
Les RFC (Request For Comments) sont les documents de référence de l'Internet. Produits par l'IETF pour la plupart, ils spécifient des normes, documentent des expériences, exposent des projets...
Leur gratuité et leur libre distribution ont joué un grand rôle dans le succès de l'Internet, notamment par rapport aux protocoles OSI de l'ISO organisation très fermée et dont les normes coûtent cher.
Je ne tente pas ici de traduire les RFC en français (un projet pour cela existe mais je n'y participe pas, considérant que c'est une mauvaise idée), mais simplement, grâce à une courte introduction en français, de donner envie de lire ces excellents documents. (Au passage, si vous les voulez présentés en italien...)
Le public visé n'est pas le gourou mais l'honnête ingénieur ou l'étudiant.
RFC 2993: Architectural Implications of NAT
Date de publication du RFC : Novembre 2000
Auteur(s) du RFC : T. Hain (Microsoft)
Pour information
Première rédaction de cet article le 19 septembre 2013
Ce RFC est la synthèse (vieille de treize ans, mais toujours juste) de l'analyse architecturale du NAT par l'IETF. Elle décrit les conséquences du NAT pour l'Internet et appelle à considérer son usage avec prudence (comme chacun peut le voir, cet appel n'a pas été entendu). C'est le document à lire pour avoir une vision de haut niveau du NAT.
Techniquement, le NAT a été décrit en 1994 dans le RFC 1631 (et dans le RFC 2663). Cette méthode était un des moyens envisagés pour gérer le problème de l'épuisement des adresses IPv4. Mais le RFC 1631 appelait à la prudence : « NAT has several negative characteristics that make it inappropriate as a long term solution, and may make it inappropriate even as a short term solution. » Entre le RFC 1631 et ce RFC 2993 (et encore plus depuis), la traduction d'adresses a été très largement déployée, sans tenir compte de ses inconvénients. Cassandre n'est jamais écoutée... Il avait même été question d'arrêter le développement et le déploiement d'IPv6, avec l'argument que le NAT suffisait à résoudre le problème de l'épuisement d'adresses IPv4 (ce point est développé en détail dans la section 8 du RFC). Il est d'autant plus difficile de faire une analyse des avantages et inconvénients du NAT que le débat est souvent très passionnel. Les Pour font remarquer que le NAT fonctionne sans intervention particulière, pour des applications très populaires (comme le Web ou le courrier). Mieux, le NAT résout un vieux problème d'IP, la confusion de l'identificateur et du localisateur : l'adresse IP interne est un identificateur, l'externe un localisateur. Le NAT divise l'Internet, autrefois unifié autour de l'unicité de l'adresse IP, en plusieurs domaines indépendants, chacun ayant son propre espace d'adressage (souvent tiré du RFC 1918). Les Contre reprochent au NAT son caractère de bricolage et sa non-transparence pour beaucoup d'applications, notamment pair-à-pair. En effet, si l'application vérifie que l'en-tête IP reste cohérent (c'est le cas de l'AH d'IPsec, cf. section 9) ou si elle transporte des adresses IP dans ses données (comme le fait SIP, et pour de bonnes raisons), elle ne fonctionnera pas à travers le NAT sans gros efforts de programmation (le principe du NAT est de déplacer les coûts, des FAI vers les programmeurs). Le NAT encourage donc l'ossification de l'Internet vers les seules applications client/serveur. Les Contre notent aussi (RFC 2101) que la division en domaines d'adressage différents font que l'adresse IP cesse d'être unique, et que la résolution d'un nom en adresse donne un résultat qui va dépendre de l'endroit où on pose la question.
Plus fondamentalement, l'Internet repose sur un petit nombre d'excellents principes architecturaux, auxquels il doit son succès, notamment le principe de bout en bout. Ce principe a par exemple pour conséquences qu'il n'y a pas d'état maintenu dans le réseau : un équipement intermédiaire peut redémarrer (et donc tout oublier), un changement de routes peut faire passer par de nouveaux équipements intermédiaires et les extrémités, les machines terminales ne s'apercevront de rien, elles ne connaissaient absolument pas les équipements intermédiaires utilisés. Cela contribue fortement à la résilience du réseau. Le NAT met fin à cela.
J'ai écrit NAT jusqu'à présent mais, en fait, le mécanisme de traduction d'adresse le plus répandu dans l'Internet est plutôt le NAPT (Network Address and Port Translation), c'est à dire qu'il ne traduit pas juste une adresse dans une autre mais un couple {adresse interne, port interne} vers un couple {adresse externe, port externe}. Une grande partie des problèmes qu'on rencontre avec le NAT sont en fait spécifiques au NAPT et n'existeraient pas avec du « vrai » NAT.
Le RFC note que bien des choses qu'on peut dire contre le NAT (cassage du principe de bout en bout, problème pour les applications pair-à-pair) s'appliquent aussi aux pare-feux. La principale différence est que le but explicite d'un pare-feu est de s'insérer sur le trajet et de perturber les communications. En cas de problème, son rôle est donc clair. Au contraire, le NAT est souvent perçu comme transparent, et on oublie plus facilement son rôle, notamment lorsqu'il faut déboguer.
S'appuyant sur le RFC 2663, la section 2 du RFC couvre la terminologie, qui est souvent malmenée lorsqu'il s'agit du NAT :
- NAT (Network Address Translation) est normalement la traduction d'une adresse IP vers une autre. On parle de static NAT lorsque la correspondance entre les deux adresses est fixe et de dynamic NAT lorsqu'elle change automatiquement. Le static NAT nécessite autant d'adresses internes que d'externes et ne règle donc pas le problème de l'épuisement des adresses IPv4.
- NAPT (Network Address Port Translation) est ce que font réellement les routeurs abusivement appelés NAT, comme la box typique de M. Michu. Elle utilise un numéro de port de la couche 4 pour démultiplexer les paquets à destination de l'adresse IP publique.
Pour étudier l'impact du NAT sur l'Internet, il faut d'abord définir ce qu'est l'Internet. La définition du RFC est que l'Internet est une concaténation de réseaux utilisant les technologies TCP/IP. Selon cette définition, le réseau privé d'une entreprise fait partie de l'Internet. Une définition plus restrictive serait de dire que l'Internet est l'ensemble des machines ayant une adresse IP publique, et pouvant donc envoyer un paquet à toute autre machine de l'Internet. Selon cette seconde définition, un réseau utilisant des adresses IP privées (RFC 1918) et connecté via un NAT ne fait pas partie de l'Internet. En effet, comme le pare-feu, le NAT isole le réseau privé et ne permet pas d'accéder à tous les services de l'Internet. Dans cette définition stricte, seul le réseau public est l'Internet (avec un grand I puisque c'est un objet unique comme l'Atlantique ou le Kilimandjaro).
La section 4 rappelle le principe de bout en bout décrit plus haut (ou dans les RFC 1958 ou RFC 2775). Le document de référence sur ce principe est l'article de J.H. Saltzer, D.P. Reed et David Clark, « End-To-End Arguments in System Design ». Que dit ce principe ? Que tout état mémorisé par une machine du réseau doit être dans les extrémités. Si une machine à l'extrémité redémarre, la communication est fichue de toute façon. En revanche, il faut éviter que le redémarrage d'une machine intermédiaire ne coupe la communication. En effet, il y a beaucoup de machines intermédiaires (faites un traceroute pour voir) et, si la panne de l'une d'elles perturbait le trafic, l'Internet serait très fragile. Cela illustre la grande différence entre un routeur normal et un routeur NAT : lorsque le routeur normal redémarre (ou change, parce qu'on passe par un autre chemin), la communication continue. Au contraire, le redémarrage d'un routeur NAT fait perdre la table de correspondance entre les tuples {adresse, port} externes et les internes, arrêtant toutes les sessions en cours.
Quelques conséquences importantes du principe de bout en bout sont donc :
- Pas besoin de synchroniser l'état des différents routeurs dans le réseau : un routeur n'a pas de mémoire. En cas de problème, router par un autre chemin est trivial. (Notez que c'est pour cela que faire du NAT lorsqu'on a plusieurs sorties vers l'Internet est très difficile, car il faut que tous les routeurs NAT se partagent leur table de correspondances externe<->interne.)
- Le nombre de machines terminales croit plus vite que celui des routeurs. Si les routeurs devaient garder un état proportionnel au nombre de machines terminales, le réseau passerait bien moins à l'échelle.
- L'absence d'état et, plus généralement d'« intelligence » dans les routeurs, fait que les décisions de sécurité n'ont pas besoin d'être gérées par le réseau. Deux machines qui communiquent s'occupent de leur sécurité et n'ont pas à faire confiance aux équipements intermédiaires. C'est important, par exemple, lorsqu'on voyage, et qu'on ne peut pas être sûr de la confiance à accorder au réseau de l'hôtel ou de l'aéroport.
- Le point ci-dessus s'applique à tous les services : l'absence d'intelligence dans le réseau (qui est liée d'ailleurs à l'idée plus récente de neutralité du réseau) permet à deux machines consentantes de mettre en œuvre des nouveaux services, sans devoir attendre que quoi que ce soit ait été déployé dans le réseau. Un réseau où une grande partie du travail serait faite dans le réseau lui-même et pas aux extrémités, serait très hostile à l'innovation. Au contraire, le succès de l'Internet est dû en grande partie à la possibilité de déployer de nouvelles applications sans permission. (Et je rajoute que l'un des principaux problèmes de l'Internet d'aujourd'hui est son ossification, due largement au NAT, qui empêche de déployer, par exemple un nouveau protocole de transport comme SCTP.)
Les deux sections suivantes sont consacrées à une mise en comparaison des avantages et inconvénients du NAT (la section 11, en conclusion, les résumera sous forme d'un tableau simple). D'abord, en section 5, ses avantages, dans la résolution de plusieurs problèmes réels :
- En masquant les adresses IP internes aux observateurs extérieurs, il permet de se dispenser de renumérotation lorsqu'on change d'opérateur (le RFC 5887, par la suite, a analysé la difficulté de la renumérotation).
- En cas d'usage intermittent, le NAT permet d'économiser les adresses IP globales en ne les attribuant qu'en cas d'usage effectif. (Cet argument n'a plus guère de sens aujourd'hui, avec les accès « always on » comme l'ADSL.)
- L'usage d'adresses privées, auto-allouées localement par l'utilisateur, dispense de justifier, auprès d'une grosse bureaucratie, l'obtention d'adresses IP uniques.
- Pour beaucoup d'applications, notamment celles de type client/serveur, aucun changement n'est nécessaire dans les machines terminales lorsqu'on déploie le NAT.
Toutes ces raisons expliquent le succès du NAT.
Et les inconvénients ? La section 6 en dresse une liste :
- Le NAT casse le principe de bout en bout.
- Le NAT remplace un modèle simple par un modèle plus complexe, plus fragile et plus difficile à déboguer.
- Il crée un SPOF (le redémarrage du routeur NAT coupe toutes les sessions de toutes les machines du réseau local). Ce point est détaillé dans la section 7.1.
- Il perturbe des techniques de sécurité comme le AH d'IPsec (RFC 4302). Pour cette raison, mais aussi pour d'autres, AH n'a guère été déployé et cet argument n'est donc peut-être pas le plus fort (alors que le RFC, à l'époque, le considérait comme « One of the greatest concerns »).
- Les adresses privées semblent très sympas au début (on se les alloue soi-même sans s'embêter et sans rien demander à personne) mais sont une grosse source d'ennuis lorsque deux réseaux privés communiquent, par exemple suite à une fusion d'entreprises, ou si on se connecte à deux réseaux distants utilisant la même plage d'adresses (la section 7.6 donne un exemple).
- Le NAT casse les protocoles qui ont une connexion de contrôle séparée de la connexion de données, ce qui est fréquent dans le multimédia (SIP, H.323, et tous les protocoles qui fonctionnent en indiquant une référence à une machine tierce). La connexion de données se fait typiquement en utilisant des adresses IP indiquées par le pair... qui ne marcheront pas car ce sont des adresses privées, le pair ne savait pas qu'il était NATé.
- Le NAT augmente la complexité de la connexion : c'est un facteur de plus à prendre en compte lorsqu'on débogue.
- Les connexions entrantes sont impossibles par défaut (ce qui pose problème si on veut héberger un serveur sur le réseau local). On peut sur les routeurs NAT typiques définir une correspondance d'un port bien connu (par exemple 80 pour HTTP) vers une machine interne mais cela ne permet qu'un seul serveur pour chaque port bien connu.
- Depuis l'écriture de ce RFC 2993, UPnP, puis le PCP (Port Control Protocol) du RFC 6887, ont facilité un peu la vie des applications coincées derrière un routeur NAT, en leur permettant un contrôle limité des correspondances statiques entre {adresse, port} externes et internes.
Il y a aussi des inconvénients plus techniques, comme le fait que le
délai d'attente de TCP avant de réutiliser un
identificateur de connexion (l'état TCP_TIME_WAIT)
peut vite être trop long pour un routeur NAT actif, le soumettant à
la tentation d'ignorer ce délai minimum (deux fois la durée de vie
d'un segment dans le réseau, normalement).
Par contre, ce RFC oublie un inconvénient important du NAPT (mais pas du NAT) : le partage d'adresses IP publiques, dont les conséquences négatives ont été analysées onze ans plus tard dans le RFC 6269.
La question de la sécurité du NAT occupe la section 9. C'est un point d'autant plus important que certaines personnes prétendent parfois que le NAT améliore la sécurité. En fait, notre RFC note que cela peut être tout le contraire, en créant l'illusion d'une barrière, d'un pare-feu, le NAT peut abaisser le niveau de sécurité. Le RFC critique aussi cette idéologie du pare-feu, qui considère que toutes les menaces sont externes, dans le style du limes romain. Si on pense qu'on est protégé derrière son routeur NAT, c'est qu'on ignore une règle de base de la sécurité, qui est que l'attaque vient souvent de l'intérieur.
Si le NAT, par définition, casse les techniques de sécurité qui protègent l'intégrité du paquet, comme l'AH d'IPsec, d'autres techniques de sécurité peuvent passer malgré le NAT. C'est le cas de TLS ou de SSH. Notez que ces techniques fonctionnent dans la couche 7 et restent donc vulnérables à des attaques qu'IPsec aurait empêchées, comme les resets TCP (cf. RFC 2385).
La section 10 contient quelques conseils de déploiement, pour le cas où on décide de faire du NAT. Le RFC recommande de chercher un mécanisme de résolution de noms qui gère le fait que les adresses soient différentes en interne et en externe, et suggère qu'un serveur DNS intégré au routeur NAT est sans doute dans la meilleure position pour faire cela. Il insiste sur le déploiement d'ALG pour les applications qui ne passent pas à travers le NAT (ou bien l'établissement d'un tunnel au dessus du NAT). Il fait remarquer (c'était une idée novatrice à l'époque) qu'il existe plein de variantes de NAPT, avec des comportements différents. Par exemple, si une application émet un paquet depuis le tuple {adresse interne, port interne} vers une destination extérieure, son tuple interne va être réécrit en {adresse externe, port externe}. Si cette application écrit ensuite à une autre destination extérieure, depuis le même tuple {adresse interne, port interne}, celui-ci sera t-il réécrit dans le même tuple {adresse externe, port externe} ou pas ? Tous les routeurs NAT n'ont pas forcément le même comportement sur ce point, et cela influe beaucoup sur les chances d'une application de passer à travers le NAT (RFC 4787).
Le RFC a aussi des suggestions plus surprenantes comme l'idée d'un registre des adresses privées, pour diminuer les risques de collision dans le cas où un client a des VPN vers deux réseaux privés utilisant la même plage d'adresses. Si cela a un sens au sein d'une même organisation (dont on peut espérer qu'elle a déjà un plan d'adressage cohérent, évitant les collisions), l'idée d'un registre plus large va à l'encontre du principe des adresses privées.
Depuis la sortie de ce RFC, l'IETF a accepté le principe d'un travail pour limiter les dégâts du NAT, le groupe de travail Behave, qui a produit plein d'excellents RFC. L'idée même d'un tel travail gênait certains à l'IETF, car ils pensaient qu'améliorer le NAT allait retarder son démantèlement souhaitable. Mais la prévalence du NAT a conduit à une position de compromis, avec un certain nombre de techniques permettant de vivre avec le NAT.
En résumé, ce RFC est hostile à la généralisation du NAT, non pas en disant qu'il ne marche pas (« it is possible to build a house of cards ») mais en notant qu'il restera toujours un bricolage fragile. Le problème de l'épuisement des adresses IPv4 doit se résoudre par le déploiement d'IPv6, pas par le NAT. On notera que cet avis n'a pas été suivi dans les treize années écoulées depuis la parution de ce RFC : l'IETF peut dire ce qu'elle veut, cela ne change rien en pratique. Les décisions ne sont pas prises par elle.
L'article seul
RFC 2923: TCP Problems with Path MTU Discovery
Date de publication du RFC : Septembre 2000
Auteur(s) du RFC : K. Lahey
Pour information
Première rédaction de cet article le 16 janvier 2008
Au moment de sa nomalisation, dans le RFC 1191, la découverte de la MTU du chemin semblait une excellente idée, en permettant d'adapter la taille des paquets IP de façon à minimiser la fragmentation. Mais plusieurs problèmes sont surgis à l'usage, notre RFC faisant la liste de ceux qui affectent plus particulièrement TCP.
Pour chaque problème, notre RFC donne un nom, décrit la question, fournit des traces tcpdump et suggère des pistes pour la résolution. Le plus fréquent des problèmes n'est pas spécifique à TCP, c'est le trou noir (section 2.1). Comme la découverte de la MTU du chemin repose sur des paquets ICMP indiquant que le paquet TCP était trop grand pour le lien, tout ce qui empêche de recevoir ces paquets ICMP perturbera la découverte de la MTU. Les paquets TCP seront abandonnés par les routeurs mais on ne verra pas pourquoi, d'où le nom de trou noir.
Qu'est-ce qui peut créer un trou noir ? Il existe plusieurs raisons (le RFC 1435 en donne une particulière) mais la plus fréquente, de loin, est l'ignorance abyssale de certains administrateurs de coupe-feux, qui bloquent complètement tout ICMP pour des « raisons de sécurité » en général fumeuses (un bon test pour détecter cette ignorance est de leur demander si le ping of death est spécifique à ICMP. S'ils disent oui, cela montre qu'ils n'ont rien compris.)
Le problème est suffisamment répandu pour qu'il ai fallu développer un nouveau protocole, où TCP fait varier la taille des paquets pour voir si les gros ont davantage de pertes, protocole décrit dans le RFC 4821. Ce protocole a été développé bien après notre RFC 2923, qui donne des conseils en ce sens mais fait preuve de prudence en craignant que, si les mises en œuvre de TCP réparent ce genre de problèmes, la cause (le filtrage d'ICMP) risque de demeurer (la section 3 revient sur cette question).
Ce débat est récurrent à l'IETF. Faut-il pratiquer la politique du pire, en refusant de contourner les erreurs de configuration (tenter de faire corriger les sites mal configurés est une entreprise courageuse, voire folle), ou bien faut-il essayer de réparer ce qu'on peut, au risque de diminuer la pression sur ceux qui ont fait ces erreurs ?
D'autres problèmes sont, eux, réellement spécifiques à TCP comme les acquittements retardés (section 2.2) provoqués par un envoi des acquittements TCP en fonction de la MSS, qui peut être bien plus grande que la MTU du chemin (cf. RFC 2525). Ce problème n'a pas de solution simple et unique.
Un autre problème lié à la MSS est la détermination de celle-ci (section 2.3). Une implémentation naïve qui déduirait le MSS à partir de la MTU du chemin annoncerait une MSS trop faible et, surtout, ne pourrait pas l'augmenter si un nouveau chemin apparait. La solution est de déduire la MSS de la MTU du réseau local (qui est stable), pas de la MTU du chemin (RFC 1122).
L'article seul
RFC 2914: Congestion Control Principles
Date de publication du RFC : Septembre 2000
Auteur(s) du RFC : S. Floyd (ACIRI)
Première rédaction de cet article le 10 septembre 2007
L'Internet ne continue à fonctionner que parce que chaque machine qui y est connectée « fait attention », entre autre parce que les logiciels qui y sont installés essaient d'éviter de congestionner le réseau. Sur quels principes repose ce contrôle de la congestion ?
D'abord, ce contrôle de congestion n'est pas fait par IP (et donc pas par les routeurs) mais dans les protocoles au dessus, TCP étant le plus utilisé. Le contrôle de congestion est donc de bout en bout entre deux machines qui communiquent et n'est pas du ressort du réseau lui-même. Cela le rend très souple et très adapté à l'innovation mais cela met une lourde responsabilité sur chaque machine de l'Internet. Comme discuté dans la section 3.2 du RFC, une machine incivile qui voudrait s'allouer le maximum de bande passante peut le faire. Et, pour l'instant, il n'existe pas de protocoles IETF pour détecter ce comportement (certains travaux de recherche ont eu lieu sur ce sujet).
Le plus gros risque si le contrôle de congestion défaillait, risque décrit dans la section 3.1, ainsi que dans la section 5, est celui d'effondrement : dans un effondrement dû à la congestion, le débit diminue si on augmente le nombre de paquets. Le réseau passe alors tout son temps à tenter de transmettre des paquets qui seront finalement perdus, retransmis, le tout sans bénéfice pour personne. L'Internet est passé plusieurs fois près de l'effondrement (cf. RFC 896, qui était également le premier à pointer le danger des machines inciviles ou boguées, qui ne réagissent pas en cas de congestion) et seule l'amélioration continue des protocoles de transport a permis de continuer la croissance du trafic.
En effet, à partir de 1986, TCP a commencé, notamment sous l'impulsion de Van Jacobson, à prêter sérieusement attention à la congestion (voir le RFC 2001 pour une description a posteriori de cet effort), notamment via le mécanisme de retraite, où l'émetteur cherche s'il y a congestion et ralentit son débit si c'est le cas.
Aujourd'hui, tout flot de données (un flot n'a pas de définition unique et rigoureuse, disons que c'est un ensemble de paquets appartenant au même échange de données, et gérés ensemble, pour ce qui concerne la congestion) doit mettre en œuvre des techniques de détection et de réponse à la congestion. Pour une application utilisant TCP, c'est fait automatiquement dans ce protocole mais une application utilisant UDP doit s'en charger elle-même. (D'autres RFC sont sortis depuis comme le RFC 5681 pour TCP.)
Outre l'effondrement, l'absence de contrôle de congestion présente un autre risque, qui fait l'objet de la section 3.2, le risque d'injustice. Si plusieurs flots se battent pour une bande passante limitée, le risque est que le mauvais citoyen, qui ne diminue pas son débit en cas de congestion, emporte une plus grosse part du gâteau que les autres. Une implémentation de TCP qui se comporterait ainsi pourrait même permettre à son vendeur de prétendre qu'il a un « TCP accéléré ». C'est une méthode analogue, mais au niveau applicatif, qu'avait utilisé le navigateur Web Netscape 1, en ouvrant plusieurs connexions TCP simultanées vers le même serveur HTTP.
La section 6 de notre RFC est ensuite dédiée aux démarches à adopter : avoir un contrôle de congestion est la principale. La section 9, en annexe, décrit plus spécifiquement les responsabilités de TCP. De nombreux RFC (par exemple le RFC 4907), référencent ce document, auquel tous les nouveaux protocoles doivent se conformer. Mais, en 2011, la question du contrôle de la congestion restait toujours largement ouverte, comme le montre le RFC 6077.
L'article seul
RFC 2889: Benchmarking Methodology for LAN Switching Devices
Date de publication du RFC : Août 2000
Auteur(s) du RFC : R. Mandeville (CQOS), J. Perser (Spirent)
Pour information
Première rédaction de cet article le 8 mai 2007
Dans la série des RFC traitant de tests de performance, celui-ci couvre les commutateurs.
S'appuyant sur le RFC 2285 qui décrit la terminologie et sur le RFC 2544, plus général, notre RFC est consacré à la difficile question des tests de performance des commutateurs.
Il détaille la marche à suivre, les tests auxquels il faut penser (par exemple les différentes tailles de trames recommandées, puisque les performances dépendent souvent de la taille de la trame), les pièges à éviter, etc.
Reste la question : est-il réellement utilisé ? Il semble que peu de tests comparatifs de commutateurs se réfèrent à ce RFC. La plupart de ceux qui le citent ont été réalisés par Spirent, la société d'un des auteurs, ou par les outils développés par cette société. On est encore loin d'une standardisation des tests de perfomance.
L'article seul
RFC 2870: Root Name Server Operational Requirements
Date de publication du RFC : Juin 2000
Auteur(s) du RFC : R. Bush (Verio), D. Karrenberg (RIPE
NCC), M. Kosters (Network Solutions), R. Plzak (SAIC)
Première rédaction de cet article le 11 février 2007
Très ancien, et remplacé depuis par le RFC 7720, ce RFC a longtemps été le seul document qui décrive les obligations techniques des serveurs de la racine du DNS.
L'attaque (largement ratée) menée contre les serveurs de la racine le 6 février 2007 est l'occasion de relire ce RFC, écrit pourtant à une époque où la configuration technique de ces serveurs était bien différente. Au moment de la sortie de ce RFC, l'ICANN et son Root Server System Advisory Committee étaient des créations récentes.
Notre RFC ne veut pas donner d'avis trop détaillé, par exemple sur le matériel nécessaire, conscient que de tels conseils se démodent très vite. Néanmoins, aujourd'hui, bien des conseils du RFC paraissent très anciens comme la recommandation de dimensionner le serveur pour résister à trois fois sa charge normale (les attaques récentes étaient plutôt de cinquante fois la charge normale).
La plupart des conseils donnés sont de simple bon sens, et peuvent s'appliquer à bien d'autres serveurs Internet comme le conseil de ne pas faire tourner de services réseau inutiles. Bref, une bonne check-list mais probablement insuffisante pour faire face aux défis d'aujourd'hui.
Karl Auerbach avait tenté de spécifier plus formellement les obligations des serveurs racine, en prenant exemple sur les SLA. Mais, pour l'instant, la ressource la plus critique de l'Internet continue à fonctionner de manière informelle.
L'article seul
RFC 2865: Remote Authentication Dial In User Service (RADIUS)
Date de publication du RFC : Juin 2000
Auteur(s) du RFC : C. Rigney, S. Willens, A. Rubens, W. Simpson
Chemin des normes
Première rédaction de cet article le 31 janvier 2008
Radius, normalisé dans ce RFC, est un protocole très simple d'AAA, conçu pour des serveurs d'accès à l'Internet (NAS, Network Access Server ou Access Point, ce dernier terme étant davantage utilisé dans le monde du sans-fil) qui sous-traitent l'authentification des utilisateurs à un serveur Radius. La machine qui accède à Internet n'a donc pas besoin de Radius, ce protocole ne sert qu'entre le NAS et le serveur d'authentification.
Radius fait partie de la famille des protocoles simples, certains disent simplistes, qui font peu de choses mais les font bien et, comme résultat, sont indélogeables. Normalisé d'abord dans le RFC 2058, puis le RFC 2138, il est désormais défini par notre RFC. Son principe est simple : lorsqu'une machine cliente se connecte au serveur d'accès (le NAS), ce dernier envoie un paquet UDP au serveur d'authentification, paquet qui contient l'information sur le client (et, dans le cas le plus simple, le mot de passe que celui-ci a indiqué). Le serveur d'accès est donc client Radius. Le serveur Radius répond par une acceptation ou un refus, accompagné, si c'est une acceptation, par la valeur de certaines options de configuration (par exemple une adresse IP).
La section 2 du RFC décrit plus en détail ce modèle. Le client Radius doit mettre dans la requête toute l'information nécessaire (nom ou NAI de l'utilisateur, numéro de port du NAS, etc). Il est également responsable, comme pour le DNS, de la réémission des demandes, s'il n'y a pas de réponse (UDP ne garantit en effet pas la délivrance des requêtes). Le RFC précise que le serveur ne doit accepter que les clients connus, configurés avec un secret partagé, il n'existe pas de serveur Radius public. Le serveur Radius authentifie ensuite l'utilisateur par les mécanismes de son choix (les bons serveurs Radius offrent d'innombrables techniques d'authentification).
La section 2.1 explique comment Radius peut être utilisé même si la requête ne contenait pas tous les éléments pour l'authentification, par exemple parce qu'on a choisi d'utiliser une authentification défi/réponse. Radius permet de transmettre le défi au client.
La section 2.4 est d'explication : elle donne les raisons pour lesquelles UDP a été choisi comme protocole de transport, choix qui a beaucoup été critiqué.
La section 3 est consacré au format de paquet, la 4 décrivant en
détail les
différents types de paquet (notamment Acceptation et Rejet). Radius
utilise les ports suivants (extraits d'un /etc/services) :
radius 1812/udp radius-acct 1813/tcp radacct
C'est également cette section qui décrit le secret que partagent le client et le serveur Radius, secret qui servira notamment à xorer le mot de passe de l'utilisateur (section 5.2) pour se protéger contre l'espionnage de la ligne.
La section 5 liste tous les attributs standard, mais Radius est extensible et permet d'en décrire d'autres comme les attributs spécifiquement Microsoft du RFC 2548 ou bien comme le préfixe IPv6 délégué du RFC 4818. Cette extensibilité est une des propriétés les plus importantes de Radius.
Un des attributs les plus répandus est
User-Name (type 1), décrit dans la section
5.1. Sa valeur est le nom de l'utilisateur (par exemple
p.dupont) ou bien son NAI
(RFC 7542, par exemple stephane@gold.example.net). Si c'est un nom, il est stocké en
UTF-8 (les précédentes versions de Radius
n'acceptaient que l'ASCII).
L'attribut Service-Type (section 5.6), permet
de demander un service particulier, par exemple que le NAS rappelle
l'utilisateur pour lui épargner les frais de communication (à
Internatif, j'utilisais ainsi, pour les tâches d'administration
système effectuées à distance, la valeur
Callback-Framed à l'époque où le téléphone était
presque toujours facturé à la minuté).
Les attributs sont encodés en TLV.
La section 7 du RFC donne plusieurs exemples d'échanges Radius. Prenons un cas typique :
- L'utilisateur arrive sur le NAS, qui lui demande nom
(
nemo) et mot de passe. - Le NAS, le client Radius,
demande
Access-Request, attributsUser-Name = nemo,User-Password = <masqué par le secret partagé>,Nas-Port = 3(pour le cas où le serveur veuille enregistrer cette information, ou même l'utiliser dans son processus de décision). - Le serveur Radius répond
Access-Accept, avec les attributsService-Type = Framed,Framed-Protocol = PPP(le PPP du RFC 1661),Framed-IP-address = 255.255.255.254(une convention courante pour dire « prends une adresse IP dynamique dans ton pool »),Framed-MTU = 1500. - Le NAS commence alors la négociation PPP avec la machine de l'utilisateur.
Notre RFC 2865 a plusieurs compagnons, notamment le RFC 2866 qui spécifie la comptabilité (le troisième A, Accounting, du sigle AAA), et RFC 2869 le mécanisme d'extensions.
Radius a été très critiqué pour sa simplicité et un protocole concurrent, Diameter, a été développé et décrit dans le RFC 3588 (remplacé ensuite par le RFC 6733). Sur le créneau des serveurs d'accès à Internet, Diameter n'a eu aucun succès.
Il existe d'innombrables mises en œuvre de Radius, un protocole qu'on trouve aujourd'hui dans tous les NAS. Radius avait à l'origine été conçu par Livingston (et mes débuts personnels avec Radius, au CNAM, étaient avec un Livingston Portmaster, avant de passer, chez Internatif, à l'US Robotics Total Control) mais est aujourd'hui une norme très répandue. Livingston a depuis été rachetée par Lucent.
Côté serveur Radius, le serveur d'origine, fait par Livingston, est
toujours d'actualité (paquetage radiusd-livingston dans Debian), mais le plus courant est désormais
Free Radius, basé sur la version de
Cistron. Free Radius est
l'Apache des serveurs Radius : très riche en
possibilités, pratiquement tout est configurable.
(Un autre serveur basé sur celui de Cistron, xtradius ne semble plus maintenu, il est par exemple très bogué sur machines 64bits.)
Côté client (NAS), voici par exemple comment se configure un
Cisco en client Radius du serveur 192.168.8.8 :
radius-server host 192.168.8.8 auth-port 1812 key THESHAREDSECRET aaa group ...
Si le NAS est une machine Unix, elle peut
utiliser le greffon Radius livré avec le démon
pppd, qui permet à pppd d'authentifier avec
Radius.
Pour déboguer le serveur, il vaut mieux utiliser d'abord un
client en ligne de commande, comme le radclient
qu'on trouve avec Free Radius. On peut aussi facilement construire un
client à soi en Python
avec pyrad (le
code d'exemple marche du premier coup). Restons avec radclient :
% echo "User-Name = bortzmeyer\nUser-Password = foobar" | radclient MYRADIUSSERVER auth toto
17:31:54.679926 IP 10.1.82.1.32772 > 10.1.82.2.1812: RADIUS, Access Request (1), id: 0xcd length: 32
et le radius.log du serveur (si on veut déboguer Free Radius, il est recommandé de suivre les conseils en http://wiki.freeradius.org/index.php/FAQ#Debugging_it_yourself) :
Fri Jan 25 17:32:21 2008 : Error: Ignoring request from unknown client 10.1.82.1:32772
En effet, rappelons que Radius impose que le serveur ne communique qu'avec des clients qui ont été enregistrés. Avec Free Radius, cela se fait dans le clients.conf :
client MYNAS.generic-nic.net {
secret = toto
shortname = MYNAS
}
Et, cette fois, ça marche :
% echo "User-Name = bortzmeyer\nUser-Password = foobar" | radclient MYRADIUSSERVER auth toto
Received response ID 233, code 2, length = 44
Service-Type = Framed-User
Framed-Protocol = PPP
Framed-IP-Address = 172.16.3.33
Framed-IP-Netmask = 255.255.255.0
tcpdump a vu :
16:13:09.963566 IP 10.1.82.1.32774 > 10.1.82.2.1812: RADIUS, Access Request (1), id: 0xec length: 50 16:13:09.963914 IP 10.1.82.2.1812 > 10.1.82.1.32774: RADIUS, Access Accept (2), id: 0xec length: 44
Si on l'avait lancé avec l'option -vvv pour qu'il soit plus bavard :
16:13:25.477228 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto UDP (17), length 78) 10.1.82.1.32774 > 10.1.82.2.1812: [udp sum ok] RADIUS, length: 50
Access Request (1), id: 0xee, Authenticator: eb33a21f4d8fc351898adc0b47b90c87
Username Attribute (1), length: 12, Value: bortzmeyer
0x0000: 626f 7274 7a6d 6579 6572
Password Attribute (2), length: 18, Value:
0x0000: 727b 82e4 ccab a138 a5cb 368e 8829 1555
16:13:25.477607 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto UDP (17), length 72) 10.1.82.2.1812 > 10.1.82.1.32774: [bad udp cksum f482!] RADIUS, length: 44
Access Accept (2), id: 0xee, Authenticator: 779e320bca7cda5972412ee6b53b10dc
Service Type Attribute (6), length: 6, Value: Framed
0x0000: 0000 0002
Framed Protocol Attribute (7), length: 6, Value: PPP
0x0000: 0000 0001
Framed IP Address Attribute (8), length: 6, Value: 172.16.3.33
0x0000: ac10 0321
Framed IP Network Attribute (9), length: 6, Value: 255.255.255.0
0x0000: ffff ff00
On peut aussi tester la santé d'un serveur Radius (attention, tous ne le mettent pas en œuvre, sur Free Radius, il faut un status_server = yes dans la configuration) avec les requêtes de type Status-Server :
% echo "Message-Authenticator = 42" | radclient MYRADIUSSERVER status toto
Received response ID 131, code 2, length = 49
Reply-Message = "FreeRADIUS up 0 days, 00:02"
Si on souhaite ajouter des attributs à soi sur un serveur Radius Unix, cela se fait en général en éditant le fichier dictionary, qui décrit les attributs. Imaginons un attribut indiquant la témpérature, je mets dans le /etc/freeradius/dictionary :
ATTRIBUTE Temperature 3000 integer
Un exemple de réalisation d'un service Radius est décrit en http://lehmann.free.fr/Contributions/FreeRADIUS/
L'article seul
RFC 2860: Memorandum of Understanding Concerning the Technical Work of the Internet Assigned Numbers Authority
Date de publication du RFC : Juin 2000
Auteur(s) du RFC : B. Carpenter (IAB), F. Baker (IETF), M. Roberts
(ICANN)
Pour information
Première rédaction de cet article le 8 octobre 2010
Dans le grande désordre qu'est la gouvernance de
l'Internet, il y a un aspect crucial qui est souvent oublié, c'est
celui de la gestion des registres IANA. Les
différentes normes de l'Internet, contenues
dans les RFC, laissent parfois un certain
nombre de paramètres à l'extérieur, dans des registres gérés par
l'IANA (cf. RFC 5226.) Ainsi, pour ajouter une valeur possible
à l'attribut NAS-port-type de
Radius, il n'est pas nécessaire de modifier le
RFC 2865 (section 5.41), il suffit, comme le documente le RFC 3575,
d'envoyer une demande qui, après instruction, sera enregistrée dans
le
registre approprié. Mais sur quelle base l'IANA rend t-elle ce
service à l'IETF ? Dans quelles
conditions ?
Ce RFC 2860 spécifie ces bases et ces conditions. Le texte original date de 2000 et était un MoU entre l'IETF (bien que celle-ci n'ait pas réellement d'existence juridique) et l'ICANN, l'organisme qui gère la « fonction IANA ». (Il a été publié sur le site de l'ICANN.) Le RFC est ainsi signé par les signataires du MoU.
Que dit ce texte indigeste rédigé en langage juridique états-unien ? D'abord, il précise que l'IANA peut gérer d'autres registres, qui ne sont pas sous contrôle de l'IETF, le plus évident étant bien sûr celui des TLD mais la section 4.3 précise que le registre des adresses IP est dans le même cas. Les deux registres les plus critiques ne sont donc pas couverts par cet accord.
Ensuite, le MoU pose le principe (section 4) que l'IANA suivra les demandes de l'IETF si celles-ci sont formalisées dans un RFC (quel que soit le statut de ce dernier). Les éventuels désaccords devront être arbitrés par l'IAB.
Et cela coûte combien ? Rien, dit la section 4.5 : l'IANA accepte de remplir cette tâche gratuitement et s'engage à le faire de manière neutre, en ne prenant en compte que des considérations techniques. On peut penser que simplement rentrer des numéros dans une base de données n'est pas un gros travail mais il est quantitativement non négligeable : à la réunion IETF de Chicago, en juillet 2007, le rapport sur l'activité IANA présenté en séance plénière expliquait que, depuis la réunion précédente en mars à Prague, l'IANA avait eu à évaluer 240 Internet-Drafts (cf. section 4.7, qui décrit cette évaluation), que 84 RFC avaient nécessité une action de sa part (par exemple le RFC 4790), 42 media types et 90 ports avaient été enregistrés. Or, aucune limite quantitative n'est indiquée dans notre RFC 2860. Au moins en théorie, on pourrait imaginer que l'IETF créer un registre d'un milliard d'entrées, avec un million de changements par jour. Gérer un tel registre écroulerait complètement l'IANA, qui n'a pourtant pas officiellement de moyen de s'y opposer. Heureusement que tout ceci est géré par des gens raisonnables.
