure idée des conséquences de certaines règles linguistiques sur la pensée humaine, et Deutscher développe trois exemples : l'orientation dans l'espace, la couleur et le genre.
Avant de résumer ces trois cas, un petit retour sur l'hypothèse de Sapir-Whorf. Sa forme la plus radicale dit donc que les concepts inexistants dans une langue ne peuvent tout simplement pas être pensés. C'est cette idée qui inspire le dictateur de 1984 pour créer une novlangue d'où des termes comme « liberté » ont été bannis. Son idée, qu'on peut qualifier de « grossièrement whorfienne » est que l'absence du mot empêchera les esclaves de penser à la révolte. Cette hypothèse là est clairement fausse : après tout, les mots ne sont pas de tout temps, ils ont tous été créés à un moment ou à un autre. De même que « liberté » ou « démocratie » ont été inventés un jour, de même pourraient-ils être réinventés si un dictateur voulait civiliser la langue française en l'épurant des mots qui donnent de mauvaises idées aux sujets.
Mais la création de néologismes n'est même pas nécessaire : si un concept n'a pas de mot, il peut quand même être décrit par périphrase, et il peut même être utilisé sans avoir de nom. Deutscher dit que l'absence de traduction du terme allemand « schadenfreude » en français ne signifie évidemment pas que les français soient incapables de se réjouir des malheurs d'autrui...
Alors, une fois éliminée la version simpliste de l'hypothèse de Sapir-Whorf, que reste-t-il ? Eh bien, pour résumer l'analyse de Deutscher, les langues n'ont pas tellement d'influence par ce qu'elles empêchent de dire (puisque n'importe quel concept peut être exprimé dans n'importe quelle langue, même s'il n'a pas de mot au début) mais par ce qu'elles obligent à préciser, et qui peut rester non spécifié dans d'autres langues.
Deutscher fournit trois exemples où des expériences ont pu montrer une influence de la langue sur la pensée. Le premier est la question de l'orientation dans l'espace. Dans la grande majorité des langues du monde, comme en français, on peut décrire une position par des coordonnées égocentriques (établies par rapport à un être humain), par exemple « Il y a une araignée près de ton pied droit » ou « Vas tout droit, puis tourne à droite à l'arbre puis à gauche avant la rivière », ou bien par des coordonnées géographiques (« Dunkerque est au nord de Barcelone » ou « Suivez le cap 340 »). En général, on utilise les coordonnées égocentriques pour les cas où on est proche, et les géographiques pour les grandes distances. Il ne viendrait à l'idée de personne de dire « Il y a une araignée près de ton pied nord ». Mais justement si ! Il existe plusieurs peuples, dont le plus étudié est celui des Guugu Yimithirr, qui n'utilisent que des coordonnées géographiques et qui racontent un naufrage avec des expressions comme « Je suis tombé du côté Est du bateau et Jim du côté Ouest. Un requin était au Nord mais il n'a pas attaqué. » Comment font-ils pour être conscients en permanence des points cardinaux, même dans l'eau, avec un requin tout proche ? Et, surtout, cela influence-t-il leur mode de pensée ?
Si la réponse à la première question est plus simple qu'il n'y paraît (un entrainement constant depuis le plus jeune âge, comme pour n'importe quelle langue humaine), la deuxième pose plus de problèmes. En linguistique, il est plus difficile de tester ses hypothèses qu'en physique. Une des expériences qui a finalement donné le plus de résultats (par Stephen Levinson) était de placer des objets sur une table, puis de les changer, en gardant leurs relations égocentriques, mais en faisant varier leurs relations géographiques, puis l'inverse. Ainsi, un objet reste à gauche d'un autre mais, la table étant tournée, il passe du Nord au Sud de l'objet de référence. Si on demande à des Guugu Yimithirr de décrire s'il y a eu changement des positions ou pas, ils donnent des réponses inverses à celles des européens. Des notions comme « rien n'a changé sur cette table » dépendent donc de la langue qu'on parle... (Cf. « Language and cognition: The cognitive consequences of spatial description in Guugu Yimithirr ».)
Autre exemple, les couleurs. Au 19ème siècle, Gladstone avait étonné les érudits de cette époque avec une analyse de l'œuvre d'Homère où il expliquait que les anciens grecs ne voyaient pas les couleurs comme nous et étaient notamment insensibles au bleu et au vert. Son raisonnement s'appuyait sur le fait qu'Homère utilise beaucoup de formules qui indiquaient un drôle de sens des couleurs (« la mer couleur du vin », « le ciel violet sombre ») et sur la conviction bien ancrée à l'époque comme quoi les différences entre les peuples ne pouvaient pas venir de la culture, seulement de différences physiques. À l'époque, les conclusions de Gladstone avaient été très contestées (« Homère était aveugle, donc il n'est pas représentatif des grecs de son époque ! » ou « Homère était un poète, la mer couleur du vin était juste une licence poétique ! ») mais Deutscher explique qu'aujourd'hui on pense que les faits constatés par Gladstone sont réels (Homère n'était pas aveugle, comme le montrent les nombreuses et vivantes descriptions qu'il fait, et il n'utilise pas de telles licences poétiques pour autre chose que les couleurs) mais Gladstone a inversé l'effet et la cause. L'ancien grec manquait de termes pour décrire les couleurs, surtout celles qu'on ne savait pas reproduire artificiellement à l'époque, et ce manque entraîne une certaine indifférence aux couleurs de la part de l'aède.
Comment prouver qu'un vocabulaire différent influence la perception des couleurs alors que, on le sait aujourd'hui, tous les êtres humains ont le même système visuel ? En demandant à des anglophones et des russophones de dire si deux couleurs sont différentes ou pas et en mesurant, non pas la réponse (identique pour tout le monde, en raison de l'unité physique de l'espèce humaine) mais le temps de réponse. Le russe a deux mots pour le bleu (голубой pour du bleu clair et синий pour du bleu plus soutenu). Or, l'expérience décrite dans « Russian blues reveal effects of language on color discrimination » montre que, si les russophones et les anglophones ont des temps de réponse identiques lorsque les deux couleurs sont toutes les deux du голубой ou bien toutes les deux du синий, en revanche, les russophones prennent plus de temps si les deux couleurs sont objectivement proches (tel que mesuré par un spectromètre) mais décrites par des mots différents. La seule différence linguistique se traduit donc par une différence de perception.
Dernier cas présenté par Deutscher, celui du genre. On sait que le français a deux genres, masculin et féminin. L'anglais ajoute le neutre et les anglophones ont toujours du mal à apprendre quel est le « sexe » de chaque objet. De la même façon, les francophones ont du mal avec l'allemand, sexué de la même façon, mais où chaque objet a un autre genre. Le monde du genre ne se limite pas au masculin, au féminin et au neutre et Deutscher cite l'exemple du guragone où il existe un genre distinct pour les légumes, et où le mot erriplen (qui veut dire avion) est de ce genre (suite à une évolution compliquée).
Est-ce que ce système de genres, et les classifications qui en résultent, influencent la pensée ? Plusieurs expériences semblent indiquer que oui. Ainsi, si on demande à des hispanophones et des germanophones de citer des adjectifs associés à certains objets, les hispanophones citent des qualités « masculines » (fort, résistant) pour un pont (el puente) et les germanophones des qualités « féminines » (beau, élégant) pour le même objet (die Brucke). Il peut être difficile d'en tirer des conclusions fermes (d'autant plus que Deutscher oublie de rappeler que la liste des qualités « masculines » ou « féminines » varie également selon les cultures et les époques...) Une meilleure expérience, faite par Maria Sera, ne mettant pas en jeu de préjugés sur les hommes et les femmes, et plus récente, fut de demander à des francophones et des hispanophones de choisir parmi plusieurs voix d'acteurs et d'actrices pour faire parler des objets qu'on leur présentait. Les francophones choisirent un acteur mâle pour le lit et les hispanophones une actrice pour la cama. Et ce fut l'inverse pour la fourchette et el tenedor. Conclusion : il semble bien que les choix effectués par la langue influencent le processus de pensée.
Il y a bien d'autres points sur lesquels les langues diffèrent, et dont il semble a priori évident qu'ils peuvent avoir une influence sur nos pensées. Mais l'auteur est prudent et fait bien la différence entre les cas où il y a eu des expériences et des résultats (comme les trois cas cités plus haut) et ceux où les seules conclusions sont subjectives. Ainsi, les obligations grammaticales du témoin (comment sait-on que le fait qu'on rapporte est vrai ?) varient beaucoup selon les langues. En français, nulle obligation d'indiquer les preuves dans une affirmation (« Un gros animal est passé près de la rivière ») alors que Claude Hagège, dans son livre « Le dictionnaire amoureux des langues » cite de nombreux cas de langues où une telle précision est obligatoire dans la grammaire (par exemple par l'utilisation de temps différents selon qu'on a été un témoin direct ou pas).
Il semble aller de soi que l'obligation de mentionner systématiquement les preuves à l'appui d'une affirmation peut influencer le mode de pensée des locuteurs de cette langue, mais personne n'a apparemment encore conçu et exécuté une expérience qui permettrait d'apporter des preuves.
À noter, pour conclure, qu'il existe un langage qui a été entièrement conçu pour tester l'hypothèse de Sapir-Whorf, le lojban. Mais son succès limité ne lui a pas permis de remplir ce rôle...
L'article seul
RFC 6090: Fundamental Elliptic Curve Cryptography Algorithms
Date de publication du RFC : Février 2011
Auteur(s) du RFC : D. McGrew (Cisco Systems), K. Igoe, M. Salter (National Security Agency)
Pour information
Première rédaction de cet article le 4 février 2011
Dans l'arsenal des algorithmes de cryptographie utilisés sur l'Internet, on trouve de plus en plus d'algorithmes basées sur les courbes elliptiques (par exemple les RFC 4754, RFC 5289, RFC 5656 et RFC 5753, sans compter les normes d'autres SDO). Mais il n'existait apparemment pas de texte de synthèse sur cette famille d'algorithmes, utilisable comme référence pour des RFC. Ce manque est désormais comblé avec ce RFC 6090 qui résume ce que tout participant à l'IETF devrait connaître des courbes elliptiques et de leur utilisation en cryptographie. Ainsi, RSA et la factorisation en nombres premiers ne restera pas la seule méthode de cryptographie asymétrique sur laquelle faire reposer la sécurité des communications à travers l'Internet.
Ce RFC nécessite donc un peu plus de connaissances en mathématiques
que la moyenne. Le débutant pourra commencer par l'excellent article
d'Adam Langley,
sur son blog
Imperial Violet, « Elliptic
curves and their implementation ». Il apprendra que
les courbes elliptiques n'ont rien à voir avec
les ellipses (en mathématiques, lorsqu'on classe des objets en deux types on
appelle souvent l'un le type pair, le type impair ; lorsqu'on tombe sur
trois types, on qualifie souvent les trois types de parabolique,
elliptique et hyperbolique, en référence aux coniques), il verra de jolies
images : (toutes les images de cet article ont été
volées à l'article sur Imperial Violet).
Il devra aussi réviser quelques notions
de maths (cf. section 2 du RFC) comme celle de
groupe (section 2.2 du RFC). En effet, les points de
la courbe elliptique, plus une opération d'addition sur la courbe
(qu'on peut aussi représenter visuellement, voir l'image plus loin),
qui a un élément neutre (un zéro),
forment un groupe.
(À noter que le RFC, lui, sans donner de nom à
cette opération, la note * qui est d'habitude réservé, en informatique, à la
multiplication, voir annexe E pour une discussion de ces deux
notations possibles.)
Une fois qu'on a l'addition, on définit la multiplication par un nombre entier positif (qui consiste juste à répéter l'addition). Pour tout point de la courbe, on peut donc relativement facilement le multiplier par un nombre quelconque (ce nombre sera la clé privée). Mais l'inverse est extrêmement dur : étant donné un point résultat, et le point de départ, comment trouver le nombre qui a servi à la multiplication ? Dans le groupe formé par les nombres entiers et l'addition usuelle, c'est trivial (c'est une simple division euclidienne). Sur la courbe elliptique, c'est au contraire une tâche herculéenne. Et c'est là son intérêt pour la cryptographie. De méme que RSA reposait sur le fait qu'une composition des facteurs premiers est triviale mais que la décomposition est très difficile, la cryptographie par courbes elliptiques repose sur le fait que la multiplication sur la courbe est simple, la division très difficile. On a donc la base de la cryptographie asymétrique, une opération mathématique très difficile à inverser.
J'ai dit que la multiplication sur la courbe elliptique était simple mais tout est relatif. L'essentiel de l'article d'Imperial Violet est consacré à la mise en œuvre logicielle et beaucoup d'optimisations sont nécessaires, pour pouvoir multiplier un point en un temps raisonnable, sachant que le facteur de multiplication est un très grand nombre. L'article devient nettement plus chevelu ici, à réserver aux fanas de l'algorithmique.
Après ce petit détour par les maths, revenons au RFC. Il utilise le sigle ECC pour parler de l'ensemble des techniques de Elliptic Curve Cryptography. Ce sont donc des techniques de clé publique, qui peuvent servir à mettre en œuvre des techniques comme Diffie-Hellman ou ElGamal. Bien qu'assez ancienne, ECC est toujours relativement peu déployé, alors qu'elle fournit en général une meilleure sécurité et des performances plus importantes. Notre RFC note que c'est sans doute en partie par manque de documents normatifs facilement disponibles (un problème que notre RFC vise justement à traiter) mais aussi en raison de problèmes d'appropriation intellectuelle (la plupart des techniques ECC sont pourries de brevets jusqu'au trognon, cf. section 9).
Le RFC fournit d'abord un arrière-plan mathématique nécessaire, en section 2. Comme il n'est pas facile de lire des formules mathématiques dans le texte ASCII auquel sont contraints les RFC, la lecture n'en est pas évidente et je suggère de partir plutôt de l'article d'Imperial Violet.
Le RFC donne ensuite la définition d'une courbe elliptique en section 3 et introduit la notion de transformation d'un système de coordonnées dans un autre, afin de faciliter les calculs (cf. annexe F pour du pseudo-code). Surtout, la section 3.3 liste les paramètres dont dépend une courbe elliptique particulière. Des propriétés de ces paramètres dépend la sécurité de la courbe et ils ne doivent donc pas être choisis au hasard (la section 3.3.2 donne les critères qu'ils doivent satisfaire). Un exemple d'une courbe et de ses paramètres, la courbe P-256, normalisée par le NIST (dans FIPS 186-2) et utilisée dans le RFC 4753, est donné en annexe D. Une autre courbe elliptique connue est Curve25519, utilisée dans DNScurve.
Une fois ECC définie, on peut l'utiliser dans des algorithmes de crypto classique. La section 4 décrit ECDH, courbe elliptique + Diffie-Hellman, pour permettre à ces chers Alice et Bob de se mettre d'accord sur un secret (qui servira au chiffrement ultérieur) bien qu'ils communiquent via un canal non sûr. Le principe est simple mais génial. Alice et Bob partent du même point G de la courbe, Alice choisit au hasard un nombre j et met G à la puissance j (je rappelle que le RFC utilise la notation multiplicative, pas l'additive comme dans l'article sur Imperial Violet, et note donc cette opération G^j). Bob en fait autant avec son nombre k pris au hasard. Chacun envoie le résultat de son calcul à l'autre, qui doit alors calculer G^(j*k). Par exemple, Alice reçoit donc G^k et calcule donc G^k^j (qui est équivalent à G^(k*j)). Alice et Bob connaissent donc le secret, G^(j*k), alors que l'écoutant éventuel n'a pu le déterminer, car il ignore j et k.
De même, on peut faire une version « courbe elliptique » de ElGamal (section 5). Cet algorithme de chiffrement était basé sur un autre groupe mathématique, celui des entiers modulo N mais on peut se servir d'un autre groupe, comme celui fourni par une courbe elliptique. C'est ainsi qu'est créé ECDSA, version à courbe elliptique de DSA (cet algorithme est disponible pour DNSSEC, cf. RFC 6605 ; il est déjà mis en œuvre dans PowerDNS ; DNSSEC a déjà un algorithme à courbe elliptique, GOST, cf. RFC 7091).
L'IETF se préoccupant de faire des protocoles qui marchent dans le monde réel, il faut se poser la question de l'interopérabilité. La section 7 décrit donc des détails pratiques nécessaires. Toujours sur le côté concret, la section 8 est consacrée aux détails d'implémentation et aux tests validant celle-ci. Par exemple, un test courant est de vérifier qu'un sous-programme produit, pour des paramètres d'entrée donnés, le résultat attendu. Comme le mécanisme de signature de KT-I (cf. section 5.4) est non déterministe, ce genre de tests ne va pas marcher, la signature étant différente à chaque fois. Par contre, la validation de la signature est, elle, déterministe (heureusement...) et peut donc être testée. De même, ECDH peut être testé avec les résultats des RFC 4753 et RFC 5114.
Reprenons de la hauteur : si les sections précédentes passionneront les mathématiciens et les programmeurs, la section 9 est consacrée aux problèmes que posent les brevets pour le déploiement des courbes elliptiques. Si les bases des courbes elliptiques semblent libres (en théorie, on ne peut pas breveter un théorème mathématique : mais, en pratique, les organismes comme l'Office Européen des Brevets violent régulièrement leurs propres règles, et semblent agir en dehors de tout contrôle démocratique), les optimisations nécessaires sont souvent plombées par un brevet. L'implémenteur d'une courbe elliptique doit donc, après avoir pris connaissance des règles de l'IETF sur le sujet (RFC 8179), consulter la base des appropriations intellectuelles publiées.
L'unique but de la cryptographie à courbes elliptiques étant la sécurité, la section Sécurité (la 10), revient donc en détail sur les précautions à prendre pour que les courbes elliptiques remplissent leur rôle. Il existe plusieurs attaques documentées (comme celle de Pohlig-Hellman), l'algorithme de Shanks ou celui de Pollard qui sont des algorithmes génériques, marchant avec n'importe quel groupe, comme des attaques spécifiques d'une courbe elliptique particulière. Le RFC insiste notamment sur l'importance de ne prendre que des courbes dont les paramètres ont été soigneusement choisis (voir aussi le RFC 4086, et l'annexe B, puisque plusieurs opérations dépendent de nombres aléatoires).
D'autre part, la cryptographie ne fait pas de miracles : si Diffie-Hellman protège contre un attaquant passif, il ne peut rien contre un intermédiaire actif.
Merci à Michael Le Barbier Grünewald pour sa relecture mathématique.
L'article seul
Essai Google AdWords pour mon blog
Première rédaction de cet article le 3 février 2011
Dernière mise à jour le 9 février 2011
Ne soyez pas surpris, chers lecteurs, si vous avez vu apparaître des pubs pour ce blog, au hasard de vos pérégrinations sur le Web. C'est parce que j'ai reçu un crédit pour utiliser le service Google AdWords et que cela faisait longtemps que je voulais le tester.
Le crédit en question était inclus dans un numéro de la revue « E-commerce, le magazine ». 50 € offerts aux lecteurs. Cela permet de jouer un moment.
Le principe de Google AdWords est que vous
payez Google pour afficher des pubs, et Google les dispose dans les
pages de résultats de son moteur de recherche, dans la rubrique
Annonces. Il existe aussi une offre Google pour héberger des
publicités sur son site, AdSense mais,
rassurez-vous, il n'est pas prévu de mettre de la pub sur www.bortzmeyer.org.
L'affichage de la pub AdWords dépend des mots-clés tapés, de la provenance géographique du client, etc. Le choix de ces mots-clés est tout l'art de Adwords ! Par défaut, vous payez automatiquement à chaque fois que Google décide d'afficher la publicité donc prudence avec le « paiement automatique » qui est le cas par défaut ! J'ai choisi au contraire le « paiement manuel » et, dans ce cas, Google ne dépense que ce qu'on a déjà payé (et arrête d'envoyer la publicité après). Cela semble donc la bonne méthode pour tester les 50 € sans risquer d'aller plus loin.
Lorsqu'on crée une campagne avec AdWords, on peut choisir un très grand nombre de paramètres (heureusement qu'il y a des valeurs par défaut car ce nombre est vraiment grand). Par exemple, on peut choisir les pays dans lesquels la publicité sera affichée. Malheureusement, le choix est purement sur une page géographique (pays ou bien région comme « Europe occidentale ») et ne peut pas se faire sur des critères linguistiques (du genre « tous les pays francophones »). La seule solution que j'ai trouvé était d'ajouter un par un tous les pays francophones auxquels je pensais (puis de rajouter le critère linguistique comme filtrage dans AdWords pour ne pas embêter les non-francophones dans les pays multilingues comme le Canada). (Par la suite, Benoit Boissinot m'a rappelé que j'aurais pu choisir tous les pays, puis uniquement le critère linguistique. Mais tout le monde en France n'a pas forcément configuré son navigateur pour demander du français ou indiqué à Google qu'il préférait le français - choix que ce dernier mémorise par la suite.)
L'un des choix les plus importants au moment de lancer sa première campagne est de choisir les mots-clés dont la demande par le client va déclencher l'affichage de la pub. Google indique pour chacun d'eux s'il est « éligible » ou « sans intérêt » mais je n'ai pas encore trouvé où les critères étaient expliqués. Ainsi, http est éligible alors que bgp est « Taux de diffusion restreint dû au faible niveau de qualité » (comme dns ou linux).
La première campagne est désormais terminée. Ça coûte très cher,
Adwords (1,67 € par clic dans mon cas), mes 50 € ont été
volatilisés en un rien de temps (quasiment tous les clics étaient en
réponse au mot-clé « http ») et,
comme prévu, Google m'a prévenu qu'il avait arrêté de diffuser les
pubs. Il ne me reste qu'un joli graphique des clics pendant la
campagne de pub : 
L'article seul
RFC 6091: Using OpenPGP Keys for Transport Layer Security (TLS) Authentication
Date de publication du RFC : Février 2011
Auteur(s) du RFC : N. Mavrogiannopoulos (KUL), D. Gillmor
Pour information
Première rédaction de cet article le 3 février 2011
Le protocole TLS, permettant de chiffrer et d'authentifier des communications sur Internet n'utilisait qu'un seul type de certificats, ceux à la norme X.509 (cf. RFC 5280). Désormais, on peut aussi se servir de certificats PGP. Ce RFC 6091 met à jour la première spécification de « PGP dans TLS », qui était dans le RFC 5081 et la fait passer du statut « expérimental » à « pour information ». (Depuis, le RFC 8446 a supprimé cette possibilité d'utiliser les clés PGP.)