Et, surtout, ce travail doit être fait avec rigueur et sérieux, les demandes acceptées avec circonspection (certains registres ont peu de place libre) et les données conservées éternellement. Elles doivent en outre être disponibles publiquement, via le Web (contrairement, par exemple, aux registres de l'UIT ; leurs normes sont maintenant accessibles mais leurs registres, non). L'IANA joue donc le rôle d'un notaire ou d'une bibliothèque.
Ce MoU a connu plusieurs mises à jour. La dernière semble dater de janvier 2007 et fixait des SLA, un problème courant car les performances de l'IANA ne sont pas extraordinaires et ont fait l'objet régulièrement de beaucoup de critiques.
L'article seul
RFC 2845: Secret Key Transaction Authentication for DNS (TSIG)
Date de publication du RFC : Mai 2000
Auteur(s) du RFC : P. Vixie (ISC), O. Gudmundsson (NAI
labs), D. Eastlake
(Motorola), B. Wellington (Nominum)
Chemin des normes
Première rédaction de cet article le 25 mars 2010
Le DNS a des vulnérabilités à plusieurs endroits, notamment des risques d'usurpation, qui permettent de glisser une réponse mensongère à la place de la bonne. Il existe plusieurs solutions pour ces problèmes, se différenciant notamment par leur degré de complexité et leur facilité à être déployées. TSIG (Transaction SIGnature), normalisé initialement dans ce RFC, est une solution de vérification de l'intégrité du canal, permettant à deux machines parlant DNS de s'assurer de l'identité de l'interlocuteur. TSIG est surtout utilisé entre serveurs DNS maîtres et esclaves, pour sécuriser les transferts de zone (aujourd'hui, presque tous les transferts entre serveurs faisant autorité sont protégés par TSIG.) Depuis, le RFC 8945 a été publié et est désormais la norme.
TSIG repose sur l'existence d'une clé secrète, partagée entre les deux serveurs, qui sert à générer un HMAC permettant de s'assurer que le dialogue DNS a bien lieu avec la machine attendue. L'obligation de partager une clé secrète le rend difficilement utilisable, en pratique, pour communiquer avec un grand nombre de clients. Mais, entre deux serveurs faisant autorité pour la même zone, ce n'est pas un problème (section 1.4). Même chose entre un serveur maître et un client qui met à jour les données par dynamic update (section 1.3 et RFC 2136). En revanche, pour permettre à des clients d'authentifier leur résolveur, il vaudrait mieux utiliser SIG(0) (RFC 2931) (ou des techniques non-DNS comme IPsec). La section 1.2 de notre RFC cite pourtant cet exemple d'authentification du résolveur, qui n'a jamais été déployé en pratique.
Bien sûr, si tout le monde utilisait DNSSEC partout, le problème n'existerait pas. Mais, en attendant ce futur lointain, TSIG fournit une solution simple et légère pour éviter qu'un méchant ne se glisse dans la conversation entre maître et esclave (par exemple grâce à une attaque BGP) et ne donne à l'esclave de fausses informations. (Il existe aussi des solutions non-DNS comme de transférer la zone avec rsync au dessus de SSH.)
Comment fonctionne TSIG ? Les sections 3 et 4 décrivent le protocole. Le principe est de calculer, avec la clé secrète, un HMAC des données transmises, et de mettre ce HMAC (cette « signature ») dans un pseudo-enregistrement TSIG qui sera joint aux données, dans la section additionnelle. À la réception, l'enregistrement TSIG (obligatoirement le dernier de la section additionnelle) sera extrait, le HMAC calculé et vérifié.
Pour éviter des attaques par rejeu, les données sur lesquelles portent le HMAC incluent l'heure. C'est une des causes les plus fréquentes de problèmes avec TSIG : les deux machines doivent avoir des horloges très proches (section 3.3, qui précise que la tolérance - champ Fudge - est de cinq minutes).
Le format exact des enregistrements TSIG est décrit en section 2. L'enregistrement est donc le dernier, et est mis dans la section additionnelle (voir des exemples plus loin avec dig et tshark). Le type de TSIG est 250 et, évidemment, ces pseudo-enregistrements ne doivent pas être gardés dans les caches. Plusieurs algorithmes de HMAC sont possibles mais un seul est obligatoire (et est le plus répandu), MD5 (RFC 1321 et RFC 2104). Un registre IANA contient les algorithmes actuellement possibles. (Le RFC 4635 a ajouté ceux de la famille SHA.)
Le nom dans l'enregistrement TSIG est le nom de la clé (une raison
pour bien le choisir), la classe est ANY,
le TTL nul et les données contiennent le nom
de l'algorithme utilisé, le moment de la signature, et bien sûr la
signature elle-même.
Le fait que la clé soit secrète implique des pratiques de sécurité
sérieuses, qui font l'objet des sections 5 et 6. Par exemple, l'outil
de génération de clés de BIND crée des fichiers en mode
0600, ce qui veut dire lisibles uniquement par
leur créateur, ce qui est la moindre des choses. Encore faut-il
assurer la sécurité de la machine qui stocke ces fichiers.
Voyons maintenant des exemples concrets où
ludwig (192.168.2.1) est un serveur DNS maître pour la zone
example.test et golgoth
(192.168.2.7) un
serveur esclave. Pour utiliser TSIG afin d'authentifier un transfert de zone entre deux machines, commençons avec BIND. Il
faut d'abord générer une clé. Le programme
dnssec-keygen, livré avec BIND, génère de
nombreux types de clés (d'où ses nombreuses options). Pour TSIG, on
veut du MD5 (mais dnssec-keygen connait d'autres
algorithmes, tapez la commande sans arguments pour avoir la liste) :
% dnssec-keygen -a HMAC-MD5 -b 512 -n HOST golgoth-ludwig-1 Kgolgoth-ludwig-1.+157+56575
On a donné à la clé le nom des deux machines entre lesquelles se fera
la communication (le nom est affiché dans le journal lors d'un
transfert réussi, et à plusieurs autres endroits, donc il vaut mieux
le choisir long et descriptif), plus un chiffre pour distinguer
d'éventuelles autres clés. La clé est partagée entre ces deux machines, on trouve la même dans le
fichier Kgolgoth-ludwig-1.+157+56575.private et
dans Kgolgoth-ludwig-1.+157+56575.key :
% cat Kgolgoth-ludwig-1.+157+56575.private Private-key-format: v1.2 Algorithm: 157 (HMAC_MD5) Key: iGSDB9st+5/xq0AZnwGWAv2ToNJFjsB33fXOh8S9VaI26k4SS7zm4uJVD2MBbYviLB9pF1fWZSUAanOYaRa9JQ== Bits: AAA=
On met alors la clé dans la configuration de BIND, sur les deux machines :
key golgoth-ludwig-1. {
algorithm "hmac-md5";
secret "iGSDB9st+5/xq0AZnwGWAv2ToNJFjsB33fXOh8S9VaI26k4SS7zm4uJVD2MBbYviLB9pF1fWZSUAanOYaRa9JQ==";
};
Sur le serveur maître, on précise que seuls ceux qui connaissent la clé peuvent transférer la zone :
zone "example.test" {
type master;
file "/etc/bind/example.test";
allow-transfer { key golgoth-ludwig-1; };
};
Les autres seront rejetés :
Mar 24 21:41:01 ludwig named[30611]: client 192.168.2.7#65523: zone transfer 'example.test/AXFR/IN' denied
Mais, si on connait la clé, le transfert est possible (ici, un test avec dig) :
% dig -y hmac-md5:golgoth-ludwig-1:iGSDB9st+5/...Ra9JQ== @192.168.2.1 AXFR example.test ; <<>> DiG 9.5.0-P2 <<>> -y hmac-md5 @192.168.2.1 AXFR example.test ; (1 server found) ;; global options: printcmd example.test. 86400 IN SOA ludwig.example.test. hostmaster.example.test. 2010032400 36000 3600 604800 86400 example.test. 86400 IN NS ludwig.example.test. example.test. 86400 IN TXT "foobar" example.test. 86400 IN SOA ludwig.example.test. hostmaster.example.test. 2010032400 36000 3600 604800 86400 golgoth-ludwig-1. 0 ANY TSIG hmac-md5.sig-alg.reg.int. 1269463439 300 16 6TTFl73Lzd5KdDs367+ZoA== 31826 NOERROR 0 ;; Query time: 29 msec ;; SERVER: 192.168.2.1#53(192.168.2.1) ;; WHEN: Wed Mar 24 21:43:59 2010 ;; XFR size: 4 records (messages 1, bytes 244)
On voit que dig affiche fidèlement tous les enregistrements, y compris le pseudo-enregistrement de type TSIG qui contient la signature.
Maintenant que le test marche, configurons le serveur BIND esclave :
zone "example.test" {
type slave;
masters {192.168.2.1;};
file "example.test";
};
server 192.168.2.1 {
keys {
golgoth-ludwig-1;
};
};
et c'est tout : l'esclava va désormais utiliser TSIG pour les transferts de zone. Le programme tshark va d'ailleurs nous afficher les enregistrements TSIG :
Queries
example.test: type AXFR, class IN
Name: example.test
Type: AXFR (Request for full zone transfer)
Class: IN (0x0001)
Answers
example.test: type SOA, class IN, mname ludwig.example.test
Name: example.test
...
Additional records
golgoth-ludwig-1: type TSIG, class ANY
Name: golgoth-ludwig-1
Type: TSIG (Transaction Signature)
Class: ANY (0x00ff)
Time to live: 0 time
Data length: 58
Algorithm Name: hmac-md5.sig-alg.reg.int
Time signed: Mar 24, 2010 21:51:17.000000000
Fudge: 300
MAC Size: 16
MAC
No dissector for algorithm:hmac-md5.sig-alg.reg.int
Original Id: 59013
Error: No error (0)
Other Len: 0
Et si l'esclave est un nsd et pas un BIND ? C'est le même principe. On configure l'esclave :
key: name: golgoth-ludwig-1 algorithm: hmac-md5 secret: "iGSDB9st+5/xq0AZnwGWAv2ToNJFjsB33fXOh8S9VaI26k4SS7zm4uJVD2MBbYviLB9pF1fWZSUAanOYaRa9JQ==" zone: name: "example.test" zonefile: "example.test" allow-notify: 192.168.2.1 NOKEY request-xfr: 192.168.2.1 golgoth-ludwig-1
Et le prochain nsdc update (ou bien la réception
de la notification) déclenchera un transfert, qui sera ainsi
enregistré :
Mar 24 22:10:07 golgoth nsd[9885]: Notify received and accepted, forward to xfrd
Mar 24 22:10:07 golgoth nsd[9966]: Handle incoming notify for zone example.test
Mar 24 22:10:07 golgoth nsd[9966]: xfrd: zone example.test written \
received XFR from 192.168.2.1 with serial 2010032403 to disk
Mar 24 22:10:07 golgoth nsd[9966]: xfrd: zone example.test committed \
"xfrd: zone example.test received update to serial 2010032403 at time 1269465007 \
from 192.168.2.1 in 1 parts TSIG verified with key golgoth-ludwig-1"
Pour générer des clés sans utiliser BIND, on peut consulter mon autre article sur TSIG.
On l'a vu, TSIG nécessite des horloges synchronisées. Une des erreurs les plus fréquentes est d'oublier ce point. Si une machine n'est pas à l'heure, on va trouver dans le journal des échecs TSIG comme (sections 4.5.2 et 4.6.2 du RFC) :
Mar 24 22:14:53 ludwig named[30611]: client 192.168.2.7#65495: \
request has invalid signature: TSIG golgoth-ludwig-1: tsig verify failure (BADTIME)
L'article seul
RFC 2827: Network Ingress Filtering: Defeating Denial of Service Attacks which employ IP Source Address Spoofing
Date de publication du RFC : Mai 2000
Auteur(s) du RFC : P. Ferguson (Cisco), D. Senie (Amaranth)
Première rédaction de cet article le 23 mars 2006
Dernière mise à jour le 14 novembre 2006
Une faille sérieuse de la sécurité dans l'Internet, identifiée depuis de nombreuses années, est la trop grande facilité avec laquelle une machine peut usurper (spoofer) son adresse IP source. Un attaquant peut ainsi déguiser son identité et court-circuiter les filtres. Ce RFC propose une solution, que les FAI devraient déployer, si on veut améliorer sérieusement la sécurité de l'Internet.
Mettons que ma machine soit connectée à l'Internet, via un
FAI, avec l'adresse IP
172.20.34.125. Je pingue une machine distante, par exemple
www.elysee.fr. C'est ma machine qui fabrique les paquets
IP et qui met dans le champ "adresse IP source" le
172.20.34.125. Mais si je suis un méchant, qu'est-ce qui
m'empêche de mettre une autre adresse en source ? Rien. (Si vous ne
savez pas programmer, ne vous inquiétez pas, des outils comme hping sont là pour cela, avec
l'option bien nommé --spoof.)
L'adresse source étant usurpée, l'attaquant ne recevra en général pas la réponse mais, pour certains protocoles, comme UDP, ce n'est pas un problème.
Et cela permet des attaques intéressantes, comme les DoS. La
victime ne pourra pas savoir d'où le paquet vient réellement. Il y a aussi les attaques
par réflexion où l'attaquant écrit à une machine tiers, en usurpant
l'adresse de sa victime. Le tiers va alors répondre à la victime, qui
se croira attaquée par le tiers, pourtant innocent. Une telle attaque
est décrite en http://www.grc.com/dos/drdos.htm.
Encore pire, les
attaques par réflexion avec amplification, qui permettent à
l'attaquant d'obtenir un débit sur sa victime supérieur à celui que
l'attaquant doit lui-même fournir. Les récentes attaques DNS,
utilisant comme tiers des relais DNS récursifs ouverts, appartiennent
à cette catégorie. Ces attaques sont décrites en http://weblog.barnet.com.au/edwin/cat_networking.html et une
approche du problème est en http://www.isotf.org/news/DNS-Amplification-Attacks.pdf.
Notre RFC propose donc de tenter de mettre fin à ces usurpations. Cela peut se faire chez les FAI, en s'assurant que ne peuvent sortir du réseau du FAI que les paquets IP dont l'adresse est une des adresses allouées par ledit FAI.
Le principe est simple (notre RFC est d'ailleurs très court car,
techniquement, il n'y a pas grand'chose à dire) : sur les routeurs du FAI, soit sur ceux faisant face
aux clients, soit sur ceux de sortie, mettre en place une
règles de filtrage interdisant tout trafic venant d'une
adresse non allouée. Par exemple, si le routeur est une machine
Linux, et que le réseau du FAI est le
172.20.128.0/22, il suffit de :
iptables --insert FORWARD --out-interface eth1 --source \! 172.20.128.0/22 --jump LOG --log-prefix "IP spoofing" iptables --insert FORWARD --out-interface eth1 --source \! 172.20.128.0/22 --jump DROP
Naturellement, il faut bien vérifier qu'on couvre tous les cas : beaucoup d'opérateurs ont du mal à compiler une liste exacte de tous leurs préfixes, ce qui explique en partie le peu de déploiement de ce RFC.
Notons que, comme toute mesure de sécurité, celle-ci a des faux positifs (le RFC cite le cas des mobiles) et qu'elle peut bloquer ou bien rendre très difficiles des usages parfaitement légitimes (le RFC cite le cas du multihoming, traité dans un autre document, le RFC 3704). Elle a aussi des faux négatifs : certaines usurpations ne seront pas forcément détectées, par exemple lorsqu'un client du FAI usurpe l'adresse d'un autre client du même FAI.
Notre RFC date de presque six ans et ne semble toujours pas largement déployé : cela donne une idée de la difficulté du problème. En effet, déployer ce RFC (aussi connu sous son numéro de bonne pratique, BCP38), coûte de l'argent au FAI et en fait économiser aux autres opérateurs de l'Internet, par les attaques que cela leur épargne. On conçoit que le simple bon sens économique et l'absence de régulation autre que celle du marché limitent la mise en œuvre de ce RFC.
L'article seul
RFC 2826: IAB Technical Comment on the Unique DNS Root
Date de publication du RFC : Mai 2000
Auteur(s) du RFC : Internet Architecture Board
Pour information
Première rédaction de cet article le 9 juillet 2006
C'est un RFC très politique et qui est donc signé par tout l'IAB. Il explique l'importance d'avoir une racine unique pour le DNS.
Les RFC qui décrivent techniquement le DNS spécifient le protocole, le format de paquets... et l'organisation des données sous forme d'un arbre. Mais ils ne précisent pas si cette arbre doit être unique ou pas. Actuellement, l'écrasante majorité des utilisateurs de l'Internet utilisent le même arbre, celui dont la racine est géré par une marionnette du gouvernement états-unien, l'ICANN. Or, il existe d'autres arbres, parfois sérieux comme ORSN (que j'utilise à la maison, donc en ce moment) et parfois fantaisistes ou malhonnêtes. Chacun de ces arbres (on dit souvent "chacune de ces racines") a sa propre liste de TLD et un nom de domaine n'a donc pas forcément la même signification partout.
Alors, faut-il promouvoir ou au contraire décourager l'usage de ces racines, parfois pompeusement nommées "racines alternatives" (alors que la plupart ne comptent que quelques PC dans des garages) ? Notre RFC est la réponse officielle de l'IAB sur ce sujet. Il commence par annoncer clairement qu'il est nécessaire de garder une racine unique. Le principal argument est que la multiplicité des racines n'empêcherait pas la communication (puisque c'est le même protocole DNS) mais lui ferait perdre sa sémantique, puisque le même URL pourrait mener à deux pages Web différentes ou que la même adresse de courrier pourrait arriver à un destinataire ou à l'autre selon la racine DNS utilisée.
À noter que l'équivalent politicien de notre RFC est le document ICP-3 de l'ICANN, où l'ICANN proclame son refus de toute concurrence.
L'argument de l'IAB est tout à fait juste (si on veut qu'un nom soit sans ambigüité, il faut une racine unique). Mais l'IAB va souvent trop loin en faisant de cette contrainte bien raisonnable une sorte de loi de la nature, qui serait imposée par le protocole DNS lui-même. Le RFC oscille en permanence entre des rappels pratiques très justes et des affirmations parfois imprudentes sur la nécessaire unicité de tout nom.
L'article seul
RFC 2822: Internet Message Format
Date de publication du RFC : Avril 2001
Auteur(s) du RFC : P. Resnick (Qualcomm)
Chemin des normes
Première rédaction de cet article le 13 janvier 2006
Dernière mise à jour le 1 octobre 2008
Le RFC 822, qui spécifiait le format des messages envoyés par courrier électronique, avait dix-neuf ans lorsque notre RFC a été publié, afin de mettre enfin à jour ce vénérable ancêtre. Lui-même a été remplacé depuis par le RFC 5322.
Comme son compagnon, le RFC 2821, qui décrit le protocole de transport des messages, notre RFC est le résultat d'une remise à plat complète d'une spécification très ancienne, pleine de succès, mais qui avait été modifiée successivement et qui devenait difficile à comprendre, par l'accumulation de changements.
Notre RFC décrit donc le format des messages lorsqu'ils circulent
sur le réseau (un logiciel de lecture de courrier peut naturellement
les afficher de manière différente, plus adaptée aux humains) : le
message comprend deux parties, l'en-tête et le corps. L'en-tête est
composée de plusieurs champs, les plus connus étant
From: (l'expéditeur),
Subject: (l'objet du message) ou bien encore
Received:, un champ dit "de trace", qui sert aux
administrateurs de courrier électronique à déterminer par où est passé
un message.
Parmi les champs de l'en-tête, plusieurs contiennent une adresse de
courrier électronique et notre RFC 2822 décrit la syntaxe de
ces adresses. Terriblement complexe (la forme "Stephane
Bortzmeyer <bortzmeyer@internatif.org>" n'est que la
plus simple mais bien d'autres sont permises), elle est le cauchemar
des implémenteurs (la syntaxe des dates est également très
chevelue). La norme de syndication Atom (RFC 4287), par exemple, se contente d'une
expression rationnelle minimale pour décrire ce
format : ".+@.+".
Il est à noter que la très grande majorité des codes
Javascript ou PHP qu'on
trouve en abondance sur le Web pour "vérifier une adresse
électronique" sont faux : ils rejettent à tort des adresses
valides (comme bortzmeyer+sncf@nic.fr sur le
serveur de la SNCF, par exemple). Ce travail
d'amateurs ou de stagiaires indique que leur auteur n'a pas lu le RFC 2822.
Le corps du message n'est quasiment pas spécifié par notre RFC, les choses perfectionnées (par exemple le multimédia) étant laissées à la norme MIME (RFC 2045 et suivants).
Après plusieurs années de bons et loyaux services, notre RFC a été remplacé par le RFC 5322.
L'article seul
RFC 2821: Simple Mail Transfer Protocol
Date de publication du RFC : Avril 2001
Auteur(s) du RFC : J. Klensin (AT&T Laboratories)
Chemin des normes
Première rédaction de cet article le 13 janvier 2006
Dernière mise à jour le 1 octobre 2008
Ce RFC mettait à jour le vieux RFC 821 qui a été pendant dix-neuf ans (!) la spécification du protocole SMTP, le principal protocole de transport de courrier électronique, l'application qui a assuré le succès de l'Internet. Il a depuis été remplacé par le RFC 5321.
Compte-tenu de l'immense succès de ce service et du protocole SMTP, on comprend que beaucoup ont reculé devant la mise à jour de SMTP. Elle était pourtant nécessaire puisque le protocole avait été étendu, notamment par l'invention de ESMTP (originellement dans le RFC 1425, une version améliorée - E signifie Extended - qui permettait au client et au serveur SMTP de négocier des options (comme le transport du courrier sur 8 bits). Cette modification, et beaucoup d'autres, rendait très difficile de déterminer le comportement normal d'un serveur SMTP.
Remettre à plat le protocole et en donner une description à jour et normative était donc une tâche utile, mais ingrate ; il n'y a pas de prestige à gagner dans de telles tâches de ménage (on notera d'ailleurs que le DNS souffre terriblement de ce problème, plusieurs dizaines de RFC étant désormais nécessaires pour le programmer correctement ; l'incapacité de l'IETF à faire pour le DNS ce qui a été fait pour SMTP est un sérieux problème). En outre, il fallait le prestige et la compétence de John Klensin, auteur de nombreux RFC, pour mener cette tâche à bien.
Le nouveau RFC décrit donc le modèle de SMTP, les entités qui participent à l'envoi d'un message, les commandes qu'elles peuvent échanger. On notera que le format des messages n'est pas décrit dans ce RFC mais dans son compagnon, le RFC 2822. Le RFC 2821 ne décrit que le protocole de transport, pas ce qui est transporté.
Ce nouveau RFC intègre donc les modifications des vingt dernières années, comme ESMTP. Il n'entraine aucun changement dans les serveurs de messagerie, se contentant de tout décrire de manière homogène. Signe des temps, notre RFC a aussi une longue section consacrée à la sécurité, complètement absente du RFC 821. La question de l'usurpation d'identité est traitée mais pas résolue : si SMTP n'authentifie pas l'émetteur, ce n'était pas par paresse ou étroitesse de vue de la part de Jon Postel, l'auteur du RFC 821. C'est tout simplement parce qu'il n'existe aucun fournisseur d'identité sur l'Internet, réseau décentralisé et sans commandement unique. Aucun protocole ne peut combler ce manque.
Mon expérience du courrier électronique remontant à quelques années (bien après le RFC 821 mais bien avant le RFC 2821), je me souviens avec amusement des tentatives d'autres protocoles (notamment le ridicule X.400) de s'imposer, par des mesures bureaucratiques ou par du simple FUD, portant souvent sur des questions de sécurité. La vérité est qu'aucun des concurrents n'avait fait mieux que SMTP, dans un réseau ouvert : tous n'ont été déployés que dans des petits réseaux fermés, où la question de l'authentification est évidemment plus simple.
Comme notre RFC ne change pas le protocole, les principes de SMTP demeurent : un protocole simple, efficace, relativement facile à implémenter et n'utilisant que des commandes textes, ce qui permet de déboguer aisément avec des outils comme telnet. Ces principes sont à la base de la révolution du courrier électronique qui fait qu'on n'imagine plus aujourd'hui une carte de visite sans une adresse électronique.
Mais l'Internet continuant d'évoluer, des limites de notre RFC apparaissent déjà. Par exemple, les nombreux efforts pour apporter des mécanismes d'authentification de l'émetteur (par exemple pour lutter contre le spam) ont souvent buté sur des problèmes de vocabulaire : le RFC 2821 ne décrit qu'imparfaitement l'architecture du courrier et le vocabulaire, pour des actions aussi simples que l'envoi d'un message à une liste de diffusion ou que la réécriture des adresses en cas de forwarding (faire suivre automatiquement un message), reste flou et mal standardisé. Il est donc difficile d'affirmer si telle ou telle nouvelle technique est contraire aux principes du courrier Internet, ceux-ci n'étant pas formellement écrits.
La norme de SMTP est désormais le RFC 5321.
L'article seul
RFC 2818: HTTP Over TLS
Date de publication du RFC : Mai 2000
Auteur(s) du RFC : E. Rescorla (RTFM)
Pour information
Première rédaction de cet article le 27 janvier 2018
C'est un RFC très ancien que ce RFC 2818, et qui décrit une technologie qui ne s'est pourtant imposée presque partout que récemment, HTTPS (HTTP sur TLS). Le RFC a depuis été remplacé par le RFC 9110.
Remettons-nous dans le contexte de l'époque : en 2000, la NSA espionnait déjà massivement, mais on n'avait pas encore eu les révélations Snowden. Les pays comme la Russie et la Chine n'avaient sans doute pas encore d'activités d'espionnage sur l'Internet et la France… espionnait le trafic Minitel. L'inquiétude à l'époque n'était pas tellement tournée vers les services secrets officiels mais plutôt vers le méchant pirate qui allait copier les numéros de carte bleue quand on allait les utiliser pour le e-commerce (concept relativement récent à l'époque). HTTPS, le HTTP sécurisé par la cryptographie semblait à l'époque réservé aux formulaires où on tapait un numéro de carte de crédit. Ce n'est qu'à partir des révélations de Snowden que HTTPS a commencé à être déployé systématiquement, et qu'il forme sans doute aujourd'hui la majorité du trafic, malgré les indiscrets de tout bord qui auraient voulu continuer à surveiller le trafic, et qui répétaient « M. Michu n'a pas besoin de chiffrement ». (Au FIC en 2016, dans une réunion publique, un représentant d'un grand FAI se désolait que le déploiement massif de HTTPS empêchait d'étudier ce que faisaient ses clients…) Ce succès est en partie dû à des campagnes de sensibilisation (menées par exemple par l'EFF) et à des outils comme HTTPS Everywhere.
Revenons au RFC. Il est très court (sept pages) ce qui est logique puisque le gros du travail est fait dans le RFC 5246, qui normalise TLS (c'était le RFC 2246, à l'époque). Car, HTTPS, c'est juste HTTP sur TLS, il n'y a pas grand'chose à spécifier. Notons que le titre du RFC est « HTTP sur TLS », que le texte ne parle que de TLS comme protocole de cryptographie et pourtant, dix-huit ans plus tard, des gens ignorants parlent encore de SSL, le prédécesseur, abandonné depuis longtemps, de TLS.
Ironie des processus internes de l'IETF, notre RFC n'est pas sur le chemin des normes Internet, il a seulement la qualité « pour information ».
La section 1 résume le RFC : HTTPS, comme TLS, protège le canal et non pas les données. Cela veut dire notamment que HTTPS ne protège pas si on a des sites miroir et que l'un d'eux se fait pirater. (En 2018, on n'a toujours pas de moyen standard de sécuriser les données envoyées sur le Web, malgré quelques briques possiblement utilisables comme XML Signature - RFC 3275 et JOSE.)
La section 2 décrit le protocole en une phrase : « Utilisez HTTP
sur TLS, comme vous utiliseriez HTTP sur TCP. »
Bon, j'exagère, il y a quelques détails. Le client HTTPS doit être un
client TLS, donc un client TCP. Il se connecte au serveur en TCP puis
lance TLS puis fait des requêtes HTTP par dessus la session TLS,
elle-même tournant sur la connexion TCP. Cela se voit bien avec
l'option -v de
curl. D'abord du TCP :
% curl -v https://www.bortzmeyer.org/crypto-protection.html * Trying 2605:4500:2:245b::42... * TCP_NODELAY set * Connected to www.bortzmeyer.org (2605:4500:2:245b::42) port 443 (#0)
Puis TLS démarre :
* ALPN, offering h2 * ALPN, offering http/1.1 * Cipher selection: ALL:!EXPORT:!EXPORT40:!EXPORT56:!aNULL:!LOW:!RC4:@STRENGTH * successfully set certificate verify locations: * CAfile: /etc/ssl/certs/ca-certificates.crt CApath: /etc/ssl/certs * TLSv1.2 (OUT), TLS header, Certificate Status (22): * TLSv1.2 (OUT), TLS handshake, Client hello (1): * TLSv1.2 (IN), TLS handshake, Server hello (2): * TLSv1.2 (IN), TLS handshake, Certificate (11): * TLSv1.2 (IN), TLS handshake, Server key exchange (12): * TLSv1.2 (IN), TLS handshake, Server finished (14): * TLSv1.2 (OUT), TLS handshake, Client key exchange (16): * TLSv1.2 (OUT), TLS change cipher, Client hello (1): * TLSv1.2 (OUT), TLS handshake, Finished (20): * TLSv1.2 (IN), TLS change cipher, Client hello (1): * TLSv1.2 (IN), TLS handshake, Finished (20): * SSL connection using TLSv1.2 / ECDHE-RSA-AES256-GCM-SHA384 * ALPN, server accepted to use http/1.1 * Server certificate: * subject: CN=www.bortzmeyer.org * start date: Sep 21 06:34:08 2016 GMT * expire date: Sep 21 06:34:08 2018 GMT * subjectAltName: host "www.bortzmeyer.org" matched cert's "www.bortzmeyer.org" * issuer: O=CAcert Inc.; OU=http://www.CAcert.org; CN=CAcert Class 3 Root * SSL certificate verify ok.
Et enfin on peut faire de l'HTTP :
> GET /crypto-protection.html HTTP/1.1 > Host: www.bortzmeyer.org > User-Agent: curl/7.52.1 > Accept: */* > < HTTP/1.1 200 OK < Server: Apache/2.4.25 (Debian) < ETag: "8ba9-56281c23dd308" < Content-Length: 35753 < Content-Type: text/html < <?xml version="1.0" ?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xml:lang="fr" lang="fr" xmlns="http://www.w3.org/1999/xhtml"> <head> ... <title>Blog Stéphane Bortzmeyer: La cryptographie nous protège t-elle vraiment de l'espionnage par la NSA ou la DGSE ?</title> ... </body> </html>
Et on termine :
* Curl_http_done: called premature == 0 * Connection #0 to host www.bortzmeyer.org left intact
Si on n'aime pas curl, on peut le faire avec le client en ligne de commande de GnuTLS, puis taper les requêtes HTTP à la main :
% echo -n "GET /who-buys-porn.html HTTP/1.1\r\nHost: www.bortzmeyer.org\r\nUser-Agent: à la main\r\n\r\n" | \ gnutls-cli www.bortzmeyer.org Processed 167 CA certificate(s). Resolving 'www.bortzmeyer.org:443'... Connecting to '2605:4500:2:245b::42:443'... - Certificate type: X.509 - Got a certificate list of 2 certificates. - Certificate[0] info: - subject `CN=www.bortzmeyer.org', issuer `CN=CAcert Class 3 Root,OU=http://www.CAcert.org,O=CAcert Inc.', serial 0x029ba3, RSA key 2048 bits, signed using RSA-SHA256, activated `2016-09-21 06:34:08 UTC', expires `2018-09-21 06:34:08 UTC', key-ID `sha256:141954e99b9c88a33af6ffc00db09f5d8b66185a7325f45cbd45ca3cb47d63ce' Public Key ID: sha1:82500582b33c12ada8891e9a36192131094bed22 sha256:141954e99b9c88a33af6ffc00db09f5d8b66185a7325f45cbd45ca3cb47d63ce Public key's random art: +--[ RSA 2048]----+ |o=o oo. | |O..+ | |+Bo | |E= o . | |*.+ . . S | |+o . | |o.+ | |o= | |. . | +-----------------+ - Certificate[1] info: - subject `CN=CAcert Class 3 Root,OU=http://www.CAcert.org,O=CAcert Inc.', issuer `EMAIL=support@cacert.org,CN=CA Cert Signing Authority,OU=http://www.cacert.org,O=Root CA', serial 0x0a418a, RSA key 4096 bits, signed using RSA-SHA256, activated `2011-05-23 17:48:02 UTC', expires `2021-05-20 17:48:02 UTC', key-ID `sha256:bd0d07296b43fae03b64e650cbd18f5e26714252035189d3e1263e4814b4da5a' - Status: The certificate is trusted. - Description: (TLS1.2)-(ECDHE-RSA-SECP256R1)-(AES-256-GCM) - Session ID: A6:A6:CE:32:08:9D:B8:D2:EF:D6:C7:D4:85:B4:39:D7:0D:04:83:72:6F:87:02:50:44:B7:29:64:E5:69:0B:07 - Ephemeral EC Diffie-Hellman parameters - Using curve: SECP256R1 - Curve size: 256 bits - Version: TLS1.2 - Key Exchange: ECDHE-RSA - Server Signature: RSA-SHA256 - Cipher: AES-256-GCM - MAC: AEAD - Compression: NULL - Options: safe renegotiation, - Handshake was completed - Simple Client Mode: HTTP/1.1 200 OK Server: Apache/2.4.25 (Debian) Content-Length: 8926 Content-Type: text/html
Et, vu par tshark, ça donne d'abord TCP :
1 0.000000000 2a01:e35:8bd9:8bb0:dd2c:41a5:337f:a21f → 2605:4500:2:245b::42 TCP 94 45502 → 443 [SYN] Seq=0 Win=28400 Len=0 MSS=1420 SACK_PERM=1 TSval=26014765 TSecr=0 WS=128 2 0.080848074 2605:4500:2:245b::42 → 2a01:e35:8bd9:8bb0:dd2c:41a5:337f:a21f TCP 94 443 → 45502 [SYN, ACK] Seq=0 Ack=1 Win=28560 Len=0 MSS=1440 SACK_PERM=1 TSval=476675178 TSecr=26014765 WS=64 3 0.080902511 2a01:e35:8bd9:8bb0:dd2c:41a5:337f:a21f → 2605:4500:2:245b::42 TCP 86 45502 → 443 [ACK] Seq=1 Ack=1 Win=28416 Len=0 TSval=26014785 TSecr=476675178
Puis TLS :
4 0.084839464 2001:db8:57aa:8bb0:dd2c:9af:222f:a21f → 2605:4500:2:245b::42 SSL 351 Client Hello 5 0.170845913 2605:4500:2:245b::42 → 2001:db8:57aa:8bb0:dd2c:9af:222f:a21f TCP 86 443 → 45502 [ACK] Seq=1 Ack=266 Win=29632 Len=0 TSval=476675200 TSecr=26014786 6 0.187457346 2605:4500:2:245b::42 → 2001:db8:57aa:8bb0:dd2c:9af:222f:a21f TLSv1.2 1494 Server Hello 7 0.187471721 2001:db8:57aa:8bb0:dd2c:9af:222f:a21f → 2605:4500:2:245b::42 TCP 86 45502 → 443 [ACK] Seq=266 Ack=1409 Win=31232 Len=0 TSval=26014812 TSecr=476675202 8 0.187583400 2605:4500:2:245b::42 → 2001:db8:57aa:8bb0:dd2c:9af:222f:a21f TLSv1.2 2320 Certificate, Server Key Exchange, Server Hello Done 9 0.187600261 2001:db8:57aa:8bb0:dd2c:9af:222f:a21f → 2605:4500:2:245b::42 TCP 86 45502 → 443 [ACK] Seq=266 Ack=3643 Win=35712 Len=0 TSval=26014812 TSecr=476675202 10 0.199416730 2001:db8:57aa:8bb0:dd2c:9af:222f:a21f → 2605:4500:2:245b::42 TLSv1.2 212 Client Key Exchange, Change Cipher Spec, Hello Request, Hello Request 11 0.283191938 2605:4500:2:245b::42 → 2001:db8:57aa:8bb0:dd2c:9af:222f:a21f TLSv1.2 360 New Session Ticket, Change Cipher Spec, Encrypted Handshake Message
C'est fait, TLS a démarré (notez le nombre de paquets qu'il a fallu échanger pour cela : TLS accroit la latence, et beaucoup de travaux actuellement à l'IETF visent à améliorer ce point). On peut maintenant faire du HTTP :
12 0.283752212 2001:db8:57aa:8bb0:dd2c:9af:222f:a21f → 2605:4500:2:245b::42 TLSv1.2 201 Application Data 13 0.365992864 2605:4500:2:245b::42 → 2001:db8:57aa:8bb0:dd2c:9af:222f:a21f TLSv1.2 1494 Application Data
Comment, on ne voit pas le HTTP, juste le Application Data générique de TLS ? Oui, c'est exprès, c'est bien à ça que sert TLS.
Bon, ce n'est pas tout d'ouvrir une session, il faut aussi la
fermer. Le RFC précise qu'il faut utiliser la fermeture TLS avant la
fermeture TCP, pour être sûr que toutes les données ont été
transmises. Le cas des fermetures de session trop brutales forme
d'ailleurs l'essentiel du RFC (que faire si la connexion TCP est
rompue avant la session TLS ? Cela peut avoir des conséquences de
sécurité, par exemple s'il n'y a pas d'en-tête HTTP
Conent-Length: et que la connexion TCP est
coupée, on ne peut pas savoir si on a tout reçu ou bien si un
attaquant a généré une fausse coupure de connexion TCP qui,
contrairement à la fermeture TLS, n'est pas authentifiée, cf. RFC 5961.
Reste la question du port à utiliser. Comme vous le savez sans
doute, HTTPS utilise le port 443. Il est enregistré
à cet effet à l'IANA. Notez que
gnutls-cli, utilisé plus haut, utilise ce port
par défaut.
Et le plan d'URI à utiliser pour HTTPS ?
Là aussi, vous le connaissez, c'est https://
donc par exemple, https://www.afnic.fr/https://www.ietf.org/blog/codel-improved-networking-through-adaptively-managed-router-queues/https://lad.wikipedia.org/wiki/Gefilte_fishhttps:// pour les URI est désormais dans le
RFC 7230, et plus détaillée que la description
informelle du vieux RFC.
Mais ça n'est pas tout d'avoir une connexion chiffrée… Comme le
notent plusieurs auteurs « TLS permet d'avoir une session sécurisée
avec un ennemi ». En effet, si vous n'authentifiez pas la machine à
l'autre bout, TLS ne sera pas très utile. Vous risquerez d'être
victime de l'attaque de l'homme du milieu où
Mallory se place entre Alice et Bob,
prétendant être Bob pour Alice et Alice pour Bob. Il est donc très
important d'authentifier le partenaire, et c'est là la principale
faiblesse de HTTPS. On utilise en général un
certificat X.509 (ou,
plus rigoureusement, un certificat PKIX,
cf. RFC 5280). Comme HTTPS part en général d'un
URI, le client a dans cet URI le
nom de domaine du serveur. C'est ce nom qu'il
doit comparer avec ce qu'il trouve dans le certificat (plus
exactement, on regarde le subjectAltName si
présent, puis le Common Name, CN, mais
rappelez-vous que le RFC est vieux, les règles ont évolué
depuis). D'autres
techniques d'authentification sont possibles, comme l'épinglage de la clé (RFC 7469), qu'on peut combiner avec les clés nues
du RFC 7250.
Si quelque chose ne va pas dans l'authentification, on se récupère un avertissement du navigateur, proposant parfois de passer outre le problème. Le RFC notait déjà, il y a dix-huit ans, que c'était dangereux car cela laisserait la session potentiellement sans protection. Globalement, depuis la sortie du RFC, les navigateurs sont devenus de plus en plus stricts, rendant ce débrayage de la sécurité plus difficile.
Voici un exemple de problème d'authentification. Le Centre
Hospitalier de Bois-Petit redirige automatiquement les
visiteurs vers la version HTTPS de son site, qui n'a pas le bon nom
dans le certificat. Ici, la protestation de
Firefox (notez la possibilité d'ajouter une
exception manuellement) :
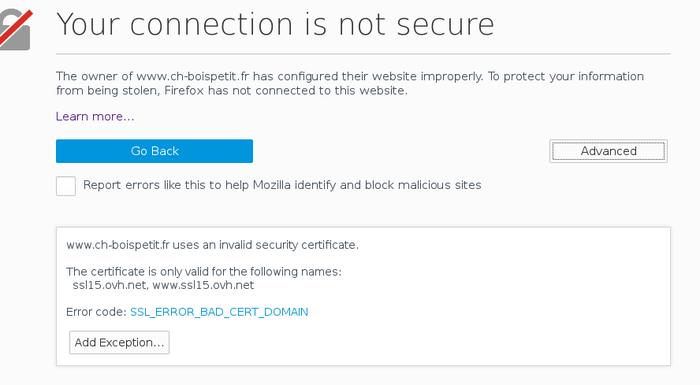
curl râle également, bien sûr :
% curl https://www.ch-boispetit.fr/ curl: (51) SSL: no alternative certificate subject name matches target host name 'www.ch-boispetit.fr'
Une variante de cette erreur se produit lorsque le site est
accessible par plusieurs noms en HTTP mais que tous ne sont pas
authentifiables en HTTPS. Par exemple, pour le quotidien
Le Monde, http://lemonde.frhttp://www.lemonde.frwww.lemonde.fr est dans le
certificat. (Même chose, aujourd'hui, pour https://wikipedia.fr/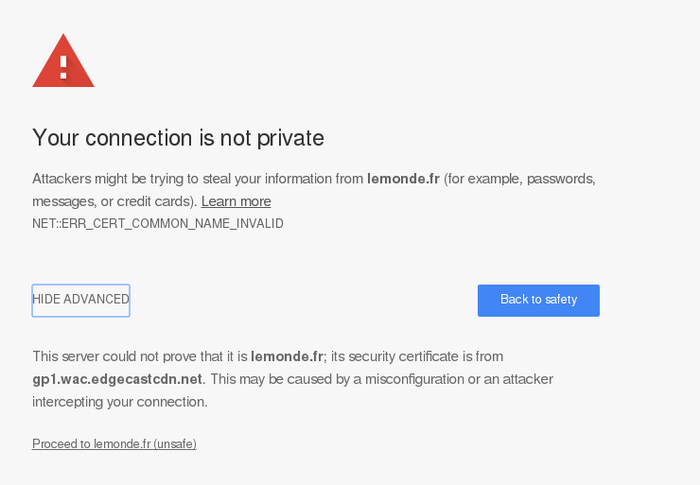
D'autres erreurs sont possibles avec la gestion des certificats, la
plus fréquente étant sans doute le certificat expiré. Si vous
voulez regarder avec votre navigateur Web des exemples d'erreurs,
l'excellent site https://badssl.com/
Le RFC note à juste titre que l'URI de départ vient souvent d'une
source qui n'est pas digne de confiance. Si vous suivez un lien qui
est dans vos signets, ou que vous le tapez
vous-même en faisant attention, l'URI est digne de confiance, et la
vérification du certificat vous protégera. Mais si vous cliquez sur
un lien dans un message envoyé par une nommée
natacha@viagra-pharmacy.ru annonçant
« Agrandissez votre pénis », ou même un lien dans un message
prétendant venir de votre patron et annonçant
« dossier très urgent à lire » (rappelez-vous que le
courrier électronique n'est pas authentifié,
sauf si on utilise PGP ou équivalent),
alors, l'URI n'est pas sûr et HTTPS ne vous protégera pas (sauf si
vous scrutez avec soin l'URI dans la barre d'adresses du navigateur,
ce que personne ne fait et, de toute façon, c'est parfois trop
tard). C'est ce qu'on appelle le hameçonnage
et c'est une attaque fréquente, contre laquelle toute la
cryptographie du monde ne vous protège pas. (Ceci dit, à l'heure
actuelle, spammeurs et hameçonneurs ne se sont pas mis massivement à
HTTPS, la plupart du temps, ils en restent au bon vieil HTTP.)
Notez qu'on n'a parlé que de la vérification par le client de l'identité du serveur (qui utilise le fait que le client connait le nom de domaine du serveur). La vérification par le serveur de l'identité du client est également possible (envoi d'un certificat par le client) mais elle nécessite que le serveur ait une base des clients connus (ou qu'il accepte tous les certificats d'une AC donnée).
Après cet article, et compte tenu du fait que HTTPS existe
formellement depuis si longtemps, vous devez vous dire que ce blog
que vous lisez est accessible en HTTPS, non ? Eh bien, il l'est mais je ne publie
pas les URI en https:// et je ne fais pas de
redirection automatique vers la version HTTPS. En effet, j'utilise
une AC gratuite et facile d'usage mais que la plupart des vendeurs n'incluent
pas dans leur magasin des AC (ce qui est une décision arbitraire :
regardez le magasin des AC via votre navigateur Web, et voyez si
vous faites confiance aux gouvernements chinois et turcs, ainsi
qu'aux entreprises privées qui ne pensent qu'au profit). Tant que ce
problème durera, je ne pourrais pas faire de HTTPS par défaut. En
attendant, si vous voulez voir ce blog sur HTTPS, sur une
Debian, faites juste sudo aptitude
install ca-cacert (puis redémarrez le navigateur), sur les
autres systèmes, allez en https://www.cacert.org/index.php?id=3
Au fait, si quelqu'un a des références de bonnes études quantitatives sur le déploiement de HTTPS entre 2000 et aujourd'hui, je suis preneur. Je connais pour l'instant la télémétrie de Firefox. Elle est affichée ici (mais malheureusement uniquement depuis 2014) et montre aujourd'hui 70 % de pages Web en HTTPS.
L'article seul
RFC 2782: A DNS RR for specifying the location of services (DNS SRV)
Date de publication du RFC : Février 2000
Auteur(s) du RFC : A. Gulbrandsen (Troll), P. Vixie (ISC), L. Esibov (Microsoft)
Chemin des normes
Première rédaction de cet article le 8 octobre 2005
Ce RFC spécifie un nouveau type d'enregistrement DNS, le SRV pour
"service". Traditionnellement, les enregistrements contenus
dans le DNS permettaient seulement de spécifier l'adresse
IP correspondant à un nom comme
www.bortzmeyer.org. Si on voulait avoir plusieurs
machines mettant en œuvre un service, il fallait mettre plusieurs
adresses dans le RRset, dans l'ensemble des
enregistrements. Et, si on voulait en plus que certaines de ces
adresses ne soient utilisés qu'en secours, si les premières ne
répondent pas, ou si on voulait que certains adresses soient utilisés
davantage que d'autres, parce qu'elles correspondent à des machines
plus rapides, eh bien il n'y avait pas de solution. Plus exactement,
il n'y en avait que pour le courrier, qui avait un type spécial,
MX, ayant à peu près ces
capacités. Mais les autres services, comme le Web, ne pouvaient pas en
bénéficier.
Ce RFC introduit donc un nouvel enregistrement, SRV, qui est depuis longtemps disponible dans les serveurs de noms. Un enregistrement SRV permet d'obtenir, pour un service, non pas une adresse IP mais le nom d'un serveur physique, avec une priorité, qui permet de rendre obligatoire le passage par certaines machines d'abord, et un poids, qui permet de donner une plus grande probabilité d'usage pour certaines machines. La priorité est déterministe et absolue (si une machine de meilleure priorité est disponible, elle doit être utilisée), le poids est probabiliste (il vaut mieux essayer les serveurs de meilleur poids). L'enregistrement donne également le port à utiliser.
Le service se spécifie en le préfixant d'un trait souligné (_),
caractère illégal dans les noms de machine, ce qui supprime le risque
de collision. Par exemple, certains clients LDAP cherchent le serveur
LDAP de leur domaine, non pas en essayant une convention comme
ldap.MONDOMAINE.org mais en demandant le SRV de
_ldap._tcp.MONDOMAINE.org. Une telle convention a
également été proposée pour whois, afin de découvrir le serveur whois
faisant autorité pour un domaine donné.
Un RRset, un ensemble d'enregistrements SRV pour
le service Web de example.org pourrait donc être
:
_http._tcp SRV 0 1 80 old-slow-box.example.org.
SRV 0 3 80 new-fast-box.example.org.
SRV 1 0 80 personal-box.adsl.my-isp.net.
ici avec deux serveurs de même priorité (zéro), un rapide ayant un poids de 3 et un lent ayant un poids de 1, puis un serveur de secours (priorité 1). Tous écoutent sur le port 80.
Pour les développeurs, il existe déjà une bibliothèque qui met en œuvre le RFC 2782 : Ruli (pour Resolver User Layer Interface) qui simplifie considérablement la tâche du développeur. Si un si faible nombre d'applications utilise les enregistrements SRV, ce n'est donc pas faute de support logiciel.
Car, malheureusement, on constate que très peu d'applications acceptent d'utiliser les SRV. Je ne connais par exemple aucun navigateur Web qui le fasse, même pas Firefox, pour lequel la discussion a commencé il y a des années (idem pour Chrome). Pour des raisons qui m'échappent, une très belle idée, qui résoudrait de nombreux problèmes de gestion d'un parc de serveurs, reste ainsi, six ans après sa normalisation, quasiment inconnue.
À part XMPP, l'utilisation la plus courante aujourd'hui doit être dans le DNS Service Discovery du RFC 6763.
L'article seul
RFC 2777: Publicly Verifiable Nomcom Random Selection
Date de publication du RFC : Février 2000
Auteur(s) du RFC : Donald E. Eastlake, 3rd (Motorola)
Pour information
Première rédaction de cet article le 22 décembre 2009
Ce curieux RFC répond à une question apparemment paradoxale : comment tirer au hasard de manière publiquement vérifiable ? Par exemple, les membres d'un des comités de l'IETF, le Nomcom, sont choisis au hasard. Comment permettre à tous les participants à l'IETF de vérifier que le tirage était bien aléatoire, alors que l'opération se fait sur l'Internet, sans qu'on puisse vérifier le dé ou la roulette ?
Une solution traditionnelle est de désigner une autorité arbitraire, considérée comme digne de confiance, et dont on n'a pas le droit de remettre l'honnêteté en doute. C'est ce que font toutes les loteries qui se déroulent « sous contrôle d'huissier ». Une telle méthode, basée sur la confiance aveugle en une entité particulière, ne colle pas avec la culture IETF.
Une autre méthode est proposée par notre RFC 2777. Utiliser un certain nombre de sources d'entropie, publiquement consultables, et les passer à travers une fonction de hachage qui garantira la dispersion des résultats, rendant ainsi très difficile d'influencer ceux-ci. Et chacun pourra faire tourner l'algorithme chez lui, vérifiant ainsi que le résultat est honnête.
La section 1 du RFC rappelle le problème original, la désignation du Nomcom (Nominating Committee, cf. RFC 2727) de l'IETF. Mais, depuis, la méthode de ce RFC a été utilisée dans bien d'autres cas.
La section 2 décrit les étapes à suivre :
- Identifier les candidats possibles (le RFC décrit le cas du Nomcom mais cette étape existe pour toute désignation),
- Publication de l'algorithme et des sources d'entropie utilisées, pour permettre la future vérification. Cette étape est indispensable car la possibilité de tous les participants de contrôler eux-même l'honnêteté du processus est vitale. (À noter que c'est justement cette possibilité qui est retirée au citoyen dans le cas de mesures anti-démocratiques comme le vote électronique.)
- Faire tourner l'algorithme et publier le résultat.
Ça, c'était le principe général. Maintenant, le gros problème est évidemment le choix de bonnes sources aléatoires. Toute la section 3 est vouée à cette question. La source doit produire un résultat qui ne peut pas être facilement influencé et qui doit être accessible publiquement. (La section 6 détaille les problèmes de sécurité.)
La section 3.1 analyse les sources possibles et en identifie trois :
- Les loteries sérieusement organisées, notamment celles faites par l'État. Notez qu'une loterie particulière peut être truquée mais, d'une part, l'algorithme repose sur plusieurs sources, d'autre part les gens qui sont prêts à truquer une loterie le feront plutôt pour des gains financiers, pas pour perturber l'IETF.
- Les résultats financiers comme le prix de vente d'une action à la clôture de la Bourse ou le volume d'actions échangée en une journée. Ce ne sont pas des nombres aléatoires mais leur valeur dépend des actes de beaucoup d'opérateurs séparés, en pratique, le résultat exact sera imprévisible.
- Les événements sportifs mais ils posent pas mal de problèmes pratiques comme les risques d'annulation ou de retard.
Attention à ne pas mettre les plus mauvaises sources en dernier, car, avec la connaissance des autres sources, publiées avant, un attaquant qui peut influencer la dernière source aurait un pouvoir excessif.
On pourrait penser qu'il faut multiplier le nombre de sources, pour limiter le pouvoir de nuisance d'une source manipulée. Mais le RFC note que le mieux est l'ennemi du bien : chaque source supplémentaire est également une source de problème, par exemple si elle ne produit aucun résultat (évenement annulé, par exemple). Il recommande environ trois sources.
Aucun des types de source cités plus haut ne produit une distribution uniforme. C'est une des raisons pour lesquelles on doit les faire passer à travers une fonction de hachage (cf. RFC 4086) pour obtenir cette uniformité. Une autre raison est que, pour certaines sources, leur valeur approximative peut être influencée (le cours en Bourse d'une action peut grimper ou descendre selon la volonté d'un gros opérateur) mais pas la totalité des chiffres. Le hachage empêchera donc ledit influenceur d'obtenir le résultat qu'il désire (section 3.2).
La section 3.3 calcule la quantité d'entropie nécessaire pour sélectionner P vainqueurs parmi N possibilités. Par exemple, pour 100 candidats et 10 places, il faut 44 bits d'entropie. (À noter que la fonction de hachage MD5, utilisée par notre RFC en suivant le RFC 1321 ne fournit « que » 128 bits d'entropie.)
Un algorithme détaillé est ensuite présenté en section 4. Les valeurs obtenues des diverses sources sont transformées en chaînes de caractères (en les séparant par des barres obliques). Ce sont ces chaînes qui sont ensuite condensées par MD5. Un exemple complet figure dans la section 5. Notez la précision avec laquelle les sources sont définies !
Une mise en œuvre de référence figure en section 7. Je l'ai rassemblée dans une archive tar. On la compile ainsi :
% make cc -c -o rfc2777.o rfc2777.c cc -c -o MD5.o MD5.c cc -lm -o rfc2777 rfc2777.o MD5.o rfc2777.o: In function `main': rfc2777.c:(.text+0x16a): warning: the `gets' function is dangerous and should not be used.
et on l'utilise ainsi (sur l'exemple de la section 5) :
% ./rfc2777 Type size of pool: (or 'exit' to exit) 25 Type number of items to be selected: (or 'exit' to exit) 10 Approximately 21.7 bits of entropy needed. Type #1 randomness or 'end' followed by new line. Up to 16 integers or the word 'float' followed by up to 16 x.y format reals. 9 18 26 34 41 45 9 18 26 34 41 45 Type #2 randomness or 'end' followed by new line. Up to 16 integers or the word 'float' followed by up to 16 x.y format reals. 2 5 12 8 10 2 5 8 10 12 Type #3 randomness or 'end' followed by new line. Up to 16 integers or the word 'float' followed by up to 16 x.y format reals. 9319 9319 Type #4 randomness or 'end' followed by new line. Up to 16 integers or the word 'float' followed by up to 16 x.y format reals. float 13.6875 13.6875 Type #5 randomness or 'end' followed by new line. Up to 16 integers or the word 'float' followed by up to 16 x.y format reals. end Key is: 9.18.26.34.41.45./2.5.8.10.12./9319./13.6875/ index hex value of MD5 div selected 1 746612D0A75D2A2A39C0A957CF825F8D 25 -> 12 <- 2 95E31A4429ED5AAF7377A15A8E10CD9D 24 -> 6 <- 3 AFB2B3FD30E82AD6DC35B4D2F1CFC77A 23 -> 8 <- 4 06821016C2A2EA14A6452F4A769ED1CC 22 -> 3 <- 5 94DA30E11CA7F9D05C66D0FD3C75D6F7 21 -> 2 <- 6 2FAE3964D5B1DEDD33FDA80F4B8EF45E 20 -> 24 <- 7 F1E7AB6753A773EFE46393515FDA8AF8 19 -> 11 <- 8 700B81738E07DECB4470879BEC6E0286 18 -> 19 <- 9 1F23F8F8F8E5638A29D332BC418E0689 17 -> 15 <- 10 61A789BA86BF412B550A5A05E821E0ED 16 -> 22 <- Done, type any character to exit.
On note l'affichage de la clé (les valeurs séparées par des barres obliques) et celui du nombre de bits d'entropie nécessaires.
Outre les exemples de sélection du Nomcom qu'on trouve dans le
RFC, cette méthode a été utilisé pour sélectionner le préfixe
xn-- des IDN. Voici la
description
de la méthode et l'annonce
du résultat.
Un autre exemple intéressant sera l'utilisation de ce RFC 2777 pour sélectionner les /8 à donner aux RIR lors de l'épuisement final des adresses IPv4.
L'article seul
RFC 2681: A Round-trip Delay Metric for IPPM
Date de publication du RFC : Septembre 1999
Auteur(s) du RFC : Guy Almes (Advanced Network & Services, Inc.), Sunil Kalidindi (Advanced Network & Services, Inc.), Matthew J. Zekauskas (Advanced Network & Services, Inc.)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 25 septembre 2008
Les mesures de performances sur l'Internet sont un sujet passionnant mais complexe. Comme il faut bien commencer par définir précisement ce qu'on mesure, ce RFC ne spécifie pas un protocole mais uniquement une métrique, une grandeur qu'on veut mesurer et qui doit faire l'objet d'une définition rigoureuse. Cette métrique est le temps d'aller-retour (RTT) d'un paquet IP.
Cette mesure du RTT est connue grâce à l'outil ping. Mais ping a, entre autres défauts, celui de ne pas reposer sur une métrique rigoureuse, ce qui rend souvent difficile de savoir ce qu'il mesure exactement. Notre RFC s'attache donc à une définition précise d'une telle métrique. Il s'appuie pour cela sur le cadre et les définitions du RFC 2330, et suit de près le RFC 2679, qui décrivait une telle métrique pour les allers simples.
La section 1.1 du RFC commence par expliquer pourquoi une telle métrique est utile : notamment parce que certaines applications, notamment les plus interactives, fonctionnent mal si le RTT est trop élevé, que sa valeur minimale donne une idée des caractéristiques intrinsèques du lien et que des augmentations de ce RTT peuvent indiquer une congestion du lien. Elle est donc pertinente dans beaucoup de cas.
Mais pourquoi, continue cette section 1.1, mesurer le temps d'aller-retour et pas seulement celui d'aller simple comme le fait le RFC 2679 ? En effet, le RTT a plusieurs défauts : en cas de routage asymétrique, le temps de parcours aller peut être très différent du temps retour (et le RTT ne permet pas de voir cette différence). Même chose si des mécanismes divers (par exemple l'asymétrie des débits en ADSL) font qu'une direction a des caractéristiques très différentes d'une autre. C'est vrai, mais le RTT a aussi des avantages, notamment le fait qu'il est beaucoup plus facile à mesurer que l'aller simple, puisqu'il ne nécessite pas que les horloges des deux machines soient synchronisées (c'est sur ce principe que fonctionne ping).
Les lecteurs étant désormais convaincus de l'intérêt de cette métrique, la section 2 passe donc à sa définition : baptisée du nom scientifique de Type-P-Round-trip-delay, le temps d'aller-retour a pour paramètre les adresses IP de la source et de la destination, le temps T de la mesure, pour unité la seconde et pour définition (section 2.4) le délai entre la mise du premier bit de la question sur le câble et la réception du dernier bit de la réponse. Type-P signifie simplement qu'il peut dépendre du type du paquet (par exemple TCP vs. UDP, ou bien le numéro de port, tout ce qui fait qu'un routeur peut traiter ce paquet rapidement ou pas). Ainsi, les mesures de ping ont pour Type-P « ICMP avec des paquets echo ». Ce terme de Type-P est défini dans la section 13 du RFC 2330.
Cette définition est donc très simple sur le papier. En pratique, elle pose quelques problèmes, signalés par la section 2.5 : le temps T de la mesure dépend, lui, d'une bonne synchronisation des horloges, la définition n'indique pas à partir de quand on renonce à attendre un paquet perdu (le résultat de la mesure est alors indéfini), etc.
Ce n'est pas tout : même lorsque la métrique est parfaite, les ordinateurs sont des machines physiques ayant plein de limitations, qui limitent la précision de la mesure. Il est symptomatique du mauvais état de la métrologie sur Internet qu'on voit souvent citer des résultats sans indiquer les marges d'erreur ou d'incertitude. La section 2.7 cite certaines de leurs causes :
- Les faiblesses des horloges (section 2.7.1) sont à prendre en compte. Si la mesure du RTT ne nécessite pas de synchronisation de celles-ci (sauf pour déterminer le temps T de la mesure), elle demande par contre un peu de stabilité. Une dérive (skew) très forte ou, plus probable, un changement brusque de l'heure par l'opérateur ou par un logiciel peut fausser un résultat. De même, la résolution des horloges peut être trop mauvaise pour la rapidité des réseaux modernes.
- La définition du RTT est lié au concept de « mise sur le câble » des bits (section 2.7.2). Un programme typique n'a pas accès à l'information sur l'instant exact où le bit est envoyé. Le temps qu'il mesure est celui de la machine, pas celui de la carte réseau. (Mon programme echoping, qui mesure le RTT, n'essaie même pas de déterminer ce wire time, je ne pense pas qu'il existe une méthode portable sur Unix pour cela.)
- Le temps de réaction de la machine visée est souvent difficile à prédire (section 2.7.3). Les routeurs Cisco, par exemple, ne génèrent pas la réponse aux paquets ICMP echo sur la carte (fast path) mais dans leur processeur généraliste, bien plus lent. Avec de telles machines, le temps mesuré par ping est largement dominé par le temps de réponse du routeur et pas par le réseau proprement dit. Sur une machine Unix, ICMP est mis en œuvre dans le noyau, ce qui fournit certaines garanties, notamment que le swapping n'interviendra pas. Mais cela ne garantit pas, par exemple, qu'une surcharge du processeur de la machine ne va pas ajouter un délai inattendu. Si le Type-P est TCP avec le port 80, comme HTTP est typiquement mis en œuvre en mode utilisateur, les incertitudes sont bien plus grandes (swapping, temps de réponse de l'application - par exemple Apache, ...)
Une fois ces problèmes surmontés, il faut indiquer à l'utilisateur
le résultat des mesures. C'est l'objet de la section 2.8 qui insiste
sur la nécessité de transmettre au dit
utilisateur toutes les informations permettant d'interpréter les
données : le Type-P (pour echoping, il faut
utiliser l'option -v et encore, l'affichage du
Type-P n'est pas vraiment clair), la façon dont une
réponse en retard est considérée comme perdue, les résultats de l'étalonnage et le chemin suivi par les paquets
(à noter que cette information n'est en général pas accessible au
programme de mesure, à part éventuellement l'interface réseau de
sortie).
Une fois cette première métrique établie, le RFC, dans sa section 3, définit un échantillonage de cette mesure, selon une distribution de Poisson. Cette seconde métrique, définie de 3.1 à 3.4, a deux paramètres supplémentaires, le temps de fin de la mesure et le taux d'envoi des paquets (le lambda de la distribution de Poisson).
La section 3.5 discute du choix du paramètre lambda, en citant le RFC 2330. En gros, comme il s'agit d'une mesure active, plus lambda est élevé et plus la mesure est précise, mais plus on a perturbé le réseau avec tous ces paquets de test.
Munis de cette deuxième métrique, le RFC cite quelques statistiques intéressantes (section 4) qui peuvent être obtenues :
- Le Xème centile (section 4.1), c'est-à-dire la valeur du RTT pour laquelle X % des mesures tombent en dessous. Ainsi, le 90ème centile est la valeur du RTT telle que 90 % des mesures donnaient une RTT plus faible. Le 50ème centile est presque équivalent à la médiane, décrite en section 4.2.
- Le délai d'aller-retour minimum (section 4.3) qui reflète le cas idéal (réseau peu ou pas chargé, machine distante peu ou pas chargée et qui répond donc aux mieux de ses capacités).
Enfin, la section 5 est consacrée aux questions de sécurité. Comme
toutes les mesures actives, celles du RTT doivent garder à l'esprit la
nécessité de ne pas surcharger le réseau (ne pas utiliser l'option
-f de ping). Mais ce point concerne la sécurité
du réseau vis-à-vis des mesures. Il y a aussi un problème de sécurité
des mesures vis-à-vis du réseau. En effet, les équipements sur le
trajet peuvent fausser la mesure en retardant ou en donnant la
priorité à certaines paquets. En cas de mesure d'un réseau franchement
hostile, il peut être nécessaire de recourir à des techniques
cryptographiques pour préserver l'intégrité des mesures.
Un protocole utilisant cette métrique a été normalisé, TWAMP (RFC 5357).
L'article seul
RFC 2680: A One-way Packet Loss Metric for IPPM
Date de publication du RFC : Septembre 1999
Auteur(s) du RFC : Guy Almes (Advanced Network & Services), S. Kalidindi (Advanced Network & Services), M. Zekauskas (Advanced Network & Services)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 3 décembre 2010
Une des tristes réalités de l'Internet d'aujourd'hui est que les paquets se perdent. Ils quittent la machine émettrice et ne sont jamais reçus par la machine réceptrice. Il y a de nombreuses causes à cela (abandon du paquet par un routeur surchargé, par exemple), mais ce RFC 2680, comme les autres documents du groupe de travail IPPM se focalise sur la mesure du phénomène, pas sur ses causes. Il définissait donc une métrique « perte de paquet » permettant de comparer des mesures entre elles en sachant qu'on parle bien de la même chose. (Il a depuis été remplacé par le RFC 7680.)
Comme les autres RFC décrivant des
métriques, des grandeurs rigoureusement définies et qu'on va mesurer,
il s'appuie sur les définitions et le vocabulaire du RFC 2330. Par ailleurs, il suit de très près le plan du RFC 2679, qui spécifiait la mesure du délai
d'acheminement d'un paquet. Cette fois, ce qui est défini est une
mesure binaire (un paquet est perdu ou bien ne l'est pas),
Type-P-One-way-Loss, puis une statistique
pour le cas où il y a plusieurs paquets, le taux de
perte moyen. (Petit rappel : Type-P signifie que
le rapport de mesure doit indiquer le type du
paquet - protocole de transport, port, etc - car le
résultat peut en dépendre. Cf. section 2.8.1.)
Pourquoi cette métrique est-elle utile ? La section 1.1 rappelle l'intérêt de connaître les pertes :
- Certaines applications, notamment interactives, se comportent mal (ou pas du tout) si le taux de pertes dépasse un certain seuil.
- Les applications plus ou moins temps-réel aiment encore moins les pertes de paquets que les autres applications.
- Les protocoles de transport comme TCP compensent les pertes en réémettant les paquets mais un taux de pertes trop élevé les empêchera d'atteindre leur débit maximum.
Mais pourquoi mesurer les pertes sur un chemin aller-simple (one-way) plutôt que aller-retour (two-way) ? La célébrissime commande ping affiche en effet des pertes après un aller-retour (ici 57 %) :
% ping -c 19 198.51.100.80 PING 198.51.100.80 (198.51.100.80) 1450(1478) bytes of data. 1458 bytes from 198.51.100.80: icmp_seq=1 ttl=46 time=168 ms 1458 bytes from 198.51.100.80: icmp_seq=5 ttl=46 time=167 ms 1458 bytes from 198.51.100.80: icmp_seq=6 ttl=46 time=167 ms 1458 bytes from 198.51.100.80: icmp_seq=9 ttl=46 time=169 ms 1458 bytes from 198.51.100.80: icmp_seq=10 ttl=46 time=167 ms 1458 bytes from 198.51.100.80: icmp_seq=13 ttl=46 time=168 ms 1458 bytes from 198.51.100.80: icmp_seq=15 ttl=46 time=168 ms 1458 bytes from 198.51.100.80: icmp_seq=18 ttl=46 time=167 ms --- 198.51.100.80 ping statistics --- 19 packets transmitted, 8 received, 57% packet loss, time 18013ms rtt min/avg/max/mdev = 167.407/168.034/169.066/0.639 ms
Mais les mesures aller-retour ont bien des limites :
- Si le chemin est asymétrique, on mesure en fait les performances de deux chemins, l'aller et le retour, qui n'ont pas forcément les mêmes caractéristiques. Même si le chemin est symétrique (passage par les mêmes routeurs à l'aller et au retour), rien ne dit que les résultats soient les mêmes dans les deux sens : files d'attente différentes, QoS peut-être réglée différemment, etc.
- Beaucoup d'applications, par exemple les transferts de fichiers, voient leurs performances dépendre essentiellement d'un seul chemin (pour un transfert de fichiers, celui que suivent les données, pas le chemin inverse par lequel ne transitent que les petits accusés de réception).
Mais les mesures aller-simple sont plus difficiles à effectuer entre autres parce qu'elles ont souvent besoin d'horloges synchronisées (section 1.2). Le principe de la mesure de notre métrique est en effet d'émettre un paquet depuis la machine source à un temps T et de l'attendre à la machine destination jusqu'au temps T + t (où t est le délai qu'on accepte d'attendre). Si les deux machines ne sont pas synchronisées, leurs mesures de T vont différer, faussant ainsi les résultats. La section 1.2 rappelle donc le vocabulaire à utiliser pour évaluer la synchronisation. Les gourous de l'horlogerie verront qu'il est différent de celui des documents UIT comme le G.810, « Definitions and terminology for synchronization networks ».
- Synchronisation (synchronization) signifie que deux horloges sont d'accord entre elles sur l'heure qu'il est (time error pour l'UIT).
- Correction (accuracy) désigne le degré d'accord entre une horloge et la vraie heure UTC (time error from UTC pour l'UIT). Deux horloges peuvent donc être synchronisées et néanmoins incorrectes.
- Résolution (resolution) est la précision de l'horloge. Certains vieux Unix n'avancent ainsi l'horloge que toutes les dix ms et sa résolution est donc de 10 ms (cela se voyait bien avec la commande ping, qui n'affichait que des RTT multiples de 10). L'UIT dit sampling period.
- Décalage (skew) est le changement dans la synchronisation ou la correction. Il se produit lorsque l'horloge va plus ou moins vite qu'elle ne le devrait. L'UIT appelle cela time drift.
Une fois ces préliminaires achevés, la section 2 décrit la métrique
principale de notre RFC,
Type-P-One-way-Packet-Loss. Sa valeur est
simplement 0 lorsque le paquet est arrivé et 1 autrement.
Il y a bien sûr davantage de choses à dire sur cette métrique. Par exemple (section 2.5), faut-il distinguer le cas où un paquet a vraiment été perdu et le cas où il est simplement arrivé en retard, après l'expiration du délai ? En théorie, on devrait attendre 255 secondes, la durée de vie maximale d'un paquet IP (RFC 791, section 3.2). En pratique, on attendra moins longtemps : après tout, pour beaucoup d'applications, un paquet en retard n'a aucun intérêt, on peut aussi bien le considérer comme perdu. C'est l'approche retenue ici.
Et si le paquet arrive corrompu, le considère-t-on comme perdu ? Là encore, oui, pas de distinction. En effet, si le paquet est corrompu, on ne peut même pas être sûr qu'il était bien le paquet attendu, puisque les bits qui permettent de le reconnaître sont peut-être ceux qui ont été changés.
Même chose si le paquet est fragmenté et que certains des fragments n'arrivent pas à tout. On ne peut pas reconstituer le paquet, on le considère comme perdu. En revanche, la duplication, elle, n'est pas considérée comme une perte.
Notre RFC 2680 décrit une métrique (une grandeur définie rigoureusement), pas une méthodologie de mesure, encore moins un protocole. Toutefois, la section 2.6 donne des indications sur ce que pourrait être une telle méthodologie. Le mécanisme recommandé est de mettre une estampille temporelle dans le paquet émis, et de regarder à l'arrivée si on détecte le paquet au bout d'un temps « raisonnable ». À noter que cette méthode n'implique pas une stricte synchronisation des horloges entre les deux machines. On est loin d'un protocole complet (je n'ai pas l'impression qu'il ait jamais été mis au point) et, par exemple, on n'indique pas comment la destination sait qu'elle doit s'attendre à voir arriver un paquet.
Toute mesure implique des erreurs et des incertitudes et la section 2.7 les analyse. D'abord, si les horloges ne sont pas synchronisées du tout, un paquet peut être déclaré comme perdu à tort (si l'émetteur a une horloge qui retarde, le paquet arrivera tard et le destinataire aura pu s'impatienter et le considéré perdu). Même problème si le délai d'attente n'est pas raisonnable, si le destinataire renonce trop vite. Ces deux problèmes peuvent être évités en synchronisant à peu près les horloges (il suffit que leur écart soit petit par rapport au délai d'attente) et en choisissant bien le délai (par exemple, sur une liaison utilisant un satellite géostationnaire, la finitude de la vitesse de la lumière impose un délai d'attente minimum de 240 ms - 2 * 35 786 / 300 000).
Une troisième source d'erreur est plus subtile : le paquet peut arriver jusqu'à la machine de destination (donc le réseau fonctionne bien) mais celle-ci le rejeter car ses ressources (par exemple les tampons d'entrée/sortie) sont pleines. Pour éviter de compter à tort des paquets comme perdus, il faut s'assurer que la machine de mesure a des ressources suffisantes pour traiter tous les paquets.
La métrique présentée en section 2 était pour
un paquet. La section 3 définit une métrique
supplémentaires,
Type-P-One-way-Packet-Loss-Poisson-Stream pour le
cas où on utilise plusieurs paquets. Et la section 4 s'en sert pour
définir une statistique utile.
Type-P-One-way-Packet-Loss-Average (section 4.1)
est le taux de pertes moyen. Si
on envoie cinq paquets et que quatre arrivent, elle vaut 0,2 (c'est ce
qu'affiche ping sous l'intitulé %
packet loss).
Cette moyenne n'est pas toujours facile à évaluer. Ainsi, sur un lien Internet typique, le taux de pertes est bas (nettement moins de 1 %). Pour obtenir une valeur statistiquement significative, il faut souvent tester avec des centaines de paquets. Comme le note la section 5, consacrée à la sécurité, c'est un problème courant des mesures actives : elles peuvent perturber le réseau qu'elle observent.
Ce RFC 2680 a par la suite été évalué dans le RFC 7290, avec des résultats positifs. Cela a mené à son évolution en RFC 7680
L'article seul
RFC 2679: A One-way Delay Metric for IPPM
Date de publication du RFC : Septembre 1999
Auteur(s) du RFC : Guy Almes (Advanced Network & Services, Inc.), Sunil Kalidindi (Advanced Network & Services, Inc.), Matthew J. Zekauskas (Advanced Network & Services, Inc.)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 12 juillet 2009
Ce RFC définissait une métrique, une grandeur à mesurer, en l'occurrence le délai d'acheminement d'un paquet d'un point à un autre du réseau. Cela semble trivial, mais la définition rigoureuse de la métrique, permettant des mesures scientifiques et leur comparaison, prend vingt pages... (Il a depuis été remplacé par le RFC 7679.)
Comme tous les RFC du groupe de travail ippm, celui-ci s'appuie sur les définitions et le vocabulaire du RFC 2330, notamment la notion de Type-P (paquets IP ayant la même « signature », c'est-à-dire même protocole de couche 4, même numéro de port, etc, car certains équipements réseaux traitent différemment les paquets selon ces variables).
Commençons par le commencement, c'est-à-dire l'introduction, en section 2. Le RFC définit une métrique pour une mesure unique (un singleton) nommé Type-P-One-way-Delay, ainsi qu'un échantillonnage, pour le cas où la mesure est répétée, et enfin diverses statistiques agrégeant les résultats de plusieurs mesures. Pourquoi une telle métrique ? Comme le rappelle la section 2.1, celle-ci est utile dans des cas comme, par exemple :
- Estimer le débit maximal qu'on obtiendra (avec certains protocoles comme TCP, il est limité par le RTT).
- La valeur minimale de ce délai d'acheminement nous donne une idée du délai dû uniquement à la propagation (qui est limitée par la vitesse de la lumière) et à la transmission. (Voir aussi la section 5.3.)
- Par contre, son augmentation nous permet de détecter la présence de congestion.
Mais pourquoi un délai d'acheminement « aller-simple » et pas « aller-retour », comme le fait ping, ou bien comme le normalise le RFC 2681 ? Après tout, le délai aller-retour est bien plus simple à mesurer. Mais il a aussi des défauts :
- Une bonne partie des routes sur l'Internet sont asymétriques. Le délai aller-retour dépend donc de deux délais aller-simple, qui peuvent être très différents.
- Même si le chemin est symétrique, les politiques de gestion de la file d'attente par les routeurs peuvent être très différentes dans les deux sens.
- Certains protocoles s'intéressent surtout aux performances dans une direction. C'est le cas du transfert d'un gros fichier, où la direction des données est plus importante que celle des accusés de réception.
Le RFC ne le mentionne apparemment pas, mais on peut aussi dire que la mesure d'un délai aller-retour dépend aussi du temps de réflexion par la machine distante (avec ping, si la machine visée est très chargée, la génération du paquet ICMP de réponse peut prendre un temps non négligeable ; c'est encore pire avec des protocoles applicatifs, où la réflexion n'est pas faite dans le noyau, et est donc vulnérable à par exemple, le swapping).
Comme avec tout système de mesure, les horloges et leurs imperfections jouent un rôle crucial. La section 2.2 rappelle des concepts (voir le RFC 2330) comme la synchronisation (le fait que deux horloges indiquent la même valeur) ou le décalage (le fait qu'une horloge aille plus ou moins vite qu'une autre).
Enfin, après tous ces préliminaires, le RFC en arrive à la définition de la métrique, en section 3. Type-P-One-way-Delay est définie comme une fonction de divers paramètres comme les adresses IP des deux parties et l'instant de la mesure. La mesure dépend aussi du Type-P (par exemple parce que certains ports sont favorisés par la QoS). Elle est en secondes. Et sa définition (section 3.4) est « Le temps entre l'envoi du premier bit du paquet sur le câble et la réception du dernier bit du paquet depuis le câble ». Si le paquet n'arrive pas, le délai est dit « indéfini » et, en pratique, pris comme étant infini.
Ce n'est pas tout de définir une métrique, il faut aussi la mesurer. Dans le monde réel, cela soulève quelques problèmes, couverts par la section 3.5. Le principal étant évidemment la synchronisation des horloges. Si le paquet part à 1247389451,578306110 (en secondes depuis le 1er janvier 1970) et arrive à 1247389453,018393817, le délai a t-il réellement été de 1,44 secondes ou bien seulement de 1,32 secondes mais les horloges différaient de 0,12 secondes ? Comme des délais peuvent être aussi bas que 100 µs, une synchronisation précise est nécessaire. Le GPS est une bonne solution pour cela, NTP une moins bonne, car sa résolution est plus faible et il dépend du réseau qu'on veut mesurer.