Pour authentifier l'autre partie, lors d'une communication TLS (utilisée par exemple avec HTTP ou bien avec SMTP), on doit signer ses messages avec sa clé privée. Le correspondant doit connaitre la clé publique pour vérifier cette signature. Avec l'ancien protocole SSL et avec son successeur TLS (normalisé dans le RFC 5246), cela se faisait en présentant un certificat X.509. X.509 a plusieurs limites, notamment le fait qu'il dépende d'une autorité de certification. Tout le monde n'a pas envie de payer une telle autorité, pour un gain de sécurité contestable. Il était donc important d'avoir une alternative.
Celle-ci est déjà mise en œuvre dans GnuTLS (pour l'instant, le seul logiciel à le faire).
Techniquement, notre RFC dépend du mécanisme d'extension TLS spécifié dans
le RFC 5246. Ces extensions permettent d'annoncer le type de
certificat utilisé (extension cert_type, numéro 9
dans le registre des extensions), et donc de choisir X.509 ou bien PGP (PGP est
normalisé dans le RFC 4880). Le RFC précise que ces
extensions ne doivent pas être utilisées si on ne gère que des
certificats X.509, pour interopérer plus facilement avec les vieilles
implémentations. Sinon, si le client propose du PGP et que le serveur
ne connait pas, ce dernier répond
unsupported_certificate. Un registre des types de certificats possibles permettra d'ajouter plus tard autre chose que X.509 ou PGP. L'algorithme de chiffrement de la session, lui, est
indépendant du fait qu'on utilise X.509 ou PGP.
Notre RFC utilise le terme de clé pour parler des clés PGP actuelles et de certificat lorsque les mêmes clés sont utilisées pour l'authentification (cf. section 2). La clé PGP est envoyée encodée en binaire, ou bien peut être récupérée sur le réseau, si celui qui veut s'authentifier indique uniquement l'empreinte de la clé (de la même façon qu'un certificat X.509 peut être récupéré sur le réseau, si celui qui veut s'authentifier indique l'URL de son certificat, cf. RFC 6066, section 5). Attention, contrairement à l'option équivalente pour X.509, la possibilité de récupérer le certificat sur le réseau ne permet pas d'indiquer le nom ou l'URL d'un serveur de certificats. Celui-ci doit être connu du serveur (qui vérifiera ensuite que les empreintes cryptographiques correspondent.)
Les changements par rapport au RFC 5081 sont
résumés dans l'annexe A. Le principal, de loin, est un changement dans
la sémantique du message indiquant le certificat (Client Certificate et Server Certificate) qui fait que les mises en
œuvre de l'ancien RFC et celles de notre nouveau RFC 6091 ne peuvent pas interopérer. Comme l'ancien
RFC n'avait que le statut « expérimental » et qu'il n'a jamais été
largement déployé, ce n'est pas un trop gros problème en pratique.
L'article seul
RFC 6094: Summary of Cryptographic Authentication Algorithm Implementation Requirements for Routing Protocols
Date de publication du RFC : Février 2011
Auteur(s) du RFC : M. Bhatia (Alcatel-Lucent), V. Manral (IP Infusion)
Pour information
Réalisé dans le cadre du groupe de travail IETF opsec
Première rédaction de cet article le 3 février 2011
Plusieurs protocoles de routage utilisent de la cryptographie pour l'authentification. C'est le cas par exemple d'OSPFv2 (RFC 2328), IS-IS (RFC 1195) et RIP (RFC 2453). Limitée au début à MD5, la liste des algorithmes utilisées croît petit à petit mais dans le désordre. L'idée de ce RFC est de spécifier le minimum d'algorithmes qu'un routeur sérieux doit gérer, de manière à garantir l'interopérabilité. Il faut être sûr que tous les routeurs aient au moins un algorithme en commun.
La section 1 détaille le problème. Lorsque qu'un protocole de routage (prenons comme exemple OSPFv2, RFC 2328, annexe D) permet d'authentifier ses pairs, il peut le faire par un mot de passe passé en clair, ou bien par un condensat cryptographique du mot de passe et d'autres informations. (D'autres protocoles sous-traitent l'authentification à une couche inférieure, comme OSPFv3 - RFC 5340 - qui la délègue à IPsec mais ils sont hors-sujet pour ce RFC. Depuis le RFC 6506, OSPFv3 a de toute façon une authentification à lui.) Le mot de passe en clair offre peu de sécurité puisque n'importe quel sniffer peut le capter. Ce mot de passe n'est vraiment efficace que contre les accidents, pas contre les attaques délibérées. La protection par condensat cryptographique n'a pas cet inconvénient. Elle fonctionne en résumant un message composé d'un secret partagé (le mot de passe) et d'autres informations connues des routeurs. Ainsi, le mot de passe ne circule jamais en clair.
Traditionnellement, la fonction de hachage utilisée était MD5 (RFC 1321) mais des attaques cryptographiques réussies contre MD5 mènent à son abandon progressif. L'avantage de MD5 était que tout le monde le connaissait et l'utilisait, alors que la migration vers de nouveaux algorithmes fait courir un risque de babelisation. Il faut noter que les attaques connues contre MD5 (RFC 4270) ne s'appliquent pas forcément à l'utilisation qu'en font les protocoles de routage et que la vulnérabilité de MD5 est donc encore dans le futur. Néanmoins, il est plus prudent de prévoir son remplacement dès aujourd'hui. Les remplaçants envisagés sont en général de la famille SHA. Ceux-ci seront sans doute à leur tour remplacés dans le futur, la cryptanalyse ne cessant jamais de progresser. L'ancienne normalisation, qui indiquait « en dur » la fonction de hachage dans la spécification du protocole de routage, n'est donc plus adaptée. Les sections suivantes du RFC détaillent la situation pour les principaux protocoles de routage cherchant, pour chacun d'eux, comment éliminer MD5 tout en ayant un algorithme commun.
Commençons par la section 2, consacrée à IS-IS. Si la norme ISO originelle ne permettait que le mot de passe en clair, le RFC 5304 a ajouté la possibilité de cryptographie, d'abord avec MD5 puis, dans le RFC 5310, d'autres algorithmes comme la famille SHA. L'avantage de l'authentification par mot de pass en clair est que, normalisée dès le début, elle fonctionne avec toutes les mises en œuvre de IS-IS. Sa sécurité est très mauvaise (il est trivial d'écouter le réseau pour découvrir le mot de passe). Il est donc recommandé d'utiliser les solutions cryptographiques, mais cela implique des algorithmes communs. Si un routeur ne connait que SHA-256 et l'autre que SHA-1, ils ne pourront pas s'authentifier mutuellement. Or, même si les deux routeurs mettent en œuvre le RFC 5310, cette situation est possible.
Notre RFC ne fait pas de choix mais demande que les futurs RFC sur IS-IS choisissent au moins un algorithme obligatoire, qui sera donc connu de tous les routeurs, et qui ne soit pas MD5.
L'autre grand protocole de routage interne, OSPF, fait l'objet de la section 3. Si OSPFv3 reposait entièrement sur IPsec et n'avait pas de mécanisme d'authentification propre (cela a changé avec le RFC 6506), OSPFv2 (de très loin le plus utilisé) a son mécanisme à lui. Ce dernier, dans la norme originale (RFC 2328), permettait le mot de passe en clair ou bien de la cryptographie avec MD5. Le RFC 5709 ajoutait la possibilité d'utiliser la famille SHA. Mais les seuls mécanismes d'authentification obligatoires sont ceux de l'ancien RFC (y compris le plus simple, « pas d'authentification »). Comme avec IS-IS, il est donc nécessaire qu'une nouvelle norme dise clairement quel est l'algorithme standard et sûr que doivent mettre en œuvre tous les logiciels OSPF.
Quant à OSPFv3 (section 4), du fait qu'il utilise IPsec, ses algorithmes communs sont ceux d'IPsec, ESP (RFC 4522) qui lui même utilise SHA-1 (RFC 2404). Ce dernier sera sans doute remplacé bientôt par AES (qui avait été introduit dans le RFC 3566).
Et le bon vieux RIP, dans sa version RIPv2 (section 5) ? Sa norme actuelle est le RFC 2453, qui ne prévoyait comme authentification que le mot de passe en clair. Le RFC 2082 ajoutait MD5 que le RFC 4822 a remplacé par SHA. Toutefois, comme les deux autres protocoles cités, RIP n'a pas d'algorithme unique garanti et une nouvelle norme est donc nécessaire, pour éviter que les routeurs ne se rabattent sur MD5 (ou, pire, sur le mot de passe en clair) pour pouvoir interopérer.
La version RIPng, elle (section 6), comme OSPFv3, se repose entièrement sur IPsec et donc sur les mêmes algorithmes.
La section 7 résume et rappelle les problèmes de sécurité abordés. D'abord, tous les mécanismes étudiés ici ne fournissent que l'authentification. Si on désire en plus de la confidentialité, il faut chercher ailleurs (par exemple IPsec avec ESP). D'autre part, les experts en cryptographie conseillent généralement de changer les clés régulièrement, diverses attaques cryptanalytiques prenant du temps. Il ne faut donc pas en donner à l'ennemi. Or, aucun de ces protocoles de routage ne fournit de mécanisme pour un remplacement coordonné des clés, il faut tout gérer à la main.
L'article seul
RFC 6077: Open Research Issues in Internet Congestion Control
Date de publication du RFC : Février 2011
Auteur(s) du RFC : Dimitri Papadimitriou (Alcatel-Lucent), Michael Welzl (University of Oslo), Michael Scharf (University of Stuttgart), Bob Briscoe (BT & UCL)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF iccrg
Première rédaction de cet article le 3 février 2011
La congestion est la plaie des réseaux informatiques depuis leurs débuts. Quelle que soit la capacité de ceux-ci, les utilisations emplissent les tuyaux jusqu'à ce que ceux-ci débordent. Il y a donc depuis quarante ans, mais surtout depuis le travail de Van Jacobson en 1988 (voir son ancien mais toujours bon « Congestion Avoidance and Control », Proceeding of ACM SIGCOMM'88 Symposium, août 1988 ; attention, c'est assez matheux, réservé aux gens qui comprennent les fonctions de Liapounov), d'innombrables études et recherches sur la congestion. (Voir par exemple l'article du Wikipédia anglophone sur TCP.) Pourtant, le problème est loin d'être épuisé, comme le montre ce RFC du groupe ICCRG de l'IRTF consacré aux problèmes non résolus en matière de congestion. Couvrant tous les aspects de ce problème, il est également une passionnante lecture sur l'état actuel de l'Internet et le bouillonnement d'activité qu'il suscite toujours chez les chercheurs.
Qu'est-ce exactement que la congestion ? La section 1 la définit comme l'état d'un réseau dont les ressources sont tellement utilisées que des phénomènes visibles par les utilisateurs et objectivement mesurables (comme le retard d'acheminement des paquets, voire leur perte) apparaissent. Sur un réseau où les ressources sont partagées mais pas réservées (cas de l'Internet), la congestion se traduit par une diminution de la qualité de service. (Voir Keshav, S., « What is congestion and what is congestion control », Presentation at IRTF ICCRG Workshop, PFLDNet 2007, Los Angeles, février 2007.)
Le contrôle de congestion, lui, est l'ensemble des algorithmes qui permettent de partager les ressources en minimisant la congestion. Il existe sous deux formes, primal et dual (je n'ai pas cherché à traduire ces termes rares, apparemment issus de la recherche opérationnelle). La première fait référence à la capacité des émetteurs à adapter leur rythme d'envoi s'ils reçoivent des indications comme quoi la congestion a lieu. Sur l'Internet, c'est typiquement le rôle de TCP. La seconde forme fait référence au travail des équipements intermédiaires, les routeurs, qui détectent la congestion et réagissent, par exemple via la RED.
Aujourd'hui, des dizaines de RFC ont « congestion » dans leur
titre ; le RFC 5783 fournit un survol de cette
littérature et le RFC 5681 synthétise tout ce qu'il faut
savoir sur la congestion dans TCP. Dans les mises en œuvre de TCP/IP
aujourd'hui, d'innombrables lignes de code sont là pour réagir à la
congestion. Malheureusement, un bon nombre des algorithmes et méthodes « historiques » pour gérer la congestion sur l'Internet rencontrent leurs limites avec les
évolution des réseaux. Résultat, plusieurs systèmes d'exploitation
sont livrés avec des algorithmes non-standard (comme, dans certains
cas, Linux, avec l'algorithme
Cubic ;
l'algorithme en cours peut être affiché avec sysctl
net/ipv4/tcp_congestion_control et les disponibles avec
sysctl
net/ipv4/tcp_available_congestion_control). (On peut voir
aussi les projets
de FreeBSD qui incluent également Cubic et d'autres.) À noter
que tous les nouveaux algorithmes ne sont pas forcément un
progrès. Francis Dupont fait ainsi remarquer, suite à cet article, que
des algorithmes comme « TCP Vegas », excellent lors des tests,
ne réussissaient pas aussi bien sur le vrai réseau.
Autre évolution, l'utilisation de solutions qui ne sont pas uniquement de bout en bout mais font participer les routeurs, comme ECN (RFC 3168).
Quels sont les défis d'aujourd'hui ? La section 2 examine les défis généraux. L'un des premiers est l'hétérogénéité de l'Internet (section 2.1). Des liens radio laissant passer quelques misérables kb/s aux fibres optiques Gb/s, l'éventail des capacités est immense. Même chose pour la latence, entre les réseaux locaux où elle est inférieure à la milli-seconde et les liaisons satellites où elle approche la seconde. Rien n'indique que de tels écarts se résorberont. On imagine le travail de TCP, qui doit fonctionner dans un environnement aussi varié. À l'époque de Van Jacobson, latence et capacité des réseaux faisait qu'une connexion TCP n'avait en transit, à un moment donné, que quelques douzaines de paquets. Aujourd'hui, cela pourrait être beaucoup plus. Il n'y a pas actuellement de consensus à l'IETF pour choisir les nouveaux algorithmes, d'autant plus que leurs interactions (entre un pair TCP qui utiliserait un ancien algorithme et un pair qui utiliserait un nouveau) sont mal connues. Si le RFC 9743 définit des critères sur le choix d'un algorithme, ceux-ci ne répondent pas à toutes les questions, comme celle de savoir si on accepte de réduire les performances des anciennes implémentations (ce que font certaines nouvelles méthodes).
Second grand problème, la stabilité (section 2.2). On souhaiterait que, à situation inchangée, les algorithmes de contrôle de la congestion convergent vers un état stable, au lieu de faire du ping-pong entre deux états (on ouvre les vannes, la congestion reprend, on diminue le débit, le trafic passe très en dessous du seuil, alors on rouvre les vannes, etc). Il existe des théories mathématiques à ce sujet pour des algorithmes en boucle fermée, comme TCP, mais qui ne servent pas dans le cas où il y a interaction entre plusieurs boucles de contrôle, ce qui est le cas de l'Internet, où le ralentissement du débit d'une connexion TCP peut pousser les autres à augmenter leur débit. On souhaite également une stabilité locale : si un système est perturbé, après la fin de la perturbation, il revient rapidement à l'équilibre.
Les modélisations issues de la théorie de l'automatique permettent d'éliminer les algorithmes les plus mauvais (s'ils ne marchent pas dans les cas simples, ce n'est pas la peine de se demander s'ils fonctionneront sur l'Internet). Mais elles sont insuffisantes pour les cas réels, l'approche la plus courante aujourd'hui est donc la simulation, ce qui ne garantit pas que ça fonctionnera en vrai. Est-ce que TCP est stable dans des conditions réelles ? Il n'y a aujourd'hui aucune certitude scientifique à ce sujet.
Ce ne sont pas les heuristiques qui manquent, lorsqu'on conçoit un nouvel algorithme de gestion de la congestion, comme par exemple le principe de la conservation des paquets (faire en sorte que l'émetteur envoie autant de paquets par seconde que le récepteur en consomme). Mais elles peuvent être trop exigeantes (c'est le cas de la conservation de paquets, dont il a été démontré qu'elle était un principe suffisant, mais pas nécessaire) ou tout simplement non démontrées.
Un exemple d'un problème réel est que TCP démarre lentement : son débit s'accroit avec le temps au fur et à mesure que l'envoyeur se rassure qu'il n'y a pas congestion. Mais beaucoup de flots de données, à commencer par les courtes connexions HTTP qui récupèrent une seule page HTML, sont de durée tellement faible que TCP n'atteint jamais son état d'équilibre et de débit maximum. Cela peut pousser certains à « améliorer » l'algorithme dans leur intérêt (c'est le cas de Google, voir leur article). Égoïsme ou bien usage normal de la liberté ? En tout cas, cela a poussé à des recherches sur un TCP résistant aux égoïstes comme dans l'article « TCP congestion control with a misbehaving receiver ».
Beaucoup plus chaude est la question de la justice, surtout dans le contexte du débat sur la neutralité de l'Internet. C'est en effet une chose d'assurer le bien de l'Internet, c'en est une autre que de vérifier que cela ne se fait pas aux dépens de certains utilisateurs, sacrifiés au bien commun. Intuitivement, la justice, dans un réseau, c'est que, en cas de sacrifices, tout le monde doit prendre sa part de manière équitable (section 2.3). On touche là clairement à des questions politiques, suscitant des articles vengeurs comme le très intéressant article de Briscoe, « Flow Rate Fairness: Dismantling a Religion » (ACM SIGCOMM Computer Communication Review, Vol.37, No.2, pp.63-74, avril 2007). Briscoe argumente essentiellement sur le fait que la justice entre les flots TCP n'a aucun intérêt, il faudrait chercher la justice entre les personnes, ou bien entre les organisations. Mais, de toute façon, la question de la justice est connue pour être impossible à définir de façon cohérente dans le parallélisme (je cite Francis Dupont) : elle est sujette à un problème de la famille du paradoxe de Condorcet sur le vote équitable, c'est-à-dire que les critères qui établissent l'équitabilité ne sont pas compatibles.
Des RFC ont également traité ce cas comme le RFC 3714. Dans l'approche traditionnelle, pour le cas ultra-simple de deux utilisateurs regardant tous les deux YouTube, la justice était considérée comme l'égalité de leurs débits. Certains idéologues du marché ont par exemple proposé de définir la justice comme « ce que les utilisateurs sont prêts à payer pour éviter la congestion ». Dans cette approche, les deux débits pourraient être très différents. Mais intégrer l'aspect financier ouvre bien d'autres boîtes remplies de questions difficiles comme le mécanisme par lequel on va comptabiliser la contribution à la congestion.
Même si on ne prend pas en compte l'argent dans l'équation, la définition de ce qui est « juste » n'est pas triviale. Pas exemple, l'égalité doit-elle être celle des bits/s ou bien celle des paquets/s ? Faut-il la mesurer sur le long terme de façon à ce qu'une application sur une machine puisse profiter à fond du réseau parce que cette machine a été raisonnable dans les heures précédentes ? Le RFC note justement que ce n'est pas forcément une question de recherche, c'est un débat, et aucun article scientifique ne va le trancher. Le RFC note également que des mécanismes trop complexes, au nom de la justice, pourraient sérieusement handicaper l'Internet (car ralentissant trop les équipements, cf. RFC 5290).
Place maintenant à l'étude détaillée des défis qui attendent l'IETF dans ce domaine. Ils font l'objet de la section 3. Le premier est celui de la répartition du travail entre le réseau (les équipements intermédiaires comme les routeurs) et machines situées aux extrémités (section 3.1). Traditionnellement, l'Internet fonctionne en limitant sérieusement les fonctions des routeurs et en concentrant le travail difficile aux extrémités, où les machines ont davantage de ressources (section 3.1.1), peuvent maintenir un état complexe, et surtout sont sous le contrôle des utilisateurs (mettre trop de fonctions dans les routeurs peut sérieusement menacer la neutralité du réseau).
En outre, si de nouveaux mécanismes de gestion de la congestion apparaissent, et qu'ils sont situés dans les couches basses (comme la couche 3), ils mettront du temps à être déployés, d'autant plus que les concepteurs de routeurs attendront sans doute que ces mécanismes soient stables avant de les câbler en dur dans leurs circuits. Mais, d'abord, que peut faire un routeur pour aider à gérer la congestion ? Il peut le faire par une meilleure gestion de ses files d'attente, ou bien il peut le faire en signalant aux extrémités les problèmes de congestion qu'il voit. La première approche est déjà utilisée mais pas de manière uniforme dans tout l'Internet. Une de ses limites est qu'on ne sait pas trop quels sont les paramètres idéaux, par exemple pour les méthodes RED ou AVQ (Adaptive Virtual Queue) et qu'on ne dispose pas de moyen de les déterminer automatiquement.
La seconde façon dont les routeurs peuvent aider, la signalisation
explicite, est utilisée dans ECN (RFC 3168), Quick-Start (RFC 4782),
XCP (eXplicit Control Protocol, draft-falk-xcp-spec) et dans d'autres protocoles. Contrairement
à TCP, XCP sépare le contrôle de la justice (s'assurer qu'aucun flot
de données ne prend toute la capacité) et le contrôle de la
congestion. Mais XCP reste très expérimental et produit parfois de
drôles de résultats (« An Example
of Instability in XCP »). Dans tous les cas, ces
mécanismes, qui donnent un plus grand rôle aux équipements
intermédiaires, doivent être évalués dans le contexte du
fonctionnement de bout en bout, qui est l'un
des principaux piliers de l'Internet (RFC 1958), qui a assuré
son succès et sa survie. La
congestion est un problème intéressant précisément parce qu'elle ne
peut pas se régler uniquement de bout en bout (puisque c'est un
phénomène spécifique au réseau) mais il faut bien réfléchir avant de
mettre dans le réseau des fonctions qui pourraient interférer avec les
politiques d'utilisation des machines terminales.
Ainsi, un protocole comme XCP ne nécessite pas d'état dans le réseau (et semble donc respecter le principe de bout en bout) mais c'est uniquement à condition que les machines situées aux extrémités jouent le jeu, c'est-à-dire ne mentent pas sur les débits mesurés. Si on veut faire marcher XCP dans un environnement... non-coopératif (avec des tricheurs), les routeurs doivent alors garder trace des différents flots de données, ce qui met en péril le principe de bout en bout.
Tous ces problèmes (de comptabiliser l'usage que les différents flots de données font du réseau, et en résistant à la triche) existent depuis qu'on parle de QoS sur l'Internet, c'est-à-dire au moins depuis IntServ (RFC 2208). Le problème reste ouvert.
Une des raisons pour lesquels ils ne sont pas résolus est qu'il n'existe aucune technique (section 3.1.2) qui ne repose pas sur un état maintenu dans le routeur, par flot (donc, posant de grands problèmes de passage à l'échelle).
Autre problème pour l'usage des équipements réseaux à des fins de
lutter contre la congestion, l'accès à l'information (section
3.1.3). Pour être efficace, le routeur qui veut gérer la congestion
doit connaître des choses comme la capacité des liens. Attendez, me
direz-vous, un routeur sait forcément que son interface
ge-3/0/2 est à 1 Gb/s ! Mais c'est plus complexe que
cela : par exemple en cas d'interface vers un réseau partagé
(Wifi) ou en cas de tunnels (RFC 2784 ou
RFC 4301 ou bien d'autres techniques). Dans ces
circonstances, un routeur IP ne connaît pas forcément la capacité des
liens auxquels il est connecté.
Idéalement, si le routeur connaît la capacité du lien et le débit effectif, il sait si on approche de la congestion ou pas, via une simple division. Nous avons vu que la capacité n'était pas toujours connue mais le débit ne l'est pas non plus forcément. S'il est très haché, avec de brusques pics, déterminer un débit, pour le diviser par la capacité, n'est pas trivial. Bref, le routeur manque souvent d'informations pour décider. Faut-il créer de nouveaux mécanismes pour l'informer ? Ne risquent-ils pas de tourner très vite à l'usine à gaz ? (Un routeur IP a déjà beaucoup de choses à faire.)
Deuxième défi auquel est confronté TCP/IP : différencier la perte d'un paquet due à la congestion de l'abandon de ce paquet en raison de sa corruption (section 3.2). Actuellement, un routeur abandonne un paquet lorsque la congestion empêche sa transmission sur l'interface suivante. L'émetteur va typiquement interpréter toute perte de paquets comme un signe de congestion et diminuer le débit (TCP le fait automatiquement). Mais la perte du paquet peut être due à une autre cause, par exemple une modification accidentelle d'un ou plusieurs bits, qui rendra invalide la somme de contrôle, amenant la carte réseau à ignorer le paquet anormal. De telles modifications sont rares sur un lien filaire (il faut un gros rayon cosmique) mais relativement fréquentes sur les liaisons radio. TCP diminuerait alors son débit à tort. Le problème est bien connu (voir Krishnan, Sterbenz, Eddy, Partridge & Allman, « Explicit Transport Error Notification (ETEN) for Error-Prone Wireless and Satellite Networks », Computer Networks, 2004, ou bien le RFC 6069). La solution n'est pas évidente, d'autant plus que les deux phénomènes peuvent être liés (une congestion qui se traduit par des corruptions) et qu'il n'est pas évident qu'il faille continuer à envoyer au même débit si on perd la moitié des paquets suite à la corruption (voir un exemple de discussion).
Il y a donc deux problèmes ouverts, détecter la congestion et y réagir. Pour la détection, on pourrait penser compter sur la somme de contrôle dans l'en-tête IP (à condition que la couche 2 n'ait pas déjà jeté le paquet corrompu, ce que fait Ethernet). UDP-lite (RFC 3828) et DCCP (RFC 4340) le font (sans indiquer quelle doit être la réaction à ces corruptions). Une étude a montré que cela marchait bien au-dessus de GPRS et mal au dessus du WiFi. De toute façon, toute détection de corruption dans la couche 3 poserait des problèmes de coopération entre couches, difficiles à assurer pour IP, qui est conçu pour fonctionner sur toutes les couches 2 possibles.
Quant à la réaction à la corruption, il n'existe aucun protocole standard pour cela, bien que plusieurs propositions aient été faites dans la littérature scientifique (le TCP dit « Westwood »).
Un autre « point noir » de la gestion de la congestion est la prise en compte de la taille du paquet (section 3.3). Aujourd'hui, TCP l'ignore complètement, en partie parce que les très grands paquets (> 1500 octets, la MTU d'Ethernet) sont extrêmement rares sur l'Internet. La question de savoir si TCP a tort ou raison d'ignorer ce facteur est toujours un sujet de recherche. DCCP, par contre, peut tenir compte de la taille des paquets (cf. RFC 5622). Les routeurs typiques, en cas de congestion, ne tiennent pas compte de la taille d'un paquet avant de le jeter, alors que certaines études semblent indiquer que cela pourrait être une bonne idée. Beaucoup de questions restent ouvertes sur ce sujet : le facteur limitatif sur le réseau, dans les prochaines années, sera-t-il le nombre de bits ou le nombre de paquets (sur les réseaux lents, c'est clairement le nombre de bits qui peut déclencher la congestion ; mais au fur et à mesure que les réseaux deviennent plus rapides, c'est la capacité des équipements à traiter un grand nombre de paquets qui devient problématique). En cas de congestion, faut-il diminuer le nombre de bits (en réduisant le débit d'émission, ce que fait TCP) ou le nombre de paquets (en tentant des paquets plus gros) ? Actuellement, l'émetteur ne sait pas pourquoi il y a congestion, ce qui rend difficile le changement de son comportement. Prendre en compte la distinction entre débit en bits et débit en paquets compliquerait l'Internet mais y aurait-il un bénéfice ? Si la taille maximale des paquets sur le réseau, actuellement limitée en pratique à 1500 octets dans la plupart des cas, devait augmenter, la question deviendrait brûlante. (Ce point est couvert avec plus de détails dans le RFC 7141.)
La grande majorité des études sur le comportement de protocoles comme TCP supposait un flot relativement régulier sur le long terme, permettant ainsi aux algorithmes d'atteindre leur équilibre. Mais, dans la réalité, les choses ne se passent pas comme cela : un fichier HTML typique se charge avec seulement quelques paquets, et TCP sera donc, pendant toute la durée du flot, dans l'état « démarrage ». Comment améliorer ce cas fréquent (section 3.4) ? Au départ, le protocole de transport ne connaît rien des caractéristiques de la liaison et ne peut donc pas optimiser son débit. L'algorithme standard de TCP est tout de prudence : conçu par Van Jacobson et connu sous le nom significatif de slow start, il consiste à être très modéré tant qu'on ne connaît pas les détails de la liaison (RFC 2581 et RFC 5681). Résultat, le débit moyen est souvent trop bas, le réseau restant inoccupé. Ce problème est reconnu depuis longtemps (RFC 3742) mais sa solution souffre du manque de bases théoriques à cette difficile question (le slow start a été conçu de manière empirique).
Une autre solution serait de modifier les applications pour qu'elles réutilisent les connexions TCP existantes. C'est ce que peut faire HTTP, avec les connexions persistentes (RFC 2616, section 8.1).
Les spécificités de l'Internet ajoutent un nouvel élément au tableau (section 3.5). Contrairement à quasiment tous les autres réseaux informatiques qui ont existé, l'Internet est multi-organisations (le RFC dit multi-domains, où un domain est un système autonome). Ainsi (section 3.5.1), il existe des mécanismes de signalisation de la congestion qui peuvent poser des problèmes dans un tel environnement. C'est le cas de ECN (RFC 3168) où des bits non utilisés jusqu'à présent servent à indiquer que le routeur qui les a mis commence à voir de la congestion. En environnement mono-domaine, tout va bien. Mais dans le cas où le paquet rencontre plusieurs domaines, peut-on encore faire confiance à ces bits, qui ont pu être mis ou retirés à tort, par exemple pour ralentir une victime située dans un autre domaine (sections 8 et 19 du RFC 3168) ? Pour ECN, il y a des solutions techniques possibles (comme le RFC 3540), quoique apparemment peu déployées. Mais, d'une manière générale, toutes les solutions reposant sur la confiance entre domaines sont incertaines (notre RFC cite aussi le cas de TRC, TCP rate controller, un système de surveillance que les flots TCP se comportent bien). L'échange d'informations entre domaines, qui serait certainement utile pour lutter contre la congestion, est frappé de suspicion (section 3.5.2). Mon voisin me dit-il la vérité ? Dois-je lui dire la vérité en sachant que les informations transmises peuvent, entre autres, l'aider à se faire une bonne image de mon réseau, brisant ainsi la confidentialité ? Or, tous les mécanismes de signalisation de la congestion par les équipements réseau sont affectés par ce manque de confiance.
Un problème de sécurité proche est celui des applications malhonnêtes. L'Internet résiste aujourd'hui à la congestion car chaque pair TCP respecte les règles, même quand elles vont contre son propre intérêt. Après tout, un émetteur n'a jamais intérêt à diminuer son débit, si d'autres le feront à sa place. La section 3.7 se penche sur les comportements négatifs que pourraient adopter des applications. Le problème a déjà été étudié et des solutions proposées (RFC 3540). Elles sont efficaces (peut-être trop, dit le RFC, laissant entendre qu'elles pourraient sanctionner des innocents). Mais elles sont très peu déployées. Une des raisons est peut-être que les attaques sont pour l'instant apparemment très peu nombreuses. En fait, note notre RFC, l'étude de la quantité de telles attaques est en soi un sujet de recherche. On ne sait pas vraiment dire pour l'instant s'il y a beaucoup de tricheurs (peut-être l'exemple Google cité plus haut mais il est très récent et pas assez étudié). On soupçonne évidemment que tout logiciel qui annonce qu'il va « optimiser le temps de téléchargement » risque fort d'y arriver en trichant...
TCP n'est pas le seul protocole de transport : certaines applications utilisent un protocole sans contrôle de congestion, comme UDP, et sont donc censées gérer la congestion elles-mêmes. Or, comme indiqué plus haut, ce n'est pas dans leur intérêt et on pourrait voir des abus, comme s'en inquiétait le RFC 3714. Cette question est presque un problème philosophique : une machine connectée à l'Internet est libre, elle peut notamment utiliser le protocole de transport de son choix. Envoyer des octets au maximum de ses possibilités, sans tenir compte de la congestion, n'est-ce pas abuser de cette liberté ? Comme les applications qui utilisent UDP sont souvent les plus gourmandes (vidéo en haute définition, par exemple), le RFC 8085 insistait sur la nécessité qu'elles se comportent gentiment et mettent en œuvre une forme de contrôle de congestion adaptée à leurs bsoins propres.
Les applications ont des exigences souvent très différentes vis-à-vis du réseau. Par exemple, les gros transferts de fichiers peuvent souvent s'exécuter en arrière-plan en profitant de la capacité du réseau quand il est libre, tout en réduisant sérieusement leur débit s'il ne l'est pas (section 3.6). Comment utiliser cette « élasticité » pour mieux gérer la congestion ? L'idée de marquer les paquets en fonction de ces exigences des applications n'est pas neuve (on la trouve déjà dans les bits ToS du RFC 791) mais il y a aussi des propositions plus récentes comme le RFC 3662. Mais en pratique, ces mécanismes ne sont guère utilisés. Actuellement, un groupe de travail de l'IETF, LEDBAT, travaille sur ce sujet (voir leur solution dans le RFC 6817).
Enfin, il reste les autres défis, ceux qui sont jugés relativement peu importants aujourd'hui et n'ont donc pas mérité une section dédiée. Ils sont regroupés dans la section 3.8. On y trouve, par exemple, la question de la mesure du RTT (bien des protocoles dépendent d'une bonne évaluation de ce temps). Aujourd'hui, seul l'émetteur d'un paquet a une bonne idée du RTT, en mesurant le moment où revient l'accusé de réception. Il n'existe malheureusement pas de moyen pour le receveur d'estimer le RTT, ce qui l'empêche d'ajuster son comportement. D'autre part, le RTT brut n'est pas forcément utilisable directement (par exemple parce qu'il varie brutalement dans le temps) et il est utile de se pencher sur des valeurs extrapolées, plus lisses, comme celles du RFC 2988.
Autre défi qui se posera un jour (sections 3.8.2) : le cas des logiciels bogués, qui réagissent mal lorsqu'on essaie une nouvelle technique, même si elle est parfaitement légale : beaucoup de machines sur Internet ont été programmées avec les pieds et plantent (ou même plantent leur voisin) si les données envoyées ne sont pas celles attendues (comme ce fut le cas lors de la fameuse crise de l'attribut BGP 99). Ainsi, même si on conçoit un nouvel algorithme génial de contrôle de la congestion, il sera peut-être difficile à déployer. C'est ce qui est arrivé à ECN, qui a connu bien des problèmes mais aussi au window scaling que plusieurs routeurs de bas de gamme rejettaient (c'est arrivé par exemple sur les boxes d'Alice). Y a-t-il une solution à ce problème ? Le RFC suggère une responsabilité au moins partielle de l'IETF en demandant que, à l'avenir, le comportement par défaut des équipements, face à des options ou des champs inconnus, soit mieux spécifié, pour que le vieux logiciel laisse toujours passer proprement les options récentes. Je pense personnellement que c'est une illusion : dans bien des cas, ces règles existaient et les logiciels bogués les ignorent, car leurs auteurs, dissimulés derrière leur anonymat (comment retrouver les responsables du code des AliceBox ?) ont ignoré complètement ces règles. La section 3.8.6 revient d'ailleurs sur le cas des équipements intermédiaires (middleboxes) qui sont souvent les pires (RFC 2775).
Comme déjà signalé plus haut, un défi général auquel est confronté le contrôle de congestion est celui de la sécurité (section 4). Par exemple (RFC 4948), les DoS sont possibles parce que l'Internet n'impose pas de contrôle de congestion (attention, le RFC parle de dDoS mais c'est à mon avis une erreur : si certains réseaux ont des mécanismes de contrôle de congestion obligatoires, aucun ne prévoit un mécanisme global, qui pourrait arrêter un botnet composé de milliers de zombies indépendants). De manière plus générale, aujourd'hui, le respect des règles qui empêchent l'Internet de s'écrouler sous le poids de la congestion est facultatif, laissé à la bonne volonté de chacun. Cela peut être vu comme un problème de sécurité. S'il existait des mécanismes de contrôle de la congestion qui résistent aux égoïstes prêts à tricher, ces mécanismes pourraient également être utilisés contre les DoS.
Voilà, désolé d'avoir été si long mais ce RFC est très riche et le champ des problèmes non encore résolus dans ce domaine de la congestion est immense. Étudiants futurs chercheurs, à vous de travailler à le défricher !
Merci à Pierre Beyssac pour sa relecture et ses commentaires.
L'article seul
Traduction de « host » (par opposition à « router »)
Première rédaction de cet article le 2 février 2011
Dernière mise à jour le 6 février 2011
L'architecture de l'Internet repose largement sur une distinction entre la machine ordinaire (le host, dans la langue de Ken Follett) et le routeur (router en anglais). Traduire le second est facile, mais le premier ? Hôte, machine, terminal, quoi d'autre ?
J'essaie en général, sur ce blog ou ailleurs, d'écrire en français
correct et cela veut dire d'utiliser avec précaution les termes en
anglais. Mais ce n'est pas toujours facile (ni d'ailleurs toujours
souhaitable) en informatique. Ainsi, il semble qu'il n'existe pas de
traduction correcte pour ce concept. Il est pourtant essentiel. Depuis
longtemps, l'Internet sépare le routeur, qui
fait passer des paquets IP d'une interface à
l'autre, et peut donc traiter des paquets dont l'adresse IP de destination n'est pas une des siennes, du
host qui, lui, n'accepte que les paquets qui lui
sont destinés (et les paquets de
diffusion). L'évolution ultérieure de
TCP/IP a toujours été d'accroître cette
différence. Ainsi, lorsque j'ai commencé sur
Unix, on se souvenait encore de l'époque où
Unix routait les paquets par défaut, dès qu'il détectait au moins deux
interfaces réseau (aujourd'hui, il faut l'activer explicitement, par
exemple avec la variable sysctl
inet.ipv6.conf.all.forwarding sur
Linux). Ensuite, il était courant que les
hosts écoutent sur le réseau avec le protocole
RIP (mis en œuvre dans le
démon routed, qui était
lancé d'autorité) pour apprendre les routes possibles.
Aujourd'hui, les documents normatifs sont même différents pour routeur et host : RFC 1812 pour le premier contre RFC 1122 et RFC 1123 pour le second.
Donc, comment traduire ce host. J'ai vu passer plusieurs traductions, sur lesquelles je sollicite l'avis de mes chers et érudits lecteurs :
- Hôte : traduction littérale de host et qui fait un peu bizarre, on pense plutôt à un dîner dans un château. Mais Jean-Marc Liotier me suggère que cela veut simplement dire que le host héberge des fonctions et services (pair BitTorrent, serveur HTTP, etc). Ce terme a l'avantage de coller à celui utilisé en Anglosaxonie, tout en promouvant l'accent circonflexe, trop souvent méprisé (merci à Olivier Marce pour s'en soucier).
- Terminal : bon terme, qui désigne bien le fait que le host est à une extrémité de la communication mais il fait un peu mainframe. On dirait une traduction inventée par les tenants du Minitel, puisque « Terminal » fait tout de suite penser à une machine dotée de capacités limitée, purement consommatrice, exactement ce que voudraient les partisans du Minitel.
- Ordinateur (proposé par Samuel C) : Pas mal pour un public non-technique (qui considère qu'un routeur n'est pas un ordinateur) mais factuellement inexact (le routeur est presque toujours un ordinateur, même si on peut envisager des routeurs qui seraient tellement spécialisés dans leur tâche qu'ils ne pourraient plus être appelés ainsi).
- Poste (proposé par Gaël Roualland) ou Station (proposé par Thomas Quinot) : original mais qu'est-ce que cela donne pour un engin mobile comme un phono sapiens ? Peut-on l'appeler « station » ? « Poste » est en tout cas amusant pour un poste téléphonique...
- Machine : bof, un routeur est une machine, aussi. Mais il semble que les non-experts n'utilisent pas ce mot pour un routeur.
- Machine hôte (suggestion de Zythom).
- Machine feuille (terme emprunté à la théorie des graphes, le routeur étant alors un nœud, et proposé par Thomas Quinot). Ou Machine d'extrémité ? Ou machine d'utilisateur (suggéré par Christophe Deleuze mais un host n'a pas forcément d'utilisateur humain derrière). Tous ces termes sont bien lourds...
- ETTD, un vieux sigle des télécoms, rappelé d'entre les morts par Thomas Quinot.
- Toujours dans la tradition télécomienne, Stéphane Bernard propose Terminaison (pensez à l'anatomie).
- Machine terminale : c'est ce que j'utilise en ce moment, je trouve que c'est un peu mieux que « terminal ».
Des avis ? Des termes pas encore proposés ?
L'article seul
Filtrage des caractères « dangereux » dans un formulaire
Première rédaction de cet article le 1 février 2011
Il y a un débat récurrent à l'intersection du monde de la sécurité informatique et de celui du développement Web sur la meilleure façon de traiter les caractères « dangereux » lorsqu'ils sont entrés par un utilisateur dans un formulaire de saisie. Faut-il interdire ces caractères dangereux, n'autoriser que les caractères sûrs ou bien... ?
Prenons l'exemple d'un formulaire Web où
l'utilisateur doit taper son nom. Le problème de départ est que certains caractères sont spéciaux pour certains
environnements. Ainsi, l'apostrophe ferme les
chaînes de caractères en SQL et, sans
précautions particulières, une apostrophe dans un nom peut mener à une
injection SQL, comme illustré dans
un dessin fameux de XKCD. De
même, les chevrons sont spéciaux en
HTML et peuvent être utilisés pour faire des
attaques XSS, si un méchant tape comme nom
<script>do_something();</script>.
Historiquement, la première défense contre ces attaques avait été
d'interdire les caractères « dangereux ». Si les données sont à un
moment ou à un autre transmises à un SGBD, on
interdit l'apostrophe. Si elles sont à un moment ou à un autre
affichées sur une page Web, on interdit les chevrons. Cette méthode
est aujourd'hui très critiquée et largement considérée comme peu sûre
car il est très difficile d'avoir une liste complète de tous les
caractères dangereux pour une application donnée. Une des premières
bogues du serveur HTTP Apache
était d'interdire la chaîne .. dans les noms de
fichiers demandés (pour empêcher qu'un attaquant ne remonte plus haut
que la racine du site Web) en oubliant que ces noms étaient traités
par un analyseur qui acceptait les guillemets et laissait donc passer
."."/repertoire/ou/je/veux/aller... Autre exemple, en SQL,
chaque SGBD rajoute quelques caractères spéciaux à la norme
SQL. Ainsi, MySQL considère les
guillemets comme caractères spéciaux au même
titre que l'apostrophe et il faut donc les filtrer également... Et
songez que le même nom entré dans un formulaire sera peut-être
transmis à un SGBD, sur une page Web, et à un shell Unix. La liste des caractères dangereux devient de plus en
plus difficile à établir.
Donc, l'approche « négative » (interdire les caractères dangereux) est très peu sûre. Elle est en outre trop violente dans certains cas. Ainsi, un nom comme « O'Reilly » ou « D'Alembert » est parfaitement légitime et il serait anormal de demander à ces personnes de changer de nom pour éviter les injections SQL... (Au passage, tout programmeur digne de ce nom devrait avoir lu l'excellent « Falsehoods Programmers Believe About Names » qui donne une idée de la variété des noms possibles pour les humains.)