IL faut aussi tenir compte de problèmes comme les paquets perdus (si le délai de garde est de cinq secondes, un paquet perdu ne doit pas compter pour un délai d'acheminement de cinq secondes, ou bien des agrégats comme la moyenne seront complètement faussés) ou comme la duplication de paquets (dans ce cas, le RFC précise que c'est la première occurrence qui compte).
Enfin, pour celui qui voudrait concevoir un protocole de mesure de cette métrique, le RFC suggère une méthodologie, en section 3.6 :
- S'assurer de la synchronisation des horloges,
- Former le paquet et y mettre l'instant de départ sur le câble (sur une machine non temps réel, cela peut être délicat de mettre cet instant exact) ,
- À la réception, mesurer l'instant et calculer la différence avec ce qui est indiqué dans le paquet,
- Évaluer l'erreur (il y en aura forcément) et, éventuellement, corriger.
Cette question de l'analyse d'erreur fait l'objet de la section
3.7. Les deux principales sources d'erreur seront liées aux horloges
(qui ne sont jamais parfaites) et à la différence entre le temps de
départ ou d'arrivée mesuré et le temps réel. Sur un système d'exploitation multi-tâches et non
temps réel comme Unix,
le temps entre le moment où le paquet arrive dans la carte
Ethernet et celui où l'application peut appeler
gettimeofday() est souvent
significatif (section 3.7.2) et, pire, variable et imprévisible (car
on dépend de l'ordonnanceur). Parmi les
mécanismes pour déterminer l'erreur, de façon à pouvoir effectuer les
corrections, le RFC suggère la calibration
(section 3.7.3).
Une fois qu'on a bien travaillé et soigneusement fait ses mesures, il est temps de les communiquer à l'utilisateur. C'est l'objet de la section 3.8. Elle insiste sur l'importance d'indiquer le Type-P, les paramètres, la métode de calibration, etc. Si possible, le chemin suivi par les paquets dans le réseau devrait également être indiqué.
Maintenant, la métrique pour une mesure isolée, un singleton, est définie. On peut donc bâtir sur elle. C'est ce que fait la section 4, qui définit une mesure répétée, effectuée selon une distribution de Poisson, Type-P-One-way-Delay-Poisson-Stream.
Une fois cette métrique définie, on peut créer des fonctions d'agrégation des données, comme en section 5. Par exemple, la section 5.1 définit Type-P-One-way-Delay-Percentile qui définit le délai d'acheminement sous lequel se trouvent X % des mesures (les mesures indéfinies étant comptées comme de délai infini). Ainsi, le 95ème percentile indique le délai pour lequel 95 % des délais seront plus courts (donc une sorte de « délai maximum en écartant les cas pathologiques »). Attention en regardant l'exemple, le RFC comporte une erreur. La section 5.2 définit Type-P-One-way-Delay-Median qui est la médiane (équivalente au 50ème percentile, si le nombre de mesures est impair). La moyenne, moins utile, n'apparait pas dans ce RFC.
Au moins un protocole a été défini sur la base de cette métrique, OWAMP, normalisé dans le RFC 4656 et mis en œuvre notamment dans le programme de même nom. Depuis, cette métrique a été légèrement modifiée dans le RFC 7679.
L'article seul
RFC 2672: Non-Terminal DNS Name Redirection
Date de publication du RFC : Août 1999
Auteur(s) du RFC : Matt Crawford (Fermilab)
Chemin des normes
Première rédaction de cet article le 7 septembre 2006
Dernière mise à jour le 16 octobre 2007
Depuis sa normalisation dans le RFC 1034, le DNS a suscité le développement d'innombrables extensions, plus ou moins réalistes, plus ou moins utilisées. L'enregistrement DNAME, sujet de ce RFC, semble très peu utilisé : il permet de donner un synonyme à une zone entière, pas à un seul nom, comme le fait l'enregistrement CNAME. (Ce RFC a depuis été remplacé par une version 2, dans le RFC 6672.)
Les enregistrements DNAME permettent d'écrire des équivalences comme :
vivendi-environnement.fr. DNAME veolia.fr.
et un nom comme www.vivendi-environnement.fr sera
transformé en www.veolia.fr. Le but étant ici de
changer le nom de l'entreprise en Veolia sans
avoir à s'inquiéter de toutes les occcurrences de l'ancien nom qui
trainent dans des signets privés,
dans la presse écrite, sur del.icio.us,
etc.
En fait, les enregistrements DNAME ne sont pas aussi simples que
cela. Le DNAME ne s'applique pas réellement à la zone mais à tous les
sous-domaines de l'apex. Il faut donc dupliquer
tous les enregistrements de l'apex (typiquement, les MX et les NS). Le
vrai fichier de zone pour
videndi-environnement.fr ressemblerait plutôt à :
@ IN SOA ... Dupliquer le SOA de veolia.fr
IN NS ... Idem pour NS et MX
IN MX ...
IN DNAME veolia.fr.
; Et ça suffit, les noms comme www.vivendi-environnement.fr seront
; gérés par le DNAME.
Notre RFC prévoit le cas où le client DNS ignore les DNAME et le serveur devrait alors synthétiser des enregistrements CNAME équivalents.
Les DNAME sont mis en œuvre dans BIND
et nsd (depuis très peu de temps pour ce
dernier) mais semblent peu déployés (si vous voulez regarder ce que
cela donne, testez testonly.sources.org qui est
un DNAME de example.org donc, par exemple,
www.testonly.sources.org existe). Selon moi, une des raisons est
que le problème peut se résoudre tout aussi simplement, sans
changement dans le DNS, par l'utilisation d'une
préprocesseur ou bien en créant un lien
symbolique entre les deux fichiers de zone (si le fichier ne contient
que des noms relatifs, ça marche très bien, que ce soit avec BIND ou
avec nsd).
L'article seul
RFC 2671: Extension Mechanisms for DNS (EDNS0)
Date de publication du RFC : Août 1999
Auteur(s) du RFC : Paul Vixie (Internet Software Consortium)
Chemin des normes
Première rédaction de cet article le 13 mars 2007
Dernière mise à jour le 7 février 2008
Le protocole DNS a presque vingt ans d'âge dans sa forme actuelle. Il souffre de nombreuses limites et notre RFC vise à permettre d'en surmonter certaines, notamment celle de la taille maximale des réponses. (Il a depuis été remplacé par le RFC 6891.)
Le DNS, dans sa forme originale, spécifiée dans le RFC 1034, ne permettait pas de négocier des options, d'indiquer au serveur ce que sait faire le client, en plus des capacités minimales qu'impose le protocole. Par exemple, la norme originale (RFC 1035, section 2.3.4) imposait une limite de 512 octets aux messages DNS envoyés sur UDP. Une telle limite est bien trop basse aujourd'hui, à la fois compte-tenu des nouvelles demandes (IPv6, IDN, DNSSEC, tous demandent des données DNS plus grandes) et des capacités des réseaux et des machines modernes. Notre RFC a donc été écrit pour traiter ce problème.
EDNS0 est un mécanisme d'extension du DNS et une première extension, pour indiquer une taille supérieure aux 512 octets. L'extension se fait en squattant des champs inutilisés du paquet (DNS est un format binaire rigide, il ne permet donc pas facilement d'ajouter de nouvelles possibilités) et en créant un pseudo-type d'enregistrement, le type OPT.
La nouvelle extension pour indiquer la taille permet au client de
spécifier la quantité d'octets qu'il est capable de recevoir. Avec le
client DNS dig, cela se fait avec l'option
bufsize.
Prenons par exemple le TLD de
Hong Kong,
.hk car c'est un des plus
gros en nombre de serveurs de noms. Si je demande cette liste :
% dig NS hk. ; <<>> DiG 9.3.4 <<>> NS hk ;; global options: printcmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 23662 ;; flags: qr rd ra; QUERY: 1, ANSWER: 15, AUTHORITY: 0, ADDITIONAL: 6 ;; QUESTION SECTION: ;hk. IN NS ;; ANSWER SECTION: hk. 604781 IN NS NS-HK.RIPE.NET. hk. 604781 IN NS B.DNS.TW. hk. 604781 IN NS NS1.HKIRC.NET.hk. hk. 604781 IN NS NS2.CUHK.EDU.hk. hk. 604781 IN NS NS2.HKIRC.NET.hk. hk. 604781 IN NS NS3.CUHK.EDU.hk. hk. 604781 IN NS SEC3.APNIC.NET. hk. 604781 IN NS TLD1.ULTRADNS.NET. hk. 604781 IN NS TLD2.ULTRADNS.NET. hk. 604781 IN NS TLD3.ULTRADNS.ORG. hk. 604781 IN NS TLD4.ULTRADNS.ORG. hk. 604781 IN NS TLD5.ULTRADNS.INFO. hk. 604781 IN NS TLD6.ULTRADNS.CO.UK. hk. 604781 IN NS ADNS1.BERKELEY.EDU. hk. 604781 IN NS ADNS2.BERKELEY.EDU. ;; ADDITIONAL SECTION: NS1.HKIRC.NET.hk. 26468 IN A 203.119.2.18 NS2.CUHK.EDU.hk. 133160 IN A 137.189.6.21 NS2.HKIRC.NET.hk. 26468 IN A 203.119.2.19 NS3.CUHK.EDU.hk. 133160 IN A 202.45.188.19 SEC3.APNIC.NET. 43917 IN A 202.12.28.140 SEC3.APNIC.NET. 43917 IN AAAA 2001:dc0:1:0:4777::140 ;; Query time: 1 msec ;; SERVER: 192.134.4.162#53(192.134.4.162) ;; WHEN: Tue Mar 13 10:22:41 2007 ;; MSG SIZE rcvd: 508
On voit que la réponse était proche des 512 octets et que, pour qu'elle tienne dans cette limite, le serveur a dû sérieusement réduire la taille de la section additionnelles (additional section). Si le serveur avait dû réduire encore plus, jusqu'à retirer des enregistrements de la section réponse (answer section), il aurait dû mettre le bit TC (troncation) à VRAI, imposant ainsi au client de reessayer en TCP.
Mais EDNS0 permet d'avoir la totalité de la section additionnelle (notez la pseudo-section lié à l'enregistrement OPT) :
% dig +bufsize=4096 NS hk ; <<>> DiG 9.3.4 <<>> +bufsize=4096 NS hk ;; global options: printcmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 36374 ;; flags: qr rd ra; QUERY: 1, ANSWER: 15, AUTHORITY: 0, ADDITIONAL: 12 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;hk. IN NS ;; ANSWER SECTION: hk. 604800 IN NS B.DNS.TW. hk. 604800 IN NS NS1.HKIRC.NET.hk. hk. 604800 IN NS NS2.CUHK.EDU.hk. hk. 604800 IN NS NS2.HKIRC.NET.hk. hk. 604800 IN NS NS3.CUHK.EDU.hk. hk. 604800 IN NS SEC3.APNIC.NET. hk. 604800 IN NS TLD1.ULTRADNS.NET. hk. 604800 IN NS TLD2.ULTRADNS.NET. hk. 604800 IN NS TLD3.ULTRADNS.ORG. hk. 604800 IN NS TLD4.ULTRADNS.ORG. hk. 604800 IN NS TLD5.ULTRADNS.INFO. hk. 604800 IN NS TLD6.ULTRADNS.CO.UK. hk. 604800 IN NS ADNS1.BERKELEY.EDU. hk. 604800 IN NS ADNS2.BERKELEY.EDU. hk. 604800 IN NS NS-HK.RIPE.NET. ;; ADDITIONAL SECTION: NS1.HKIRC.NET.hk. 26487 IN A 203.119.2.18 NS2.CUHK.EDU.hk. 133179 IN A 137.189.6.21 NS2.HKIRC.NET.hk. 26487 IN A 203.119.2.19 NS3.CUHK.EDU.hk. 133179 IN A 202.45.188.19 SEC3.APNIC.NET. 43936 IN A 202.12.28.140 SEC3.APNIC.NET. 43936 IN AAAA 2001:dc0:1:0:4777::140 TLD2.ULTRADNS.NET. 105673 IN A 204.74.113.1 TLD3.ULTRADNS.ORG. 19273 IN A 199.7.66.1 TLD5.ULTRADNS.INFO. 3385 IN A 192.100.59.11 ADNS1.BERKELEY.EDU. 2047 IN A 128.32.136.3 ADNS2.BERKELEY.EDU. 65275 IN A 128.32.136.14 ;; Query time: 22 msec ;; SERVER: 192.134.4.162#53(192.134.4.162) ;; WHEN: Tue Mar 13 10:22:22 2007 ;; MSG SIZE rcvd: 599
Et voilà, tout le monde est désormais content.
EDNS0 a été normalisé il y a sept ans (une mise à jour de la norme a eu lieu avec le RFC 6891, qui remplace cleui-ci). EDNS0 est mis en œuvre dans BIND depuis la version 9. Malheureusement, bien des serveurs et des résolveurs ne le déploient pas encore ou, s'ils le font, sont bloqués par un coupe-feu mal programmé ou mal configuré. Ainsi, l'ICANN, avant d'autoriser l'ajout d'adresses IPv6 aux serveurs de noms de la racine, a dû se lancer dans un long processus de test, prenant notamment en compte les obstacles au déploiement de EDNS0. (Ces adresses ont finalement été ajoutées le 4 février 2008.) Le même problème se reposera sans doute pour la signature de la racine en 2010.
Pour les amateurs de programmation, du code C d'analyse d'un paquet DNS contenant de l'EDNS est dans mon article « Décoder les paquets DNS capturés avec pcap ».
L'article seul
RFC 2663: IP Network Address Translator (NAT) Terminology and Considerations
Date de publication du RFC : Août 1999
Auteur(s) du RFC : Pyda Srisuresh (Lucent Technologies), Matt Holdrege (Lucent Technologiesv)
Pour information
Première rédaction de cet article le 15 novembre 2007
Ce RFC semble être le premier à avoir parlé du NAT et à avoir tenté de le définir, de lister ses propriétés, et de proposer un vocabulaire standard.
Le déploiement du NAT, à partir de la fin des années 1990, était largement dû à l'épuisement des adresses IPv4 et à la difficulté d'en obtenir suffisamment. Mais ce déploiement s'est fait en dehors de l'IETF, sans standardisation, sans description rigoureuse des fonctions effectuées par le routeur NAT. Plusieurs protocoles IETF ne pouvant pas passer certains NAT (cf. RFC 3027), plusieurs RFC ont été écrits pour proposer des solutions, et, avant tout, pour bien définir le problème.
Il existe deux grandes terminologies (qui se recouvrent partiellement) : celle de STUN (RFC 3489) bâtie sur la notion de cône (le NAT fait correspondre un large pool d'adresses vers un pool plus petit, d'où l'image du cône), et une terminologie qui semble s'être imposée, celle de notre RFC, qui a été ultérieurement reprise et étendue par le groupe Behave, par exemple dans le RFC 4787.
C'est donc notre RFC qui définit, dans sa section 4, des termes comme :
- Basic NAT qui ne travaille que sur les adresses IP,
- NAPT, qui travaille aussi sur les numéros de port,
- etc.
Je recommande, si on veut une bonne introduction aux problèmes posés par le NAT, l'excellent article Peer-to-Peer Communication Across Network Address Translators.
L'article seul
RFC 2648: A URN Namespace for IETF Documents
Date de publication du RFC : Août 1999
Auteur(s) du RFC : Ryan Moats (AT&T)
Pour information
Première rédaction de cet article le 2 mars 2007
L'IETF produit des documents, c'est son activité essentielle. Ces documents ayant un caractère normatif, il faut pouvoir les identifier via un identificateur formel unique. Ce RFC propose d'utiliser les URN pour cela.
Notre RFC alloue donc un nouvel espace de nommage
ietf aux URN. Le RFC 4408 va donc devenir
urn:ietf:rfc:4408. Les documents Best
Common Practices, les BCP, qui sont des liens vers un RFC
donné vont également pourvoir être référencés. Par exemple, le BCP 47,
Tags for Identifying Languages est actuellement le
RFC 4646 mais il a longtemps été le RFC 3066 et avant cela le RFC 1766. Son nouvel
identificateur sera urn:ietf:bcp:47. À noter que ce RFC a
depuis été étendu et précisé par le RFC 6924.
Ce RFC ne propose pas de mécanisme de
résolution pour accéder à un RFC via son URN. Un
tel mécanisme pourrait par exemple être bâti sur DDDS (RFC 3403 et RFC 3404). Il inclus juste quelques scripts Perl qui peuvent servir à un service de
résolution (par exemple, l'un d'eux peut convertir un URN IETF en
URL). (Les amateurs d'Emacs
Lisp préféreront peut-être browse-urn.el.
J'ai aussi trouvé une extension
Firefox mais qui ne marche pas pour moi.)
Est-ce cause de cela ? En tout cas, ce RFC a été un échec et on ne
voit presque jamais d'URN IETF dans la nature. Les RFC sont toujours cités de
manière informelle, par leur numéro, ou sous forme d'un lien vers
http://www.rfc-editor.org/rfc.html ou bien http://www.ietf.org/rfc.html ou encore http://tools.ietf.org/html/.
L'article seul
RFC 2645: ON-DEMAND MAIL RELAY (ODMR) ; SMTP with Dynamic IP Addresses
Date de publication du RFC : Août 1999
Auteur(s) du RFC : R. Gellens (Qualcomm)
Chemin des normes
Première rédaction de cet article le 11 mars 2009
Le protocole de transfert de courrier électronique SMTP, normalisé dans le RFC 5321, est prévu pour des cas où la connexion est la règle et l'absence de connexion une exception. S'il ne peut joindre le serveur suivant, le MTA SMTP réessaie de temps en temps, pendant trois à cinq jours puis renonce. Ce mécanisme ne marche pas lorsque le serveur suivant n'a pas d'adresse IP fixe, ce qui est fréquent, ou bien lorsqu'il est fréquemment déconnecté (tellement fréquemment que les périodes où l'envoyeur essaie ont de fortes chances de ne pas coïncider avec celles où le receveur est connecté). Il existe plusieurs solutions à ce problème et notre RFC normalisait ODMR (On-demand mail relay), également appelé ATRN (Authenticated TURN). Il n'a pas été un succès et reste très peu déployé aujourd'hui.
Parmi les concurrents de ODMR, une autre
extension de SMTP, ETRN,
normalisée dans le RFC 1985. Mais ETRN nécessitait une
adresse IP fixe. Au contraire, le principe de
ODMR, une extension de SMTP, est simple : le receveur contacte
l'envoyeur en SMTP, sur le port 366, à son
choix, à l'heure qu'il veut,
s'authentifie, et envoie une commande SMTP, ATRN
qui prend en paramètre un ou plusieurs noms de domaine. L'envoyeur
expédie alors, toujours en SMTP, le courrier de ce domaine (section 4 du RFC). Voici un
exemple, pris dans la section 6, où le receveur est example.org et son
fournisseur de courrier, qui lui garde en attendant la connexion de
son client, est example.net :
P: 220 EXAMPLE.NET on-demand mail relay server ready C: EHLO example.org P: 250-EXAMPLE.NET P: 250-AUTH CRAM-MD5 EXTERNAL P: 250 ATRN C: AUTH CRAM-MD5 P: 334 MTg5Ni42OTcxNzA5NTJASVNQLkNPTQo= C: Zm9vYmFyLm5ldCBiOTEzYTYwMmM3ZWRhN2E0OTViNGU2ZTczMzRkMzg5MAo= P: 235 now authenticated as example.org C: ATRN example.org,example.com P: 250 OK now reversing the connection C: 220 example.org ready to receive email P: EHLO EXAMPLE.NET C: 250-example.org C: 250 SIZE P: MAIL FROM: <Lester.Tester@dot.foo.bar> C: 250 OK P: RCPT TO: <l.eva.msg@example.com> C: 250 OK, recipient accepted ... P: QUIT C: 221 example.org closing connection
La machine à états complète d'ODMR est
présentée en section 5. Notez que
l'authentification est obligatoire (section 5.1.2). Pour
réclamer le courrier de example.org, il faut
prouver qui on est ! Dans l'exemple ci-dessus, l'authentification se
fait en CRAM-MD5, la seule méthode que tous les
clients et serveurs ODMR doivent mettre en
œuvre. ATRN lui-même est décrit en section
5.2.1. Comme dans l'exemple ci-dessus, il peut prendre plusieurs noms
de domaine comme paramètre. Le « retournement » de la session SMTP est
dans la section 5.3 (le serveur ODMR devient client SMTP et
réciproquement). Les codes de réponse ODMR sont en section 7. Par
exemple, un ATRN lorsqu'il n'y a pas eu
authentification renvoie 530 Authentication required.
Comme indiqué plus haut, ODMR nécessite un accord préalable avec un
fournisseur de messagerie (qui peut être n'importe où sur
l'Internet et n'est pas forcé d'être le
FAI). Les enregistrements MX du domaine du récepteur, mettons
example.org, sont alors pointés vers le serveur
ODMR du fournisseur. Je ne trouve pas de liste de fournisseurs gérant
ODMR, probablement parce que cette technique n'est quasiment plus utilisée.
Le fournisseur, outre l'exigence d'authentification, peut prendre d'autres précautions comme de restreindre l'accès au port 366 à certaines adresses IP (section 8).
J'ai indiqué qu'ODMR semble abandonné. Quelles sont les alternatives ? On trouve des solutions spécifiques d'un fournisseur, avec un protocole privé tournant sur un port donné, sur lequel le client est censé se connecter pour annoncer sa disponibilité. Aujourd'hui, comme hier, UUCP semble nettement dominer ce domaine d'application.
Il ne semble pas exister beaucoup d'implémentations activement maintenues de ODMR. Le démon odmr semble fonctionner avec le MTA Postfix. Brian Candler avait écrit un odmrd pour Courier, démon qui ne semble plus exister. Un plan détaillé de mise en œuvre dans Postfix avait été écrit mais ne semble pas avoir été mené à bout.
Côté client (le receveur de courrier), fetchmail gère ODMR, on peut utiliser l'option --protocol ODMR.
L'article seul
RFC 2629: Writing I-Ds and RFCs using XML
Date de publication du RFC : Juin 1999
Auteur(s) du RFC : M. Rose (Invisible Worlds)
Pour information
Première rédaction de cet article le 9 mars 2006
Dans toute organisation qui s'occupe de technique, le choix du format de fichiers pour la documentation est une question délicate et souvent polémique. L'IETF n'y échappe pas et ce RFC, qui tentait de normaliser un format XML pour l'écriture des RFC n'a pas été un succès complet. (Depuis, il a été remplacé par le RFC 7749.)
Contrairement à beaucoup d'organisations de normalisation, qui produisent des normes dans des formats spécifiques d'un traitement de textes commercial, au mépris des besoins et intérêts des lecteurs, l'IETF a toujours insisté sur l'importance de publier dans un format ouvert. Pour des raisons historiques, les RFC sont publiés en texte brut, encodé en ASCII (ce qui ne permet pas d'afficher correctement les noms des auteurs non anglo-saxons). Toujours pour des raisons historiques, l'éditeur des RFC (qui est indépendant de l'IETF) utilise nroff comme format d'entrée (décrit dans le RFC 2223). Si cela peut sembler archaïque, il faut se rappeler que l'IETF a des exigences bien particulières et qu'un RFC n'est pas une note de service, qui sera jetée au bout de quelques semaines : étant (souvent) une norme, le RFC doit pouvoir être lu par tous, pas seulement par les clients de Microsoft, et il doit être pérenne (le RFC sur IP, le RFC 791 date de septembre 1981 ; quel traitement de textes à forts effets visuels pourrait durer aussi longtemps ?).
Ce format antédiluvien pose néanmoins de plus en plus de problèmes et des alternatives ont été proposées. Il est intéressant de noter qu'aucune n'a fait l'objet d'un consensus et, l'IETF n'ayant aucun moyen de trancher ce genre de querelles, les auteurs de RFC continuent à utiliser plusieurs formats.
Les deux formats les plus utilisés sont le gabarit MS-Word, décrit dans le RFC 3285 et un format XML, décrit dans notre RFC.
Compte-tenu des avantages de XML (portabilité, ouverture du format, possibilité
d'édition avec n'importe quel éditeur et
possibilité de produire facilement des formats d'affichage comme
HTML), le choix semblait évident. Notre RFC
décrit, grâce à une DTD, les éléments XML
autorisés (au nombre de 42, ce qui rend ce langage bien plus simple
que DocBook ou
OpenDocument). On trouve des outils de
conversion (par exemple vers nroff) de ce format, un index en XML des RFC (je l'utilise pour
créer automatiquement le point de départ des articles RFC de ce blog), et des documents
d'exemple sur http://xml.resource.org/.
Notre RFC apparait donc ainsi en HTML et le source XML commence avec :
<rfc number="2629" category="info"> <title>Writing I-Ds and RFCs using XML</title> <author initials="M.T." surname="Rose" fullname="Marshall T. Rose"> <email>mrose@not.invisible.net</email> </author> <date month="June" year="1999"/> <section title="Introduction" toc="default"> <t>This memo describes how to write a document for the I-D and RFC series using <xref target="XML" format="default" pageno="false">the Extensible Markup L anguage</xref> (XML). This memo has three goals: <list style="numbers"> <t>To describe a simple XML Document Type Definition (DTD)
Notre RFC souffre de son âge par exemple en utilisant toujours une DTD, technique désormais dépassée. Et la principale transformation, celle en texte, n'est pas faite avec XSLT mais avec un script TCL ad hoc. Une nouvelle version de notre RFC est à l'étude depuis un certain temps.
Comme l'a montré encore récemment une longue discussion à l'IETF, il ne manquait plus à ce format que l'adoption généralisée... Peut-être que son successeur, le RFC 7749 réussira mieux.
L'article seul
RFC 2616: Hypertext Transfer Protocol -- HTTP/1.1
Date de publication du RFC : Juin 1999
Auteur(s) du RFC : Roy T. Fielding (Department of Information and Computer Science), James Gettys (World Wide Web Consortium), Jeffrey C. Mogul (Compaq Computer Corporation), Henrik Frystyk Nielsen (World Wide Web Consortium), Larry Masinter (Xerox Corporation), Paul J. Leach (Microsoft Corporation), Tim Berners-Lee (World Wide Web Consortium)
Chemin des normes
Première rédaction de cet article le 6 juin 2007
Pas besoin de présenter HTTP, un des protocoles les plus importants de l'Internet, en raison du succès du Web. Notre RFC était la norme officielle de HTTP, depuis remplacé par une série de huit RFC.
Le Web a beaucoup évolué depuis la sortie du RFC mais son protocole principal reste le même, HTTP 1.1. Contrairement aux normes portant sur le format des données, qui sont en général réalisées par le W3C, HTTP est une norme IETF. Le RFC est très long car, si HTTP est très simple dans son principe (ce qui a beaucoup aidé à son succès), il contient de nombreux détails (par exemple de nombreux en-têtes peuvent être transmis entre serveurs et clients pour des options variées) et je parie que peu de logiciels mettent en œuvre la totalité du RFC.
On notera aussi que, si HTTP est surtout connu pour permettre à un
navigateur Web d'accéder à une page
HTML, il peut aussi servir de protocole pour
permettre à deux applications de communiquer, notamment en suivant
l'architecture REST (voir programmation-rest.html et signaler-a-signal-spam.html
pour des exemples REST). Ainsi, des protocoles comme IPP (RFC 2911) ou XCAP, XML Configuration Access
Protocol (RFC 4827), utilisent HTTP (pas forcément
en REST). Un RFC a même été écrit pour essayer de décrire dans quels
cas il était souhaitable de réutiliser HTTP pour un protocole
Internet, le RFC 3205.
Le protocole repose sur un mécanisme requête /
réponse très simple (section 1.4). Le client se connecte en
TCP au serveur, envoie une requête sur une
seule ligne, la requête incluant un URI, éventuellement des options sous forme d'en-têtes
analogues à ceux du courrier électronique (Accept:
text/*), éventuellement un contenu, et reçoit une réponse sous forme d'un code
numérique indiquant de manière non ambigüe le résultat de la requête,
d'en-têtes optionnels et d'un corps, la ressource demandée.
Le terme de ressource est défini dans la section 1.3. Il est plus général que celui de page. Une ressource n'est pas forcément une page HTML, ce n'est même pas toujours un fichier.
Il existe plusieurs requêtes, définies en section 5.1.1. Les plus connues sont GET (récupérer une ressource, sans rien modifier), POST (modifier une ressource), PUT (créer une nouvelle ressource) et DELETE (comme son nom l'indique). Mais il faut noter que, si les applications REST, par définition, utilisent les différentes requêtes pour les différentes actions qu'elles peuvent effectuer, le navigateur Web typique ne connait que GET et POST. Et beaucoup d'applications ne sont pas REST, utilisant par exemple le POST comme un fourre-tout, l'action étant exprimée par un paramètre du POST et pas par la requête. C'est dommage, car la sémantique de chaque requête est rigoureusement définie par le RFC (voir particulièrement la section 9.1), notamment pour ce qui concerne les caches, l'idempotence et les invariants comme GET(PUT(x)) = x (en français : après un PUT, un GET du même URI doit donner la ressource transmise lors du PUT).
Les codes numériques de retour sont à trois chiffres, le premier chiffre indiquant la catégorie (2 est un succès, 4 une erreur dûe au client, 5 une erreur dûe au serveur, etc), comme avec SMTP. L'erreur la plus célèbre est sans doute la 404, « ressource non trouvée », décrite dans la section 10.4.5, qui se produit par exemple lorsqu'un webmestre n'a pas lu l'article Cool URIs don't change et a changé ses fichiers de place.
Il existe évidemment une pléthore de logiciels clients et serveurs
HTTP, puisque les navigateurs Web et les serveurs comme Apache, parlent tous HTTP. Mais, pour apprendre le
protocole, les clients en ligne de commande
sont très pratiques. Ici, curl avec l'option
--verbose permet de voir les requêtes envoyées par le
client au serveur (elles sont précédées d'un signe >) et les
réponses du serveur (précédées d'un signe <) :
% curl --verbose http://www.bortzmeyer.org/2616.html * About to connect() to www.bortzmeyer.org port 80 * Trying 80.67.170.20... connected * Connected to www.bortzmeyer.org (80.67.170.20) port 80 > GET /2616.html HTTP/1.1 > User-Agent: curl/7.15.5 (i486-pc-linux-gnu) libcurl/7.15.5 OpenSSL/0.9.8c zlib/1.2.3 libidn/0.6.5 > Host: www.bortzmeyer.org > Accept: */* > < HTTP/1.1 404 Not Found < Date: Wed, 06 Jun 2007 13:20:03 GMT < Server: Apache/1.3.26 Ben-SSL/1.48 (Unix) Debian GNU/Linux AuthMySQL/3.1 mod_throttle/3.1.2 mod_watch/3.17 < Connection: close < Transfer-Encoding: chunked < Content-Type: text/html; charset=iso-8859-1 ...
Ou bien, avec wget, son option --debug, et une ressource qui existe (dans le cas
ci-dessus, le fichier n'avait pas encore été copié sur le serveur,
d'où le résultat 404) :
% wget --debug http://www.bortzmeyer.org/1035.html ... Connecting to www.bortzmeyer.org|80.67.170.20|:80... connected. ... ---request begin--- GET /1035.html HTTP/1.0 User-Agent: Wget/1.10.2 Accept: */* Host: www.bortzmeyer.org Connection: Keep-Alive ---request end--- ... ---response begin--- HTTP/1.1 200 OK Date: Wed, 06 Jun 2007 13:23:48 GMT Server: Apache/1.3.26 Ben-SSL/1.48 (Unix) Debian GNU/Linux AuthMySQL/3.1 mod_throttle/3.1.2 mod_watch/3.17 Last-Modified: Wed, 30 May 2007 18:21:58 GMT ETag: "2e6e69-19a6-465dc0c6" Accept-Ranges: bytes Content-Length: 6566 Connection: close Content-Type: text/html; charset=utf-8
Afficher les en-têtes du dialogue entre le client et le serveur peut aussi se faire, si on utilise le navigateur Firefox, avec son extension « HTTP headers ».
Pour un exemple concret des options qui peuvent être passées au
serveur via les en-têtes, prenons
If-Modified-Since (section 14.25) qui permet au
client d'annoncer au serveur « J'ai déjà une version de cette
ressource, obtenue à telle date, ne me l'envoie que si tu as une
version plus récente ». Par exemple, sur le site des étiquettes de langue, on
a le registre dans divers formats. Ces formats sont produits
localement, après avoir transféré le registre original. Celui-ci étant
un gros fichier, on l'analyse pour trouver sa date et on utilise
l'option --time-cond de curl pour générer un
en-tête If-Modified-Since. Voici le script :
#!/bin/sh
MYURL=http://www.langtag.net/
LTR_URL=https://www.iana.org/assignments/language-subtag-registry
LTR_LOCAL=language-subtag-registry
if [ -e ${LTR_LOCAL} ]; then
ltr_date=`head -n 1 ${LTR_LOCAL} | cut -d" " -f2`
current_date=`date +"%Y%m%d" --date="${ltr_date} +1 day"`
else
# Trick to force a downloading
current_date="19700101"
fi
curl --verbose --output ${LTR_LOCAL}.TMP \
--compressed \
--referer ${MYURL} \
--proxy "" \
--time-cond "${current_date}" \
${LTR_URL}
...
Cela donne ceci, si le fichier n'existe pas (on a pris une date arbitraire dans le passé) :
... > If-Modified-Since: Thu, 01 Jan 1970 00:00:00 GMT > < HTTP/1.1 200 OK < Last-Modified: Fri, 04 May 2007 18:36:16 GMT < Content-Length: 80572
Si par contre le fichier existe et on a la version du 5 mars 2007, curl affiche :
... > If-Modified-Since: Sat, 05 May 2007 00:00:00 GMT > < HTTP/1.1 304 Not Modified ...
et le fichier n'est pas transféré.
Naturellement, si on veut développer un client HTTP, au delà de ce que permet curl (qui permet déjà beaucoup de choses), on dispose de nombreuses bibliothèques toutes faites comme httplib pour Python, libcurl (avec le programme du même nom) ou neon pour C, etc. HTTP est suffisamment simple pour qu'on puisse écrire rapidement un client, même sans ces bibliothèques comme le montre cet exemple en Python.
À noter que notre RFC utilise, pour décrire le protocole, une variante de l'ABNF standard, décrite en section 2.1, ce qui a suscité un certain nombre de problèmes.
Ce RFC 2616 a été remplacé en juin 2014 par une série de huit RFC, commençant par le RFC 7230. Le protocole HTTP 1.1 reste le même.
L'article seul
RFC 2606: Reserved Top Level DNS Names
Date de publication du RFC : Juin 1999
Auteur(s) du RFC : D. Eastlake, A. Panitz
Première rédaction de cet article le 30 octobre 2005
Ce RFC est très court mais a suscité (et suscite toujours, via
d'actuelles tentatives de le modifier) beaucoup de débats. Il est en
effet situé à l'intersection des domaines de
l'IETF et de l'ICANN
puisqu'il normalise certains noms de TLD et
certains noms de domaines dans les TLD comme
.com.
On a souvent besoin de noms de domaine sans avoir envie de les
réserver : le cas le plus fréquent concerne la documentation. Si
j'écris un texte expliquant comment configurer le logiciel, mettons,
NSD, j'ai besoin de
mettre des noms de domaines et il est préférable d'utiliser des noms
qui ne sont pas déjà en service. En effet, un certain nombre de lecteurs
utiliseront littéralement le nom qui apparait dans la documentation,
au lieu de comprendre que ce n'est qu'un exemple. On voit ainsi
souvent des francophones utiliser, bien à tort, le domaine
toto.fr alors qu'il est bel et bien alloué et que
son titulaire n'est peut-être pas ravi de cet usage !
Un autre usage courant concerne les tests de logiciel : si on veut créer un domaine "bidon" sur ses serveurs, il est préférable de ne pas masquer ainsi un domaine réel.
Ce RFC réserve donc quatre TLD,
.example pour la documentation,
.test pour les tests, ainsi que
.invalid et
.localhost. Malgré une demande fréquente, il
n'existe pas dans ce RFC de TLD pour un usage local
(.local était souvent proposé mais n'a acquis un statut officiel qu'avec les RFC 6761 et RFC 6762, bien plus tard). L'IETF est plutôt hostile à tout
ce qui est "local", notamment en raison des problèmes que cela pose
lorsque deux organisations fusionnent ou bien se connectent (c'est
pour la même raison que les adresses IPv6
site-local ont été remplacées, dans le RFC 4193). La méthode recommandée est donc plutôt
d'utiliser un sous-domaine pour les données privées par exemple
local.example.net.
Le RFC réserve également trois domaines de second niveau,
example.com, example.net et
example.org. Tous ces domaines ont été bloqués
par l'IANA et, pour les domaines de second
niveau, un serveur Web a été installé, qui renvoie à ce RFC.
L'article seul
RFC 2578: Structure of Management Information Version 2 (SMIv2)
Date de publication du RFC : Avril 1999
Auteur(s) du RFC : Keith McCloghrie (Cisco Systems, Inc.), David Perkins (SNMPinfo), Juergen Schoenwaelder (TU Braunschweig)
Chemin des normes
Première rédaction de cet article le 23 septembre 2010
Le SMI est le cadre général, dans ce cadre on écrit des descriptions des objets gérés, les MIB, on les interroge avec le protocole SNMP. L'essentiel de la gestion technique de l'Internet, en tout cas de la partie qui consiste à interroger les équipements réseau, se fait ainsi, d'où l'importance de ce RFC. Il documente la version 2 de la SMI (SMIv2), la version SMIv1 était décrite dans le RFC 1155, qui reste d'actualité pour certaines MIB (c'est le cas de la MIB-II, la MIB de base, normalisée dans le RFC 1213, même si elle a connu des évolutions comme celle du RFC 2863). (À noter que la première description de la SMIv2 était dans le RFC 1902, que notre RFC 2578 remplace.) La structure du RFC 2578 est très différente de celle du RFC 1155 et, à mon avis, moins concrète. Cela rend très difficile de voir les changements importants entre SMIv1 et SMIv2, d'autant plus que le RFC 2578 ne comporte pas de chapitre sur les changements.
Notre RFC décrit donc le SMI, le cadre de
base de la description d'informations qu'on gère, typiquement avec
SNMP. Il y a longtemps que la ligne officielle
de l'IAB est que tout protocole Internet soit
gérable, et ait donc une MIB, écrite selon les
règles du SMI (section 1). Les sections 1 et 3 rappellent des principes du SMI comme le choix de l'utilisation d'un
sous-ensemble de ASN.1 pour décrire les classes
d'objets gérés. De même, le SMI se veut extensible, car tout ne peut pas
être prévu à l'avance. Les MIB permettent de définir trois sortes de
choses, les modules (ainsi le RFC 5813 spécifie le module
forcesMib pour le protocole
ForCES,Forwarding and Control Element Separation, RFC 3746), les objets (le même RFC 5813
crée un objet
forcesLatestProtocolVersionSupported, dont la
valeur est un entier indiquant la version du protocole) et les
notifications (comme, toujours dans ForCES,
forcesAssociationEntryUp qui indique qu'une
association entre deux éléments du protocole devient opérationnelle).
Toutes les définitions de ce RFC, en ASN.1, sont rassemblées dans la section 2.