Qu'en est-il de l'approche « positive », n'autoriser que des
caractères sûrs ? Alors que même le plus débutant des bricoleurs
PHP sait que l'approche négative est mauvaise,
l'approche positive est au contraire celle qui est généralement
recommandée. Par exemple, les fanas des expressions
rationnelles vont autoriser uniquement les noms
correspondant à l'expression [a-zA-Z]+ puis, après
quelques protestations d'utilisateurs nommés Robbe-Grillet ou Du Pont, passer à
[a-zA-Z -]+. Cette approche est très sûre, car elle
ne nécessite pas d'avoir une liste exhaustive des caractères
dangereux. Elle est souvent nommée input
sanitization (par exemple dans le dessin de XKCD, qui la
conseille implicitement).
Mais elle est aussi très restrictive. Pour les noms de famille pris comme exemple, elle interdirait O'Reilly. Et, si on l'autorise, on se retrouve avec le problème de départ, la présence d'un caractère dangereux dans le nom. Les seuls cas où cette méthode positive marche bien, ce sont ceux où les valeurs à entrer dans le formulaire sont contraintes par des règles syntaxiques strictes. Par exemple, s'il s'agit, non plus de noms quelconques mais d'identificateurs formatés selon une certaine grammaire, alors la méthode positive est acceptable, à condition que le programmeur suive réellement la grammaire en question. Or, bien des programmeurs ne prennent jamais la peine de lire les spécifications et font donc du code qui restreint arbitrairement les termes possibles, par exemple dans les adresses de courrier.
En pratique, la méthode positive se heurte donc vite à des
limites. C'est encore plus net si on prend en compte
Unicode. Car, si on a des utilisateurs nommés
Skłodowska ou Liétard, ASCII ne suffit
plus. On peut passer aux expressions Unicode (si le moteur
d'expressions rationnelles que vous utilisez les gèrent, ce qui, en
2011, devrait être la règle) et on écrit quelque chose comme
[\p{L}\p{Zs}-']+ (où p{L} est
l'ensemble des lettres). Mais la liste des caractères ayant la
propriété L (pour « lettre ») est tellement longue (la grande majorité
des caractères Unicode sont des lettres, plus de 100 000 dans la
version 6) qu'il serait
imprudent de jurer qu'il n'y en a pas un dans le lot qui soit
dangereux dans certaines circonstances... (Déjà, dans mon expression,
il y a l'apostrophe.)
Que reste-t-il comme solution ? Elle est plus difficile et peut dans certains cas être moins sûre mais la seule méthode correcte est de ne pas filtrer en entrée mais en sortie. À part pour les cas où on peut s'appuyer sur une norme précise pour définir un jeu de caractères autorisé et où ce jeu ne comporte aucun caractère dangereux pour aucun des logiciels qu'on utilisera, c'est la bonne approche. Il faut donc accepter tout ce qui correspond à la sémantique du champ en question, puis contrôler l'utilisation de ces données au moment de l'exportation (vers SQL, vers PDF, vers LaTeX, vers HTML, etc). C'est une simple application du principe de robustesse (« soyez tolérant dans ce que vous acceptez et prudent dans ce que vous envoyez »).
Pour faciliter la tâche du programmeur, et pour diminuer les risques d'oubli, il est bien sûr recommandé de se servir pour ce contrôle de mécanismes de gabarits comme les requêtes préparées en SQL ou comme des gabarits XML, par exemple TAL.
Merci à Pierre Beyssac, Ollivier Robert et Bertrand Petit pour leurs conseils avisés.
L'article seul
Coupure de l'Internet en Égypte
Première rédaction de cet article le 28 janvier 2011
Dernière mise à jour le 2 février 2011
Quelques jours après que je publie un article posant la question « Peut-on éteindre l'Internet », le dictateur Moubarak a décidé d'illustrer un des points de l'article : oui, on peut couper l'Internet localement, pendant un temps relativement long (au moins plusieurs jours). L'Égypte a donc été presque totalement privée d'Internet du 28 janvier au 2 février.
Comme d'habitude lors de ce genre d'événements, on ne sait pas
grand'chose, ce qui n'empêche pas les informations erronées. Ainsi, un
article de la BBC explique que la coupure
s'est faite sur la base du DNS, ce qu'aucun
fait observé ne permet de dire. Bien au contraire, le phénomène, vu
de l'extérieur, montre que la censure a frappé plus bas, du côté des
couches 1 à 3. En effet, même de l'extérieur,
alors qu'on n'a pas besoin du DNS, on ne va pas très loin. Ici, depuis
le réseau de Verizon aux États-Unis, en visant
un des serveurs DNS de
.eg :
% traceroute FRCU.EUN.eg traceroute to FRCU.EUN.eg (193.227.1.1), 30 hops max, 60 byte packets 1 192.sub-66-174-112.myvzw.com (66.174.112.192) 66.711 ms 67.259 ms 67.439 ms 2 66.174.112.255 (66.174.112.255) 76.192 ms 76.588 ms 76.931 ms 3 81.sub-66-174-13.myvzw.com (66.174.13.81) 77.121 ms 85.802 ms 86.028 ms 4 98.sub-66-174-12.myvzw.com (66.174.12.98) 89.049 ms 86.694 ms 113.811 ms 5 90.sub-66-174-9.myvzw.com (66.174.9.90) 116.961 ms 116.436 ms 113.944 ms 6 87.sub-66-174-9.myvzw.com (66.174.9.87) 123.913 ms 73.061 ms 70.609 ms 7 253.sub-69-83-16.myvzw.com (69.83.16.253) 84.492 ms 84.283 ms 93.580 ms 8 xe-7-1-0.edge3.Washington1.Level3.net (4.59.144.25) 94.144 ms !N 93.805 ms !N 94.264 ms !N
Le !N signifiant Network Unreachable et, comme on n'a pas quitté les États-Unis, on voit que les routeurs de Level 3, privés d'informations BGP, ne savent plus où envoyer les paquets. Un coup d'œil sur le service RIS du RIPE-NCC le confirme : le préfixe n'est plus du tout visible (cela va et ça vient : il est parfois à nouveau annoncé, puis supprimé).
Pour une présentation générale du problème en français, l'article de 20 minutes est satisfaisant. Un peu plus technique, celui de Rue89. Quelles sont les bonnes sources pour les détails techniques ? Les habituelles, le blog de Renesys, ExtraExploit, les RIPE labs et BGPmon. Ces articles ne sont pas forcément d'accord entre eux. Par exemple, le nombre de préfixes IP égyptiens varie de 2900 à 3500 mais cet écart est normal : il n'y a pas de moyen simple et fiable de décider si tel préfixe est en Égypte ou ailleurs, le routage dans l'Internet n'étant pas basé sur la nationalité. Un certain nombre des « préfixes égyptiens qui fonctionnent toujours » sont donc probablement situés dans d'autres pays. À noter également qu'il n'y a que 129 préfixes égyptiens alloués par AfriNIC mais un préfixe n'est pas forcément égal à une route, en raison, entre autres, de la désagrégation, de l'utilisation de préfixes alloués par un autre RIR, etc.
Autres intéressants articles sur la coupure égyptienne, les statistiques BGP du RIPE, et des graphes par le même RIPE-NCC.
Comme l'a noté Renesys, le réseau de
l'opérateur NOOR semble encore largement accessible. Contrairement à ce que j'avais pu écrire au début, il semblerait que les liaisons physiques sont toujours là. On peut voir les
préfixes qu'il annonce sur un looking
glass comme http://www.robtex.com/as/as20928.html#bgp ou bien https://www.dan.me.uk/bgplookup?asn=20928&include_downstream=on. Cela
permet de trouver assez facilement une adresse IP égyptienne qui
répond toujours par exemple la 217.139.5.1, qui répond à
ping et à traceroute :
traceroute to 217.139.5.1 (217.139.5.1), 30 hops max, 60 byte packets 1 192.sub-66-174-112.myvzw.com (66.174.112.192) 173.370 ms 173.406 ms 173.519 ms 2 66.174.112.255 (66.174.112.255) 173.607 ms 175.010 ms 176.161 ms 3 81.sub-66-174-13.myvzw.com (66.174.13.81) 315.883 ms 316.606 ms 316.478 ms 4 98.sub-66-174-12.myvzw.com (66.174.12.98) 317.190 ms 316.777 ms 318.488 ms 5 * 90.sub-66-174-9.myvzw.com (66.174.9.90) 320.371 ms * 6 87.sub-66-174-9.myvzw.com (66.174.9.87) 319.318 ms 327.311 ms 337.118 ms 7 253.sub-69-83-16.myvzw.com (69.83.16.253) 452.587 ms 301.666 ms 307.929 ms 8 xe-7-1-0.edge3.Washington1.Level3.net (4.59.144.25) 308.167 ms 280.718 ms 280.341 ms 9 vlan80.csw3.Washington1.Level3.net (4.69.149.190) 221.054 ms 221.299 ms 105.477 ms 10 ae-82-82.ebr2.Washington1.Level3.net (4.69.134.153) 105.679 ms 217.237 ms 216.963 ms 11 ae-4-4.ebr2.Newark1.Level3.net (4.69.132.102) 218.182 ms 217.496 ms 218.182 ms 12 ae-23-52.car3.Newark1.Level3.net (4.68.99.39) 218.974 ms 218.595 ms 218.196 ms 13 TELECOM-ITA.car3.Newark1.Level3.net (4.71.148.10) 219.340 ms 218.955 ms 235.213 ms 14 ge15-0.palermo6.pal.seabone.net (195.22.218.211) 475.708 ms 472.234 ms 472.138 ms 15 noor.palermo6.pal.seabone.net (195.22.198.34) 432.727 ms 431.700 ms 431.638 ms 16 * * * 17 217.139.5.1 (217.139.5.1) 431.051 ms 431.587 ms 431.142 ms
(Seabone est un service de Telecom Italia, qui gête entre autres un câble méditerranéen et on voit qu'on a pu aller jusqu'à Palerme, puis en Égypte.)
J'avais parlé du domaine de tête
.eg. Fonctionne t-il
toujours ? Oui, car un seul de ses serveurs est situé en Égypte. Les
deux autres, aux États-Unis et en Autriche, continuent à répondre, bonne illustration de la résilience
du DNS :
% check_soa eg There was no response from FRCU.EUN.eg RIP.PSG.COM has serial number 2010100421 NS5.UNIVIE.AC.AT has serial number 2010100421
Évidemment, sans route pour acheminer les paquets ensuite, cela n'a que peu d'intérêt...
Quelle leçon à en tirer sur la résilience de l'Internet ? (Voir aussi l'interview de Benjamin Bayart sur PublicSénat.) D'abord, que l'Égypte a peu d'opérateurs internationaux et peu de liens physiques vers l'extérieur. Cela facilite la censure (juste quelques coups de téléphone à donner) et cela augmente également la vulnérabilité de l'Internet égyptien aux coupures accidentelles comme l'avait montré la grande panne de 2008. Aujourd'hui, la situation n'a pas trop changé (voir une jolie carte) et on peut se demander qu'elle est la part de la pauvreté (qui empêche de multiplier les liens), de la géopolitique (qui rend peu envisageable des passages par la Libye ou par Israël), de l'incompétence ou du calcul cynique (moins de liens égal un réseau plus contrôlable).
{kind=link}
Et à l'intérieur de l'Égypte, que se passe t-il ? On n'a pas
beaucoup de témoignage pour l'instant. La question de savoir si
l'Internet d'un
pays peut fonctionner en autonomie, déconnecté de l'Internet mondial,
a déjà fait l'objet de plusieurs discussions. Ici, pour ne prendre que
le cas du DNS, l'Égypte a deux serveurs DNS
racine au Caire
(les serveurs F et J, à noter que, au moins pour F, son
administrateur n'y a plus accès depuis l'extérieur), ainsi qu'un
serveur de .com donc il
est possible qu'un Internet égyptien isolé puisse continuer à
fonctionner.
J'ai reçu un témoignage d'un français installé en Égypte et qui connaît un peu les réseaux : il semble bien que la coupure touchait aussi l'intérieur. Je le cite « Le gouvernement a coupé plusieurs choses, en plusieurs jours. Dans l'ordre : les SMS sur les mobiles ne sont plus passés, puis les communications voix, puis la 3G. Le gouvernement espérait que cela diminuerait les manifs mais devant la foule dans les manifs, le téléphone mobile a été rétabli. Actuellement, on peut m'appeler sans trop de problème, mais je ne peux plus appeler vers l'étranger. Apparemment les communications intérieures fonctionnent. Ensuite seulement, ils ont coupé l'accès Internet. Au bureau, on a l'ADSL. Le réseau "physique" était toujours actif (je voyais la diode ADSL normalement) mais sur l'ordinateur, je n'accédais à rien : pas de sites étrangers et même pas de sites locaux. Tout était coupé. »
Et la reprise ? Elle s'est faite le 2 février, vers 1100 UTC. On trouve des observations sur cette reprise en :
- L'analyse de BGPmon,
- Les statistiques du RIPE,
- Celle
de Renesys. Cet article, et le précedent, pointent le retard du
réseau académique égyptien à revenir, alors qu'il héberge le serveur
de noms primaire de
.EG.
Une des raisons pour lesquelles la dictature égyptienne a rétabli la connexion à l'Internet est peut-être de pure finance : selon un article du Monde, citant l'OCDE, cette coupure aurait coûté très cher à l'économie égyptienne.
L'article seul
RFC 6079: HIP BONE: Host Identity Protocol (HIP) Based Overlay Networking Environment
Date de publication du RFC : Janvier 2011
Auteur(s) du RFC : G. Camarillo, P. Nikander, J. Hautakorpi, A. Keranen (Ericsson), A. Johnston (Avaya)
Expérimental
Réalisé dans le cadre du groupe de travail IETF hip
Première rédaction de cet article le 25 janvier 2011
Voici un RFC bien abstrait, qui normalise un mécanisme pour construire des réseaux virtuels (overlays) en utilisant le protocole HIP. Un de ces premiers réseaux virtuels pourrait être celui du protocole RELOAD, utilisé pour faire du SIP pair-à-pair.
Le nom de ces réseaux virtuels, HIP bone, est un jeu de mots sur l'os coxal (hip bone en anglais) et une allusion à d'autres réseaux virtuels comme le défunt 6bone. Mais le but est très différent : IPv6 ne peut pas passer sur l'infrastructure IPv4 du vieil Internet et doit donc être « tunnelé » au dessus d'IPv4, l'ensemble de ces tunnels formant le 6bone. Au contraire, HIP (RFC 7401) étant un protocole entièrement situé dans les machines terminales, il n'a pas besoin de tunnels pour marcher. On peut expérimenter avec HIP dès aujourd'hui. Alors, à quoi sert un HIP bone ? L'idée est de faciliter le développement de services pair-à-pair, d'utiliser HIP pour construire un réseau virtuel de machines HIP, les autres fonctions utiles (comme le stockage des données) étant fournies par des protocoles pair-à-pair situés au dessus (nommés peer protocol dans le RFC). Ces protocoles seront donc déchargés, grâce à HIP, de certaines des tâches de bas niveau.
HIP est un protocole de séparation du localisateur et de l'identificateur. Le routage dans le HIP bone se fait sur l'identificateur et c'est HIP qui se charge de le mettre en correspondance avec les localisateurs sous-jacents, le routage dans l'Internet se faisant sur la base de l'adresse IP (qui, en HIP, est réduite au rôle de localisateur). Si vous ne connaissez pas HIP, la section 3 du RFC sert de rappel.
Le HIP bone lui-même est introduit en section 4. Un réseau virtuel bâti au dessus d'un réseau réel comme l'Internet dépend d'un mécanisme de maintien du réseau (table de routage, tests de connectivité, pairs qui arrivent et qui repartent, etc), d'un mécanisme de stockage et de récupération de données (par exemple une DHT), et d'un mécanisme de gestion des connexions (se connecter à un pair, échanger des messages). Dans le HIP bone, HIP ne fournit que ce dernier service. L'application qui utilisera le HIP bone pourra parler directement à HIP pour certaines fonctions et au peer protocol pour les autres (cf. la figure 3 du RFC).
On l'a dit, notre RFC ne fait que spécifier un cadre assez
général. Une bonne partie devra être faite dans le peer
protocol et la section 5 du RFC rappelle ce qui relèvera de
la responsabilité dudit protocole. Par exemple, il existe actuellement
un Internet-Draft décrivant
RELOAD (REsource LOcation And Disovery),
draft-ietf-p2psip-base,
et un autre qui décrit comment bâtir un réseau virtuel pour RELOAD au
dessus de HIP, draft-ietf-hip-reload-instance.
Ainsi (section 5.1), c'est au peer protocol de
gérer le délicat problème du recrutement (qui peut entrer dans le
réseau virtuel). Pour aider ces protocoles situés au dessus d'un
HIP bone, la section 6 liste quelques paramètres
utiles qui seront mis dans les messages HIP comme le nouvel
OVERLAY_ID, qui identifiera un réseau virtuel
donné (car une machine HIP sera peut-être membre de plusieurs réseaux virtuels).
Voilà, une fois ce RFC 6079 lu et assimilé, il ne vous reste plus qu'à concevoir votre réseau virtuel à vous ⌣.
L'article seul
RFC 6092: Recommended Simple Security Capabilities in Customer Premises Equipment for Providing Residential IPv6 Internet Service
Date de publication du RFC : Janvier 2011
Auteur(s) du RFC : J. Woodyatt (Apple)
Pour information
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 25 janvier 2011
Ah, la sécurité informatique... Sujet de polémiques sans fin, à l'IETF comme ailleurs. Faut-il des pare-feux ? Faut-il protéger le PC de M. Michu par défaut ? Vaut-il mieux la liberté ou bien la sécurité (réponse en un paragraphe, de préférence) ? Il est très difficile de réunir un consensus sur ce thème et, après avoir essayé, le groupe de travail v6ops de l'IETF a décidé de produire uniquement des recommandations sur la configuration d'un pare-feu pour les CPE (les « boxes ») IPv6, sans s'engager sur la question de savoir s'il fallait un pare-feu ou pas...
Le CPE (Customer Premises Equipment) est le petit boîtier qui connecte le réseau du client résidentiel (M. Michu) au FAI. Parfois fourni par le FAI, parfois acheté en supermarché, il est typiquement laissé tel quel, sans changement de la configuration, et sa configuration par défaut a donc une grande importance. Aujourd'hui, où le principal protocole de l'Internet est IPv4, le CPE a en général une configuration par défaut qui inclut l'allocation d'adresses IP privées (RFC 1918) aux machines du réseau local, et une connexion au FAI, par laquelle arrivera une adresse IP publique. Certaines personnes croient que le fait que les machines « internes » ont une adresse IP privée leur assure une certaine sécurité. C'est largement faux mais, ce qui est sûr, c'est que le mécanisme de traduction d'adresses entre l'intérieur et l'extérieur empêche l'ouverture de connexion à la demande des machines extérieures. Si une imprimante a un serveur HTTP pour sa configuration, le monde extérieur ne peut pas s'y connecter par des moyens normaux (il existe plusieurs moyens « anormaux » comme le changement DNS, et c'est pour cela que le bénéfice en terme de sécurité est douteux). Parfois, on est content de ce barrage (qui empêche les méchants barbares de se connecter à notre innocente imprimante, qui n'est probablement pas configurée de manière très sûre, avec son mot de passe d'usine jamais changé), parfois on le regrette (quand le transfert de fichiers en pair-à-pair échoue ou bien quand un coup de téléphone SIP s'établit mais que la voix ne passe pas). Ce filtrage de fait peut en effet frapper aussi bien les applications légitimes que les autres.
Et en IPv6 ? Le NAT s'est imposé pour IPv4 car, de toute façon, vu le manque d'adresses IPv4, il n'y avait pas le choix. Mais en IPv6, on revient à l'abondance. Chaque machine du réseau local a une adresse IP unique au niveau mondial et redevient donc contactable. La sécurité largement illusoire que fournissait le NAT disparait. Que faut-il mettre à la place ? Un pare-feu ? Et, si oui, configuré comment à sa sortie d'usine ? (Rappelez-vous que M. Michu ne changera probablement jamais la configuration. La règle d'ergonomie que rappelle notre RFC est que le réglage de la sécurité dans le CPE doit être facile à faire et encore plus facile à ignorer.)
Notre RFC 6092 ne répond pas à toutes les questions sur la sécurité d'IPv6. Il vise le cas où on veut fournir une sécurité simple dans un environnement simple, celui de l'accès Internet résidentiel. Les cas plus complexes, par exemple celui d'un réseau d'une entreprise, avec des ingénieurs compétents, sont délibérement laissés de côté (section 1 et RFC 4864). Ici, ce RFC propose un compromis jugé raisonnable dans ce contexte, entre la sécurité et le respect du principe de connexion de bout en bout, qui est à la base du succès d'Internet.
Chaque virgule de ce RFC a été négociée avec acharnement. Ainsi, le statut de ce document est « pour information » mais il utilise le vocabulaire normatif du RFC 2119, tout en précisant en section 1.2 que c'est uniquement pour la précision du discours.
La section 2 du RFC décrit le modèle de réseau considéré. Le CPE est un engin simple (on ne peut donc pas lui demander des services complexes), routeur par défaut du réseau local (RFC 8504), et n'ayant typiquement qu'une seule interface avec l'extérieur, celle qui mène au FAI, plus un petit nombre d'interfaces vers l'intérieur (par exemple Ethernet et WiFi). Pour ce qui concerne la sécurité, leur vision du monde est également très simple : un univers rassurant et civilisé du côté du réseau local, un monde hostile et dangereux de l'autre côté. Le RFC 4864 résume les services de sécurité attendus : filtrer les paquets clairement anormaux (comme les paquets venant de l'extérieur mais prétendant avoir une adresse IP source interne, ou comme les paquets martiens du RFC 4949), ne pas permettre de paquets entrants sans qu'une « connexion » ait d'abord été initiée de l'interieur, permettre des exceptions manuellement configurées (sur la base des adresses IP et ports source). En IPv4, un routeur NAT fournissait plusieurs de ces services sans même y penser, comme effet de bord de la traduction d'adresses (qui, en IPv4, impose de garder un état, donc de se souvenir des connexions ouvertes). En IPv6, routage et filtrage sont nettement séparés. Le RFC 4864 proposait donc de répondre au besoin des utilisateurs (qui s'attendent au même niveau de protection en IPv4 et IPv6) en ayant par défaut un pare-feu à état, qui bloque les connexions entrantes.
Il faut noter que certaines applications voudraient bien autoriser les connexions entrantes, au moins depuis certaines adresses. Il n'existe pas actuellement de mécanisme normalisé pour qu'une application puisse dire au CPE « je veux bien recevoir des connexions sur mon port 443, s'il te plait, laisse-les passer ». Plusieurs projets ont été discutés à l'IETF mais sans résultat consensuel pour l'instant.
Autre point à garder en tête, le CPE est un routeur et doit donc se comporter comme tel (RFC 8504, sur les obligations des routeurs). Il doit également (section 2.1) bloquer certains paquets dangereux, comme les usurpateurs ou les martiens cités plus haut, ainsi que ceux ayant l'en-tête de routage 0 (RFC 5095). En revanche, le CPE ne doit pas empêcher le développement de nouveaux services et applications sur l'Internet. Il ne faut donc pas qu'il bloque aveuglément les paquets IPv6 ayant des en-têtes de sécurité ou de routage.
Au niveau 3, le CPE va devoir bloquer par défaut les tunnels, sauf ceux d'IPsec (car il serait paradoxal qu'un pare-feu, censé améliorer la sécurité, bloque par défaut un protocole qui permet de sécuriser le trafic). Pour la même raison, HIP doit être autorisé.
Et au niveau 4 (section 2.3) ? Le principe posé est celui d'une fermeture par défaut : pas de paquets TCP ou UDP entrants s'ils n'ont pas été sollicités de l'intérieur, par une application se connectant à l'extérieur. C'est cette simple règle, qui prend juste une phrase du RFC, qui a suscité le plus de tempêtes de discussions autour de ce document, puisqu'elle revient à renoncer, par écrit, au principe de la connectivité de bout en bout.
La section 3 du RFC transforme ensuite ces principes généraux en recommandations concrètes. Si on est pressé, on peut lire à la place la section 4, qui est un résumé de ces recommandations. Les recommandations sont identifiées par un numéro unique et je vais reprendre ici la syntaxe du RFC, qui les désigne par REC-N où N est le numéro. Dans ses recommandations, cette section s'appuie sur la classification des paquets et des flots (ensemble de paquets liés à la même « connexion ») :
- Un paquet va vers l'extérieur s'il est issu d'une machine interne, à destination d'une machine externe et vers l'intérieur si c'est le contraire.
- Pour les flots, c'est plus complexe. Si une machine interne fait une connexion TCP vers le port 80 d'une machine externe, la majorité des octets sera de l'extérieur (le serveur HTTP) vers l'intérieur alors qu'on considérerait plutôt cette connexion comme allant vers l'extérieur. La définition d'un flot allant vers l'extérieur considère donc que c'est le premier paquet qui détermine la direction du flot. Notons que c'est très simpliste et que cette définition ne couvre pas des cas comme SIP/RTP où l'appelant peut demander à recevoir des paquets sur une toute autre « connexion ».
La section 3.1 traite ensuite du cas du filtrage le plus simple, le filtrage sans état, où chaque paquet est examiné uniquement pour son contenu, indépendamment de tout contexte. Il ne s'agit donc que de filtrage de paquets, sans considérer les flots. Ce filtrage sans état devrait éliminer les usurpateurs (REC-5, REC-6, RFC 2827 et RFC 3704). De même, les adresses IPv6 appartenant à des services obsolètes (RFC 3879) ou non admises sur l'Internet public (RFC 6890) devraient être rejetées (REC-3). Les requêtes DNS de l'extérieur devraient être rejetées (REC-8).
Les sections 3.2 et 3.3 traitent ensuite du cas du filtrage avec état, où le CPE filtrant se souvient des paquets précédents et peut donc reconstituer des flots. Le cas facile (section 3.3) est celui où le protocole de couche 4 a une sémantique de connexion. Le pare-feu peut alors savoir exactement quand la connexion est ouverte et quand elle se termine (ce qui permet de libérer les ressources allouées pour le filtrage). Parmi les protocoles dans ce cas, TCP, SCTP mais aussi tous les futurs protocoles de transport à connexion. Un problème typique des pare-feux avec état est en effet qu'ils regardent l'établissement et la fermeture de la connexion et que cela implique qu'ils connaissent le protocole de transport utilisé (beaucoup de pare-feux de bas de gamme ne connaissent pas SCTP et le bloquent donc aveuglément, ce qui rend difficile le déploiement de ce « nouveau » protocole).
Commençons par TCP, le cas le plus simple (section 3.3.1). REC-31 demande que les CPE qui gèrent TCP le gèrent complètement et de manière conforme à la machine à états du RFC 793, y compris dans ses aspects moins connus comme l'ouverture simultanée (les deux pairs envoyant un SYN presque en même temps). C'est quand même un comble qu'il faille un RFC pour dire que les autres RFC doivent être respectés et cela donne une idée des problèmes auquel est confronté l'Internet aujourd'hui. Afin de maximiser les chances qu'une application nouvelle fonctionne correctement, REC-33 demande que le filtrage ait un comportement indépendant de la destination, c'est-à-dire que l'adresse de destination ne soit pas prise en compte pour mettre en correspondance un paquet avec un flot. Le comportement dépendant de l'adresse peut être adopté si on souhaite contrôler davantage. Voir le RFC 5382 pour plus de détails sur la gestion de TCP dans un CPE.
Autre demande de notre RFC qui ne correspond pas à l'état actuel de la plupart des CPE : REC-34 exige que, par défaut, les paquets TCP SYN entrants bloqués suscitent l'envoi d'un message ICMP Destination unreachable. Aujourd'hui, il est probable que la grande majorité des CPE avalent silencieusement le paquet TCP, sans prévenir l'envoyeur.
Et les délais de garde ? A priori, pour les protocoles orientés
connexion comme TCP, ils ne sont pas nécessaires, puisque la fin d'une
connexion sera toujours explicite, avec les paquets FIN (ou
RST). Mais, en pratique, le CPE peut rater la fin d'une connexion (par
exemple parce qu'un des pairs TCP a été éteint et n'a donc pas pu
terminer proprement la connexion). Pour gérer ce cas, tous les
équipements intermédiaires qui gèrent les états des connexions TCP
ajoutent un délai de garde et, si aucun paquet n'est passé pendant ce
délai, ils suppriment l'état, ce qui empêchera les paquets ultérieurs
de passer. C'est souvent un problème pour les applications comme
SSH, qui peuvent laisser passer des heures sans
envoyer de paquets (avec OpenSSH, la directive
ServerAliveInterval permet d'envoyer des paquets
pour maintenir la connexion ouverte). Il existe aussi des mécanismes
pour envoyer des paquets TCP sans réel contenu, uniquement chargés de
maintenir une connexion ouverte (RFC 1122, qui
spécifie une durée par défaut de deux heures, bien trop longue pour la
plupart des CPE). REC-35 demande donc un délai de garde minimal par
défaut de
deux heures et quatre minutes (voir le RFC 5382 pour les
raisons de ce choix), bien plus long que celui des CPE d'aujourd'hui.
Comme TCP a besoin d'ICMP (notamment pour découvrir la MTU du chemin), REC-36 rappelle que, si un équipement transmet du TCP, il doit aussi transmettre les messages ICMP essentiels, Destination unreachable et Packet too big. A contrario (REC-37), le passage d'un paquet ICMP ne doit pas entraîner le CPE à supprimer les états des connexions TCP (décider, lors de la réception d'un paquet ICMP, si on coupe la connexion TCP associée est un processus complexe, voir le RFC 5927).
TCP est très répandu et relativement bien connu. On peut espérer (même si c'est illusoire) que tous les CPE le gèrent bien. Mais qu'en est-il de SCTP, son concurrent bien moins connu (section 3.3.2) ? D'abord, il faut noter que SCTP a des particularités, notamment le fait qu'une même connexion puisse utiliser plusieurs adresses IP. Cela rend le modèle simple de notre RFC 6092 inapplicable puisqu'il faudrait que les différents routeurs qui voient passer les paquets d'une même connexion se coordonnent (ce qui ne serait pas « simple »). Toutefois, les applications SCTP qui n'exploitent pas toutes les fonctions de ce protocole peuvent quand même s'en tirer. Si tous les paquets passent au même endroit (un seul routeur) et que cet endroit suit le RFC 4960, comme indiqué par REC-38, alors tout peut bien se passer. En pratique, SCTP souffre bien plus du fait que beaucoup de CPE bloquent tous les protocoles inconnus, ce qui signifie en général tous ceux ayant été créés il y a moins de vingt ans (les boxes sont très conservatrices).
La section 3.2, elle, s'occupe du cas moins facile où, contrairement à ce qui se passe avec TCP ou SCTP, il n'y a pas de connexion explicite. Le CPE ne peut pas savoir quand une « session » se termine. La seule solution générale est d'attendre un certain temps après le dernier paquet vu. Autrement, il faut que le CPE connaisse le protocole applicatif utilisé (et sache ainsi, par exemple, qu'une « session » DNS, c'est typiquement seulement deux datagrammes UDP, un de requête et un de réponse). La section 3.2.2 avertit que cette méthode ne doit pas mener à une interdiction de fait des applications nouvelles, donc inconnues du CPE.
Pour ICMPv6, les recommandations concernant son filtrage figurent dans le RFC 4890 (pour le résumer : il ne faut surtout pas filtrer aveuglément la totalité d'ICMP). La règle ajoutée par notre RFC 6092 est de vérifier, avant de faire suivre un paquet ICMP, que les données de la couche transport qu'il contient correspondent à une session en cours (section 3.2.1).
Pour les autres protocoles, afin de maximiser les chances qu'une application nouvelle ou un protocole de couche 4 nouveau fonctionnent correctement, la section 3.2.2 recommande fortement que le filtrage ait un comportement indépendant de la destination (REC-11, endpoint independent filter), c'est-à-dire que l'adresse de destination ne soit pas prise en compte pour mettre en correspondance un paquet avec un flot. Le comportement dépendant de l'adresse peut être adopté si on souhaite une sécurité plus fasciste, peut-être via une option de configuration du pare-feu.
Le cas spécifique d'UDP (rappelons qu'il existe d'autres protocoles de transport que TCP et UDP) est traité en section 3.2.3. Le RFC 4787 donnait déjà des règles pour le comportement attendu d'un routeur NAT avec UDP. Ces règles s'appliquent toujours dans le cas de notre CPE IPv6. Par exemple, REC-14 demande un délai de garde minimum, avant de détruire l'état associé à un flot, de deux minutes (moins si les ports sont dans la zone bien connue, cf. REC-15). Beaucoup d'applications avaient en effet souffert de CPE qui détruisaient l'état trop tôt, empêchant les paquets ultérieurs de passer.
Et IPsec ? Il est en section 3.2.4. Comme son utilisation permet d'améliorer sérieusement la sécurité de l'Internet, il serait paradoxal qu'un équipement assurant des fonctions de sécurité le bloque. REC-21 et REC-22 demandent donc qu'IPsec passe par défaut. Même chose pour HIP avec REC-26. Notons que de telles recommandations laissent de côté le cas de futurs protocoles de sécurité, dont le déploiement risque d'être bloqué par un CPE qui interdit trop de choses par défaut.
Enfin, les applications de gestion font l'objet de la section 3.5. La plupart des CPE ne verront jamais leur configuration par défaut modifiée et, si c'est le cas, celui ou celle qui change la configuration ne sera en général pas un expert. Le RFC ne donne pas plus de détails, à part l'insistance sur le fait que ces fonctions de configuration ne doivent pas être accessibles depuis l'Internet, seulement depuis le réseau local.
On l'a vu, le comportement par défaut d'un CPE qui suit ce RFC est
d'interdire les connexions entrantes. Or, certaines applications
souhaiteraient pouvoir en recevoir (section 3.4), soit parce qu'elle
jouent un rôle de serveur, soit parce que le fonctionnement du
protocole sous-jacent implique que l'application se mette en écoute
(c'est le cas de SIP). Il n'existe pas de
mécanisme normalisé pour l'application de dire au pare-feu « laisse
entrer les paquets RTP en provenance de
2001:db8:1010::47:1 », même s'il existe des
solutions non-standard comme UPnP. Avec les CPE
traditionnels, gérant de l'IPv4 NATé, les applications se servent
typiquement de STUN pour « ouvrir
(indirectement) une brèche »
dans le pare-feu. Et en IPv6 ? Même s'il n'y a pas de NAT, les
recommandations de notre RFC 6092 ont le même résultat
d'empêcher les connexions entrantes. L'idéal serait un mécanisme
standard équivalent à UPnP ou à des propositions comme
l'Application Listener Discovery Protocol. Mais il n'existe pas et l'état actuel des
discussions à l'IETF ne permet pas de penser qu'il apparaitra bientôt,
bien que des propositions existent comme une extension des RFC 5189 ou RFC 4080.
En attendant, les recommendations pour les CPE sont d'offrir un mécanisme pour permettre aux applications de solliciter l'ouverture du pare-feu (REC-48) et de permettre, via une action de l'administrateur, de couper le pare-feu ou de changer sa politique pour laisser entrer les connexions (REC-49). Bien sûr, ce dernier mode impose que les machines sur le réseau local soient proprement sécurisées (le RFC utilise une formulation plus restrictive, en demandant que les machines aient leur propre pare-feu, alors que ce n'est qu'une solution de sécurisation parmi d'autres) mais il est nécessaire que cette option soit présente, car c'est la seule qui permet l'accès à toutes les potentialités de l'Internet. Sans elle, le CPE n'est pas un point d'accès à l'Internet mais un Minitel amélioré.
La section 7, consacrée spécifiquement à la sécurité, prend de la hauteur et rappelle quelques bons principes de sécurité. Elle note ainsi que le RFC ne prétend pas que la politique par défaut proposée (qu'on peut résumer par « zéro connexion entrante par défaut ») soit effective, simplement qu'elle assure le même niveau de sécurité ou d'insécurité que celui fourni par un routeur NAT d'aujourd'hui. Comme le rappelle le RFC 2993, cette politique peut même diminuer la sécurité (par exemple par l'« illusion du limes », ce qui fait qu'on se fie aveuglément à la protection qu'elle offre et qu'on oublie de sécuriser l'intérieur). Les bonnes pratiques de sécurité, et des protections comme celles recommandées dans le RFC 4864 sont donc toujours d'actualité. Après tout, les attaques ne viennent pas que de l'extérieur. Même quand l'attaquant humain n'a pas accès au réseau local, il peut trouver un moyen (via du malware, par exemple) de l'attaquer de l'intérieur.
Cette section sur la sécurité note que la grande majorité des ordinateurs dont le système d'exploitation gère IPv6 ont également un mécanisme de filtrage compatible IPv6. Ce n'est toutefois pas forcément le cas pour les autres machines, comme les imprimantes.
Petite exception au principe comme quoi la sécurité d'un réseau situé derrière un CPE IPv6 conforme à ce RFC est à peu près la même que celle d'un réseau NATé : IPsec n'est pas, par défaut, autorisé par le CPE typique actuel. De toute façon, le dernier paragraphe du RFC, écrit dans le pur style juridique états-unien, note bien que l'IETF n'est responsable de rien et ne garantit pas que les règles énoncées dans ce RFC améliorent la sécurité... C'est une innovation dans un RFC : verra-t-on le RFC sur TCP dire « L'IETF ne promet pas que vous échapperez à la congestion si vous suivez cet algorithme » et celui sur SMTP affirmera-t-il « Attention, utiliser le courrier vous expose au spam » ?
L'article seul
Peut-on éteindre l'Internet ?
Première rédaction de cet article le 23 janvier 2011
Ce jeudi 27 janvier, l'Epitech organisait une intéressante conférence sur le thème « Peut-on éteindre l'Internet ? ». Je n'ai malheureusement pas pu y aller alors je livre mes réflexions ici. (Jean-Michel Planche a fait un compte-rendu de la conférence.)
Le sujet fait évidemment allusion à un certain nombre de cas connus : projet états-unien de doter le Président d'un gros bouton rouge pour éteindre l'Internet, pannes spectaculaires comme celle due à l'attribut 99 de BGP ou celle du DNS chinois, « attaques accidentelles » comme celle de Pakistan Telecom contre YouTube ou celle de China Telecom, mesures liberticides prises par des États qui trouvent l'Internet trop libre (filtrage systématique, allant jusqu'au détournement du DNS en Chine, loi LOPPSI en France, etc), tentatives (assez ridicules, surtout en France) de faire taire WikiLeaks. Tous ces faits mènent à se poser des questions : si un excité du menton veut censurer Internet, est-ce possible ? Une attaque par les chinois rouges et communistes peut-elle nous priver de services indispensables à la vie humaine, comme Facebook ? La prochaine bogue dans IOS ou Windows va-t-elle stopper tout l'Internet ?
Il n'a pas manqué d'articles sensationnalistes sur ce thème. Selon eux, l'Internet serait tellement fragile que deux ou trois lycéens dans leur garage, a fortiori une organisation comme Al-Quaida, pourrait tout casser. Par exemple, lors de la bavure de China Telecom en avril 2010, on a vu apparaitre une quantité d'articles ridicules sur la soi-disant vulnérabilité de l'Internet (par exemple sur Fox News ou Computer World). Ces articles sensationnalistes ont évidemment eu plus de succès que la froide technique.
À l'opposé de ce discours apocalyptique « on va tous mourir », on voit des neuneus se présentant comme hackers qui prétendent que l'Internet est invulnérable, que les puissants de ce monde n'arriveront jamais à le censurer, et qu'on ne peut pas arrêter le libre flot de l'information.
Qu'en est-il vraiment ? Peut-on éteindre l'Internet ou pas ? Est-il très robuste ou très fragile ? Ces questions n'ont pas de réponse simple. Si on me presse pour fournir une réponse binaire, je dirais « On ne peut pas éteindre complètement l'Internet. Besson et Mitterrand rêvent, ils n'ont pas ce pouvoir. Et l'Internet, très résilient, résistera toujours aux pannes comme celle de l'attribut 99. ». Mais la vraie réponse mériterait d'être bien plus nuancée. Pour citer Pierre Col, « L'Internet est globalement robuste et localement vulnérable ».
Car tout dépend de l'objectif qu'on se fixe en disant « éteindre l'Internet ». Il est très difficile de couper l'Internet pendant une longue période. Mais des attaques réussies l'ont déjà sérieusement perturbé pendant plusieurs minutes, avant que les protocoles et les humains ne réagissent. L'Internet n'est pas invulnérable. Une des meilleures raisons pour lequelles la question « Peut-on éteindre l'Internet ? » n'a pas de réponse simple est qu'il est très facile de perturber l'Internet (BGP, par exemple, n'offre pratiquement pas de sécurité et il n'en aura pas de si tôt), mais très difficile de faire une perturbation qui dure plus de quelques heures (dans tous les cas existants, la réaction a pris bien moins de temps que cela).
De même, il est très facile de planter un service donné. Même pas besoin de pirates chinois pour cela. Une erreur de configuration, et un service fondamentalement stratégique est inaccessible. Pour beaucoup de simples utilisateurs, de ceux qui ne travaillent pas quotidiennement sur l'Internet, « Facebook est en panne » n'est pas très différent de « l'Internet est en panne ». Mais, pourtant, pendant de telles pannes, tout le reste de l'Internet fonctionne (et même mieux, les tuyaux étant moins encombrés). Si on peut comprendre que Jean-Kevin Michu ressente douloureusement l'arrêt de son service favori, les analystes qui prétendent produire un discours sérieux sur l'Internet devraient un peu raison garder et ne pas parler de « vulnérabilité de l'Internet » à chaque fois que Twitter a une panne.
Il est aussi très facile de rendre l'utilisation de l'Internet plus difficile. Tous les censeurs du monde ont appris que couper complètement l'accès était irréaliste. En revanche, le rendre difficile, imposer aux utilisateurs l'emploi de mesures de contournement complexes, est possible. Cela ne découragera pas l'informaticien déterminé et compétent, mais cela peut gêner tellement l'utilisateur ordinaire qu'il renoncera à certains usages. C'est le pari d'organisations répressives comme l'Hadopi, qui sait très bien que les geeks continueront à télécharger quoi qu'il arrive, mais qui compte sur le fait que 95 % de la population ne les suivra pas. Et cela marche dans certains cas. Les censeurs ne sont hélas pas sans dents.
Enfin, on peut aussi noter qu'il est très facile d'éteindre l'Internet en un lieu donné. Chez moi, je peux couper l'accès à ma famille facilement. Dans un pays donné, on peut empêcher l'accès Internet. Cela se fait en Birmanie ou en Corée du Nord. En Tunisie, la mise en place du système de censure connu sous le nom d'« Ammar404 » avait été précédée d'une coupure complète de l'Internet pendant six mois, bloquant tous les usages légitimes. Il a fallu une révolution pour mettre fin au système de filtrage installé à cette occasion. Bref, si une coupure complète dans le monde entier est très difficile, un dictateur local a toujours des possibilités, comme l'a montré le cas de l'Égypte. (À propos de l'Égypte : le lendemain de la coupure de l'Internet dans ce pays, un utilisateur de Google tape la recherche « Comment peut-on couper un pays entier d'Internet ? » qui l'amène sur cet article. Mitterrand et Hortefeux se renseignent ?)
Arrivé à ce point, certains lecteurs trouvent peut-être que je suis trop prudent et qu'il devrait être quand même possible de répondre en deux mots à une question aussi simple que « peut-on éteindre l'Internet ? ». Mais, si la question est compliquée, c'est parce que l'Internet n'est pas un objet unique et localisé dans l'espace, qu'on peut détruire facilement. C'est plutôt une espèce vivante. Chaque individu est très vulnérable, on peut le tuer et, si on est suffisamment dénué de scrupules, on peut même en tuer beaucoup. Mais éradiquer l'espèce entière est plus difficile. La résistance de l'Internet aux pannes et aux attaques n'est pas celle d'un blockhaus passif, qu'on peut toujours faire sauter, avec suffisamment d'explosifs. C'est la résistance d'une espèce vivante, et intelligente (les professionnels qui font fonctionner l'Internet réagissent, corrigent, modifient, et rendent la tâche difficile pour les censeurs et les agresseurs, comme l'a montré la mobilisation autour de WikiLeaks). L'Internet peut être blessé mais le tuer nécessitera beaucoup d'efforts.