Qu'est-ce qu'une MIB
et qu'est-ce qu'on met dedans ? La MIB, écrite en
ASN.1, rassemble des objets qui ont tous un
nom, plus exactement un OBJECT
IDENTIFIER (OID, section 3.5). Ce nom est une suite de chiffres, alloués
hiérarchiquement (ce qui garantit l'unicité, cf. section 4). Certains de ces chiffres
ont aussi parfois une étiquette en lettres. Ainsi, le nœud 1 est
étiquetté iso et géré par
l'ISO. Tous les objets Internet sont sous le
sous-arbre 1.3.6.1 (3 étant alloué par l'ISO à d'autres organisations et
6 étant le DoD qui financait le projet, 1
revenant à l'IAB). En
ASN.1, cela se dit :
internet OBJECT IDENTIFIER ::= { iso(1) org(3) dod(6) 1 }
et les objets officiels sont sous le sous-arbre 1.3.6.1.2. Pour prendre
un exemple d'objet, ifOperStatus, l'état effectif
d'une interface réseau (par exemple une carte
Ethernet) est { ifEntry 8
}, c'est-à-dire 1.3.6.1.2.1.2.2.1.8
puisque ifEntry était
1.3.6.1.2.1.2.2.1 (il faut se rappeler qu'une MIB
est arborescente). Chaque interface réseau recevra ensuite un
OBJECT IDENTIFIER à elle,
1.3.6.1.2.1.2.2.1.8.1,
1.3.6.1.2.1.2.2.1.8.1, etc. Voici un exemple vu
avec snmpwalk (-O n lui dit
d'afficher les OID, pas les étiquettes), sur une machine qui a quatre
interfaces réseaux dont deux fonctionnent :
% snmpwalk -v 1 -O n -c tressecret 192.0.2.68 1.3.6.1.2.1.2.2.1.8 .1.3.6.1.2.1.2.2.1.8.1 = INTEGER: up(1) .1.3.6.1.2.1.2.2.1.8.2 = INTEGER: up(1) .1.3.6.1.2.1.2.2.1.8.3 = INTEGER: down(2) .1.3.6.1.2.1.2.2.1.8.4 = INTEGER: down(2)
Sans -O n, on aurait eu :
% snmpwalk -v 1 -c tressecret 192.0.2.68 1.3.6.1.2.1.2.2.1.8 IF-MIB::ifOperStatus.1 = INTEGER: up(1) IF-MIB::ifOperStatus.2 = INTEGER: up(1) IF-MIB::ifOperStatus.3 = INTEGER: down(2) IF-MIB::ifOperStatus.4 = INTEGER: down(2)
Si 1.3.6.1.2 désigne les objets « officiels »,
1.3.6.1.3 (section 4 du RFC) est pour les
expérimentations et 1.3.6.1.4 pour les objets
privés et 1.3.6.1.4.1 pour les objets spécifiques à une entreprise. Par
exemple, si Netaktiv a
obtenu
le numéro 9319, ses objets seront sous 1.3.6.1.4.1.9319.
L'objet a aussi une syntaxe (section 7), par exemple
INTEGER, OCTET STRING (voir
la section 7.1.2 pour une discussion subtile sur sa taille maximale),
BITS (un tableau de bits),
OBJECT IDENTIFIER ou NULL. C'est un
sous-ensemble d'ASN.1 qui est utilisé pour bâtir des définitions à
partir de ces types primitifs, en les organisant en séquences ou en
tables (section
7.1.12). Par exemple, l'état d'une
interface réseau, ifOperStatus, déjà cité, est
défini par le RFC 1213 comme
INTEGER. Voici la définition complète :
ifOperStatus OBJECT-TYPE
SYNTAX INTEGER {
up(1), -- ready to pass packets
down(2),
testing(3) -- in some test mode
}
ACCESS read-only
STATUS mandatory
DESCRIPTION
"The current operational state of the interface.
The testing(3) state indicates that no operational
packets can be passed."
::= { ifEntry 8 }
Notre RFC définit aussi des types à partir de ces types primitifs, types qui pourront être utilisés par toutes les MIB. C'est le cas de :
IpAddress(section 7.1.5, et limitée à IPv4, le typeIpv6Addressest apparu dans le RFC 2465), uneOCTET STRINGde quatre octets (IPv6 n'était pas encore inventé),CounterN(section 7.1.6 et 7.1.10), un entier positif sur 32 (Counter32) ou 64 (Counter64) bits, croissant de manière monotone modulo sa valeur maximale.Gauge(section 3.2.3.4) qui, contrairement àCounter, peut monter et descendre.
Un exemple d'utilisation de BITS (section
7.1.4) figure dans le RFC 5601 (FCS : somme de contrôle):
pwFcsRetentionStatus OBJECT-TYPE
SYNTAX BITS {
remoteIndicationUnknown (0),
remoteRequestFcsRetention (1),
fcsRetentionEnabled (2),
fcsRetentionDisabled (3),
localFcsRetentionCfgErr (4),
fcsRetentionFcsSizeMismatch (5)
}
MAX-ACCESS read-only
La section 5 du RFC est consacrée spécifiquement aux modules et notamment à leurs métadonnées (organisme à contacter, numéro de version, etc). La section 6 se penche sur les définitions d'objets. L'exemple du RFC est imaginaire mais voici un exemple réel tiré du RFC 5813 (CE = Control Engine, la partie du routeur qui fait tourner les protocoles de routage) :
forcesLatestProtocolVersionSupported OBJECT-TYPE
SYNTAX ForcesProtocolVersion
MAX-ACCESS read-only
STATUS current
DESCRIPTION
"The ForCES protocol version supported by the CE.
The current protocol version is 1.
Note that the CE must also allow interaction
with FEs supporting earlier versions."
::= { forcesMibObjects 1 }
forcesAssociations OBJECT IDENTIFIER ::= { forcesMibObjects 2 }
Un objet a enfin un encodage sur le câble (à peine mentionné dans le RFC) car ASN.1 ne spécifie pas comment les objets doivent être sérialisés en bits. Le SMI utilise BER.
Les MIB sont souvent utilisées comme base pour créer de nouvelles MIB, par exemple parce que le protocole a évolué et qu'on met à jour la MIB. La section 10 donne d'utiles conseils dans ce cas, notamment l'importance de ne pas retirer d'éléments de la MIB car les clients SNMP peuvent être restés à l'ancienne MIB. Les nouveaux éléments ne les gènent pas (ils ne les interrogeront pas) mais un élément supprimé va les prendre en défaut. Dans tous les cas, les OID ne doivent jamais être réaffectés. Si la définition d'un objet change de manière incompatible, c'est un nouvel objet et il doit recevoir un nouvel OID. La section 10.2 liste les changements compatibles : ajouter une nouvelle valeur à une énumération, par exemple (mais pas en retirer).
Une implémentation complète du SMI figure en http://www.ibr.cs.tu-bs.de/projects/libsmi/ (sur une
Debian, c'est dans le paquetage
libsmi2-dev). Sur beaucoup de
systèmes d'exploitation, les MIB elles-mêmes sont distribuées et, par
exemple, sur Debian ou une Gentoo, elles se trouvent dans /usr/share/snmp/mibs.
L'article seul
RFC 2553: Basic Socket Interface Extensions for IPv6
Date de publication du RFC : Mars 1999
Auteur(s) du RFC : Robert E. Gilligan (FreeGate Corporation), Susan Thomson (Bell Communications Research), Jim Bound (Compaq Computer Corporation), W. Richard Stevens
Pour information
Première rédaction de cet article le 19 février 2008
A priori, l'IETF ne normalise pas d'API (et c'est pour cela que ce RFC n'a que le statut de « pour information »), se limitant aux « bits qu'on voit passer sur le câble ». Mais le monde de la normalisation n'est pas toujours si simple et, à l'époque, il était important de publier rapidement une documentation sur la nouvelle API nécessaire aux applications pour faire de l'IPv6.
Les API Unix et réseaux sont typiquement gérées par l'IEEE, via sa norme POSIX. Mais POSIX n'est pas librement téléchargeable sur le réseau, ce qui limite son utilité. Pour cette raison et pour d'autres, l'IETF a donc publié ce RFC, dont on notera qu'un des auteurs est W. Richard Stevens, auteur de Unix network programming, le livre de référence sur le sujet. Il succède à un premier RFC sur la question, le RFC 2133 et a lui-même été remplacé par le RFC 3493.
Depuis leur apparition, les prises (socket dans la langue de Stevens) sont le principal mécanisme d'accès au réseau pour les programmes. Les programmes qui les utilisent sont relativement portables, bien au delà du système BSD où elles sont nées. Traditionnellement multi-protocoles, les prises ne permettaient néanmoins pas d'accéder à IPv6. C'est désormais le cas et l'interface décrite dans ce RFC est désormais largement présente (MacOS X a été le dernier système d'exploitation à la proposer).
Elle ne concerne que le langage C. Les autres langages disposent souvent de mécanismes de plus haut niveau que les prises comme les Streams de Java.
Idéalement, la plupart des applications ne devrait pas avoir besoin de savoir si elles utilisent IPv4 ou IPv6. Concentrée dans la couche Réseau, le protocole utilisé ne devrait pas concerner l'application. Mais C est un langage de bas niveau, et expose donc le protocole de couche 3 utilisé (même si la section 2 du RFC explique que l'API cherche à être la plus générale possible).
La section 2.1 résume les principaux changements qui ont été faits
pour permettre l'utilisation d'IPv6. Ils incluent une nouvelle
constante (section 3.1) pour indiquer les adresses IPv6
(AF_INET6, puisque AF_INET, comme
son nom ne l'indique pas clairement, étant spécifique à IPv4) et une
pour le protocole IPv6 (PF_INET6). Notons que le
RFC documente aussi PF_UNSPEC, qui permet à
l'application de dire qu'elle se moque du protocole utilisé (ce qui
devrait être le cas le plus courant). Il y a bien sûr une nouvelle
structure de données (section 3.3) pour placer les adresses IPv6,
quatre fois plus grandes. Les sockaddr sont
désormais des représentations de la prise, indépendantes de la famille
d'adresses, les sockaddr_in6 étant spécifiques à
IPv6. Elles contiennent :
struct sockaddr_in6 {
sa_family_t sin6_family; /* AF_INET6 */
in_port_t sin6_port; /* transport layer port # */
uint32_t sin6_flowinfo; /* IPv6 traffic class & flow info */
struct in6_addr sin6_addr; /* IPv6 address */
uint32_t sin6_scope_id; /* set of interfaces for a scope */
};
Les appels système sur les prises, décrits dans la section 3.5, eux, ont peu changés, socket, connect, bind, continuent comme avant.
Les sections 3.6. et 3.7 concernent l'interopérabilité avec
IPv4. Le monde des applications a une forte inertie. Les développeurs,
déjà très occupés, ne portent pas leurs applications vers la nouvelle
interface instantanément. Ces deux sections expliquent donc comment
assurer le recouvrement des deux protocoles. On notera qu'avec cette
interface, pour faire un serveur qui écoute en
IPv4 et IPv6, il faut créer une prise IPv6, les
clients IPv4 recevront alors des adresses
IPv4-mapped comme
::FFFF:192.0.2.24. Ce n'est pas très
intuitif... (Heureusement, c'est plus simple pour un client.)
La section 6 du RFC parle des fonctions de bibliothèque pour
effectuer les traductions de noms en adresses et
réciproquement. L'ancienne gethostbyname, très spécifique
à IPv4 et souffrant d'autres limitations, ne devrait plus être
utilisée depuis des années (le nombre de programmes qui l'utilisent
encore ou de tutoriels qui l'expliquent donne une idée de l'extrême
inertie d'un secteur qui se prétend novateur et réactif). Les
« nouvelles » fonctions getaddrinfo et
getnameinfo (section 6.4) la remplacent. Le RFC propose
également en sections 6.1 et 6.2 getipnodebyname et
getipnodebyaddr, qui seront supprimées dans le
RFC suivant, le RFC 3493. Un programme
typique désormais fait :
char *server = "www.example.org";
char *port_name = "42";
int mysocket;
/* addrinfo est défini dans netdb.h et inclus une "struct sockaddr"
(une prise, incluant l'adresse IP) dans son champ ai_addr. Sa
description figure dans la section 6.4 du RFC. */
struct addrinfo hints, *result;
hints.ai_family = PF_UNSPEC;
hints.ai_socktype = SOCK_STREAM;
error = getaddrinfo(server, port_name, &hints, &result);
if (error) {
err_quit("getaddrinfo error for host: %s %s",
server, gai_strerror(error));
}
/* La première adresse IP sera dans result->ai_addr, pour les
suivantes, il faudra suivre result->ai_next */
mysocket = socket(...);
error = connect(mysocket, result->ai_addr, result->ai_addrlen);
...
Un des rares cas où un client réseau a besoin de manipuler des adresses IP (pas seulement de les stocker et de les passer d'une fonction à une autre) est lors de l'affichage, par exemple en mode bavard. Pour éviter que le programme ne doive connaitre les détails de syntaxe des adresses (celle d'IPv4 n'a jamais été normalisée, celle d'IPv6 est décrite dans le RFC 4291), notre RFC décrit en section 6.6 des fonctions de conversion de et vers un format texte, inet_ntop et inet_pton.
L'inertie des programmeurs étant très forte, et celle des enseignants également, on peut parier, bien que ce RFC soit vieux de neuf ans, que beaucoup de cours de programmation réseaux sont encore donnés avec la vieille interface, qui ne marche qu'en IPv4...
L'article seul
RFC 2544: Benchmarking Methodology for Network Interconnect Devices
Date de publication du RFC : Mars 1999
Auteur(s) du RFC : Scott Bradner (Harvard University), Jim McQuaid (NetScout Systems)
Pour information
Première rédaction de cet article le 11 avril 2007
Dans la longue liste des RFC consacrés aux mesures de performance réseau, un RFC de méthodologie pour les mesures des engins qui connectent les réseaux entre eux : routeurs, commutateurs et ponts.
Ce RFC s'appuie sur le vocabulaire du RFC 1242 et décrit une méthodologie pour mesurer les performances d'un équipement d'interconnexion. Les tests organisés dans un but commercial (« Notre équipement est le plus rapide du marché ») sont souvent en effet irréalistes. Notre RFC contient donc beaucoup de détails concrets. Ainsi, la section 11 contient de nombreux exemples des choses qu'il faut penser à ajouter au test pour le rapprocher des conditions réelles : une pincée de paquets de diffusion pour ralentir les commutateurs, quelques messages des protocoles de routage pour que le routeur aie autre chose à faire, des requêtes SNMP, filtres, etc. La section 12, elle, conseille d'utiliser de nombreuses adresses, aléatoirement réparties (le RFC 4814 détaille davantage le pourquoi de cette recommendation).
De même, la section 21 explique l'intérêt qu'il y a à utiliser du trafic irrégulier, avec des pointes de trafic, un trafic trop constant ne rendant pas forcément compte de toutes les capacités de l'engin.
Enfin, l'appendice C du RFC couvre le format recommandé pour les paquets de test. Il suggère l'utilisation du protocole UDP echo (celui qu'utilise, par défaut, echoping).
Les tests décrits par ce RFC sont prévus pour un environnement de laboratoire, où on se moque des répercussions de ces tests. Le RFC 6815 a été ajouté par la suite pour rappeler qu'il ne faut pas effectuer les tests de notre RFC sur un vrai réseau, réseau qu'ils pourraient perturber sérieusement.
L'article seul
RFC 2516: A Method for Transmitting PPP Over Ethernet (PPPoE)
Date de publication du RFC : Février 1999
Auteur(s) du RFC : Louis Mamakos (UUNET Technologies), Kurt Lidl (UUNET Technologies), Jeff Evarts (UUNET Technologies), David Carrel (RedBack Networks), Dan Simone (RedBack Networks), Ross Wheeler (RouterWare)
Pour information
Première rédaction de cet article le 14 décembre 2007
Le protocole PPP sert à bien d'autres choses qu'aux liaisons modem. Par exemple, il est un des plus utilisés pour les connexions ADSL, dans sa variante PPPoE, que décrit notre RFC.
Comme la plupart des technologies d'accès aujourd'hui, une connexion ADSL typique fournit un accès en Ethernet et PPP (RFC 1661) n'avait été conçu que pour le point-à-point où il n'y a que deux machines sur le réseau. L'essentiel de notre RFC est donc consacré au protocole de découverte (section 5) par lequel une machine PPPoE va pouvoir trouver son concentrateur d'accès, en demandant à la cantonade.
La section 3 décrit le principe du protocole. Le client PPPoE (PPP
est pair-à-pair, pas client-serveur mais le
protocole de découverte, lui, est client-serveur) émet
un paquet PADI de recherche du concentrateur, celui-ci répond avec un
paquet PADO (qui contient des étiquettes,
décrites dans l'annexe A, pour donner des informations supplémentaires) et lui indique un numéro de session
(0x2041 dans les exemples ci-dessous) qui permet
de séparer les différentes sessions PPP qui coexistent sur le même
Ethernet.
Ensuite, c'est LCP qui prend le relais et on fait du PPP classique (la section 7 donne quelques détails, notamment sur les problèmes de MTU mais attention, le RFC 4638 l'a mise à jour).
Voici, sur une machine Debian, un extrait du
fichier de configuration /etc/ppp/peers/nerim
pour se connecter au FAI
Nerim. Le « modem » ADSL est configuré en
simple pont pour que la machine Debian puisse
joindre le concentrateur
d'accès en Ethernet :
# Nerim via LDcom degroupe pty "pppoe -I eth1 -T 80 -m 1412" linkname nerim # wait for PADO (3s) connect-delay 3000 # Le reste n'est pas spécifique à PPPoE...
Pour créer le pseudo-terminal (pty) où PPP
va se connecter, on lance le démon pppoe.
Voici la découverte du concentrateur d'accès avec la commande Unix
pppoe :
# pppoe -A -I eth1
Access-Concentrator: SE800-CBV3-1
Service-Name: ldcom
AC-Ethernet-Address: 00:30:88:10:3c:b9
et voici son résultat, vu avec tcpdump (sections 5.1 et 5.2 du RFC) :
% tcpdump -n -e -I eth1 22:25:39.424864 00:0c:76:1f:12:7b > ff:ff:ff:ff:ff:ff, ethertype PPPoE D (0x8863), length 24: PPPoE PADI 22:25:39.469939 00:30:88:10:3c:b9 > 00:0c:76:1f:12:7b, ethertype PPPoE D (0x8863), length 60: PPPoE PADO [AC-Name "SE800-CBV3-1"] [Service-Name "ldcom"] [EOL]
Si, au lieu de regarder avec tcpdump l'interface Ethernet (ici
eth1), on regarde l'interface PPP (ici
ppp0), on voit passer des paquets IP
classiques. Pour voir l'encapsulation PPP, il faut regarder
l'interface Ethernet et le trafic ressemble à :
% tcpdump -n -e -I eth1 22:28:16.129173 00:0c:76:1f:12:7b > 00:30:88:10:3c:b9, ethertype PPPoE S (0x8864), length 62: PPPoE [ses 0x2041] PPP-IP (0x0021), length 42: IP 213.41.181.9.35156 > 204.13.160.129.80: F 212:212(0) ack 875 win 6984 22:28:16.323916 00:30:88:10:3c:b9 > 00:0c:76:1f:12:7b, ethertype PPPoE S (0x8864), length 62: PPPoE [ses 0x2041] PPP-IP (0x0021), length 42: IP 204.13.160.129.80 > 213.41.181.9.35156: . ack 213 win 8189
Notez que le type Ethernet a changé, passant de
0x8863 pour la découverte à
0x8864 pour la session (section 4 du RFC).
L'article seul
RFC 2474: Definition of the Differentiated Services Field (DS Field) in the IPv4 and IPv6 Headers
Date de publication du RFC : Décembre 1998
Auteur(s) du RFC : Kathleen Nichols (Cisco), Steven Blake (Torrent Networking Technologies), Fred Baker (Cisco), David L. Black (EMC Corporation)
Chemin des normes
Première rédaction de cet article le 13 février 2008
Dernière mise à jour le 18 février 2008
La question du traitement differencié des paquets IP occupe beaucoup de monde depuis les débuts de l'Internet. En gros, il s'agit de savoir si les routeurs et autres équipements intermédiaires vont traiter tous les paquets IP de la même manière, où bien si certains auront la priorité, ou en tout cas un traitement particulier selon certains critères. Si la question a un aspect politique, lié à la revendication de neutralité du réseau, pour savoir qui va décider quels paquets seront sacrifiés, notre RFC ne couvre que l'aspect technique : il change complètement un des champs du paquet IP, pour tenir compte de l'échec qu'avait été ce champ Type Of Service.
Avant de mettre en œuvre des traitements differenciés, encore
faut-il savoir à quels paquets les appliquer. Dans le
RFC original sur IPv4,
le RFC 791, un champ du paquet,
TOS, Type Of Service était
réservé au marquage du paquet. Il permettait d'indiquer la priorité
souhaitée et les critères les plus importants pour ce paquet (débit,
coût, latence, etc). La norme Posix prévoit
des moyens pour les applications de définir ces champs (un programme
comme echoping les
met en œuvre avec ses options -p et
-P). Voici un exemple en C de définition
du champ TOS avec setsockopt :
result = setsockopt(mysocket, IPPROTO_IP,
IP_TOS, IPTOS_THROUGHPUT, sizeof(int));
/* IPTOS_THROUGHPUT vaut 0x08 et était censé maximiser le débit. Cf. RFC 791,
section 3.1 */
Pour voir les capacités des différents systèmes d'exploitation à fixer ces valeurs, on peut regarder mon article sur la fixation d'options IP depuis un programme.
Ce mécanisme n'a eu aucun succès, peu d'applications fixent ce champ et peu de routeurs le traitaient comme spécifié. Il y a plusieurs raisons à cet échec, et toutes ne sont pas techniques, loin de là. Par exemple, comment empêcher une application de toujours demander la plus forte priorité ? (La question est discutée dans le section 7.1 de notre RFC.)
Parmi les raisons techniques, il y avait le fait que le mécanisme du RFC 791 était trop rigide. Par exemple, les critères exprimables étaient en nombre limité et trop vagues. Une nouvelle architecture pour la qualité de service, Differentiated Services, connue sous l'abréviation de Diffserv a été définie dans le RFC 2475. Ses conséquences pratiques sur le format des paquets font l'objet de notre RFC 2474, qui met donc à jour le RFC 791 et qui s'applique également à son équivalent IPv6, le RFC 2460, pour la définition du champ Traffic class (équivalent IPv6 du champ TOS).
Le champ TOS de IPv4 change donc de nom. Il devient DS
(Differentiated Services) et la
sémantique n'est plus fixée par le RFC. Un TOS de
0x08 voulait toujours dire « Je cherche à
maximiser le débit » alors qu'un DS de 0x08
aura une signification donnée par les routeurs du domaine
administratif où le paquet passe. Aux frontières de ces domaines, par
exemple pour passer d'un opérateur à un autre, il faudra changer le
champ (section 2 du RFC) ou bien utiliser des valeurs attribuées par un accord entre
opérateurs (Diffserv définit un mécanisme, pas une politique). La
section 1 de notre RFC prévient que, si le
forwarding de chaque paquet est un problème bien
connu, l'attribution et la gestion de politiques de qualité de service
est un problème bien plus ouvert. Neuf ans après la sortie du RFC, il
ne semble pas en voie de résolution. La même section 1 rappelle que
des politiques simples et appliquées statiquement sont peut être la
meilleure solution.
La section 3 décrit le nouveau champ DS. Voici l'ancien champ ToS, sur huit bits, du RFC 791 :
0 1 2 3 4 5 6 7
+-----+-----+-----+-----+-----+-----+-----+-----+
| | | | | | |
| PRECEDENCE | D | T | R | 0 | 0 |
| | | | | | |
+-----+-----+-----+-----+-----+-----+-----+-----+
Et voici le nouveau champ DS (Differentiated Services) :
0 1 2 3 4 5 6 7
+---+---+---+---+---+---+---+---+
| DSCP | CU |
+---+---+---+---+---+---+---+---+
DSCP: differentiated services codepoint
CU: currently unused
(La partie réservée a été remplie ultérieurement par l'ECN du RFC 3168.) Le champ DSCP contient un index dans une table des PHB (per-host behavior) qui sont les traitements que le routeur applique. Des exemples de PHB sont « fait passer ce paquet devant tout le monde dans la queue » ou bien « n'hésite pas à jeter ce paquet si le réseau est congestionné ». Le PHB par défaut (section 4.1) étant le traditionnel « faire de son mieux » des routeurs IP. Certains RFC définissent des PHB comme le RFC 2597 sur le Assured Forwarding.
On voit sur les schémas que, contrairement à l'ancien TOS, le DSCP n'a pas de structure interne. 64 valeurs différentes sont possibles, et les sections 4 et 5 discutent de leur allocation, la section 6 couvrant d'éventuelles standardisations de certaines valeurs.
Si on regarde ce qui passe sur le réseau avec tshark (option -V), on verra :
Internet Protocol, Src Addr: 172.19.1.1 (172.19.1.1), Dst Addr: 172.19.1.2 (172.19.1.2)
...
Differentiated Services Field: 0x08 (DSCP 0x02: Unknown DSCP; ECN: 0x00)
0000 10.. = Differentiated Services Codepoint: Unknown (0x02)
.... ..0. = ECN-Capable Transport (ECT): 0
.... ...0 = ECN-CE: 0
On voit que le 0x08 mis dans le champ équivaut à
un DSCP de 0x02, qui ne correspond pas à une
valeur connue de manière standard (d'où le Unknown DSCP).
L'informatique est un monde très conservateur et, neuf ans après la sortie de ce RFC, on continue couramment à utiliser des mots comme TOS, normalement abandonnés (cf. par exemple la bogue echoping #1892544). La norme Posix continue à définir uniquement des constantes pour l'ancien comportement (comme IP_TOS ou IPTOS_THROUGHPUT, utilisés plus haut). Il n'est pas facile de changer une API si utilisée !
Sur Linux, on peut aussi changer la valeur
du champ DSCP avec Netfilter et sa commande
iptables. Cela se fait en modifiant la table
mangle (qui permet de modifier un paquet, pas
seulement de l'accepter ou de le refuser), avec la pseudo-chaîne de
destination DSCP. Par exemple :
# iptables -t mangle -A OUTPUT -p tcp --dport 22 -j DSCP --set-dscp 0x02
va changer le DSCP de tous les paquets à destination du port 22. Pour les raisons expliquées plus haut, tcpdump va afficher ce DSCP de 0x2 en 0x8 :
17:50:35.477598 IP (tos 0x8, ttl 64, id 1040, offset 0, flags [DF], proto TCP (6), length 60)
192.168.2.1.36067 > 10.22.58.30.22: Flags [S], cksum 0xe4b2 (correct), seq 3255303173, win 5840, options [mss 1460,sackOK,TS val 8714261 ecr 0,nop,wscale 6], length 0
Pour mettre en œuvre le traitement différencié sur un routeur Cisco, on peut consulter Implementing Quality of Service Policies with DSCP.
Aujourd'hui, DSCP ne semble pas avoir eu beaucoup plus de succès que son prédécesseur. Il est difficile de mesurer le taux de déploiement car tous sont internes à une organisation. Certains RFC comme le RFC 4504 (section 2.12) ont rendu obligatoire l'utilisation de DSCP mais ils n'ont pas forcément été respectés. Si une entreprise qui déploie de la VoIP utilise DSCP en interne pour permettre aux coups de téléphone de passer même lorsqu'un gros transfert de fichiers est en cours, tout en simplifiant la configuration de ses routeurs, cela ne se voit pas à l'extérieur.
L'article seul
RFC 2460: Internet Protocol, Version 6 (IPv6) Specification
Date de publication du RFC : Décembre 1998
Auteur(s) du RFC : Stephen E. Deering (Cisco Systems, Inc.), Robert M. Hinden (Nokia)
Chemin des normes
Première rédaction de cet article le 1 juillet 2008
Si IPv4 est normalisé dans un seul document, le RFC 791, le candidat à sa succession IPv6 est décrit de manière plus modulaire, dans plusieurs RFC dont notre RFC 2460, essentiellement consacré au format des paquets. Il a depuis été remplacé par le RFC 8200.
Remplaçant le premier RFC sur le format des paquets IPv6, le RFC 1883, notre RFC 2460 est resté stable pendant dix-huit ans, alors que la plupart des RFC sur IPv6 ont connu des révisions ; les autres RFC importants pour IPv6 sont le RFC 4291 sur l'adressage - certainement le moins stable -, le RFC 4861 sur le protocole de découverte des voisins, le RFC 4862 sur l'autoconfiguration des adresses et le RFC 4443 sur ICMP.
À l'heure actuelle, le déploiement de ce RFC est très limité : peu de paquets IPv6 circulent sur Internet et il est loin d'avoir succédé à IPv4. Le fait d'avoir un numéro de version plus élevé ne suffit pas ! Notre RFC 2460 présente sans hésiter IPv6 comme le successeur d'IPv4, ce qui reste pour l'instant un vœu pieux.
IPv6 reprend largement le modèle qui a fait le succès d'IPv4 : un protocole de datagrammes, un routage jusqu'au prochain saut (peu ou pas de routage de bout en bout), des datagrammes acheminés « au mieux possible », un en-tête de paquet simple et où les champs sont de taille fixe. La section 1 du RFC résume les différences entre les formats de paquets IPv4 et IPv6.
La plus spectaculaire des différences est bien sûr l'augmentation de la taille des adresses. Toujours fixe (contrairement à des concurrents où les adresses étaient de tailles variables), cette taille passe de 32 à 128 bits. Le maximum théorique d'adresses (en supposant une allocation parfaite) passe donc de quatre milliards (ce qui ne permet même pas d'allouer une adresse à chaque personne sur Terre) à plus de 10^40, un nombre qui défie l'imagination.
Compte-tenu de l'épuisement rapide des adresses IPv4, cette augmentation est à elle seule une bonne raison de migrer vers IPv6. Elle reflète les changements de paradigme successifs en informatique, de « un ordinateur par entreprise » au début des années 70, lorsque IPv4 a été conçu, à « un ordinateur par département » au cours des années 80 puis à « un ordinateur par personne » avec l'explosion de la micro-informatique et à « plusieurs ordinateurs par personne » de nos jours lorsque le cadre dynamique et branché se promène avec davantage d'appareils électroniques sur lui que n'en portait James Bond dans ses premiers films. Les quatre milliards d'adresses d'IPv4 sont donc aujourd'hui bien insuffisantes.
Mais ce changement de format des adresses est également la faiblesse d'IPv6 : il ne permet en effet pas à des machines v4 et v6 de communiquer directement et les premiers adopteurs du nouveau protocole ne peuvent donc pas parler aux anciens, ce qui a puissamment freiné le déploiement d'IPv6.
Les autres changements apportés par IPv6 sont moins connus mais semblaient à l'époque justifier le nouveau protocole :
- Le format de l'en-tête est simplifié, facilitant la tâche des routeurs (en pratique, IPv4 garde son avantage, la complexité de son format étant compensée par l'expérience des développeurs et la quantité de main d'œuvre qui a travaillé à optimiser les routeurs IPv4).
- Les options sont à la fois plus libres, notamment en taille, et moins contraignantes à gérer pour les routeurs,
- Les services d'authentification et de confidentialité ont été inclus (cet argument est souvent cité en faveur d'IPv6 mais il est largement bidon, IPv4 ayant désormais les mêmes capacités, et elles n'ont pas souvent été intégrées dans les implémentations IPv6).
La section 3 détaille le format du nouvel en-tête de paquet.
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |Version| Traffic Class | Flow Label | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Payload Length | Next Header | Hop Limit | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | | + + | | + Source Address + | | + + | | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | | + + | | + Destination Address + | | + + | | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Contrairement aux paquets IPv4, il n'y a pas de champ « Options » de taille variable. Le champ « Version » contient évidemment le numéro 6 (il y a eu des protocoles ayant reçu le numéro 5 ou 7 mais ils n'ont jamais été déployés). Le champ DSCP, ex-TOS, d'IPv4 est remplacé par les champs Traffic class et Flow label qui semblent très peu utilisés en pratique (sections 6 et 7 du RFC, ainsi que l'annexe A ; le flow label a été ensuite mieux normalisé dans le RFC 6437).
Le champ Next header indique le type de l'en-tête suivant. La plupart du temps, c'est l'en-tête d'un protocole de transport comme TCP (numéro 6) ou DCCP (numéro 33), dont les numéros sont stockés dans un registre IANA. Mais cela peut être aussi un en-tête d'extension de la couche réseau par exemple 44 pour les fragments (ces numéros sont stockés dans le même registre IANA). Notez que, depuis, le RFC 6564 a modifié les règles pour les futurs en-têtes, imposant un format commun. (Pour analyser les paquets IPv6, voir mon article « Analyser les en-têtes IPv6 avec pcap ».)
Vu avec tshark, la version texte de
l'analyseur Wireshark, et son option
-V, voici un paquet IPv6 contenant lui-même du TCP :
Internet Protocol Version 6
0110 .... = Version: 6
[0110 .... = This field makes the filter "ip.version == 6" possible: 6]
.... 0000 0000 .... .... .... .... .... = Traffic class: 0x00000000
.... .... .... 0000 0000 0000 0000 0000 = Flowlabel: 0x00000000
Payload length: 40
Next header: TCP (0x06)
Hop limit: 64
Source: 2a01:e35:8bd9:8bb0:21e:8cff:fe76:29b6 (2a01:e35:8bd9:8bb0:21e:8cff:fe76:29b6)
Destination: 2a01:e35:8bd9:8bb0:21c:23ff:fe00:6b7f (2a01:e35:8bd9:8bb0:21c:23ff:fe00:6b7f)
La section 4 présente les en-têtes d'extension. Grande nouveauté d'IPv6, ils sont situés entre l'en-tête IP normal et l'en-tête de la couche transport. La plupart d'entre eux sont ignorés par les routeurs situés sur le trajet et traités seulement à l'arrivée (alors qu'un routeur IPv4 devait, en théorie, toujours examiner les options). Notre RFC normalise certaines de ces extensions, mais d'autres peuvent être ajoutées par des RFC ultérieurs comme par exemple le RFC 3775 qui normalise le Mobility Header (numéro 135, section 6.1 du RFC).
C'est ainsi que la section 4.3 décrit l'en-tête d'extension « Hop-by-hop », une de celles qui doivent être examinées par tous les routeurs sur le trajet. Elle contient des options (décrites en section 4.2), qui sont stockées sous forme de tuples TLV. Le type de chaque option indique, dans ses deux premiers bits, si l'option peut être ignorée ou non.
Le symétrique de cet en-tête est le « Destination », section 4.6, qui stocke, de la même façon, les options qui ne doivent être traitées que par le destinataire. (Pour mettre un tel en-tête dans vos paquets, voir mon article.)
La section 4.4 décrit l'en-tête « Routing » qui permet d'indiquer la route qu'on souhaite voir le paquet prendre, ou bien d'enregistrer la route effectivement suivie. Notons qu'un champ, le « Routing Type », indique le type de routage souhaité et que sa valeur 0 ne doit plus être utilisée : en raison de problèmes de sécurité serieux, le Type 0 Routing Header a été abandonné dans le RFC 5095.
La section 4.5 décrit l'en-tête « Fragment » qui permet de représenter des paquets IP qui, trop longs, ont été fragmentés par l'émetteur (contrairement à IPv4, les routeurs IPv6 n'ont pas le droit de fragmenter).
La section 5 décrit les questions liées à la taille des paquets. IPv6 impose une MTU minimale de 1280 octets et, en théorie, une machine qu n'enverrait que des paquets de cette taille (ou plus petits) n'aurait jamais de problème. Au delà, on doit utiliser la découverte de la MTU du chemin, spécifiée dans le RFC 1981 mais dont le moins qu'on puisse dire est qu'elle n'est pas très fiable (cf. RFC 4821).
Les différences avec le RFC 1883 sont décrites après la bibliographie. Elles sont en général de peu d'importance. Par exemple, la MTU minimale passe à 1280 octets (après des débats enfiévrés, à une époque où LocalTalk était une technologie assez courante, le RFC 1883 utilisait 576 octets). Outre changement, la possibilité d'envoyer des très grands paquets, les jumbograms, a disparu du RFC de base et figure désormais dans un RFC dédié, le RFC 2675. Le RFC 8200, qui a remplacé notre RFC, n'a pas apporté de changements cruciaux.
L'article seul
RFC 2440: OpenPGP Message Format
Date de publication du RFC : Novembre 1998
Auteur(s) du RFC : Jon Callas (Network Associates, Inc.), Lutz Donnerhacke (IKS GmbH), Hal Finney (Network Associates, Inc.), Rodney Thayer (EIS Corporation)
Chemin des normes
Première rédaction de cet article le 4 octobre 2007
Dernière mise à jour le 3 novembre 2007
Le logiciel PGP est synonyme de cryptographie pour beaucoup de gens. Un des plus anciens et des plus utilisés pour les fonctions de confidentialité mais aussi d'authentification, PGP est très célèbre mais on sait peu que ses messages sont normalisés, dans ce RFC.
PGP a vu son format de données normalisé pour la première fois en août 1996, dans le RFC 1991. Cette norme a été révisée par la suite et notre RFC n'est pas le dernier (le RFC 4880 est la version actuelle).
Cette normalisation permet à diverses mises en œuvre de PGP d'interopérer. La plus connue aujourd'hui est la seule libre, GNU Privacy Guard (qui n'existait pas encore au moment de la publication du RFC). Il ne faut donc plus confondre le logiciel PGP, écrit à l'origine par Phil Zimmermann, et qui est non-libre, avec le format PGP que décrit notre RFC et que des logiciels autres que PGP peuvent lire ét écrire.
Le principe du chiffrement avec PGP est simple. Une clé de session (le terme est impropre puisqu'il n'y a pas de session au sens de TLS mais c'est celui utilisé par le RFC) est créée pour chaque destinataire, elle sert à chiffrer le message et cette clé est chiffrée avec la clé publique du destinataire (section 2.1 du RFC).
Pour l'authentification, c'est aussi simple conceptuellement. Le message est résumé et le résumé est chiffré avec la clé privée de l'émetteur (section 2.2 du RFC).
Le format PGP permet également la compression (qui améliore la sécurité en supprimant les redondances) et l'encodage en Base64, baptisé ASCII armor, pour passer à travers des logiciels qui n'aiment pas le binaire (la section 6 détaille cet encodage).
La section 3 explique les éléments de base utilisés par le format PGP. L'un des plus importants est le concept d'entier de grande précision (MPI pour Multi-Precision Integers), qui permet de représenter des entiers de très grande taille, indispensables à la cryptographie, sous forme d'un doublet longueur + valeur.
Enfin les sections 4 et 5 expliquent le format lui-même. Un message PGP est constitué de paquets (rien à voir avec les paquets réseau). Chaque paquet a un type, une longueur et un contenu. Par exemple, un paquet de type 1 est une clé de session chiffrée, un paquet de type 2 une signature, un paquet de type 9 du contenu chiffré, etc.
La section 7 du RFC décrit un type de message un peu particulier, qui n'obéit pas à la syntaxe ci-dessus, les messages en clair mais signés. Ces messages ont l'avantage de pouvoir être lus sans avoir de logiciel PGP. Ils nécessitent donc des règles spéciales.