Une autre raison pour laquelle je ne donne pas de réponse ferme est que je ne suis pas trop intéressé par les débats pour observateurs passifs, regardant l'incendie en se demandant gravement s'il va être éteint ou pas. Je préfère travailler à améliorer la situation. Peut-on améliorer la résilience de l'Internet, sa résistance aux censeurs, aux pannes, et aux attaques diverses ? Et là, la réponse est claire : oui, on peut. On peut analyser les vulnérabilités, travailler à repérer les SPOF et à les supprimer, chercher les dépendances cachées qui risqueraient de faire s'écrouler un domino après l'autre, etc. Là, un travail est possible et nécessaire. Pendant que la loi LOPPSI impose un filtrage de l'Internet et donc diminue sa résistance aux pannes (le système de filtrage ralentit, perturbe et, d'une manière générale, ajoute un élément supplémentaire qui peut marcher de travers), d'autres efforts essaient de rendre l'Internet plus fiable. Par exemple, trop de liaisons physiques sont encore peu redondantes et une seule pelleteuse peut couper plusieurs câbles d'un coup.
Plus grave, trop de choses dans l'Internet dépendent d'un petit nombre de logiciels, ce qui fait qu'une bogue a des conséquences étendues. Trop de routeurs utilisent IOS et une seule bogue plante des routeurs sur toute la planète. Comme dans un écosystème où il n'y a pas de variété génétique, un germe peut faire des ravages. Autre exemple, le système ultra-fermé de Skype n'a qu'un seul logiciel, le leur, et une seule bogue peut l'arrêter complètement. Ce point illustre d'ailleurs l'illusion qu'il y aurait à essayer de rendre l'Internet plus robuste par des moyens matériels, comme plus de machines, ou logiciels, comme de passer le DNS en pair-à-pair. L'exemple de Skype, qui repose largement sur des techniques pair-à-pair, montre que ces techniques ne protègent en rien si une erreur dans le logiciel plante tous les pairs en même temps.
Il n'y a pas de solution magique au problème de la résilience de l'Internet. Mais il faut accroître sa diversité, qui permettra de faire face aux menaces du futur.
Des articles intéressants sur ce sujet :
- « Couper Internet en France : possible ou pas ? », analyse à la lumière de la coupure égyptienne.
- Suite à la coupure égyptienne, plusieurs articles ont découvert des techniques que les experts connaissaient bien et qui peuvent présenter davantage de résilience pour la communication, comme UUCP ou Fidonet. Voyez par exemple l'opinion « Internet is easy prey for governments » qui fait l'éloge de Fidonet.
- « How Egypt did (and your government could) shut down the Internet » par Iljitsch van Beijnum.
- Une amusante et intéressante expérience de pensée sur la liste Nanog : Que se passe-t-il si un agent fédéral arrive chez vous et demande d'arrêter l'Internet ?.
- Le rapport sur la résilience de l'Internet en France.
Enfin, j'ai écrit un article plus long sur cette question, pour la conférence SSTIC.
L'article seul
RFC 6076: Basic Telephony SIP End-to-End Performance Metrics
Date de publication du RFC : Janvier 2011
Auteur(s) du RFC : D. Malas (CableLabs), A. Morton (AT&T Labs)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF pmol
Première rédaction de cet article le 20 janvier 2011
Le protocole de signalisation SIP est aujourd'hui le plus utilisé pour la voix sur IP. Il existe de nombreux fournisseurs SIP concurrents, de nombreux services SIP un peu partout. Comment les comparer ? Ce RFC se consacre à définir des métriques pour la téléphonie SIP.
Il est le premier RFC produit par le groupe de travail PMOL de l'IETF, groupe de travail qui est consacré à la définition de métriques pour les couches hautes (notamment la couche 7), le groupe IPPM se consacrant aux couches basses comme la couche 3. En suivant ses recommandations, il devrait être possible de comparer des mesures de performances SIP entre différents services. À noter qu'il existait déjà des métriques pour des systèmes de téléphonie autres, comme SS7, mais rien pour SIP.
Comme PMOL (contrairement à un autre groupe de travail sur les mesures, BMWG) établit des métriques pour le monde extérieur, le grand Internet, les résultats des mesures sont influencés par des variables extérieures à SIP, par exemple la qualité du réseau (latence et capacité libre). Les métriques définies ici n'essaient pas de séparer ces variables « réseau » des autres. On teste donc un service, pas uniquement un serveur.
D'autre part, il s'agit bien de définir des métriques (des grandeurs mesurables et définies rigoureusement) et pas des objectifs chiffrés, genre SLA. Ce RFC définit ainsi ce qu'est exactement un temps de réponse, mais pas quelle valeur de ce temps est acceptable pour l'utilisateur.
Après ces préliminaires, la section 2 définit le vocabulaire utilisé. Ainsi, End-to-end fait référence à une liaison entre les deux entités qui communiquent (deux téléphones, par exemple), même si cette communication passe, au niveau 3 par beaucoup de routeurs, et au niveau 7 par plusieurs relais SIP. Une session est la communication établie par SIP (dont le rôle principal est justement d'établir et de fermer les sessions ; le transfert de la voix encodée n'est pas directement du ressort de SIP) et elle peut donc comprendre plusieurs flots de données différents, par exemple plusieurs connexions TCP.
Enfin (non, tout le travail préparatoire n'est pas fini, on n'est pas encore arrivé aux métriques elles-mêmes), toute mesure faisant intervenir le temps, la section 3 est dédiée aux problèmes de mesure de celui-ci. C'est essentiellement une reprise du RFC 2330, section 10. Pour les besoins des mesures SIP (moins exigeantes que les mesures comme le temps d'acheminement d'un paquet IP du RFC 7679), une erreur de moins d'une milli-seconde est demandée, ainsi qu'une stabilité de un pour mille pour la fréquence de l'horloge.
La section 4 introduit enfin ces fameuses métriques. Le temps commence lorsque le premier message est envoyé par un des UA (User Agents, typiquement un téléphone, matériel ou logiciel). Même si ce premier message doit être répété, l'horloge n'est pas remise à zéro. On arrête le chrono lorsque l'opération souhaitée par l'UA est faite, même si elle a nécessité plusieurs transactions SIP (par exemple, si un appel a été redirigé). Des options comme l'authentification (qui est fréquemment utilisée dans le monde SIP car les fournisseurs de service qui procurent un accès au téléphone classique ne sont jamais gratuits) peuvent sérieusement augmenter la durée mesurée mais on n'essaie pas de les retirer du total : elles font partie du service mesuré (voir section 5.3 pour les détails). Enfin, les métriques de la section 4 ne précisent pas la taille de l'échantillon utilisé, se contentant de rappeller qu'on a en général de meilleurs résultats en augmentant la taille de l'échantillon.
Pour comprendre les métriques, il faut se rappeller que le fonctionnement typique d'un téléphone SIP est :
- Au démarrage du téléphone, on s'enregistre auprès d'un fournisseur SIP (SSP pour SIP Service Provider) tel que OVH ou Free/Freephonie. Cela permettra, notamment, de recevoir des appels entrants même si l'appelant ne connait pas notre adresse IP actuelle.
- Pour chaque appel téléphonique, on établit une session SIP avec le destinataire, et cette session sert à transmettre les paramètres d'envoi du flux audio (qui n'est pas envoyé dans la session SIP mais via un protocole séparé comme RTP).
Parmi les métriques définies, on trouve :
- RRD (Registration
Request Delay, section 4.1). Elle mesure le temps écoulé entre un
enregistrement d'un UA auprès d'un fournisseur SIP (requête
REGISTER) et la réponse réussie, typiquement200 OK(les échecs sont comptés différemment, voir section 4.2), exprimée en milli-secondes. - IRA (Ineffective Registration Attempts, section 4.2) qui est le pourcentage des tentatives d'enregistrement qui échouent, soit par réponse négative, soit par expiration du délai d'attente.
- SRD (Session Request Delay, section 4.3), qui
est le délai nécessaire pour établir une nouvelle session. En termes
de téléphonie classique, c'est le moment entre la composition du
numéro et le décrochage du téléphone en face. En SIP, c'est le délai
entre la requête
INVITEet la réponse à celle-ci (la réponse pouvant être négative, par exemple un 486 - Occupé). - SDT (Session Duration Time, section 4.5) est la durée
d'une session (d'un appel). C'est la différence entre le moment de la
fin de la session (par requête explicite ou bien par expiration du
délai d'attente) et la réponse réussie à un
INVITE. - SER (Session Establishment Ratio, section 4.6) est le pourcentage de tentatives d'établissement de sessions SIP qui réussit (de même que IRA était le pourcentage de tentatives d'enregistrement auprès du SSP qui échouaient).
Le logiciel de test sipsak affiche dans certains cas des durées mais elles ne sont pas exprimées en terme des métriques de ce RFC donc il faudrait lire le source pour avoir leur sémantique exacte. Ici, l'établissement d'une session :
% sipsak -vv -s "sip:bortzmeyer@ekiga.net" ... message received: SIP/2.0 200 OK ... ** reply received after 6.770 ms **
Et ici une session complète avec envoi d'un message :
% sipsak -vv -B "This is a test" -M -s "sip:stephane@10.10.86.76" ... received last message 55.642 ms after first request (test duration).
L'article seul
RFC 6066: Transport Layer Security (TLS) Extensions: Extension Definitions
Date de publication du RFC : Janvier 2011
Auteur(s) du RFC : Donald Eastlake 3rd (Stellar Switches)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 18 janvier 2011
Ce RFC décrit les extensions au protocole cryptographique
TLS (résumées
en section 1.1). Je n'en cite que certaines ici, lisez le RFC pour une
liste complète. Ces extensions ne changent pas le protocole : un client ou un
serveur TLS qui ne les comprend pas pourra
toujours interagir avec ceux qui les comprennent. Le serveur doit en
effet ignorer les informations contenues dans le Hello
Client qu'il ne connait pas (section 7.4.1.2 du RFC 5246).
Le mécanisme général des extensions figure dans le RFC 5246,
notamment la section 7 de ce dernier (voir la structure en 7.4.1.2). En gros, le principe est
d'ajouter des données à la fin du paquet Hello,
qui marque le début de la négociation TLS. Dans le langage de
spécification propre à TLS, la liste des extensions possibles est un
enum (indiqué en section 1.1) mais elle est désormais en
ligne à l'IANA.
SNI (Server Name Indication, section 3) permet au client TLS d'indiquer au serveur le nom sous lequel il l'a trouvé. Cela autorise le serveur à présenter des certificats différents selon le nom sous lequel on y accède, fournissant ainsi une solution au problème récurrent de l'authentification avec TLS lorsqu'un serveur a plusieurs noms. À noter que SNI fonctionne avec les IDN, le RFC décrivant le mécanisme à suivre. Si le RFC 4366 permettait au client d'envoyer plusieurs noms, cette possibilité a été supprimée.
Maximum Fragment Length, section 4, permet au client d'indiquer qu'il souhaiterait des fragments de données de taille plus réduite. Cela peut être utile pour un client contraint en mémoire ou en capacité réseau, par exemple un téléphone portable. Certains de ces clients contraints apprécieront également Truncated HMAC (section 7) qui autorise à réduire la taille du MAC utilisé pour protéger l'intégrité des paquets.
Normalement, dans TLS, le certificat du client est envoyé pendant la session TLS. Mais l'extension Client Certificate URLs (section 5) permet au client d'indiquer un URL où le serveur ira chercher le certificat, allégeant ainsi le travail du client (là encore, c'est prévu pour les clients limités en puissance ou en capacité réseau). Une somme de contrôle en SHA-1 est ajoutée à la liste des URLs envoyés, pour permettre davantage de vérifications (autrement, le serveur risquerait, en cas d'empoisonnement DNS, par exemple, de récupérer un mauvais certificat). Dans le même esprit, la section 8 décrit (Certificate Status Request), une extension qui permet d'indiquer la volonté d'utiliser OSCP (RFC 6960), un protocole d'interrogation de la validité de certificats X.509 (plus léger que l'habituel téléchargement de la liste de certificats révoqués, suivi d'un traitement local).
Qui dit nouvelles extensions, dit nouvelles erreurs. La section 9
est donc consacrée aux nouveaux codes d'erreur, pour toutes les
extensions décrites. La plus évidente étant
unsupported_extension où le client TLS
reçoit une extension qu'il n'avait pas demandé (mise dans son
Hello). Certaines n'existaient pas dans le RFC 4366 comme
certificate_unobtainable, utilisé si le mécanisme
de Client Certificate URLs de la section 5 n'arrive
pas à récupérer le certificat indiqué.
Tout le protocole TLS servant à la sécurité, il est normal de se
demander si les extensions en question vont avoir un effet positif ou
pas sur la sécurité. C'est ce que fait la section 11, qui examine les
points forts ou faibles de la sécurité de chaque extension. SNI ne
semble pas poser trop de problème, par contre Client Certificate
URLs fait que le serveur TLS va jouer un rôle de client
(en général, avec le protocole HTTP), ce qui
soulève des questions : le client TLS ne va t-il pas utiliser cette
extension pour pousser le serveur à attaquer un serveur HTTP, d'autant
plus que le client TLS contrôle complètement l'URL ? Ou bien le client
TLS coincé derrière un pare-feu ne va-t-il pas essayer de convaincre
le serveur TLS de récupérer quelque chose de son côté du pare-feu ? Un
serveur HTTP normalement non accessible depuis l'Internet pourrait
ainsi être indirectement attaqué, si un serveur TLS gérant cette
extension se trouve sur son réseau. Il est donc recommandé que cette
extension ne soit pas activée par défaut et seul un jeu limité de plans
d'URL soit accepté (ce dernier conseil me semble vain : le plan
http: sera forcément sur la liste et c'est sans
doute le plus intéressant pour un attaquant).
Quant à Truncated HMAC, elle peut aboutir à affaiblir la sécurité puisque le HMAC court est forcément moins fiable. Ce n'est pas forcément très grave car une attaque par force brute contre ce HMAC ne peut pas être faite hors-ligne mais doit être exécutée pendant la session TLS et qu'une seule erreur de la part de l'attaquant coupe la session.
L'annexe A résume les changements depuis la RFC 4366. Le principal est que la RFC 4366 spécifiait à la fois un mécanisme d'extension et des extensions spécifiques. Le mécanisme d'extension ayant été mis dans le RFC 5246 (section 7.4.1.2 à 7.4.1.4), notre RFC 6066 ne contient plus que les extensions.
D'autre part, l'extension SNI a été simplifié en éliminant la possibilité de noms en UTF-8. Désormais, IDN ou pas, le nom doit être représenté en ASCII. Et le condensat cryptographique sur les certificats reçus par l'extension Client Certificate URLs est désormais obligatoire.
L'article seul
RFC 6056: Transport Protocol Port Randomization Recommendations
Date de publication du RFC : Janvier 2011
Auteur(s) du RFC : M. Larsen (TietoEnator), F. Gont (UTN/FRH)
Réalisé dans le cadre du groupe de travail IETF tsvwg
Première rédaction de cet article le 18 janvier 2011
Lorsqu'un méchant attaquant tente de s'infiltrer dans une conversation en TCP, par exemple pour la couper ou la ralentir, il doit, soit être sur le trajet des paquets et pouvoir les regarder soit, dans le cas le plus fréquent, celui d'une attaque en aveugle, deviner un certain nombre d'informations qui « authentifient » la connexion TCP. Parmi celles-ci, le port source est trop souvent trop facile à deviner. Notre RFC expose pourquoi et surtout comment rendre ce port source plus dur à trouver.
De manière plus rigoureuse : lors d'une attaque en aveugle (où le méchant n'est pas en position de sniffer les paquets de la connexion TCP), les paquets mensongers injectés par le méchant ne seront acceptés par la machine victime que si le penta-tuple {Adresse IP source, Adresse IP destination, Protocole, Port Source, Post Destination} est correct (cf. RFC 5961 et RFC 5927). Pour la sécurité de TCP face à ces attaques en aveugle, il vaut donc mieux que ce tuple soit caché. Mais une partie est triviale à deviner (par exemple, pour une connexion BGP, le port de destination sera forcément 179 dans un sens et, dans l'autre, ce sera le port source). Il faut donc faire porter l'effort sur les autres parties, en essayant de les rendre le moins prévisibles possible. Une telle protection fonctionnera aussi bien avec les attaques par TCP lui-même que en passant par ICMP.
Bien sûr, cela ne remplace pas une bonne protection cryptographique des familles mais le moins qu'on puisse dire est qu'IPsec est laborieux à déployer et le but de notre RFC est de fournir une solution aujourd'hui. Il est à noter que les mécanismes de ce RFC peuvent être déployés unilatéralement et ne changent pas les protocole de transport (il n'est d'ailleurs pas spécifique à TCP ; ainsi, le DNS, protocole qui tourne surtout sur UDP, a dû déployer des techniques analogues, notamment en réponse à la faille Kaminsky ; voir le RFC 5452).
La section 1 du RFC résume ce problème (voir aussi les RFC 4953, RFC 5927 et RFC 5961). Dans un protocole client-serveur, le protocole est souvent déterminé par l'application (BGP ne peut tourner que sur TCP), le port de destination est souvent fixe (80 pour HTTP), les adresses IP des serveurs en général connues. L'adresse IP du client n'est pas en général secrète (pour BGP, les adresses IP de tous les participants à un point d'échange sont un secret de Polichinelle). Il ne reste donc que le port source pour empêcher l'attaquant de fabriquer des faux paquets qui seraient acceptés. Certes, stocké sur 16 bits, il ne peut stocker, dans le meilleur des cas, que 65 536 valeurs différentes mais c'est mieux que rien. L'idée n'est pas de fournir une protection absolue mais simplement de rendre la tâche plus pénible pour l'attaquant.
Et, justement, il existe des moyens de faire varier ce port source de manière à rendre difficile sa prédiction par l'attaquant. Cela ne vaut pas des techniques comme l'authentification TCP du RFC 5925 mais c'est déjà un progrès pour la sécurité. En dépit du titre du RFC, il ne s'agit pas de rendre le port source réellement mathématiquement aléatoire mais simplement plus dur à deviner.
Place maintenant à l'exposé des méthodes. Juste un peu de vocabulaire : une « instance » est une communication identifiée par un penta-tuple (c'est équivalent à une connexion pour les protocoles de transport à connexions comme TCP). L'« ID » d'une instance est simplement le penta-tuple {Adresse IP source, Adresse IP destination, Protocole, Port Source, Post Destination}.
Il y a port et port. La section 2 explique
le concept de « port temporaire ». Pour chaque protocole
(TCP, UDP ou autre), les
65 536 valeurs possibles pour les ports se répartissent en « ports bien
connus » (jusqu'à 1023 inclus), « ports enregistrés » (jusqu'à 49151
inclus) et « ports dynamiques et/ou privés » (le reste). Normalement,
une application de type client/serveur se connecte à un « port bien
connu » (parfois à un « port enregistré ») et utilise comme port
source un port temporaire pris parmi les ports dynamiques. Pour que
l'ID d'instance soit unique (sinon, il ne jouerait pas son rôle), une
mise en œuvre simple est d'avoir une variable par protocole,
mettons next_ephemeral, qui indique le prochain
port libre et est incrémentée à chaque connexion. L'algorithme est en
fait un peu plus compliqué que cela (section 2.2) car il faut tenir compte des
ports déjà en service, et de ceux que l'administrateur système a
manuellement interdit (par exemple, dans le serveur DNS
Unbound, la plage de ports à utiliser se
configure avec outgoing-port-permit et
outgoing-port-avoid, dans son concurrent
BIND, avec
use-v6-udp-ports et
avoid-v6-udp-ports ; autre exemple, dans
FreeBSD, la fonction
in_pcblookup_local() vérifie les ports
utilisés).
Mais le principal problème de cet algorithme simple est que le port source choisi pour la communication est facile à deviner. Si l'attaquant gère un serveur auquel le client se connecte, il lui suffit de regarder le port utilisé, d'ajouter un, et il saura le port utilisé pour la connexion suivante. Il pourra alors monter facilement les attaques décrites dans les RFC 4953 et RFC 5927.
Avant de trouver une solution à ce problème de prédictibilité, il faut se pencher sur le problème des collisions entre ID d'instances. Même si le client fait attention à utiliser un penta-tuple qui n'est pas en service de son côté, il peut parfaitement choisir un port source qui correspondra à un penta-tuple encore en activité de l'autre côté. En effet, l'autre côté doit garder la connexion (et donc le penta-tuple) en mémoire jusqu'à être sûr que plus aucun paquet IP n'est encore en route et, si le client est très actif (ouvre de nouvelles connexions souvent), le risque de tomber sur un penta-tuple encore en activité est élevé. Cela peut alors entraîner les problèmes décrits dans le RFC 1337. Choisir le prochain port de manière incrémentale, comme dans l'algorithme exposé plus haut, minimise le risque, puisqu'on ne réutilisera un port qu'après que toute la plage possible ait été épuisée.
Comment faire alors ? Faut-il choisir entre la sécurité qu'apportent une sélection non-linéaire du port source à utiliser et le sécurité par rapport aux collisions d'ID d'instances ? La section 3 expose plusieurs méthodes pour rendre le prochain port source plus difficile à prédire pour un attaquant. D'abord, qu'attend t-on d'un algorithme d'embrouillage du choix du port ? On voudrait à la fois qu'il rende la prédiction difficile pour l'attaquant, qu'il minimise le risque de collision d'ID, et qu'il ne marche pas sur les pieds des applications qui sont configurées pour un port précis (par exemple un serveur SSH qui écouterait sur le port 4222). Un algorithme qui assurerait la première fonction (rendre la prédiction difficile) pourrait, par exemple, être de tirer au hasard le prochain port utilisé. Mais les deux autres fonctions en souffriraient... N'imposons donc pas un vrai tirage aléatoire et voyons les compromis raisonnables. Le premier algorithme présenté, celui qui incrémente le numéro de port de un, a les problèmes inverses (il minimise la réutilisation mais maximise la prédictibilité).
On l'a vu, la plage des ports temporaires allait traditionnellement de 49152 à 65535. Mais elle est trop étroite pour assurer une vraie inprédictibilité du port source et la section 3.2 demande donc que, par défaut, la plage utilisée par les algorithmes de choix aille de 1024 à 65535. Comme cette plage inclus des ports réservés à l'IANA, l'algorithme de choix doit donc faire attention à ne pas sélectionner des ports qui sont utilisés sur la machine locale (ou qui pourraient l'être).
Place maintenant aux algorithmes effectifs. La section 3.3 décrit
successivement les différents algorithmes possibles, avec du
pseudo-code proche du C pour leur implémentation. L'algorithme 1,
en section 3.3.1, est celui de simple tirage au hasard de la variable
next_ephemeral à chaque utilisation. Si le port
sélectionné n'est pas utilisable (par exemple parce qu'un serveur
écoute déjà sur ce port), on essaie le suivant, puis le suivant etc. Attention,
si on veut qu'il soit efficace, il faut que le générateur aléatoire le
soit réellement (cf. RFC 4086). La traditionnelle
fonction random(), dans la plupart
des cas, ne l'est pas. Comme cet algorithme 1 n'a pas de mémoire, il
peut sélectionner un port qui avait été utilisé récemment, augmentant
ainsi les risques de collision des ID d'instances. En outre, il a une
autre faiblesse : s'il existe une longue plage de ports déjà utilisés,
et que le tirage au hasard fait tomber dans cette plage, le port situé
immédiatement après la plage sera très souvent sélectionné, ce qui
augmente la prévisibilité.
L'algorithme 2, en section 3.3.2, améliore l'algorithme 1 en tirant au hasard, non seulement le port initial, mais aussi l'incrément à utiliser si le port initial n'est pas libre. Il est donc le moins prévisible mais, en cas d'extrême malchance, il peut échouer à trouver un numéro de port, même s'il y en a un de libre.
L'algorithme 3 (section 3.3.3, inspiré du mécanisme décrit par
Bellovin dans le RFC 6528) renonce à utiliser un générateur
aléatoire et repose au contraire sur un condensat des paramètres de l'instance (adresses
IP, etc). Prenons une fonction F qui reçoit les deux adresses IP, le
numéro de port de l'autre partie et une clé secrète et les condensent
en un nombre qui sera l'incrément appliqué à la variable
next_ephemeral. En dépendant des paramètres de
l'instance, on minimise la réutilisation des ID d'instances. On peut
d'ailleurs ajouter d'autres paramètres comme, sur un système
multi-utilisateurs, le nom de l'utilisateur. Cette fonction F doit évidemment être une fonction
de hachage cryptographique comme MD5 (RFC 1321). Certes, MD5 a aujourd'hui des faiblesses
cryptographiques connues mais il ne s'agit que de rendre le prochain
port imprévisible, tâche pour laquelle il suffit. La clé secrète,
elle, est ici pour empêcher un attaquant qui connaitrait la fonction
de hachage utilisée de faire tourner le même algorithme et de prédire
ainsi les numéros de port. Elle est typiquement choisie aléatoirement
au démarrage de la machine.
L'algorithme 3 peut être perfectionné en ajoutant un second
condensat, qui servira à indexer une table des variables
next_ephemeral (au lieu d'avoir une variable
unique). C'est l'algorithme 4, présenté en section 3.3.4.
Enfin, le dernier algorithme, le numéro 5 (section 3.3.5) choisit
l'incrément de next_ephemeral au hasard mais
l'applique ensuite de manière déterministe, ce qui limite les risques
de collision d'ID puisque le numéro de port utilisé augmente à chaque
fois (et repart une fois arrivé au bout). Notez le rôle du paramètre N
(dont le RFC dit qu'il devrait être configurable) pour déterminer si
on utilise de petits incréments (plus prévisibles mais diminuant les
risques de collision) ou des grands (avec les avantages et les
inconvénients renversés).
Certains de ces algorithmes dépendent d'une clé secrète, choisie au hasard. Comment choisir celle-ci ? La section 3.4 qu'elle doit être assez longue (128 bits sont recommandés). Elle suggère aussi de changer cette clé de temps en temps. Mais attention : juste après le changement, le risque de collision va augmenter.
On l'a vu, il existe plusieurs algorithmes acceptables pour
atteindre notre objectif de sélection de numéros de port peu
prévisibles. Lequel choisir ? La section 3.5 est une évaluation
comparée desdits algorithmes, basée sur le très bon article de Mark Allman,
« Comments On Selecting Ephemeral
Ports », publié dans ACM
Computer Communication Review, 39(2), 2009. Tous ces
algorithmes évitent les collisions de manière satisfaisante (moins de
0,3 % des cas mais le chiffre exact dépend de beaucoup de choses,
comme le rythme d'ouverture et de fermeture des nouvelles connexions).
L'étude empirique d'Allman montre que les algorithmes 1 et 2, les
seuls réellement aléatoires sont aussi, comme attendu, ceux qui
montrent le plus de collisions d'ID d'instances. Les algorithmes 3 et
surtout le 4 sont ceux qui imposent la plus grande consommation de
ressources machines (calcul du condensat cryptographique et, pour le
4, consommation de mémoire pour la table). À noter enfin que, dans
certains systèmes d'exploitation et certaines applications (celles qui appellent
bind() sans indiquer de numéro de
port), les algorithmes 3 et 4 ne sont pas utilisables car l'adresse IP
et le port distant ne sont pas connus au moment où on sélectionne
le port local et la fonction de hachage ne dispose donc pas d'assez
d'arguments. Le système d'exploitation doit alors se rabattre sur un
algorithme comme le 2 ou bien effectuer un bind()
paresseux en retardant l'allocation effective du port local jusqu'au
moment où la connexion est réellement faite (avec, par exemple,
connect()). C'est par exemple ce que
fait Linux. (Pour l'anecdote, ce point avait été ma contribution à ce RFC, en 2008, au début du processus d'écriture.)
De nos jours, un grand nombre de machines sont coincées derrière un routeur NAT ou plus exactement NAPT (Network Address and Port Translation, RFC 2663) qui utilise les numéros de ports pour démultiplexer le trafic entre les différentes machines du réseau local. Comme l'explique la section 4, les techniques d'obscurcissement du prochain numéro de port peuvent être alors prises en défaut si le routeur NAPT change ces ports par d'autres, choisis de manière trop prévisible. Le RFC impose donc que le routeur NAT, soit conserve les numéros de port (RFC 4787 et RFC 5382), soit choisisse lui-même les ports selon un mécanisme non prévisible.
Une fois les algorithmes exposés, compris et analysés, la section 5 reprend à nouveau de la hauteur pour parler d'une approche générale de la sécurité. D'abord, elle rappelle qu'un attaquant qui n'est pas aveugle, qui peut sniffer le réseau où passent les paquets, se moque des algorithmes exposés ici puisqu'il peut lire directement le numéro de port dans les paquets. Dans ce cas, il n'y a pas d'autre solution que des protections cryptographiques comme celles du RFC 4301.
Plus rigolo, certains choix pour la liste des ports exclus peuvent poser de sérieux problèmes de sécurité. Ainsi, si un système d'exploitation prend comme liste de ports à éviter la totalité de la liste IANA, il ne doit pas utiliser l'algorithme 1 car les ports qui se trouvent immédiatement après la liste réservée seront sur-représentés.
Comment est-ce mis en œuvre en pratique ? L'annexe A du RFC précise les choix effectués par les principaux systèmes d'exploitation libres (pour les autres, on ne sait pas s'ils sont sûrs puisqu'on ne peut pas examiner le source). Ainsi, Linux utilise l'algorithme 3, avec MD4 comme fonction de hachage (même si le RFC dit que c'est MD5). Sur un Linux 2.6 de septembre 2010, le code se trouve (de haut en bas, dans l'ordre des appels successifs), en indiquant fichier-source:fonction :
net/ipv4/inet_hastables.c:inet_hash_connect(qui utilisenet/ipv4/inet_connection_sock.c:inet_get_local_port_rangepour récupèrer auprès de sysctl les ports utilisables),net/ipv4/inet_hastables.c:inet_sk_port_offset,drivers/char/random.c:secure_ipv4_port_ephemeralqui fait le hachage des paramètres indiqués par l'algorithme 3 (adresses et ports).
FreeBSD, OpenBSD et
OpenSolaris utilisent l'algorithme 1. La séquence des appels est (dans le HEAD du CVS de FreeBSD en octobre 2010) :
in_pcbconnect,in_pcbconnect_setup,in_pcbbind_setup(qu'on peut voir, si on n'a pas les sources sur sa machine, enhttp://fxr.watson.org/fxr/source/netinet/in_pcb.c?im=bigexcerpts#L325).
Merci à Benoit Boissinot pour son aide dans la navigation dans le source de FreeBSD.
Une petite anecdote historique pour terminer : la prédiction correcte des numéros de série des tanks allemands pendant la Seconde Guerre mondiale a permis aux Alliés de calculer le nombre de tanks ennemis. Comme quoi, toute information trop régulière et prévisible peut être exploitée par l'ennemi.
L'article seul
Les lecteurs de fichiers EPUB sur Android
Première rédaction de cet article le 17 janvier 2011
Je n'ai jamais été très fana des lecteurs de livres numériques pour les raisons expliquées dans un autre article. Mais les temps changent et il faut réviser ses conclusions de temps en temps. J'ai donc décidé de regarder ce qui se faisait en matière de lecteurs de livres au format EPUB sur mon téléphone Android. Pourquoi ce format ? Parce qu'il est à la fois entièrement ouvert (contrairement à PDF) et qu'il est plus adapté aux appareils numériques (contrairement, là encore, à PDF, qui reste accroché à l'antique notion de page et qui ne permet pas, par exemple, au texte de s'adapter à la largeur de l'écran).
Premièrement, une petite méthodologie de test. J'ai évalué les
lecteurs sur quatre livres différents, deux que j'avais fait moi-même
et deux que j'avais récupéré. Les deux faits par moi l'ont été en
suivant des techniques différentes, pour augmenter la surface des
tests. Les deux récupérés sur l'Internet était une version de « L'Île à hélice » de Jules Verne, trouvée
chez Gutenberg, et l'autre le « Epub
Format Construction Guide » de Harrison
Ainsworth. Parmi les tests, j'ai tenté d'ajouter un catalogue
existant, en l'occurrence celui du projet Gutenberg, accessible en
m.gutenberg.org au format
OPDS (regardez l'élément <link
rel="alternate"
type="application/atom+xml;type=feed;profile=opds-catalog"...
dans le source).
J'ai testé les logiciels suivants :
- StarBooks,
- FBreader,
- Moon + reader,
- Cool reader,
- Aldiko,
- et Laputa.
Tous sont gratuits (mais pas forcément libres) et disponibles sur le Market. Pour chacun d'eux, je teste les fonctions qui me semblent importantes (et je suis bien conscient qu'il peut y en avoir beaucoup d'autres comme l'application des feuilles de style CSS, la traduction de l'interface, le rendu des images ou, bien sûr, la possibilité de lire d'autres formats que le EPUB).
StarBooks, comme d'ailleurs d'autres logiciels, a une esthétique inspirée d'une bibliothèque traditionnelle, avec étagères en bois. Curieuse influence du passé sur le présent. StarBooks ne peut pas lire un des livres que j'ai fait, le seul (et vague) message était Import failed: <null>. Bien que ce fichier passe tous les tests EPUB (et soit lu par tous les autres lecteurs), je veux bien croire qu'il a des défauts mais j'aurais apprécié un meilleur message d'erreur. Les trois autres fichiers fonctionnent.
La lecture se fait page à page (pas de défilement continu), avec un joli effet visuel imitant, là encore, un livre en papier. Il y a aussi une règle pour la navigation directe. Pas de fonction de recherche.
On ne peut pas réellement prendre de notes, juste définir des signets (avec un court texte qui les décrit) qui permettent de retrouver rapidement un passage.
Le zoom normal d'Android (par pincement de l'écran) ne fonctionne pas (comme avec, hélas, tous les logiciels testés ici), il faut régler la taille de la police par le menu Réglages. Je n'ai pas trouvé de moyen d'inclure un catalogue comme celui de Gutenberg.
FBreader est surtout connu pour marcher également sur des machines de bureau Unix. C'est un logiciel libre. Il peut charger tous mes fichiers. Il n'essaie pas de copier bêtement le look « bibliothèque » (même si certaines icônes représentent des livres papier).
Comme avec Starbooks, la lecture se fait seulement page à page. La règle pour la navigation directe (permettant d'aller directement à, par exemple, la moitié du livre) est assez planquée (dans le menu Plus), mais, par contre, il y a une fonction de recherche dans le texte, très agréable.
Il ne permet pas non plus d'annotations, et la fonction de signets est assez sommaire (pas moyen de modifier le texte par défaut).
Le zoom normal d'Android ne fonctionne pas, il faut régler la taille de la police par le menu Réglages. La fonction Bibliothèque réseau permet facilement d'ajouter le catalogue de Gutenberg et d'accéder ainsi à leurs nombreux livres.
Moon + Reader permet de faire défiler progressivement le texte, sans être obligé de passer entièrement d'une page à une autre (une limitation du papier que, curieusement, tous les autres lecteurs EPUB reprennent). Il y a aussi une règle de déplacement direct et une curieuse fonction de déplacement automatique, pour ceux qui arrivent à lire à vitesse à peu près constante. On peut cependant la piloter avec le bouton Volume. Je ne suis pas sûr que cela soit réellement utile mais c'est amusant. Comme avec plusieurs autres logiciels Android, Moon + Reader ne reconnait malheureusement pas le bouton Recherche du téléphone mais a bien une fonction de recherche de texte intégrée.
Moon + Reader dispose de signets et surtout d'une fonction de prise de notes, très agréable bien qu'assez cachée (« Plus d'options » puis « Sélection de texte », ce qui n'est pas très intuitif).
Pour l'intégration de catalogues externes, celui du projet Gutenberg est défini par défaut, j'ai donc testé avec celui de revues.org qui marche très bien.
Cool reader est sans doute le plus simple. Il lit en page à page et n'a pas de règle pour la navigation directe : il faut taper le nombre indiquant quel pourcentage du livre on a déjà lu ! Pas de prise de notes et les signets ne sont identifiés que par des numéros. Mais il existe une possibilité d'aller à une page donnée, en indiquant son numéro. Et la fonction de recherche, accessible par le bouton normal du téléphone, est très pratique.
Les catalogues accessibles sur l'Internet ne lui semblent pas accessibles.
Aldiko est celui qui reprend le plus l'esthétique des livres papier et de leurs bibliothèques. La lecture de fichiers EPUB y est incroyablement pénible. C'est le seul lecteur où on ne puisse pas naviguer dans le système de fichiers Android. Il faut mettre les livres à un endroit précis avant de les importer !
La lecture se fait page à page. Il ne semble pas y avoir de règle pour la navigation accélérée. Mais la fonction de recherche est très bien faite.
Les signets sont simples à utiliser mais je ne vois pas de fonction de prise de notes. L'ajout du catalogue de Gutenberg se passe bien (à part qu'il faut indiquer explicitement un titre alors que tous les autres logiciels le trouvent automatiquement dans le catalogue en ligne).
Et enfin, Laputa. C'est de loin le plus compliqué à utiliser, au point qu'il se lance avec plusieurs écrans de documentation à lire. Malgré cela, je n'ai pas réussi à lui faire lire mes fichiers EPUB, ni à lire un livre en ligne. Un logiciel pour les experts, donc.
Enfin, Alice Bernard me suggère Mantano Reader que je n'ai pas testé mais qu'elle considère comme le meilleur lecteur EPUB sur Android.
Alors, lequel choisir ? Pour l'instant, j'ai sélectionné Moon + Reader, très complet, et qui a deux fonctions que je trouve nécessaires, la lecture en défilement continu (et pas page à page) et la prise de notes. Alice Bernard me fait remarquer qu'il a d'autres avantages : « Un point fort par exemple : régler la luminosité de l'écran (en faisant glisser son doigt de bas en haut ou de haut en bas sur le bord gauche), et régler la taille des caractères (même principe, sur le bord droit). » Seul problème, il n'est pas libre (si c'est un critère vital, FBreader est très bien).
Reste à voir si cela m'éloignera des livres papier...
Quelques articles sur ce sujet :
- Un article de eBouquin mais qui mentionne seulement deux lecteurs EPUB, Aldiko et FBreader,
- Un article sur jedisaber qui parle des lecteurs ePUB pour toutes les plate-formes, dont Android.
- L'excellent guide du projet Gutenberg qui ne mentionne également qu'Aldiko et FBreader.
L'article seul
Aya de Yopougon
Première rédaction de cet article le 16 janvier 2011
Mes enfants et moi-même venont de terminer le sixième tome des aventures d'Aya de Yopougon, qui a autant plu aux petits qu'au grand. Ce feuilleton en bandes dessinées compte les aventures d'une jeune ivoirienne dans les années 80. Aya veut devenir médecin, mais la série ne tourne pas qu'autour d'elle, c'est plutôt une grande fresque avec plein de personnages, le gentil mais bébête Hervé, le menteur Grégoire, la débrouillarde Bintou, le fils-à-papa Moussa, la (trop) gentille Félicité, le séducteur Mamadou, et aussi Innocent qui se cherche, Adjoua qui ne se méfie pas assez... (Les personnages masculins sont nettement plus négatifs que les féminins. Il faut dire qu'il n'est pas facile d'être femme en Afrique.)
Un des personnages dit à un moment : « arrêtez, on n'est pas un feuilleton télévisé brésilien ». Mais si ! Par le nombre de personnages, la richesse en rebondissements, la variété des évènement, on est bien dans un feuilleton, et un des meilleurs, en plus ! Certes, l'auteure a choisi de présenter une Afrique différente de celle qu'on voit à la télé, où il n'y a de place que pour les guerres et les famines avec gentil docteur blanc venant sauver les populations reconnaissantes. Dans le livre, on voit au contraire la Côte d'Ivoire du temps de Houphouët-Boigny, assez idéalisée (même si je suppose que l'auteure s'est largement basée sur des souvenirs personnels et que sa jeunesse a ressemblé à celle d'Aya), où il n'y a pas de guerre ou de famine. La situation n'est pas idéale (l'enlèvement d'une jeune fille, pour la ramener de force au village, le professeur d'université qui ne donne des bonnes notes qu'aux étudiantes qui couchent avec lui) mais il y a toujours de la place pour l'espoir en une vie meilleure. Comment vivent les jeunes abidjanais aujourd'hui que le pays est à nouveau au bord de la guerre civile ? À l'époque, en tout cas, les choses étaient différentes. Ainsi, le racisme est totalement absent (c'était avant que Bédié n'en fasse une arme politique).
Yopougon est un quartier populaire d'Abidjan, aussi loin du pittoresque et misérable village de brousse que des hôtels internationaux de Cocody et du Plateau (personnellement, tout ce que je connais à Abidjan). Les gens y vivent, y travaillent, y aiment et font des projets. C'est déjà quelque chose qu'on voit rarement dans les reportages sur l'Afrique.
Aya nous montre aussi un monde où on parle français (la langue officielle et la seule qui permet à tous les ivoiriens de se comprendre) mais pas le même français qu'à Paris. Le passionné des langues vivantes appréciera les différences, aussi bien dans le vocabulaire que dans la syntaxe.
Je ne sais pas si les ivoiriens lisent ces livres. Mais le français curieux y apprendra beaucoup sur l'Afrique. Le plus entreprenant testera les recettes de cuisine à la fin de chaque tome...
L'article seul
Quinzinzinzili
Première rédaction de cet article le 12 janvier 2011
Si vous êtes aussi amateur de science-fiction que moi, vous avez certainement déjà lu des tas de romans « post-guerre atomique », où une poignée de survivants héroïques luttent courageusement pour maintenir un noyau de civilisation (et, en général, réussissent). Qui a commencé ce genre ? Quel était le premier livre « post-guerre atomique » ? C'est évidemment difficile, voire impossible à dire. Mais le roman de Régis Messac, « Quinzinzinzili », parmi ceux écrits en français, est sans doute un des tout premiers. Il a été publié en 1934 et a une autre particularité : les survivants ne sont pas héroïques du tout. En fait, l'auteur ne fait pas preuve d'un grand optimisme quant au comportement des humains dans de telles situations...
Loin de maintenir la civilisation, les survivants développeront au contraire avec art une barbarie équivalente à celle qui vient de déclencher la guerre. Ils oublieront presque tout de la civilisation et un de leurs rares souvenirs sera une vague prière, le « Notre Père » en latin, comprise de travers, et où le « Qui es in coelis » deviendra « Quinzinzinzili », le nouveau Dieu de leur univers en ruines. Après tout, si la science et la culture ont servi à préparer la guerre qui vient d'anéantir presque tout le monde, la barbarie est peut-être préférable ? Messac, qui écrivait juste avant la Seconde Guerre mondiale a pu rapidement mesurer à quel point son pessimisme était plus réaliste que les prédictions lénifiantes d'autres auteurs de SF.
Le livre a été réédité récemment (merci à Patrick Guignot pour les informations), en 1998 (Éditions de l'Agly) et encore en 2007 (l'Arbre vengeur). L'exemplaire dans ma bibliothèque date de 1972 et je l'ai trouvé au marché aux livres. Si vous le trouvez, n'hésitez pas à vous précipiter sur ce chef d'œuvre de la littérature de science-fiction française, de l'époque des Hommes frénétiques et de la Guerre des mouches.