On notera que gpg permet d'afficher les
paquets présents dans un message PGP, ce qui est pratique pour
l'apprentissage ou le débogage. Voyons un exemple avec un fichier
test.txt de 35 octets,
signé mais non chiffré :
% gpg --list-packets test.gpg
:compressed packet: algo=1
:onepass_sig packet: keyid 4136479797D6D246
version 3, sigclass 00, digest 2, pubkey 17, last=1
:literal data packet:
mode b (62), created 1191502517, name="test.txt",
raw data: 35 bytes
:signature packet: algo 17, keyid 4136479797D6D246
version 3, created 1191502517, md5len 5, sigclass 00
digest algo 2, begin of digest 0d e4
data: [159 bits]
data: [158 bits]
Malheuresement, gpg n'affiche pas les valeurs numériques des types, telles que listées par le RFC. Mais les noms qu'il utilise sont les mêmes que dans le RFC, on peut donc facilement trouver la section qui explique ce qu'est un "onepass_sig packet".
Avec un message chiffré, on obtient :
% gpg --list-packets test.txt.gpg
:pubkey enc packet: version 3, algo 16, keyid F3A0253D6C2A95F9
data: [1022 bits]
data: [1023 bits]
:pubkey enc packet: version 3, algo 16, keyid C0FE90B0F08F74D7
data: [2044 bits]
data: [2048 bits]
You need a passphrase to unlock the secret key for
user: "Stephane Bortzmeyer (Personl address) <stephane@bortzmeyer.org>"
2048-bit ELG-E key, ID F08F74D7, created 2000-03-31 (main key ID 97D6D246)
:encrypted data packet:
length: 102
mdc_method: 2
gpg: encrypted with 1024-bit ELG-E key, ID 6C2A95F9, created 2005-02-18
"Kim Minh Kaplan <kaplan@kim-minh.com>"
gpg: encrypted with 2048-bit ELG-E key, ID F08F74D7, created 2000-03-31
"Stephane Bortzmeyer (Personl address) <stephane@bortzmeyer.org>"
:compressed packet: algo=2
:literal data packet:
mode b (62), created 1191502765, name="test.txt",
raw data: 35 bytes
On notera que c'est après l'affichage des premiers paquets que gpg demande la phrase de passe pour lire la clé privée. En effet, les premiers paquets ne sont pas chiffrés, puisqu'ils indiquent la clé à utiliser pour déchiffrer le reste (PGP a une option pour masquer ces paquets, cf. section 5.1).
L'article seul
RFC 2418: IETF Working Group Guidelines and Procedures
Date de publication du RFC : Septembre 1998
Auteur(s) du RFC : Scott Bradner (Harvard University)
Première rédaction de cet article le 19 mars 2020
Comment ça, ce RFC est vieux ? Oui, il l'est mais il est toujours d'actualité plus de vingt ans après, et fait toujours autorité. Il décrit le fonctionnement des groupes de travail de l'IETF.
Petit rappel : l'IETF est l'organisme qui normalise les protocoles de l'Internet, « de la couche réseau à la couche applications ». Le mécanisme de production des normes est spécifié dans le RFC 2026, et les structures utilisées sont dans le RFC 2028. Pour exécuter ce mécanisme, l'IETF est divisée en groupes de travail (Working Group) et ce RFC décrit comment ils sont censés fonctionner. Si vous êtes curieux ou curieuse, regardez la liste des groupes de travail actuels (ils sont 119 au moment où j'écris ces lignes, il y en avait déjà plus de 100 au moment de la rédaction du RFC.) Les groupes sont regroupés en zones (areas) et il y en sept à l'heure actuelle. Par exemple, le groupe de travail QUIC, qui normalise le protocole de même nom, fait partie de la zone Transport (Transport Area.) Si vous voulez savoir comment sont désignés les directeurs de chaque zone (AD, pour Area Director), lisez le RFC 7437. Ensemble, ces directeurs forment l'IESG, la direction technique de l'IETF.
L'IETF n'a pas de membres à proprement parler. Tout le monde peut participer (contrairement à la grande majorité des organisations de normalisation), ce qui se fait via les listes de diffusion et dans des réunions physiques, quand elles ne sont pas annulées pour cause d'épidémie.
Revenons aux groupes de travail. Contrairement à beaucoup d'organisations de normalisation, l'IETF a des groupes de travail qui sont, sauf exception, focalisés sur une tâche bien précise, et qui ont une durée de vie limitée. Un groupe qui réussit est un groupe qui sera fermé, ceux qui trainent des années et des années ne sont pas en général les plus efficaces.
D'abord, comment est-ce qu'on crée un groupe de travail ? La section 2 du RFC décrit la naissance d'un groupe. Le point de départ est en général un individu ou un groupe d'individus qui décident qu'un problème technique donné est à la fois important, et traitable par l'IETF. Rappelons qu'on ne fait pas un groupe juste pour bavarder. Il doit y avoir un but précis, et réaliste. Première étape, en parler aux directeurs de la zone concernée. (Note personnelle : je me souviens d'être passé par ces étapes pour le projet « DNS privacy », qui a donné naissance au groupe dprive.) C'est l'IESG qui décide ou non de créer le groupe. Les critères :
- Une bonne compréhension du problème (l'IETF n'est pas un organisme de recherche, et ne travaille pas sur des problèmes ouverts),
- Des objectifs réalistes et atteignables (« supprimer le spam » ou bien « rendre impossible les problèmes de sécurité » ne sont pas réalistes),
- Sujet non déjà traité dans un groupe existant,
- De claires indications que des gens vont effectivement travailler sur le problème ; il ne suffit pas que des gens aient dit « ce serait bien que », il faut des volontaires déterminés à écrire les futurs RFC, la normalisation, c'est du travail,
- Et que ces gens soient compétents sur le sujet, ce qui n'est pas toujours évident sur certains problèmes où les experts ne sont pas à l'IETF,
- Et que le projet ne vienne pas d'une seule personne, ou d'une seule entreprise (qui, dans ce cas, pourrait très bien se débrouiller seule) ; le RFC estime qu'il faut au moins quatre à cinq personnes actives, et une ou deux douzaines qui suivent de près, pour que le groupe ait un sens,
- L'IETF ne travaille pas pour l'amour de l'art, il faut aussi des indications comme quoi le résultat sera vraiment utilisé en vrai dans le vrai monde,
- Et le RFC suggère aussi de regarder si le travail ne serait pas mieux fait en dehors de l'IETF, citant l'exemple de clubs privés d'organisations (comme 3GPP) ; politiquement, cela me semble contestable qu'une organisation ouverte comme l'IETF envisage de laisser le champ libre à ces clubs privés,
- Que les questions de propriété intellectuelle liées à ce sujet soient bien comprises (vœu pieux, vu leur complexité),
- Que le projet implique une vraie action de l'IETF, pas juste un coup de tampon approbateur sur une technologie déjà développée complètement à l'extérieur (problème fréquent dans des organisations comme l'ISO ou l'ETSI.) Je mentionnais QUIC précédemment : l'IETF a beaucoup modifié la version originelle, proposée par Google.
Pour tester tous ces points, il y aura parfois une session relativement informelle, la BoF, avant la décision finale de créer le groupe (voir aussi la section 2.4 qui détaille ces BoF, et le RFC 5434, publié par la suite.)
Étape suivante, le groupe a besoin d'une charte qui définit son but (regardez par exemple celle du groupe quic.) Notez que les chartes indiquent des étapes, avec des dates, qui ne sont quasiment jamais respectées (celles du groupe quic viennent d'être prolongées.) La charte indique également :
- Le nom du groupe ; l'humour geek est souvent présent et on voit des groupes nommés clue, bier, kitten, tictoc…
- Les personnes responsables, les deux co-présidents du groupe, et le directeur de zone qui supervise ce groupe,
- La liste de diffusion du groupe, puisque c'est le principal outil de travail de l'IETF, pour assurer la traçabilité du travail, elles sont toutes archivées sur le service MailArchive (voici par exemple le travail de quic.)
Le dernier groupe créé, au moment de la publication de cet article, est le groupe webtrans.
Une fois créé, comment fonctionne le groupe ? Les groupes disposent d'une grande autonomie, l'IETF essaie de ne pas trop micro-gérer chaque détail (c'est pas complètement réussi.) L'idée de base est que le groupe doit être ouvert, et atteindre des décisions par le biais du « consensus approximatif » (approximatif pour éviter qu'un râleur isolé n'aie un droit de veto sur le groupe.) En pratique, c'est aux présidents du groupe de gérer ce fonctionnement. Les règles sont plutôt des guides que des lois formelles à respecter absolument. Donc, les règles :
- L'activité de l'IETF est publique (contrairement à des organismes comme l'ISO) donc les groupes également,
- L'essentiel de l'activité doit se faire en ligne (même en l'absence de confinement), pour éviter d'exclure ceux qui ne peuvent pas se déplacer, via une liste de diffusion (exemple, celle du groupe regext, qui normalise les interfaces des registres),
- Mais il y a quand même des réunions physiques, normalement trois fois par an, même si elles n'ont normalement pas de pouvoir de décision (toujours pour éviter d'exclure les gens qui n'ont pas pu venir, par exemple pour des raisons financières),
- (D'ailleurs, opinion personnelle, les réunions formelles des groupes de travail sont parfois assez guindées, avec peu de réel travail, celui-ci se faisant hors réunion, dans les couloirs ou bien en ligne),
- Le consensus approximatif est une notion difficile, qui n'est pas rigoureusement définie, pour éviter des règles trop rigides, le RFC note toutefois que 51 % des participants, ce n'est pas un consensus,
- Et comment estimer s'il y a consensus ? Dans la salle, on peut faire lever les mains, ou procéder au humming (procédure où on émet un son la bouche fermée, l'intensité du son permet de juger du soutien de telle ou telle position, cf. RFC 7282), qui a l'avantage d'un relatif anonymat, sur la liste de diffusion, c'est plus difficile, le RFC met en garde contre un simple comptage des messages, qui favorise les gens les plus prompts à écrire beaucoup ; là encore, ce sera aux présidents du groupe de déterminer le consensus.
Et une fois que le groupe a bien travaillé, et produit les documents promis ? On a vu que l'IETF n'aimait guère les groupes qui trainent dix ans sans buts précis, donc l'idéal est de mettre fin au groupe à un moment donné (section 4). Au moment de la rédaction de cet article, c'est ce qui vient d'arriver au groupe doh (qui avait normalisé le protocole du même nom, cf. l'annonce de la terminaison, et la page actuelle du groupe.)
Toute cette activité nécessite du monde, et il y a donc plusieurs postes importants à pourvoir (section 6 du RFC). D'abord, les président·e·s des groupes de travail. Il est important de comprendre que ce ne sont pas eux ou elles qui vont écrire les documents. Leur rôle est de faire en sorte que le groupe fonctionne, que les travaux avancent, mais pas de rédiger. C'est déjà pas mal de travail, entre les groupes où ça s'engueule, les trolls négatifs, ou bien les auteurs qui ne bossent pas et qui ne répondent pas aux sollicitations (je plaide coupable, ici, j'ai fait souffrir plusieurs présidents de groupe.) Les présidents sont responsables du résultat, il faut que les normes soient produites, et qu'elles soient de qualité. Cela implique une activité de modération de la liste (pas la censure, comme entend souvent aujourd'hui ce terme de « modération », mais des actions qui visent à calmer les discussions), l'organisation des sessions physiques, la production de compte-rendus de ces réunions, la distribution des tâches (il n'y a pas que l'écriture, il y a aussi la lecture, il faut s'assurer que les documents ont été attentivement relus par plusieurs personnes compétentes) et d'autres activités.
Et comme il faut bien que quelqu'un écrive, il faut également au groupe des rédacteurs. On les appelle parfois « auteurs », parfois « éditeurs », pour mettre en avant le fait que le vrai auteur est le groupe de travail. Quelque soit le terme, le travail est le même : rédiger, relire, intégrer les décisions du groupe de travail, etc. C'est un travail souvent ardu (je parle d'expérience.)
Une autre catégorie d'acteurs du groupe de travail est celle des design teams. Un design team est un sous-ensemble informel du groupe de travail, chargé de travailler à un projet lorsqu'il semble que le groupe entier serait trop gros pour cela. Les design teams ne sont pas forcément formalisés : deux personnes dans un couloir décident de travailler ensemble, et c'est un design team.
Le but final est de produire des documents. La section 7 du RFC décrit le processus d'écriture. Tout futur RFC commence sa vie comme Internet-Draft. (Le meilleur moyen d'accéder aux Internet-Drafts est sans doute le DataTracker.) Comme leur nom l'indique, les Internet-Draft sont des brouillons, pas des documents définitifs. N'importe qui peut écrire et soumettre (notez que les instructions dans le RFC ne sont plus d'actualité) un Internet-Draft, sa publication ne signifie aucune approbation par l'IETF. Si vous ressentez le désir d'en écrire un, notez que les instructions du RFC sur le format désormais dépassées, il faut plutôt lire le RFC 7990.
Une fois le document presque prêt, il va passer par l'étape du dernier appel au groupe (WGLC, pour Working Group Last Call.) Comme son nom l'indique, ce sera la dernière occasion pour le groupe d'indiquer si le document est considéré comme publiable. Après, il quittera le groupe et sera de la responsabilité de l'IETF toute entière, via l'IESG (section 8 de notre RFC.)
Ce RFC est ancien, je l'avais dit, et plusieurs mises à jour ont eu lieu depuis, sans le remplacer complètement. Cela a été le cas des RFC 3934 (lui-même remplacé par le RFC 9945), RFC 7475 et RFC 7776.
L'article seul
RFC 2385: Protection of BGP Sessions via the TCP MD5 Signature Option
Date de publication du RFC : Août 1998
Auteur(s) du RFC : Andy Heffernan (cisco Systems)
Chemin des normes
Première rédaction de cet article le 6 janvier 2009
Le protocole TCP est vulnérable à plusieurs attaques fondées sur l'envoi de paquets prétendant venir d'un correspondant légitime, alors qu'ils sont injectés dans le réseau par le méchant. La communauté des opérateurs Internet est depuis longtemps particulièrement soucieuse de ces risques pour les sessions BGP entre ses membres et a donc développé ce bricolage qui consiste à insérer une option TCP validant très partiellement les paquets. (Bien que cette vulnérabilité de TCP soit très générale, cette solution n'a été utilisée que pour BGP. Le résultat est un très court RFC, traitant - assez mal - un problème très particulier.)
Une attaque typique contre BGP est une DoS où le méchant envoie un paquet TCP RST (ReSeT, sections 3.1 et 3.4 du RFC 793) qui va couper brutalement la session. Les techniques récentes comme TLS ne protègent pas contre ce genre d'attaques car elle opèrent juste en dessous de la couche application, et ne peuvent pas authentifier les paquets TCP (section 1). Même chose si on avait une solution purement BGP.
La solution de ce RFC est donc (section 2) d'insérer dans chaque segment TCP un résumé cryptographique MD5 portant sur une partie des en-têtes IP et TCP, les données, et un secret partagé entre les deux routeurs. L'attaquant ne connaissant pas ce mot de passe, il ne peut pas fabriquer de faux paquets.
À noter que, bien qu'enregistrée dans le registre IANA des options, ce n'est pas une « vraie » option TCP : les options TCP (section 3.1 du RFC 793) ne sont pas, comme leur nom l'indique, obligatoires. Chacun des deux pairs peut les refuser. Ici, pour éviter toute attaque par repli, la signature TCP MD5 est à prendre ou à laisser.
Passons aux bits sur le câble, avec la section 3 qui décrit le format dans le paquet. Puis aux considérations pratiques avec la section 4 qui détaille les problèmes qui peuvent se produire avec les signatures MD5, comme les soucis qui peuvent provenir car des paquets TCP légitimes peuvent être refusés (section 4.1 mais qui ne mentionne pas le fait que des paquets ICMP, non validés par la signature MD5, peuvent par contre être acceptés alors qu'ils sont faux), le coût en performance à cause des opérations cryptographiques (section 4.2 mais il faut relativiser : lorsque le RFC a été écrit, l'exemple de processeur de routeur était le MIPS R4600, à 100 Mhz) ou l'augmentation de la taille des paquets (section 4.3).
Plus sérieux est le problème de la vulnérabilité de MD5. Elle était déjà bien connue à l'époque (section 4.4) et ça ne s'est évidemment pas arrangé. (En décembre 2008, une attaque réussie contre MD5 a permis de générer de faux certificats X.509). À noter que le RFC ne prévoit pas de moyen d'indiquer un autre algorithme cryptographique que MD5, pour les raisons expliquées dans cette section 4.4. De l'avis de certains, dans le cas de BGP, MD5 reste encore relativement raisonnable. Néanmoins, cela ne pouvait pas durer éternellement et c'est l'une des motivations qui ont finalement mené au remplacement de ce protocole (cf. RFC 5926).
Presque tous les routeurs dédiés savent utiliser cette option MD5 TCP. Ainsi, sur IOS, c'est le mot-clé password :
router bgp 64542 neighbor 192.0.2.108 password g2KlR43Ag
La situation est plus délicate sur les routeurs non-dédiés, par
exemple fondés sur
Unix. Linux ou
FreeBSD n'ont pas eu pendant longtemps le support du RFC 2385 en série (il existait des patches comme http://hasso.linux.ee/doku.php/english:network:rfc2385), en partie pour une question de principe (cette
option viole le modèle en couches avec ses aller-retours entre
l'application et TCP). (Pour Quagga, voir
certains liens en http://wiki.quagga.net/index.php/Main/AddRes.) Aujourd'hui, le
noyau Linux (par exemple en version 2.6.26) a cette fonction (au
moment de la compilation, activer TCP: MD5 Signature Option
support (RFC2385) (EXPERIMENTAL), ce qui est le cas sur
Debian par défaut).
En pratique, l'exigence de sessions « TCP MD5 » a souvent servi à éliminer ceux qui utilisent Quagga sur Unix et n'avaient pas de moyen facile de configurer leurs routeurs selon cette option.
Une autre objection fréquente faite à ce RFC 2385 est qu'il aurait mieux valu utiliser IPsec, qui a l'avantage de couvrir les autres protocoles (comme ICMP) et d'être plus générique. Mais IPsec, notamment en raison de sa complexité, a connu peu de déploiements.
Le groupe de travail tcpm de l'IETF a donc finalement développé un meilleur protocole, TCP Authentication Option (TCP-AO), normalisé dans le RFC 5925.
Un bon exposé technique en français sur ce RFC est dans l'article « Les signatures MD5 des segments TCP ».
L'article seul
RFC 2360: Guide for Internet Standards Writers
Date de publication du RFC : Juin 1998
Auteur(s) du RFC : Gregor D. Scott (Director, Defense Information Systems Agency)
Première rédaction de cet article le 14 septembre 2006
Écrire une norme, comme écrire n'importe quelle spécification, est un art. Ce RFC vise à améliorer la qualité des normes IETF en conseillant leurs auteurs sur ce qui fait une bonne norme.
On note que l'IETF s'impose une tâche qui n'est pas considérée comme telle par toutes les SDO : s'assurer que la norme soit lisible et que les implémenteurs la comprennent suffisamment bien pour que les implémentations soient interopérables.
Le RFC couvre donc les points suivants :
- La nécessité de se pencher de très près sur les problèmes de sécurité.
- La définition précise du comportement d'un logiciel lorsque celui avec qui il communique viole la spécification (les premiers RFC étaient écrits pour un monde parfait où tout le monde "jouait le jeu").
- La célèbre règle "Be liberal in what you accept, and conservative in what you send", spécifiée dans le RFC 791. Très souvent citée, parfois mal comprise, cette règle a permis le décollage d'un Internet composé de logiciels très variés, d'origine très différentes. Mais elle est aussi responsable de beaucoup de problèmes liés au laxisme des implémentations et notre RFC recommande donc la prudence en l'appliquant.
- Le choix des options : trop d'options et l'interopérabilité en souffre (car deux implémentations ne mettent pas forcément en œuvre les mêmes). Pas assez d'options et le protocole ne peut pas s'adapter.
- La spécification rigoureuse, presque juridique, des obligations et interdictions. Cela se fait par les mots-clés MUST, SHOULD et MAY, définis dans le RFC 2119, mots-clés qui sont écrits en majuscules pour montrer que ce n'est pas leur sens courant qui est utilisé.
- Les conventions de notation, par exemple pour les automates à états finis, utilisés dans de nombreux RFC.
- La nécessité de permettre la gestion du protocole, notamment via le protocole standard de l'IETF.
- La nécessité de s'adapter à un monde varié, non limité aux États-Unis et non limité aux anglophones.
- Et de nombreux autres points.
Des conseils pratiques apparaissent ensuite dans la section 3, pour décrire le format des paquets et les automates à états finis.
Notre RFC se clot sur une liste de choses à vérifier lorqu'on écrit une norme.
Globalement, les normes produites par l'IETF et distribuées dans les RFC sont d'une qualité très supérieure, notamment en terme de clarté et de précision, aux normes d'autres organismes. Le succès fulgurant de l'Internet en a été le résultat. Mais cela n'interdit pas de s'améliorer et ce document permet aux RFC d'être encore meilleurs.
L'article seul
RFC 2345: Domain Names and Company Name Retrieval
Date de publication du RFC : Mai 1998
Auteur(s) du RFC : John C. Klensin (MCI Internet Architecture), Ted Wolf, Jr. (Electronic Commerce), Gary W. Oglesby (MCI Internet Architecture)
Expérimental
Première rédaction de cet article le 13 février 2007
Un problème récurrent sur le Web est de trouver le site Web d'une entité (administration, association, entreprise) dont on connait le nom. Ce RFC propose un nouveau protocole spécialisé dans cette tâche, protocole qui n'a eu aucun succès bien que des idées analogues continuent à se manifester de temps en temps.
Actuellement, les utilisateurs dépendent de trucs plus ou moins
efficaces : par exemple, ajouter
.com au nom de l'entité et
taper cela dans un navigateur. Mais
.com voit de nombreuses
collisions de noms (http://www.mont-blanc.com/ n'est ni
le stylo, ni la crème dessert) et le DNS ne
peut renvoyer qu'une seule réponse. Et il y a d'autres
TLD que
.com.
Une autre solution est de taper le nom de l'entité cherchée dans un moteur de recherche comme Exalead. Cette fois, en cas d'ambiguïté, on peut avoir plusieurs réponses, mais on risque aussi de trouver des sites Web qui parlent de l'entité en question mais qui ne sont pas gérées par elle. Pire, à quelques jours d'intervalle, on peut tomber sur des sites complètement différents, le moteur de recherche ayant entretemps mis son index à jour.
Notre RFC proposait donc, et je crois que c'est la première fois que c'était explicite, un système de mots-clés. Un serveur spécialisé écoute des requêtes et, si la requête correspond à un mot-clé enregistré, il renvoie une liste d'URL, pour que l'utilisateur puisse choisir (ce qui ne convient donc qu'aux protocoles synchrones, donc pas au courrier électronique). Pour simplifier, le RFC propose que le protocole utilisé soit le classique whois, normalisé dans le RFC 3912.
Ce RFC expérimental n'a connu aucun succès et je ne crois pas qu'il
y aie eu de déploiement significatif. Le service qui avait été crée
par les auteurs du RFC, companies.mci.net,
n'existe plus. Si, du point de vue technique, ce protocole très simple
ne pose aucun problème, les auteurs avaient soigneusement évité toutes
les questions non-techniques comme « Qui gérera le registre des
mots-clés ? » ou bien « Puis-je enregistrer une société
Harry Potter alors que c'est déjà une
marque déposée ? ».
Mais l'idée refait son chemin de temps en temps, en général poussée par des sociétés qui tentent de vendre, littéralement, du vent. Elles créent un registre de mots-clés, conçoivent un protocole, développent un greffon pour Internet Explorer et veulent ensuite vendre des mots-clés aux naïfs.
L'article seul
RFC 2330: Framework for IP Performance Metrics
Date de publication du RFC : Mai 1998
Auteur(s) du RFC : Vern Paxson (MS 50B/2239), Guy Almes (Advanced Network & Services, Inc.), Jamshid Mahdavi (Pittsburgh Supercomputing Center), Matt Mathis (Pittsburgh Supercomputing Center)
Pour information
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 4 janvier 2009
La mesure des performances sur Internet est un vaste sujet, rendu plus difficile par l'utilisation massive de mots mal définis ou, pire, utilisés à contre sens (« débit », « bande passante » ou, pire, « vitesse » étant de bons exemples). C'est pour cela que le travail du groupe IPPM (IP Performance Metrics) a commencé par ce RFC 2330 qui essaie de définir un cadre solide pour parler de mesures de performances.
Prenons l'exemple d'un cas qui semble trivial : un liaison Internet est saturée et on n'arrive plus à y faire passer tous les films qu'on veut regarder. Pour la remplacer, on hésite entre deux liaisons dont on voudrait bien mesurer la capacité, afin de choisir la « meilleure ». Mais que veut dire exactement « cette liaison permet un débit de 20 Mb/s » ? Ce chiffre est mesuré dans quelle couche ? Est-il valable en permanence ou bien est-ce une moyenne ? Dépend-il de la taille (ou d'autres caractéristiques) des paquets ? Sans réponse claire à ces questions, le chiffre de 20 Mb/s ne signifie pas grand'chose. D'autant plus que les vendeurs ont tout intérêt à brouiller les pistes. (Au fait, cette notion, nommée « capacité », est définie dans le RFC 5136.)
La section 3 du RFC résume les buts : définir des métriques, c'est-à-dire des grandeurs mesurables et définies de manière rigoureuse. Pour cela, notre RFC spécifie le cadre commun à toutes les métriques, qui seront développées dans des RFC ultérieurs (comme le RFC 2678 pour la métrique de connectivité ou bien le RFC 2681 pour la métrique de temps d'aller-retour entre deux points).
Quels sont les critères pour une « bonne » métrique ? C'est la question que traite la section 4. Parmi ces critères :
- Pouvoir être définie rigoureusement,
- Pouvoir être mesurée de façon reproductible,
- Être utile en pratique, pour les utilisateurs ou les administrateurs du réseau.
On voit que les questions de vocabulaire vont être cruciales. Pour rompre avec le flou des données, il faut que les grandeurs mesurées soient définies d'une manière rigoureuse et précise. Ainsi, la section 5 donne des définitions pour un certain nombre d'éléments qui seront utilisés dans les métriques. Par exemple, host, machine connectée au réseau, inclus explicitement les routeurs, link est un lien de couche 2, path un ensemble contigu de links, etc.
Une fois ces bases de langage établies, le RFC s'attaque aux concepts (section 6). Il s'attache à bien établir la différence entre la définition d'une métrique (qui doit avant tout être complète et rigoureuse) et la mesure effective (qui n'est pas toujours facile, comme illustré plus loin par la discussion sur la mesure du wire time).
Cette section est aussi l'occasion de poser certaines conventions comme le fait que les temps se mesurent toujours en UTC et que les kilos valent toujours 1000 (suivant la règle des télécommunications, celle du stockage informatique étant plutôt qu'un kilo vaut 1024).
Une fois une métrique définie, il faut la mesurer : c'est l'objet de la section 6.2. On peut le faire directement en mesurant la grandeur qui nous intéresse ou indirectement, par exemple en calculant ou en déduisant cette grandeur d'autres mesures. Les particularités de la mesure doivent être soigneusement étudiées et publiées avec les résultats. Par exemple, certaines mesures modifient la grandeur mesurée (des pings répétés chargent le réseau et modifient donc le temps d'aller-retour que ping est censé mesurer). La science de la mesure est aussi ancienne que la physique et ces problèmes, tout comme ceux des erreurs ou incertitudes (section 6.3) sont bien connus, mais souvent oubliés lorsqu'il s'agit de réseaux informatiques. Le RFC a donc raison de les rappeler et d'insister sur l'importance de les documenter lorsqu'on publie.
Les métriques ne vivent pas seules : il est souvent utile de les composer, ce que traite la section 9. Elle décrit en 9.1 les compositions spatiales où les mesures sur des sous-chemins (subpath) s'additionnent. Par exemple, le délai de propagation d'un paquet le long d'un chemin (path) est proche de la somme des délais de propagation sur les sous-chemins. En 9.2, on trouve les compositions temporelles, où le passé permet de prédire le futur. Par example, si on a mesuré le débit sur un lien depuis vingt-quatre heures, et que sa variation selon l'heure est bien comprise, on va pouvoir déduire le débit futur pendant les prochaines vingt-quatre heures.
La plupart des mesures, en matière de réseau, font intervenir le temps. Le concept est souvent mal compris et une section entière, la 10, est dédiée à Chronos. Certes, l'Internet dispose depuis longtemps d'un protocole standard pour la gestion d'horloges, NTP (RFC 5905). Mais ses buts sont différents : il vise à garder des horloges synchronisées sur une longue période. Pour la mesure, on s'intéresse à des périodes plus courtes pour lesquelles NTP n'est pas forcément la solution.
Quels sont les problèmes avec les horloges ? Une horloge peut avoir un écart (offset) avec le « vrai » temps, UTC (ou bien avec une autre horloge, si on s'intéresse juste au fait qu'elles soient synchronisées). Si cet écart est inférieur à une certaine valeur, on dit que l'horloge est correcte (accurate). Et l'horloge peut avoir un décalage (skew), elle peut avancer plus ou moins vite que la normale (et donc cesser au bout d'un moment d'être correcte). Pire, la dérive peut être variable, auquel cas on mesure la dérivée seconde du décalage sous le nom de dérive (drift). Enfin, l'horloge a une certaine résolution (resolution), la plus petite unité de temps qu'elle peut mesurer.
Pour minimiser l'effet de ces limites sur la mesure, le RFC recommande donc que les horloges des différentes machines impliquées soient synchronisées, idéalement à partir d'une source extérieure commune (comme le GPS). Le RFC illustre l'importance de la synchronisation par un simple exemple. Si on mesure le délai de transmission d'un paquet sur un lien transaméricain, une valeur de 50 ms est raisonnable. Si le décalage est de 0,01 %, après seulement dix minutes, l'écart atteindra 60 ms soit davantage que ce qu'on veut mesurer.
NTP n'est pas forcément la bonne solution car son exactitude dépend des liens Internet, exactement ceux dont on veut mesurer les caractéristiques. D'autre part, NTP donne la priorité à la correction, pas à la limitation du décalage. NTP peut délibèrément accélérer ou ralentir une horloge (augmenter ou diminuer le décalage) pour la rapprocher du temps correct. On n'a pas envie que cela survienne pendant une mesure !
Un autre problème de mesure lié au temps est celui du wire time (section 10.2). Les mesures sont souvent effectuées sur les machines elle-mêmes, et pas via un équipement spécial connecté au câble. Les machines ne sont pas forcément optimisées pour la mesure et n'ont pas forcément un noyau temps réel. Elles peuvent donc introduire leurs propres inexactitudes. Pour séparer les délais internes à la machine des délais du réseau, le RFC recommande d'utiliser dans les métriques le « temps du câble » (wire time), pas le temps de la machine. Le premier reflète le moment où le paquet est effectivement présent sur le câble. Plus rigoureux, il est par contre plus difficile à mesurer. Ainsi, pour un programme comme ping, le temps de la machine (host time) est facilement connu grâce à gettimeofday alors qu'il n'y a pas de moyen de mesurer le temps du câble, depuis une application Unix ordinaire. C'est donc une instance particulière du problème discuté plus haut, où le souci de donner une définition correcte de la métrique a priorité sur la facilité de mesure.
Pour réaliser une mesure du temps du câble, le RFC recommande d'utiliser un filtre à paquets comme le BPF qui associe à chaque paquet une estampille temporelle en général proche du temps du câble. Il recommande également de ne pas faire tourner ce filtre sur la machine qu'on veut observer, pour limiter les perturbations.
Les mesures impliquent des statistiques et la section 11 quitte les rivages de la physique pour revenir à ceux de la mathématique. Elle est consacrée à la différence entre les mesures uniques (singleton) et les échantillons (samples), ensembles de mesures uniques. Par exemple, un échantillon de mesures consiste en « une heure de mesures uniques, chacune prise à intervalles de Poisson avec un écart moyen d'une seconde entre les mesures ». L'échantillonnage est un art délicat et la section 11.1 expose différents moyens de le réaliser. Par exemple, le plus simple est la mesure périodique, à intervalles fixes. Mais elle a des défauts :
- Si la grandeur mesurée est elle-même périodique, la mesure risque de se faire toujours au même moment, par rapport à la période du phénomène observé. On peut alors ne pas percevoir la périodicité de celui-ci.
- Si la mesure est active, l'injection de données à intervalles périodiques entraîne parfois des effets de synchronisation non désirés (cf. un article fameux, S. Floyd et V. Jacobson, The Synchronization of Periodic Routing Messages, IEEE/ACM Transactions on Networking, avril 1994).
- Enfin, l'échantillonage périodique est prévisible, ce qui peut être gênant si un malhonnête essaie d'influencer le résultat.
Le RFC recommande donc d'échantilloner à intervalles aléatoires, suivant une certaine distribution. Quelques exemples de telles distributions suivent comme celle de Poisson en section 11.1.1.
Autre piège de la mathématique, les probabilités (section 12). Le RFC met en garde contre leur abus lors de la définition d'une métrique. Dire que 34 paquets sur 100 ont été perdus (ce que ping affiche sous l'étiquette packet loss) est un fait, dire que « la probabilité de perte d'un paquet est de 0,34 » est une interprétation, qui suppose que le phénomène soit aléatoire (ce qui est faux, la perte des paquets, contrairement à la désintégration d'un atome radioactif est très déterministe).
Outre les questions physiques et mathématiques, la mesure cache des
pièges liés à l'informatique. Pour plusieurs raisons, les différents
paquets ne reçoivent pas le même traitement. Par exemple, certains
FAI ralentissent délibérement les paquets
considérés comme liés à un protocole pair à pair. La mesure dépend donc du type de paquets, ce que la
section 13 formalise avec la notion de « paquets de type
P ». Lorsqu'on dit « la machine
2001:db8:42::bad:cafe est joignable », cela n'est
pas toujours vrai pour tous les protocoles, en raison notamment des
coupe-feux. Il faut donc dire « la machine
2001:db8:42::bad:cafe est joignable pour un
certain type P », où P est défini comme, mettons « paquets
TCP à destination du
port 80 ».
L'article seul
RFC 2328: OSPF Version 2
Date de publication du RFC : Avril 1998
Auteur(s) du RFC : John Moy (Ascend Communications)
Chemin des normes
Première rédaction de cet article le 11 mai 2008
OSPF est le protocole de routage interne de l'IETF. Si RIP est encore utilisé à certains endroits, si des protocoles non-standard, spécifiques à un fabricant de routeurs sont parfois utilisés sur des sites où l'intérêt des normes ouvertes n'a pas été compris, si son concurrent ISO 10589, IS-IS a connu quelques déploiements, OSPF est de loin le plus répandu. Ce RFC est la spécification normative d'OSPF version 2, la version pour IPv4.
Par définition, les IGP, comme OSPF, sont utilisés uniquement à l'intérieur d'un système autonome. Il est donc toujours difficile de produire des statistiques fiables directes, rien ne permettant de dire, vu de l'extérieur, quel IGP utilise une organisation. Mais il n'y a pas de doute qu'OSPF est de loin le plus répandu. Son histoire a parfois été cahotique, et vient d'une grande discussion à l'IETF pour créer un IGP moderne, discussion très chaude qui avait opposé les partisans des protocoles à vecteur de distance, comme RIP aux protocoles à état des liens, comme OSPF. (Christian Huitema, dans son excellent livre « Et Dieu créa l'Internet » décrit ce débat. Le premier article sur un protocole à états des liaisons dans l'ancien Arpanet est l'excellent An Overview of the New Routing Algorithm for the ARPANET en 1979.)
OSPF a finalement été normalisé dans le RFC 1131 en octobre 1989, qui connaitra plusieurs successeurs, les plus récents étant le RFC 2178, et son successeur, notre RFC 2328. L'annexe G décrit les différences avec le RFC 2178, aucune n'étant vitale (il s'agit bien du même protocole).
Notre RFC 2328 est un des plus longs jamais publiés par l'IETF, avec presque deux cent pages. Il n'est pas spécialement pédagogique, son but étant de permettre le développement d'implémentations compatibles du protocole. Il ne cherche pas à aider l'administrateur réseau, ni à informer le curieux de passage. La table des matières est déroutante, conçue selon une logique qui a un sens, mais pas celui du nouveau venu. Pour une explication de plus haut niveau (mais pas forcément facile) d'OSPF, on peut consulter le livre écrit par l'auteur du RFC. Pour une présentation plus orientée vers l'ingénieur en charge du réseau, on peut citer mon cours OSPF. Mais, de toute façon, OSPF est compliqué, il ne faut pas se faire d'illusions.
Quels sont les principes de base d'OSPF ? Comme décrit dans le résumé du RFC et dans la section 1, OSPF est un protocole à état des liens (link state et ce terme se retrouve partout dans le RFC). Chaque routeur diffuse par inondation ( flooding) l'état de ses interfaces réseaux et tout routeur connait donc l'état de tout le réseau, tous les routeurs ont la même information. À partir de celle-ci, chaque routeur fait tourner l'algorithme SPF pour trouver les routes à suivre. Le fait que tous les routeurs aient la même information facilite le calcul de routes sans boucles.
Le routage proprement dit se fait ensuite uniquement sur les en-têtes IP, sans encapsulation ultérieure.
Comme le système autonome a en général des connexions avec d'autres systèmes autonomes, certains des routeurs apprennent également des routes par d'autres protocoles comme BGP (RFC 4271) et OSPF permet d'importer ces routes dans la base de données, comme « routes externes ».
OSPF dispose d'un mécanisme hiérarchique, les zones (areas), qui permet de limiter la diffusion de l'information, rendant ainsi ce protocole moins sensible aux changements d'échelle. La règle « tous les routeurs ont exactement la même base de données des états des liens » doit donc être nuancée : elle n'est valable qu'à l'intérieur d'une seule zone.
Tout le vocabulaire d'OSPF est rassemblé dans la section 1.2. Comme souvent avec les documents informatiques en anglais, il n'y a pas une seule traduction en français qui fasse autorité. J'ai repris ici le vocabulaire de mon cours.
Vue la taille du protocole, il est impossible de citer toutes les sections du RFC. Seules celles qui me semblent les plus importantes sont listées ici.
La section 2 du RFC détaille la base des états de liens, le cœur d'OSPF. Sa section 2.1 précise comment sont représentés les routeurs et les réseaux. Ces derniers peuvent être point à point, à diffusion comme Ethernet, ou bien NBMA (Non-Broadcast Multiple Access, qui font l'objet de la section 2.1.1 et pour lesquels les choses sont assez complexes) comme le relais de trames. La représentation du lien dépend du type de réseau auquel le routeur est connecté.
La section 2.1.2 illustre tout ceci avec un exemple de base de données pour un réseau petit mais relativement complexe. La section 2.2 montre ensuite le résultat du SPF sur ce réseau.
La 2.3 explique la modélisation des informations externes, obtenues depuis un autre protocole. Elles sont de deux types, le type 1 pour les informations venant du système autonome (et donc dont le coût peut être comparé aux coûts OSPF) et le type 2 pour les informations extérieures, non seulement à OSPF, mais également au système autonome, et pour lesquelles le coût est toujours supérieur au coût OSPF.
La section 4 décrit le fonctionnement du protocole : chaque routeur OSPF, au démarrage, rassemble les informations sur ses propres interfaces réseau, puis apprend l'existence de ses voisins, et forme une adjacence sur chaque réseau. Il échange ensuite l'information sur l'état des liens avec le routeur adjacent (rappelons que tous les voisins ne sont pas adjacents, seuls le DR - Designated Router - et le BDR - Backup Designated Router le sont).
Cette information sur les états des liens est transmises sous forme d'unités nommés LSA (Link State Advertisement), qui sont transmis par inondation (procédure décrite en détail en section 13), jusqu'à ce que tous les routeurs de la zone aient la même information.
Plus concrète, la section 4.3 normalise le format des paquets OSPF. Celui-ci fonctionne directement sur IP, avec le numéro de protocole 89. Les champs du protocole sont de taille fixe, pour faciliter la mise en œuvre. Les détails du format sont renvoyés à l'annexe A. Le traitement des paquets figure dans la section 8.
La section 5 est dédiée aux différentes structures de données que doit manipuler le routeur OSPF. Par exemple, le Router ID est un entier de 32 bits qui identifie de manière unique un routeur du système autonome. Cet entier est en général représenté avec la même syntaxe qu'une adresse IPv4 (même pour la version d'OSPF conçue pour IPv6). D'autres structures de données sont décrites dans les sections 9 (les interfaces réseaux) ou 10 (les routeurs voisins).
La section 7 explique le protocole par lequel les routeurs OSPF
d'un même segment de réseau se trouvent et s'échangent des
informations. Tous les routeurs du lien envoient des paquets de type
Hello à une adresse de diffusion restreinte,
224.0.0.5 (les valeurs numériques nécessaires au
protocole, comme cette adresse, sont dans l'annexe A). Ici,
tcpdump montre ces paquets émis par le routeur
de Router ID 192.134.7.252, de
la zone 0 (l'épine dorsale) :
22:29:04.906209 IP (tos 0xc0, ttl 1, id 22064, offset 0, flags [none], proto OSPF (89), length 64) 192.134.7.252 > 224.0.0.5: OSPFv2, Hello, length: 44
Router-ID: 192.134.7.252, Backbone Area, Authentication Type: none (0)
Options: [External]
Hello Timer: 10s, Dead Timer 40s, Mask: 255.255.255.240, Priority: 1
Designated Router 192.134.7.252
Sur un réseau à diffusion comme Ethernet, un routeur est élu routeur principal (Designated Router, DR, section 7.3 mais l'algorithme d'élection figure, lui, dans la section 9.4). Les adjacences ne se forment qu'avec lui et tous les échanges OSPF passent par lui (il existe aussi un routeur de secours, le BDR, Backup Designated Router, section 7.4).
La section 12 présente les paquets LSA (Link State Advertisement, ou annonces de l'état des liens), par lesquels les routeurs OSPF se tiennent au courant de leur situation. La section est très longue car il y a beaucoup d'informations possibles à transmettre !
Une fois que les routeurs ont toute l'information nécessaire, ils peuvent faire tourner l'algorithme SPF de Dijkstra et calculer ainsi les routes, selon la procédure que décrit la section 16. (RIP utilisait Bellman-Ford.)
D'autres sections couvrent des parties plus « exotiques » du protocole, moins nécessaires en première approche.
La section 3 est consacrée au découpage en zones. (Notez toutefois que seuls les plus grands réseaux OSPF en ont besoin. Dans un document plus pédagogique, les zones auraient été reléguées à la fin.) Les routeurs d'une zone ne connaissent pas la topologie interne aux autres zones, seulement le moyen de joindre un routeur ABR (Area Border Router, section 3.3) attaché à cette zone. Les zones OSPF sont forcément attachées à une zone principale, numérotée 0 (section 3.1), qui sert d'épine dorsale au réseau.
La section 14 explique le mécanisme d'expiration des LSA dans la base (ils ne restent en effet pas éternellement).
La section 15 spécifie les liens virtuels qui permettent de connecter des parties physiquement disjointes d'une zone.
Les annexes B et C contiennent les paramètres d'OSPF, les valeurs numériques
qui gouvernent le comportement du routeur. L'annexe B décrit les
constantes, dont la valeur est fixe, comme
MaxAge, la durée de vie maximale d'un LSA (fixée
à une heure). L'annexe C contient les variables, que l'on peut
modifier via la configuration du routeur (attention, il est souvent
nécessaire que tous les routeurs du lien, ou bien tous les routeurs de
la zone, soient d'accord sur la valeur). Par exemple, avec
Quagga, on peut changer Interface
output cost (le « coût » d'une interface réseau) en mettant
dans le fichier ospfd.conf :
interface xxx0 ! Ligne lente, son usage est découragé ip ospf cost 10000
L'annexe D est consacrée à l'authentification. OSPF trouvant ses voisins par diffusion, un routeur méchant peut assez facilement s'insérer dans un réseau et diffuser de fausses informations. Sur un réseau partagé par plusieurs organisations, par exemple un point d'échange Internet, il n'est pas rare de voir passer des paquets OSPF, émis, espérons-le, suite à une erreur de configuration et pas par malveillance. Pour éviter que les adjacences ne se forment entre deux voisins, OSPF permet d'utiliser un secret partagé que doivent connaitre les routeurs.
Il existe aujourd'hui deux mises en œuvre libres d'OSPF :
mais on trouve évidemment ce protocole dans tous les routeurs, des Cisco aux Juniper en passant par les Vyatta.
L'article seul
RFC 2317: Classless IN-ADDR.ARPA delegation
Date de publication du RFC : Mars 1998
Auteur(s) du RFC : Havard Eidnes (SINTEF RUNIT), G. de Groot (Software Design, Inc.), Paul Vixie (Internet Software Consortium)
Première rédaction de cet article le 17 janvier 2007
Dernière mise à jour le 18 avril 2008
Traditionnellement, la résolution d'adresses IP en noms se faisait via une délégation dans le domaine spécial .arpa. Mais comment faire pour les préfixes IP qui ne s'arrêtent pas sur une frontière d'octet ?
Les anciennes classes d'adresses IP ont été supprimées en septembre 1993 par
le RFC 1518. Depuis, on peut obtenir des adresses
IPv4 qui ne sont pas alignées sur une frontière
d'octet, par exemple on peut avoir le préfixe
192.0.2.128/27, de longueur 27 bits. L'ancienne
technique de délégation dans in-addr.arpa ne
marche donc plus. Avec cette ancienne technique, le responsable de
192.0.2.0/24 aurait demandé à son FAI de lui
déléguer (ou bien de remplir lui-même)
2.0.192.in-addr.arpa et le gérant de la zone
DNS aurait mis des enregistrements comme :
1 IN PTR golgoth.contrevent.example. 2 IN PTR sov.contrevent.example. 3 IN PTR oroshi.contrevent.example.
Maintenant, comment faire avec les nouvelles adresses, « sans classe » ? La solution proposée par notre RFC, et qui ne n'a nécessité aucune modification des serveurs ou des résolveurs, consiste en un jeu d'enregistrements CNAME chez le FAI, une délégation DNS à une zone ad hoc, puis des enregistrements PTR chez son client, le titulaire du préfixe.
La zone chez le client peut porter n'importe quel nom. Par
exemple, pour 192.0.2.128/27, on peut utiliser
128/27.2.0.192.in-addr.arpa ou bien
128-159.2.0.192.in-addr.arpa ou même
Horde.2.0.192.in-addr.arpa. (Le choix du nom peut
être restreint par le FAI, qui a typiquement une politique et des
programmes automatiques pour gérer ce service. Mais le DNS, lui, s'en
moque.)
Supposons qu'on prenne
128/27.2.0.192.in-addr.arpa. Le FAI met alors
dans son 2.0.192.in-addr.arpa :
1 IN CNAME 1.128/27.2.0.192.in-addr.arpa. 2 IN CNAME 2.128/27.2.0.192.in-addr.arpa. 3 IN CNAME 3.128/27.2.0.192.in-addr.arpa.
Le FAI délègue alors 128/27.2.0.192.in-addr.arpa à son client.
Celui-ci, le titulaire du préfixe n'a plus qu'à créer la zone
128/27.2.0.192.in-addr.arpa sur ses serveurs de
noms et à la peupler comme une zone in-addr.arpa
classique :
1 IN PTR golgoth.contrevent.example. 2 IN PTR sov.contrevent.example. 3 IN PTR oroshi.contrevent.example.
En cas de tentative de résolution de l'adresse IP
192.0.2.3 en nom, le résolveur DNS trouvera
d'abord l'alias (CNAME), le suivra et arrivera au bon enregistrement PTR.
L'article seul
RFC 2277: IETF Policy on Character Sets and Languages
Date de publication du RFC : Janvier 1998
Auteur(s) du RFC : Harald Tveit Alvestrand (UNINETT)
Première rédaction de cet article le 22 janvier 2007
L'internationalisation est un sujet chaud aujourd'hui mais il y a des années que l'IETF s'était penché sur la question. Ce RFC présente les recommandations de l'IETF pour les futurs protocoles,développés après la sortie du RFC.
Notre RFC commence par poser des principes simples : d'abord, les humains parlent des langues différentes et il n'est pas prévu de changer cela. (Dans certaines réunions, on entend parfois des opposants à la diversité linguistique marmonner que ce serait plus simple si tout le monde parlait la même langue et déplorer que la « dictature du politiquement correct » les empêche de le dire ; de fait, on n'entend jamais ce genre d'objections publiquement.)
Les protocoles réseaux doivent donc s'adapter à cette
situation. Ces protocoles transportent du texte à deux endroits :
comme commandes, pour tous les protocoles où les commandes ne sont pas
en binaire (c'est le cas de SMTP, avec
EHLO, MAIL FROM, etc ou de
HTTP avec GET et
PUT). Ces commandes ne sont normalement jamais
vues des utilisateurs, uniquement des implémenteurs et n'ont donc pas
besoin d'être internationalisées. De même, des mots-clés de certains
formats comme From: ou
Subject: dans le format du courrier (RFC 5322) n'ont pas besoin d'être présentés tels quels
à l'utilisateur et le protocole n'a donc pas à les traduire.
Mais les protocoles transportent aussi du texte conçu pour être montré aux humains : contenu de la page Web pour HTTP, du courrier pour SMTP, etc. Et, là, le protocole doit respecter le texte, et ne pas imposer qu'il soit écrit en anglais, donc notamment ne pas le restreindre au jeu de caractères ASCII.
Dans tous les cas, le protocole doit permettre (via les étiquettes de langue, normalisées dans le RFC 5646) d'indiquer quelle est la langue d'un texte. Et les protocoles synchrones doivent permettre de négocier la langue utilisée. Dans les cas où cela n'a pas été possible, notre RFC impose, dans sa section 4.5, l'anglais, seul cas où cette langue est privilégiée.
On notera que ces excellents principes laissent de nombreux cas indéterminés. Par exemple, un nom de domaine doit-il être considéré plutôt comme un élement de protocole, qui n'a donc pas besoin d'être internationalisé (c'est plus ou moins l'idée derrière le RFC 4185), ou bien comme un nom prévu pour être connu des utilisateurs et pour lequel l'internationalisation est donc nécessaire (ce qui est le point de vue du RFC 3490) ?
Enfin, il y a loin de la coupe aux lèvres pour les anciens protocoles : l'auteur de notre RFC, Harald Tveit Alvestrand, un pilier de l'internationalisation à l'IETF (et l'auteur du premier RFC sur les étiquettes de langue, le RFC 1766) est très actif dans le groupe de travail IETF EAI/IMA qui n'a pas encore fini d'internationaliser les adresses de courrier électronique...
L'article seul
RFC 2229: A Dictionary Server Protocol
Date de publication du RFC : Octobre 1997
Auteur(s) du RFC : Rickard E. Faith (U. North Carolina), Bret Martin (Miranda)
Pour information
Première rédaction de cet article le 1 mai 2007
Dernière mise à jour le 17 juin 2007
Un très simple RFC, pour décrire un protocole requête / réponse pour interroger un dictionnaire distant.
Suivant la tendance de son époque, le protocole DICT utilise un port spécifique pour le routage du message et est très direct : la requête est envoyée sur une ligne et la réponse partiellement structurée est renvoyée en échange. Plus riche que les protocoles plus anciens comme whois ou finger (par exemple, la réponse est précédée d'un code numérique, comme avec SMTP ou HTTP, permettant une analyse facile), DICT est quand même bien plus simple que les usines à gaz modernes, par exemple à base de SOAP. Et il dispose malgré cela de possibilités intéressantes comme celle de recevoir de l'Unicode.
Aujourd'hui, un tel protocole serait peut-être bâti sur REST mais, à ma connaissance, cela n'a pas encore fait l'objet de normalisation.
Tel qu'il est, DICT est très simple à programmer et c'est par
exemple fait dans le module Emacs
dictionary. Avec ce module, il suffit de mettre dans son ~/.emacs des lignes comme :
(global-set-key [f5] 'dictionary-search) (autoload 'dictionary-search "dictionary" "Ask for a word and search it in all dictionaries" t) (autoload 'dictionary-match-words "dictionary" "Ask for a word and search all matching words in the dictionaries" t) (autoload 'dictionary-lookup-definition "dictionary" "Unconditionally lookup the word at point." t) (autoload 'dictionary "dictionary" "Create a new dictionary buffer" t) ;(setq dictionary-server "dict.example.org")
et un appui sur <F5> affichera la définition du terme sur lequel se trouve le curseur.
Une autre solution est d'utiliser, en ligne de commande, l'excellent outil curl qui est client DICT. Par exemple, si on cherche la définition de corrugated dans le Webster, on trouve :
% curl dict://dict.org/lookup:corrugated:web1913
220 aspen.miranda.org dictd 1.9.15/rf on Linux 2.6.18-4-k7 <auth.mime> <4730178.11990.1182115574@aspen.miranda.org>
250 ok
150 1 definitions retrieved
151 "Corrugated" web1913 "Webster's Revised Unabridged Dictionary (1913)"
Corrugate \Cor"ru*gate\ (-g?t), v. t. [imp. & p. p. {Corrugated}
(-g?`t?d); p. pr. & vb. n. {Corrugating} (-g?`t?ng).]
To form or shape into wrinkles or folds, or alternate ridges
and grooves, as by drawing, contraction, pressure, bending,
or otherwise; to wrinkle; to purse up; as, to corrugate
plates of iron; to corrugate the forehead.
{Corrugated iron}, sheet iron bent into a series of alternate
ridges and grooves in parallel lines, giving it greater
stiffness.
{Corrugated paper}, a thick, coarse paper corrugated in order
to give it elasticity. It is used as a wrapping material
for fragile articles, as bottles.
.
250 ok [d/m/c = 1/0/18; 0.000r 0.000u 0.000s]
221 bye [d/m/c = 0/0/0; 0.000r 0.000u 0.000s]
Les seuls dictionnaires accessibles par ce protocole que j'ai trouvées en ligne sont en anglais. Je n'en connais pas en français, les réalisations concrètes et utiles étant rares dans le monde de la francophonie (contrairement aux colloques de prestige). Ainsi, le dictionnaire de l'ATILF ne semble pas disposer d'une interface adaptée aux programmes (qu'elle soit bâtie sur DICT ou sur un autre protocole). Même chose pour le Wiktionnaire, malheureusement, même si un outil, apparemment à installer soi-même, existe.
Quant à ce qui concerne le serveur, je vous invite à lire l'article de Jan-Piet Mens.
L'article seul
RFC 2181: Clarifications to the DNS Specification
Date de publication du RFC : Juillet 1997
Auteur(s) du RFC : Robert Elz (Computer Science), Randy Bush (RGnet, Inc.)
Chemin des normes
Première rédaction de cet article le 14 juillet 2008
Le DNS est à la fois un des protocoles de base de l'Internet, dont presque toutes les transactions dépendent, et un des protocoles les plus mal spécifiés. Les RFC de référence, les RFC 1034 et RFC 1035, sont toujours en service mais, écrits il y a plus de vingt ans, ils accusent leur âge. Ils sont souvent ambigus et ont été mis à jour par de nombreux RFC ultérieurs. Ainsi, celui qui développe une nouvelle mise en œuvre du DNS doit lire plusieurs RFC successifs. L'un des plus importants est notre RFC 2181 qui avait clarifié plusieurs points particulièrement importants de la norme originelle.
On ne peut rien faire avec le DNS si on ne lit pas ce RFC 2181. Il est une sorte de FAQ des erreurs les plus souvent commises en lisant trop vite les RFC 1034 et RFC 1035. Mais il corrige aussi ces RFC, qui comportaient parfois de réelles erreurs (sections 1, 2 et 3).
Les consignes de notre RFC 2181 sont très variées.
Ainsi, la section 4 rappelle que le serveur DNS doit répondre depuis l'adresse IP à laquelle la question a été posée (pour un serveur qui a plusieurs adresses). La section 4.2 pose le même principe pour le numéro de port.
La section 5 introduit un concept nouveau, celui de RRSet (Resource Record Set ou « ensemble d'enregistrements de données »). Ce concept n'existait pas dans les RFC 1034 et RFC 1035. Un RRSet est un ensemble d'enregistrements DNS pour le même nom de domaine, et le même type. Ainsi, ce groupe forme un RRSet :
foobar.example.com. IN AAAA 2001:DB8:123:456::1 foobar.example.com. IN AAAA 2001:DB8:CAFE:645::1:2
mais pas celui-ci :
foobar.example.com. IN AAAA 2001:DB8:123:456::1 baz.example.com. IN AAAA 2001:DB8:CAFE:645::1:2
(car le nom est différent) ni celui-ci :
foobar.example.com. IN AAAA 2001:DB8:123:456::1 foobar.example.com. IN A 192.0.2.34
(car le type est différent).
Le RFC impose ensuite (section 5.1) que les enregistrements d'un RRSet soient tous envoyés dans une réponse (ou bien que le bit TC - indiquant la troncation - soit positionné, ce que détaille la section 9). Pas question de n'envoyer qu'une partie d'un RRSet. Il impose également que les différents enregistrements d'un RRSet aient le même TTL (section 5.2). Il existe également des règles pour DNSSEC (section 5.3) mais elles concernent l'ancienne version de DNSSEC, qui a depuis été remplacée par DNSSEC-bis (RFC 4033 et suivants).
De même qu'un serveur ne peut pas n'envoyer qu'une partie des
enregistrements d'un RRSet, il ne doit pas
fusionner un RRSet reçu en réponse avec des données
du même RRSet qui seraient dans son cache (section
5.4). Le reste de la section 5.4 est d'ailleurs consacré à la
nécessaire paranoïa d'un serveur de noms
récursif. En effet, le RFC 2181 lui impose de ne pas accepter
aveuglément n'importe quelle donnée mais de juger de la confiance
qu'on peut lui accorder (section 5.4.1). Ainsi, les données présentes
dans la section additional d'une réponse DNS sont
moins fiables que celles de la section answer. Le
déploiement de notre RFC a ainsi résolu un gros problème de sécurité
du DNS : les serveurs de noms récursifs avalaient tout le contenu de
la réponse, sans juger de sa valeur, et étaient donc faciles à
empoisonner avec de fausses données. Ainsi, avant le RFC 2181, un serveur qui demandait les enregistrements de type A
pour www.example.org et qui recevait une
réponse :
;; QUESTION SECTION: ;www.example.org. IN A ;; ANSWER SECTION: www.example.org. IN A 192.0.2.1 ;; ADDITIONAL SECTION: www.google.example. IN A 192.0.2.178
acceptait l'enregistrement A dans la section additionnelle, bien que cet enregistrement n'aie aucun rapport avec la question posée et ne fasse pas autorité.
La section 6 du RFC traite des frontières de zones DNS
(zone cuts). L'arbre des noms de domaine est
découpé en zones (RFC 1034,
section 2.4 et 4.2), chaque zone étant
traditionnellement décrite dans un fichier de zone spécifique. Pour
connecter une zone parente à la fille, la parente ajoute des
enregistrements de type NS. Il faut se rappeller que les frontières de
zone ne se voient pas dans le nom de domaine. Est-ce que
org.uk est géré par la même organisation que
co.uk ? Vous ne pouvez pas le savoir juste en
regardant ces noms. D'autre part, les zones ne correspondent pas
forcément à des frontières organisationnelles. Pendant longtemps,
nom.fr était dans une zone différente de
fr alors que les deux domaines étaient gérés par
le même organisme, l'AFNIC. En sens inverse, le
futur domaine .tel n'aura qu'une seule zone, tout
en permettant aux utilisateurs de mettre leurs propres données.
Bref, la zone est une notion complexe. Notre RFC rappelle juste que les données de délégation (les enregistrements NS) ne font pas autorité dans la zone parente (section 6.1). En dehors des enregistrements indispensables à la délégation (NS et peut-être A et AAAA de colle), les serveurs ne doivent pas envoyer de données qui sont au delà d'une frontière de zone.
La section 8 corrige légèrement la définition du TTL qui se trouve section 3.6 du RFC 1034 en imposant que ce soit un entier non signé.
La section 10 s'attaque à des question plus délicates car plus visibles par l'utilisateur humain, les questions de nommage. Au contraire des règles des sections précédentes, qui ne seront guère vues que par les programmeurs qui écrivent des serveurs de noms, les règles des sections 10 et 11 concernent tous les gérants de zones DNS.
D'abord, un rappel en début de section 10 : dire que telle machine
« a pour nom de domaine gandalf.example.net » est
un net abus de langage. Une machine n'a pas un
nom qui serait le « vrai » ou l'« authentique ». Il faut plutôt dire
que des tas de noms dans le DNS peuvent pointer sur une machine
donnée. Ainsi, il n'y a aucune obligation d'avoir un seul
enregistrement de type PTR (section 10.2) pour une adresse IP donnée.
La section 10.1 clarifie les enregistrements de type CNAME. Leur noms peut être trompeur car il veut dire Canonical Name (« nom canonique ») alors que le CNAME sert plutôt à enregistrer des alias (section 10.1.1). Si le DNS contient :
www.example.org. IN CNAME www.example.net.
il ne faut pas dire que www.example.org est le
CNAME de www.example.net mais plutôt qu'il est
l'alias de www.example.net ou, plus
rigoureusement, qu'il existe un enregistrement de type CNAME dont le
nom est www.example.org.
La section 10.2 rappelle qu'on peut avoir plusieurs enregistrements
de type PTR et surtout qu'un PTR peut mener à un alias, et pas
directement au nom de domaine désiré. Cette propriété est d'ailleurs à
la base de la délégation sans classe de
in-addr.arpa décrite dans le RFC 2317.
Par contre, les enregistrements NS et MX ne peuvent pas mener à un alias (section 10.3). Un logiciel comme Zonecheck teste d'ailleurs cela.
Enfin, la section 11 est peut-être la plus ignorée de tout le RFC. Consacrée à la syntaxe des noms de domaines, elle rappelle (c'est juste un rappel, les RFC 1034 et RFC 1035 étaient déjà clairs à ce sujet) qu'un nom de domaine peut prendre n'importe quelle valeur binaire. Si vous entendez quelqu'un dire que « le DNS est limité aux caractères ASCII » ou bien « le DNS est limité aux lettres, chiffres et tiret », vous pouvez être sûr que la personne en question est profondément ignorante du DNS. Le DNS a toujours permis de stocker n'importe quels caractères, même non-ASCII et, s'il a fallu inventer les IDN du RFC 3490, c'est pour de tout autres raisons.
La section 11 souligne juste que les applications qui utilisent le DNS peuvent avoir des restrictions. Ainsi, avant les IRI du RFC 3987, les adresses du Web étaient en effet limitées à ASCII.
L'article seul
RFC 2141: URN Syntax
Date de publication du RFC : Mai 1997
Auteur(s) du RFC : Ryan Moats (AT&T)
Chemin des normes
Première rédaction de cet article le 26 février 2008
Dans la grande famille des URI, il y a les URL et les URN, dont la syntaxe faisait l'objet de ce RFC, remplacé depuis par le RFC 8141.
Le RFC 3986, qui normalise la syntaxe générique des URI, délègue les détails des familles particulières d'URI à d'autres RFC comme celui-ci. Le RFC 2141 précisait la syntaxe générique pour le cas des URN, des URI dont les propriétés sont a priori la persistence et la non-résolvabilité (donc, plutôt des noms que des adresses, cf. RFC 1737 et RFC 3305).
La section 2, Syntax, forme donc l'essentiel de
ce court RFC. Un URN est formé avec le plan urn,
un NID (Namespace IDentifier) qui indique
l'organisme qui gère la fin de l'URN, le NSS (Namespace
Specific String), tous séparés par des
deux-points. L'enregistrement des autorités
identifiées par le NID était traité dans le RFC 3406, également remplacé depuis par le RFC 8141.
Par exemple, si on prend les URN néo-zélandais du RFC 4350, le NID est nzl et un URN
ressemble donc à
urn:nzl:govt:registering:recreational_fishing:form:1-0.
Comme avec les autres URI, les caractères considérés comme « spéciaux » doivent être protégés avec l'encodage pour cent (section 2.3).
La section 5, consacrée à l'équivalence
lexicale de deux URN, explique comment on peut
déterminer si deux URN sont égaux ou pas, sans connaitre les règles
particulières de l'organisme qui les enregistre. Ainsi,
urn:foo:BAR et urn:FOO:BAR
sont lexicalement équivalents (le NID est insensible à la casse) mais
urn:foo:BAR et urn:foo:bar
ne le sont pas, le NSS étant, lui, sensible à la casse (les deux URN
sont peut-être fonctionnellement équivalents mais cela dépend de la
politique d'enregistrement de l'organisme désigné par foo).
L'article seul
RFC 2136: Dynamic Updates in the Domain Name System (DNS UPDATE)
Date de publication du RFC : Avril 1997
Auteur(s) du RFC : Paul Vixie (Internet Software Consortium), Susan Thomson (Bellcore), Yakov Rekhter (Cisco Systems), Jim Bound (Digital Equipment Corp.)
Chemin des normes
Première rédaction de cet article le 16 janvier 2007
Dernière mise à jour le 16 octobre 2010
Ce RFC étend officiellement le traditionnel protocole DNS aux mises à jour dynamiques. Traditionnellement, les serveurs DNS faisant autorité utilisaient l'information contenue dans un fichier statique. À partir du moment où existe le Dynamic DNS Update, ils peuvent aussi être mis à jour en temps quasi-réel, par exemple pour suivre les changements de topologie.
Ainsi, un ordinateur portable qui se déplace mais
souhaiterait être toujours connu sous son nom (mettons
monportable.dyn.example.org) peut utiliser les
mises à jour dynamiques pour prévenir le serveur
DNS maître de sa nouvelle adresse IP. La mise à jour peut être lancée par le portable
lui-même (le serveur DHCP peut aussi être
client Dynamic DNS Update pour que les adresses
qu'il attribue se retrouvent dans le DNS (option ddns-update-style du
serveur DHCP de l'ISC).
L'idée originale avait été documentée dans l'article « The Design and Implementation of the BIND Servers » en 1984 (et mise en œuvre dans le serveur de noms développé par les auteurs) mais n'a été normalisé que longtemps après.
Notre RFC spécifie donc la façon un peu complexe dont la requête DNS doit être composée (certains champs du protocole ont dû être réaffectés). Une des particularités des mises à jour dynamiques est l'existence de pré-conditions à l'opération. Si ces pré-conditions, indiquées par le client, ne sont pas remplies, la mise à jour n'est pas faire par le serveur (les deux implémentations citées ci-dessous permettent de déclarer ces pré-conditions).
Le programme nsupdate, distribué avec BIND,
permet de faire facilement ces mises à jour. Il existe aussi des
bibliothèques pour des programmes qu'on écrit soi-même comme
l'excellent Net::DNS pour
Perl (un exemple
complet est en ligne). Voici un exemple de
script lançant nsupdate (sur Debian, c'est à
mettre dans le fichier /etc/dhclient-exit-hooks (ou dans le répertoire /etc/dhcp3/dhclient-exit-hooks.d),
il sera ainsi lancé par le client DHCP de l'ISC
lorsqu'il aura obtenu une adresse IP).
#!/bin/sh cd /etc/bind if [ x$reason = xBOUND ]; then # Attention, le fichier ".key" doit apparemment également être là nsupdate -kKexample-dyn-update.+157+18685.private -d <<EOF server nsupdate.example.org zone dyn.example.org update delete monportable.dyn.example.org update add monportable.dyn.example.org 300 A $new_ip_address send EOF fi
[Je suppose que cela peut fonctionner avec d'autres clients DHCP comme pump mais je n'ai pas testé.] nsupdate utilise ici TSIG (l'option -k) pour s'authentifier. Il supprime l'ancienne liaison nom->adresse et en ajoute une nouvelle. La variable new_ip_address a été créée par le client DHCP avant qu'il n'appelle notre script.
Comme l'usage de TSIG (cf. RFC 2845) nécessite que les horloges des deux machines
soient synchronisées, il faut veiller à ce que ces horloges soient
correctes (autrement, BIND notera quelque chose du genre request has invalid signature: TSIG example-dyn-update: tsig verify failure (BADTIME)).
On peut aussi faire les mises à jour depuis son langage de
programmation favori et on trouve de nombreux exemples en ligne comme
http://www.net-dns.org/docs/Net/DNS/Update.html pour
Perl ou bien http://www.dnspython.org/examples.html pour Python. (Voici un exemple plus complet en Python, avec dnspython.)
Sur le serveur DNS BIND, il aura fallu générer la clé :
% dnssec-keygen -a HMAC-MD5 -b 512 -n HOST example-dyn-update
La commande ci-dessus créera les fichiers .key et
.private qu'on pourra envoyer aux clients. À
noter que cette commande nécessite beaucoup d'entropie pour son
générateur aléatoire et qu'elle peut donc prendre de nombreuses
minutes à s'exécuter, quelle que soit la vitesse de la machine.
La configuration correspondante, est :
// For dynamic updates
key "example-dyn-update." {
algorithm hmac-md5;
secret "CLE-SECRET=";
};
zone "dyn.example.org" {
type master;
// Old and insecure way: authenticate by IP address
//allow-update {
// my-networks;
//};
// http://www.linux-mag.com/2001-11/bind9_01.html
// See #2700
allow-update {
key "example-dyn-update.";
};
// Future work:
// http://www.oreilly.com/catalog/dns4/chapter/ch11.html#38934
//update-policy {
// grant *.dyn.example.org self IGNORED;
// deny * wildcard *;
//};
// If you want also to restrict it to some IP addresses (untested):
//acl address_allow { 10/8; };
//acl address_reject { !address_allow; any; };
//allow-update { !reject; key "...."; };
file "/etc/bind/db.dyn.example.org";
};
.
Lors d'une mise à jour dynamique, on trouvera dans le journal de BIND quelque chose comme :
23-May-2012 22:19:56.255 client 127.0.0.1#47960: signer "foobar-example-dyn-update" approved 23-May-2012 22:19:56.255 client 127.0.0.1#47960: updating zone 'foobar.example/IN': deleting rrset at 'www.foobar.example' AAAA 23-May-2012 22:19:56.255 client 127.0.0.1#47960: updating zone 'foobar.example/IN': adding an RR at 'www.foobar.example' AAAA
Certains registres de noms de domaines, comme Nominet pour .uk utilisent ces mises à jour dynamiques pour ajouter ou modifier des domains (Nominet l'a lancé en février 2005 et a fait une bonne présentation au RIPE-NCC).
On notera que MS-Windows, par défaut, « téléphone à la maison », c'est-à-dire qu'il tente de mettre à jour les serveurs DNS avec son adresse. S'il n'a pas été correctement configuré, sa requête parvient aux serveurs de la racine du DNS, leur imposant une forte charge. C'est pour cela qu'il est souvent recommandé de le débrayer.
L'article seul
RFC 2131: Dynamic Host Configuration Protocol
Date de publication du RFC : Mars 1997
Auteur(s) du RFC : Ralph Droms (Computer Science Department)
Chemin des normes
Première rédaction de cet article le 8 mars 2007
DHCP est certainement un des plus grands succès de l'IETF. Mis en œuvre dans tous les systèmes, présent dans presque tous les réseaux locaux, on a du mal à se souvenir de la vie « avant » lorsque la configuration de chaque machine était manuelle.
DHCP permet à une machine (qui n'est pas forcément un ordinateur) d'obtenir une adresse IP (ainsi que plusieurs autres informations de configuration) à partir d'un serveur DHCP du réseau local. C'est donc une configuration « avec état », qui nécessite un serveur, par opposition aux systèmes « sans état » qui ne dépendent pas d'un serveur. Deux utilisations typiques de DHCP sont le SoHo où le routeur ADSL est également serveur DHCP pour les trois PC connectés et le réseau local d'entreprise où deux ou trois machines Unix distribuent adresses IP et informations de configuration à des centaines de machines.
Le DHCP spécifié par notre RFC (qui remplace son prédécesseur, le RFC 1541), ne fonctionne que pour IPv4 ; un compagnon, le RFC 8415 traite d'IPv6. DHCP succède à BOOTP (qui était décrit dans le RFC 951), en introduisant notamment la notion de bail (lease), qui limite la durée de vie d'une allocation d'adresse. DHCP est donc un très vieux protocole, mais qui marche très bien. Son héritage BOOTP (il a même récupéré les numéros de ports) rend parfois la lecture du RFC compliquée car plusieurs concepts ont gardé leur nom BOOTP. De plus, certaines fonctions essentielles de DHCP comme le bail sont mises en œuvre par une option BOOTP, à chercher dans le RFC 1533.
DHCP fonctionne par diffusion. Un client DHCP, c'est-à-dire une machine qui veut obtenir une adresses, diffuse sur tout le réseau (DHCP fonctionne au dessus d'UDP) sa demande. Le serveur se reconnait et lui répond.
Le serveur choisit sur quels critères il alloue les adresses IP (notre RFC dit « DHCP should be a mechanism rather than a policy »). Il peut les distribuer de manière statique (une même machine a toujours la même adresse IP) ou bien les prendre dans un pool d'adresses et chaque client aura donc une adresse « dynamique ». Le fichier de configuration ci-dessous montre un mélange des deux approches.
Par exemple, si le logiciel serveur est celui de l'ISC, sa configuration peut ressembler à :
# My domain
option domain-name "sources.org";
# Nameservers that the clients should use
option domain-name-servers ns.sources.org;
option subnet-mask 255.255.255.0;
# Duration of the lease, in seconds
default-lease-time 600;
max-lease-time 3600;
subnet 172.19.1.0 netmask 255.255.255.0 {
range 172.19.1.8 172.19.1.10;
# The default router to use. Do note that the DHCP server lets you
# specify it as a name, not an address
option routers gw.sources.org;
# Dynamic pool of IP addresses. Up to twenty clients.
range 172.19.1.100 172.19.1.120;
}
# This machine has a fixed (static) IP address
host preston {
hardware ethernet 08:00:20:99:fa:f4;
fixed-address preston.sources.org;
}
Sur le serveur, toujours avec ce logiciel, le journal indiquera les arrivées et départs des clients :
Mar 8 20:18:38 ludwigVI dhcpd: DHCPDISCOVER from 08:00:20:99:fa:f4 via eth0 Mar 8 20:18:38 ludwigVI dhcpd: DHCPOFFER on 172.19.1.2 to 08:00:20:99:fa:f4 via eth0 Mar 8 20:18:38 ludwigVI dhcpd: DHCPREQUEST for 172.19.1.2 from 08:00:20:99:fa:f4 via eth0 Mar 8 20:18:38 ludwigVI dhcpd: DHCPACK on 172.19.1.2 to 08:00:20:99:fa:f4 via eth0
Le client a d'abord cherché un serveur (section 3.1 du RFC), avec DHCPDISCOVER, le serveur lui a répondu en proposant l'adresse IP 172.19.1.2 (DHCPOFFER), le client l'a formellement demandé (DHCPREQUEST) et le serveur a confirmé (DHCPACK).
Et le client ? Il existe des clients DHCP dans tous les
systèmes. Lorsqu'on configure une machine
MS-Windows pour « Acquérir automatiquement une
adresse IP », c'est en DHCP qu'elle demande. Sur
Unix, un client courant est dhclient, ou bien
pump. Sur une machine NetBSD, on configure dans
/etc/rc.conf l'utilisation de dhclient
pour avoir un client DHCP :
dhclient=YES dhclient_flags=hme0
On notera que le démon dhclient tournera
en permanence. Il faut en effet demander périodiquement le
renouvellement du bail (délai de dix minutes dans la configuration du
serveur vue plus haut). Sur une machine Debian,
la configuration du client serait, dans
/etc/network/interfaces :
auto eth0 iface eth0 dhcp
Il faut bien noter (et notre RFC le fait dans sa section 7) que DHCP n'offre aucune sécurité. Comme il est conçu pour servir des machines non configurées, sur lesquelles on ne souhaite pas intervenir, il n'y a même pas un mot de passe pour authentifier la communication. Un serveur DHCP pirate, ou, tout simplement, un serveur DHCP accidentellement activé, peuvent donc être très gênants.
L'article seul
RFC 2130: The Report of the IAB Character Set Workshop held 29 February - 1 March, 1996
Date de publication du RFC : Avril 1997
Auteur(s) du RFC : Chris Weider (Microsoft Corp.), Cecilia Preston (Preston & Lynch), Keld Simonsen (DKUUG), Harald T. Alvestrand (UNINETT), Randall Atkinson (cisco Systems), Mark Crispin (Networks & Distributed Computing), Peter Svanberg (Dept. of Numberical Analysis and Computing Science (Nada))
Pour information
Première rédaction de cet article le 2 mars 2007
La question des jeux de caractères à utiliser sur Internet n'est pas nouvelle. Un des premiers RFC à la mentionner a été ce compte-rendu d'un séminaire IAB.
Ce séminaire, tenu en 1996, a étudié les différentes questions posées à l'IETF à ce sujet. Puisque l'IETF ne se préoccupe que de ce qu'on voit « sur le câble » (on the wire), les questions de rendu, comme le choix dex glyphes sont expréssement exclues.
Notre RFC conclus (section 8) par la nécessité de permettre l'utilisation d'Unicode dans tous les protocoles IETF, avec l'encodage UTF-8. En revanche, il reste prudent, voire timoré, pour ce qui concerne les identificateurs, prônant par exemple le statu quo pour les noms de domaines (qui seront finalement unicodisés dans le RFC 3490).
Ce séminaire mènera finalement à la publication du RFC 2277, qui définit, encore aujourd'hui, la politique de l'IETF en matière de jeux de caractères et de langues.
L'article seul
RFC 2119: Key words for use in RFCs to Indicate Requirement Levels
Date de publication du RFC : Mars 1997
Auteur(s) du RFC : Scott Bradner (Harvard University)
Première rédaction de cet article le 6 novembre 2007
Voici un méta-RFC, ne spécifiant aucun protocole, mais donnant des consignes sur la rédaction des autres RFC. Il spécifie les termes à utiliser pour exprimer des règles normatives comme « Le client doit faire ceci... » ou bien « Le serveur doit répondre cela... » de façon à permettre à l'implémenteur d'un protocole de bien discerner ce qui est obligatoire de ce qui ne l'est pas.
Dans ce domaine comme dans beaucoup d'autres, l'IETF est parti d'une situation où tout était informel pour arriver à une situation d'extrême normativité. Les RFC sont écrits en langue naturelle (il n'y a jamais eu de tentative de trouver ou de développer un langage formel pour les spécifications) et cette langue naturelle est souvent bien floue. En l'absence de règles portant sur le langage, les premiers RFC utilisaient parfois des verbes comme must (doit) ou may (peut) de manière imprécise, menant les implémenteurs à des disputes sur le droit à ne pas implémenter tel ou tel aspect de la norme.
D'où ce RFC, qui donne un sens rigoureux à certains mots, et qui les écrit EN MAJUSCULES pour qu'on ne les confonde pas avec leur usage « flou ». Sont ainsi rigoureusement spécifiés :
- MUST : l'implémentation DOIT agir ainsi,
- SHOULD : l'implémentation DEVRAIT agir ainsi, sauf raison explicite et bien comprise (SHOULD peut se résumer par « Dans le doute, faites-le »),
- MAY : l'implémentation PEUT faire ainsi si ça lui chante.
De même, leurs négations comme MUST NOT ou des variantes comme RECOMMENDED sont également définies.