L'article seul
Il n'existe pas de « caractères spéciaux »
Première rédaction de cet article le 6 janvier 2011
Ceci est un billet d'humeur. Si vous n'aimez pas les billets d'humeur, ou bien si vous trouvez qu'ils sont un moyen facile de remplir son blog à peu de frais, passez à l'entrée suivante dans votre flux de syndication. La raison de ce billet est qu'une recherche sur Google des termes « caractères spéciaux » donne pour moi 201 000 résultats, presque tous utilisant cette expression à tort. Or, il n'y a pas de caractères spéciaux. Tous les caractères Unicode sont égaux !
Un exemple parmi ces 201 000, un article d'une revue de bonne qualité, consacré à une bogue informatique amusante et qui explique « l’iPhone aurait du mal à gérer les caractères spéciaux, type “ç” ou “ê” insérés dans les SMS ». Mais ces caractères n'ont rien de spécial ! Ce sont des caractères Unicode comme les autres, et, dans un article en français, le ç n'a rien de plus spécial que le c ! Les ignorants emploient en général ce terme de « caractères spéciaux » pour parler de ceux qui ne sont pas dans US-ASCII. Mais c'est un provincialisme très étroit : même pour les langues utilisant l'alphabet latin, la quasi-totalité d'entre-elles utilisent des caractères qui ne sont pas dans US-ASCII et ne sont pas spéciaux pour autant.
En Europe, je crois que seuls l'anglais, le frison et le néerlandais peuvent s'écrire avec uniquement ASCII. Et encore : en anglais, des mots comme résumé (à ne pas confondre avec le verbe resume, qui n'a pas le même sens, c'est pour cela que les accents sont importants) nécessitent aussi ces caractères injustement qualifiés de spéciaux. De même, en néerlandais, on a des noms propres avec accent (comme België), certains utilisent la ligature ij (U+0133) ou bien on trouve un accent dans le numéral 1. (Autres exemples sur Wikipédia.)
Donc, je le répète, tous les caractères Unicode sont égaux : ils ont tous un point de code (un nombre, comme U+00E7 pour ç, U+0063 pour c, U+00E9 pour é ou U+0178 pour Ÿ) et un nom. (Seule exception, dans le monde Unicode, l'encodage UCS-2, qui ne traite pas les points de code supérieux à 65535, pourtant la majorité des caractères Unicode. Il ne devrait donc jamais être employé. UTF-16, lui, traite d'une manière... spéciale, ces caractères mais, au moins, il permet de les représenter. Mauvais encodage, toutefois.)
Les seuls caractères qu'on peut légitimement appeler « caractères spéciaux » sont ceux qui nécessitent un échappement dans le langage qu'on utilise. Ainsi, il est normal de dire « \ est un caractère spécial dans les chaînes de caractères en C » ou bien « & est un caractère spécial en XML » et de rappeler aux programmeurs qu'ils doivent faire attention en les manipulant. Mais c'est tout.
Une note au passage sur les SMS, qui étaient cités dans l'exemple que je donnais : la question de l'Unicode dans SMS est complexe et, dans ce cas précis, certains caractères sont en effet spéciaux et traités différemment. Mais la très grande majorité des 201 000 autres exemples ne concernent pas cette technologie archaïque.
Merci à Alix Guillard, Marco Davids, Patrick Vande Walle, André Sintzoff et Rafaël Garcia-Suarez pour leurs commentaires érudits sur le néerlandais.
L'article seul
Désormais, IPv6 natif officiel chez Gandi Hosting
Première rédaction de cet article le 6 janvier 2011
Le service d'hébergement de Gandi (dont le nom officiel doit être une marketingerie comme Gandi Claoude) est désormais accessible en IPv6, en natif et en officiel.
Bien sûr, on pouvait toujours utiliser un tunnel, par exemple vers Hurricane Electric mais les tunnels créent bien des problèmes avec leur MTU réduite, et certains ne sont pas toujours très fiables. Il vaut donc nettement mieux avoir une connectivité IPv6 native. Ce service chez Gandi fonctionnait déjà depuis de nombreux mois mais il vient juste de passer officiel, quelques semaines avant l'épuisement complet des adresses IPv4 à l'IANA. Désormais, plus de manipulations manuelles à faire, le serveur reste juste à attendre les RA (Router Advertisement, cf. RFC 4861).
Il acquiert ainsi son adresse IP fixe :
% ip -6 addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qlen 1000
inet6 2001:4b98:dc0:41:216:3eff:fece:1902/64 scope global dynamic
valid_lft 2591625sec preferred_lft 604425sec
inet6 fe80::216:3eff:fece:1902/64 scope link
valid_lft forever preferred_lft forever
Les instructions techniques détaillées, pour les curieux, sont en
http://wiki.gandi.net/fr/hosting/gandi-expert/manage-ipv6. tcpdump
ne semble pas avoir de moyen simple de sélectionner uniquement les
paquets RA donc j'affiche ici les paquets ICMP
diffusés à tous :
# tcpdump -n -v -i eth0 icmp6 and dst host ff02::1
11:54:43.315300 IP6 (class 0xe0, hlim 255, next-header ICMPv6 (58) \
payload length: 56) \
fe80::641 > ff02::1: ICMP6, router advertisement, length 56 \
hop limit 64, Flags [none], pref medium, router lifetime 1800s, \
reachable time 0s, retrans time 0s \
mtu option (5), length 8 (1): 1500[ndp opt]
Et on voit le routeur annoncé :
% ip -6 neighbor show fe80::641 dev eth0 lladdr 00:07:b4:02:b2:01 router REACHABLE
(Autre solution, avec tshark, due à Benjamin Bachelart :
# tshark -i eth0 'ip6[6] == 0x3a and ip6[40] == 0x86'
.)
Toujours pour les curieux, voici quelle était la configuration d'une
machine Debian pendant la phase de tests. On
mettait dans /etc/network/interfaces :
iface eth0 inet6 static address <ipv6 address generated by mkv6> netmask 64 gateway <default gw generated by mkv6>
Cela n'est désormais plus nécessaire, on n'a plus besoin de quelque chose de particulier dans ce fichier.
Ce blog est accessible en IPv6 via ce réseau. Voici un traceroute depuis Free :
% traceroute6 www.bortzmeyer.org traceroute to xvm6-fece-1902.ghst.net (2001:4b98:dc0:41:216:3eff:fece:1902) from 2a01:e35:8bd9:8bb0:2cf2:e0fd:cfb3:2e53, port 33434, from port 50724, 30 hops max, 60 byte packets 1 2a01:e35:8bd9:8bb0::1 (2a01:e35:8bd9:8bb0::1) 2.752 ms 3.372 ms 3.013 ms 2 6to4-1-th2-e3.intf.routers.proxad.net (2a01:e00:2:a::2) 24.076 ms 22.391 ms 23.572 ms 3 th2-crs16-1-te1-4-0-2.intf.routers.proxad.net (2a01:e00:2:a::1) 25.504 ms 25.772 ms 24.505 ms 4 free-pni-2.xe3-0-0.tcr1.th2.par.as8218.eu (2001:1b48:2:1::5) 51.469 ms 24.452 ms 22.309 ms 5 e2-1.ter1.th1.par.as8218.eu (2001:1b48:2:210::2) 26.384 ms 26.709 ms 26.382 ms 6 2001:1b48:3:10::2 (2001:1b48:3:10::2) 40.969 ms 39.376 ms 41.073 ms 7 po86-ip6-jd2.core2-d.paris.gandi.net (2001:4b98:86::39) 40.613 ms 43.533 ms 41.934 ms 8 vl2-ip6.dist1-d.paris.gandi.net (2001:4b98:2::40) 33.785 ms 36.439 ms 35.686 ms 9 xvm6-fece-1902.ghst.net (2001:4b98:dc0:41:216:3eff:fece:1902) 37.401 ms 37.709 ms 42.030 ms
À noter qu'il ne semble hélas pas y avoir de peering IPv6 entre Free et Gandi.
L'article seul
RFC 6049: Spatial Composition of Metrics
Date de publication du RFC : Janvier 2010
Auteur(s) du RFC : A. Morton (AT&T Labs), E. Stephan (France Telecom Division R&D
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 4 janvier 2011
Prenant la suite du RFC 5835, ce nouveau RFC du groupe de travail IPPM définit la composition spatiale des métriques, ou comment passer des mesures faites sur des parties du chemin d'un paquet à la mesure sur le chemin complet.
Déjà, le RFC 2330 spécifiait des possibilités de composition temporelle et spatiale des mesures faites sur le réseau. Le RFC 5835 définissait ensuite plus rigoureusement le cadre général des compositions de mesures. Il posait des exigences comme, par exemple, le fait qu'une fonction de composition devait spécifier si les mesures partielles étaient faites avec les mêmes paquets ou pas (cf. section 2.2). Finalement, notre RFC 6049 précise ce cadre pour les compositions dans l'espace : si un paquet se promène sur l'Internet et va de A à C en passant par B, peut-on composer deux mesures, faites de A à B et de B à C, en une mesure pour le chemin complet, de A à C ? Et, si oui, comment ?
D'abord, pourquoi cet exercice ? Juste pour le défi intellectuel ? Non, dit la section 1.1, il existe des raisons pratiques à cette composition. Les RFC qui définissent les métriques, comme le RFC 7679 sur le délai d'acheminement d'un paquet ou bien le RFC 7680 sur le taux de pertes de paquets tiennent pour acquis qu'on a un accès complet à la source et à la destination et qu'on peut donc effectuer une mesure de bout en bout. Mais, parfois, ce n'est pas possible, par exemple parce que le chemin franchit une frontière administrative, et on n'a parfois que la possibilité de mesurer des sous-chemins (comme dans l'exemple de A à C ci-dessus). La composition spatiale devient alors un moyen de calculer la mesure sur le chemin complet.
Dans le futur, on pourrait même imaginer d'autres possibilités comme, dans le cas où on n'a pas de mesure pour un des sous-chemins, de calculer la valeur à partir de la mesure du chemin complet et des mesures sur les autres sous-chemins (« soustraction » et non plus « addition »). Mais cette possibilité n'est pas encore définie par le RFC (cf. section 2.1 et 2.3, qui pose que, pour l'instant, si la mesure n'a pas été faite sur un des sous-chemins, c'est le résultat entier qui est indéfini).
Pour définir les compositions elles-mêmes, le RFC procède en deux temps. La section 3 définit les paramètres communs à toutes les métriques et les sections suivantes définissent les paramètres spécifiques aux trois métriques retenues, le délai d'acheminement, le taux de pertes et la variation du délai.
Parmi les paramètres génériques, on peut citer par exemple (section 3.1.8), les causes possibles de déviation par rapport à la vérité de base (section 3.7) du RFC 5835. Ainsi, lorsqu'on mesure sur une partie du chemin, rien ne garantit que les paquets suivront le même chemin que si on mesure sur le chemin complet, en raison, entre autres, de l'ECMP. Sans compter le fait que, si les mesures ne se font pas au même moment, le routage a pu changer entre la mesure d'un sous-chemin et celle du chemin complet.
Les trois métriques spécifiques suivent cet exposé des paramètres génériques. La première est le délai d'acheminement (RFC 7679). D'abord, avant de composer de tels délais, la section 4.1 définit la notion de Type-P-Finite-One-way-Delay-<Sample>-Stream qui est une réduction d'une série de mesures, excluant celles où le paquet n'est pas arrivé (cela permettra de calculer des choses comme la moyenne). Cette façon de simplifier le problème est analogue à celle du RFC 3393 et est également utilisée dans la Recommandation UIT Y.1540, « Internet protocol data communication service - IP packet transfer and availability performance parameters ».
Armé de cette nouvelle définition, on peut s'attaquer à celle de Type-P-Finite-One-way-Delay-Mean (section 4.2). Informellement, c'est simplement la moyenne des délais. Et, finalement, on en arrive à la fonction composée, Type-P-Finite-Composite-One-way-Delay-Mean, qui est simplement la somme des moyennes des délais, somme prise sur tous les sous-chemins. Pour prendre un exemple trivial, si un paquet met en moyenne 0,12 ms pour aller de A à B et 0,05 ms pour aller de A à C, alors la Type-P-Finite-Composite-One-way-Delay-Mean sur le chemin de A à C (s'il passe par B, bien sûr), sera de 0,17 ms. Naturellement, cela suppose que le nombre de paquets utilisé pour calculer la moyenne sur chaque sous-chemin soit suffisant pour qu'on ait une valeur représentative. Il y a aussi d'autres conditions : par exemple, si la distribution des paquets sur un sous-chemin est multi-modale, la moyenne ne voudra pas dire grand'chose.
Comme on a défini une moyenne, on peut définir un minimum (section 4.3). Type-P-Finite-Composite-One-way-Delay-Minimum est la somme des délais minimaux d'acheminement sur chaque sous-chemin. Si on a fait trois tests et que le trajet de A à B a pris 0,12, puis 0,16 puis enfin 0,1 ms, et que celui de B à C a pris 0,05 ms à chaque fois, le Type-P-Finite-Composite-One-way-Delay-Minimum vaut 0,1 + 0,05 = 0,15 ms. On voit que cela suppose que les délais des sous-chemins sont indépendants, ce qui est raisonnable.
Cela, c'était pour le délai d'acheminement, pour lequel on a défini deux fonctions de composition, pour la moyenne et pour le minimum. La section 5 passe au taux de pertes de paquet. En partant de la définition de la perte Type-P-One-way-Packet-Loss du RFC 7680, on peut définir une probabilité de pertes, Type-P-One-way-Packet-Loss-Empirical-Probability puis une composition de cette probabilité, Type-P-Composite-One-way-Packet-Loss-Empirical-Probability. La définition est un peu plus compliquée que pour les compositions précédentes mais, de manière résumée, la probabilité de survie sur le chemin complet est le produit des probabilités de survie sur chaque sous-chemin. Comme la probabilité de perte est 1 - la probabilité de survie, le calcul est facile à faire.
Toutes ces métriques (je n'ai pas détaillé la troisième, présentée en section 6) ont été enregistrées dans la MIB qui sert de registre des métriques (cf. RFC 4148).
L'article seul
Fiche de lecture : Le président des riches
Auteur(s) du livre : Michel Pinçon, Monique Pinçon-Charlot
Éditeur : Zones / La découverte
978-2-35522-018-0
Publié en 2010
Première rédaction de cet article le 2 janvier 2011
Les sociologues Michel Pinçon et Monique Pinçon-Charlot sont désormais à la retraite et leur dernier livre, « Le président des riches », est nettement moins technique que les précédents (comme l'excellent « Les ghettos du gotha ») et plus militant. Il s'agit d'expliquer le fonctionnement de la présidence Sarkozy et de la façon dont le gouvernement de ce dernier pratique une politique pro-riche (ce qui n'est pas nouveau) et s'en vante lourdement (c'est, par contre, une innovation).
Michel Pinçon et Monique Pinçon-Charlot décrivent en détail plusieurs affaires emblématiques de la France de Sarkozy : le bouclier fiscal, la gestion de l'EPAD (où la nomination du fils à papa n'était que l'aspect le plus spectaculaire mais pas forcément le plus important), la gestion de la publicité sur les chaînes de télévision publiques, le cumul d'une activité politique et d'une activité d'avocat d'affaires par Sarkozy, la soi-disant suppression des paradis fiscaux, etc. À chaque fois, un lien directeur, « Les riches, premiers servis ». Si cette politique n'est pas originale (et les auteurs notent qu'il y a peu de chances que le Parti Socialiste fasse différemment, s'il arrive au pouvoir), Sarkozy est de loin le président qui l'a revendiqué le plus ouvertement, gênant même les familles riches traditionnelles par sa grossièreté de nouveau riche bling-bling (« Si on n'a pas une Rolex à cinquante ans, on a raté sa vie », comme le dit un de ses fidèles soutiens).
Michel Pinçon et Monique Pinçon-Charlot font un utile travail de retour sur les événements lorsqu'il s'agit de sujets sur lesquels les annonces sensationnalistes avaient rarement été suivies de bilans précis. Ainsi, bien que Sarkozy ait annoncé en octobre 2009 qu'il avait supprimé les paradis fiscaux, peu de journalistes sont allés enquêter un ou deux ans après : ils auraient pourtant pu constater que les supprimés étaient bien actifs comme avant... De même, leur étude très fouillée de la gestion de la Défense montre que la candidature ridicule et népotiste de Jean Sarkozy a aussi servi de cirque médiatique, permettant de masquer la mainmise de l'État et de la Sarkozie sur le site et sur les communes environnantes, dépouillées de toute prérogative dans la gestion de leur propre territoire.
Que faire, se demandent les auteurs à la fin ? Simplement faire comme les riches, la seule classe sociale qui applique strictement les principes marxistes-léninistes : conscience de soi, réglement des conflits en interne (avez-vous vu comme l'affaire Bettencourt a disparu des gros titres ?), parti politique représentant ses intérêts, militantisme très actif dans tous les lieux de pouvoir possibles... Si les autres classes sociales faisaient preuve de la même solidarité, le changement serait possible.
L'article seul
Fiche de lecture : In the land of invented languages
Auteur(s) du livre : Arika Okrent
Éditeur : Spiegel & Grau
978-0-385-52788-0
Publié en 2009
Première rédaction de cet article le 1 janvier 2011
Il y a déjà eu plusieurs livres consacrés aux langues construites, ces langues créées de toutes pièces pour essayer d'effacer Babel, pour faire progresser la science, ou tout simplement par intérêt intellectuel. Le livre d'Arika Okrent, écrit par une linguiste mais accessible à tous, se distingue par un ton léger, plein d'anecdotes amusantes mais aussi une réflexion sur ce processus de création. L'auteur a de la sympathie pour les inventeurs mais aucune illusion quant à leurs chances de succès : inventer une langue est une chose, faire qu'elle soit adoptée en est une autre. D'autant plus que bien des inventeurs, tout à leur passion, en oublient la simple utilisabilité... Et qu'ils ont souvent une approche trop rationnelle, croyant qu'une langue est meilleure si on la conçoit scientifiquement, sans se demander si les bizarreries des langues naturelles ne sont pas indissociables de leur utilité.
Depuis la première que l'histoire a enregistré, la Lingua Ignota d'Hildegarde de Bingen, il y a eu tellement eu de langues construites qu'on ne peut pas les mentionner toutes. Dans son court livre, Okrent se focalise sur quelques langues :
- La langue philosophique de John Wilkins, basée sur une stricte classification des concepts, dont Borges s'est moqué dans un texte fameux,
- L'espéranto, de loin la langue construite la plus parlée,
- Le langage de symboles de Bliss,
- Le Loglan de James Brown, qui a ensuite donné naissance au Lojban,
- Le Klingon, au succès relatif mais paradoxal, pour une langue qui, contrairement à presque toutes les autres, n'avait pas été conçue pour être adoptée.
L'auteur a à chaque fois essayé d'apprendre la langue en question et d'écrire au moins un court texte. Ses récits de débutante sont la meilleure part du livre. Ce n'était pas un apprentissage facile car certaines de ces langues n'ont manifestement jamais été testées par leur concepteur avant d'être publiées. Okrent compare ainsi le fait de parler en Lojban à de la programmation plus que de la conversation : il faut très soigneusement réflechir à chaque détail de la phrase, tout a son importance, mais lorsqu'on y arrive, on est très fier.
Mais les langues construites sont aussi une aventure humaine et Arika Okrent décrit sans complaisance les inventeurs, dont certains poussaient très loin la trollitude. C'est ainsi que James Brown, par exemple, kidnappera son enfant suite à une dispute conjugale, et lui déniera tout contact avec sa mère pendant des années. D'autre part, et comme Charles Bliss, il passera l'essentiel de son temps à faire des procès à tous ceux qui essayaient d'adopter son système, en décourageant ainsi la plupart (c'est de là que vient la création du Lojban, Brown ayant déposé la marque Loglan...)
Depuis qu'on crée des langues, y a-t-il eu des changements ? Oui, dit l'auteur : elle distingue trois phases dans la riche histoire des langues construites. La première, vers les 17ème et 18ème siècles, nourrie de la Raison, a essayé de construire une langue qui exprimerait parfaitement les concepts. L'idée-force de cette phase, dont le meilleur représentant était Wilkins, était que les langues naturelles sont un obstacle à la communication par leur manque de précision (par exemple, un mot peut signifier plusieurs choses) et que la langue parfaite devait être conçue en commençant par une tentative (héroïque mais évidemment vaine) de classifier tous les concepts possibles (des plus concrets aux plus abstraits), concepts qu'il suffirait ensuite d'utiliser.
La seconde phase, essentiellement vivante au 19ème siècle et connue surtout par le volapük et l'espéranto, est plus pragmatique : il ne s'agit plus de faire une langue parfaite mais de faire une langue qui soit utilisable par tous. L'idée est politique : si les hommes parlent la même langue, ils se feront moins la guerre. Cette idée très 19ème, période de guerres violentes entre les États-nations en construction ou déjà établis, se comprend mieux lorsqu'on sait que dans la ville natale de Zamenhof, quatre communautés linguistiques étaient présentes, et pas dans une bonne entente...
Contrairement aux concepteurs de la première phase, qui se focalisaient sur la perfection de leur œuvre, l'adoption devant ensuite suivre naturellement, ceux de la deuxième phase ont une approche plus militante et passent beaucoup de temps, à promouvoir leur langue, par l'exemple et la conviction.
Et la troisième phase ? Présente essentiellement au 20ème siècle, elle a souvent renoncé à avoir trop d'ambitions : désormais, l'adoption par les masses est secondaire, on conçoit des langues pour s'amuser, pour tester une idée scientifique (ce fut le cas du Loglan), pour une série télévisée (le Klingon). Loin des anciennes rivalités entre langues construites (chacune essayant d'attirer davantage de locuteurs), cela devient même un sujet de rassemblement, comme les conférences de conlangers, où on échange sur les meilleures techniques de création de langues...
Parmi les autres ouvrages sur le sujet des langues construites, on cite souvent « La quête d'une langue parfaite dans l'histoire de la culture européenne » d'Umberto Eco mais je ne l'ai pas encore lu...
L'article seul
Articles des différentes années : 2026 2025 2024 2023 2022 2021 2020 Précédentes années
Syndication : Flux Atom avec seulement les résumés et Flux Atom avec tout le contenu.
{kind=link}