Et voici pourquoi les RFC sont désormais truffés de mots en majuscules. Par exemple, le RFC 2616 contient : The HTTP protocol does not place any a priori limit on the length of a URI. Servers MUST be able to handle the URI of any resource they serve, and SHOULD be able to handle URIs of unbounded length if they provide GET-based forms that could generate such URIs.
Voici aussi pourquoi les groupes de travail de l'IETF passent souvent beaucoup de temps à discuter pour savoir si telle fonction doit être précédée d'un MUST ou d'un SHOULD. En gros, le MUST permet une meilleure interopérabilité (puisque toute mise en œuvre d'un protocole sait exactement à quoi s'attendre) mais contraint davantage, et peut-être excessivement.
L'article seul
RFC 2050: INTERNET REGISTRY IP ALLOCATION GUIDELINES
Date de publication du RFC : Novembre 1996
Auteur(s) du RFC : Kim Hubbard (InterNIC Registration Services), Mark Kosters (InterNIC Registration Services), David Conrad (Asia Pacific Network Information Center), Daniel Karrenberg (RIPE NCC), Jon Postel (USC/Information Sciences Institute)
Première rédaction de cet article le 10 février 2008
Les règles d'affectation des adresses IP sont un des sujets chauds (ou qui devraient l'être) de la gouvernance de l'Internet. Comme toute ressource critique et limitée, sa gestion fait l'objet d'âpres débats. Ce RFC est le seul qui parle de cette gestion, domaine réservé des RIR. (Il a depuis été remplacé par le RFC 7020.)
Ce n'est pas l'IETF mais le groupe des
RIR existants à l'époque qui a écrit ce RFC. Une
note de l'IESG en tête précise d'ailleurs que
ce RFC documente une politique, sans forcément l'approuver. En effet,
les politiques d'attribution des adresses IP sont actuellement
entièrement gérées au sein des RIR, même si des organismes comme
l'ICANN ou, plus récemment,
l'ITU ont parfois essayé de s'en mêler. Mais
pourquoi des décisions aussi techniques que l'attribution des adresses
du bloc 192.0.2.0/24 devraient-elles poser des
problèmes politiques ?
Il y a deux problèmes avec ces adresses : l'un est la taille limitée du registre. Si un protocole prévoit huit bits pour un champ indiquant une option, cela ne laisse que 256 valeurs possibles et l'organisme qui gère ces valeurs (l'IANA pour les protocoles Internet) doit les attribuer avec prudence, pour ne pas épuiser trop tôt la ressource. Or, les adresses IPv4 étant sur 32 bits (quatre milliards de valeurs), on ne peut pas en affecter une à chaque habitant de la planète. En pratique, il y a même moins de quatre milliards d'adresses possibles, en raison du facteur H (expliqué en RFC 1715 et RFC 3194). IPv6 résout complètement ce problème, avec ses adresses sur 128 bits.
Mais il existe aussi un autre problème : les préfixes d'adresses IP sont manipulés par les routeurs, échangés avec le protocole BGP (RFC 4271) et stockés dans les tables de routage desdits routeurs. Il existe des limites, aussi bien à la taille de ces tables (les routeurs de haut de gamme n'utilisent typiquement pas de la mémoire standard mais des ASIC spécialisés, très rapides mais plus limités en taille), qu'à la quantité de données échangées en BGP si les tables grossissent « trop ». La controverse technique fait rage entre certains gros opérateurs acharnés à limiter la taille des tables de routage et certains utilisateurs qui pensent que les limites ne sont pas purement techniques et que le désir de limiter la concurrence entre opérateurs joue également un rôle (voir par exemple le RFC 4984 pour une passionnante discussion sur le sujet).
Cela explique que gérer des adresses IP ne soit pas une tâche purement administrative d'enregistrement. Les RIR, émanation des opérateurs Internet, ont donc des politiques d'allocation, qui sont en IPv4 très restrictives, et qui le deviendront encore plus au fur et à mesure que la pénurie s'aggrave.
Ce RFC, qui succède au RFC 1466, décrit ces politiques, dans leurs grands principes (les politiques précises sont décrites sur le site Web de chaque RIR, elles changent assez souvent). Sa section 1 pose les buts, qui découlent des problèmes décrits plus haut :
- Conservation d'une ressource rare (un problème, on l'a vu, qui disparait avec IPv6).
- « Routabilité ». Ce point technique est par contre quasi-identique en v4 et v6. Il fait référence au fait qu'une mauvaise gestion des adresses IP pourrait se traduire par un travail insupportable pour les routeurs. Par exemple, si les adresses IP des clients d'un même fournisseur ne sont pas agrégeables en un petit nombre de préfixes (par exemple parce qu'elles ne sont pas contigües), le fournisseur va annoncer en BGP beaucoup plus de préfixes, au détriment de tous (voir le fameux CIDR report pour l'état actuel de l'agrégation).
- Enregistrement des informations sur les allocations, afin de pouvoir tracer l'utilisateur d'une adresse. C'est pour cela que les RIR ont un serveur whois (RFC 3912).
La même section 1 présente les différents acteurs, de l'IANA (fonction actuellement assurée par l'ICANN), qui alloue des adresses aux RIR, jusqu'aux LIR (en général des FAI) qui les reçoivent des RIR.
Notons que l'IANA n'a traditionnellement jamais mis de critères à la distribution d'adresses IP aux RIR. Malgré la très théorique section 6, qui donne aux utilisateurs le droit de faire appel des décisions auprès de l'IANA, le pouvoir reste concentré aux mains des RIR.
La section 2 décrit le mécanisme de distribution des adresses. Celles-ci sont allouées aux LIR par les RIR, en larges blocs, puis affectées aux clients finaux par les LIR, en blocs plus petits. Normalement, l'affectation, contrairement à l'allocation, est réversible : le client final n'est pas propriétaire de ses adresses (on parle d'adresses PA pour Provider-Aggregatable, les autres sont PI, Provider-Independent, et attribuées directement par le RIR).
Pour satisfaire les buts énumérés dans la section 1, le RFC énonce des règles comme le principe que les adresses soient prêtées et pas données. Il comporte aussi des micro-règles comme de spécifier que les clients finaux ne devraient pas avoir d'adresses IP statiques !
La section 2.2 est consacrée à l'enregistrement et insiste sur l'importance que les informations soient correctes et à jour. Comme pour les registres de noms de domaine, il s'agit d'un vœu pieux et les serveurs whois des RIR distribuent quotidiennement des informations dépassées, voire fausses.
La section 3 est plus spécifiquement consacrée à l'affectation,
c'est à dire à la distribution des adresses des LIR vers les clients
finaux. C'est elle qui explique les règles devant lesquelles va
plancher l'utilisateur, comme « 25 % des adresses affectées doivent
être pour un usage immédiat » ou comme la nécessité de fournir un plan
d'adressage (section 3.2) comme le fameux ripe-141
(aujourd'hui 381 mais souvent connu sous son ancien numéro).
Notez que, contrairement à ce que prétend la section 4.4, où le RIR s'autorise à enquêter sur l'utilisation effective des adresses, il n'y a jamais de contrôle et bien des organisations ont obtenu des quantités importantes d'adresses IP avec des plans mirobolants d'accès Internet par ADSL pas cher avec des dizaines de milliers d'abonnés en quelques semaines. Les règles des RIR favorisent donc ceux qui savent bluffer avec talent.
Le RFC 2050 n'a jamais été mis à jour. Pour voir les politiques d'allocation actuelles des RIR, il faut consulter leurs sites Web :
On peut comparer facilement les différentes politiques en http://www.nro.net/documents/nro46.html.
Lors de forums de discussion sur la gouvernance de l'Internet, relativement peu de discussions ont eu lieu sur l'allocation d'adresses IP, si on compare avec la gestion de la racine du DNS. Parce que les RIR, plus anciens et beaucoup plus efficaces, ont une meilleure légitimité que l'ICANN ? Parce que les RIR ont réussi à convaincre les participants à ces forums de regarder ailleurs ? Parce que la question est trop technique pour les politiciens et les avocats qui remplissent ces forums ? En tout cas, aujourd'hui où l'épuisement rapide des adresses IPv4 pose de manière encore plus aigüe l'allocation des adresses restantes, on peut s'inquiéter de ce qui va se produire dans les prochaines années. Certains proposent déjà ouvertement un marché des adresses IP, permettant aux pays du Nord, qui ont obtenu le plus d'adresses au début de l'Internet, de les vendre. C'est officiellement interdit par les RIR, mais cette interdiction tiendra t-elle face aux forces du marché ?
L'article seul
RFC 2047: MIME (Multipurpose Internet Mail Extensions) Part Three: Message Header Extensions for Non-ASCII Text
Date de publication du RFC : Novembre 1996
Auteur(s) du RFC : Keith Moore (University of Tennessee)
Chemin des normes
Première rédaction de cet article le 2 novembre 2008
La série de RFC sur
MIME, qui a introduit les caractères composés
(et les écritures non-latines), ainsi que les objets multimédia, dans
le monde du courrier électronique, comprend,
entre autres, ce RFC qui normalise une méthode pour mettre des
caractères non-ASCII dans les
en-têtes du courrier, ces métadonnées situées
avant le corps du message et structurées en nom:
valeur.
Normalement, le courrier, tel qu'il était normalisé par le RFC 822 (aujourd'hui RFC 5322), ne permettait que le jeu de caractères ASCII dans les en-têtes. C'est ainsi qu'il fallait écrire :
From: Stephane Bortzmeyer <bortzmeyer@sources.org> Subject: Du cafe bien fort !
au lieu de la forme correcte en français :
From: Stéphane Bortzmeyer <bortzmeyer@sources.org> Subject: Du café bien fort !
Notre RFC 2047 vise tout simplement à fournir une solution à ce problème, en encodant les caractères non-ASCII, en Quoted-Printable ou en Base64. Les en-têtes ci-dessus apparaitront donc sur le réseau comme :
From: =?iso-8859-1?q?St=E9phane?= Bortzmeyer <bortzmeyer@sources.org> Subject: Du =?iso-8859-1?q?caf=E9?= bien fort !
Ainsi, le message pourra passer à travers toute l'infrastructure du courrier qui n'accepte que l'ASCII. Ce sera au MUA de les remettre sous une forme lisible (voir par exemple mon article Décoder les en-têtes du courrier électronique).
L'approche de notre RFC est donc conservatrice : on ne demande pas à tous les logiciels sur le trajet de connaître MIME, autrement ce dernier n'aurait jamais été déployé. (MIME n'utilise même pas, par prudence, certaines fonctions du RFC 822 qui auraient pu aider mais qui sont trop souvent boguées, cf. section 1.) Aujourd'hui où l'infrastructure du courrier est très différente, une méthode plus radicale pourrait être réaliste et c'est l'approche du bien plus récent RFC 6532.
La section 2 du RFC donne la grammaire exacte : un terme encodé est
précédé de =? suivi de l'encodage des caractères. (Pour le corps
du message, tel que normalisé dans le RFC 2045,
l'encodage est indiqué dans un en-tête,
Content-Type. Pour les en-têtes eux-mêmes, il a
fallu trouver une autre solution.) Puis on trouve le surencodage
appliqué par MIME, Q pour
Quoted-Printable et B pour
Base64 puis le terme lui-même, ainsi encodé. Le
tout est terminé par un ?=. Voici le résultat,
produit par un programme Python avec le module email :
% python
>>> from email.header import Header
>>> h = Header('niçoise', 'iso-8859-1')
>>> print h
=?iso-8859-1?q?ni=E7oise?=
Notons que l'encodage utilisé est appelé charset (jeu de caractères) par MIME, ce qui n'est pas vraiment le terme correct (« utf-8 » est un encodage, le jeu de caractères est Unicode). La section 3 normalise ce paramètre, pour lequel les valeurs standard de MIME sont utilisées.
La section 4 décrit en détail les surencodages possibles, Quoted-Printable et Base64. Le premier (RFC 2045) convient mieux lorsque le texte comprend des caractères latins, avec quelques caractèrs composés. Le second (RFC 4648) est préférable si le texte est composé de caractères non-latins. La section 4.2 détaille quelques spécificités de Quoted-Printable et notamment l'utilisation du _ à la place de l'espace comme dans :
% python
>>> from email.header import Header
>>> h = Header("réveillés dans une Citroën niçoise", "ISO-8859-1")
>>> print h
=?iso-8859-1?q?r=E9veill=E9s_dans_une_Citro=EBn_ni=E7oise?=
Pour le même genre de tâches, les programmeurs Perl peuvent utiliser Encode::MIME::Header.
L'article seul
RFC 2046: Multipurpose Internet Mail Extensions (MIME) Part Two: Media Types
Date de publication du RFC : Novembre 1996
Auteur(s) du RFC : Ned Freed (Innosoft International, Inc.), Nathaniel S. Borenstein (First Virtual Holdings)
Chemin des normes
Première rédaction de cet article le 1 mars 2009
La norme MIME permettant de distribuer du contenu multimédia par courrier électronique est composée de plusieurs RFC dont le plus connu est le RFC 2045 qui décrit la syntaxe des messages MIME. Mais notre RFC 2046 est tout aussi important car il traite d'un concept central de MIME, le type des données. En effet, MIME attribue un type à chaque groupe de données qu'il gère. Cela permet d'identifier du premier coup telle suite de bits comme étant une image PNG ou une chanson codée en Vorbis. Ces types ont eu un tel succès qu'ils ont été repris par bien d'autres systèmes que MIME par exemple dans HTTP pour indiquer le type de la ressource envoyée au navigateur Web (avec Firefox, on peut l'afficher via le menu Tools, option Page info), ou même par certains systèmes d'exploitation comme BeOS qui, dans les métadonnées du système de fichiers, stocke le type de chaque fichier sous forme d'un type de média. Logiquement, le nom officiel a donc changé et on ne devrait plus dire type MIME mais « type du média ».
Ces types, conçus à l'origine pour être codés dans le message et
jamais vus par les utilisateurs ont finalement été diffusés largement
et presque tout auteur de contenu sur l'Internet a déjà vu des codes
comme text/html (une page
HTML), image/jpg (une
image JPEG) ou bien
application/octet-stream (un fichier binaire au
contenu inconnu). Si on veut voir la liste complète, ils sont
enregistrés dans un
registre à l'IANA, géré selon les règles du RFC 6838.
Quelle est la structure des types de média ? Chacun est composé de
deux parties (section 1 du RFC), le type de premier niveau comme
text ou audio qui identifie
le genre de fichiers auquel on a affaire (section 2) et le
sous-type qui identifie le format utilisé. Un
type est donc composé d'un type de premier niveau et d'un sous-type,
séparés par une barre oblique. Ainsi,
text/plain désigne des données au format
« texte seul » (type text
et format plain, c'est-à-dire sans aucun
balisage). application/msword
est un fichier lisible uniquement par un certain programme ou
catégorie de programmes (d'où le type de premier niveau
application) et au format
msword, c'est-à-dire le traitement de textes de Microsoft. Notez aussi le
type multipart, utile lorsqu'on transporte en
même temps des données de types différents (chaque partie sera alors
marquée avec son propre type de média).
Les types de média sont ensuite indiqués selon une méthode qui
dépend du protocole. Dans le courrier électronique, cela se fait avec
l'en-tête Content-Type par exemple pour un
message en texte seul :
Content-Type: text/plain;
charset="utf-8"
(Notez un paramètre supplémentaire, la mention de l'encodage, appelé par MIME charset, car un texte brut peut être en ASCII, en Latin-1, en UTF-32, etc. Voir section 4.1.2.)
Dans le monde du Web, voici un exemple affiché par le client HTTP wget :
% wget http://upload.wikimedia.org/wikipedia/commons/e/ec/En-us-type.ogg ... Length: 12635 (12K) [application/ogg] ...
Ici, un fichier Ogg (la prononciation
de « type » en anglais) a été chargé et le serveur
HTTP avait annoncé le type MIME application/ogg
(depuis le RFC 5334, cela devrait être
audio/ogg mais le changement est lent sur l'Internet).
La définition complète des types de premier niveau figure dans la
section 2. pour chaque type, on trouve sa description, les paramètres
qui ont du sens pour lui (comme charset dans
l'exemple plus haut), la manière de gérer les sous-types inconnus,
etc.
La section 3 décrit les sept types de premier niveau de l'époque (ils sont dix, début 2017). Il y a deux types composites et cinq qui ne le sont pas, détaillés en section 4.
Le plus simple, text est... du texte
et qu'on puisse visualiser sans logiciel particulier. L'idée est
également qu'on peut toujours montrer de telles données à un
utilisateur humain, même si le sous-type est inconnu (règle simple
mais pas toujours d'application simple, comme l'ont montré les
polémiques sur text/xml). Cela fait donc de
text un excellent format stable et lisible par
tous (et qui est donc utilisé pour les RFC eux-même). Les formats
illisibles sans logiciel particulier ne sont donc pas du
text au sens MIME. Des exemples de formats
text ? Évidement plain cité
plus haut, le texte brut mais aussi :
troff(RFC 4263),enrichedaliasrichtext, qui avait été créé spécialement pour MIME (RFC 1896) mais qui n'a jamais eu beaucoup de succès.csv(RFC 4180) pour des données au populaire format CSV.
En théorie, les formats de balisage légers modernes comme reST ou comme ceux des Wiki par exemple le langage de MediaWiki pourraient rentrer ici mais, en pratique, aucun sous-type n'a encore été enregistré.
La section sur les encodages, 4.1.2, recommande que le paramètre
charset soit le PGCD des
encodages possibles. Par exemple, si le texte ne comprend que des
carractères ASCII, charset="UTF-8" est correct
(puisque UTF-8 est un sur-ensemble d'ASCII)
mais déconseillé. mutt met en œuvre
automatiquement cette règle. Si on écrit dans sa configuration,
set send_charset=us-ascii:iso-8859-15:utf-8, mutt
marquera le message comme ASCII s'il ne comprend que des caractères
ASCII, sinon ISO-8859-15 s'il ne comprend que
du Latin-9 et UTF-8 autrement.
image (section 4.2), audio (section 4.3) et
video (section 4.4) sont décrits ensuite.
application (section 4.5) est plus difficile à saisir. Ce
type de premier niveau est conçu pour le cas où les données sont
définies par une application (ou un groupe d'applications puisque, par
exemple, de nombreuses applications peuvent lire le format
PDF, que le RFC 3778 a enregistré sous
le nom de application/pdf). Le RFC détaille
l'exemple de application/postscript pour le
langage Postscript (section 4.5.2). Ce type
application est souvent associé à des problèmes
de sécurité car charger un fichier sans précaution peut être dangereux
avec certains types de fichier ! Le RFC cite des exemples comme
l'opérateur deletefile de Postscript mais
beaucoup d'autres formats ont des contenus potentiellement « actifs ».
Il y a un certain recouvrement entre les domaines de
text et de application,
parfaitement illustré par le vieux débat sur le statut de
HTML : est-ce du texte ou pas ?
La section 3 couvre aussi le cas des types de premier niveau
composés comme multipart et
message, détaillés en section 5. Le premier
(section 5.1) permet de traiter des
messages comportant plusieurs parties, chaque partie ayant son propre
type. Par exemple, un message comportant du texte brut et une musique
en Vorbis sera
de type multipart/mixed et comportera deux
parties de type text/plain et
audio/ogg (ou, plus précisément, audio/ogg; codecs="vorbis"). On peut aussi avoir plusieurs
parties équivalentes (par exemple le même texte en texte brut et en
HTML) et utiliser alors le type
multipart/alternative. (Mais attention à bien
synchroniser les deux parties.)
Le second type composé, message (section 5.2) sert à
encapsuler des messages électroniques dans d'autres messages, par
exemple pour les faire suivre ou bien pour un avis de non-remise. Un
message au format du RFC 5322 sera ainsi marqué
comme message/rfc822 (le RFC 822 étant
l'ancienne version de la norme).
On peut aussi avoir des types de premier niveau et des sous-types
privés (section 6), attribués par simple décision
locale. Pour éviter toute confusion avec les identificateurs
enregistrés, ces identificateurs privés doivent commencer par
x- comme par exemple
application/x-monformat.
À noter qu'il n'existe pas de types MIME pour les
langages de programmation. Quasiment tous sont
du texte brut et devraient être servis en
text/plain. Leur donner un type n'aurait
d'intérêt que si on voulait déclencher automatiquement une action sur
ces textes... ce qui n'est en général pas une bonne idée, pour des
raisons de sécurité. C'est ainsi que seuls les langages
sandboxables
comme Javascript (RFC 9239) ont leur
type MIME. Résultat, on voit souvent les types privés utilisés,
par exemple le fichier /etc/mime.types qui, sur
beaucoup d'Unix, contient la correspondance
entre une extension et un type MIME, inclus,
sur une Debian,
text/x-python pour les fichiers
.py (code Python). Par
contre, pour C, le type est
text/x-csrc et pas simplement
text/x-c, sans doute pour être plus
explicite. Autre curiosité, je n'y trouve pas de type MIME pour les
sources en Lisp...
Ce RFC a remplacé l'ancien RFC 1522, les changements, importants sur la forme mais peu sur le fond, étant décrits dans l'annexe B du RFC 2049.
L'article seul
RFC 2045: Multipurpose Internet Mail Extensions (MIME) Part One: Format of Internet Message Bodies
Date de publication du RFC : Novembre 1996
Auteur(s) du RFC : Ned Freed (Innosoft International, Inc.), Nathaniel S. Borenstein (First Virtual Holdings)
Chemin des normes
Première rédaction de cet article le 4 avril 2008
Autrefois, du temps des dinosaures, les internautes vivaient dans des cavernes et gravaient au silex des courriers en texte seul, sur des écorces d'arbre. En 1992, MIME a été inventé et, depuis, les humains sont civilisés et envoient du spam en HTML, des vidéos débiles et des photos ratées par courrier électronique. Notre RFC 2045 est l'actuelle norme MIME.
À l'origine du courrier électronique, la
norme (aujourd'hui le RFC 5322) décrivait surtout les
métadonnées, les en-têtes du message, comme
From: (l'expéditeur) ou
Date: (la date d'envoi). Le
corps du message, lui, était laissé au seul
texte brut, dans le seul jeu de caractèrs
US-ASCII.
Pour transmettre du non-texte, par exemple des images de Carla Bruni, on se servait d'encodages non-standard, qui transformaient le fichier binaire en texte. C'était l'époque de uuencode (ou de Binhex pour les macounistes). Même pour le texte seul, dès qu'on dépassait les limites du jeu de caractères ASCII, donc, dès qu'on écrivait autre chose que l'anglais, on ne pouvait plus rester strictement dans les limites du RFC 822 (la norme du courrier de l'époque). Ces limites et les motivations pour MIME sont décrites dans la section 1 du RFC.
MIME a changé cela. Normalisé à l'origine dans le RFC 1341, puis dans le RFC 1521 (et suivants) et finalement dans notre RFC 2045 et ses compagnons suivants, MIME repose sur quatre piliers :
- Un format pour le corps du message, normalisé dans le RFC 2045, format récursif, permettant d'inclure diverses parties dans un message,
- Des encodages pour les parties binaires,
- Une notion de type, normalisée dans le RFC 2046, permettant d'étiqueter sans ambiguïté les parties du message, notion qui a eu un grand succès et est utilisée par bien d'autres protocoles,
- Un truc permettant de mettre des caractères non-ASCII dans les en-têtes (RFC 2047).
Pour le texte, MIME utilise la notion de character set (section 2.2). Comme l'explique une note de cette section, le terme est erroné, puisqu'il s'agit en fait, dans MIME, d'un encodage, pas simplement d'un jeu de caractères.
Avec la section 3, commence la description du format MIME lui-même. MIME ajoute quelques
nouveaux en-têtes à commencer par MIME-Version
(section 4)
qui indique qu'il s'agit d'un message MIME. La section 5 décrit
l'en-tête Content-type qui spécifie le type MIME
du message ou de la partie du message. Il existe un zoo entier de ces
types, conservé dans un registre
à l'IANA. Le principe est que le type est
composé de deux parties, le type proprement dit, qui identifie le
genre de données (texte, image, son, ...) et le sous-type qui
identifie le format. Ainsi, image/png est une
image au format PNG,
text/troff est du texte au format
troff (RFC 4263). Plus complexes, les
types message ou
application. Le premier identifie un message MIME
inclus dans un autre message MIME (par exemple lors de l'envoi d'un
avis de non-réception (RFC 3461). Le second identifie des
données binaires qui ne peuvent être comprises que par une application
spécifique, indiquée par le sous-type. La classification MIME n'est
pas toujours aussi évidente et je n'ai personnellement jamais compris
pourquoi XML est en
application/xml et pas
text/xml. Enfin, des paramètres peuvent se
trouver dans cet en-tête, par exemple pour indiquer
l'encodage d'un texte (Content-Type:
text/plain; charset=utf-8) ou bien pour indiquer le site où
récupérer un document pointé (comme dans le programme d'exemple
ci-dessous).
La section 6 introduit un autre en-tête,
Content-Transfer-Encoding qui indique comment le
contenu a été emballé pour passer à travers des serveurs (qui peuvent
n'accepter que l'ASCII). Un Content-Transfer-Encoding:
8bit spécifie que le contenu n'a pas été modifié du tout,
il faudra alors que tous les serveurs laissent passer le 8bits. À une
époque très lointaine, où les mammouths étaient encore fréquents en
France, certains serveurs mettaient le huitième bit à zéro ou autres
horreurs ; une longue polémique, au début des années 1990, avait
opposé ceux qui voulaient transmettre les textes en français en 8bits
(et tant pis pour les quelques serveurs archaïques) et ceux qui
préféraient l'encoder dans des systèmes comme
Quoted-Printable
(Content-Transfer-Encoding: quoted-printable,
décrit en détail dans la section 6.7), qui étaient plutôt pires pour
les MUA de l'époque, qui affichaient caf=E9 au
lieu de café...
À titre d'exemple, voici un programme Python qui analyse un message MIME. Le
programme n'est pas récursif, bien que cela soit souvent utile pour
les messages MIME, la définition même du format étant récursive (un
message peut être composé de parties qui sont elles-mêmes composées de
parties, etc, cf. la note de la section 2.6). Ces messages contiennent
une partie de type message/external-body qui
donne des instructions d'accès à un fichier par FTP :
import email
from email.MIMEText import MIMEText
...
# We receive the message on standard input (for instance through
# procmail and its pipe action)
message = email.message_from_file(sys.stdin)
subject = message.get("subject")
# A MIME message can be single-part but we are interested only in multi-parts
if not message.is_multipart():
raise NotForMe("Not multipart")
...
# The body of the message
parts = message.get_payload()
# Iterate over the parts of the message
for part in parts:
if part.get_content_type() == "message/external-body":
params = dict(part.get_params())
if params["access-type"] == "anon-ftp":
url = "ftp://%s/%s/%s" % (params["site"],
params["directory"],
params["name"])
...
À l'époque du RFC 822, écrire un programme qui analysait les messages électroniques était trivial, on pouvait travailler directement avec le texte, même un simple grep suffisait. Avec MIME, les parties multiples (section 5.1 du RFC 2046), et les encodages variés, l'utilisation de bibliothèques comme email en Python devient indispensable. Par exemple, les spammeurs encodent souvent leurs messages en Base64 (section 6.8, désormais dans le RFC 4648), afin de trompeur les analyseurs de mots-clés naïfs.
On note que ce RFC, ce qui est relativement rare, contient également d'intéressantes notes (introduites par NOTE) sur les choix effectués par les concepteurs du format MIME. Leur lecture permet de mieux comprendre ces choix.
L'article seul
RFC 2033: Local Mail Transfer Protocol
Date de publication du RFC : Octobre 1996
Auteur(s) du RFC : J. Myers (Carnegie Mellon)
Pour information
Première rédaction de cet article le 21 février 2006
Ce RFC normalise LMTP (Local Mail Transfer Protocol), une variante du protocole SMTP de transmission du courrier électronique.
SMTP convient mal aux cas où le serveur suivant ne gère pas de file d'attente et peut, de manière synchrone, délivrer le message ou bien annoncer avec certitude qu'il est indélivrable. En fait, LMTP est un protocole de communication entre MTA et MDA, pas entre MTA, comme l'est SMTP.
LMTP est très proche de SMTP, il reprend les mêmes concepts et commandes, mais il y a quelques différences, notamment le fait que, si un message a plusieurs destinataires, le succès ou bien l'échec de la délivrance peut être par utilisateur et pas seulement par message.
LMTP est mis en œuvre dans Postfix (voir la documentation provisoire) et dans Cyrus.
L'article seul
RFC 2026: The Internet Standards Process -- Revision 3
Date de publication du RFC : Octobre 1996
Auteur(s) du RFC : Scott O. Bradner (Harvard University)
Première rédaction de cet article le 1 décembre 2008
Comment sont développées les normes Internet ? Qui les décide ? Comment les changer ? Ce RFC repond à toutes ces questions, en décrivant le processus de normalisation dans l'Internet. Bien sûr, comme pour beaucoup de processus sociaux, la réalité est parfois très éloignée de la description...
La plupart des normes techniques qui régissent l'Internet sont écrites dans des RFC (l'inverse n'est pas vrai : beaucoup de RFC ne sont pas des normes). Ces RFC de normalisation sont développés au sein de l'IETF et on peut trouver une description des activités de l'IETF dans mon exposé IETF à JRES.
Certains RFC ne décrivent pas un protocole ou un format mais des règles à suivre lors du développement des normes et c'est le cas de ce RFC. Son introduction rappelle que toute cette activité se déroule sous la responsabilité de l'ISOC (l'IETF n'est qu'une étiquette, elle n'a pas de personnalité juridique).
La section 1 résume les grands principes : il n'existe pas de « police des normes » (section 1.1) qui ferait respecter les RFC, la conformité à ces normes est volontaire (une norme industrielle n'est pas une loi). Et les normes Internet sont censées représenter une technique qui fonctionne, qui est bien comprise et pour laquelle existent au moins deux mises en œuvre interopérables (contrairement à une légende très répandue, il n'est pas exigé qu'une de ces mises en œuvre soit libre).
Le processus d'élaboration des normes lui-même est résumé en section 1.2. Il est ouvert à tous, est pratiqué par « la communauté » (community, mot fourre-tout dans le discours politique états-unien, qui n'est jamais clairement défini et qui exprime surtout la nostalgie du petit village fermé et regroupé autour de son église) et vise à obtenir un consensus de toutes les parties prenantes. Les procédures de ce RFC doivent être honnêtes, ouvertes et objectives. (Oui, la langue de bois est très présente dans ce RFC.)
Le RFC explique bien la difficulté de la normalisation dans un monde qui évolue aussi vite que celui des réseaux informatiques. La normalisation est forcément lente, à la fois pour des raisons sociales (construire le consensus) et techniques (écrire une norme correcte est un travail difficile), alors que la technique bouge très vite.
La section 2 décrit les documents qui sont produits par le processus de normalisation. Il commence évidemment (section 2.1) par les RFC. Ces textes, bien mal nommés (RFC voulait dire Request For Comments, ce que ne reflète plus leur statut et leur stabilité ; mais le nom est resté) existent depuis très longtemps (le RFC 1 a été publié en avril 1969). Ils sont largement et gratuitement disponibles (pendant longtemps, cela a été une des spécificités de ces normes, et une des raisons du succès de TCP/IP par rapport aux technologies concurrentes). Ils sont publiés par un organisme séparé, le RFC editor. C'est lui qui définit les règles (assez archaïques) de format, le texte brut, obligatoire pour les RFC qui ont le statut de norme.
Car ce n'est pas le cas de tous les RFC. Les normes proprement
dites ne sont qu'un sous-ensemble des RFC. Dans l'index, on les reconnait au texte STDnnn qui indique leur numéro dans la série des normes
(STanDard ; par exemple,
UDP, RFC 768 est STD0006). D'autres RFC n'ont pas ce statut et
peuvent être publiés par le RFC editor seul, sans
implication de l'IETF. C'est un point important, souligné par le RFC 1796 : Not All RFCs are Standard.
Mais les RFC ne naissent certainement pas tout armés ? Comment évoluent-ils et à partir de quoi ? C'est l'objet de la section 2.2, consacrée aux Internet-Drafts (on dit aussi I-D), les RFC en gestation. Un I-D n'a aucune valeur normative et notre RFC sur les normes rappelle bien qu'il est déconseillé de s'appuyer sur un I-D, par exemple pour un appel d'offres. De même, un vendeur ne devrait pas citer d'I-D dans la liste des fonctions de son produit. En effet, les I-D ne sont pas stables et peuvent changer à tout moment (en outre, même si le RFC 2026 ne le rappelle apparemment pas, n'importe qui peut écrire un I-D et le faire distribuer par l'IETF, il n'y a pas de contrôle).
La section 3 introduit une distinction qui n'a guère été utilisée entre les spécifications techniques (TS pour Technical Specifications) et les consignes d'application (AS pour Applicability Statement), qui expliquent comment appliquer les premières. Même le vocabulaire n'est pas resté et les sigles TS et AS ne semblent plus utilisés à l'IETF.
La section 4 en arrive au chemin des normes (standards track, la route que suivent les RFC vers le nirvana du statut de « norme au sens strict »). À noter que cette partie a été réformée par la suite dans le RFC 6410, qui a réduit le nombre d'étapes à deux. Les détails des anciens trois statuts sont publiés dans la section 4.1. Une fois publiée en RFC, la technique qui a été lancée sur le chemin des normes a le statut de proposition de norme (proposed standard, section 4.1.1). Si tout va bien, lorsqu'elle mûrira, et que deux mises en œuvre distinctes existeront, un nouveau RFC sera publié, avec le statut de projet de norme (draft standard, section 4.1.2). Enfin, après de longs efforts, des tests d'interopérabilité et pas mal d'actions de lobbying, un dernier RFC sera publié, avec le statut de norme au sens propre (Standard ou Internet Standard ou Full Standard, section 4.1.3). C'est par exemple ce qui est arrivé au format ABNF, proposition de norme dans le RFC 2234, projet de norme dans le RFC 4234 et désormais norme complète dans le RFC 5234 (voir la section 6.2 pour des détails, notamment de délais obligatoires). Par contre, si l'expérience montre qu'une technique a des failles et qu'il faut modifier la spécification de manière non triviale, on repart de zéro (section 6.3).
Mais il faut noter que ces trois statuts ne correspondent pas toujours à la réalité. Des techniques très employées sont restées au statut de proposition (par exemple Sieve, RFC 5228), d'autres ont le statut de norme alors qu'elles ne sont plus utilisées (comme chargen du RFC 864). Il faut donc prendre ce classement avec prudence. (Je me souviens d'une réunion où une juriste d'un gros FAI, assez ignorante de tout ce qui concerne la normalisation, avait défendu leur politique de filtrage du courrier en ergotant sur le fait que le RFC 2821 n'était que proposition de norme...) C'est entre autre pour cela que le RFC 6410 a par la suite réduit le nombre de statuts possibles à deux.
Il existe aussi de nombreux RFC qui ne sont pas du tout sur le chemin des normes (section 4.2). C'est le cas des RFC « expérimentaux » (section 4.2.1), statut normalement réservé aux protocoles pas vraiment mûrs et sur lesquels il n'existe pas encore de consensus sur leur inocuité. Ce statut peut aussi être attribué pour des raisons politiques, comme ce fut le cas avec le RFC 4408, bloqué par la volonté de certains gros acteurs.
Le statut « pour information » (section 4.2.2) est notamment celui de tous les RFC qui ne décrivent pas un protocole ou un format mais rendent compte d'une expérience, ou formulent un cahier des charges, ou expliquent les raisons de certains choix. Pour éviter les collisions avec le travail de normalisation à proprement parler, l'IESG a son mot à dire sur ces RFC, pour pouvoir soulever d'éventuelles objections (section 4.2.3).
Enfin, le statut « historique » (section 4.2.4) revient aux RFC qui ont été officiellement considérés comme dépassés par les évolutions techniques et l'expérience acquise. C'est ainsi que, par exemple, le protocole whois++ qui devait remplacer whois, avait été normalisé dans le RFC 1913 qui, n'ayant jamais connu de déploiements significatifs, a été reclassé historique...
À noter que, de même que l'avancement d'une technique sur le chemin des normes nécessite une action délibérée de certains, le reclassement en « historique » demande que quelqu'un fasse le travail de documentation des raisons du reclassement. C'est pour cela que beaucoup de RFC sont simplement tombés en désuétude, sans même que quelqu'un se donne la peine de les faire formellement reclassifier (comme le RFC 1256).
Un statut particulier a droit à une section à lui : BCP
(Best Current Practices, « Bonnes pratiques
actuelles », section 5). Ces documents ne normalisent pas une
technique mais une façon de l'utiliser « correctement ». Ils reçoivent
également un numéro commençant par BCP. C'est
ainsi que le RFC 2827, sur le filtrage des
paquets trichant sur l'adresse source, est également
BCP0038 et que le RFC 5226,
sur la gestion des registres IANA est aussi le
BCP0026. Un autre usage des BCP est de garder un
pointeur vers la version actuelle de la
norme. En effet, les RFC ne sont jamais modifiés mais remplacés. Si on
se réfère à un RFC, on court donc le risque de pointer un jour vers un
texte obsolète et il est donc recommandé d'utiliser plutôt le numéro
de BCP. Par exemple, BCP0047 désignera toujours
le RFC actuel sur les étiquettes
de langue (actuellement le RFC 5646).
Le processus d'avancement des normes est décrit complètement en section 6. Je rappelle qu'il n'est pas automatique. Une norme n'avance pas toute seule mais seulement parce qu'un groupe de gens trouvait important de la faire avancer... et a su convaincre l'IESG (section 6.1.2).
L'IETF étant une organisation humaine et le fait de travailler sur des normes techniques ne supprimant pas les passions et les intérêts matériels, les conflits sont fréquents. Il n'est donc pas étonnant qu'il existe une section, la 6.5, sur les conflits et leur résolution. Elle détaille un mécanisme d'escalades successives. D'abord, faire appel aux présidents du groupe de travail considéré, puis au directeur de zone (une zone chapeautant plusieurs groupes), puis à l'IESG puis à l'IAB, ultime arbitre.
Il n'y a pas que l'IETF dans le monde et certaines normes très importantes sur Internet sont issues d'autres organisations (par exemple, HTML vient du W3C, Ethernet de l'IEEE et X.509 de l'UIT). La section 7 décrit donc l'interaction avec les autres SDO. Certaines normes sont qualifiées d'« ouvertes » et d'autres de « autres » mais sans que ces termes soient définis avec précision. Les normes « ouvertes » (ce terme a traditionnellement été utilisé à l'IETF de manière très laxiste, intégrant même des normes comme celles de l'ISO, qui ne sont pas publiquement accessibles) peuvent être référencées par les RFC. Les « autres » sont typiquement découragées mais peuvent être utilisées si nécessaire (section 7.1.2).
Le processus de développement des normes à l'IETF a toujours été ouvert, et les discussions elles-mêmes sont enregistrées et archivées (contrairement à l'ISO où tout, même les votes, est secret). La section 8 décrit les obligations de conservation que s'impose l'IETF.
Ce RFC 2026, dérivé du RFC 1602, lui même issu du RFC 1310, est assez ancien et c'est une autre raison pour laquelle il ne reflète pas toujours bien le processus actuel. Il a parfois été mis à jour (par exemple, sur la question des droits de propriété intellectuelle, qui était traitée en section 10, mais qui est maintenant du ressort des RFC 8721 et RFC 5378) mais de manière incomplète.
L'article seul
RFC des différentes séries : 0 1000 2000 3000 4000 5000 6000 7000 8000 9000
{kind=link}